클래스 분리 후 클래스간 의존관계를 어떻게 연결할까?
- 상속 관계 (Is - a 관계)
- 조합 관계(has - a 관계)
-> 둘 다 가능한 경우 조합을 먼저 트라이 해보는게 좋음.
코드의 재사용성 측면에서는 상속이 유리하지만, 유연성 측면에서는 조합이 더 유리.
조합도 코드를 재사용하는 거긴함 (좀 더 코드가 많아진다는 단점)
가장 상위의 메소드 시그니처 등이 변경되었을 때 상속의 경우 파급 효과 때문에 유지보수가 힘들어짐.
ex)
public class WinningLotto extends ArrayList<Lotto> {
}-> 상속 관계
-> ArrayList의 메소드들을 다 외부에 노출하는 것. (add, remove..)
-> arrayList의 기능을 확장하는게 아니기 때문에 적합하지 않음
-> 일단은 조합을 먼저 고려하기
클래스가 서로 의존한다는 건..
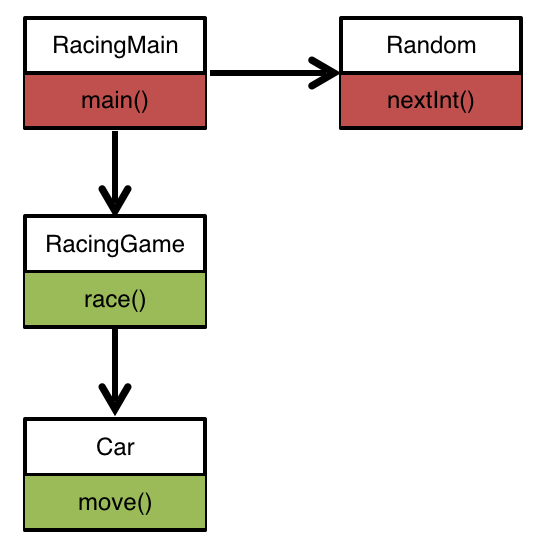
파라미터에 특정 클래스를 갖는 것도 의존 관계. 다만 인터페이스를 추출하고 실제 호출하는 쪽에서 구현 클래스를 지정하는 방식으로 루즈 커플링 가능.
인터페이스 분리
movable(수레, 기차 등을 예측), movingStrategy(움직이는 기준)
-> 미래를 예측하기 어렵다. 그런데 디자인 패턴을 활용하면 멋있어보인다 ㅋㅋ
-> 오버엔지니어링이 될 가능성. 유지보수가 오히려 어려워지는 경우도 있다.
=> 따라서 새로운 요구사항이 들어왔을 때 빠르게 리팩토링하는 게 더 좋을 수도 있다(처음부터 완벽한 설계를 하고자 하면 이후에 바꾸기가 아까워질 수 있기 때문에..)
인터페이스를 잘 찾으려면..
- 변화가 자주 발생하는 부분을 찾아야함(서비스에 대한 이해도가 높아야함)
- 변화가 자주 발생하는 부분(인터페이스 + 구현 클래스)과 발생하지 않는 부분(구현 클래스)을 분리하는 센스가 필요.
인터페이스 추출의 양적 기준
- 요구사항이 변화될때마다 if else가 추가되는 부분.
- 메서드 하나가 길어지는 부분.
예제
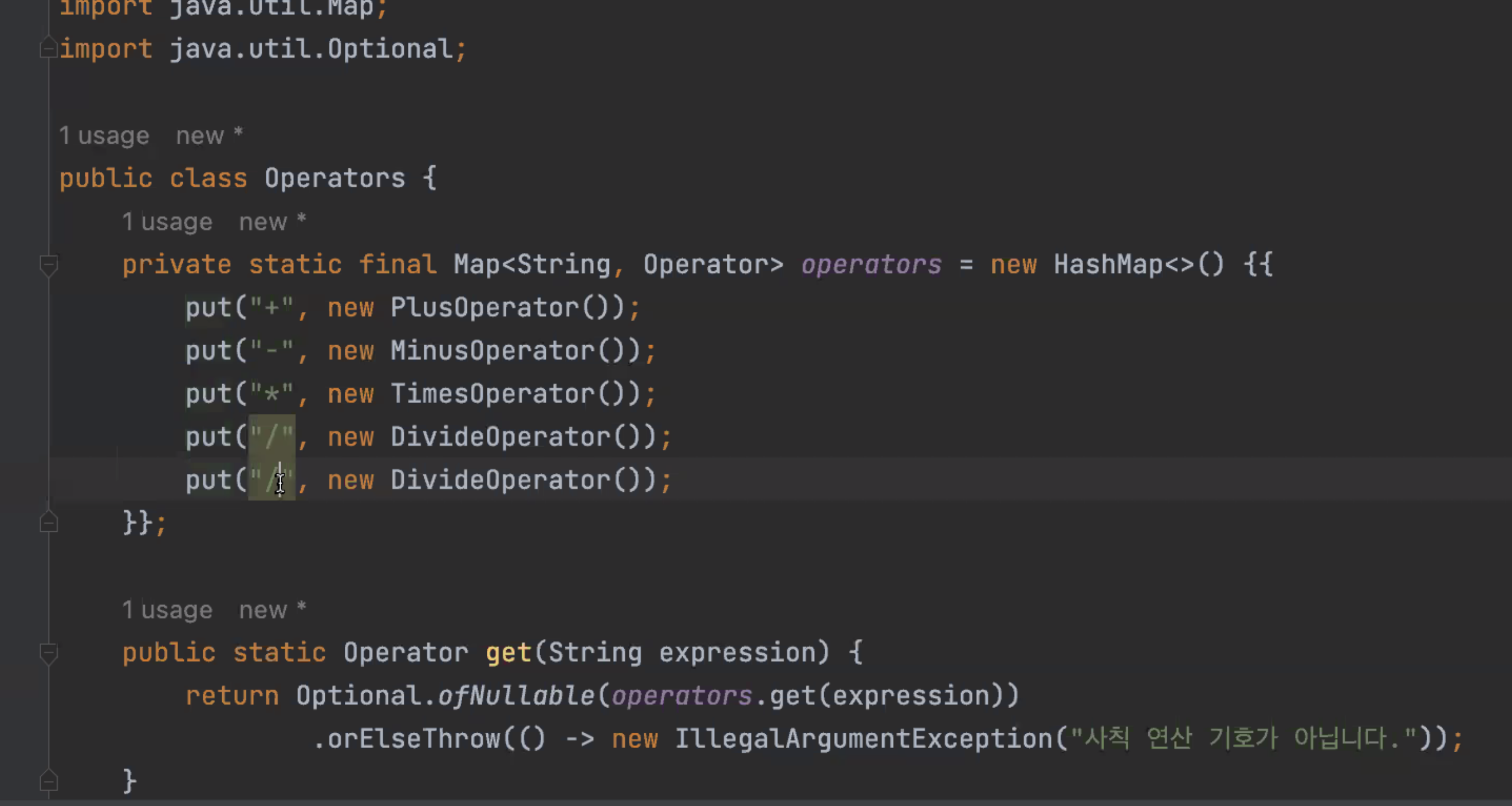 -> Configuration 클래스에서 operator들이 들어있는 map을 빈으로 만들어서 쓸 수도 있다
-> Configuration 클래스에서 operator들이 들어있는 map을 빈으로 만들어서 쓸 수도 있다
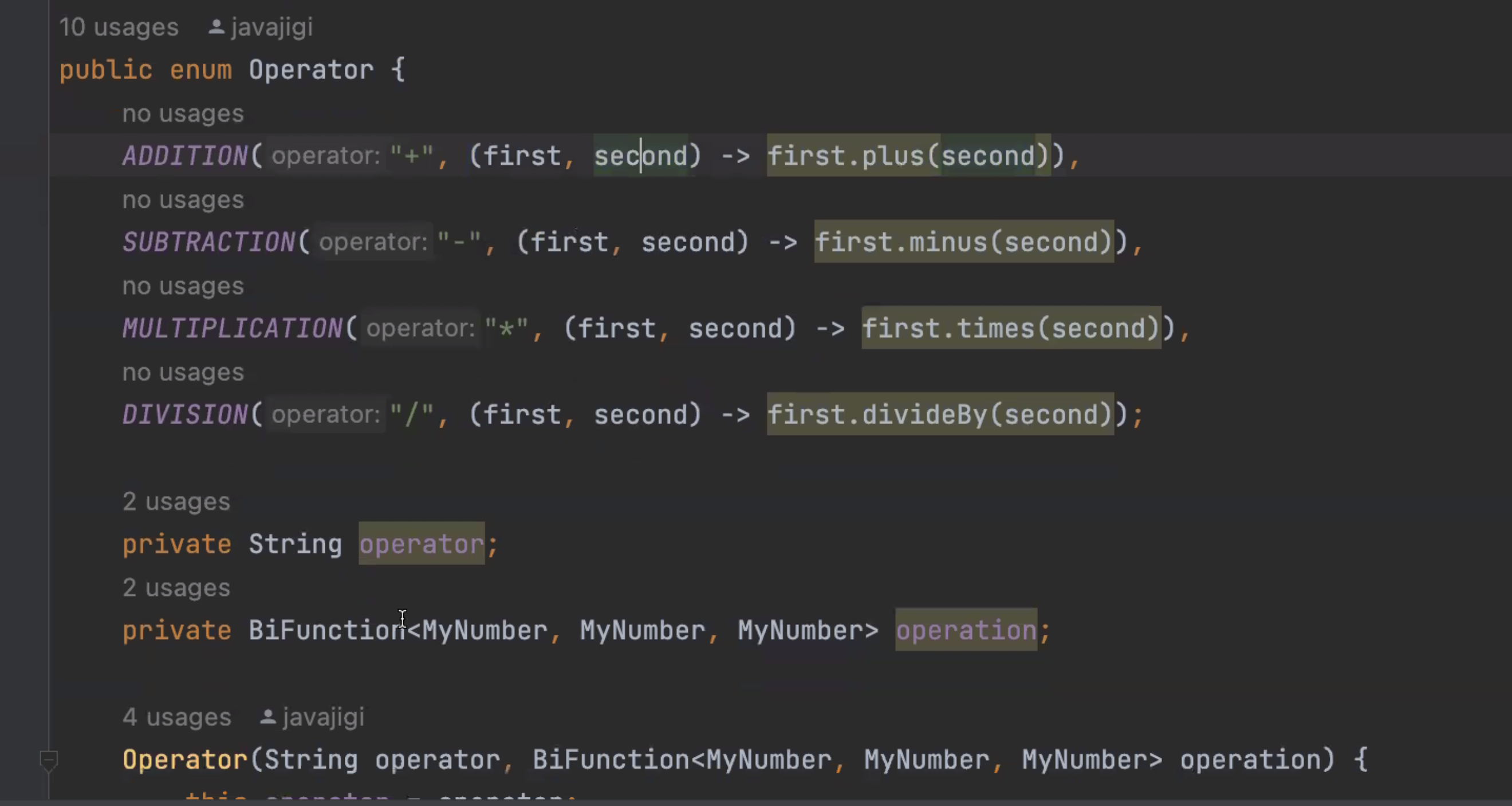 -> map 대신 enum으로 전환
-> map 대신 enum으로 전환
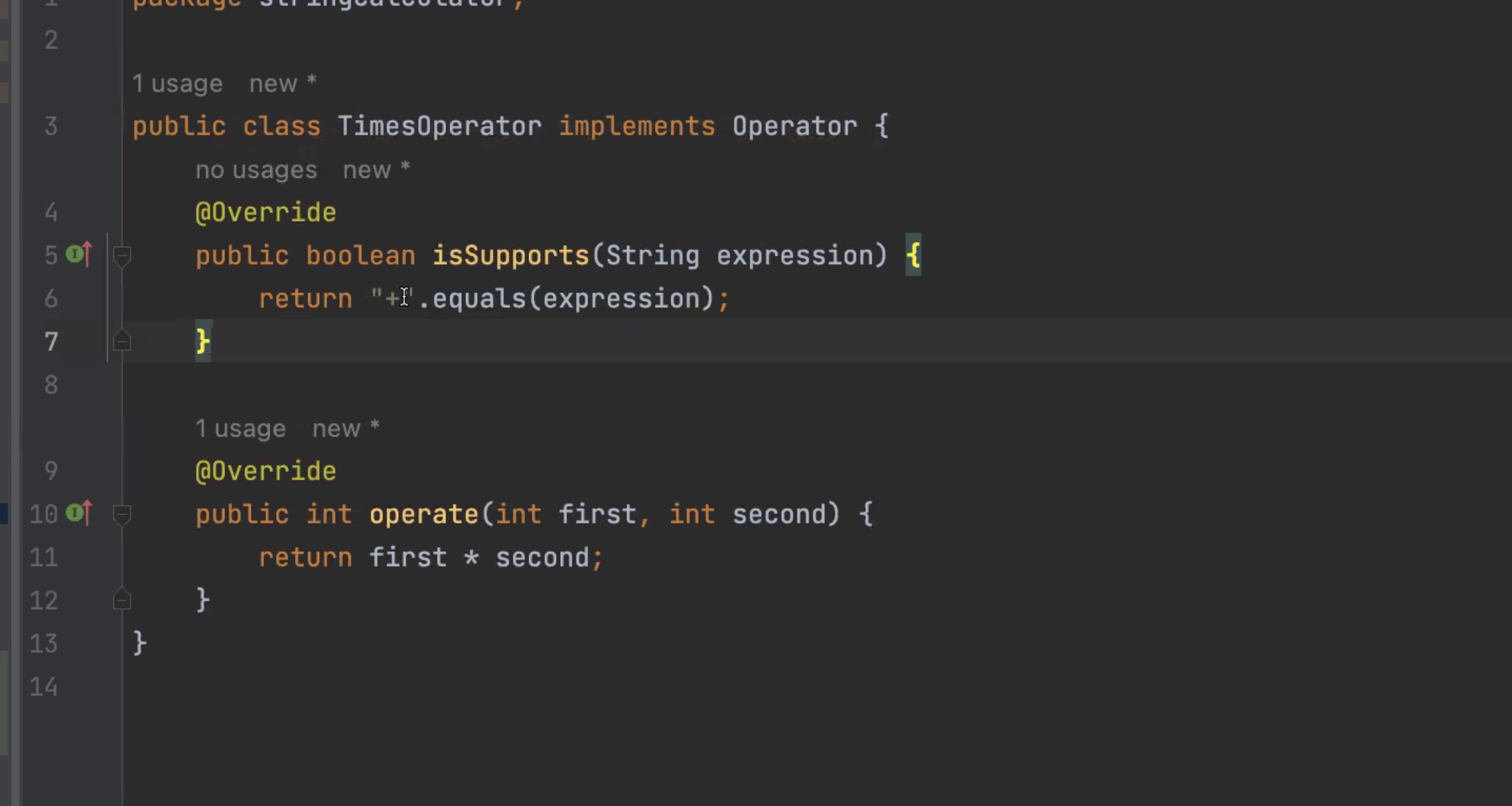 -> 조건이 단순히 string에 따른 구분보다 복잡해지는 경우, 어떤 조건을 만족하는지 확인하는 메서드를 인터페이스에 추가할 수 있다.
-> 조건이 단순히 string에 따른 구분보다 복잡해지는 경우, 어떤 조건을 만족하는지 확인하는 메서드를 인터페이스에 추가할 수 있다.
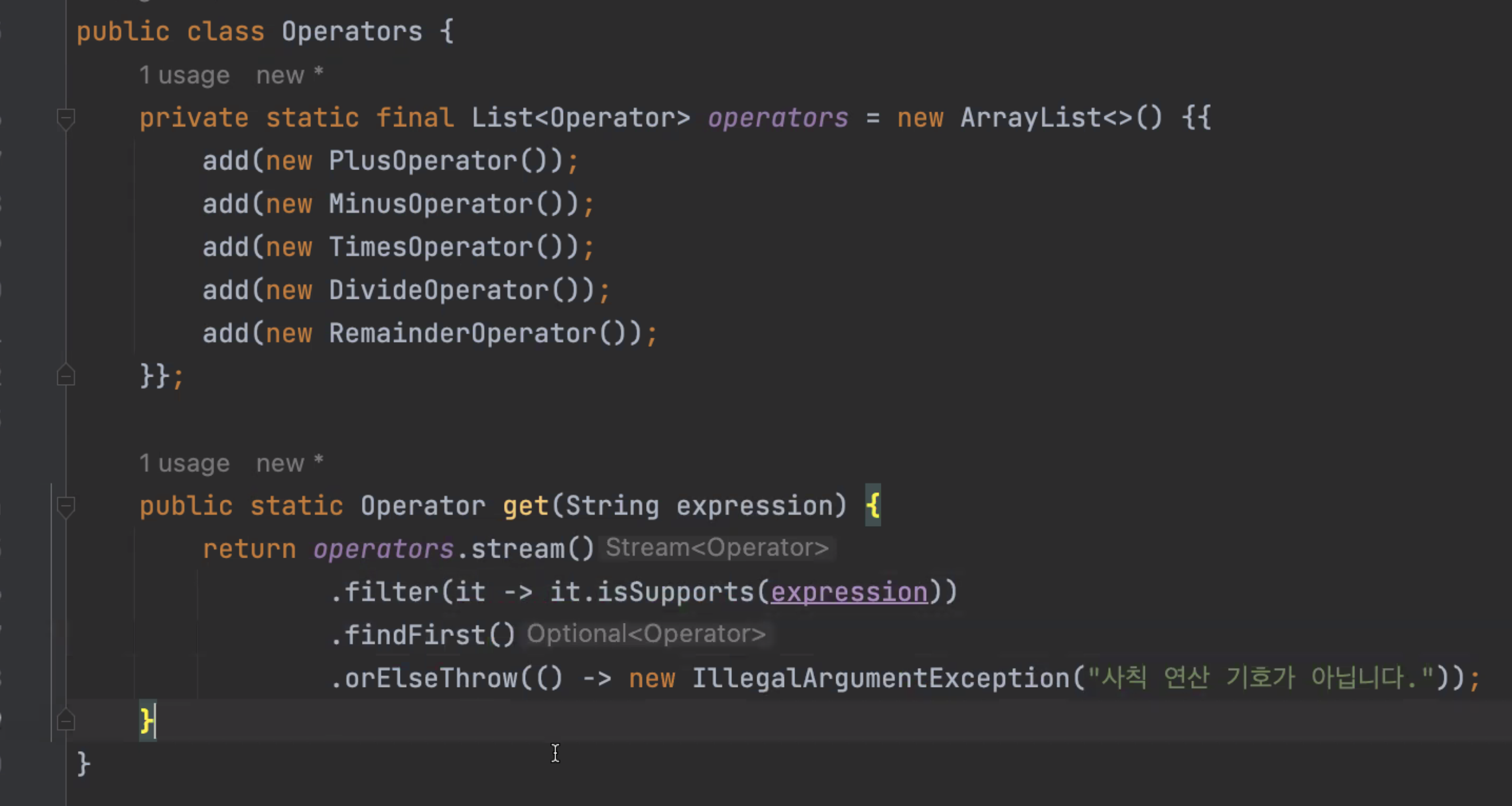 -> 이런식으로 활용
-> 이런식으로 활용
실제로 스프링의 인터페이스를 뜯어보면 쌍으로 다니는 애들이 많다 -> 조건을 만족하면 얘를 실행해라..
인터페이스의 구현 클래스들에 중복 코드가 많이 생긴다면, 인터페이스-구현클래스 사이에 추상클래스를 놓아보자
// 구현 클래스마다 겹치는 메서드 1
public int size() {
return entrySet().size();
}
// 구현 클래스마다 겹치는 메서드 2
public boolean isEmpty() {
return size() == 0;
}
// 구현 클래스마다 겹치는 메서드 3
public boolean containsValue(Object value) {
Iterator<Entry<K,V>> i = entrySet().iterator();
if (value==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getValue()==null) return true;
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (value.equals(e.getValue())) return true;
}
}
return false;
}
// 달라지는 부분 -> abstract로 정의
public abstract Set<Entry<K,V>> entrySet();cf. 마커 인터페이스
/**
* Marker interface that indicates that a {@link WebExceptionHandler} is used to render
* errors.
*
* @author Brian Clozel
* @since 2.0.0
*/
@FunctionalInterface
public interface ErrorWebExceptionHandler extends WebExceptionHandler {
}-> 아무 역할도 안하는 마커 인터페이스도 있음
-> 나중에 이 인터페이스를 통해 어떤 클래스가 이 클래스를 implementation 했는지 안했는지 체크 후 동작.
-> 혹은, WebExceptionHandler가 좀 더 추상적인 개념이고 그 사이에 한 단계 구체화된 개념을 놓고 싶을때도 사용하는 듯. (위 예시의 케이스..)
cf. 커스텀 어노테이션
@interface
public class Example {
}@Around(value = “@annotation(june.Example)”)aspect와 함께 쓰면 어노테이션이 달려있을 때 특정 동작을 하게 할 수 있음.
스트랭귤러 패턴
레거시 코드가 있는 상태에서 개선 및 개발하는게 훨씬 더 어렵다.
-> 이때 기존 레거시를 포기하고 아예 생산하는 방식은 절대 지양
-> as-is와 to-be가 일정기간 공존하면서 점진적으로 리팩토링 (데드라인에 대한 압박을 줄이며 리팩토링 가능)
-> 다 리팩토링 되면 레거시를 대체
- 느리고, 귀찮더라도 테스트코드(Unit Test, Acceptance Test) 먼저 작성하고 리팩토링하기(테스트코드가 없는 경우) -> 그래야 방패막이 생긴다. 물론 로직이 간단한 경우라면 바로 옮길 수도 있다.
핵심 비즈니스 로직은 어디에 위치해야 할까?
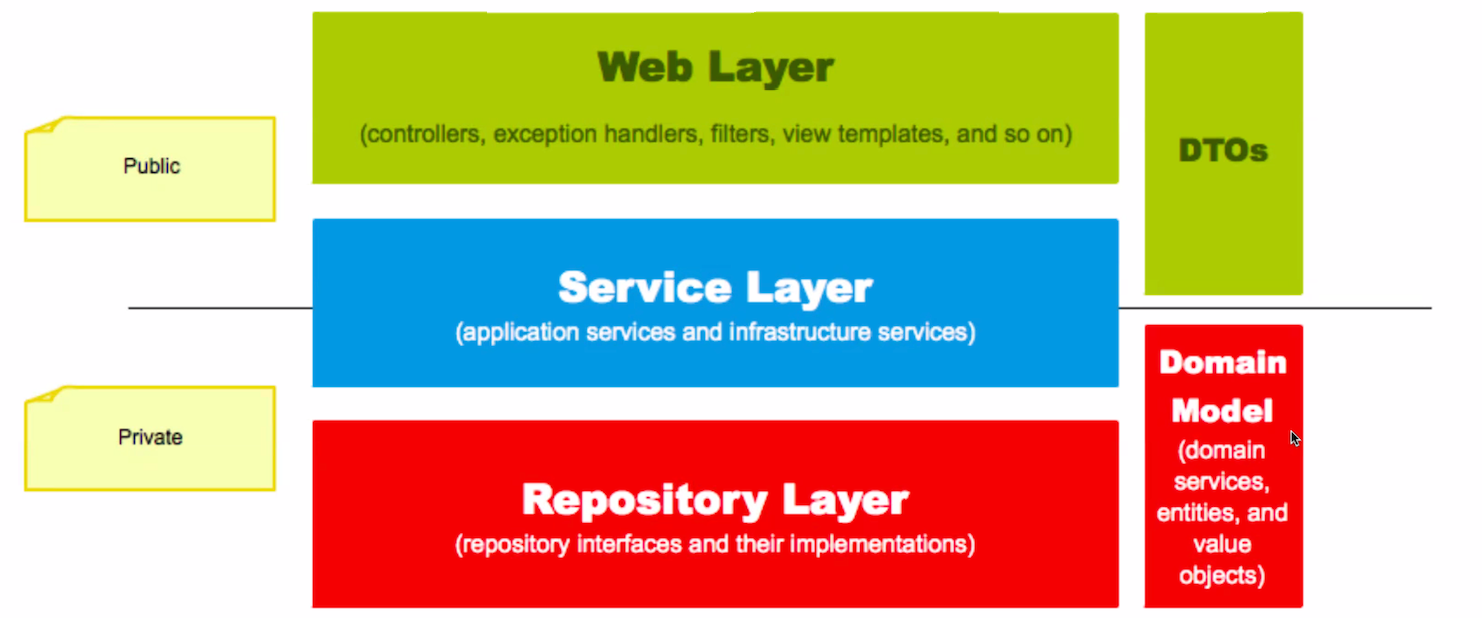
- 핵심 비즈니스 로직은 service가 아니라 domain에서 담당해야한다. (즉 각 도메인 객체들이 핵심 비즈니스 로직을 나눠가져야한다.)
-> 테스트 하기 쉬운 부분과 어려운 부분을 쪼개는 관점에서도, service에 둘 경우 비지니스 로직 + 데이터베이스 쿼리 로직이 섞여있기 때문에 테스트하기가 더 어려워진다.
서비스 레이어의 역할
- 도메인 객체 로딩
- 도메인 객체에 메시지 보내기
- 상태가 바뀐 도메인 객체를 db에 반영
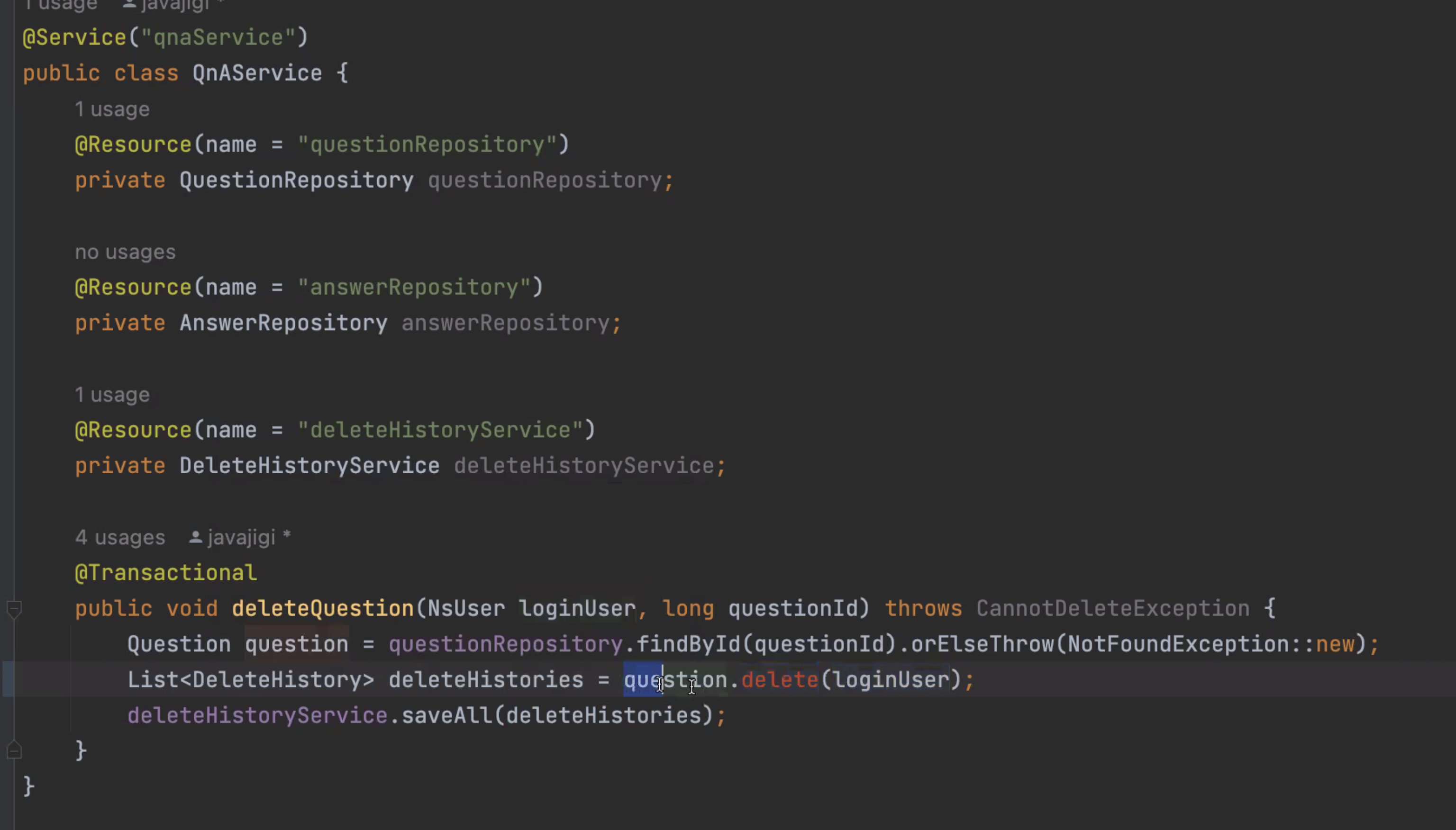
-> 이렇게 할 경우 서비스 레이어는 로직이 거의 없어져서 단위테스트가 필요없다 (도메인 객체만 단위테스트하면 됨)
-> 도메인 객체가 테이블과 1:1 매칭되어 로직까지 들어갔을때 복잡하다면.. 클래스 분리 + 일급 컬렉션 적용 등이 필요!!
-> 그러면 분리되었을떄 걔와 관계된 메서드들이 따라가게 된다
- 만약 두개 이상의 도메인이 로직에 참여한다면, 별도의 객체로 만들기
- TDD를 잘하는 사람은 mock을 최후의 수단으로만 사용한다. (mocking을 하면 테스트 코드가 필연적으로 더 읽기 어려워진다.)
- 개념 하나에 하나의 단어만 사용하기(같은 추상적 개념을 다른 단어로 표기하지 말자)
- 테스트 하기 어려운 부분과 쉬운 부분을 쪼갠 후 이것들의 의존관계를 엮을 때 DI 방식을 사용한다
- DTO와 도메인 객체를 분리하기(도메인은 가능한 한 setter 없이)
