매치 기능 구현 중 다음과 같은 요구사항이 있었다.
- 특정 유저 사이 매치 이력이 존재하지 않는 경우에만 매치 요청을 성공시킨다.
따라서, 다음과 같은 쿼리가 생겼다.
❗️ 기존 JPQL 쿼리
@Query("""
select m from Match m
where ((m.requester.id = :user1Id and m.receiver.id = :user2Id)
or (m.requester.id = :user2Id and m.receiver.id = :user1Id))
and m.status IN ('PENDING', 'ACCEPTED', 'REJECTED')
""")하지만 이 쿼리는 full table scan이 발생할 위험이 크다. 지금은 괜찮지만, 데이터가 쌓이면 쌓일수록 성능에 치명적이다. 이 쿼리가 full table scan이 발생할 위험이 큰 이유는 3가지이다.
1. OR 조건의 복잡성
인덱스는 보통 특정 조건에 따라 데이터를 정렬해두는데, (A and B) OR (B and A) 와 같이 여러개의 OR 조건이 존재하면 복잡한 조건을 처리하기 위해 각각 인덱스 탐색 후 병합하는 과정이 필요하다.
이때, DB Optimizer는 인덱스를 두 번 검색해서 결과를 합치는 비용보다 그냥 처음부터 끝까지 다 읽는(Full Table Scan)비용이 더 싸다고 판단할 때가 많다. 특히 데이터 양이 많아질수록 OR 조건은 인덱스를 타지 못하고 누락될 확률이 높다.
2. 복합 인덱스의 부재
이 쿼리가 효율적으로 동작하려면 (requester_id, receiver_id) 또는 (receiver_id, requester_id) 형태의 복합 인덱스가 필요하다. 또한, 인덱스가 있더라도 (requester, receiver) 순으로 1개만 존재한다면, 첫 번째 파트(OR의 앞부분)에서는 잘 작동하지만, 두번째 OR 조건을 찾을때는 인덱스 효율이 급격히 떨어진다.
3. 낮은 데이터 선택도
현재 쿼리에는 m.status IN ('PENDING', 'ACCEPTED', 'REJECTED')이라는 조건이 있는데, 사실 MatchStatus Enum은 'NONE', 'PENDING', 'ACCEPTED', 'REJECTED' 4개 뿐이다.
따라서, Match 테이블의 데이터 대부분이 이 세 가지 상태 중 하나이기 때문에 인덱스를 타는 것이 오히려 손해다. DB Optimizer는 전체 데이터의 약 15~25% 이상을 읽어야한다고 판단하면 인덱스를 버리고 Full Table Scan을 선택해버리기 때문이다.
❓❓ 그럼 status NOT IN 'NONE' 으로 수정하면 되지 않나?
라고 생각했지만, 찾아보니 이건 해결책이 아니었다.
NOT IN 조건으로 수정한다고 해서 Full Table Scan이 방지되지 않고, 오히려 인덱스 활용을 더 어렵게 만들 가능성이 크기 때문이다.
부정 연산자의 특성
B-Tree 인덱스는 "이 값이 어디 있는가"를 찾는데 최적화 되어있다. 반면
NOT이나!=같은 부정 조건은 "이 값이 아닌 모든 것"을 찾아야하므로, 인덱스의 정렬된 구조를 활용하지 못하고 결국 테이블 전체를 훑게 된다.
📚 해결 방안들
그럼 이 문제를 해결해야 하는데, 해결할 수 있는 방법은 여러가지가 존재한다.
방법1: Union All 활용
OR 쿼리를 두 개의 별도 select로 나누어 UNION ALL로 합침으로써, 각 쿼리가 최적의 인덱스를 타게 유도하는 방법이다.
- ❗️JPQL은 UNION 또는 UNION ALL 키워드를 직접 지원하지 않음. (Hibernate 6부터 일부 지원하긴 하지만, 아직 안정적이지 않음)개선된 쿼리 예시 (native query)
@Query(value = """
(SELECT * FROM match m
WHERE m.requester_id = :requesterId
AND m.status IN ('PENDING', 'ACTIVE', 'REJECTED'))
UNION ALL
(SELECT * FROM match m
WHERE m.receiver_id = :receiverId
AND m.status IN ('PENDING', 'ACTIVE', 'REJECTED'))
ORDER BY created_at DESC
""", nativeQuery = true)
List<Match> findAllByUserIdNative(@Param("requesterId") Long requesterId, @Param("receiverId") Long receiverId);방법2: 데이터 구조 변경
-
user1_id, user2_id를 정렬하여 저장한다.
-
즉, 작은 id가 무조건 앞에 오도록 저장함으로써 2개의 OR 조건이 아니라
where user1 = :min and user2 = :max단일 조건으로 조회하도록 할 수 있다.
방법3: 쿼리를 2개로 분리, Service Layer에서 합치기
예시
//requester_id 인덱스 타고 검색
List<Match> findAllByRequesterIdAndStatusIn(Long requesterId);
//receiver_id 인덱스 타고 검색
List<Match> findAllByReceiverIdAndStatusIn(Long receiverId);- 하지만, 이 방법은 조회 목적에 부합하지 않기 때문에 별로라고 생각했다.
방법4: DB Index 생성
예시
-- requester 조회를 위한 인덱스
CREATE INDEX idx_match_requester_status ON match (requester_id, status);
-- receiver 조회를 위한 인덱스
CREATE INDEX idx_match_receiver_status ON match (receiver_id, status);-
idx_match_req_res라는 이름의 인덱스를 match 테이블에 걸겠다는 뜻이다. -
(requester_id, receiver_id, status): 복합 인덱스를 구성할 컬럼들의 순서이다.
💫 인덱스 적용 방법
인덱스를 설정할때, 앞순서부터 탐색하기때문에 순서도 중요하다.
Index 설정
CREATE INDEX idx_match_requester_status_receiver ON matches (requester_id, receiver_id, status);-
모든 조회 컬럼을 포함한 복합 인덱스 구성이다.
-
쿼리에 필요한 데이터가 모두 인덱스에 있기 때문에 DB Table을 스캔하지 않고 Index만 읽어서 데이터를 얻을 수 있다.
또한, 코드 기반으로 JPA Entity에 인덱스를 설정할수도 있다.
예시
- 이렇게 선언해두면, JPA가 테이블을 생성하거나 업데이트할때 인덱스도 같이 만들어준다.
@Entity
@Table(name = "match", indexes = {
@Index(name = "idx_match_requester_status_receiver", columnList = "requester_id, receiver_id, status"),
})
public class Match { ... }인덱스 설정 후 확인
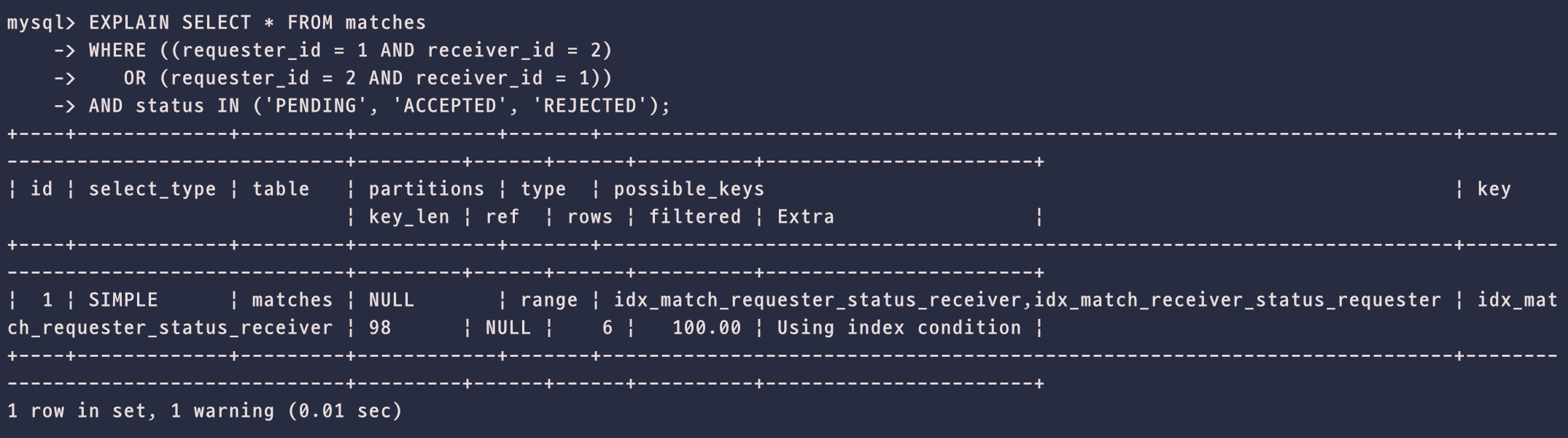
인덱스 설정 후에는 반드시 EXPLAIN 명령어로 확인해봐야 한다.
EXPLAIN SELECT * FROM matches
WHERE (
(requester_id = 1 AND receiver_id = 2)
OR (requester_id = 2 AND receiver_id = 1)
)
AND status IN ('PENDING', 'ACCEPTED', 'REJECTED')- 이때 type이 ALL이면 full table scan을 하고 있다는 뜻이고, ref/range가 나온다면 인덱스가 잘 적용되고 있다는 듯이다.
- 또한 key 항목에 설정한 인덱스 이름이 존재하면 성공적으로 만들어진 것이다.
하지만 데이터 양이 너무 적다면, 옵티마이저가 전략적으로 full table scan을 하는 경우도 있기때문에, 테
스트 DB를 생성하고, 프로시저(Procedure)를 통해 데이터 10만건을 넣고 테스트 해봤다.
프로시저(Procedure)란?
DB 안에 저장해두고 호출을 통해 실행하는
미리 컴파일된 SQL 로직이다. 이런 더미 데이터를 넣어두고 테스트할때 자주 쓰인다.
데이터 10만건 삽입 확인
이제 인덱스를 설정하기 전과 후의 조회 속도, 조회 방식을 비교해보자.
✈️ 인덱스 조회 전/후 성능 비교
❗️ 인덱스 적용 전 조회 속도와 EXPLAIN
조회 속도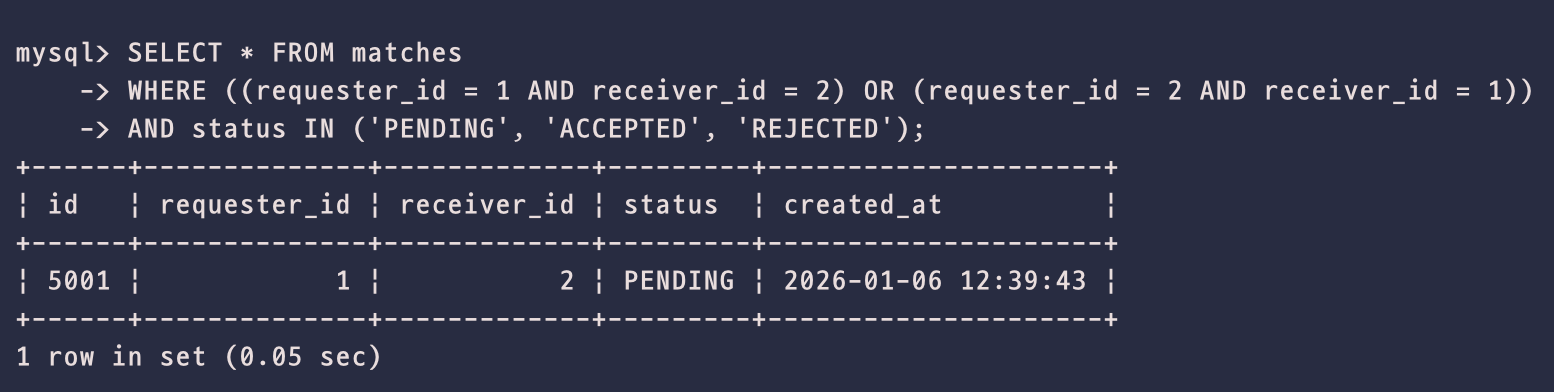
-
먼저, 조회 속도는 0.05초가 걸렸다.
-
빠른데? 라고 생각할 수 있지만, 현재 PC의 CPU와 메모리는 이 조회만 처리하고 있기 때문에 빠르게 나오는 것이다. 만일 100명이 동시에 이 쿼리를 날린다면 5초 동안 멈추게 되기 때문에, 실제 서비스 환경이라면 치명적일 수 있다.
EXPLAIN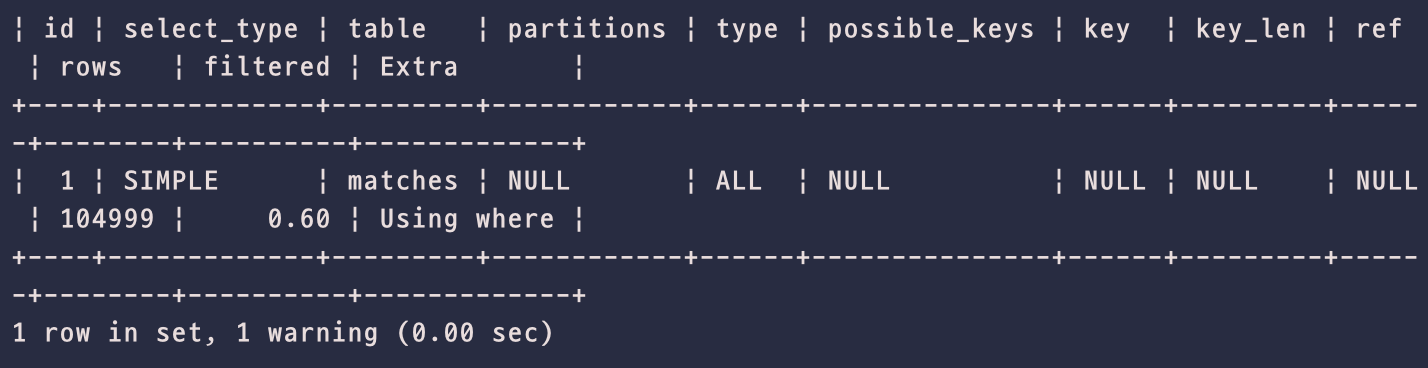
-
explain을 통해 조회 방법을 확인해보면,
type: ALL,ref: NULL,rows: 104999를 확인할 수 있다. -
즉, full table scan을 통해 104999개의 데이터를 검사했다는 뜻이다.
인덱스 생성
✅ 인덱스 적용 후 조회 속도와 EXPLAIN
조회 속도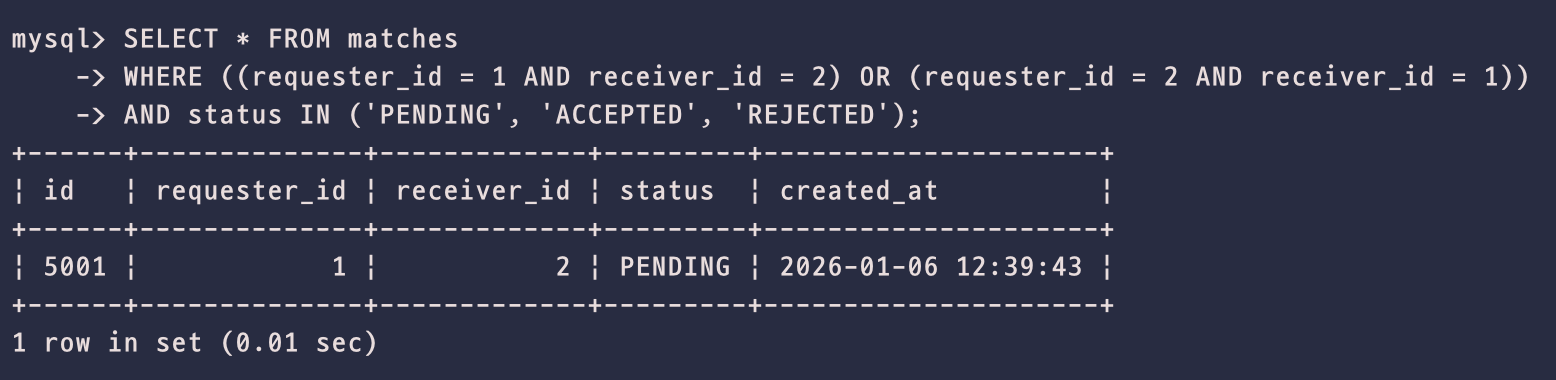
- 먼저, 조회 속도는 0.05초 -> 0.01초로 확연히 감소했다.
EXPLAIN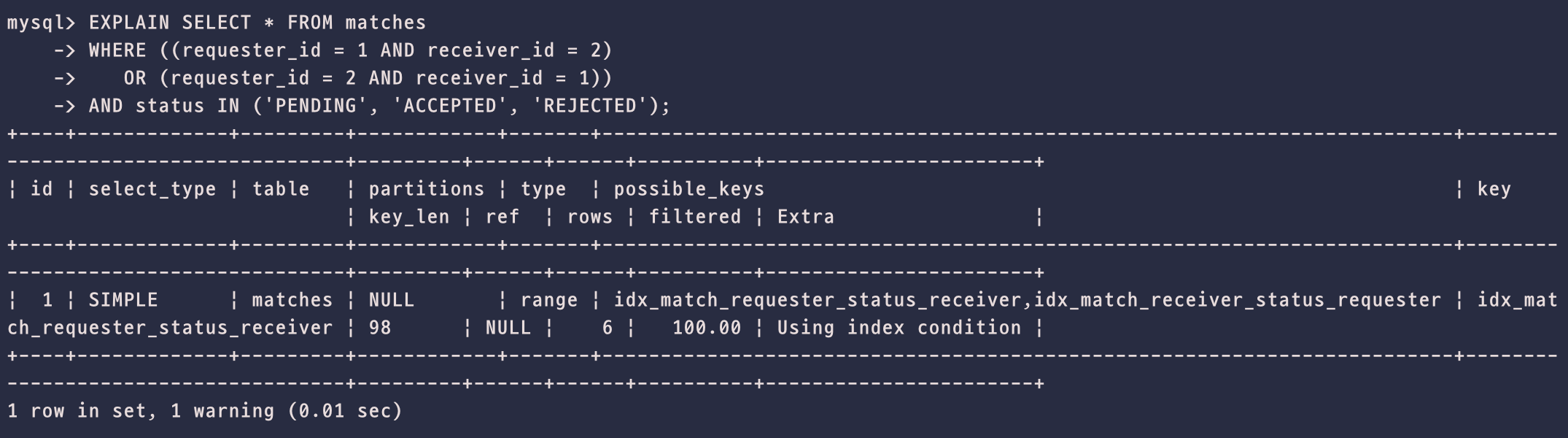
-
type: range: 인덱스를 사용하여 특정 범위 내의 데이터만 훑었다는 뜻이다. -
key: idx_match_requester_status_receiver: 옵티마이저가 방금 만든 복합 인덱스를 선택했다는 뜻이다. -
key_len: 98: 숫자가 클수록 인덱스의 여러 컬럼을 깊게 썼다는 뜻이다. -
rows: 6: 10만건의 데이터 중 6건만 검사하고 결과를 찾아냈다는 뜻이다. -
Extra: Using index condition: ICP(Index Condition Pushdown)가 작동 중이라는 뜻이다. 즉, 스토리지 엔진 레벨에서 필터링을 미리 처리했다.
정리
이렇게 인덱스 설정 하나만으로 성능을 크게 개선할 수 있다!!
