
import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
tf.__version__# 2.15.0Dataset 준비
- 학습을 위해 제공되는 MNIST dataset을 준비
# Load training and eval data from tf.keras
(train_data, train_labels), (test_data, test_labels) = \
tf.keras.datasets.cifar10.load_data()Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 5s 0us/stepprint(train_data.shape, train_labels.shape)
print(test_data.shape, test_labels.shape)# (50000, 32, 32, 3) (50000, 1)
# (10000, 32, 32, 3) (10000, 1)# 데이터 전처리 파트 -> 도메인 지식이 들어가게 됩니다.
train_data = train_data / 255.
train_labels = train_labels.reshape(-1)
train_data = train_data.astype(np.float32)
train_labels = train_labels.astype(np.int32)
test_data = test_data / 255.
test_labels = test_labels.reshape(-1)
test_data = test_data.astype(np.float32)
test_labels = test_labels.astype(np.int32)Dataset 구성
- 원활한 학습을 위해서 데이터셋을 구성해주고, Label을 one-hot으로 변환해준다.
def one_hot_label(image, label):
label = tf.one_hot(label, depth=10) # [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
return image, labelbatch_size = 32
max_epochs = 10
# for train
N = len(train_data)
train_dataset = tf.data.Dataset.from_tensor_slices((train_data, train_labels))
train_dataset = train_dataset.shuffle(buffer_size=10000)
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.repeat().batch(batch_size=batch_size)
print(train_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_data, test_labels))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.repeat().batch(batch_size=batch_size)
print(test_dataset)#<_BatchDataset element_spec=(TensorSpec(shape=(None, 32, 32, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 10), dtype=tf.float32, name=None))>
#<_BatchDataset element_spec=(TensorSpec(shape=(None, 32, 32, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 10), dtype=tf.float32, name=None))>- 데이터 확인
index = 12190
print("label = {}".format(train_labels[index]))
plt.imshow(train_data[index].reshape(32, 32, 3))
plt.colorbar()
#plt.gca().grid(False)
plt.show()
모델 제작
# Conv2D - 3, 64 - MaxPool2D
# Conv2D - 3, 128 - MaxPool2D
# Conv2D - 3, 256 - MaxPool2D
# Flatten
# Dense 256
# Dense 256
# Dense output 10model = tf.keras.models.Sequential()
model.add(layers.Conv2D(6, (5,5), activation='relu'))
model.add(layers.MaxPool2D()) # 2x2, strides=2
model.add(layers.Conv2D(16, (5,5), activation='relu'))
model.add(layers.MaxPool2D())
model.add(layers.Flatten()) # 데이터의 차원을 1차원으로 만들어주는 레이어
model.add(layers.Dense(120, activation='relu'))
model.add(layers.Dense(84, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# LeNet 5
Training
tf.keras.losses.CategoricalCrossentropy()
cce = tf.keras.losses.CategoricalCrossentropy()
loss = cce([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]],
[[.9, .05, .05], [.5, .89, .6], [.05, .01, .94]])
print('Loss: ', loss.numpy()) # Loss: 0.3239model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])모델 확인
# without training, just inference a model in eager execution:
predictions = model(train_data[0:1], training=False)
print("Predictions: ", predictions.numpy())#Predictions: [[0.1001787 0.0871859 0.09879868 #0.10397458 0.09840901 0.10669483
0.09029824 0.10176784 0.10831907 0.10437319]]tf.keras.utils.plot_model(model, show_shapes=True)
학습진행
- model.fit 함수가 최근에 model.fit_generator 함수와 통합
- Dataset을 이용한 학습을 진행
# using `numpy type` data
# history = model.fit(train_data, train_labels,
# batch_size=batch_size, epochs=max_epochs,
# validation_split=0.05)
# using `tf.data.Dataset`
history = model.fit(train_dataset, epochs=max_epochs,
steps_per_epoch=int(len(train_data) / batch_size))Epoch 1/10
1562/1562 [==============================] - 10s 5ms/step - loss: 1.9004 - accuracy: 0.3088
Epoch 2/10
1562/1562 [==============================] - 8s 5ms/step - loss: 1.6456 - accuracy: 0.4009
Epoch 3/10
1562/1562 [==============================] - 8s 5ms/step - loss: 1.5628 - accuracy: 0.4332
Epoch 4/10
1562/1562 [==============================] - 8s 5ms/step - loss: 1.5037 - accuracy: 0.4552
Epoch 5/10
1562/1562 [==============================] - 8s 5ms/step - loss: 1.4511 - accuracy: 0.4775
Epoch 6/10
1562/1562 [==============================] - 7s 5ms/step - loss: 1.4086 - accuracy: 0.4949
Epoch 7/10
1562/1562 [==============================] - 8s 5ms/step - loss: 1.3722 - accuracy: 0.5088
Epoch 8/10
1562/1562 [==============================] - 7s 5ms/step - loss: 1.3409 - accuracy: 0.5198
Epoch 9/10
1562/1562 [==============================] - 7s 5ms/step - loss: 1.3112 - accuracy: 0.5314
Epoch 10/10
1562/1562 [==============================] - 8s 5ms/step - loss: 1.2881 - accuracy: 0.5421학습결과 확인
history.history.keys()# dict_keys(['loss', 'accuracy'])acc = history.history['accuracy']
loss = history.history['loss']
epochs_range = range(max_epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.legend(loc='upper right')
plt.title('Training and Loss')
plt.show()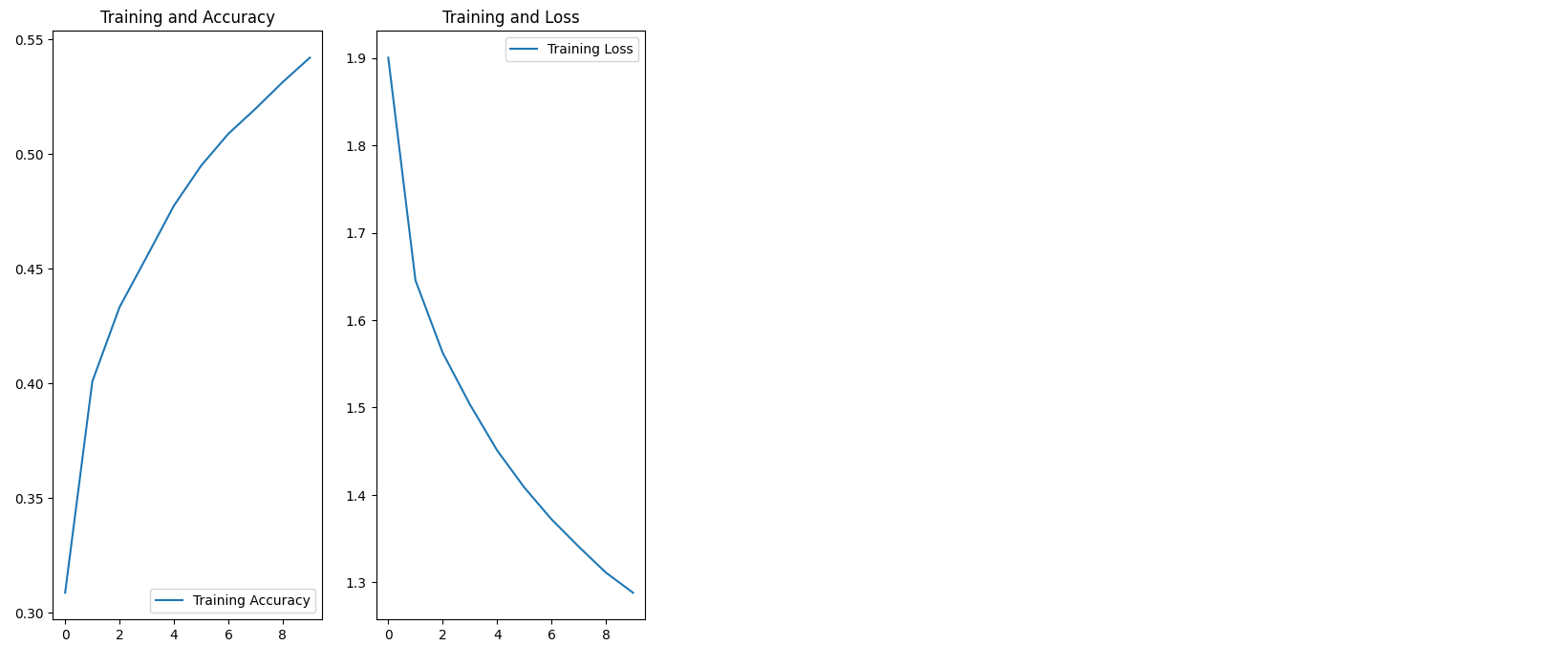
results = model.evaluate(test_dataset, steps=int(len(train_data) / batch_size))#1562/1562 [==============================] - 5s 3ms/step - loss: 1.2961 - accuracy: 0.5363# loss
print("loss value: {:.3f}".format(results[0]))
# accuracy
print("accuracy value: {:.4f}%".format(results[1]*100))#loss value: 1.296
#accuracy value: 53.6272%np.random.seed(219)
test_batch_size = 16
batch_index = np.random.choice(len(test_data), size=test_batch_size, replace=False)
batch_xs = test_data[batch_index]
batch_ys = test_labels[batch_index]
y_pred_ = model(batch_xs, training=False)
fig = plt.figure(figsize=(16, 10))
for i, (px, py) in enumerate(zip(batch_xs, y_pred_)):
p = fig.add_subplot(4, 8, i+1)
if np.argmax(py) == batch_ys[i]:
p.set_title("y_pred: {}".format(np.argmax(py)), color='blue')
else:
p.set_title("y_pred: {}".format(np.argmax(py)), color='red')
p.imshow(px.reshape(32, 32, 3)) # ciar10 32, 32, 3
p.axis('off') 

AI, Information and Communication, Electronics, Computer Science, Bio, Algorithms