!pip install transformersRequirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2023.11.17import tensorflow as tf
from transformers import AutoTokenizer
from transformers import TFGPT2LMHeadModeltokenizer = AutoTokenizer.from_pretrained('skt/kogpt2-base-v2', bos_token='</s>', eos_token='</s>', pad_token='<pad>')
model = TFGPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2', from_pt=True)/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_token.py:88: UserWarning:
The secret `HF_TOKEN` does not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(
Some weights of the PyTorch model were not used when initializing the TF 2.0 model TFGPT2LMHeadModel: ['transformer.h.2.attn.masked_bias', 'transformer.h.7.attn.masked_bias', 'transformer.h.10.attn.masked_bias', 'transformer.h.0.attn.masked_bias', 'transformer.h.8.attn.masked_bias', 'transformer.h.9.attn.masked_bias', 'transformer.h.11.attn.masked_bias', 'transformer.h.3.attn.masked_bias', 'transformer.h.5.attn.masked_bias', 'transformer.h.4.attn.masked_bias', 'transformer.h.6.attn.masked_bias', 'transformer.h.1.attn.masked_bias', 'lm_head.weight']
- This IS expected if you are initializing TFGPT2LMHeadModel from a PyTorch model trained on another task or with another architecture (e.g. initializing a TFBertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TFGPT2LMHeadModel from a PyTorch model that you expect to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFGPT2LMHeadModel were initialized from the PyTorch model.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFGPT2LMHeadModel for predictions without further training.print(tokenizer.bos_token_id)
print(tokenizer.eos_token_id)
print(tokenizer.pad_token_id)
print('-' * 10)
print(tokenizer.decode(1))
print(tokenizer.decode(2))
print(tokenizer.decode(3))
print(tokenizer.decode(4))#1
#1
#3
#----------
#</s>
#<usr>
#<pad>
#<sys>import pandas as pd
import tqdm
import urllib.requesturllib.request.urlretrieve("https://raw.githubusercontent.com/songys/Chatbot_data/master/ChatbotData.csv", filename="ChatBotData.csv")
train_data = pd.read_csv('ChatBotData.csv')len(train_data)# 11823train_data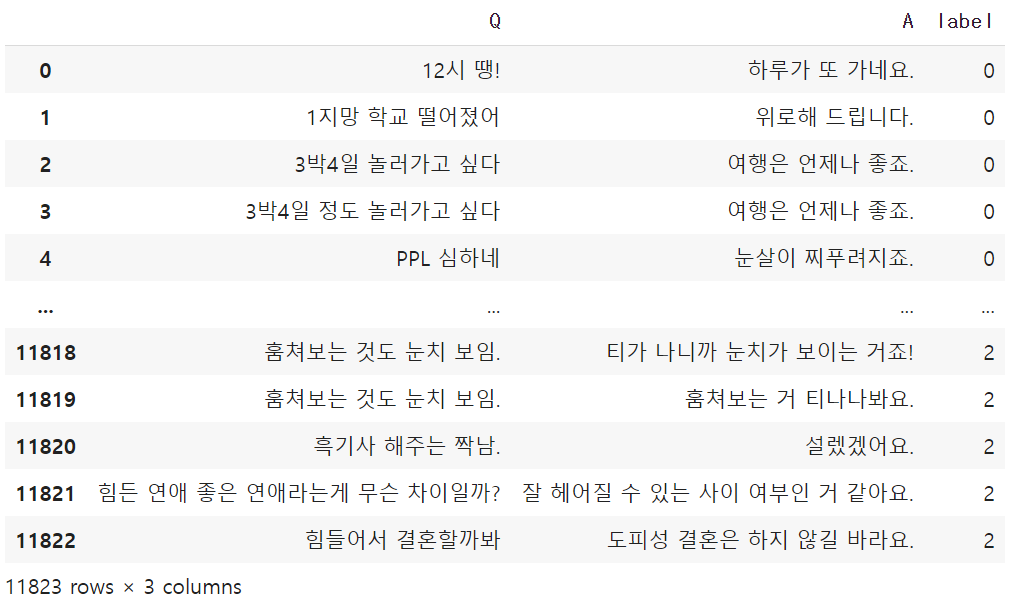
train_data['Q'].map(len).max() + train_data['A'].map(len).max() + 4# 136batch_size = 8def get_chat_data():
for question, answer in zip(train_data.Q.to_list(), train_data.A.to_list()):
bos_token = [tokenizer.bos_token_id]
eos_token = [tokenizer.eos_token_id]
sent = tokenizer.encode('<usr>' + question + '<sys>' + answer)
yield bos_token + sent + eos_tokendataset = tf.data.Dataset.from_generator(get_chat_data, output_types=tf.int32)dataset = dataset.padded_batch(batch_size=batch_size, padded_shapes=(136,), padding_values=tokenizer.pad_token_id)for batch in dataset:
print(batch)
breaktf.Tensor(
[[ 1 2 9349 ... 3 3 3]
[ 1 2 9020 ... 3 3 3]
[ 1 2 9085 ... 3 3 3]
...
[ 1 2 9815 ... 3 3 3]
[ 1 2 9815 ... 3 3 3]
[ 1 2 9815 ... 3 3 3]], shape=(8, 136), dtype=int32)tokenizer.decode(batch[0])</s><usr> 12시 땡!<sys> 하루가 또 가네요.</s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>print(batch[0])tf.Tensor(
[ 1 2 9349 7888 739 7318 376 4 12557 6824 9108 9028
7098 25856 1 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3], shape=(136,), dtype=int32)print(tokenizer.encode('</s><usr> 12시 땡!<sys> 하루가 또 가네요.</s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>'))[1, 2, 9349, 7888, 739, 7318, 376, 4, 12557, 6824, 9108, 9028, 7098, 25856, 1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3]adam = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08)steps = len(train_data) // batch_size + 1
print(steps)# 1478EPOCHS = 3
for epoch in range(EPOCHS):
epoch_loss = 0
for batch in tqdm.tqdm_notebook(dataset, total=steps):
with tf.GradientTape() as tape:
result = model(batch, labels=batch)
loss = result[0]
batch_loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, model.trainable_variables)
adam.apply_gradients(zip(grads, model.trainable_variables))
epoch_loss += batch_loss / steps
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, epoch_loss))
text = '오늘도 좋은 하루!'sent = '<usr>' + text + '<sys>'input_ids = [tokenizer.bos_token_id] + tokenizer.encode(sent)
input_ids = tf.convert_to_tensor([input_ids])output = model.generate(input_ids, max_length=50, early_stopping=True, eos_token_id=tokenizer.eos_token_id)decoded_sentence = tokenizer.decode(output[0].numpy().tolist())decoded_sentence.split('<sys> ')[1].replace('</s>', '')output = model.generate(input_ids, max_length=50, do_sample=True, top_k=10)
tokenizer.decode(output[0].numpy().tolist())def return_answer_by_chatbot(user_text):
sent = '<usr>' + user_text + '<sys>'
input_ids = [tokenizer.bos_token_id] + tokenizer.encode(sent)
input_ids = tf.convert_to_tensor([input_ids])
output = model.generate(input_ids, max_length=50, do_sample=True, top_k=20)
sentence = tokenizer.decode(output[0].numpy().tolist())
chatbot_response = sentence.split('<sys> ')[1].replace('</s>', '')
return chatbot_responsereturn_answer_by_chatbot('안녕! 반가워~')return_answer_by_chatbot('너는 누구야?')return_answer_by_chatbot('사랑해')return_answer_by_chatbot('나랑 영화보자')return_answer_by_chatbot('너무 심심한데 나랑 놀자')return_answer_by_chatbot('영화 해리포터 재밌어?')return_answer_by_chatbot('너 딥 러닝 잘해?')return_answer_by_chatbot('너 취했어?')return_answer_by_chatbot('커피 한 잔 할까?')
AI, Information and Communication, Electronics, Computer Science, Bio, Algorithms
안녕하세요. 글 잘 보았습니다!
궁금한 점이 생겨서 댓글 남깁니다.
저는 BERT를 공부하는 중에
/usr/local/lib/python3.10/dist-packages/huggingface_hub/utils/_token.py:88: UserWarning:
The secret
HF_TOKENdoes not exist in your Colab secrets.To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
warnings.warn(
해당 메시지가 떴는데, 이 메시지는 그냥 넘어가도 되는 걸까요?
편하실 때 답변 주시면 감사하겠습니다!
감사합니다 :)