테스트 종류
1. 도메인 객체 단위테스트
2. 인수테스트
3. 서비스 레이어 테스트
=> 계속 하고자 하는 부분은 서비스에 산재되어있던 비즈니스 로직을 연관된 도메인 객체로 옮기고 도메인 객체 단위테스트를 작성하는 것
=> 이렇게 됐을 때 서비스 레이어의 mock 기반 테스트는 선택의 영역이 됨
=> 필요 없는 테스트 코드는 그때그때 다 지우기 (유지보수 비용 줄이기)
리팩토링
- 하루에 한시간 씩이라도 리팩토링하는 시간을 갖기
- 기능이 추가된다면 이때 리팩토링을 병행
클래스 분리, 인터페이스 추출의 기준
- 반복되는 부분은 부모 객체로 뽑기 (ex. AbstractEntity)
- 라이프 사이클이 같은 데이터들을 하나의 객체로 뽑기 (ex. questionBody)
- 비즈니스 로직이 복잡한 부분을 뽑아보고, 거기서 묶어보기
- 도메인 지식이 낮은 경우 필드들 중에 관련성이 있는 애들 뽑아보기
테이블이 아닌 도메인 객체부터 설계하자
참고: https://www.youtube.com/watch?v=VjbBGjVRxfk
-> 테이블, 쿼리, CRUD보다 비즈니스 로직에 집중
-> 객체 설계로부터 시작하기 (이때는 테이블 구조 의식하지 않기)
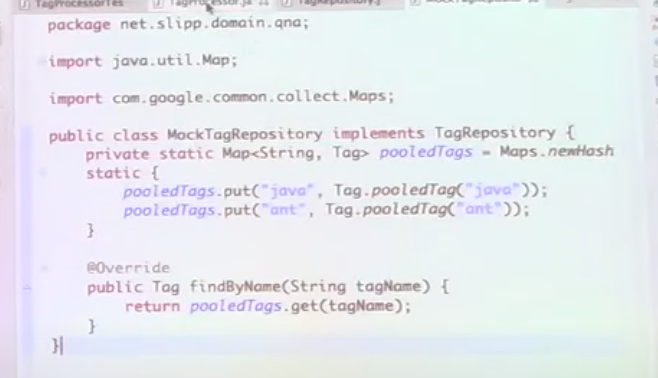
-> 테이블 없이 개발할때 이런 식으로 MockRepository를 만들어서 사용
-> 단 실제 구현부(service) 쪽에서는 실제 TagRepository의 의존성을 갖기(그래야 이후 실제 repository로 변경하기 편함)
-> 이처럼 db가 없는 상태에서도 충분히 비즈니스 로직 개발이 가능
-> 우선 객체 설계, 객체 간의 관계 맺는 것만 고민하며 개발 (객체가 특정 다른 객체의 list를 갖는 상태로 그냥 두기.)
-> 비즈니스 로직 개발이 끝나면 그때 db를 고민 (pk, manyToOne, elementCollection, lazyLoading 등 객체지향적으로 짠 것과 db가 맞지 않는 부분을 수정)
- 이후 만들어진 n개 객체를 1개의 테이블로 맵핑
도메인 객체 먼저 설계하는 것의 장점
도메인 객체 설계를 먼저하고 리팩토링을 진행하면 db를 만들어놨을 때보다 리팩토링이 쉬워짐 (테이블 수정이 필요 없기 때문에)
도메인 객체 먼저 설계하는 것의 어려움
- students가
list<nsUser>를 가지면 성능상의 이슈
-> 하다보면 그렇기 때문에 도메인 객체 설계시부터 다르게 해야겠네 하는 감이 생김
-> nsUserId, sessionId를 갖는 student를 설계 (session이 n개의 student를 가짐, 유저는 n개의 session을 가짐, 이렇게 두개가 맵핑되는 테이블(stuent)가 필요)
-> 단 ORM을 쓴다면 성능이슈가 없어서 student가 session, nsUser 자체를 가져도 됨. students는list<student>를 가짐 - pk, fk, 저장 시간 등 추가되어야할 칼럼 고려해야함
- 성능 때문에 역정규화가 필요한 경우도 있음
예제
DB 테이블 : Session, NsUser, Student
도메인 객체 : Session, NsUser, Student, Enrollment
특정 필드 ex Enrollment가 db 테이블이 아닌 경우에는,
얘를 필드로 갖지 않고,
메서드에서 걔를 new Enrollment(..)로 생성하여 사용할수도 있음
(맵핑과 비즈니스 로직을 분리. mybatis를 쓰면 이게 더 나을 수 있음)
jpa에서는 session - enrollment - students - list<student> 이렇게 되어있으면 자동으로 로딩을 해줌. 구조 변경 필요 없음
근데 마이바티스에서는 불가능. (어려운 부분이 많긴함.)
그러면 Session의 메서드에 students를 전달해줘서 강제로 맵핑해줄 수 있음. -> jpa 쓰면 따로 조회해서 넘겨주지 않아도 자동으로 연결이 됨 (레이지로딩)
도메인 객체와 DB 맵핑 객체 (entity)
보통 db 맵핑 객체, 도메인 객체를 둘다 도메인객체라고 부르긴 하는데 도메인 객체와 entity는 엄밀히 따지면 다른 용어로, 두개의 쓰임을 구분할 수 있음 (이 경우 딱 떨어지는 정답은 없음)
-> 도메인 객체를 DB 맵핑 객체로 쓰지 않는 걸 추천
-> 분리하지 않는 경우 중복이 많이 생기긴 함.
-> jpa 쓰면 분리하지 않아도 가능하긴 함(실용주의 노선. jpa는 레이지로딩이 되기 때문에 list<object>를 가지더라도 쓰지 않는 데이터 ex 학생 목록 를 로딩하지 않음.)
-> 비즈니스 로직도 가지면서 디비 맵핑도 되는 식으로 도메인 객체랑 db와 맵핑되는 객체를 일반적으로는 혼용해서 많이씀 (상황에 따라 적절히 섞어쓰기)
=> DB가 아닌 다른 서비스에서 데이터를 받는 경우에도, 다른 msa에서 데이터를 받는 객체랑 비즈니스 로직이 있는 우리쪽 도메인 객체를 분리해서 구현하기
도메인 객체에서는 DB 접근하지 않기
- 기존에는 service에서 repository 접근을 하는데, 도메인 객체로 역할이 분담되다보면(ex. enroll) 이런 고민이 생김
- 대신 enroll이 바뀐 student를 반환하고, service에서 db 접근이 좋다고 생각
도메인 객체에서는 객체 저장, 조회 등 db 접근은 직접하지 않는 것을 추천 -> 이렇게 되면 단위 테스트, 설계가 더 어려워짐
out -> in vs. in -> out
out -> in
controller 쪽부터 개발. 일반적으로 많이 사용
in -> out
tdd에 적합한 방식. 핵심이 되는 도메인 객체부터 tdd로 개발.
개발하면서 아닌 것 같으면 버리고 다른 걸로 다시 도전
top down vs. bottom up
top down
인터페이스 등을 완벽히 설계 후 구현 : 책임 주도 설계
객체의 책임?
객체가 무엇을 알고, 무엇을 할 수 있는지 (field & method)

책임 주도 설계
책임을 먼저 찾고 그걸 어떤 객체가 맡을지 할당하는 방식
bottom up
일단 구현하고 지속적으로 리팩토링 (토비님 강의에 좀 더 가까움)
=> 처음에는 구현 위주(bottom up) 방식으로 개발해보고,
이후 익숙해지면 인터페이스를 먼저 고민하는 식(책임 주도 설계, top down)으로도 구현해보기
=> 단 처음부터 너무 완벽한 설계를 하려는 욕심은 버리자
=> 한가지 방식에만 매몰되지 않고, 여러 방식을 도전하며 조금씩 개선된 설계를 해보기
- 일정 부분 설계를 하고 도메인 객체도 만들어본 다음 테스트 코드가 따라가는 것도 괜찮다고 생각
- 그러나 지속적인 리팩토링하려면 테스트코드가 밑바탕이 되어야하니까 결국 테스트 코드는 필요
책임 주도 설계
-
시스템의 책임을 파악, 시스템 책임을 더 작은 책임으로 나눔
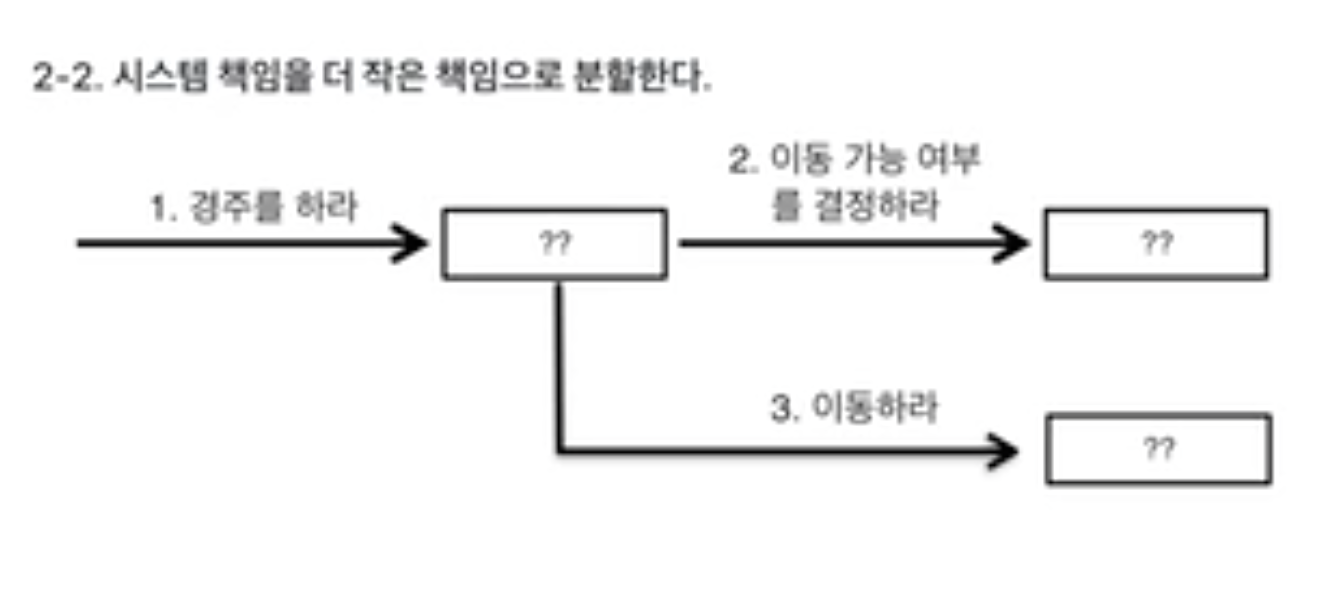
-
책임을 어떤 객체에 할당할지 결정
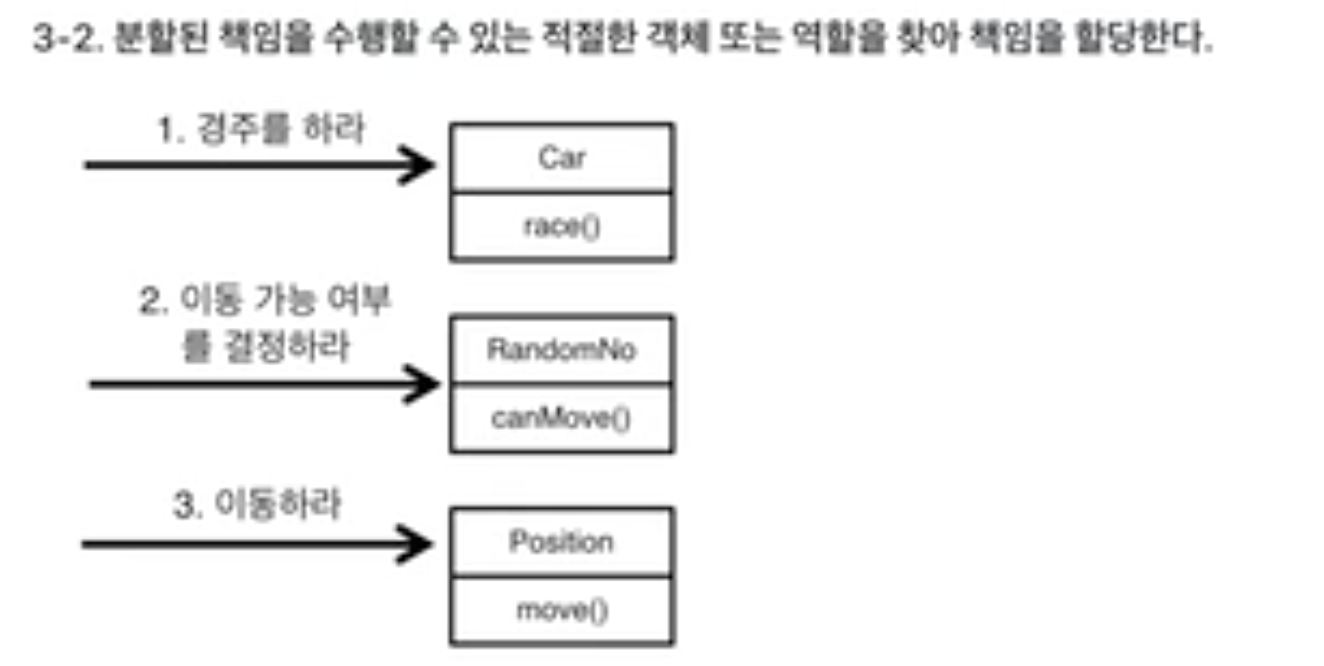
-
객체들을 협력하게 만듦
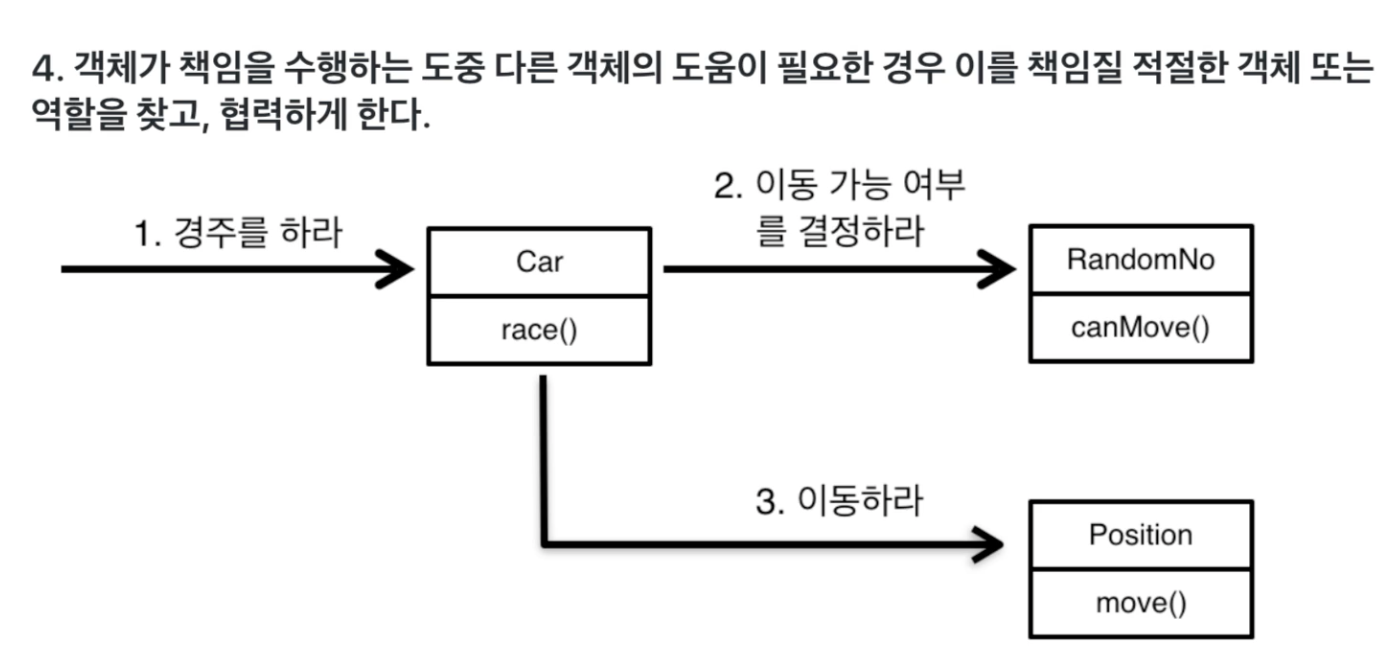
역할 : 다른 것으로 교체할 수 있는 책임의 집합
연극에 비유하면,
연극 = 협력
배역 = 역할
배우 = 객체
어떤 역할은 여러 객체가 수행할 수 있음.
자동차 경주 게임 예시
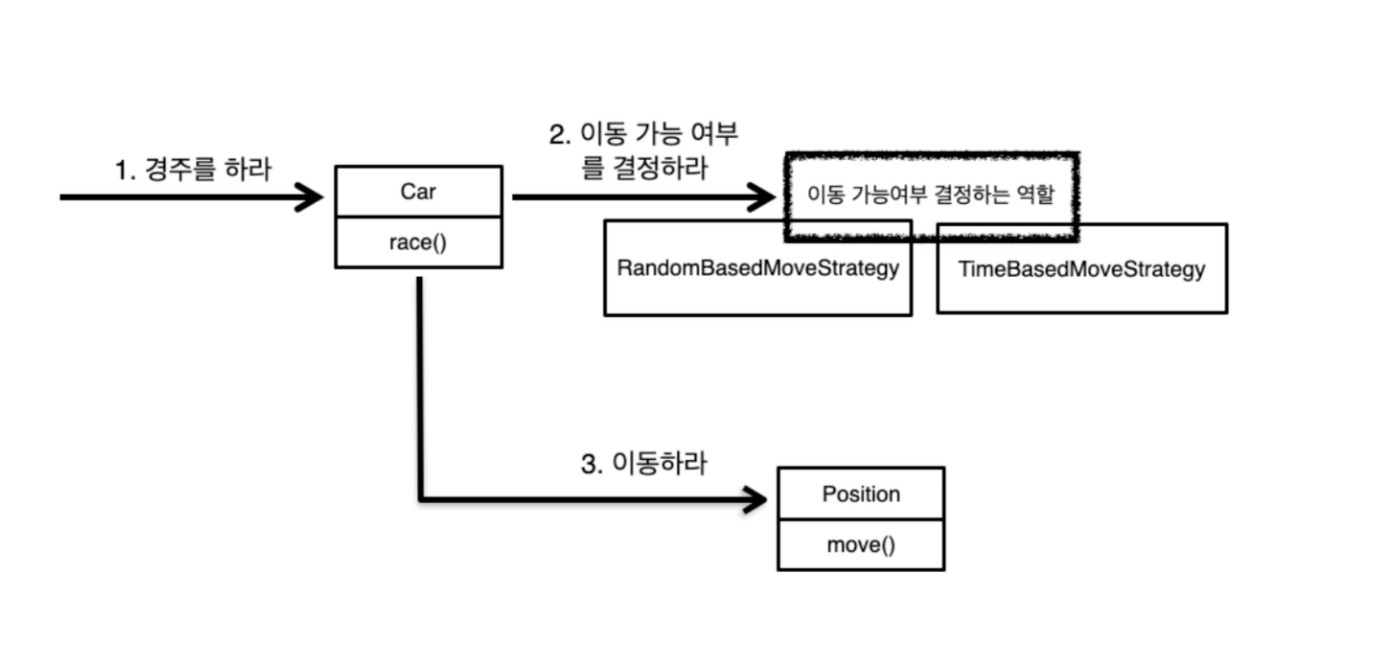
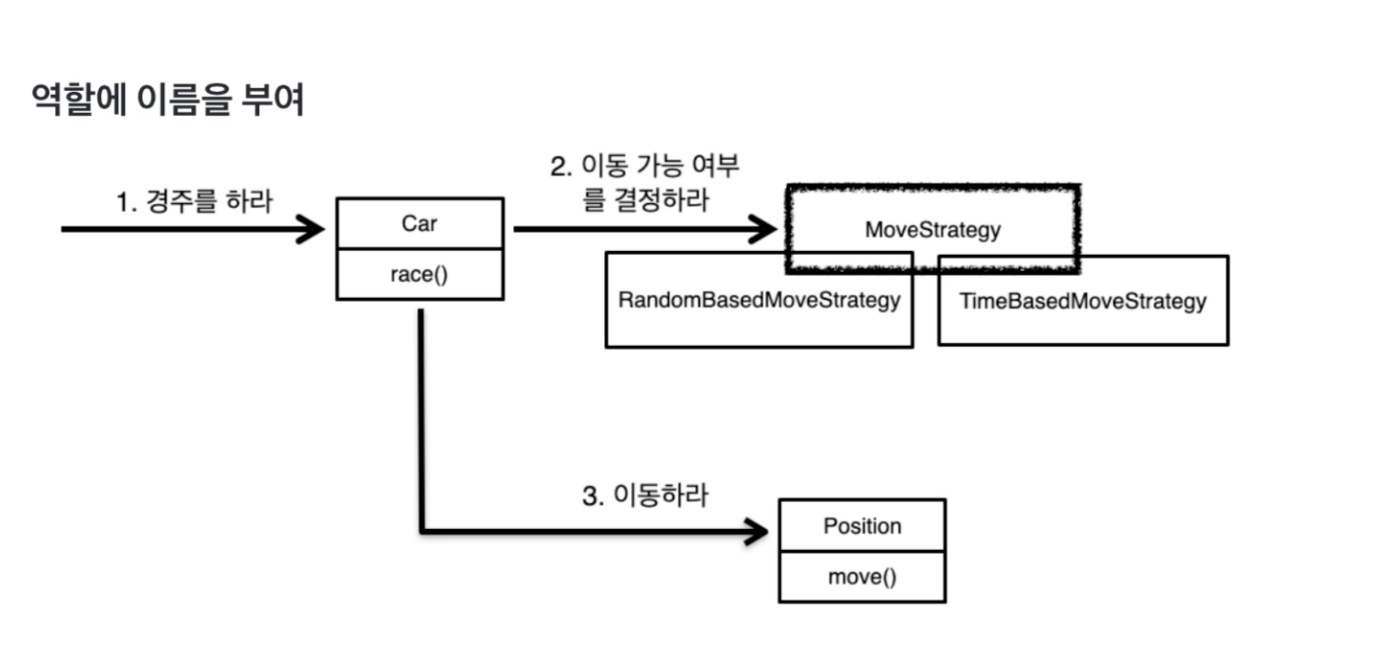
이동 가능 여부 결정하는 역할
- random 값에 따라 이동 여부 결정
- 시간에 따라 이동 여부 결정
=> 각각 strategy(객체)는 같은 역할(이동 가능 여부 결정)을 함
=> 공통의 역할을 잘 추출하면 이걸 실현하는 클래스는 다양하게 변경 가능하도록 설계 가능
=> 역할 == 인터페이스
컴파일 타임 의존성 vs 런타임 의존성
역할을 추출 했다면,
컴파일 타임 의존성이 아닌 런타임 의존성을 갖게 해야함
// 컴파일 타임 의존성
MovingStrategy strategy = new RandomValueMovingStrategy();
// 런타임 의존성
public void move(MovingStrategy strategy) {
}=> 의존 관계를 외부에서 주입(Dependancy Injection)하기 때문에 런타임 의존성은 언제든지 바꿔치기 가능
스프링에서는 빈 팩토리에서 서로 다른 객체를 연결해주는데(DI), 스프링이 없으면 이걸 직접 해주면 됨.
사다리 타기 예제
객체가 가지는 메시지에 집중
로직과 input, output이 구분된다면?
public interface LadderCreator {
Ladder create(int countOfPerson, int height);
}
public interface Ladder {
PlayResults play();
PlayResult play(int source);
}
public class PlayResult {
private Position source;
private Position target;
}
public interface Line {
int move(int position);
}
// 실제 사람과 결과를 맵핑
public class Result Processor {
private List<Person> people;
private List<Result> result;
LottoResults toResults(PlayResults results) {
}
}=> 이렇게 구현체 말고 뼈대만 먼저 설계를 함
=> 인터페이스의 구현체를 만듦
=> 그럼 나중에 성능이 떨어져서 바꾸고 싶을때 규격에 맞는 구현체만 바꿔주면 됨
cyclic(circular) dependancy 해결 방법
=> 인터페이스를 추출하다보면 인터페이스와 구현체 사이에 cyclic dependancy가 생기는 경우가 많음 (세개 패키지가 순환하는 경우도 cyclic)
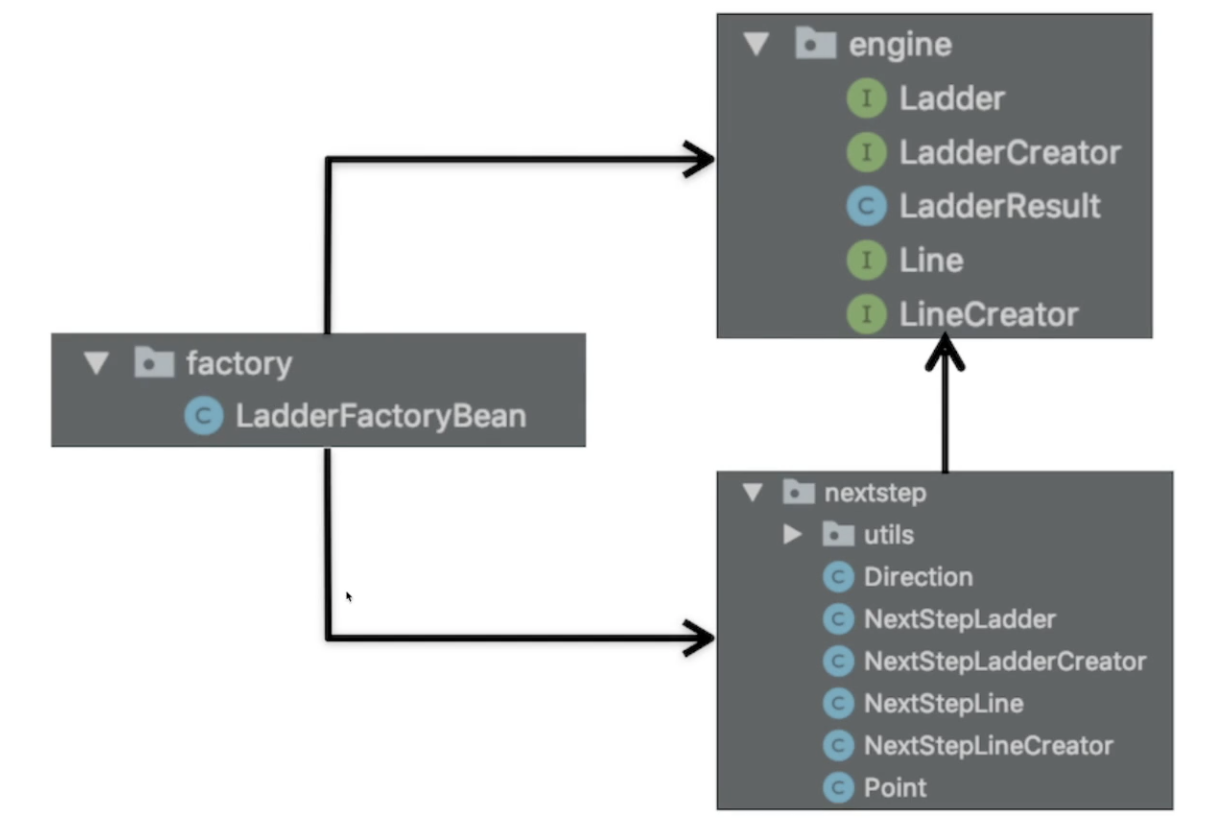
=> interface package(engine)와 구현체 package(nextstep) 간에 의존관계가 양방향이 돼버리는 경우, 중간에 둘을 연결해주는 또다른 패키지가 필요
public class LadderFactoryBean {
public static LadderCreator createLadderFactory() {
LineCreator lineCreator = new NextStepLineCreator();
return new NextStepLadderCreator(lineCreator);
}
}=> 이게 원래 스프링 프레임워크의 DI 컨테이너에서 해주는 역할
-
cyclic dependancy를 가지면 ddd, msa로 갈때 쪼개는게 힘들어짐 (sonarqube 같은 정적 분석도구를 이용해서 찾고 해결하기. ci에 연결해서 매일 새벽에 리포팅 하는 방식도 좋음)
-
인스턴스 변수를 10개까지 줄이자
-
강의 후 오브젝트 읽으면서 적용해보기(특히 3장)
-
나중에 TDD를 익히고 책도 읽고 적용하며 역량을 내재화한 후에 ATDD나 DDD 듣기
