쿠버네티스 안에서 애플리케이션을 실행하은 이유 중 하나는 인프라스트럭처 장애가 나더라도 사용자 개입없이 혹은 제한적 수동 개입만으로 중단없이 계속 실행할 수 있게 해주기 때문이다.
서비스를 중단없이 사용하려면 애플리케이션 뿐만 아니라 쿠버네티스 컨트롤 플레인 구성 요소도 항상 동작하고 있어야한다.
따라서 오늘은 이 고가용성을 어떻게 구성할 수 있는지 알아보자.
애플리케이션 가용성 향상
쿠버네티스에서 실행되는 애플리케이션의 가용성을 높이기 위해서는 특정 파드(서버)가 장애가 나더라도 다른 파드로 정상 서비싱할 수 있게 디플로이먼트 리소스로 애플리케이션을 실행하고 적절한 수의 레플리카를 설정하면 된다.
쿠버네티스 컨트롤 플레인 구성요소의 가용성 향상
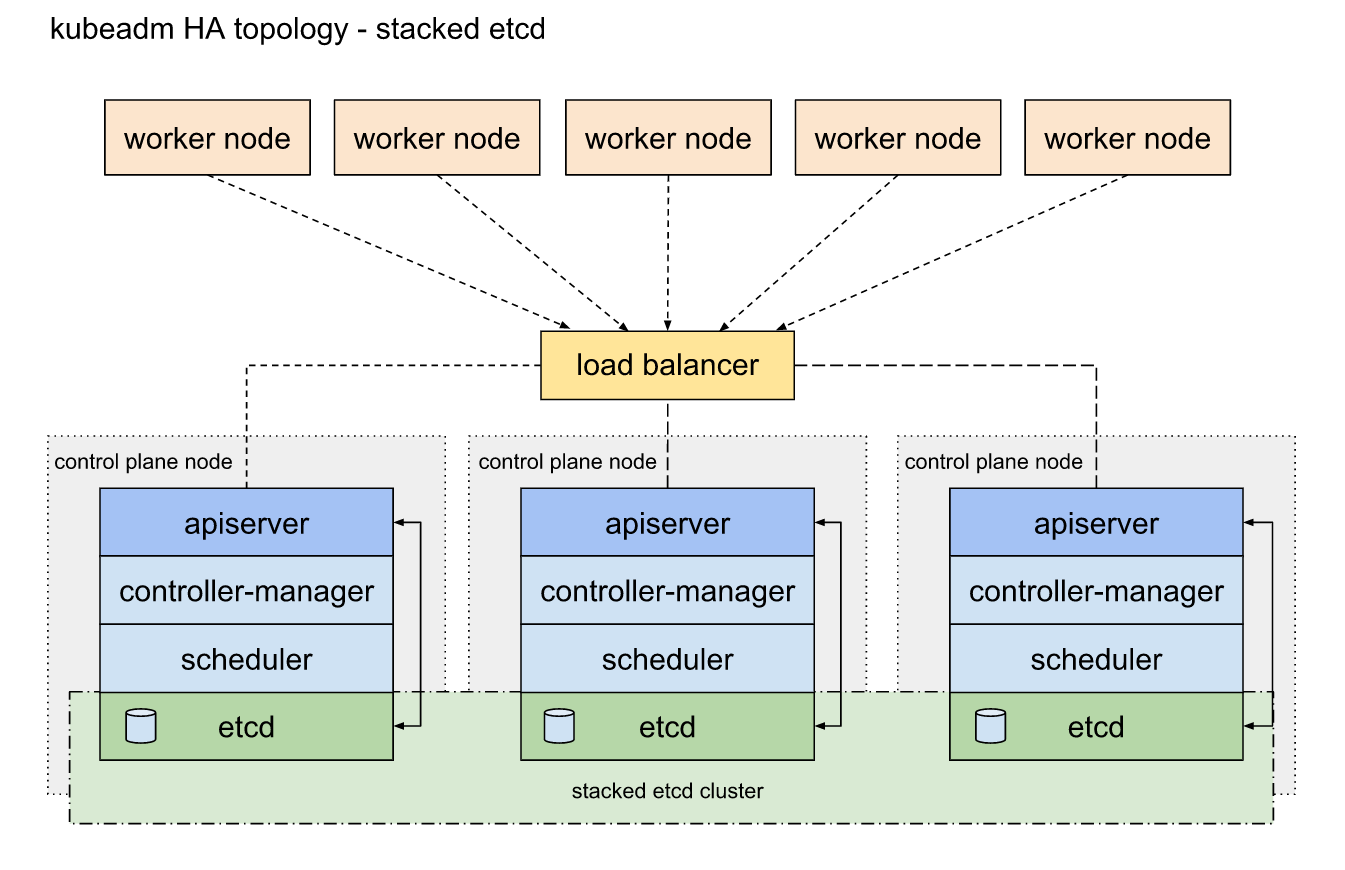
쿠버네티스 컨트롤 플레인 구성요소는 다음과 같다.
Etcd, API 서버, 컨트롤러 매니저, 스케줄러
각 구성요소의 세부 설명을 건너뛰고 가용성을 높이는 내용만 짚어보겠다.
각 세부 내용이 궁금하신 분은 아래의 글을 읽어보시길 추천드립니다.
https://velog.io/@baeyuna97/%EC%BF%A0%EB%B2%84%EB%84%A4%ED%8B%B0%EC%8A%A4-%EB%82%B4%EB%B6%80-%EC%9D%B4%ED%95%B4-1-%EB%A7%88%EC%8A%A4%ED%84%B0-1%ED%83%84
etcd 클러스터 실행
Etcd는 분산 시스템으로 설계되었으므로 그 주요 기능은 여러 etcd 인스턴스를 실행하는 기능이라, 가용성을 높이는 것은 필요한 수만큼 여러 노드에 실행하고 서로 인식할 수 있게 해주면 된다.
Etcd는 모든 인스턴스에 걸쳐 데이터를 복제하기 때문에 3대의 머신으로 구성된 클러스터는 한 노드가 실패하더라도 읽기와 쓰기 작업을 모두 수행할 수 있습니다.
이렇게 고가용성을 위해 두개 이상의 etcd 인스턴스를 실행하는 경우 여러 etcd 인스턴스는 일관성을 유지해야 합니다.
따라서, 분산된 etcd 들은 쿠버네티스 시스템의 실제 상태가 무엇인지 합의에 도달해야하는데요.
Etcd는 RAFT 합의 알고리즘을 사용해 어느 순간이든 각 노드 상태가 대다수의 노드가 동의하는 현재 상태이거나 이전 동의 상태 중에 하나임을 보장합니다.
이러한 합의 알고리즘은 클러스터가 다음 상태로 진행하기 위해 과반수가 필요하기에 etcd 인스턴스 수는 홀수개여야합니다.
API 서버
API 서버의 가용성을 높이는 일은 훨씬 간단한데요.
API 서버는 상태를 저장하지 않기 때문에 필요한 만큼 API 서버를 실행할 수 있고 서로 인지할 필요도 없습니다.
일반적으로 모든 etcd 인스턴스에 API 서버를 함께 띄웁니다.
이렇게 하면 모든 API 서버가 로컬에 있는 etcd 인스턴스하고만 통신하기 때문에, etcd 인스턴스 앞에 로드밸런서를 둘 필요가 없습니다.
컨트롤러와 스케줄러
여러 복제본을 동시에 실행할 수 있는 API 서버와 달리 컨트롤러 매니저나 스케줄러의 여러 인스턴스 동시 실행은 쉽지 않습니다.
컨트롤러와 스케줄러는 클러스터 상태를 감시하고 상태가 변경될 때 반응해야하는데..
이런 구성 요소의 여러 인스턴스가 동시에 실행되면 한개의 상태 변경을 n개의 컨트롤러, 스케줄러가 반응하여 n번의 실제 변경작업이 이뤄질 수 있기 때문입니다.
이러한 이유로 컨트롤러 매니저나 스케줄러는 여러 인스턴스를 실행하기 보다는 한번에 하나의 인스턴스만 활성화되게 해야합니다. (Active-Standby)
구성요소 자체적으로 선출 리더 방식이 있어 리더만 실제로 작업하고 나머지 인스턴스는 대기하면 리더가 실패할 경우를 기다립니다.
리더 선출 매커니즘
리더 선출을 위해서 서로 직접 대화할 필요가 없습니다.
리더 선출 매커니즘은 API 서버에 오브젝트를 생성하는 것만으로 완전히 동작합니다.
특별한 유형의 리소스를 사용하는 것도 아닌데요.
엔드포인트 리소스를 사용합니다!
특별한 이유는 없고 단지 동일한 이르으로 된 서비스가 존재하지 않는 한 부작용이 없기에 엔드포인트 오브젝트를 사용합니다.
Endpoint 리소스 내부 control-plane.alpha.kubernetes.io/leader 어노테이션을 보면 holderIdentity 필드가 있다.
여기 기입된 인스턴스가 리더가 됩니다.
Annotations: control-plane.alpha.kubernetes.io/leader={"holderIdentity":"controller-0","leaseDurationSeconds":15,"acquireTime":"2018-01-19T13:12:57Z","renewTime":"2018-01-19T13:13:54Z","leaderTransitions":1}
리더가 되면 주기적으로 리소스를 갱신해서, 다른 모든 인스턴스에서 리더가 살아 있음을 알릴 수 있도록 해야합니다.
리더가 장애가 생기면 다른 인스턴스는 리소스가 한동안 갱신되지 않은 것을 확인하고 자신의 이름을 리소스에 기록해 리더가 되려고 합니다.
생각보다 매우 간단하죠?
