
Thanos를 쓰는 이유를 알기위해서는 Prometheus에 대해서 먼저 알아야합니다.
Prometheus 한계점
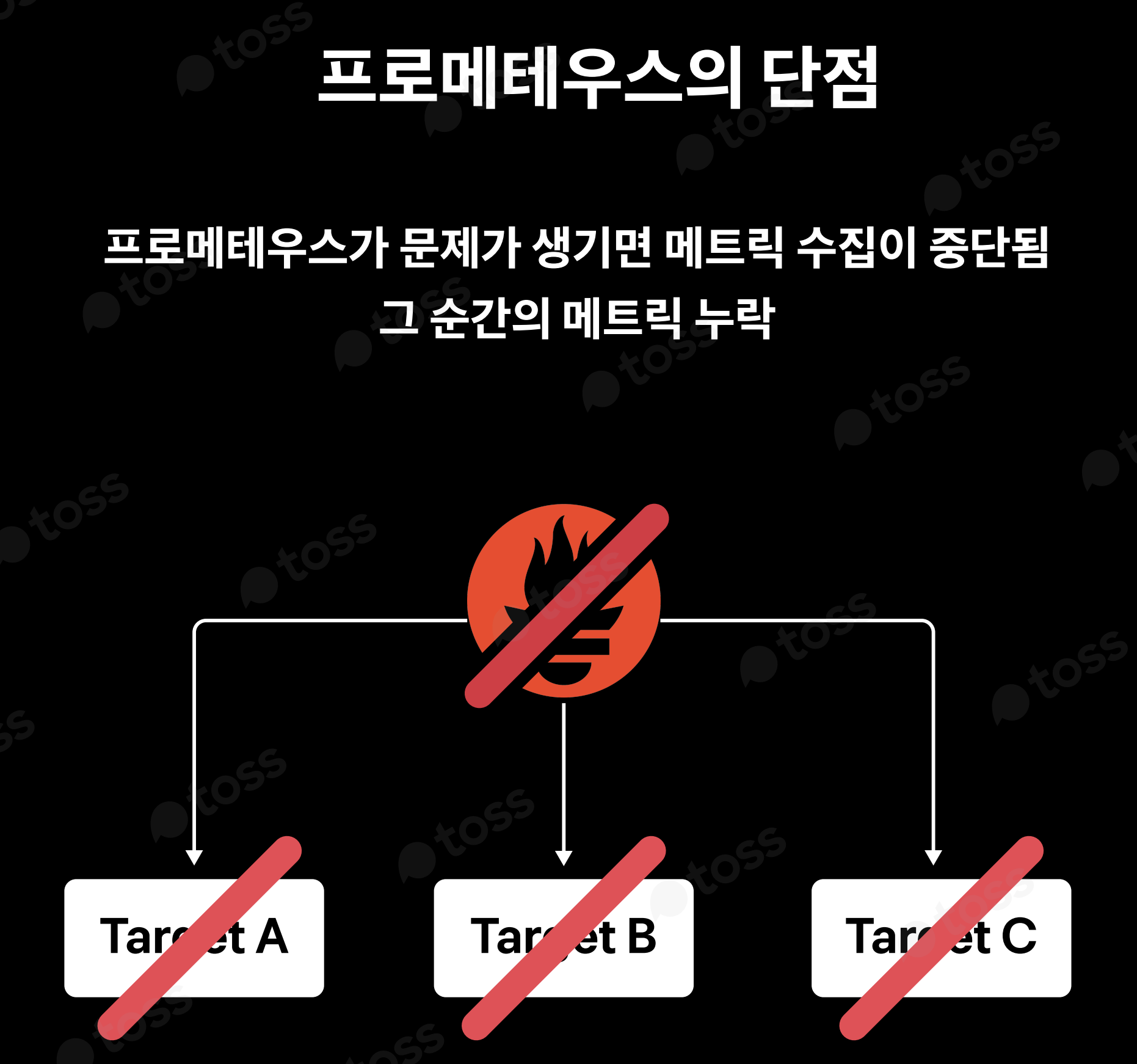
1. Prometheus는 scale-out이 불가능
그래서 여러개를 사용시에는 매번 재구동을 해야하기에 shutdown 시 모니터링이 중지되므로 리소스 손실의 문제가 있습니다.
2. 과다한 메모리 사용
수집하는 매트릭량+tsdb의 크기가 메모리에 비례하게됩니다.
따라서 과도한 메모리를 사용할 경우 문제가 발생할 수 있으므로 수집하는 메트릭량을 효과적으로 감소해서 운영해야합니다.
즉, 프로메테우스가 쌓고 있는 tsdb의 사이즈를 줄여야합니다.
Thanos 장점
1) Global Query View
다수의 Prometheus 서버에서 수집된 로그에 대해 한번에 조회할 수 있다.
2) Unlimited Retention
저장된 로그를 S3 와 같은 외부 저장공간에 저장할 수 있다.
로컬 스토리지의 한계로 인한 저장 기간의 제한이 없습니다.
3) Prometheus Compatible
Prometheus 의 한계점을 커버해준다.
4) Downsampling & Compaction
장기간의 로그를 조회할 경우, 실제 데이타는 10초 간격이라 해도,
조회에 필요한 데이타는 10분에 한건으로 다운샘플링할 수 있다.
Thanos 아키텍처
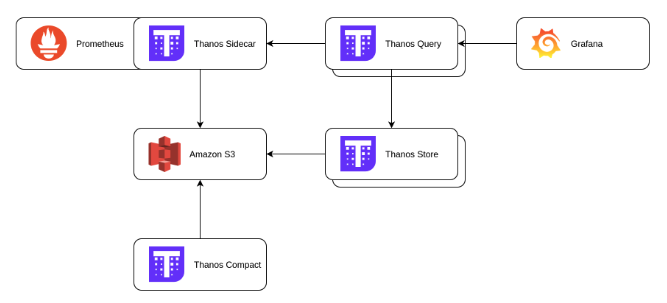
- Thanos Sidecar
Prometheus 의 작동을 방해하지 않고, 옆에서 같이 데이타를 수집합니다. - Thanos Store
로그 데이타를 저장합니다.
S3 와 같은 외부 저장공간으로 로그를 전송 또는 다시 가져올 수 있다. - Thanos Querier
다수의 Prometheus 서버에서 수집된 로그를 한번에 조회할 수 있다. - Thanos Compactor
로그데이타를 다운샘플링할 수 있다.
Thanos로 prometheus 한계저 극복
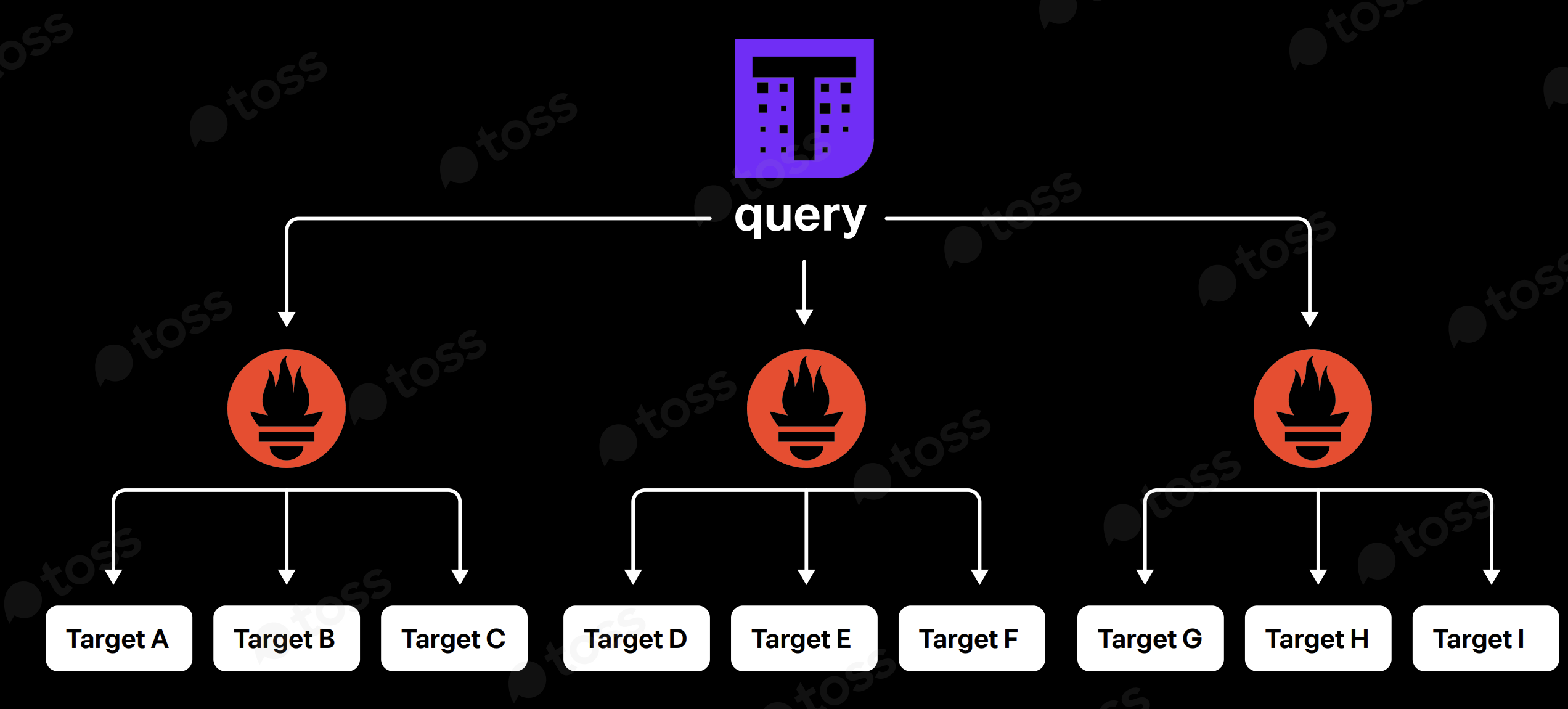
1. thanos query를 통한 통합 쿼리를 통해 prometheus들이 수집한 매트릭을 한곳에서 사용이 가능합니다.
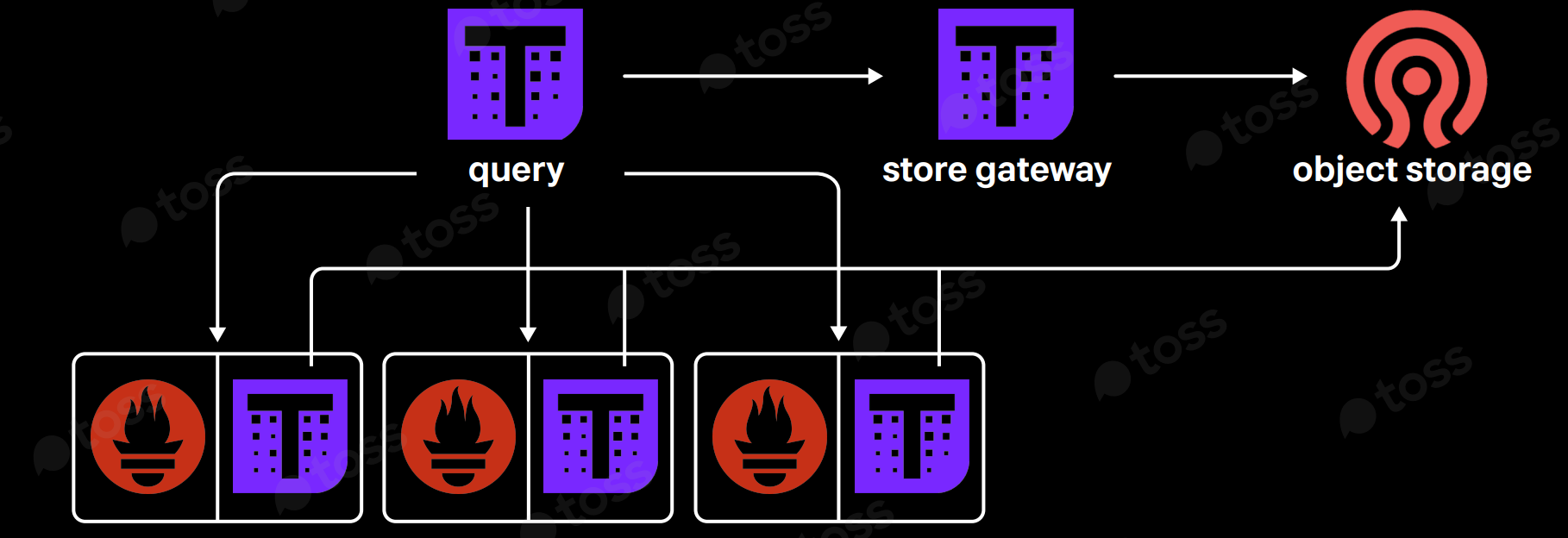
2. Thanos Sidecar로 tsdb 사이즈 축소
Thanos Sidecar로 tsdb를 Object storage에 업로드하고 thanos store gateway를 통해 long-term 매트릭을 조회하는 방식을 통해 tsdb의 저장을 최소화할 수 있습니다.
TOSS SLASH 21을 보니, https://toss.im/slash-21/sessions/1-2
해당 영상의 토스코어 DevOps Engineer팀의 이재성님께서 모니터링 서비스에 prometheus의 단점과 그를 극복하기에 thanos가 왜 적합한지를 잘 설명해주고 계십니다.
뛰어난 분들이 계신 곳인것 같아요...bb 저도 저런 대외 기술발표를 언젠간 꼭 할겁니다!!!무튼 해당 영상도 꼭 살펴보심이 도움이 되실 것입니다.
