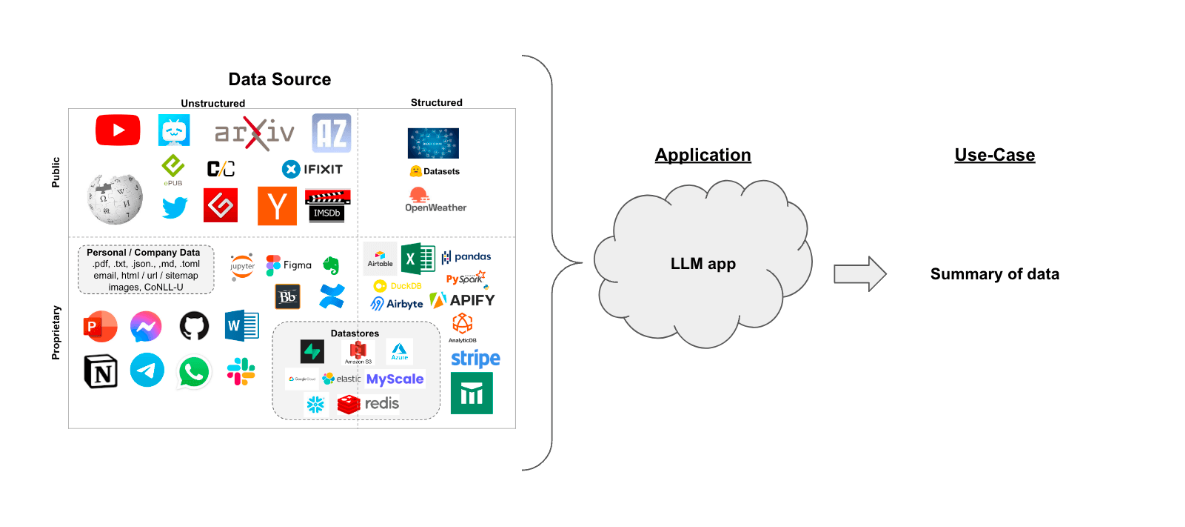
Use case
일련의 문서(PDF, 노션 페이지, 고객 질문 등)가 있고 그 내용을 요약하고 싶다고 가정해 보겠습니다.
텍스트를 이해하고 종합하는 데 능숙한 LLM은 이를 위한 훌륭한 도구입니다.
이 안내서에서는 LLM을 사용하여 문서 요약을 수행하는 방법을 살펴보겠습니다.
Overview
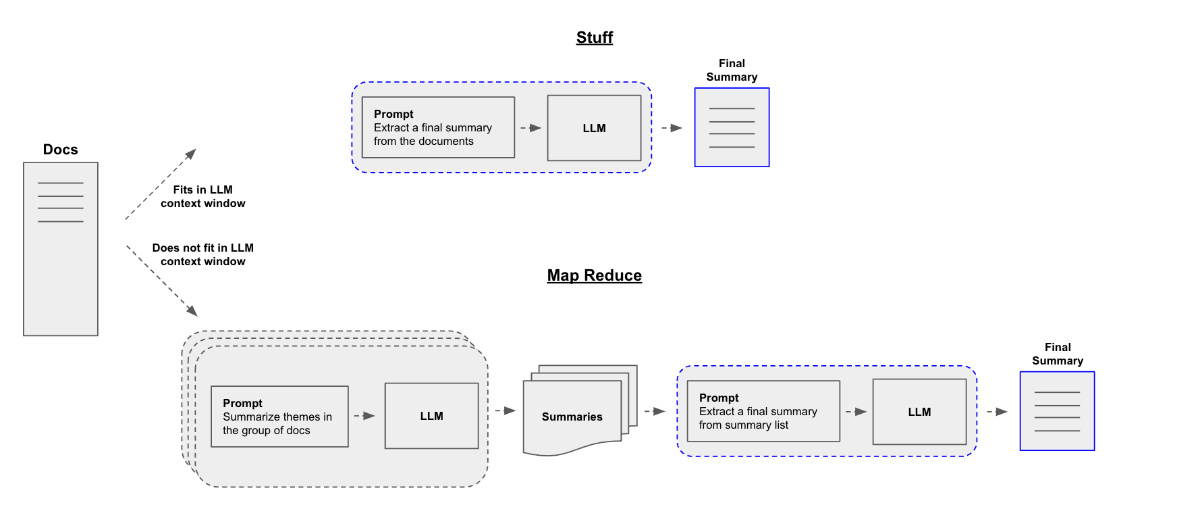
Summarization model을 구축할 때 가장 중요한 질문은 문서를 LLM의 컨텍스트 창으로 어떻게 전달할 것인가 하는 것입니다. 이를 위한 두 가지 일반적인 접근 방식이 있습니다:
-
stuff: 모든 문서를 하나의 프롬프트에 '채우기'만 하면 됩니다. 이 방법은 가장 간단한 접근 방식입니다.
-
Map-reduce: '맵' 단계에서 각 문서를 자체적으로 요약한 다음 그 요약을 최종 요약으로 '축소'합니다.
Quickstart
미리 보기를 위해 두 파이프라인을 load_summarize_chain이라는 단일 객체로 래핑할 수 있습니다.
블로그 게시물을 요약하고 싶다고 가정해 봅시다. 이를 몇 줄의 코드로 만들 수 있습니다.
먼저 환경 변수를 설정하고 패키지를 설치합니다:
!pip install openai tiktoken chromadb langchainCollecting openai
Downloading openai-1.10.0-py3-none-any.whl (225 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 225.1/225.1 kB 2.9 MB/s eta 0:00:00
Collecting tiktoken
Downloading tiktoken-0.5.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (2.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.0/2.0 MB 11.3 MB/s eta 0:00:00import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# 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특히 다음과 같이 더 큰 컨텍스트 창 모델을 사용하는 경우 chain_type="stuff"를 사용할 수 있습니다:
- 16k 토큰 OpenAI gpt-3.5-turbo-1106
- 100k 토큰 Anthropic Claude-2
chain_type="map_reduce" 또는 chain_type="refine"을 제공할 수도 있습니다.
from langchain.chains.summarize import load_summarize_chain
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
chain = load_summarize_chain(llm, chain_type="stuff")
chain.run(docs)/usr/local/lib/python3.10/dist-packages/langchain_core/_api/deprecation.py:117: LangChainDeprecationWarning: The class `langchain_community.chat_models.openai.ChatOpenAI` was deprecated in langchain-community 0.0.10 and will be removed in 0.2.0. An updated version of the class exists in the langchain-openai package and should be used instead. To use it run `pip install -U langchain-openai` and import as `from langchain_openai import ChatOpenAI`.
warn_deprecated(
/usr/local/lib/python3.10/dist-packages/langchain_core/_api/deprecation.py:117: LangChainDeprecationWarning: The function `run` was deprecated in LangChain 0.1.0 and will be removed in 0.2.0. Use invoke instead.
warn_deprecated(
The article discusses the concept of LLM-powered autonomous agents, which use large language models as their core controllers. It covers the components of these agents, including planning, memory, and tool use, as well as case studies and proof-of-concept examples. The challenges of using natural language interfaces and the reliability of model outputs are also addressed. The article provides citations and references for further reading.Option 1. Stuff
load_summarize_chain을 chain_type="stuff"와 함께 사용하면
StuffDocumentsChain을 사용하게 됩니다.
이 체인은 문서 목록을 가져와 프롬프트에 모두 삽입하고 프롬프트를 LLM에 전달합니다:
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
# Define prompt
prompt_template = """Write a concise summary of the following:
"{text}"
CONCISE SUMMARY:"""
prompt = PromptTemplate.from_template(prompt_template)
# Define LLM chain
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-16k")
llm_chain = LLMChain(llm=llm, prompt=prompt)
print(llm_chain)
# Define StuffDocumentsChain
stuff_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="text")
docs = loader.load() # Web Base Loader
print(stuff_chain.run(docs))#prompt=PromptTemplate(input_variables=['text'], template='Write a concise summary of the following:\n"{text}"\nCONCISE SUMMARY:') llm=ChatOpenAI(client=<openai.resources.chat.completions.Completions object at 0x7d3792c9dae0>, async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x7d3792065b70>, model_name='gpt-3.5-turbo-16k', temperature=0.0, openai_api_key='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', openai_proxy='')
#The effectiveness of cold showers in providing health benefits is still uncertain due to a lack of research. Some studies suggest that cold showers may reduce sick days and improve mood, but the evidence is not strong. More research is needed to determine the true effects of cold showers. Skillshare is offering SciShow viewers 2 free months of unlimited access to their platform of over 20,000 classes.Option 2. Map-Reduce
Map-Reduce 접근 방식을 풀어보겠습니다. 이를 위해 먼저 LLMChain을 사용하여 각 문서를 개별 요약에 매핑합니다. 그런 다음 ReduceDocumentsChain을 사용하여 이러한 요약을 하나의 전역 요약으로 결합합니다.
먼저, 각 문서를 개별 요약에 매핑하는 데 사용할 LLMChain을 지정합니다:
from langchain.chains import MapReduceDocumentsChain, ReduceDocumentsChain
from langchain.text_splitter import CharacterTextSplitter
llm = ChatOpenAI(temperature=0)
# Map
map_template = """The following is a set of documents
{docs}
Based on this list of docs, please identify the main themes
Helpful Answer:"""
map_prompt = PromptTemplate.from_template(map_template)
map_chain = LLMChain(llm=llm, prompt=map_prompt)프롬프트 허브를 사용하여 프롬프트를 저장하고 가져올 수도 있습니다.
Prompthub with Langchain
!pip install langchainhubCollecting langchainhub
Downloading langchainhub-0.1.14-py3-none-any.whl (3.4 kB)
Requirement already satisfied: requests<3,>=2 in /usr/local/lib/python3.10/dist-packages (from langchainhub) (2.31.0)
Collecting types-requests<3.0.0.0,>=2.31.0.2 (from langchainhub)
Downloading types_requests-2.31.0.10-py3-none-any.whl (14 kB)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests<3,>=2->langchainhub) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests<3,>=2->langchainhub) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests<3,>=2->langchainhub) (1.26.18)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests<3,>=2->langchainhub) (2023.11.17)
Collecting urllib3<3,>=1.21.1 (from requests<3,>=2->langchainhub)
Downloading urllib3-2.1.0-py3-none-any.whl (104 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 104.6/104.6 kB 3.0 MB/s eta 0:00:00
Installing collected packages: urllib3, types-requests, langchainhub
Attempting uninstall: urllib3from langchain import hub
map_prompt = hub.pull("rlm/map-prompt")
map_chain = LLMChain(llm=llm, prompt=map_prompt)map_prompt#ChatPromptTemplate(input_variables=['docs'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['docs'], template='The following is a set of documents:\n{docs}\nBased on this list of docs, please identify the main themes \nHelpful Answer:'))])ReduceDocumentsChain은 문서 매핑 결과를 가져와서 단일 출력으로 줄이는 작업을 처리합니다. 이 함수는 일반 CombineDocumentsChain(StuffDocumentsChain과 같은)을 감싸지만, 누적 크기가 token_max를 초과하는 경우 CombineDocumentsChain으로 전달하기 전에 문서를 축소하는 기능을 추가합니다. 이 예시에서는 실제로 문서를 결합하는 데 체인을 재사용하여 문서를 축소할 수도 있습니다.
따라서 매핑된 문서의 누적 토큰 수가 4000 토큰을 초과하면 4000 토큰 미만의 문서를 StuffDocumentsChain에 재귀적으로 전달하여 일괄 요약을 생성합니다. 그리고 이러한 일괄 요약이 누적적으로 4000 토큰 미만이 되면 마지막으로 모든 문서를 StuffDocumentsChain에 전달하여 최종 요약을 생성합니다.
# Reduce
reduce_template = """The following is set of summaries:
{docs}
Take these and distill it into a final, consolidated summary of the main themes.
Helpful Answer:"""
reduce_prompt = PromptTemplate.from_template(reduce_template)# Note we can also get this from the prompt hub, as noted above
reduce_prompt = hub.pull("rlm/map-prompt")reduce_prompt#ChatPromptTemplate(input_variables=['docs'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['docs'], template='The following is a set of
#documents:\n{docs}\nBased on this list of docs, please identify the main themes \nHelpful Answer:'))])# Run chain
reduce_chain = LLMChain(llm=llm, prompt=reduce_prompt)
# Takes a list of documents, combines them into a single string, and passes this to an LLMChain
combine_documents_chain = StuffDocumentsChain(
llm_chain=reduce_chain, document_variable_name="docs"
)
# Combines and iteravely reduces the mapped documents
reduce_documents_chain = ReduceDocumentsChain(
# This is final chain that is called.
combine_documents_chain=combine_documents_chain,
# If documents exceed context for `StuffDocumentsChain`
collapse_documents_chain=combine_documents_chain,
# The maximum number of tokens to group documents into.
token_max=4000,
)map and reduce chain을 이용해서 하나로 줄입니다.:
# Combining documents by mapping a chain over them, then combining results
map_reduce_chain = MapReduceDocumentsChain(
# Map chain
llm_chain=map_chain,
# Reduce chain
reduce_documents_chain=reduce_documents_chain,
# The variable name in the llm_chain to put the documents in
document_variable_name="docs",
# Return the results of the map steps in the output
return_intermediate_steps=False,
)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
split_docs = text_splitter.split_documents(docs) # loader.load()WARNING:langchain.text_splitter:Created a chunk of size 1003, which is longer than the specified 1000print(map_reduce_chain.run(split_docs))Based on the list of documents provided, the main themes can be identified as follows:
1. Large Language Models (LLMs): This theme focuses on the concept and capabilities of LLMs as discussed in the documents. It includes discussions on LLM-powered autonomous agents and their potential beyond generating written content.
2. Prompting and Prompt Engineering: This theme explores the use of prompts and prompt engineering techniques in working with LLMs. It may include discussions on how to effectively prompt LLMs to achieve desired outputs or behaviors.
3. Autonomous Agents: This theme discusses the concept of autonomous agents and their components within an LLM-powered system. It covers topics such as planning, memory, tool use, and the agent's ability to solve problems and perform tasks.
4. Steerability: This theme focuses on the concept of steerability in LLMs and autonomous agents. It may include discussions on how to control or guide the behavior of LLMs and agents to achieve specific outcomes.
5. NLP and Language Model Applications: This theme explores the applications of natural language processing (NLP) and language models in various domains. It may include discussions on specific use cases, case studies, or examples of LLM-powered agents in action.
6. Resources and Tools: This theme covers the availability of resources and tools related to LLMs and autonomous agents. It may include references to datasets, APIs, libraries, or frameworks that are useful for working with LLMs and building autonomous agents.
These main themes provide an overview of the topics covered in the list of documents and highlight the key areas of focus within the set of documents.Option 3. Refine
Refine은 map-reduce와 유사합니다:
- 문서 구체화 체인은 입력 문서를 반복하고 반복적으로 응답을 업데이트하여 응답을 구성합니다. 각 문서에 대해 문서가 아닌 모든 입력, 현재 문서, 최신 중간 답변을 LLM 체인으로 전달하여 새로운 답변을 얻습니다.
이 기능은 chain_type="refine"을 지정하여 쉽게 실행할 수 있습니다.
chain = load_summarize_chain(llm, chain_type="refine")
chain.run(split_docs)Long-term planning and task decomposition pose challenges for Language Model-based Autonomous Agents (LLMs). These agents struggle to adjust plans in the face of unexpected errors, making them less robust compared to humans. Additionally, the reliability of the natural language interface used by LLMs is questionable, as they may make formatting errors and exhibit rebellious behavior. As a result, much of the agent demo code focuses on parsing model output. The provided context does not provide any additional information to refine the original summary.프롬프트를 제공하고 중간 단계를 반환하는 것도 가능합니다.
prompt_template = """Write a concise summary of the following:
{text}
CONCISE SUMMARY:"""
prompt = PromptTemplate.from_template(prompt_template)
refine_template = (
"Your job is to produce a final summary\n"
"We have provided an existing summary up to a certain point: {existing_answer}\n"
"We have the opportunity to refine the existing summary"
"(only if needed) with some more context below.\n"
"------------\n"
"{text}\n"
"------------\n"
"Given the new context, refine the original summary in Italian"
"If the context isn't useful, return the original summary."
)
refine_prompt = PromptTemplate.from_template(refine_template)
chain = load_summarize_chain(
llm=llm,
chain_type="refine",
question_prompt=prompt,
refine_prompt=refine_prompt,
return_intermediate_steps=True,
input_key="input_documents",
output_key="output_text",
)
result = chain({"input_documents": split_docs}, return_only_outputs=True) # split docsprint(result["output_text"])#Questo articolo discute il concetto di costruire agenti autonomi alimentati da grandi modelli di linguaggio (LLM) ed esplora i diversi componenti di tali agenti, tra cui la pianificazione, la memoria e l'uso degli strumenti. Sottolinea il potenziale dei LLM nel risolvere problemi generali e fornisce esempi di dimostrazioni di proof-of-concept. Introduce anche concetti come Chain of Hindsight (CoH) e Algorithm Distillation (AD) che consentono al modello di migliorare le sue uscite e imparare più velocemente. Inoltre, fornisce contesto su diversi tipi di memoria umana, tra cui la memoria sensoriale, la memoria a breve termine e la memoria a lungo termine. Viene discusso l'uso della memoria esterna e dell'algoritmo Maximum Inner Product Search (MIPS) per migliorare le prestazioni degli agenti autonomi. Viene introdotto il concetto di utilizzare strumenti esterni per estendere le capacità dei modelli di linguaggio, come dimostrato da studi di caso come ChemCrow e agenti per la scoperta scientifica. Infine, viene presentato il framework HuggingGPT, che utilizza ChatGPT come pianificatore di attività per selezionare modelli disponibili sulla piattaforma HuggingFace in base alle descrizioni dei modelli e riassumere le risposte in base ai risultati dell'esecuzione. Sottolinea l'importanza di valutare costantemente le azioni, autocriticare il comportamento e riflettere sulle decisioni passate per migliorare le prestazioni. Tuttavia, dopo aver esaminato le idee chiave e le dimostrazioni di costruzione di agenti basati su LLM, emergono alcune limitazioni comuni. Queste includono la capacità limitata di includere informazioni storiche, istruzioni dettagliate, contesto delle chiamate API e risposte a causa della lunghezza del contesto finito. Inoltre, la pianificazione a lungo termine e la decomposizione delle attività rimangono sfide, poiché i LLM faticano ad adattare i piani di fronte a errori imprevisti. Inoltre, l'affidabilità dell'interfaccia di linguaggio naturale è dubbia, poiché i LLM possono commettere errori di formattazione e occasionalmente mostrare comportamenti ribelli. Questo articolo fornisce anche riferimenti a studi e risorse aggiuntive per approfondire l'argomento.print("\n\n".join(result["intermediate_steps"][:3]))This article discusses the concept of building autonomous agents powered by large language models (LLM). It explores the different components of such agents, including planning, memory, and tool use. The potential of LLM extends beyond generating written content and can be used as a general problem solver. The article also provides examples of proof-of-concept demos and discusses the challenges associated with building LLM-powered agents.
Questo articolo discute il concetto di costruire agenti autonomi alimentati da grandi modelli di linguaggio (LLM). Esplora i diversi componenti di tali agenti, tra cui la pianificazione, la memoria e l'uso degli strumenti. Il potenziale di LLM si estende oltre la generazione di contenuti scritti e può essere utilizzato come risolutore di problemi generale. L'articolo fornisce anche esempi di dimostrazioni di proof-of-concept e discute le sfide associate alla costruzione di agenti alimentati da LLM.
Questo articolo discute il concetto di costruire agenti autonomi alimentati da grandi modelli di linguaggio (LLM). Esplora i diversi componenti di tali agenti, tra cui la pianificazione, la memoria e l'uso degli strumenti. Il potenziale di LLM si estende oltre la generazione di contenuti scritti e può essere utilizzato come risolutore di problemi generale. L'articolo fornisce anche esempi di dimostrazioni di proof-of-concept e discute le sfide associate alla costruzione di agenti alimentati da LLM. Inoltre, viene presentato il concetto di Chain of Hindsight (CoH) che permette al modello di migliorare i propri output attraverso un processo di auto-riflessione basato su feedback passati. Viene anche introdotto l'Algorithm Distillation (AD) che applica lo stesso principio alle traiettorie di apprendimento per compiti di reinforcement learning. Questi approcci dimostrano di poter migliorare le prestazioni degli agenti autonomi e di apprendere in modo più rapido rispetto ad altri metodi.YouTube Loader
- YouTube 자막 분석
!pip install youtube-transcript-api pytube faiss-cpu tiktokenCollecting youtube-transcript-api
Downloading youtube_transcript_api-0.6.1-py3-none-any.whl (24 kB)
Collecting pytube
Downloading pytube-15.0.0-py3-none-any.whl (57 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 57.6/57.6 kB 2.3 MB/s eta 0:00:00
Collecting faiss-cpu
Downloading faiss_cpu-1.7.4-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (17.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 17.6/17.6 MB 34.5 MB/s eta 0:00:00# From: https://towardsdatascience.com/getting-started-with-langchain-a-beginners-guide-to-building-llm-powered-applications-95fc8898732c
from langchain.document_loaders import YoutubeLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
embeddings = OpenAIEmbeddings()
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=HsonXuJs8-s") # Cold showers FTW!
documents = loader.load()
# create the vectorestore to use as the index
db = FAISS.from_documents(documents, embeddings)
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
query = "Should children do a cold shower"
result = qa({"query": query})
print(result['result'])There is limited research on the effects of cold showers specifically for children. It is generally recommended to consult with a healthcare professional before making any changes to a child's bathing routine.Pandas Data load agent
- 졍형 데이터 분석
!pip install langchain-experimentalRequirement already satisfied: pip in /usr/local/lib/python3.10/dist-packages (23.1.2)
Requirement already satisfied: install in /usr/local/lib/python3.10/dist-packages (1.3.5)
Collecting langchain-experimental
Downloading langchain_experimental-0.0.45-py3-none-any.whl (162 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 162.8/162.8 kB 2.8 MB/s eta 0:00:00from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
from langchain_experimental.agents.agent_toolkits import create_csv_agent
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")df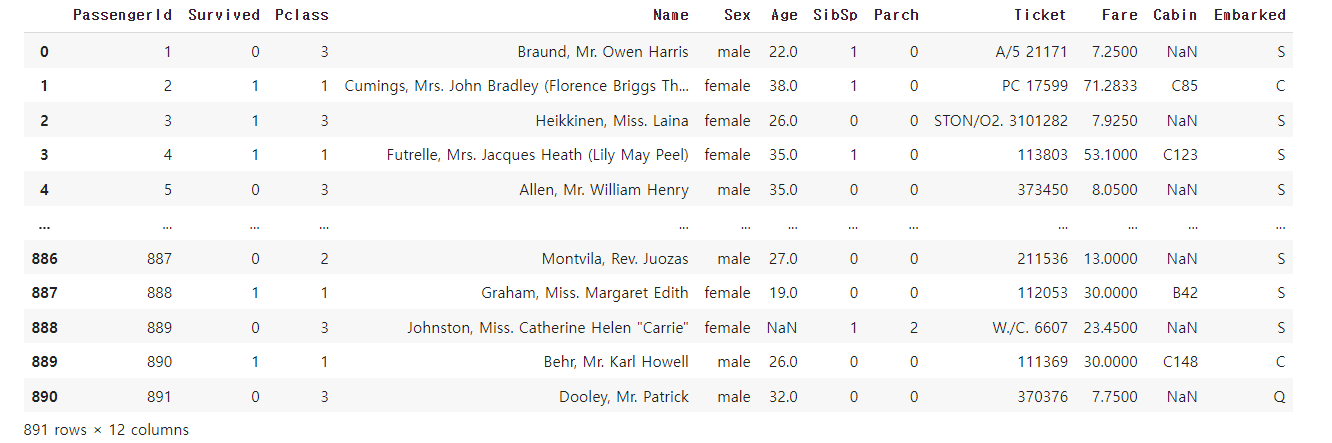
agent = create_csv_agent(
OpenAI(temperature=0),
"https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv", # multi = [] list type
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)agent.run("how many rows are there?")
> Entering new AgentExecutor chain...
Thought: I need to count the number of rows
Action: python_repl_ast
Action Input: df.shape[0]
Observation: 891
Thought: I now know the final answer
Final Answer: There are 891 rows.
> Finished chain.
There are 891 rows.agent.run("what does Pclass stand for?")
> Entering new AgentExecutor chain...
Thought: I should look at the dataframe to see what Pclass is
Action: python_repl_ast
Action Input: df.columns
Observation: Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
Thought: Pclass is one of the columns
Action: python_repl_ast
Action Input: df.columns[2]
Observation: Pclass
Thought: I now know the final answer
Final Answer: Pclass stands for Passenger Class.
> Finished chain.
Pclass stands for Passenger Class.연습문제
- 외부 웹페이지 로더를 이용한 텍스트 요약
- LangChain 라이브러리를 사용하여 주어진 문서들을 요약하는 파이프라인을 만들어야 합니다. 이 파이프라인은 문서 로딩, 임베딩 생성, 요약 과정을 포함해야 합니다.
WebBaseLoader를 사용하여 웹페이지의 텍스트 콘텐츠를 불러옵니다.- 불러온 텍스트 콘텐츠의 임베딩을 생성합니다.
- 생성된 임베딩을 기반으로 텍스트를 요약하는 함수를 구현합니다.
- stuff, map-reduce, refine으로 요약하는 모델을 구현합니다.
# sk-ezhBkoGBH2NFwENvG3g2T3BlbkFJayeOkK4D6g4mHzUGjX3cloader = WebBaseLoader("https://www.bbc.com/news/technology-67630454")
docs = loader.load()
# 분리되는 파트
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
chain = load_summarize_chain(llm, chain_type="stuff")
chain.run(docs)Google has released a new AI model called Gemini, which it claims has advanced reasoning capabilities and can "think more carefully" when answering difficult questions. The AI was tested on problem-solving and knowledge in various subject areas and is said to be the most capable AI model yet. It can recognize and generate text, images, and audio, and will be integrated into Google\'s existing tools. Gemini is said to outperform human experts in intelligence tests and has the ability to learn from sources other than text, such as pictures. However, it faces competition from other AI products and concerns about the potential risks and dangers of AI technology.docs
[Document(page_content='Google claims new Gemini AI \'thinks more carefully\'HomeNewsSportBusinessInnovationCultureTravelEarthVideoLiveHomeNewsSportBusinessInnovationCultureTravelEarthVideoLiveHomeNewsSportBusinessInnovationCultureTravelEarthVideoLiveGoogle claims new Gemini AI \'thinks more carefully\'By Shiona McCallum and Zoe KleinmanTechnology teamGoogleGoogle says Gemini will power text and image servicesGoogle has released an artificial intelligence (AI) model which it claims has advanced "reasoning capabilities" to "think more carefully" when answering hard questions.AI content generators are known to sometimes invent things, which developers call hallucinations.Gemini was tested on its problem-solving and knowledge in 57 subject areas including maths and humanities.Boss Sundar Pichai said it represented a "new era" for AI.Google adopted a cautious approach to the launch of its AI chatbot, Bard, earlier this year, describing it as "an experiment". Bard made a mistake in its own publicity demo, providing the wrong answer to a question about space.But Google is making some big claims for its new model, describing it as its "most capable" yet and has suggested it can outperform human experts in a range of intelligence tests.Gemini can both recognise and generate text, images and audio - but is not a product in its own right.Instead it is what it known as a foundational model, meaning it will be integrated into Google\'s existing tools, including search and Bard. AI raceGemini appeared to have set a "new standard", highlighting its ability to learn from sources other than text, such as pictures, according to Chirag Dekate, from analysts Gartner.He said that might "enable innovations that are likely to transform generative AI." Google has so far struggled to attract as much attention and as many users users as OpenAI\'s viral chatbot ChatGPT.But it claims the most powerful version of Gemini outperforms OpenAI\'s platform GPT-4 - which drives ChatGPT - on 30 of the 32 widely-used academic benchmarks.However, a new, more powerful version of the OpenAI software is due to be released next year, with chief executive Sam Altman saying the firm\'s new products would make its current ones look like "a quaint relative".It remains to be seen whether the recent turmoil at OpenAI - which saw Mr Altman fired and rehired in the space of a few days - will have any impact on that launch.The firm also faces fresh competition from Elon Musk\'s xAI, which is seeking to raise up to $1bn to invest in research and development. Chinese firm Baidu is also racing ahead with its own AI products.But as the technology rapidly evolves, so do fears about its potential to cause harm.Governments around the world are trying to develop rules or even legislation to contain the possible future risks of AI.In November, the subject was discussed at a summit in the UK, where signatories agreed a declaration calling for its safe development. The King also said possible dangers needed to be addressed with a sense of "urgency, unity and collective strength".GoogleArtificial intelligenceRelatedInactive Google accounts to be deleted from Friday8 days agoTechnologyGoogle and Canada reach deal to avert news ban29 Nov 2023US & CanadaMan on mission to get Guernsey on the Google map29 Nov 2023GuernseyMore24 hrs agoAI funding to speed up mental health diagnosisA Cambridge psychiatrist is developing an AI system to speed up mental health diagnosis in children.24 hrs agoCambridgeshire1 day agoThe people creating digital clones of themselvesBusiness leaders and experts are making online copies of themselves to answer the questions they get.1 day agoBusiness1 day agoChatGPT tool could help scammers and hackersA cutting-edge tool from Open AI appears to be poorly moderated, allowing it to be abused by cyber-criminals.1 day agoTechnology2 days agoNvidia boss confident about safety of AIThe president and chief executive of the chipmaker to ChatGPT says the rise of AI is no cause for concern.2 days agoBusiness3 days agoAI scheme to reduce patient hospital admissionsNew algorithm will predict patients\' medical problems before they happen.3 days agoWiltshireHomeNewsSportBusinessInnovationCultureTravelEarthVideoLiveBBC ShopBBC in other languagesTerms of UseAbout the BBCPrivacy PolicyCookiesAccessibility HelpContact the BBCAdvertise with usAdChoices/ Do Not Sell My InfoCopyright 2023 BBC. All rights reserved.\xa0\xa0The BBC is not responsible for the content of external sites.\xa0Read about our approach to external linking.Beta Terms By using the Beta Site, you agree that such use is at your own risk and you know that the Beta Site may include known or unknown bugs or errors, that we have no obligation to make this Beta Site available with or without charge for any period of time, nor to make it available at all, and that nothing in these Beta Terms or your use of the Beta Site creates any employment relationship between you and us. The Beta Site is provided on an “as is” and “as available” basis and we make no warranty to you of any kind, express or implied.In case of conflict between these Beta Terms and the BBC Terms of Use these Beta Terms shall prevail.HomeNewsNewsIsrael-Gaza WarWar in UkraineWorldAfricaAsiaAustraliaEuropeLatin AmericaMiddle EastUS & CanadaUKUKEnglandN. IrelandScotlandWalesIn PicturesBBC VerifySportBusinessBusinessFuture of BusinessTechnology of BusinessWork CultureMarket DataInnovationInnovationTechnologyScience & HealthArtificial IntelligenceCultureCultureFilm & TVMusicArt & DesignStyleBooksEntertainment NewsTravelTravelDestinationsWorld’s TableCulture & ExperiencesAdventuresThe SpeciaListEarthEarthNatural WondersWeather & ScienceClimate SolutionsSustainable BusinessGreen LivingVideoLiveLiveLive NewsLive SportAudio', metadata={'source': 'https://www.bbc.com/news/technology-67630454', 'title': "Google claims new Gemini AI 'thinks more carefully'", 'description': 'Tech giant says Gemini will supercharge existing products, and take on market leader GPT-4.', 'language': 'No language found.'})]# map-reduce
# Reduce
reduce_template = """The following is set of summaries:
{docs}
Take these and distill it into a final, consolidated summary of the main themes.
Helpful Answer:"""
reduce_prompt = PromptTemplate.from_template(reduce_template)
# Run chain
reduce_chain = LLMChain(llm=llm, prompt=reduce_prompt)
# Takes a list of documents, combines them into a single string, and passes this to an LLMChain
combine_documents_chain = StuffDocumentsChain(
llm_chain=reduce_chain, document_variable_name="docs"
)
# Combines and iteravely reduces the mapped documents
reduce_documents_chain = ReduceDocumentsChain(
# This is final chain that is called.
combine_documents_chain=combine_documents_chain,
# If documents exceed context for `StuffDocumentsChain`
collapse_documents_chain=combine_documents_chain,
# The maximum number of tokens to group documents into.
token_max=3000,
)# Combining documents by mapping a chain over them, then combining results
map_reduce_chain = MapReduceDocumentsChain(
# Map chain
llm_chain=reduce_chain,
# Reduce chain
reduce_documents_chain=reduce_documents_chain,
# The variable name in the llm_chain to put the documents in
document_variable_name="docs",
# Return the results of the map steps in the output
return_intermediate_steps=False,
)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
split_docs = text_splitter.split_documents(docs) # loader.load()
print(map_reduce_chain.run(split_docs))Google has introduced a new AI model called Gemini, which boasts advanced reasoning abilities and outperforms human experts in intelligence tests. The AI can handle text, images, and audio and is intended for integration into Google's tools. The AI race is intensifying with competition from OpenAI, xAI, and Baidu, but concerns about AI's potential harm are also growing, leading to discussions about regulations and safe development.# refine
chain = load_summarize_chain(llm, chain_type="refine")
chain.run(docs)Google has released a new AI model called Gemini, which it claims has advanced reasoning capabilities and can "think more carefully" when answering difficult questions. The AI was tested on problem-solving and knowledge in various subject areas and is said to be the most capable AI model yet. It can recognize and generate text, images, and audio, and will be integrated into Google\'s existing tools. Gemini is said to outperform human experts in intelligence tests and can learn from sources other than text, such as pictures. However, it faces competition from other AI products and concerns about the potential harm of AI technology.2. YouTube 요약
- 주어진 YouTube 비디오의 자막을 Langchain API를 사용하여 요약합니다.
- QA 함수를 이용해서 영상에 있는 내용들을 정리해보세요.
- 질문들을 만들어서 영상의 내용들을 요약해 결과를 출력해보세요.
embeddings = OpenAIEmbeddings()
loader = YoutubeLoader.from_youtube_url("https://youtu.be/LBudghsdByQ?si=aJfjubFgDOThIBP9") # Cold showers FTW!
documents = loader.load()
# create the vectorestore to use as the index
db = FAISS.from_documents(documents, embeddings)
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(
llm=#TODO,
chain_type="stuff",
retriever=#TODO,
return_source_documents=True)
query = #TODO
result = qa({"query": query})
print(result['result'])query = "한국에 무슨 문제가 있어?"
result = qa({"query": query})
print(result['result'])정형 데이터 분석
- CSV 파일을 로드하고 기본적인 데이터 분석을 수행한 후, Langchain API를 사용하여 분석 결과를 요약합니다.
1. 파이썬 스크립트를 작성하여 CSV 파일을 입력으로 받습니다. 2. 파일을 분석하여 행 수, 특정 열의 평균 등 기본적인 통계를 계산합니다. 3. Langchain API를 통해 이 분석 결과를 요약하여 출력합니다. 4. california_housing_train 데이터셋을 이용해서 각 데이터 특징과 집값의 관계에 대해 분석해보세요.
agent = create_csv_agent(
OpenAI(temperature=0),
"/content/sample_data/california_housing_train.csv", # multi = [] list type
verbose=True,
agent_type=AgentType.#TODO,
)agent.run(#TODO)