우리는 앞선 포스팅을 통해 모델 서빙에 대해 알아보았다.
모델 서빙
서빙은 손님에게 음식을 가져다주는 행위를 말한다. 모델 서빙도 이와 같은 개념인데, 딥러닝이든 머신러닝이든 어떠한 모델이 예측한 예측값을 사용자에게 전달하는 것이다.
모델 서빙을 위해서는 여러 상황을 고려해야 하는데, 시간에 따라 변화하는 모델의 변경이력과 성능을 관리하는 형상관리와 장애와 유연함에 대응하는 고가용성/확장성이다.
모델 서빙을 위해서는 여러 상황을 고려해야 하는데, 시간에 따라 변화하는 모델의 변경이력과 성능을 관리하는 형상관리와 장애와 유연함에 대응하는 고가용성/확장성이다.
이러한 고려사항을 해결하기 위해 최근 모델 서빙에 대한 연구가 활발하게 이루어지고 있는데,
대표적으로 소개되는 해결책으로 모델 컨테이너와 카나리 모델/롤백이다.
이는 앞선 포스팅에서 잘 설명해 두었으니 앞선 포스팅을 확인해주세요.
간단히만 짚고 넘어갈게요.
모델 컨테이너
모델 컨테이너를 통해 모델 운영을 추상화하여 마치 도커 컨테이너를 이용하여 개발자들이 운영을 신경쓰지 않고 개발에 집중할 수 있게 하듯이 데이터 과학자가 모델 개발에 집중할 수 있게끔한다.
카나리
카나리는 옛날 석탄 광산에서 유독가스의 누출 위험을 알려주는 새이다.
MLOps에서 새로운 모델을 서빙하는 것은 꽤나 위험한 일이기 때문에, 광부가 카나리를 이용하 미리 위험을 알 수 있듯이, 데이터 과학자들도 카나리 모델을 통해 테스트를 해볼 수 있다.또한 운영중인 모델의 성능이 기준보다 좋지 않다면 특정 모델로 교체해야 하는데, 이것이 롤백이다.
모델 컨테이너를 사용하기 때문에 내부 모델의 바이너리 파일을 교체하는 것으로 간단히 롤백할 수 있다.
서빙을 간편하게 해주는 도구
이러한 서빙을 간편하게 해주는 도구가 오늘 비교해볼 kubeflow와 mlflow이다.
우선 둘의 유사점과 차이점부터 살펴볼까 한다.
kubeflow와 mlflow 유사점
- 모델 개발에 대한 협력적인 환경을 조성하기 위해 만들어졌다.
- 확장과 커스터마이징이 가능하다.
- 머신러닝 플랫폼으로 대표되는 기술이다.
kubeflow와 mlflow 차이점
1. 동작방식

kubeflow
kubeflow는 기본적으로 쿠버네티스를 기반으로 동작하는 컨테이너 오케스트레이터이다.
따라서 kubeflow에서 모델을 학습시킨다는 것은 "쿠버네티스 클러스터" 안에서 일어나는 일이다.mlflow
반면 mlflow는 모델에 대한 실험과 버전을 트래킹하는 파이썬 프로그램으로, 실제 학습은 내가 지정한 환경(ex. 로컬, 특정 서버)에서 실행되는 것이다.
mlflow는 단지 모델의 파라미터나 metric만 추척하며 기록한다.
kubeflow는 기본적으로 쿠버네티스에 대한 지식이 필요하기 때문에 그런 이유로 데이터 과학자들이 mlflow를 더 선호하는 경우도 많다.
kubeflow는 어렵지만 그만큼 높은 생산성을 가지고 있고, 최근 많은 기업에서 사용되고 있다.
2. 확장성
kubeflow는 근본적으로 확장성 있는 환경을 위해 만들어졌기 때문에 이 부분에 있어 mlflow보다 막강한 장점을 지니고 있다.
kubeflow
쿠브플로우는 엔드투엔드 AI, ML 플랫폼입니다.
머신러닝 워크플로우의 머신러닝 모델 학습부터 배포 단계까지 모든 작업에 필요한 도구와 환경을 쿠버네티스 위에서 쿠브플로우 컴포넌트로 제공합니다.
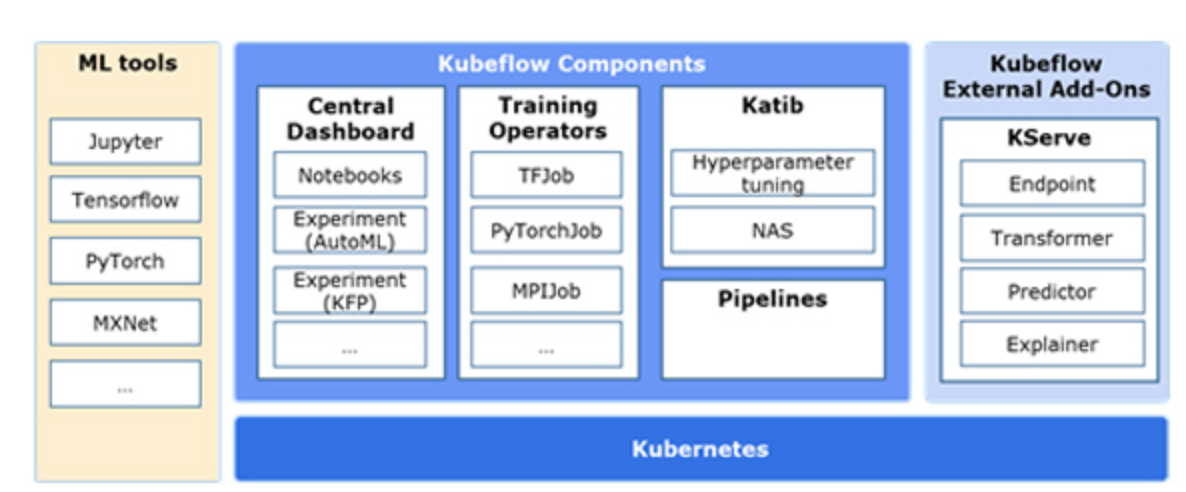
위의 이미지에 보이는 쿠브플로우 컴포넌트에 대해 알아보겠습니다.
Central Dashboard
웹브라우저를 통해 대시보드 UI로 Notebooks, Experiments (AutoML), Experiments (KFP) 등의 컴포넌트를 이용할 수 있습니다.
Notebooks
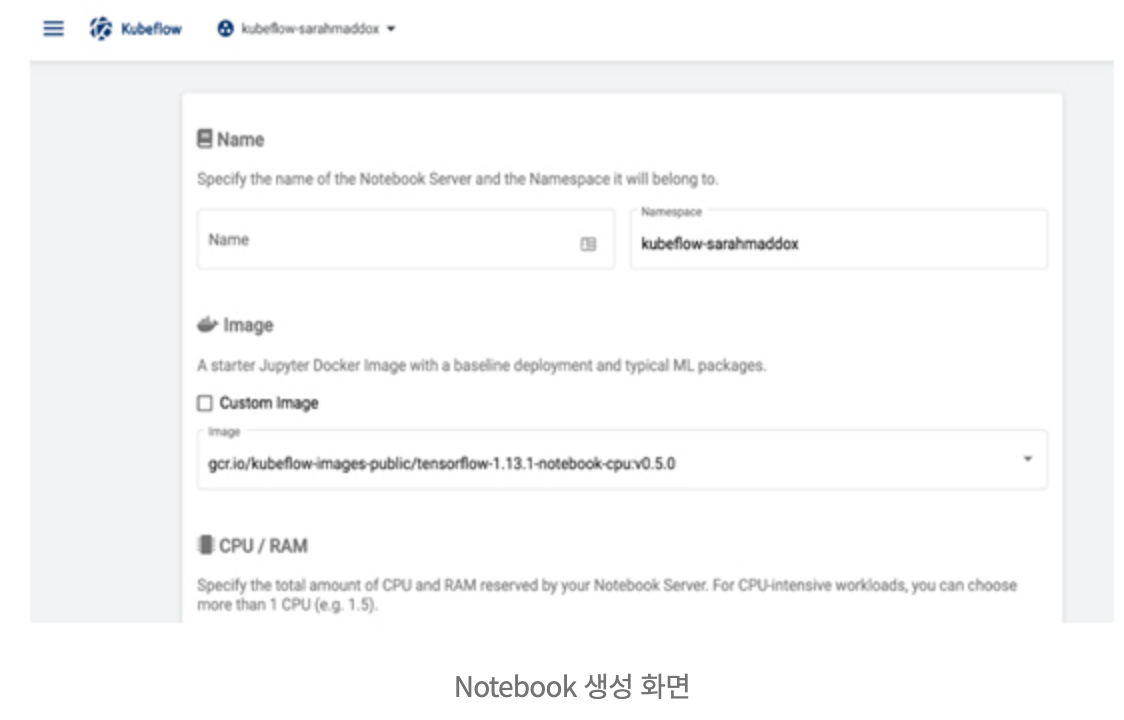
웹브라우저에서 파이썬 코드를 작성하고 실행할 수 있는 주피터(Jupyter) Notebook 개발 도구를 제공합니다.
이미지 경로와 자원 등을 설정하여 쿠버네티스상에 Notebook을 생성할 수 있습니다. 사용자는 생성한 Notebook을 이용해 데이터 전처리와 탐색적 데이터 분석 등을 수행하여 머신러닝 모델 코드를 개발할 수 있습니다.
Training Operators
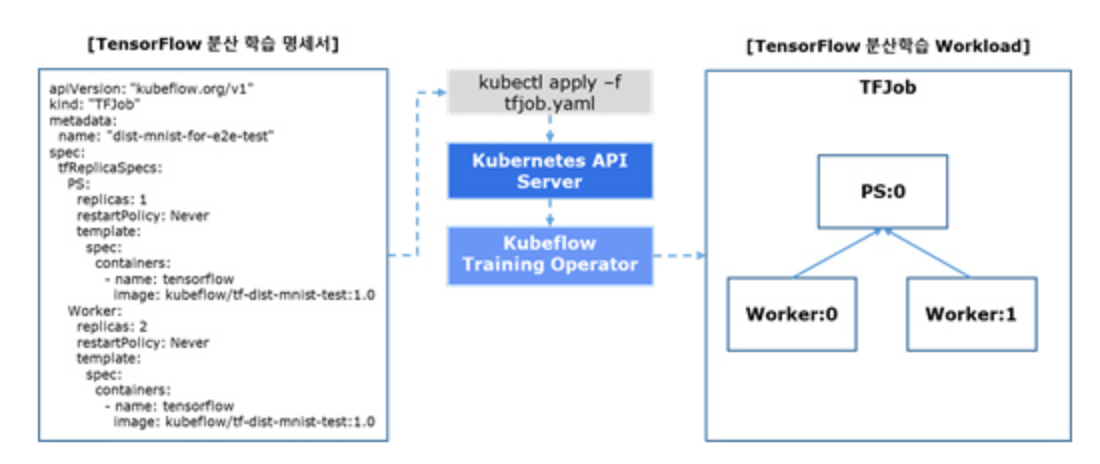
Training Operators는 텐서플로우(TensorFlow), PyTorch, MXNet 등 다양한 딥러닝 프레임워크에 대해 분산 학습을 지원합니다.
쿠버네티스 상에서 머신러닝 모델을 분산 학습하여 학습에 드는 시간을 줄일 수 있습니다. 사용자가 분산 학습 명세서를 작성하여 쿠버네티스에 배포하면 쿠브플로우 Training Operator는 명세서에 따라 워크로드를 실행합니다. 명세서에는 머신러닝 모델 코드를 담고 있는 도커 이미지 경로와 분산 학습 클러스터 정보 등을 정의합니다.
Experiments(AutoML)
AutoML은 머신러닝 모델의 예측 정확도와 성능을 높이기 위한 반복 실험을 자동화하는 도구입니다.
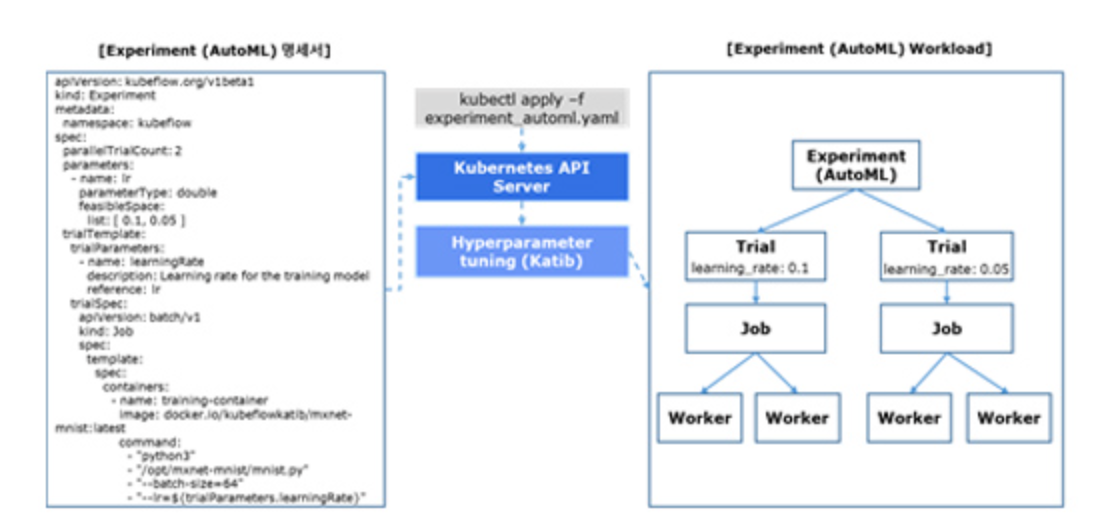
쿠브플로우에서는 카티브(Katib)를 사용하여 AutoML 기능을 제공합니다. 카티브는 하이퍼 파라미터 튜닝(Hyper Parameter Tuning), 뉴럴 아키텍처 탐색(Neural Architecture Search, NAS) 기능이 있습니다. 하이퍼 파라미터 튜닝은 모델의 하이퍼 파라미터를 최적화하는 작업이고 NAS는 모델의 구조, 노드 가중치 등 뉴럴 네트워크 아키텍처를 최적화하는 작업입니다.
카티브를 이용하면 학습률(Learning rate) 하이퍼 파라미터가 0.1, 0.05 중 어느 값이 모델의 예측 정확도를 높이는 값인지 찾는 실험을 자동화할 수 있습니다. 먼저 Experiment (AutoML) 명세서를 작성한 후 쿠버네티스에 배포하면 카티브가 명세서에 정의한 하이퍼 파라미터와 병렬 처리 설정에 따라 실험을 동시에 수행하여 가장 성능이 좋은 하이퍼 파라미터를 찾습니다.
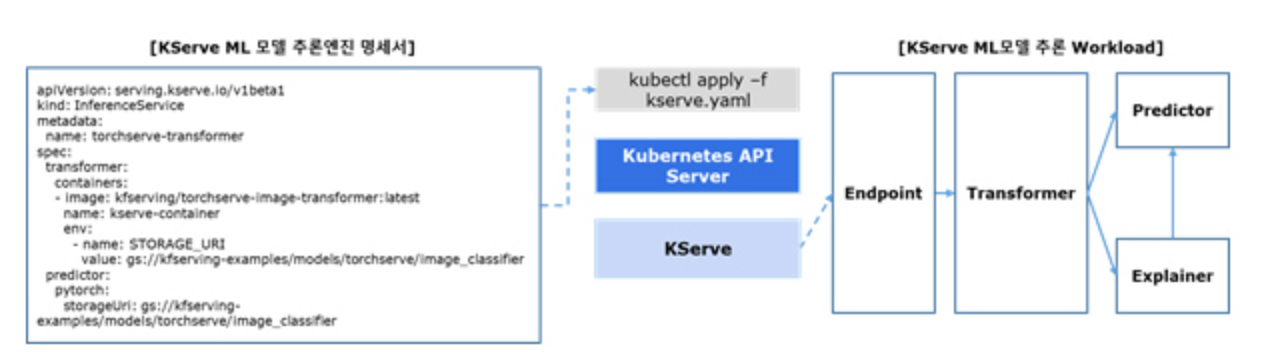
KServe
쿠브플로우는 KServe를 통해 쿠버네티스에 머신러닝 모델을 배포하고 추론 기능을 제공합니다.
KServe는 Endpoint, Transformer, Predictor, Explainer로 이루어져 있습니다.
Endpoint가 Predictor에 데이터를 전달하면 Predictor는 데이터를 예측하거나 분류합니다. Endpoint는 데이터의 가중치 비율을 조절하여 Predictor에 전달할 수 있어서 A/B테스트도 가능합니다.
Transformer나 Explainer는 필요에 따라 추가 가능한데 Predictor 와 연결하여 사용합니다. Explainer는 데이터를 예측하거나 분류한 결과에 대해 판단 이유를 제시하는 설명 가능한 인공지능(eXplainable Artificial Intelligence, XAI) 역할을 하며, Transformer는 데이터 전처리, 후처리 기능을 제공합니다.
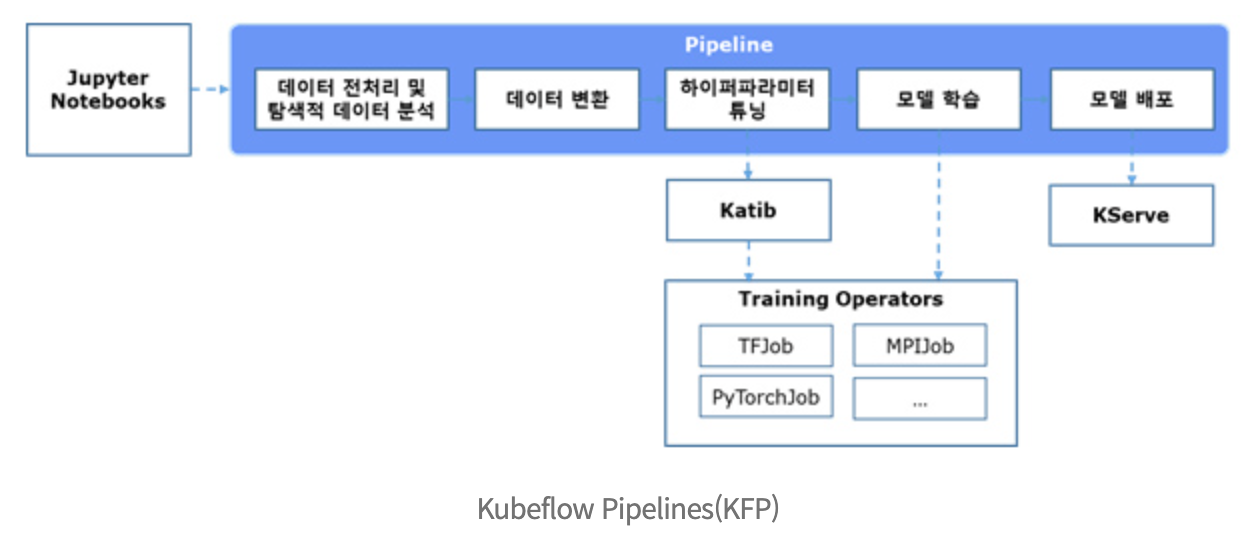
Kubeflow Pipelines(KFP)
Kubeflow Pipelines(KFP)은 머신러닝 워크플로우를 구축하고 배포하기 위한 ML Workflow Orchestration 도구입니다.
KFP의 목표는 Pipelines과 Pipeline Components를 재사용하여 다양한 실험을 빠르고 쉽게 수행하는 것입니다. Pipelines은 Pipeline Components을 연결해서 DAG (Directed Acyclic Graph) 형태로 Workflow를 구성할 수 있으며, Workflow Engine으로 Argo Workflow를 사용합니다.