Bert-GCN이라는 논문을 보다보면, 여러번 transductive learning이라는 키워드를 마주하게 된다.
그렇다면 transductive learning이란 무엇을 의미하는가?
Transduction(machine learning)
해당 단어에 대한 설명을 wiki에서 빌려오면 아래와 같이 설명하는 것을 알 수 있다.
In logic, statistical inference, and supervised learning, transduction or transductive inference is reasoning from observed, specific (training) cases to specific (test) cases. In contrast, induction is reasoning from observed training cases to general rules, which are then applied to the test cases.
머신러닝에서의 해결 방법에서의 transduction은 induction과 상반되는 추론 방법을 의미한다.
induction은 training case에서 일반적인 규칙을 찾아 test case에 적용을 하는 반면, transduction은 training, test case 를 모두 관찰하여 추론이 이루어진다는 의미
즉, induction은 일반화된 패턴을 찾아서 test case에 적용하지만, transduction은 일반화 과정없이 답을 도출한다는 뜻
이렇게만 들어서는 무슨 말인지 모르겠다.
개인적으로 이렇게 정리해서 논문 앞에다 붙여놨더니, 이해도 안 될뿐더러 설명도 어려웠다.
그렇다면 아래의 예시와 함께 확인해보자!
Example

해당 그림과 같은 데이터가 주어졌을 때, A, B, C 몇개의 점에는 label이 있으며, 다른 점들은 label이 주어지지 않았다. 우리의 목표는 unlabeled data에 적절한 label을 예측하는 것이다.
이 문제를 insductive 관점으로 접근한다면, labeled data인 A, B, C 만으로 지도학습 알고리즘(superviesed-learning algorithm)을 적용 해 나머지 데이터들에 대해 예측해야 한다. 하지만 이렇게 접근했을 때에는 labeled data가 5개로 매우 적어 해당 구조를 표현하는 모델을 만들기 어려울 것이다.
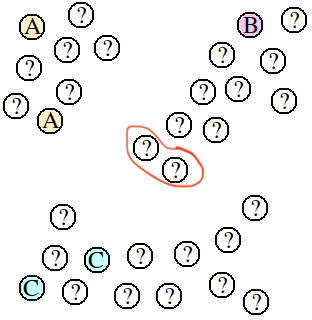
예를 들어, 근접이웃 알고리즘(nearest-neighbor algorithm)으로 접근하면, 가운데 표시된 데이터들은 B로 클러스터링 되는 것이 적절하지만, A 나 C로 예측될 수 있다는 것이다.
위의 예시를 통해 알 수 있는 transductive 접근법의 장점은 적절한 경계를 찾아낼 수 있기 때문에 labeled data가 적을 때에도 더 좋은 예측을 할 수 있다는 것이다.
하지만, transductive learning은 예측 모델을 구축하지 않기 때문에, 학습에 사용되지 않는 데이터가 추가되었을 경우 예측하기 어렵고, 모든 데이터를 다시 학습해야 한다는 단점이 있다. 이 경우 데이터가 스트림을 통해 증가될 경우 계산 비용이 많이 들 수 있다. 또한, 미리 학습된 데이터의 예측이 바뀔 수 도 있다.(좋은 방향일지 나쁜 방향일지는 때에 따라 다름^^)
반면에 지도학습알고리즘은 이런면에서 매우 적은 계산비용으로도 새로운 데이터를 바로 labeling 할 수 있다.
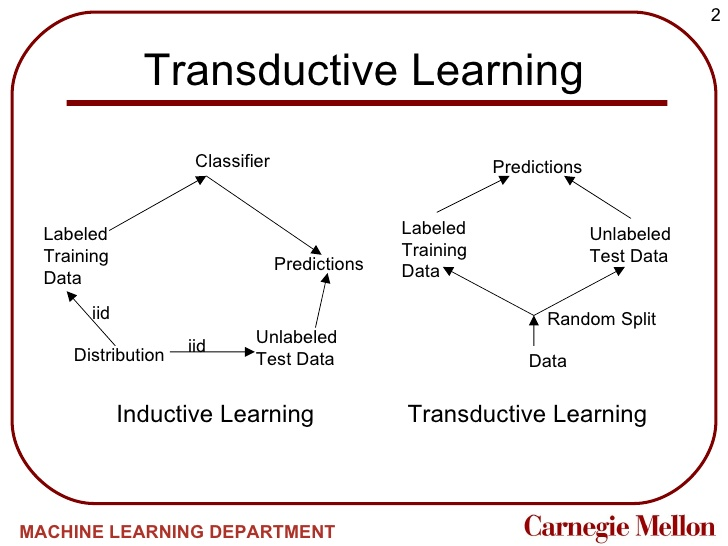
위 그림을 통해 inductive learning과 transductive learning의 차이를 직관적으로 알 수 있다.
BertGCN논문과 연결
The merits of GNNs and transductive learning are as follows:
(1) the decision for an instance (both not depend merely on itself, but also its neighbors. This makes the model more immune to data out- liers;
(2) at the training time, since the model prop- agates influence from supervised labels across both training and test instances through graph edges, unlabeled data also contributes to the process of representation learning, and consequently higher performances.
(paper: BertGCN: Transductive Text Classification by Combining GCN and BERT)
그렇다면 이제 BertGCN과 연결지어서 설명할 수 있다.
(1) unlabeled data에 대한 represetation을 결정할 때, 해당 노드 뿐만 아니라 이웃된 노드에게서도 영향을 받기 때문에, 이상치에 면역을 가지게 된다. (예민하지 않고 일반화된 결과를 얻을 수 있다고 이해했음)
(2) 훈련 때에 모델은 엣지를 통해 train data와 test data 전체에 labeled data의 영향을 모두에게 전파하기 때문에 unlabeled data또한 학습 과정에 사용되어 결과적으로 더 높은 성능을 보일 수 있다.
Reference
