
Section 01. 네트워크 개요
네트워크(Network)
네트워크 개요
- 네트워크는 송신자의 메시지를 수신자에게 전달하는 과정으로 한 지점에서 원하는 다른 지점까지 의미 있는 정보를 보다 정확하고 빠르게 상대방이 이해할 수 있도록 전송하는 것을 의미한다.
- 또한 메시지를 전송하거나 메시지를 받을 수 있는 것을 의마하며 사용자들이 스마트 폰(Smart Phone)이나 데스크톱 컴퓨터(DeskTop Computer) 등을 사용하여 인터넷(Internet)을 사용할 수 있는 것은 네트워크라는 것이 있어서 가능한 것이다.
- 네트워크는 유선의 케이블을 컴퓨터에 연결해서 사용할 수도 있고 케이블을 사용하지 않고 무선으로도 사용할 수 있다. 즉, 연결 형태에 따라서 유선 네트워크와 무선 네트워크로 분류할 수 있다.
거리 기반 네트워크의 종류
네트워크를 분류할 때 신호(Signal)가 전송되는 거리에 따라서 네트워크를 분류하는데 IEEE 802 위원회라는 표준화 기관에서 약 3m ~ 5m 거리까지 전송할 수 있는 네트워크를 PAN(Personal Area Network)이라고 정의했고, 약 50m 정도 전송할 수 있는 네트워크를 LAN(Local Area Network)으로 분류했다.
거리에 따른 네트워크 유형
PAN(Personal Area Network)
약 5m 이내의 인접 지역 간의 통신 방법
초 인접 지역 간의 통신 방법으로 거리가 짧은 특성을 가진다
짧은 거리로 인하여 보통은 유선보다는 무선의 WPAN이 많이 활용된다.
LAN(Local Area Network)
근거리 영역의 네트워크로서 동일한 지역(공장, 사무실) 내의 고속 전용회선을 연결하여 구성하는 통신망
단일 기관 소유의 네트워크로 50m 범위 이내 한정된 지역
Client Server와 Peer to Peer 모델
WAN보다 빠른 통신 속도
WAN(Wide Area Network)
광대역 네트워크망으로 서로 관련이 있는 LAN 사이에 연결하는 상호 연결망
LAN에 비해 선로 에러율이 높고, 전송 지연이 크다
WAN의 설계 시 전송 효율과 특성 고려
두 목적지 간을 최단 경로를 연결시켜주려는 라우팅 알고리즘이 중요
제한된 트래픽 조건 하에서 흐름 제어와 과도한 지연을 제거
MAN(Metropolitan Area Network)
LAN과 WAN의 중간 형태의 네트워크로 데이터, 음성, 영상 등을 지원하기 위해 개발
전송 매체 : 동출 케이블, 광케이블
DQDB(Distributed Quene Dual Bus)
데이터 전송(Data Transfer) 방식
무전기를 생각해본다. 무전기는 송신자와 수신자가 음성을 전송한다. 하지만 무전기는 한 사람이 말을 하고 있는 도중에 수신자는 말을 할 수 없다. 이렇게 동시에 데이터를 주고받을 수 없는 전송 방식을 반이중(Half Duplex) 방식이라고 한다. 또한 송신자는 보내기만 하고 받을 수 없는 데이터 전송 방식을 단방향(Simplex)이라고 한다.
데이터 전송 방식은 단방향, 반이중, 전이중으로 분류된다.
단방향 통신(Simplex)
데이터를 전송만 할 수 있고, 받을 수 없다.
반이중 통신(Half Duplex)
데이터를 송신하고 수신할 수는 있지만, 동시에 할 수는 없다.
전이중 통신(Full Deplex)
전이중 방식의 가장 대표적인 예가 바로 전화기이다. 전화기는 동시에 데이터를 주고받을 수 있다. 이런 방식을 전이중 통신(Full Duplex)라고 하며, 동시에 데이터를 송신 및 수신할 수 있는 통신 방식이다.
네트워크 토폴로지(Network Topology)
네트워크 토폴로지(통신망의 구조)
컴퓨터 네트워크의 요소들(링크, 노드 등을) 물리적으로 연결해 놓은 것, 또는 그 연결 방식이다.
정보 통신망의 구성이라는 것은 데이터 통신을 위해서 각각의 정보 단말장치(컴퓨터)를 어떤 형태로 연결할 것인가에 대한 것이다.
계층형(Tree) 토폴로지
트리 구조 형태로 정보 통신망을 구성하는 것으로 정보 단말 장치를 추가하여 용이한 구성이다.
장점
네트워크 관리가 쉽고 확장이 편리하다
네트워크의 신뢰도가 쉽다.
단점
특정 노드에 트래픽이 집중화되면 네트워크 속도가 빨라진다/
병목 현상이 발생할 수 있다.
버스형(Bus) 토폴로지
중앙의 통신 회선 하나에 여러 개의 정보 단말 장치가 연결된 구조로 근거리 통신망(LAN; Local Area Network)에서 사용하는 통신망 구성 방식이며, 버스의 끝에 터미네이터(Terminator)를 달아서 신호의 반사를 방지한다.
장점
설치 비용이 적고, 신뢰성이 우수하다
구조가 간단하다
버스에 노드 추가가 쉽다.
단점
전송되는 데이터가 많으면 네트워크 병목 현상이 발생한다.
장애 발생 시에 전체 네트워크 영향을 받는다.
성형(Star) 토폴리지
중앙에 있는 정보 단말 장치에 모두 연결된 구조로 항상 중앙의 정보 단말 장치를 통해서만 연결이 가능한 구조이다. 성형은 중앙의 정보 단말 장치에 에러가 발생하면 모든 통신이 불가능한 구조이다.
장점
고속의 네트워크에 적합하다
노드 추가가 쉽고 에러 탐지가 용이하다.
노드에 장애가 발생해도 네트워크는 사용이 가능하다
단점
중앙 노드에 장애가 발생하면 전체 네트워크를 사용할 수 없다.
설치 비용이 고가이고 노드가 증가하면 네트워크 복잡도가 올라간다.
링형(Ring) 토폴로지
인접해 있는 정보 단말 장치가 연결된 구조이다. 링형은 토큰링(Token Ring)에서 사용한다.
장점
노드의 수가 증가 되어도 데이터 손실이 없다
충돌이 발생하지 않는다
경제적인 네트워크 구성이 가능하다
단점
네트워크 구성의 변경이 어렵다
회선에 장애 발생 시 전체 네트워크를 사용할 수 없다
망형(Mesh) 토폴리지
모든 정보 단말 장치가 통신회선을 통해서 연결된 구조로 한쪽 통신회선에 에러가 발생해도 통신을 수행할 수 있는 구조이다. 망형은 국방 네트워크처럼 한 네트워크에 장애가 발생해도 네트워크를 계속 사용할 수 있는 안전한 네트워크에서 사용하지만 구축 시에 비용이 많이 발생하는 문제가 있다.
장점
완벽하게 이중화가 되어 있으므로, 장애 발생 시에 다른 경로를 통해서 네트워크를 사용할 수 있다.
많은 양의 데이터를 송수신할 수 있다.
단점
네트워크 구축 비용이 고가이다.
운영 비용이 고가이다.
회선 표현 및 패킷 교환
회선 교환(Circuit Switching)
회선 교환의 개념
정보통신망의 분류는 전화기와 인터넷을 생각하면 분명히 이해할 수 있다. 전화기는 전화번호를 전화기에 입력하면 신호가 간다. 신호는 전화를 받는 사람이 전화를 받을 때까지 계혹 울리고 만약 누군가와 통화 중이면 통화 중을 알려주며, 전화를 받으면 그 때부터 통화가 이루어지고 안정적으로 통화를 할 수 있다. 즉, 전화기는 발신자와 수신자 간에 회선을 독점하는 것으로 수신자가 전화를 받으면, 그 때부터 둘 사이의 독점적인 통화가 안정적으로 이루어진다.
이러한 통신 방식을 회선 교환이라고 한다.
QOS(Quality Of Service)
QOS란 네트워크 품질을 평가하는 지표를 의미하며, QoS가 가장 우수한 네트워크가 바로 회선 교환이다. 회선 교환은 한 번 연결이 이루어지면 안정적으로 통신을 할 수가 있다. 하지만 연결이 이루어진다는 것은 선로를 독점해서 사용한다는 의미라서 자원을 많이 사용하고 다중 통신이 어려운 문제점이다.
회선 교환은 포인트 투 포인트(Point to Point)방식으로 연결(Connection)을 확립하고 안정적으로 통신할 수 있는 방법이다.
회선 교환의 특징
교환기를 통해 통신 회선을 설정하여 직접 데이터를 교환하는 방식이다
직접 교환 방식으로 음성 전화 시스템에 활용된다
송신자의 메시지는 같은 경로로 전송된다
실시간으로 처리할 수 있고 안정적인 통신이 가능하다
포인트 투 포인트(Point to Point) 방식으로 사용된다.
대역폭(Banswidth)
데이터 통신에서 최고 주파수와 최저 주파수의 차이를 말한다
주파수의 상한과 하한의 차이로 헤르츠(Hz)라 표현한다.
대역폭이 크면 클수록 많은 데이터를 전송할 수 있다.
회선 교환의 장점과 단점
장점
대용량의 데이터를 고속으로 전송할 때 좋음
고장적인 대역폭(Bandwidth)을 사용
접속에는 긴 시간이 소요되나 접속 이후에는 접속 지연이 없으며 데이터 전송률이 일정함
아날로그나 디지털 데이터로 직접 전달
연속적인 전송에 적합
단점
회선 이용률 측면에서 비효율적이다.
연결된 두 장치는 반드시 같은 기종 사이에 송수신이 요구된다.(다양한 속도를 지닌 개체간 통신 제약)
속도나 코드의 변환이 불가능(교환망 내에서의 에러 제어 기능이 어렵다)_
실시간 전송보다 에러 없는 데이터 전송이 요구되는 구조에서는 부적합
통신 비용이 고가임
패킷 교환(Packet Switching)
패킷 교환의 개념
패킷 교환은 송신 측에서 모든 메시지를 일정한 크기의 패킷으로 분해해서 전송하고, 수신 측에서 이를 원래의 메시지로 조립하는 것이다.
인터넷을 사용하여 통신을 하려면 전화기에 전화번호와 같은 식별자가 필요한데 그것이 IP(Internet Protocol) 주소이다. 이러한 IP 주소를 할당하여 네트워크에 데이터를 보내면 IP 주소를 확인한 후에 데이터를 전송한다. 인터넷은 전화망과 다르게 경로를 독립적. 고정적으로 사용하지 않고 네트워크의 상태(속도, 대역폭)에 따라 다른 경로로 발송하게 된다. 이것은 마치 네비게이션과 같은 것으로, 즉 교통량의 정보를 확인하고 최적의 경로를 선택하는 방식으로 데이터를 보내는 것이 인터넷이다. 이처럼 인터넷은 전송하고자 하는 데이터에 IP 주소를 붙이는데 이렇게 IP 주소가 붙은 패킷을 데이터그램(Datagram)이라고 한다.
패킷(Packet)
네트워크를 사용해서 전송하기 위해서 일정한 단위로 나눈 데이터 전송 단위이다.
데이터 송신자와 수신자가 하나의 단위로 처리하는 데이터 처리 단위이다.
컴퓨터의 데이터를 최적의 경로를 전송하기 위해서는 경로를 결정하는 장비가 필요한데 그것이 바로 라우터(Router)이다.
패킷 교환망(Packet Switching Network)은 송신자가 전송할 데이터를 일정한 크기의 패킷(Packet)이라는 길이로 분류하여 데이터를 전송하면, 수신 측은 전송된 패킷을 다시 조립하여 원래의 메시지를 만든다.
패킷 교환은 전송할 패킷에 대해서 우선 순위가 같은 것을 표시해서 중요한 패킷을 식별할 수도 있게 한다. 패킷 교환 네트워크는 공중 교환 데이터망(Public Switched Data Network)이다.
패킷 교환의 특징
다중화 : 패킷을 여러 경로로 공유한다
채널 : 가상 회선 혹은 데이터그램 교환 채널을 이용
경로 선택 : 패킷마다 회적의 경로를 설정한다
순서 제어 : 패킷마다 최적의 경로로 보내지기 때문에 도착 순서가 다를 수 있다. 즉 패킷의 순서를 통제한다.
트래픽 제어 : 전송 속도 및 흐름을 제어
에러 제어 : 에러를 탐지하고 재전송한다.
패킷 교환의 장점과 단점
장점
회선 이용률이 높고, 속도 변환, 프로토콜 변환이 가능하며, 음성 통신이 가능하다
고 신뢰성 : (경로 선택, 전송 여부 판별 및 장애 유무 등) 상황에 따라 교환기 및 회선등의 장애가 발생하더라도 패킷의 우회 전송이 가능하므로 전송의 신뢰성이 보장된다.
고품질 : 디지털 전송이므로 인접 교환기 간 또는 단말기와 교환기 간에 전송 오류검사를 실시하여 오류 발생 시 재전송이 가능하다
고효율 : 다중화를 사용하므로 사용 효율이 좋다
이 기종 단말 장치 간 통신 : 전송 속도, 제어 절차가 다르더라도 교환망이 변환 처리를 제공하므로 통신이 가능하다
단점
경로에서의 각 교환기에서 다소의 지연이 발생한다
이러한 지연은 가변적이다. 즉 전송량이 증가함에 따라 지연이 더욱 심할 수 있다.
패킷별 헤더 추가로 인한 오버헤드 발생 가능성 존재
데이터그램과 가상 회선
데이터그램과 가상회선 동작 원리
데이터그램(Datagram) 네트워크는 패킷 교환 방식으로 동작하면서 IP 주소를 사용하는 인터넷을 의미한다. 가상회선은 앞에서 설명한 회선 교환 방식과 데이터그램 방식의 장점을 결합한 통신 기술로 가상회선은 처음 패킷으로 최적의 경로를 고정하고 경로가 고정되면 그 다음은 패킷으로 나누어 고속으로 전송하는 기술이다. 가상회선은 데이터그램보다 빠르고 안정적으로 통신할 수 있지만, 데이터그램 네트워크처럼 많은 사용자가 동시에 사용하기는 한계가 존재한다. 이러한 가상회선의 가장 대표적인 통신 기술이 ATM이다. ATM은 학교 내에서 고속의 네트워크를 서비스하기 위해서 사용된다. 즉, 특정 영역에서 사용하며 대중적으로 사용하는 데이터그램 네트워크(인터넷)보다는 공유(Share)에 한계가 있다.
가상회선과 데이터그램 차이점
가상회선(Virtual Circuit)
패킷을 전송하기 전에 논리적인 연결을 먼저 수행한다(제어패킷에 의한 연결형 서비스를 제공)
송신자는 호출을 하고 호출 수신 패킷을 주고받아서 연결하는 방식이다
회선 교환처럼 사용하지만, 교환기에 패킷이 일시적으로 저장하여 일정한 전송률 보장은 못한다
비교적 긴 메시지의 전송 시 더 효과적
이미 확립된 접속을 끝내기 위해서 Clear Request 패킷을 이용
데이터그램(Datagram)
각 전송패킷을 미리 정해진 경로 없이 독립적으로 처리하여 교환하는 방식
같은 목적지의 패킷도 같은 경로를 거치지 않고, 서로 다른 경로를 통해서 목적지에 도달하며 호 설정 단계의 회피가 가능하다
망의 한 부분이 혼잡할 때 전송 패킷에 다른 경로를 배정 가능, 융통성 있는 경로를 설정한다
특정 교환기의 고장 시 모든 패킷을 잃어버리는 가상회선 방식과는 달리, 그 경로를 피해서 전송할 수 있으므로 더욱 신뢰할 수 있다.
짧은 메시지의 패킷들을 전송할 때 효과적/재정렬 기능 필요하다
메시지 교환(Message Switching)
메시지 교환 개념
메시지 교환망(Message Switching Network)은 송신된 메시지를 중앙에서 축적하여 처리하는 방법으로 흔히 축적 교환 방식이라고 한다.
메시지를 메모리에 저장하고 여러 수신자에게 데이터를 전송할 수 있다.
전자 우편에서 사용된다.
축적 교환 방식
메시지 교환 방식은 축적 교환으로 동작한다. 축적 교환이라는 것은 송신자가 메시지를 전송하면 전송한 메시지를 일정한 단위로 나누어서 버퍼(Buffer)라는 것에 저장한 후에 저장이 완료되면 다시 그것을 읽어들여서 전송 경로를 결정하는 전송을 의미한다. 우리가 사용하는 인터넷도 축적 교환 방식으로 메시지를 전송한다.
메시지 교환 방식
메시지를 공유하여 데이터를 보낼 수 있다
메시지 별로 우선순위를 부여한다.
에러 제어가 제공한다
응답 속도가 느리다.
대화형 시스템으로 사용하기 어렵다
Section 02. 근거리 통신 기술
근거리 통신 개요
근거리 통신 개념
동일 건물이나 공장, 학교 구내 등 제한된 일정 지역 내에 분산 설치된 각종 정보기기들 사이에서 통신을 수행하기 위해 구성된 최적화되고 신뢰성 있는 고속의 통신 채널을 제공하는 것이 근거리 통신망이다. 근거리 통신망은 일반적으로 전송 거리가 약 50m 정도의 거리이다.
근거리 통신(LAN)의 특징
건물 내에서 데이터 통신을 위해 사용되고 공유 파일 서버, 프린터 공유 등을 위해서 사용된다.
이 기종 통신과 연결되어 데이터를 송수신할 수 있다.
10Mbps에서 100Mbps의 속도로 데이터를 전송한다.
멀티미디어 데이터를 전송할 수 있다.
채널(Channel)
채널은 데이터 통신을 위해서 통신 매체에서 제공하는 통로로 채널을 점유하여 통신이 이루어진다. 채널의 가장 쉬운 예은 TV 채널의 11번, 9번, 7번이 있다.
LAN(Local Area Network)의 주요 내용
자원 공유
원격지의 자원을 공유
복수의 사용자에게 독점적 사용권을 부여
사용자는 불편 없이 모든 자원을 효율적으로 사용
분산 처리
독립된 각 장비에서 계산과 작업을 처리
전체 시스템의 능력은 연결도니 모든 컴퓨터의 능력에 따라 결정
분산 제어
분산된 지역의 독립적인 장치 간의 통신을 통하여 프로세스를 제어
높은 데이터 전송 속도, 신뢰도 유지
정보 교환
Video 및 Voice 신호 전달
Text 데이터 전달
근거리 통신의 장점과 단점
근거리 통신(LAN)의 장점
전송되는 패킷 손실 및 지연이 적다
사용자 간에 쉽고 빠르게 자료(문서, 동영상 등)를 공유할 수 있다.
신뢰성이 높고 구축 비용이 적다
오류 발생률이 낮다
근거리 통신(LAN)의 단점
전송 거리가 짧아서 거리에 제약이 있다.
UTP 및 광케이블로 구축되지만, 네트워크에 노드가 많아지면 충돌이 발생하여 성능이 떨어진다.
근거리 통신에서 자원 공유
자원 공유 방법
근거리 통신에서 파일 공유 및 프린터 공유를 어떻게 하는지 알아본다. 공유를 원하는 폴더에서 마우스 오른쪽 버튼을 누르고 [속성]을 선택한다. [속성] 창이 나오면 [공유] 탭에서 [고급 공유] 버튼을 클릭한다.
자원공유 검색
공유를 완료하고 근거리 네트워크에서 정상적으로 공유되엇는지 확인하기 위해서 윈도의 net share 명령을 사용할 수 있다.
근거리 통신 프로토콜
ALOHA(Additive Links Online Hawaii Area)
ALOHA(Additive Links Online Hawaii Area)는 중앙국에 의한 제어 없이 무작위로 공통 전송 채널에 접속하는 경쟁 방식의 다원 접속 프로토콜이다.
송신측 : 전송할 패킷이 잆으면 언제든지 패킷을 송신한 뒤에 수신측으로부터 오는 확인 응답 신호를 기다린다.
수신측 : 패킷이 수신되면 패킷의 오류를 검사한 후 확인 신호를 송신측으로 보낸다.
송신측에서는 수신측으로부터 확인 신호가 도착하면 다음 패킷을 전송한다
패킷을 발송한 후 일정한 시간 내에 확인 신호가 들어오지 않으면 패킷이 손실된 것으로 인정하고 일정 시간 대기 후 재전송을 시도한다.
Slotted ALOHA
Slotted ALOHA는 중앙 제어국에서 보내 준 클럭 신호를 이용하여 모든 국들을 동기화시켜 패킷을 전송한다.
Slotted ALOHA는 패킷 충돌 확률을 감소시키고 성능을 개선했다.
ALOHA보다 전송 처리율이 2배이다.
주로 무선 LAN에서 사용한다.
CSMA/CD
CSMA/CD 및 CSMA/CD는 Slotted ALOHA의 방식이 발전된 형태로 전송을 바라는 스테이션이 전송 매체를 살펴서 다른 전송이 있는지를 조사하고, 상대 스테이션의 전송이 끝날 때까지 전송을 하지 않는다.
CSMA/CD(CSMA with Collision Detection) LAN
CSMA를 발전시킨 것으로 CSMA 방식에 충돌 감지를 빨리하고 충돌이 발생하면 즉시 검출하여 데이터 프레임의 송신을 중단하고 대기한 다음, 회선이 사용 중이 아닐 때 프레임을 재전송하는 방식이다.
CSMA/CD 동작 방식 : 충돌이 없는 경우
1. 전송을 원하는 호스트는 네으퉈크에 캐리어를 감지ㅐ 전송이 가능한지 검샇ㄴ다.
ex.
호스트 A는 호스트 D로 데이터 프레임을 전송
2.1. 호스트는 전송이 가능할 경우 전송을 시작한다.
2.2. 호스트 A에서 발생한 프레임은 공유 매체를 통하여 호스트 B,C,D로 Broadcast 된다.
2.3. 호스트 B,C는 목적지 IP 주소가 자기가 아니라는 걸 알면 바로 프레임을 폐기한다.
3.1. 호스트 D는 목적지가 자기라는 걸 알고 호스트 A에게 Unicast로 응답한다.
3.2. 하지만 Shared Device Hub 네트워크에서는 유니캐스트와 브로드캐스트의 차이가 없다.
CSMA/CD 동작 방식 : 충돌이 발생하는 경우
1. 전송을 원하는 호스트는 네트워크에 캐리어를 감지해 전송이 가능한지 검사한다.
ex.
호스트 A는 호스트 D로 데이터 프레임을 전송하고 호스트 B는 호스트 C로 데이터 프레임을 전송
- 호스트 A에서 발생한 프레임과 호스트 B에서 발생한 프레임은 공유 매체에서 Collision을 발생시킨다.
3.1. Collision이 발생되면 Jam Signal을 모든 호스트로 전송하여 Collision 발생에 대해서 알린다.
3.2. Jam Signal을 받은 호스트들은 일정한 시간 후에 다시 전송을 시작한다. 최대 15번까지 재전송한다.
IEEE 802 위원회의 LAN 표준안
IEEE 802 위원회는 LAN 관련 표준화를 수행하는 표준화 기관이다. 가장 대표적인 예가 무선 LAN 관련 표준인데, 무선 LAN은 모두 802.11로 시작한다. 그 이유는 IEEE 802 위원회가 무선 LAN을 위해서는 약 50m 전송 거리, 11Mbps 전송 속도 등을 요구사항으로 정의했기 때문이다. 이 조건을 만족하는 무선 LAN 표준들로는 IEEE 802.11b. IEEE 802.11a, IEEE 802.11g 등이 있으며 IEEE 802.11 요구사항은 좀 더 발전되어서 54Mbps, 100Mbps 등으로 변경되어 있다.
IEEE
1963년 설립된 미국전기전자기술협회로 전기학회 및 무선학회가 합병된 학회이다. LAN(Local Area Network) 표준을 정의하고 있다.
IEEE 802 위원회 LAN 표준
802.1 : 상위 계층 인터페이스와 MAC BRIDGE
802.2 : LLC(Logical Link Control)
802.3 : CSMA/CD(Carrier Sense Multiple Access/Collision Detection)
802.4 : 토큰버스(Token Bus)
802.5 : 토큰링(Token Ring)
802.6 : MAN(Metropolitan Area Network)
802.7 : 광대역(Broadband) LAN
802.8 : 광섬유(Fiber Optic) LAN
802.9 : 종합 데이터 & 음성 네트워크
802.10 : 보안(Security)
802.11 : 무선 네트워크(Wireless Network)
이더넷(Ethernet)
이더넷 개요
이더넷은 LAN(Local Area Network)를 위해 개발된 근거리 유선 네트워크 통신망 기술로 IEEE 802.3에 표준으로 정의되어 있다.
일반적으로 동축 케이블 또는 비차폐 연선을 사용하고 버스 형식을 방을 구성한다.
가장 보편적으로 시스템으로 10BASE-T, 100BASE-T 등이 있다.
이더넷 장점과 단점
이더넷의 장점
적은 용량의 데이터를 전송할 경우 성능이 우수하다
설치 비용이 저렴하고 관리가 쉽다
네트워크 구조가 간단하다
이더넷의 단점
네트워크 사용 시에 신호 때문에 충돌이 발생한다
충돌이 발생하면 네트워크에서 지연이 발생한다
시스템의 부하가 증가하면 충돌도 계속적으로 증가한다.
이더넷 표준
10Base - 5
동축 케이블로 500m의 길이를 가진다.
Thick 케이블이라고도 부르며, 2.5m 간격으로 트랜시버를 연결하여 사용
10Base - 2
Thin 케이블이라고도 부르며 200m의 길이를 가진다
10Base - T
UTP 케이블을 이용하는 것으로 현재 가장 많이 사용됨
100m의 길이를 가진다.
UTP 케이블(Cable)
UTP 케이블은 5개의 카테고리로 분류되며 유선 LAN을 연결한다.
UTP 케이블 카테고리(Category)
Category 1 : 전화 통신에 사용하며 데이터 전송에 적합하지 않는다.
Category 2 : UTP 연결 방식 중 하나로 최대 4Mbps 속도로 데이터 전송
Category 3 : 10Base-T 네트워크에 사용, 최대 10Mbps 데이터 전송
Category 4 : 토큰링 네트워크에서 사용, 최대 16Mbps로 데이터 전송
Category 5 : UTP 케이블 연결 방식, 최대 100Mbps로 데이터 전송
UTP 케이블의 배열
UTP 케이블에는 각 케이블의 배열 정보를 의미하는 케이블 타입이 기록되어 있다.
UTP 케이블은 카테고리 5를 사용하고 4쌍의 꼬임선으로 모두 8가닥으로 이루어진다.
케이블 배열에는 순서가 있는데 T568A 타입과 T568B이 있다. 만약 다이렉트 케이블을 연결할 때는 양쪽 모두 같은 타입을 사용하고 다른 타입을 사용할 때는 크로스 케이블로 한 쪽은 T568A를 사용하고 다른 한 쪽 T568B를 사용한다.
EIA-568A
1번
케이블 색 : 흰색 + 녹색
신호 : Tx+
2번
케이블 색 : 녹색
신호 : Tx-
3번
케이블 색 : 흰색 + 주황
신호 : Rx+
4번
케이블 색 : 파랑
신호 : 사용 안 함
5번
케이블 색 : 흰색 + 파랑
신호 : 사용 안 함
6번
케이블 색 : 주황
신호 : Rx-
7번
케이블 색 : 흰색 + 갈색
신호 : 사용 안 함
8번
케이블 색 : 갈색
신호 : 사용 안 함
EIA-568B
1번
케이블 색 : 흰색 + 주황
신호 : Tx+
2번
케이블 색 : 주황
신호 : Tx-
3번
케이블 색 : 흰색 + 녹색
신호 : Rx+
4번
케이블 색 : 파랑
신호 : 사용 안 함
5번
케이블 색 : 흰색 + 파랑
신호 : 사용 안 함
6번
케이블 색 : 녹색
신호 : Rx-
7번
케이블 색 : 흰색 + 갈색
신호 : 사용 안 함
8번
케이블 색 : 갈색
신호 : 사용 안 함
고속 이더넷(Fast Ethernet)
고속 이더넷 개요
IEEE 802.3에서 제안된 것으로 기존 이더넷에 비해서 전송 속도가 향상되었으며, 100Mbps로 데이터를 전송할 수 있다.
100Base-T로 이름으로 정의되었다. 여기서 100은 데이터 전송 속도를 의미한다.
100Base-T 옵션은 모두 IEEE 802.3 매체 접근 제어 프로토콜과 프레임 형식을 사용한다. 기존의 10Base-T 이더넷과 프레임과 포멧이 같고, 매체 접근 방식도 CSMA/CD로 동일하며 MAC(Media Access Protocol) 프로토콜 그대로 사용가능하다.
고속 이더넷의 특징
성형(Star) 네트워크 토폴리지를 사용한다
CSMA/CD 방식을 사용하여 기존 이더넷의 10Mbps보다 10배 향상된 100Mbps의 전송 속도를 갖는다.
케이블의 길이는 최대 100m로 제한(FDDI와는 다르게 적은 비용으로 고속의 LAN 환경 구축이 가능)되며 데이터 전송률을 100Mbps이다.
고속 이더넷(Fast Ethernet)은 표준 이더넷과의 호환성을 구축하였고 동일한 48비트 주소 체계와 동일한 프레임 형식을 유지하며 동일한 최소 프레임 길이 및 최대 프레임 길이를 유지한다.
프레임(Frame)
프레임은 전송하는 단위를 의미하고 동기화 신호, 시작 비트, 하드웨어 주소, 프레임 검사 비트 등을 포함한다.
기존 이더넷과 고속 이더넷 차이점
이더넷(Ethernet)
표준 : IEEE 802.3
속도 : 10Mbps
토폴로지 : 성형과 버스형
MAC 프로토콜 : UTP, Fiber
전이중 케이블 : 지원
다른 이름 : 10Base-T
고속 이더넷(Fast Ethernet)
표준 : IEEE 802.3
속도 : 100Mbps
토폴로지 : 성형
MAC 프로토콜 : UTP, Fiber, STP
전이중 케이블 : 지원
다른 이름 : 100Base-T
기가비트 이더넷(Gigabit Ethernet)
기가비트 이더넷 개요
1초에 1Gbps의 속도로 데이터를 전송할 수 있는 이더넷 표준 기술이다
100Base-X로 정의 되었다.
호환성이 좋아서 기존 이더넷과 호환된다.
1995년 후반, IEEE802.3 위원회는 이더넷 구성 형태에서 초당 기가비트의 속도로 패킷을 전달하기 위한 방법을 연구하기 위해 고속 연구 그룹을 결성하였다.
CSMA/CD 프로토콜과 10Mbps와 100Mbps의 기존 이더넷 형태를 유지하며 이더넷과 고속 이더넷의 관리 시스템 이용이 가능하다
기가비트 이더넷의 특징
성형(Star) 네트워크 토폴로지를 사용한다.
MAC 프로토콜로 CSMA/CD 방식을 사용한다.
고속 이더넷보다 고가이지만, 10배의 전송 속도를 가진다
케이블의 길이를 줄이고 전송 속도를 향상시킨다.
채널 용량 단위
bps(bit per second) : 초당 전송할 수 있는 비트 수이다
Kbps(Kilo bit per second) : 1000비트 단위로 초당 전송할 수 있는 비트 수이다
Mbps(Mega bit per second) : 100만 단위로 초당 전송할 수 있는 비트 수이다
Gbps(Giga bit per second) : 10억 단위로 초당 전송할 수 있는 비트 수이다
토큰패싱(Token Passing)
토큰패싱의 개요
토큰이라 제어 비트를 송신하고 해당 토큰을 확보해서 통신을 하는 방식이다
통신 회선에 대한 제어 신호가 논리적으로 형성된 링에서 각 노드 간을 옮겨가면서 데이터를 전송하는 방식이다.
링(Ring) 형태의 네트워크 토폴로지를 사용한다
충돌이 발생하지 않는다.
토큰패싱의 특징
가변 길이의 데이터 프레임 전송이 가능하다
하드웨어 장비가 복잡하고 평균 대기 시간이 높다
부하가 높을 때에는 안정감이 있고, 접근 시간이 대략적으로 일정한 값을 유지한다.
링형 토폴로지 통신망에서 통신 회선에 대한 제어 신호가 각 노드 간을 순차적으로 옮겨 가면서 데이터를 전송하는 방식이다.
특정한 비트 패턴으로 구성된 짧은 프레임 형태이다.
통신 회선의 길이가 무제한이다
확장성이 어렵다
고속 버스트 전송에 유리하다
토큰 패싱의 장점과 단점
장점 :
충돌이 발생하지 않는다
성능 저하가 적다
단점 :
설치 비용이 고가이고 복잡하다
노드가 많으면 성능이 떨어지다
토큰에 대한 분실이 발생할 수 있다.
Section 03. 데이터 통신
정보신호
아날로그 신호와 디지털 신호
정보신호(Information Signal)에는 아날로그 신호와 디지털 신호가 있다. 아날로그 신호는 연속적으로 변화하는 전자기파로서 간단하게 생각하면 사람의 음성 신호가 아날로그 신호이다. 음성은 소리에 높낮이가 있어서 유연한 곡선형 형태로 나타나며 이러한 아날로그 신호는 거리가 멀어지면 점점 감쇄하는 현상이 발생한다.
디지털 신호의 대표적인 예는 컴퓨터이다. 컴퓨터는 데이터를 표현할 때 오직 0 혹은 1로만 표현된다. 아날로그 신호에 비해서 잡음이 적고 오류율이 적은 장점이 있다.
신호 변환 방식
아날로그
아날로그 전송
증폭기를 이용하여 신호의 세기를 증폭(잡음까지 증폭됨 왜곡 심함)
신호 변환기 : 전화기
디지털 전송
코덱을 사용
디지털 전송을 하기에 원음만을 재생
왜곡 현상 방지 : 패턴 재생을 통해 신호 재전송 역할
신호 변환기 : PCM
디지털 신호
아날로그 전송
모뎀을 사용(아날로그 통신망을 이용하여 디지털 신호 전송)
신호 변환기 : 모뎀
디지털 전송
DSU를 사용
적당한 간격으로 리피터를 설치
신호 변환기 : DSU
아날로그 신호를 아날로그 전달하는 대표적인 방식은 전화기이다. 전화기는 음성을 아날로그 신호를 전송한다. 그럼 아날로그 신호를 디지털로 변환해서 전송하는 것이 무엇일까 컴퓨터를 사용해서 목소리를 녹음한다면 바로 그것이 아날로그를 디지털로 전송하는 것이다. 아날로그를 디지털로 전송하려면 정보신호를 변환해야 하느느데 이렇게 아날로그 그리고 디지털 신호를 디지털로 전송할 때는 디지털 신호를 안정적이고 멀리 보내기 위해서 신호를 변환해야 하는데 그것을 DSU(Digital Service Unit)라고 한다.
디지털 신호의 장점과 아날로그 신호의 단점
디지털 신호의 장점
저렴한 비용
데이터 무결성의 보장
전송 용량의 이용 확대
데이터 안정성 증대(암호화 작업 가능)
정보의 종합
아날로그 신호의 단점
유지보수 비용 증가
잡음 증폭도 높음
정보 전송 방식
정보 전송 부호화
정보 전송 부호화
정보 전송 부호(Transmission Code)는 데이터 전송이 단순한 전기적 신호만으로 이루어지는 것이 아니라 송신자와 수신자 상호 간에 규정된 데이터 형태를 약속하는 것이다.
전송 부호에는 2진 부호, ASCII Code, EBCDIC Code 등이 존재한다. 2진 부호는 정보 전송을 두 가지 상태(0 혹은 1)로 표현하는 데이터인 비트(Bit)로 송신하는 것이다. ASCII Code는 7개의 정보 비트와 1개의 패리티(Parity) 비트로 구성해서 에러를 검사하는 기능을 가진다. ASCII Code는 128개의 문자를 표현할 수 있다.
EBCDIC Code는 다양한 문자, 숫자, 기호 등을 전송하기 위해서 정보 비트가 8비트로 구성된 문자 코드를 지원한다. EBCDIC Code는 기존 BCD Code(64개를 표현)를 확장해서 256개의 문자를 표현할 수 있다.
부호화 종류
2진 부호 : 0혹은 1의 비트로 데이터를 전송
BCD Code : 64개의 64가지 정보를 표현
ASCII Code : 7비트로 128의 128개의 정보를 표현
EBCDIC Code : 8비트로 256의 256개의 정보를 표현
직렬 전송과 병렬 전송
직렬 전송과 병렬 전송 개요
직렬 전송은 하나의 전송로를 사용해서 데이터를 순차적으로 송신하는 방식이다. 직렬 전송은 회선이 적고 전송 비용이 적은 장점을 가지고 있다.
병렬 전송은 여러 개의 전송로로 데이터를 동시에 전송하는 방식으로 회선이 많이 필요하고 전송 비용이 비교적 많이 발생한다. 하지만 전송 속도가 빠른 장점이 있다.
직렬 전송과 병렬 전송의 차이점
직렬 전송
개념 :
한 문자의 비트를 하나의 전송선로를 통해서 순차적으로 전송
특징 : 동기식 전송 방식
장점 :
전송 에러가 적다
장거리 전송
통신 회선 비용이 저렴
단점 :
전송 속도가 느리다
병렬 전송
개념 :
한 문자의 비트들을 각자의 전송로를 통해서 한꺼번에 전송
특징 : 송수신기가 단수
장점 :
데이터를 빠르게 전송
단점 :
에러 발생 가능성이 높다
비동기식 전송과 동기식 전송
비동기식 전송과 동기식 전송 개요
비동기식 전송은 한 문자 단위로 데이터를 전송하는 방식으로 문자를 전송할 때 스타트 비트(Start Bit)와 스톱 비트(Stop Bit)를 사용해서 데이터를 전송한다. 전송하는 문자들 사이에는 유휴 시간이 존재한다
동기식 전송은 문자를 블록 단위로 빠르게 전송하는 방식으로 많은 양의 데이터를 전송할 수 있는 장점을 가지고 있고 무자 동기방식과 비트 동기방식으로 구분된다.
비동기식 전송과 동기식 전송의 차이점
비동기식 전송
개념 :
한 번에 한 문자씩 전송
한 문자 전송마다 동기화 수행
전송 단위 :
문자 단위의 비트 블록
전송 속도 : 저속
전송 효율 : 낮음
장점 : 동기화가 단순하며 저렴
단점 : 문자 사이에 유휴 시간 발생
동기식 전송
개념 :
데이터를 블록으로 나누어 블록 단위로 전송
전송 단위 : 프레임
전송 속도 : 고속
전송 효율 : 높음
장점 : 원거리 전송에 용이
단점 : 고가
데이터 통신 방식
교환 회선과 전용 회선
정보 전송 회선은 전송하기 위한 매체를 의미한다. 이러한 회선 중 교환기를 사용해서 데이터를 전환하는 것을 교환 회선이라고 하고 교환기를 사용하지 않고 정보 수신자 간에 직접 전달하는 것을 전용 회선 방식이라고 한다.
교환 회선
정보 전송 시에 교환기를 사용해서 송수신
회선 교환 및 축적 교환으로 나누어진다
데이터 양이 적으며 사용자가 많을 때 사용하는 방식
전용 회선
교환기를 사용하지 않고 점 대 점(일대일)으로 직접적으로 통신을 수행
사용자는 적지만 전송할 데이터가 많을 때 사용하는 방식
Point to Point와 Multi Point 개요
송신자와 수신자 간에 데이터를 전송할 때 송신자 한 명이 한 명의 수신자에게 전송하는 방식과 한 명의 송신자가 여러 명의 수신자에게 데이터를 전송하는 방식이 존재한다. 이러한 방식을 Point to Point 방식과 Multi Point 방식이라고 한다.
Point to Point(포인트 투 포인트) 방식
송신자는 하나의 통신 회선을 통해서 1대 1로 연결하여 데이터를 전송한다. 즉 전용 회선을 사용해서 데이터를 보내기 때문에 안정적이고 빠르게 데이터를 전송할 수 있는 장점을 가지고 있다.
Multi Point(멀티 포인트) 방식
한 개의 회선을 통해서 여러 명의 사용자에게 데이터를 전송하는 방식이다. 한 개의 회선을 사용하기 때문에 어느 순간에 어느 수신자에게 데이터를 보낼지 결정해야 하는데 이것을 위해서 폴링(Polling)과 셀렉션(Selection) 방식이 존재한다.
폴링은 전송 회선에 전송할 데이터가 있는지 주기적으로 검사하는 방법이고 셀렉션 방식은 수신자가 받을 준비가 되어 있는지 확인하는 방법이다.
Point to Point와 Multi Point의 회선 제어 기법
Point to Point 방식의 회선 제어 기법인 컨벤션(Contention)
송신자와 수신자가 한번 연결되면 독점적으로 사용하는 방법이다
송신 요구를 누가 먼저 했는지에 따라 회선 사용권이 결정된다.
Multi Point 방식의 회선 제어 기법인 폴링과 셀렉션 방식
폴링(Polling)
송신자 단말기에서 전송할 데이터가 있는지를 물어 전송할 데이터가 있으면 전송을 허가하는 방법
셀렉션(Selection)
수신자의 단말기가 데이터를 수신 받을 준비가 되어 있는지 물어보고 준비가 되어 있으면 송신자가 데이터를 전송하는 방법
회선 제어 단계
회선 연결 : 물리적으로 송신자와 수신자의 회선을 연결
링크 확랍 : 송신자와 수신자가 데이터 전송이 가능한지 확인
메시지 전송 : 송신자가 수신자에게 데이터를 전송
링크 단절 : 송신자와 수신자의 링크를 단절
회선 절단 : 물리적인 회선을 절단하고 종료
전송 매체
전송 선로는 실제 데이터를 보내기 위해서 보내는 물리적인 선로로 유선과 무선으로 구분할 수 있다.
유선 선로
트위스티드 페어 케이블(Twisted Pair Cable)
트위스티드 페어는 2개의 구리 선이 서로 감싸 있는 것으로 전화선으로 많이 사용되는 케이블이다
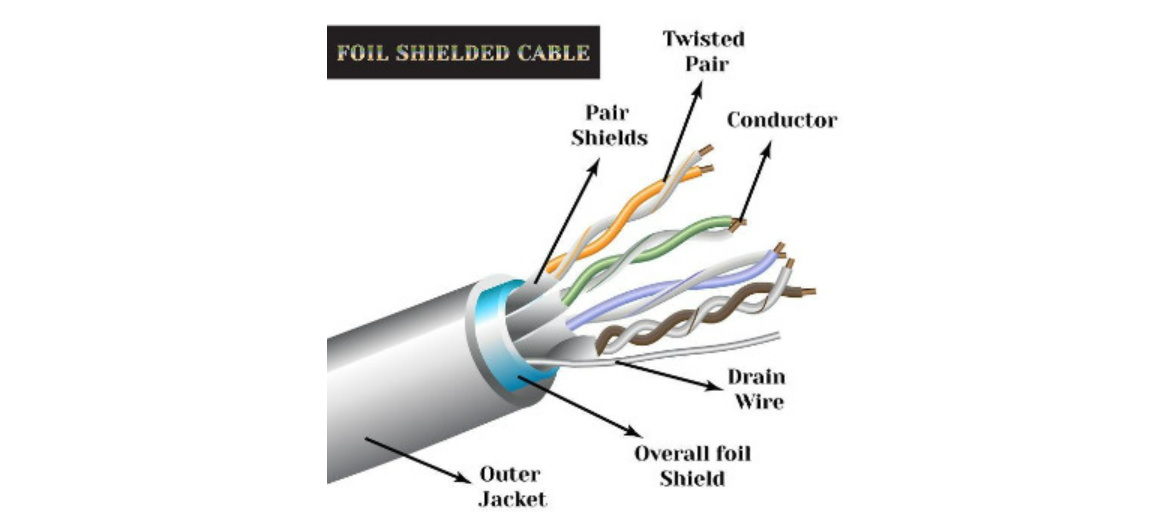
동축 케이블(Coaxial Cable)
중앙의 구리선에 플라스틱 절연체로 감싸서 만든 것으로 보통 가정에서 TV를 수신할 때 많이 사용되는 케이블이다.

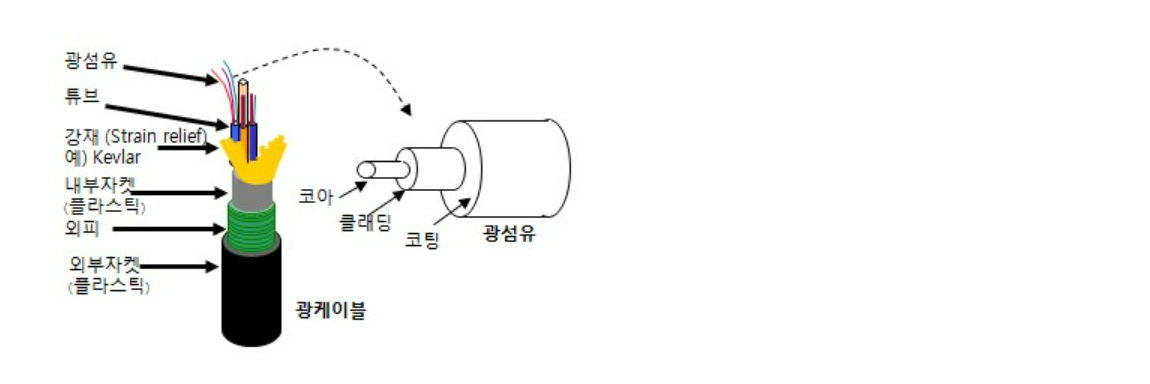
광섬유 케이블(Optical Fiber Cable)
빛의 전반사 현상을 이용하여 데이터를 전송할 수 있는 케이블로 신뢰성이 높고 온도 변화에도 안정적이고 에러율이 낮다.
물리적 케이블 간의 차이점
트위스티드 페어 케이블
구성이 용이하고, 비용이 저렴하나 혼선, 감쇠, 도청이 쉽다.
동축 케이블
동축 케이블, 구리선 사용한다
광섬유 케이블
빛에 의한 데이터 전송, 감쇠에 영향을 받지 않음 도청에 강하다
단점 : 높은 비용, 설치가 어렵다.
전송 에러
노이즈(Noise)
전송 시스템에 의해 생긴 다소의 왜곡을 포함한 전송 신호 및 송수신 과정에서 추가된 불필요한 신호
주변의 모니터, 형광등, 전자레인지 등 회선이 설치된 환경 특성에서 유발
감쇠(Alternuation)
데이터가 회선을 통하여 전송되는 도중 전기적 신호가 약해지는 현상
혼선(Crosstalk)
서로 다른 전송로에 상이한 전송 신호가 전기적 결합에 의해 다른 회선에 영향을 주는 현상으로 통신 품질을 저하시키는 직접적이 요인
변조
변조
변조(Modulation)는 아날로그 혹은 디지털로 부호화된 신호를 전송 매체에 전송할 수 있도록 주파수 및 대역폭을 갖는 신호를 생성하는 일련의 과정이다. 부호화(Encoding)는 신호를 현재 정보나 다른 형태로 변환하는 것이다.
변조 방식
디지털 신호를 아날로그 신호로 변조하는 방식은 진폭 편이 변조, 주파수 편이 변조, 위상 편이 변조 방식이 존재한다.
아날로그 변조
아날로그를 아날로그 신호를 변조하는 것으로 진폭 변조(AM : Amplitude Modulation), 주파수 변조(FM : Frequency Modulation), 위상 변조(PM : Phase Modulation) 등의 방법이 있다.
주파수 변조(FM : Frequency Modulation)
반송파의 기준 주파수를 중심으로 하여 정보 신호의 변화에 비례하여 변화시킨 것으로 이는 변조된 신호의 주파수 대역은 넓어지지만 잡음에 강하여 FM 방송, 저속 데이터 전송용 모뎀 등을 이용한다.
위상 변조(PM : Phase Modulation)
반송파의 위상을 정보 신호의 변화에 비례하여 변화시킨 것으로 디지털 전송용 모뎀, 디지털 무선 전송 등에 사용함
디지털 변조
디지털 신호를 아날로그 신호로 변조 하는 것으로 진폭 편이 변조(ASK : Amplitude Shift Keying), 주파수 편이 변조(FSK : Frequency Shift Keying), 위상 편이 변조(PSK : Phase Shift Keying)등이 있다.
진폭 편이 변조(ASK : Amplitude Shift Keying)
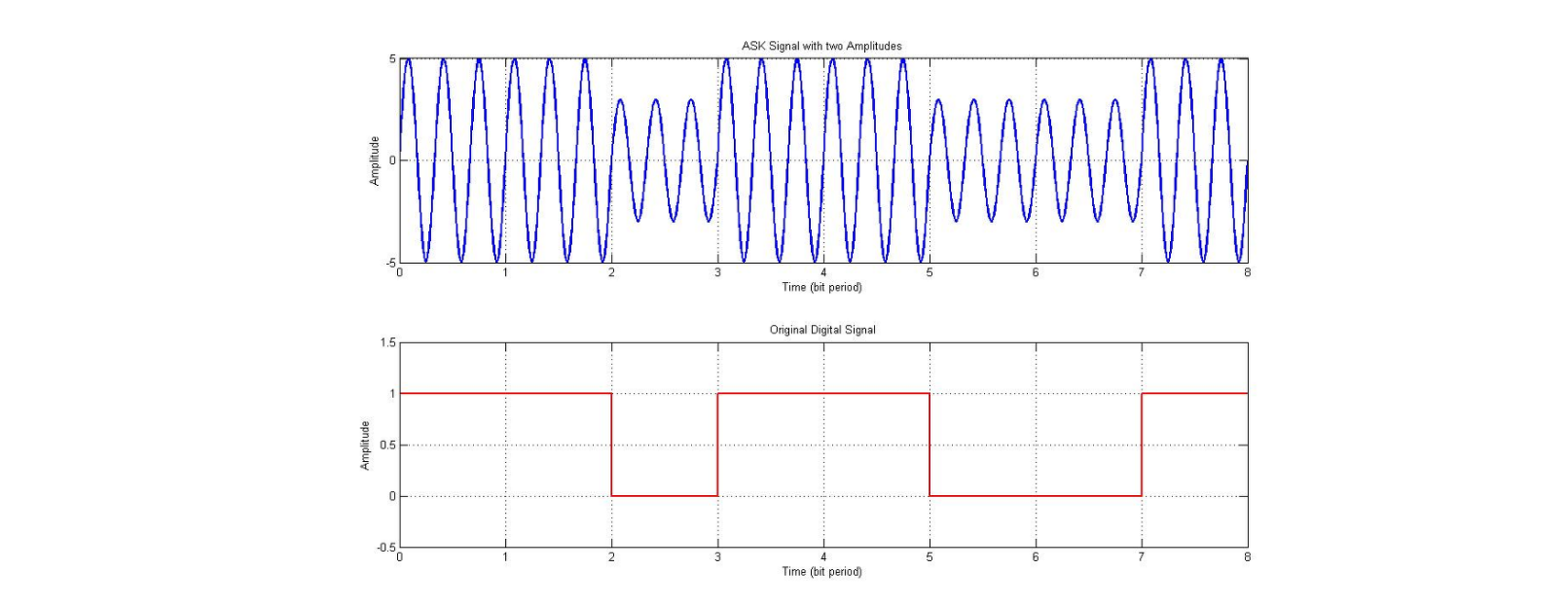
2진수 0과 ㅂ에 서로 다른 진폭을 적용하여 신호를 변조하는 방법으로 광섬유로 디지털 데이터를 전송하는데 사용된다.
장점 : 회로가 간단하고 가격이 저렴한다
단점 : 잡음이나 신호의 변동에 약하고 비효율적인 방법이라 데이터 전송용으로 거의 사용 안 한다.
주파수 편이 변조(FSK : Frequency Shift Keying)
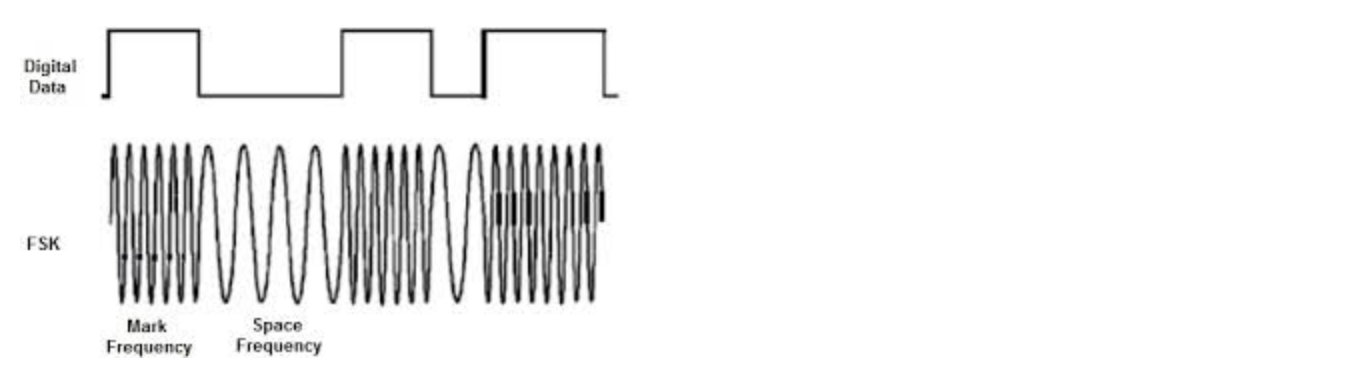
0과 1에 서로 다른 주파수를 사용하여 변조하는 것으로 주로 저속의 비동기 전송에서 많이 사용된다.
ASK보다 에러에 강하고 비교적 회로가 간단하다.
위상 편이 변조(PSK : Phase Shift Keying)
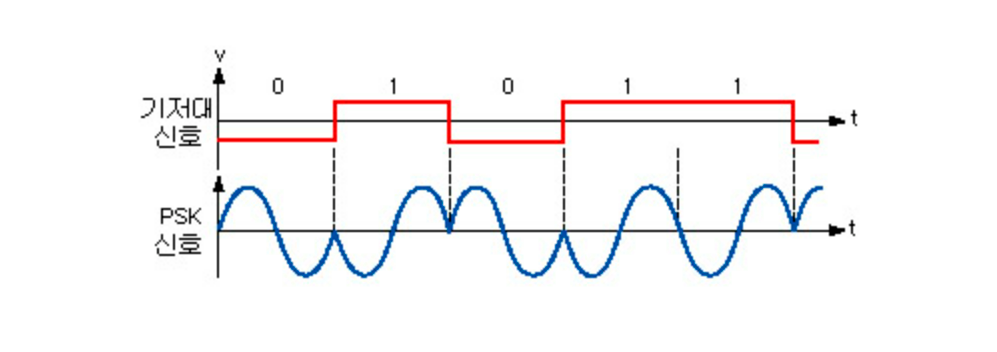
0과 1에 서로 다른 위상을 적용하여 변조하는 것으로, 종속, 고속 동기 전송에서 많이 사용되는 변조 방식이다. 위상 편이 변조는 주로 모뎀에서 사용된다.
장점 : 위상을 달리함으로써 복잡도가 높은 데이터 전송률이 높아진다.
직교 진폭 변조(QAM : Quadrature Amplitude Modulation)
같은 주파수로 위상이 90도 다른 2개의 파를 사용하고 각각을 진폭 변조하여 조합한 것, 즉 진폭 변조(AM)와 위상 변조(PM) 방법을 조합한 것으로, 고속 디지털 신호를 가능한 한 좁은 주파수 대역으로 전송하는 데 적합하여 고속 모뎀, 고속 디지털 무선 전송 등에 사용함
베이스밴드(Baseband)와 브로드밴드(Broadband)
베이스밴드(Baseband)
디지털 신호를 변조하지 않고 그대로 전송하는 방식으로 데이터 전송 품질이 우수하다. 변조를 하지 않기 때문에 별도의 모뎀이 필요 없고, 근거리 전송에 많이 사용된다.
베이스밴드의 장점
네트워크 운영 비용이 아주 저렴하며, 전이중 방식인 양방향 전송이 가능하다
네트워크 구성이 간단해서 근거리 통신에 많이 사용된다.
베이스밴드의 단점
장거리 전송을 하려면 추가적으로 리피터라는 장치가 필요하기 때문에 장거리 전송에는 부적합하다
통신 잡음에 쉽게 변형되어서 손실이 크다
브로드밴드(Broadband)
디지털 신호를 여러 개의 신호를 변조해서 다른 주파수 대역으로 동시에 전송하는 방식이다. 동시에 전송하기 때문에 하나의 통신선로에 여러 개의 채널을 사용해서 동시에 전송한다. 브로드밴드 장거리 전송에 사용된다.
브로드밴드의 장점
장거리 전송에 효율적이고 비용이 저렴하며 잡음에 의한 신호 감소가 적다
다중채널을 사용해서 음성, 영상 등을 전송한다.
브로드밴드의 단점
회로가 매우 복잡하기 떄문에 설치 및 관리가 어렵다
베이스밴드보다 속도가 느리다
단방향 전송이다.
베이스밴드와 브로드밴드 차이점
베이스밴드(Baseband)
종류 : 디지털
거리 : 근거리
채널 : 단일채널
방식 : 양방향
용도 : 데이터 전송
변복조 : 없음
다중화 : 시분할 다중화
브로드밴드(Broadband)
종류 : 아날로그
거리 : 장거리
채널 : 다중채널
방식 : 단방향
용도 : 음성, 영상, 데이터
변복조 : 필요함
다중화 : 주파수 분할 다중화
PCM(Pulse Code Modulation)
PCM 변조 개요
아날로그 신호를 디지털 신호로 변조하는 것으로 아날로그 신호를 펄스로 변환하여 전송하고 수신 측에서 이를 다시 아날로그 신호로 환원하는 방법이다. PCM 방식은 고품질의 정보와 다양한 형태의 서비스가 가능하다.
PCM 변조 과정
표본화(Sampling) : 아날로그 파형을 연속적인 시간 폭으로 나누어 작은 간격의 직사각형으로 시분할하여 신호를 만든다.
양자화(Quantization) : 표본화된 신호의 진폭은 일정한 값이 아니라서 수량화를 수행하는 결과
부호화(Encoding) : 양자화된 진폭 값을 2진법으로 나타낼 수 있어서 아날로그 신호를 디지털 신호로 변환한다.
복호화(Decoding) : 디지털 신호를 펄스 신호로 변환한다
여과(Filtering) : 본래의 아날로그 신호로 변환한다.
PCM 방식은 전송 레벨의 변동이 없고, 잡음에 강하며 펄스 코드를 이용한 변조 방식과 다중화가 용이한 장점이 있다. 하지만 점유 주파수 대역폭이 큰 단점이 있다.
다중화(Multiplexing)
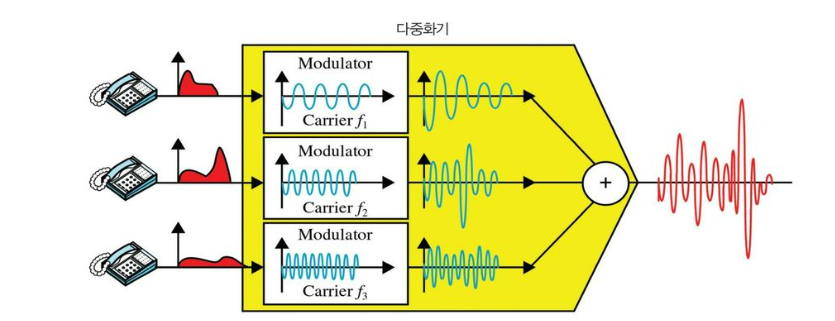
다중화(Multiplexing)
다중화 개요
다중화(Multiplexing)는 여러 단말장치의 신호를 하나의 통신회선을 통해서 송신하고 수신 측에서 여러 단말 장치의 신호를 분리하여 입출력할 수 있는 방식이다.
다중화는 하나의 통신회선을 사용하기 때문에 회선과 모뎀을 절약할 수 있는 방법이다.
다중화의 종류
주파수 분할 다중화, 시분할 다중화, 역다중화, 파장 분할 다중화
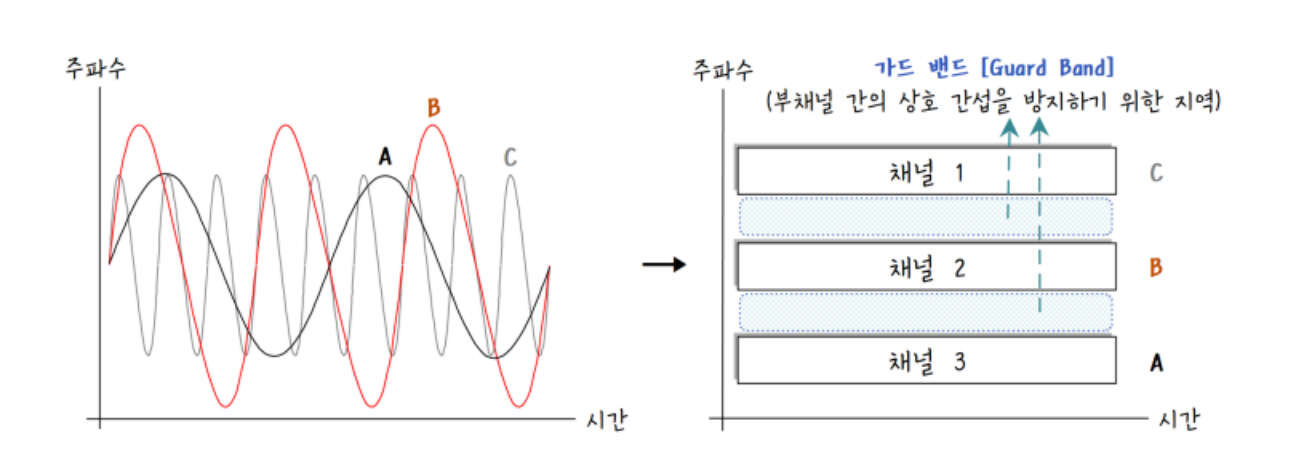
주파수 분할 다중화(FDM : Frequency Division Multiplexing)
좁은 주파수 대역을 사용하는 여러 개의 신호를 넓은 주파수 대역을 가진 하나의 전송로를 사용해서 전송되는 방식이다. 통신 채널이 제한된 주파수 대역을 여러 개의 독립된 저속 채널의 집단으로 분리한다.
사용자는 채널을 점유하여 데이터 통신을 수행한다. 보호대역은 채널 간의 완충 지역으로 불필요하게 대역폭을 낭비하게 된다.
시분할 다중화(TDM : Time Division Multiplexing)
전송회선의 데이터 전송 시간을 타입슬롯(Time slot)이라는 일정한 시간 폭으로 나누어서 일정한 크기의 데이터를 채널 별로 전송하는 방법이다. 고속 전송이 가능하고 포인트 투 포인트(Point to Point) 방식에 주로 사용되며 동기식 시분할 다중화와 비동기식 시분할 다중화 방식이 있다.
역다중화(Demultiplexing)
하나의 신호를 2개의 저속 신호로 나누어서 전송하며 하나의 채널이 고장이 발생해도 50%의 속도로 계속적으로 사용할 수 있는 장점을 가지고 있다. 두 개의 음성 회선을 사용해서 광대역 통신 속도를 얻을 수 있는 장치이다.
파장 분할 다중화(WDM : Wavelength Division Multiplexing)
광섬유를 사용해서 하나의 선로에 8개 이상의 신호를 중첩해서 전송할 수 있는 기술이다.
집중화기(Concentrator)
집중화기 개요
여러 개의 입력 회선을 n개의 출력 회선으로 집중화하는 장치로 입력 회선의 수는 출력 회선의 수보다 같거나 많다. 즉, 집중화기는 하나의 고속 통신회선에 여러 개의 저속 통신 회선을 접속하기 위해서 사용된다.
집중화기 특징
- 고속회선을 사용할 수 있게 해준다.
- 동적인 시간을 할당한다
- 입출력 각각의 대역폭이 다르다
- 구조가 복잡하고 불규칙한 전송에 사용한다.
Section 04. 광대역 기술
프레임 릴레이(Frame Relay)
프레임 릴레이 개요
플레임 릴레이(Frame Relay)는 멀티 엑세스를 위한 네트워크로 LAN과 비슷하게 두 개 이상의 장비를 네트워크에 동시에 연결하여 X.25의 패킷 전송 기술을 고속 데이터 통신에 적합하도록 개선한 프로토콜이다.
X.25.
X.25는 네트워크 선로가 좋지 않았을 때 개발된 네트워크로서 많은 에러 처리 기능을 포함하고 있다.
X.25는 에러 처리 때문에 통신에서 오버헤드가 높다
프레임 릴레이는 네트워크 선로가 좋은 환경에서 등장한 것으로 X.25.의 에러 처리를 단순화하여 오버헤드를 감소히켰다.
프레임 릴레이(Frame Relay)의 특징
상위 계층에서 오류를 복구하고 재전송한다.
경로 설정이 가능하다
데이터의 전송 속도를 향상시켜 전송 지연을 감소한다.
망 내부 기능을 단순화한다.
하나의 물리적 링크에 복수의 논리적인 가상 회선을 설정한다.
망과 단말 사이의 PCV(Permanenet Virtual Circuit)마다 DLCI(Data Link Connection Identifier)를 설정한다.
단순한 데이터 처리 절차만을 규정한다.
프레임 릴레이 구조
프레임 릴레이(Frame Relay) 기본 프로토콜 구조

Flag는 모든 프레임의 시작과 끝에 위치하여 프레임을 구분하며, FCS는 프레임의 에러를 검색하여 에러가 발생한 프레임은 제거된다.
프레임 릴레이(Frame Relay) 제어 프로토콜 구조

제어부가 존재하여 에러 제어 및 흐름 제어 기능을 수행한다.
HDLC(High-Level Data Link Control)
HDLC 개요
HDLC(High-Level Data Link Control)는 전이중(Full Duplex)과 반이중(Half Duplex) 통신 모두를 지원하는 비트 지향(Bit-oriented) 프로토콜로 점 대 점 링크 및 멀티 포인트(Multi Point) 링크를 위하여 ISO에서 개발된 국제 표준 프로토콜이다
HDLC의 특징
반이중 및 전이중 통신을 지원한다
동기식 전송 방식이다.
오류 제어를 위해 Go-back-N ARQ 및 선택적 재전송 ARQ(Automatic Repeat Request) 방식을 사용한다.
흐름 제어를 위해 슬라이딩 윈도우 방식을 사용한다.
프레임 내에 제어 정보인 명령과 응답을 이용하여 연속적인 정보를 전송하는 제어 절차이다.
명령은 상대방에 대한 데이터 링크의 설정, 데이터 전송, 종료 지시이며, 응답은 명령에 대한 실행 결과이다.
사용하는 문자 코드와 상관이 없으며 비트 삽입에 의해 투명한 데이터의 전송을 보장한다.
HDLC 프레임
HDLC 프레임 구조

HDLC 프레임 종류
정보 프레임(Information Frame) : 사용자 데이터 전달
감독 프레임(Supervisor Frame) : 흐름 및 에러 제어
무번호 프레임(Unnumbered Frame) : 회선 설정, 유지, 종결
HDLC 프레임 구조
플래그 필드
프레임 양 끝의 범위를 정한다
01111110
끝과 시작을 나타내는 플래그로 하나씩 지운다
수신기는 프레임 시작을 동기화하기 위해 계속적으로 플래그 조사
주소 필드
프레임을 송수신하는 부 스테이션을 식별
일반적으로 8비트 사용
7비트의 배수 확장 사용 가능
11111111은 모든 부 스테이션에 방송
제어 필드
형식이 다른 프레임을 정의
정보(Information) : 사용자를 위한 데이터 전송
감독(Supervisor) : 피기백이 사용되지 않은 ARQ
번호없는(Unnumbered) : 보조 링크 제어 기능
첫 번째의 한 비트 혹은 두 비트가 종류 식별
정보 필드
정보 프레임과 번호 없는 프레임에 존재
8비트의 배수로 사용
가변적인 길이
FCS(Frame Check Sequence)
에러 검출
16비트 CRC
선택적으로 32비트 CRC를 사용
ATM(Asynchronous Transfer Mode)
ATM 개요
ATM(Asynchronous Transfer Mode)은 가상회선을 사용하는 비동기 통신기술로 첫 번째 패킷이 전송될 때 송신자와 수신자 간에 최적의 전송 경로를 확정시킨다. 전송 경로가 확정되면 두 번째 패킷부터는 포워딩(Forwarding)만 수행하기 때문에 전송 속도가 빠르다.
즉, 인터넷은 패킷이 전송될 때마다 최적의 경로를 계산하고 데이터를 전송하는 포워드를 수행하지만, ATM은 한번만 경로를 결정하면 메시지는 포워드만 하기 때문에 안정적으로 빠르게 데이터를 전송할 수 있다. 결론적으로 회선 교환 네트워크와 패킷 교환 네트워크의 장점을 결합한 것이다.
ATM의 특징
고속으로 안정적 통신이 가능하다
비동기 전송 모드를 사용한다
음성, 영상과 같은 멀티미디어 전송과 데이터 전송이 가능하다
IP 헤더를 사용하지 않고 53바티으의 고정길이 셀(Cell)이라는 ATM 전용 헤더를 사용한다
가상 경로 설정과 연결형 모드로 빠른 데이터 전송이 가능하다
셀 전송 시에 우선 순위 기능을 부여하여 네트워크 품질을 향상시킨다.
ATM과 인터넷의 차이점
ATM
헤더 : 53바이트 셀(Cell)
경로 설정 : 한 번만 경로를 결정
데이터 : 음성, 영상, 데이터
공유 : 제한적 사용자
교환 방식 : 가상회선
QoS : 우수
인터넷
헤더 : IP 헤더
경로 설정 : 전송되는 패킷마다 경로 설정
데이터 : 음성, 영상, 데이터
공유 : 공유가 우수한 네트워크
교환 방식 : 패킷 교환
QoS : 낮음
PART 02. TCP/IP
Section 01. OSI 7 계층
프로토콜
프로토콜의 개요
데이터 송신자와 수신자 사이에 통신을 하기 위해서 서로 간에 약속이 필요하다. 즉, 어떻게 데이터를 보낼 것이고 데이터 포맷은 어떻게 할 것이고, 등에 대한 전반적인 약속이 필요한 것이다. 프로토콜은 이처럼 통신망에서 통신을 원하는 양측 시스템에 데이터를 주고 받기 위해 미리 약속된 운영상의 통신 규약이다. 즉, 데이터 통신 수행 규칙들의 집합이다.
프로토콜의 구성요소
프로토콜은 송신자와 수신자 간에 데이터 통신을 위해서 서로 간의 규약을 의미한다. 이러한 규약은 송신자와 수신자 간에 구문, 의미, 순서를 규약한다.
구문(Syntax) : 데이터 형식, 신호 레벨, 부호화
의미(Semantics) : 개체의 조정, 에러 제어 정보
순서(Timing) : 순서 제어, 통신 속도 제어
데이터 전송 방식
송신자와 수신자 간에 데이터를 전송하는 것은 비트 단위로 데이터를 전송하는 방법과 바이트 단위 전송 방법, 문자 단위 전송 방법이 존재한다.
비트 단위 전송 데이터를 전송할 때 특수 플래그를 포함시켜 데이터를 전송하는 방법으로 SDLC(Synchronous Data Link Control) 프로토콜, HDLC(High Level Data Link Control) 프로토콜이 존재한다.
바이트 단위 전송은 전송을 위한 제어 정보를 데이터 헤더에 포함시켜서 데이터를 전송하는 것으로 DDCM(Digital Data Communication Message) 프로토콜이 존재한다.
문자 단위 전송은 데이터를 전송할 때 데이터의 시작과 끝에 특수문자를 포함시켜 전송하는 것으로 BSC(Binary Synchronous Communication) 프로토콜이 있다.
통신 프로토콜 중에서 가장 대표적인 것은 ISO(International Organization for Standardization)에서 정의한 OSI(Open System Interconnection) 7계층 프로토콜이 있다.
OSI 7계층
OSI 7계층(Open System Interconnection) 개요
개방형 시스템의 효율적인 네트워크 이용을 위하여 모든 데이터 통신 기준 계층으로 분할하고, 각 계층 간의 필요한 프로토콜을 규정한다.
국제표준화기구 ISO(International Standards Organization)에서 1977년 개방형 시스템(Open System) 간의 상호 정보전송을 위해서 제정한 표준안이다.
7 계층으로 분류하여 서로 다른 네트워크 간에 통신이 가능하도록 제시했다.
OSI 7 계층 목표
정보가 전달되는 Framework를 제공해서 네트워크 형태에 차이가 발생해도 데이터 통신을 지원한다.
Framework : 작업(Task)을 처리하기 위한 기본적인 틀을 의미하고 상세한 부분까지는 정의하지 않는다.
OSI 7 계층의 특징
개방형 시스템 간에 상호 접속을 위해서 표준화 된 방법을 제시했다.
OSI 7계층별로 정보 흐름을 최소화하여 각 계층의 독립성을 향상시켰다.
프로토콜의 표준화를 제시하여 효율성 및 생산성을 향상시켰다.
캡슐화
OSI 7계층은 상위 계층인 애플리케이션(Application)계층부터 하위 계층인 물리(Physical)계층까지 7개의 계층으로 이루어져 있는데 각 계층에서 계층에 대한 정보를 헤더에 추가해서 메시지에 헤더를 붙이는 과정을 캡슐화라고 한다.
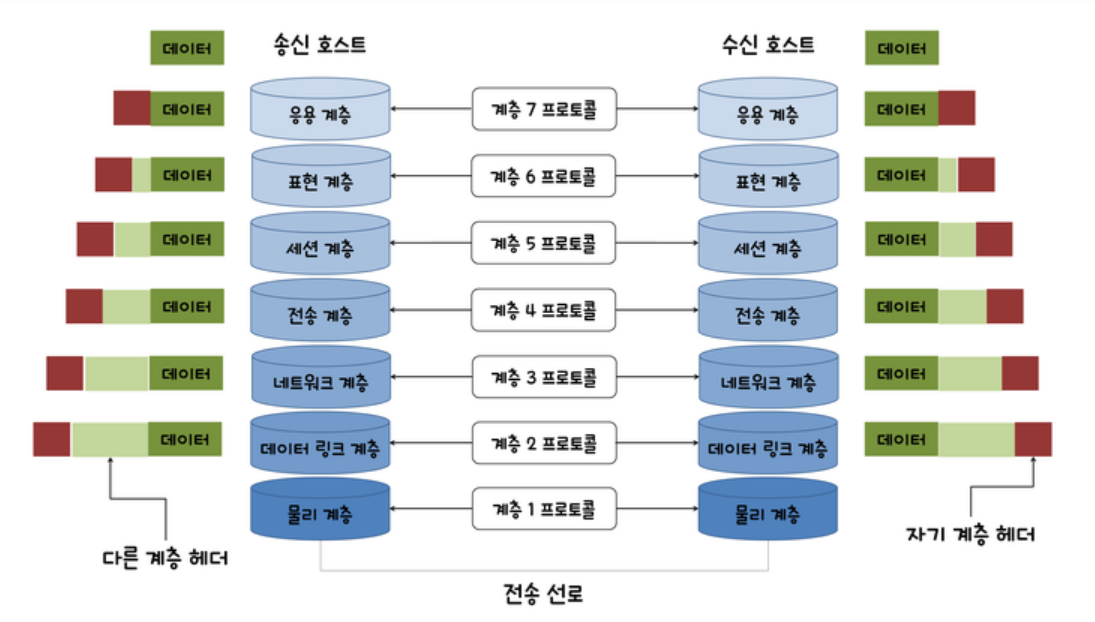
계층별 특징
(1) 애플리케이션(Application) 계층
사용자들이 사용하는 프로그램이 있는 계층이다.
데이터 송신을 위해서 메시지(Message)를 만든다
최상위 계층으로 하위 계층의 구조를 몰라도 네트워크를 사용할 수 있다.
인터넷을 위한 HTTP, 파일 업로드 및 다운로드를 위한 FTP, 네트워크 모니터링을 위한 SNMP, 전자우편 발송과 수신을 위한 SMTP 등과 같은 프로토콜이 있다.
(2) 표현(Presentation) 계층
애플리케이션에서 전송한 메시지에 대해서 코드화를 수행한다.
사전에 정해진 코드를 변환한다.
메시지를 압축해서 전송되는 데이터량을 줄인다.
네트워크 송신 과정에서 스니핑(Sniffing)을 통해서 메시지를 훔쳐볼 수 있기 때문에 암호화를 수행한다.
(3) 세션(Session) 계층
송신자와 수신자 간에 통신을 위해서 동기화 신호를 주고받는다
세션 연결을 하고 가상 연결을 제공한다
통신 방식인 다순, 반이중, 전이중 방식을 제공한다.
(4) 전송(Transport) 계층
송신자와 수신자 간에 논리적 연결(Logicla Connection)을 수행한다.
종단 간에(End to End) 연결을 관리한다.
전송 계층의 프로토콜은 TCP와 UDP가 있다.
종단 간에 에러가 발생하면 에러르 탐지하고 재전송하는 방법으로 에러를 수정한다.
TCP와 UDP는 헤더와 삼께 데이터에 에러가 있는지 확인한다.
(5) 네트워크(Network) 계층
수신자의 IP 주소를 읽어서 라우터가 경로를 결정한다.
경로 설정은 최단 경로 알고리즘과 같은 라우팅 알고리즘을 사용해서 결정하고 경로가 결정되면 포워딩(Forwarding)을 수행한다.
IPv4 주소와 IPv6 주소가 있다.
네트워크의 에러 확인을 위해서 ICMP 프로토콜을 사용한다.
6) 데이터 링크(Data Link) 계층
네트워크 계층에서 붙인 IP 헤더에서 IP 주소를 읽어서 하드웨어 주소인 MAC 주소를 구한다.
에러를 탐지하고 교정한다.
네트워크에 부하가 발생하지 않도록 흐름제어(Flow Control)를 한다.
물리적 하드웨어
물리 계층에서 메시지를 전송하기 위해서는 MAC 주소를 알아야 한다. 자신의 컴퓨터 MAC 주소는ipconfig/all명령어를 실행해서 확인할 수 있다. MAC 주소는 48비트로 이루어져 있고 상위 24비트는 제조사 번호이고 하위 24비트는NIC(Network Interface Card)의 일련번호이다.
(7) 물리(Physical) 계층
물리적 선로로 전송하기 위해서 전기적 신소인 비트(Bit)로 데이터를 전송한다.
만약 전송 거리가 멀면 리피터와 같은 장치를 사용해서 신호를 증폭시켜야 한다.
OSI 7 계층별 세부 기능
7. Application
사용자 소프트웨어를 네트워크에 접근 가능하도록 한다.
사용자에게 최종 서비스를 제공한다.
주요 프로토콜(매체)
FTP, SNMP, HTTP, Mail, Telnet등
6. Presentation
포맷 기능, 압축, 암호화
텍스트 및 그래픽 정보를 컴퓨터가 이해할 수 있는 16진수 데이터로 변환
압축, 암호, 코드 변환
GIF, ASCII. DBCDIC
-
Session
세션 연결 및 동기화 수행 방식, 통신 방식 결정
가상 연결을 제공해서 Login/Logout 수행
단순, 반이중, 전이중 결정 -
Transport
가상 연결, 에러 제어, Data 흐름 제어, Segement 단위
두 개의 종단 간 End - To - End 데이터 흐름이 가능하도록 논리적 연결
신뢰도, 품질 보증, 오류 탐지 및 교정 기능 제공
다중화(Multiplexing) 방생
TCP, UDP(SSL 및 TLS 실행) -
Network
경로 선택, 라우팅 수행, 논리적 주소 연결(IP)
데이터 흐름 조절, 주소 지정 매커니즘 구현
네트워크에서 노드에 전송되는 패킷 흐름을 통제하고, 상태 메시지가 네트워크 상에서 어떻게 노드를 전송되는가를 정의, Datagram 단위
IP, ICMP
라우팅 프로토콜 (RIP, OSPF) -
Data Link
물리 주소 력정, 에러 제어, 흐름 제어, 데이터 전송
Frame 단위, 전송 오류를 처리하는 최초의 계층
흐름 제어, 오류 제어(APQ)
브리지, HDLC
Frame Relay -
Physical
전기적, 기계적 연결 정의, 실제 Data Bit 전송
Bit 단위, 전기적 신호, 전압 구성, 케이블, 인터페이스 등을 구헝한다.
매체 : 동축케이블, 광섬유, Twisted Pair Cable
OSI 7계층 네트워크 장비
Physical
Cable :
Twisted Pair Cable, Coaxail, Fiber Optical Cable
Repeater :
네트워크 구간의 케이블의 전기적 신호를 재생하고 증폭하는 장치
디지털 신호를 제공, 아날로그 신호 증폭 시 잡음과 왜곡까지 증폭
Data Link
Bridge :
서로 다른 LAN Segment를 연결, 관리자에게 MAC 주소 기반 필터링 제공하여 더 나은 대역폭(Bandwidth) 사용과 트래픽을 통제
리피터와 같이 데이터 신호를 증폭하지만 MAC 기반에서 동작
Switch :
목적지의 MAC 주소를 알고 있는 지정된 포트로 데이터를 전송
Repeater와 Bridge의 기능을 결합
네트워크의 속도 및 효율적 운영, Data Link 계층에서도 작동
Network
Router :
패킷을 받아 경로를 설정하고 패킷을 전달
Bridge는 MAC 주소를 참조하지만 Router는 네트워크 주소까지 참조하여 경로를 설정
패킷 헤더 정보에서 IP 주소를 확인하면서 목적지 네트워크로만 Broatcast을 차단
Application
Gateway
서로 다른 네트워크 망과의 연결(PSTN, Internet, Wireless Network 등)
패킷 헤더의 주소 및 포트 외의 거의 모든 정보를 참조
에러 제어(Error Control)
에러 제어 개요
네트워크를 사용해서 데이터를 송신하다 보면 정말 다양한 에러(Error)가 발생한다. 송신과 수신을 하는 프로그램 에러부터 네트워크 케이블 절단, 무선으로 전송할 때의 신호 감쇠, 잡음 등 너무나 많은 형태의 에러가 있다. 에러가 발생하면 우선 에러가 발생했는지 탐지(Detection)해야 하고 그 다음 에러를 수정해야 한다.
우선 탐지는 수신자가 제대로 수신 받고 있는지 송신자에게 알려주어야 하고 수신 받은 데이터에 에러가 없는지는 송신자와 수신자 간의 일정한 약속으로 확인해야 한다. 이렇게 수신 받은 데이터에 에러가 없는지 확인하는 것은 FEC(Forward Error Correction)이라고 하고 수신자가 데이터를 수신 받지 못하면 재전송해야 하는데 이를 BEC(Backword Error Connection)라고 한다.
FEC(Forward Error Control)
오류 검출 및 정정 코드
해밍코드(Hamming Code)
오류 발견 및 교정이 가능한 코드
1비트의 에러 검출 및 교정
CRC 코드(Cyclic Redundancy Check)
데이터 통신에서 전송 중에 오류가 발생했는지를 확인하기 위해서 덧붙이는 코드
패리티 비트(Parity Bit)
하나의 비트로 코드의 에러를 검출하는 것으로 데이터 내의 Set(1) 비트 수를 체크하여 짝수와 홀수에 따라 코드를 그대로 두거나 1비트를 추가하여 에러를 검출
홀수 패리티(Odd Parity) : 비트 수가 홀수 개인 경우
짝수 패리티(Even Parity) : 비트 수가 짝수 개인 경우
FEC 기법 중에서 가장 간단한 방법은 1의 개수가 짝수인지 홀수인지를 확인해서 에러 여부를 확인하는 패리티 검사(Parity Check)이다. 또한 특정 합계를 계산하여 합계가 맞는지 확인하는 블록 합계 검사도 있다. 에러 발생 시에 수정까지 할 수 있는 기법은 해밍 코드(Hamming Code)방법이 있다. 하지만 실제 많이 사용되는 방법은 CRC 기법인데, CRC는 Check Sum 비트를 전송하여 Check Sum 비트로 수신자가 연산하여 에러 여부를 확인하는 것으로 무선 LAN과 이더넷(Ethernet) 프레임에서 사용한다.
FEC(Forward Error Correction)와 BEC(Backword Error Correction)
FEC(Forward Error Correction)
송신 측이 특정한 정보 비트를 함께 전송하여 수신 측에서 이 정보 비트로 에러 발생시 수정하는 방식(수신 측이 에러 처리)
데이터 전송 과정에서 발생한 오류를 검출하여 오류를 재전송 요구 없이 수정
재전송 요구가 없어 역 채널이 필요없고 연속적인 데이터 전송이 가능
오류 검출 및 수정을 위한 잉여 비트들이 추가 전송되므로 전송 효율 감소
해밍 코드와 상승 코드 방식이 있다.
BEC(Backword Error Correction)
수신 측이 에러 검출 후 송신 측에게 에러가 발생한 데이터 블록을 다시 전송 요청하는 방식(송신 측이 에러 처리, ARQ : Auto Repeat reQuest)
패리티 검사, CRC 등 Checksum을 이용하여 오류 검출 후 오류 제어는 ARQ가 처리
Stop-and-wait, Go-Back-N, Selective-repeat ARQ, Adaptive ARQ가 있다.
BEC(Backward Error Control)
BEC 기법
Stop and Wait 방식 :
송신자가 데이터를 전송하고 수신응답이 오면 다음 데이터를 전송한다.
Go - Back - N 방식 :
수신자가 데이터를 수신 받지 못할 경우 마지막으로 수신 받은 데이터 이후의 모든 데이터를 재전송하는 방법으로 TCP 프로토콜에서 사용하는 방법이다.
Selective repeat 방식 : 수신자가 수신 받은 데이터 중에서 중간에 빠져 있는 것만 재전송하는 방식으로 에러를 처리하는 것이다.
BEC 기법의 특징
Stop - and - Wait
재전송 요청 방법 : 에러 발생 즉시 재전송
수신 방법 : 순차적으로 수신
장단점 :
가장 단순한 구현
신뢰성 있는 전송
대기 시간 존재로 전송 효율 저하
Go - Back - N
오류 발생 또는 잃어버린 프레임 이후의 모든 프레임을 재 요청하거나 타임 아웃으로 자동 재송신된다.
수신 방법 :
프레임의 송신 순서와 수신 순서가 동일해야 수신
장단점 :
간단한 구현
적은 수신 측 버퍼 사용량
Selective Repeat
오류 발생 또는 잃어버린 프레임에 대해서만 재 요청 또는 타임아웃으로 인한 자동 재송신
순서와 상관없이 윈도우 크기만큼의 범위 내에서 자유롭게 수신
장단점 :
구현이 복잡
버퍼 사용량이 크다
보다 적은 재전송 대역폭
Section 02. TCP/IP 계층
TCP/IP 프로토콜
TCP/IP 프로토콜 개요
Transmission Control Protocol/Internet Protocol은 DoD(미국방성) 모델이라고 하며 OSI 7 Layer와 매우 흡사하다
이 기종 간 네트워크 환경에 대한 표준으로 OSI보다 먼저 만들어지고 가장 많이 사용되고 있다.
미국 ARPANET에서 개발된 프로토콜이다.
인터넷에서 사용되고 있으며 다양한 네트워크와 상호 접속이 가능하다.
ARPANET
미국 국방성에서 국방 관련 기관 간에 정보 공유를 위해서 추진한 프로젝트로 원격 로그인, 파일 전송, 전자우편 등의 기능을 지원하는 네트워크이다.
TCP/IP 4계층
(1) 애플리케이션(Application) 계층
애플리케이션 계층은 사용자들이 사용하는 프로그램이 있는 계층이다.
FTP, Telnet, SSH, HTTP, SMTP, SNMP 등의 프로토콜이 있다.
(2) 전송(Transport) 계층
신뢰성 있게 메시지를 전송하는 TCP 프로토콜이 있다.
비연결형으로 연결하지 않고 빠르게 메시지를 전송하는 UDP 프로토콜이 있다.
TCP는 가상의 연결을 지원하고 에러처리를 실행해서 신뢰성 있게 전송한다.
(3) 인터넷(Internet) 계층
IP 주소를 읽어서 경로를 결정하는 라우팅(Routing)을 실행한다.
논리적 주소인 IP 주소를 부여하고 최단 경로를 결정한다.
IP 주소를 하드웨어 주소인 MAC 주소를 변환하는 ARP 프로토콜을 지원한다.
네트워크의 에러를 검사하는 ICMP 프로토콜을 지원한다.
(4) 네트워크 접근(Network Access) 계층
물리적 케이블 혹은 무선 통신과 연결하고 메시지를 전송한다
전기적 신호로 변환해서 메시지를 전송한다.
TCP/IP 프로토콜 스니핑
스니핑(Sniffing) 도구를 사용해서 웹사이트로 송수신되는 패킷을 모니터링 해보자. 웹 사이트이기 때문에 애플리케이션 계층에서는 HTTP 프로토콜을 사용하고 HTTP는 내부적으로 TCP를 사용한다. 그래서 전송 계층에서는 TCP 프로토콜이 나타나게 된다. 그 다음은 인터넷 계층에서 IP 주소를 부여한다. 네트워크 계층은 이더넷(Ethernet)으로 메시지를 전송한다.
TCP/IP와 OSI 7계층
TCP/IP 4 계층은 OSI 7계층을 그대로 준수하고 있다.
OSI 7계층(Applciation, Presentation, Session)
TCP/IP 4계층(Application)
네트워크를 실제로 사용하는 응용 프로그램으로 구성
FTP, TELNET, SMTP 등이 있다.
OSI 7계층(Transport)
TCP/IP 4계층(Transport)
도착하고자 하는 시스템까지 데이터를 전송
프로세스를 연결해서 통신한다
TCP, UDP
OSI 7계층(Network)
TCP/IP 4계층(Internet)
datagram을 정의하고 routing 하는 일을 담당
IP, ARP, RARP, ICMP
OSI 7계층(Data Link, Physical)
TCP/IP 4계층(Network Access)
케이블, 송수신기, 링크 프로토콜, LAN 접속과 같은 물리적 연결 구성을 정의
TCP/IP 프로토콜 구성
TCP/IP 프로토콜은 TCP, UDP, IP, ICMP, ARP, RARP로 구성된다.
TCP :
Connection Oriented Protocol(연결 지향)로 사용자에게 신뢰성 있는 서비스를 위해서Error Control기법을 포함하고 있으며, TCP는 송신자가 보낸 메시지에 대해서 수신자가 전송 받았는지 확인하기 위해서 수신자는 ACK가 오지 않거나 동일한 ACK 번호가 오면 다시 전송하는 것이다.
UDP :
Connectionless Protocol(비연결)로 데이터 전송을 보장하지 않는 비신뢰성 서비스를 제공하지만, TCP에 비해서 전송 속도가 빠른 특징을 가진다.
ARP :
IP Address를 LAN 카드의 물리적 주소인 MAC 주소를 변환한다.
RARP :
MAC 주소를 IP Address로 변환하는 역할을 수행한다.
ICMP :
네트워크 오류와 상태를 점검하기 위해서 사용된다.
IP :
네트워크 주소와 호스트 주소 정의에 의한 네트워크의 논리적 관리를 담당하는 것으로 송신자와 수신자의 주소를 지정한다.
애플리케이션 계층
애플리케이션 계층 개요
애플리케이션 계층은 일반 사용자들이 사용하는 프로그램이 있는 계층으로 사용자는 프로그램을 사용해서 통신을 하게 되는 것이다. 애플리케이션 계층은 응용 프로그램이 있으므로 프로토콜을 사용해서 새로운 서비스를 만들어 낼 수 있고 이러한 서비스는 동영상 학습 프로그램, VoIp 전화, 카카오톡 등의 다양한 형태가 있다. 이러한 응용 프로그램들은 내부적으로 전자우편(eMail), 파일 전송(FTF), 웹(HTTP)등을 사용하게 된다.
애플리케이션 계층(Application Layer)
해당 Application(전자우편, Ftp, Http)에 맞게 사용자 인터페이스를 설계하는 계층이다
통신하는 상대편 응용 계층과 연결을 하고 상대편 컴퓨터와 기본적인 사항을, 에러 제어, 일관성 제어를 한다.
어떻게 파일을 보낼지, 프린터를 어떻게 공유할지, 전자우편을 어떻게 보낼지를 다룬다.
애플리케이션 계층의 서비스
애플리케이션 계층에 있는 응용 프로그램에는 파일을 업로드 하거나 다운로드 하는 FTP 서비스와 www.boongisa.com이라고 웹 브라우저에 입력하면 IP 주소를 돌려주는 DNS 서비스가 있다. 또한 www.limbest.com이라고 입력하면 HTML 문서를 전송하거나 수신 받는 HTTP 프로토콜과 원격으로 네트워크를 경유해서 서버에 접속하는 Telnet, ssh등의 프로그램이 있다.
애플리케이션 계층 관련 서비스
FTP
File Transfer Protocol
사용자의 파일을 업로드 혹은 다운로드한 프로그램
파일 전송을 위한 인터넷 표준으로 제어 접속과 데이터 접속을 위한 분리된 포트를 사용함
DNS
Domain Name Server
DNS Query를 사용해서 DNS Server에 해당 URL에 매핑되는 IP 주소를 제공하는 서비스
HTTP
Hyper Text Transfer Protocol
웹 브라우저와 웹 서버 사이에서 웹 페이지의 Request 및 Response를 수행하는 프로토콜
Telnet
특정 지역의 사용자가 지역적으로 다른 곳에 위치한 컴퓨터를 온라인으로 연결하여 사용하는 서비스
SMTP
Simple Mail Transfer Protocol
RFC 821에 명시된 인터넷 전자우편을 위한 프로토콜로 메시지 전달을 위해서 Store and Forward 방식을 사용
암호화 및 인증 기능 없이 사용자의 이메일을 전송하는 프로토콜
SNMP
Simple Network Management Protocol
네트워크에 대한 트래픽, 세션 등의 네트워크의 상태를 모니터링하고 정보를 전달할 때 사용하는 프로토콜
SMTP는 전자우편을 발송할 때 MIME라는 전자우편 데이터 형식으로 메일 전송하거나 수신 받기 위해서 사용되고 SNMP는 네트워크의 트래픽을 모니터링하기 위해서 사용하는 프로토콜이다.
전송 계층
전송 계층 개요
전송 계층은 송신자와 수신자 간에 논리적 연결(Logical Connection)을 수행하는 것으로 TCP 프로토콜과 UDP 프로토콜이 존재한다. TCP 프로토콜을 사용하는 경우 연결지향(Connection Oriented) 방식을 사용하고 UDP는 비연결성(Connectionless) 방식을 사용한다.
전송 계층(Transport Layer)
수신 측에 전달되는 데이터에 오류가 없고 데이터의 순서가 수신 측에 그대로 보존되도록 보장하는 연결지향 서비스(Connection Oriented Service)의 역할을 하는 종단간(end - to - end) 서비스 계층
전송 계층 프로토콜은 신뢰성 있는 전송을 하는 TCP와 비신뢰성 전송을 하는 UDP 프로토콜이 존재한다.
세그먼트(Segment)
세그먼트라는 것은 전송 계층에서 TCP 혹은 UDP를 사용할 때 해당 헤더(Header)를 메시지에 붙이는 것을 의미한다.
세그먼트의 TCP와 UDP
TCP Header는 UDP에 비해서 크기가 크고 UDP는 작은 특성이 있다. TCP는 신뢰성 있는 데이터 전송을 위해서 가상의 연결을 수행한다. 가상의 연결 이후에 데이터를 송수신하는데 송신자가 메시지를 전송하면 수신자는 ACK를 되돌려서 수신여부를 확인 해준다. 만약 수신자가 동일한 ACK 번호를 반복적으로 전송한다면 어떤 이유로든 데이터를 받지 못하는 것이고 만족적인 ACK가 되돌아오면 TCP는 에러 제어 기법을 통해 재전송을 수행한다. 이때 재전송 방법은Go - Back - N방법이고, 이 방법은 되돌아온 ACK 번호 이후의 모든 것을 전부 재전송하는 것이다. 또한 동일한 ACK 번호가 송신자에게 계속 되돌아오면 송신자는 전송 속도를 낮춘다. 이러한 것을 혼잡 제어(Congestion Control)이라고 한다. 이를 통해서 네트워크 전송망을 효율적으로 사용하는 것이다. 즉, 수신 받지 못하는 상황에서 계속적으로 빠르게 전송한다면 네트워크의 부하를 유발할 것이다.
TCP는 Sequence 번호를 가지고 메시지의 순서를 파악할 수 있게 해준다. 송신자의 메시지가 꼭 순서대로 도착하지 않는다. 그 이유는 비동기 방식으로 데이터를 보내면서 경로 또한 다른 경로로 보내질 수 있기 때문이다.
Check Sum은 TCP와 UDP는 모두에게 존재하는 것인데. 이것은 송신 중에 메시지의 변조를 파악하기 위해서 송신자와 수신자 간에 에러를 체크하기 위한 방법이다. 즉, 패리티 비트 같은 것이다.
Recieve Window는 수신자의 윈도우 크기를 의미하며, 이것음 메모리 버퍼를 이야기한다. 즉 수신자의 버허가 비어 있으면, 송신자는 해당 버퍼의 크기만큼의 데이터를 한꺼번에 전송한다. 수신자의 버퍼가 1개 비어있아면 송신자가 1개만 보내는 것이다. 이것을 통해서 전송 효율을 관리하는 것이다.
TCP
TCP(Transmission Control Protocol) 개요
네트워크 계층 상위에서 수행되는 전송 계층의 프로토콜로 클라이언트와 서버 간의 연결지향, 신뢰성 있는 데이터 전송, 에러 제어, 흐름 제어 등의 기능을 수행하는 프로토콜이다.
TCP 프로토콜은 메시지를 송수신하기 전에 연결지향으로 먼저 연결을 확인하고 연결이 확립되면 메시지를 송수신하는 방식으로 기동된다. 하지만 TCP는 연결을 지향할 뿐 물리적으로 연결된 것은 아니라서 주기적으로 메시지를 송수신해서 송수신 가능 여부를 확인한다. 이러한 송수신 가능 여부를 확인하는 것은 TCP의 역할이 아니며 TCP/IP 프로토콜 군의 ICMP 프로토콜이 그 역할을 담당한다.
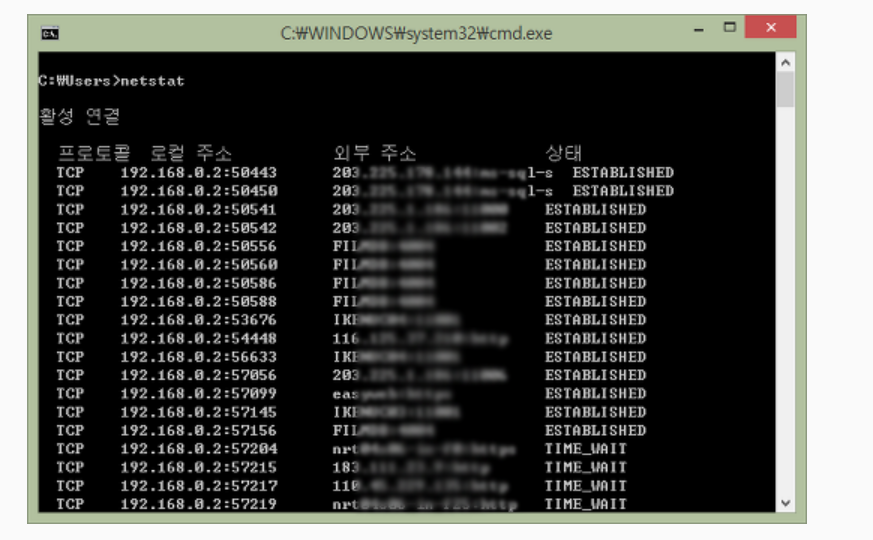
TCP 상태 전이
TCP 상태 전이는 TCP 프로토콜에서 가장 중요한 요소로 TCP의 최초 연결 신청부터 연결, 종료까지의 상태 변화을 의미한다. TCP의 상태 정보를 확인할 수 있는 가장 손쉬운 방법은 리눅스 혹은 윈도우에서 nestat 명령을 실행하는 것이다.
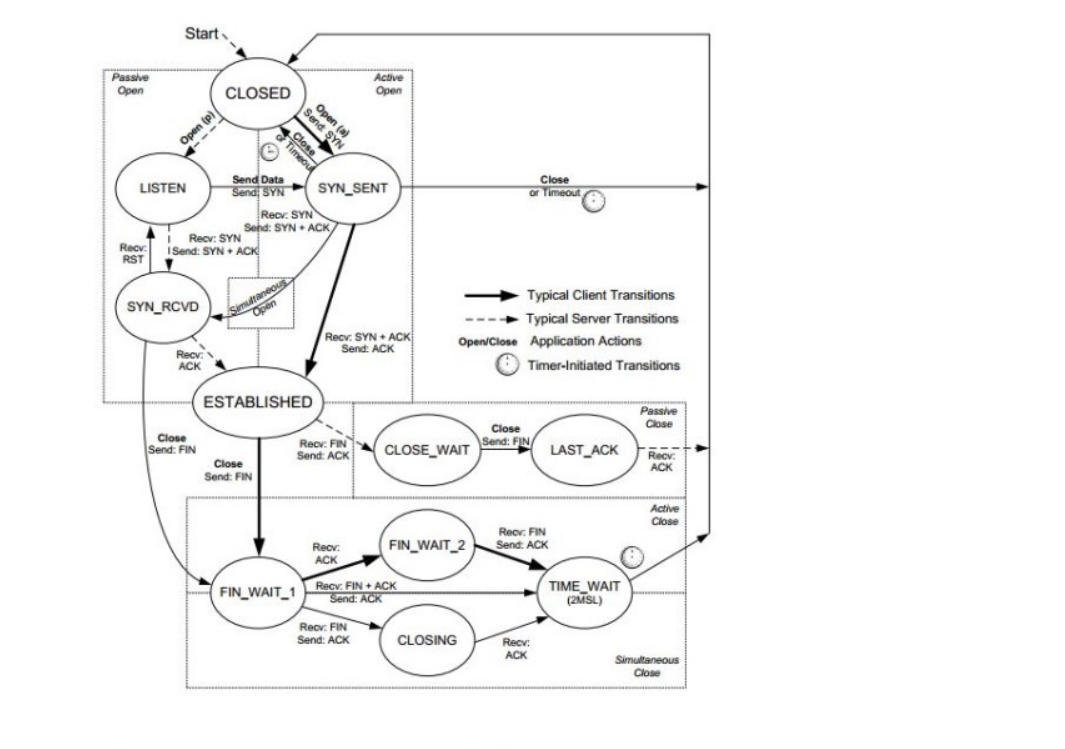
TCP 상태 전이 과정
앞의 TCP 상태 전이를 하나하나 살펴보면 다음과 같다.
클라이언트는 먼저 서버에 연결 요청 메시지인 SYN 신호를 보내고 SYN-SENT 상태가 된다. 서버는 처음 기동이 되면 클라이언트의 연결을 받기 위해서 LISTEN 상태에서 클라이언트의 연결을 대기한다. 그리고 클라이언트로부터 SYN 메시지가 수신되면 서버는 클라이언트에게 SYN, ACK를 전송하고 SYN-RECIEVED 상태로 바뀐다.
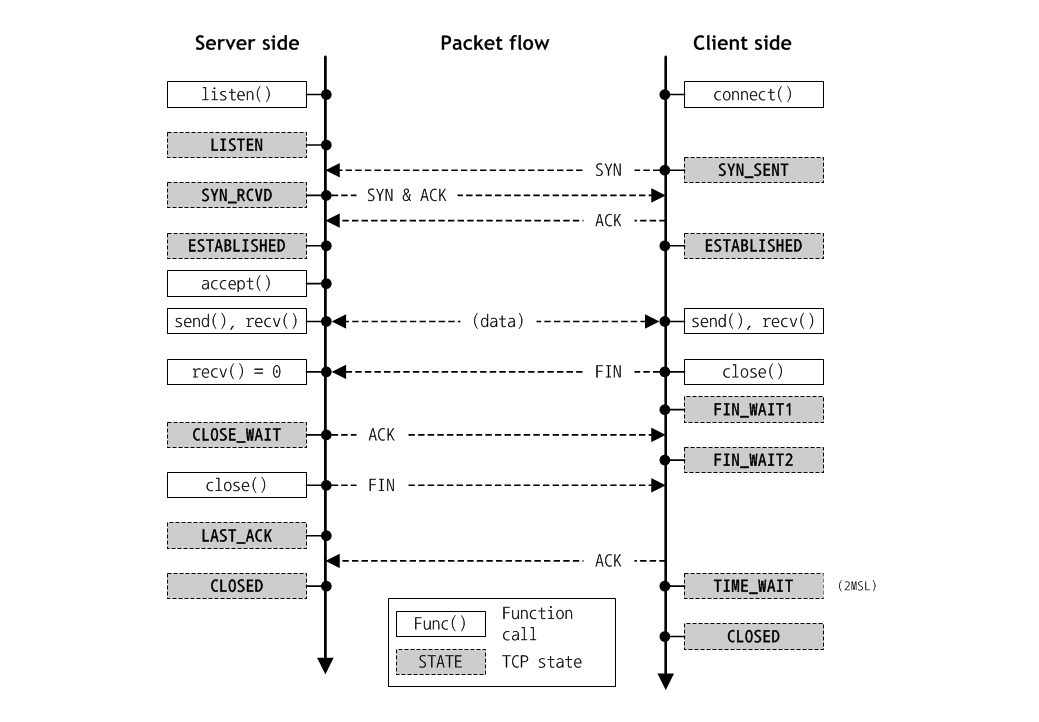
그리고 클라이언트는 ACK를 서버에 전송하고 클라이언트와 서버는 ESTABLISHED 상태인 연결 확립 상태가 된다.
TCP 상태 값 확인
netstat 명령어를 사용해서 TCP 연결 상태를 확인해본다. 윈도우에서 -p 옵션을 사용하면 모니터링하고 싶은 프로토콜을 지정할 수 있다.
TCP 프로토콜의 Header 구조
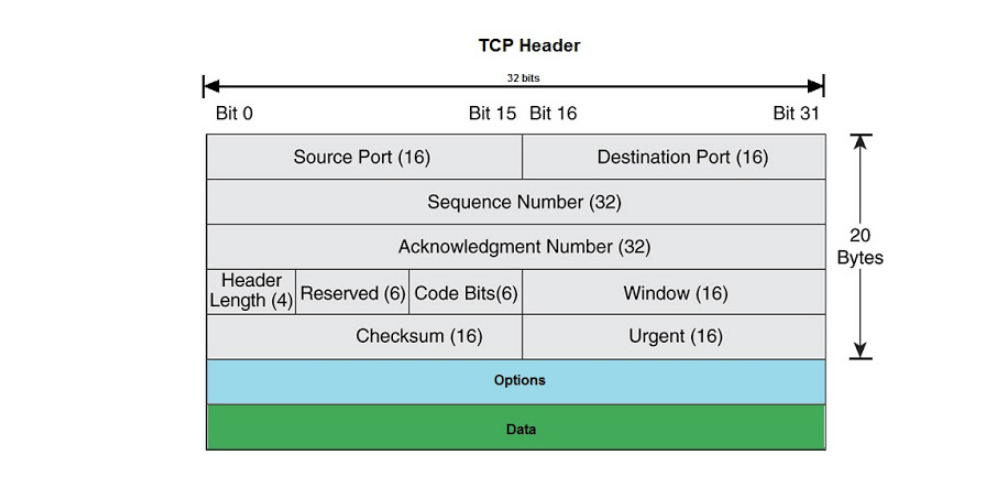
신뢰성 있는 전송, 에러 제어
순서 제어(Sequence Control)
완전이중 방식(Full Duplex data)
연결지향(Connection Oriented)
3-way Handshaking
흐름 제어(Flow Control)
TCP의 주요 기능
신뢰성 있는 전송
수신자는 데이터를 송신 받고 ACK Number를 송신자에게 전송한다. 송신자가 ACK Number가 수신되지 않으면 재전송을 실행하여 신뢰성 있는 데이터 송수신을 수행한다.
순서 제어
송신자의 메시지 순서를 맞추기 위해서 송신자는 메시지 전송 시에 Sequence Number를 같이 보낸다. 그러면 수신자는 메시지의 순서가 맞지 않게 도착해도 Sequence Number를 통해서 정렬을 수행할 수 있다.
완전이중(Full Duplex)
전화기처럼 송신자는 송신, 수신자는 수신을 동시에 할 수 있다.
흐름 제어(Flow Control)
수신자가 메시지를 제대로 받지 못하면, 송신자는 전송 속도를 늦추어 네트워크 효율성을 제어한다.
혼잡 제어(Congestion Control)
수신자의 메모리 버퍼 정보 즉, Window Size를 수신 받아서 수신자의 버퍼 상태를 보고 전송 속도를 조절한다.
TCP 헤더 세부 내용
근원지 포트(Source Port) : 가상 선로의 송신 측 포트(End Point of Sender)
목적지 포트(Destination Port) : 가상 선로의 수신 측 포트(End Point of Reciever)
일련 번호(Sequence Number) : 송신자가 전송하는 데이터의 일련 번호
전송 확인(Piggyback Acknowledgement) : 수신자가 응답받은 데이터의 수
일련번호와 전송 확인은 데이터 흐름 제어(Flow Control)에 사용되는 32bit 정수이다.
슬라이딩 윈도우 프로토콜은 송신자가 일련번호와 함께 데이터를 전송하고, 수신자는 받은 데이터의 수를 의미하는 전송 확인 번호를 응답함으로써 안정적인 데이터 전송을 보장한다.
TCP Header 구조 세부내용 (2)
TCP 헤더 길이(TCP Header Length)
TCP 헤더에 몇 개의 32bit 워드가 포함되어 있는가를 나타내는 필드
옵션 필드가 가변 길이를 갖기 때문에 필요, 이 값을 이용하여 실제 데이터의 시작점을 개선
URG(Urgent) : 긴급 지점(Urgent Pointer)이 사용될 때 1로 설정
ACK(Acknowlegement) : 전송 확인(Piggyback Achknowledgement)이 필요로 할 때 설정
EOM(End Of Message) : 마지막 메시지임을 가리킨다
재설정(RST, Reset) : 연결의 재설정(Reset a Connection)
동기화(SYN, Synchronization) : 연결 설정 요구(Establish Connection)
FIN(Finish) : 연결 해제에 사용되며, 송신 측에서 더 이상의 전송할 데이터가 없음을 의미
윈도우 사이즈(Window Size) : 수신 측에서 수신할 수 있는 최대 Byte 수
체크썸(Checksum) : 전송 데이터에 대한 완벽한 신뢰성을 위한 것으로, 모든 데이터의 합에 대한 '1'의 보수로 계산
급송 지점(Urgent Point) : 다음에 이어지는 데이터가 급송되어야 함을 의미하며, 인터럽트 메시지 대신 사용
옵션(Options) : 전송 셋업 과정의 버퍼 크기에 대한 통신 등 기타 목적에 활용
송신 측은 전송한 데이터에 대한 수신 측의 전송 확인(ACK)이 도착하기 전에도 윈도우 크기만큼의 데이터를 연속적으로 보낼 수 있다.
수신 측에서는 자신의 버퍼 크기에 따라 이 값을 조절하며, 윈도우 크기가 '0'이 되면 송신자는 전송을 잠시 중단한다.
흐름 제어(Flow Control)
송수신측 사이의 전송 패킷의 양과 속도를 조절하여 네트워크를 효율적으로 사용한다.
송수신측 사이의 처리 속도와 버퍼 크기 차이에 의해 생길 숭 씨는 수신측의 오버플로우를 방지한다.
슬라이딩 윈도우(Sliding Window)
슬라이딩 윈도우 개요
슬라이딩 윈도우(Sliding Window)는 흐름 제어를 수행하는 방법으로 수신자가 수신 받을 만큼 데이터를 전송하는 방법이다.
TCP 호스트 간의 효율적인 데이터 전송을 위해서 호스트 간에 송수신 혹은 수신 할 수 있는 Size 정보를 제공한다.
송신 측의 윈도우와 수신 측의 윈도우 제공)
Stop - and - Wait 단점을 보완한 방식으로 수신 측의 확인 신호를 받지 않더라도 미리 정해진 프레임의 수만큼 연속적으로 전송한다.
TCP가 사용하는 방법이다.
슬라이딩 윈도우 동작 방법
수신 측은 설정한 윈도우 크기만큼 송신측에서 확인 응답(Ack)이 없어도 전송할 수 있게 하여 동적으로 패킷의 흐름을 제어하는 방식이다.
일정한 수의 패킷을 전송하고 응답이 확인되면 윈도우를 이동하여 그 다음 패킷을 전송한다.
슬라이딩 윈도우 처리 단계
Step 1 : 송신자와 수신자의 윈도우 크기를 맞춤
Window size = 3, 송신자는 1,2,3을 전송한다.
Step 2 : 응답대기 및 전송
송신 후 수신자로부터 ACK 1,2에 대한 응답이 오면 다음 윈도우로 이동하여 전송한다.
슬라이딩 윈도우의 장점
송신자와 수신자 간의 네트워크 전송 효율을 극대화하기 위해서 수신자의 버퍼 크기를 확인하고 최대한으로 전송 효율을 극대화한다.
수신자의 ACK의 경우 매번 ACK를 받을 수도 있지만, ACK 신호도 묶어서 처리해서 불필요한 네트워크 부하를 최소화한다.
혼잡 제어(Congestion Control)
혼잡 제어 개요
라우터가 Packet을 처리할 수 있는 속도보다 많은 Packet을 수신하는 경우 라우터는 Packet을 손실하게 되고, 송신측에서는 Packet을 재전송하게 되는데, 이러한 과정의 연속으로 데이터의 손실이나 지연이 발생한다.
혼잡 제어는 송신 단말의 전송률을 직접 제어하여 혼잡으로 인해 손실된 데이터를 최소화한다.
TCP Slow Start
Sender에서 Packet을 전송하는 비율과 Reciever에서 수신된 ACK를 통해 Congestion Window를 지수의 크기로 증가시키는 기법이다.
TCP Slow Start는 혼잡 제어를 하는 방법 중 하나로 TCP가 시작될 때 전송 속도를 초기 값부터 지속적으로 올리는 방법이다. 즉, 1Mbps의 속도로 데이터 전송을 시작하고 조금씩 임계값까지 속도를 올린다. 그러다가 수신자에게 Duplication ACK 값이 오면 데이터를 제대로 수신 받지 못함을 판단하고 송신 속도를 초기 값으로 낮추는 방법이다. 또한 Duplication ACK 값이 송신자에게 오지 않아도 전송 속도가 임계값에 도착하면 전송 속도를 임계값의 50%로 낮추고 다시 전송 속도를 올린다.
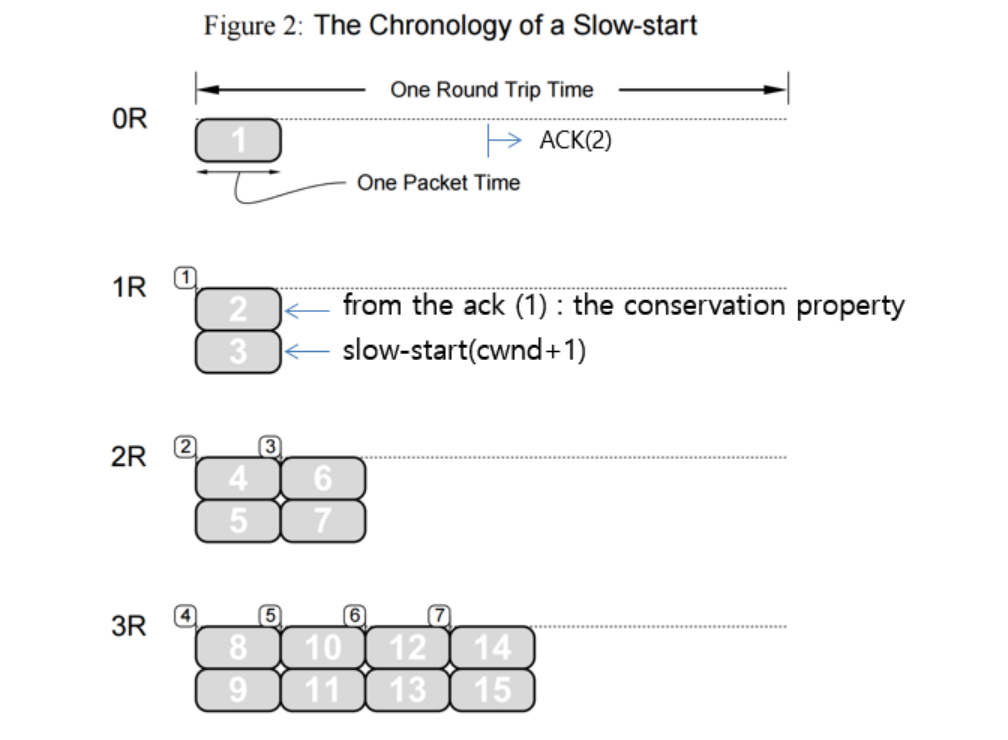
Congestion Avoidance(혼잡 회피)
일정 시간 동안 ACK가 수신되지 않거나, 일정 수의 Duplicate ACK가 수신되면, 송신자는 Packet 손실을 알게 되고 Congestion Avoidance 상태가 된다.
각 연결마다 Congestion Window와 Slow Start Threshold 두 개의 변수를 유지한다.
Congestion Avodiance 동작
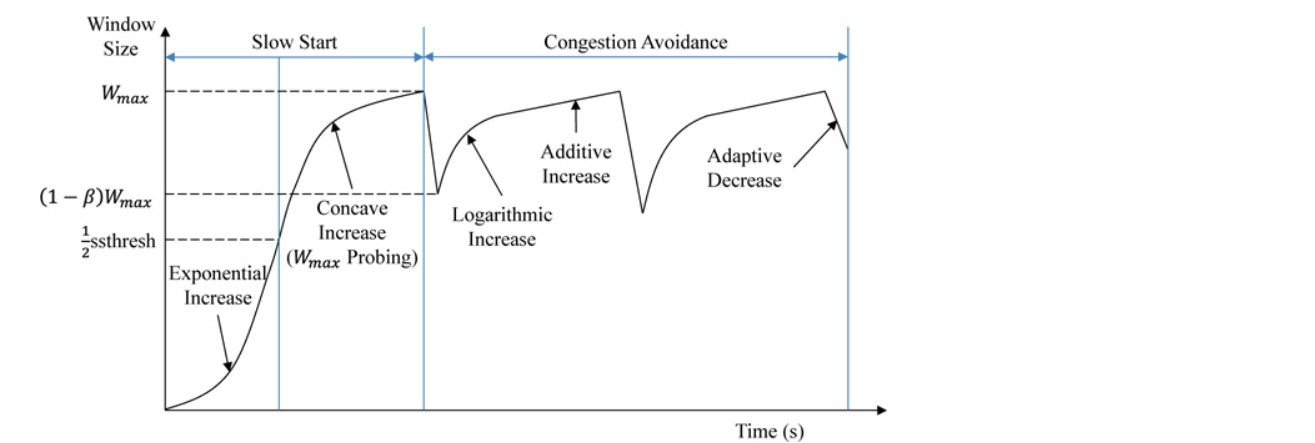
Slow Start 상태에서 CWind의 값이 계속 증가하여 임계 값에 도달하면 Congestion Avoidance 상태로 돌아가게 된다.
Congestion Avoidance 상태에서는 매번 ACK가 수신될 때마다 CWind를 1/Cwind만큼 증가
Slow Start에서의 CWind의 증가가 지수적인데 반해 Congestion Avoidance 상태에서는 선형적인 증가
TCP 혼잡 제어 알고리즘
Fast Retransmit
Retransmit Threshold 이상 연속된 Duplicate ACK를 수신하는 경우 TCP는 해당 Segmen를 즉시 다시 전송한다.
Fast Recovery
Fast Retransmit한 이후 새로 Slow Start를 통해서 설정된 열결의 인정 상태에 도달할 필요 없이 Congestion Avoidance 상태에서 전송할 수 있도록 하는 것
UDP(User Datagram Protocol)
UDP 개요
UDP는 데이터를 빠르게 전송할 용도로 사용하며, TCP에 비해 기능은 없지만 데이터를 빠르게 송수신 할 수 있는 장점이 있다. 하지만 UDP는 재전송 기능이 없어서 네트워크에서 패킷이 손실될 수 있어 데이터가 전송되는 것을 보장하지 않는 단점이 있다.
비연결성, 비신뢰성의 특성으로 Packet을 빠르게 전달할 수 있는 프로토콜이다.
송수신의 여부에 대한 책임을 Application이 가진다.
UDP의 특징
비신뢰성(Unreliable)
Packet을 목적지에 성공적으로 전송한다는 것을 보장하지 않는다
비접속형(Connectionless)
전달되는 Packet에 대한 상태 정보 유지를 하지 않는다
간단한 Header 구조
TCP에 비해서 간단한 헤더 구조로 인하여 처리 단순
빠른 전송
TCP에 비해 전송 속도가 빠르다
UDP 프로토콜의 Header 구조
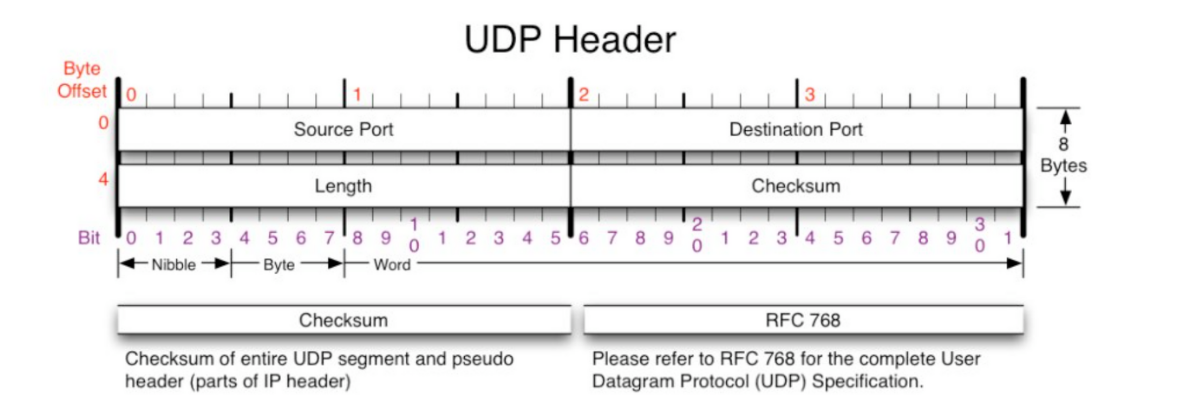
가상 선로(Virtual Circuit)의 개념이 없는 비연결성
블록 단위로 데이터 전송
블록 재전송 및 흐름 제어 등이 없음(데이터 신뢰성이 없다)
슬라이딩 윈도우 등의 복잡한 기술을 사용하지 않는다
UDP의 각 사용자는 16bit의 포트 번호를 할당 받는다.
실제 UDP 헤더를 보면 다음과 같다. 즉 송신자의 포트 번호, 수신자의 포트 번호 길이(Length), 무결성 검사를 위한 Check sum 필드만이 존재해서 아주 간단하다.
인터넷 계층
인터넷 계층 개요
인터넷 계층은 송신자의 IP 주소와 수신자의 IP 주소를 읽어서 경로를 설정하거나 전송하는 역할을 수행한다.
다중 네트워크 링크를 통해 패킷의 발신지 - 대 - 목적지 전달에 대한 책임을 가지낟(데이터 링크 혹은 노드간 전달 책임 즉, Point to Point)
인터넷 계층은 IP, ICMP의 TCP/IP 프로토콜 군이 존재하고 멀티캐스팅을 위한 IGMP(Internet Group Management Protocol), 라우팅을 위한 BGP, OSPF, RIP 등이 존재한다.
경로 설정(Routing)은 수신자의 IP 주소를 읽어서 어떻게 목적지까지 가는 것이 최적의 경로인지를 판단하는 것이다. 이러한 작업을 하는 것이 라우터(Router)라는 네트워크 장비이다.,
인터넷 계층 기능
경로 설정(Routing) : 경로를 설정
Point to Point Packet 전달
논리 주소 지정(Logical Addressing)
주소 변환(Address Transformation)
인터넷 계층의 논리적 주소 지정 : IP 주소로 변환해서 사용한다는 의미
데이터그램(Datagram) : 기존 패킷(Packet)에 IP Header를 붙이는 것을 의미
인터넷 계층의 논리적 주소 지정이라는 것은 www.boangisa.com의 URL을 210.10.10.101의 IP 주소로 변환해서 사용한다는 의미이다.
데이터그램(Datagram)
데이터그램(Datagram)이란 기존 패킷(Packet)에 IP Header를 붙이는 것을 의미한다.
IP(Internet Protocol) 프로토콜
IP 프로토콜은 IP 주소 형태로 송신자와 수신자의 IP 주소를 가지고 있고 IP 주소를 읽어서 최적의 경로를 결정할 수 있게 해준다. IP 프로토콜은 32비트 주소 체계로 이루어진 IPv4와 128비트 주소 체계로 이루어진 IPv6가 있다.
IP 프로토콜 개요
TCP/IP망의 네트워크 계층(IP 계층)의 주소화, 데이터그램 포맷, 패킷 핸들링 등을 정의해놓은 인터넷 규악이다.
인터넷 프로토콜은 현재 IPv4, IPv6가 사용 중이다.
IPv6는 IP 주소의 부족 문제를 해겨하기 위해서 주소 비트 수를 128비트로 늘린 것으로 이것은 모든 디지털 단말기에 IP 주소를 부여하여 인터넷과 연계하라고 하는 것이다. 우리는 최근 이러한 서비스를 IoT 서비스라고도 한다.
IP Header 구조
IP Header 정보를 보면, IP 프로토콜이 무슨 기능을 가지고 있는지 좀 더 명확하게 알 수 있다. IP Header에는 버전(Version) 정보를 가지고 있다. 버전 정보는 IPv4 혹은 Ipv6을 구분하는 역할을 수행한다. 즉, 버전 정보를 보고 라우터가 IP Header의 구조를 파악하는 것이다.
또한 Flag와 Fragment Offset이라는 것이 있는데, 이것은 패킷을 전송할 때 패킷의 크기가 너무 크면 패킷은 분할된다. 만약 패킷이 분할 될 경우에 분할된 패킷을 수신자가 수신 이후에 다시 조립을 해야 하기 때문에 패킷 분할과 관련된 정보가 있는 것이다.
TTL(Time to Live)은 IP 패킷이 통과할 수 있는 라우터의 수를 의미하며 라우터를 하나 통과할 때마다 1씩 감소하여 0이 되면 패킷은 자동으로 폐기된다. 이것ㅇ은 인터넷에서 무한 정으로 네트워크에 떠도는 패킷을 없애기 위해서이다.
Protocol은 IP Header위의 상위 프로토콜의 종류를 의미하며 TCP 혹은 UDP인지를 의미한다.
Header Checksum은 헤더의 무결성을 검사하기 위한 것이다.
IP(Ineternet Protocol) Header 구조
Vesion : IPv4 버전
Header LENgth : Header의 전체 길이
Type of Service : 서비스 유형
Total Length : IP Datagram의 Byte 수
Identification : Host에서 보낸 Datagram 식별
Flags & Offset : IP Datagram 단편화 정보
Time to live : Datagram이 통과할 수 있는 라우터의 수
Protocol : ICMP, TCP, UDP
Header checksum : IP Header Checksum 계산
IP 단편화(Fragmentation)
네트워크에는 MTU(Maximum Transmission Unit)라는 것이 있다. MTU는 한 번에 통과할 수 있는 패킷의 최대 크기를 의미한다. 그래서 MTU 값보다 패킷의 크기가 크면 패킷은 분할되고 그 정보를 Flag과 Offset에서 가지고 있다.
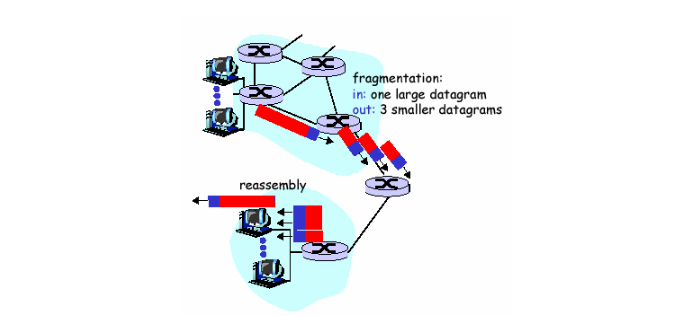
물론 패킷이 수신자에게 도착하면 다시 조립되어서 원래의 패킷을 만든다.
MTU 값을 확인하고 싶으면 이더넷(Ethernet) 정보를 조회하면 되고 ifconfig 명령을 리눅스에서 실행하면 된다.
윈도우에서 어떤 프로세스가 네트워크를 사용하는지 확인해본다.
윈도우에서netstat-b옵션을 사용하면 어떤 프로세스가 네트워크를 사용하는지 확인할 수 있다.
IP 주소와 서브넷 마스트(Subnet Mask)
서브넷 마스크(Subnet Mask)
IP 주소는 클래스(Class)로 분류하고 있다. 클래스는 IP주소를 분류하는 기준으로 사용된다. IP 클래스의 구조는 네트워크 ID와 호스트 ID로 분류할 수 있는데 네트워크 ID는 네트워크에 부여될 수 있는 것이고, 호스트 ID는 하나의 네트워크에 부여될 수 있는 호스트 IP 주소의 자릿수이다.
그러므로 최대 32비트에 호스트 ID의 자리가 크면 하나의 네트워크에 많은 수의 컴퓨터에 IP 주소를 부여해서 사용할 수 있는 것이다.
클래스(Class)의 구조
Class A
첫 바이트 7Bit가 네트워크 식별자
한 네트워크에 가장 많은 호스트를 가진다
Class B
14Bit의 네트워크 식별자
한 네트워크에 약 2의 16승 대의 호스트 수용
Class C
세 번째 바이트까지 네트워크 식별자
한 네트워크에 256대까지 수용
Class D
멀티캐스트 주소로 사용
서브넷팅(Subnetting)
주어진 네트워크 주소를 작게 나누어 여러 개의 서브넷(논리적)으로 구성된다.
네트워크 식별자 부분을 구분하기 위한 Mask를 서브넷 마스크(Subnet Mask)라고 한다.
서브넷팅 예제
일반적으로 Class C를 두 빝의 서브넷 마스크로 사용하여 구성하면 다음과 같다
Class C인 203.252.63 네트워크를 할당 받은 기관에서 6개의 서브 네트워크를 구성한다.
서브넷 ID가 모두 0인 것과 1인 서브넷은 특수 주소로 제외된다.
총 8개의 서브넷이 필요하다.
CIDR(Classless Inter-Domain Routing) 표기법
'o/n'으로 표시하고 n 비트만큼 네트워크 주소를 의미하고 나머지 비트는 호스트 주소이다. 예를 들어200.10.100/24로 표시하는 네트워크 주소는 256.255.255.0의 C 클래스 주소를 의미한다. 즉 24라는 값은 서브넷 마스크 값에서 1로 설정된 1의 수를 의미하며 1의 수는 왼쪽부터 설정한다. 즉255.255.255.0은1111111.111111111.11111111.0000000000로 1의 개수가 24개이다.
라우팅(Routing)
라우팅 개요
Internetwork를 통해서 데이터를 근원지에서 목적지로 전달하는 기능이다
경로 설정에서 최단 경로 선정 및 전송을 수행하는 포워딩(Forwarding)을 한다.
목적지에 대한 경로 정보(Routing Table)을 인접한 라우터들과 교환하기 위한 규약이다.
정적 라우팅과 동적 라우팅
라우터는 IP 헤더에서 목적지의 IP주소를 읽어서 경로를 결정하는 작업이다. 이러한 경로를 결정할 때 사전에 미리 고정한 정적 경로(Static Routing) 방법이 있고, 네트워크의 상태를 파악헤서 최적의 경로를 결정하는 동적 경로(Dynamic Routing) 방법이 있다.
정적 경로의 방식의 경우, 경로 설정이 실시간으로 이루어지지 않기 때문에 초기에 관리자가 다양한 라우팅 정보를 분석하여 최적의 경로 설정이 가능하며, 라우터의 직접적인 처리 부하를 감소시킬 수 있어서 비교적 환경 변화가 적은 형태의 네트워크에 적합하다.
동적 경로 방식의 경우 경로 설정이 실시간으로 이루어지기 때문에 네트워크 환경 변화에 능동적인 대처가 가능하며, 라우팅 알고리즘을 통해 자동으로 경로 설정이 이루어지며, 수시로 환경이 변화되는 형태의 네트워크에 적합한 방법이 있다.
라우팅 경로 고정 여부에 따른 라우팅 프로토콜의 종류
정적 경로(Static Routing)
관리자가 라우팅 테이블을 직접 경로 설정, 경로가 고정적이며, 수동으로 갱신하는 방식
기법 : Floating Static Rounting 등
동적 경로(Dynmaic Routing)
네트워크 관리자의 개입 없이 네트워크 상황 변화에 따라 인접 라우터 간에 자동으로 경로 정보를 교환 설정
경로 정보를 교환하며 최적의 경로를 결정 및 상황에 따른 능동 대처가 가능
기법 : Delance Vector Routing , Linked State Routing
IGP와 EGP 라우팅 프로토콜
라우팅 프로토콜은 경로를 결정하는 알고리즘을 포함한 프로토콜이며, 한 도메인 내에서 경로를 결정하는 IGP(In-ternal Gateway routing Protocol)와 도메인 간 경로를 결정하는 EGP(Exterior Gateway routing Protocol)로 분류된다.
라우팅 범위에 따른 라우팅 프로토콜의 종류
IGP(Internal Gateway Rounting Protocol)
동일 그룹(기업 또는 ISP(Internet Service Provider) 내에서 라우팅 정보를 교환
EGP(Exterior Gateway Routing Protocol)
다른 그룹과의 라우팅 정보를 교환
라우팅 프로토콜의 종류
Distance Vector와 Link State
라우팅 프로토콜 중에서 Distance Vector는 경로를 결정할 때 통과하는 라우터의 수가 적은 쪽으로 경로를 정하는 방법이다. 일명 홉 카운터(Hop Count) 또는 TTL(TTL(Time to Live)이라고 한다. 이것은 도로에서 교차로가 적은 경우 빠르게 도착하는 이유와 같은 것이다. Distance Vector는 RIP, IGRP, EIGRP, BGP의 프로토콜이 존재한다.
Link State 기법은 네트워크 대역폭, 지연 정보 등을 종합적으로 고려해 Cost를 산정하고 해당 Link와 Cost에 따라 경로를 결정하는 방법으로 대표적으로 OSFP가 있다. 이러한 기법은 주기적으로 지연과 같은 정보를 라우팅에 공유해야 하고 이것은 라우터 브로드캐스트를 통해서 공유한다.
OSPF는 라우터들을 트리 형태의 자료 구조처럼 연결하고 라우터 간에 정보를 공유한다. OSPF는 대규모 네트워크에서 사용되는 라우팅 프로토콜이고 구조가 복잡한 특성이 있다.
BGP(Border Gateway Protocol)
인터넷에서 많이 사용되는 외부 라우팅 프로토콜를 서로 다른 자율 시스템(AS: Autonomous System)에서 동작하는 라우팅 프로토콜이다. 즉 자율 시스템 간의 라우팅 프로토콜이다,
Distance Vector 방식과 Link State 방식의 차이점
Distance Vector
알고리즘 :
최단 경로(Shorter Path)를 구하는 벨만 포드(Bellman-Ford) 알고리즘 기반
동작 원리
네트워크 변화 발생 시 해당 정보를 인접한 라우터에 정기적으로 전달하고, 인접 라우터에서 라우팅 테이블에 정보 갱신
라우팅 정보 : 모든 라우터까지의 거리 정보 보관
정보 전송 시점 : 일정 주기(30초, 이웃 라우터와 공유)
대표 프로토콜 : RIP, IGRP, EIGRP(내부 라우팅), BGP
단점
변화되는 라우팅 정보를 모든 라우터에서 주기적으로 갱신하므로 망 자체의 트래픽을 유발
라우팅 정보를 변경하는 문제 발생 시 Routing Loop가 발생할 가능성이 있다.
RIP(Routing Information Protocol)
RIP 개요
RIP는 거리 벡터 기반의 라우팅 프로토콜로 목적지까지 경로를 결정할 때 통과해야 하는 라우터의 수가 적은 쪽으로 경로를 결정하는 것이다. 통과해야 하는 라우터 수를 홉수(Hop Count)라고 하고 만약 홉 수가 16Hop을 넘으면 패킷을 폐기한다. RIP는 라우팅 테이블을 유지하며 네트워크 상태 정보를 보유해야 한다. 이를 위해서 RIP는 30초 단위로 RIP 브로드캐스팅(Broadcasting)을 통해서 라우팅 테이블을 관리한다.
RIP의 주요 특징
개념
RFC 1058에 정의 되어있고 대표적인 거리 벡터 라우팅 프로토콜
동작 원리
라우터 간 거리 계산을 위한 척도로 홉 수(Hop Count)를 사용
16Hop 이상이면 패킷을 폐기
180초 이내에 새로운 라우팅 정보가 수신되지 않으면 해당 경로를 이상 상태로 간주
수신된 목적지의 거리 값과 현재 거리 값을 비교하여 작은 것을 기준으로 라우팅 테이블을 변경
라우팅 정보
라우팅 정보 변경 시 모든 망에 적용하므로 큰 규모의 양에는 적합하지 않는다.
라우팅 테이블
윈도우 시스템에서 라우팅 테이블의 확인은 nestat 명령어에서 -r 옵션으로 확인이 가능하다
netstat-r이외에도 윈도우에서 route PRINT 명령어로 라우팅 테이블에 대한 확인이 가능하다.
OSPF(Open Shorest Path First)
OFPF는 대규모 네트워크에서 사용하는 라우팅 알고리즘으로 링크 상태(Link State) 알고리즘을 사용한다. 링크 상태 알고리즘은 네트워크의 대역폭과 지연 정도, 흡수 등을 종합적으로 고려하여 최단 경로를 결정하는 것이다. 라우팅 알고리즘은 다익스트라가 제안한 최단 경로 알고리즘을 사용하고 최단 경로는 링크의 비용에 따라 결정된다.
OSPF 개념 및 특징
RFC 1247에 정의되어 있는 IP 라우팅 프로토콜
대규모 IP망에서 사용되며 Link State과 Routing Protocol이다
링크에서의 전송 시간을 링크 비용으로 사용하여 각 목적지별 최단 경로를 구한다.
네트워크에 변화가 발생했을 때 상대적으로 짧고 간단한 링크 상태 정보를 교환
OSPF 동작 원리
링크(Link)의 지연(Delay), 처리량(Throughout), 신뢰성(Relibability) 정보를 이용
네트워크를 Area를 구분하여 많은 라우팅 정보의 교환으로 인한 라우팅의 성능 저하를 예방하고 대역폭을 절약
링크 변화 갑지 시 변경된 링크에 대한 정보만을 즉시 모든 라우터에 전달하여 빠르게 라우팅 테이블)을 갱신
OSPF 계위
OSPF는 라우팅 계위를 만들어 라우팅을 수행한다. 라우팅 계위는 OSPF에서 관리하는 라우터들 간의 그 역할을 정의한 것이다. 예를 들어 경계 라우터(Boundary Router)는 다른 네트워크로 전달되는 패킷의 경로를 결정하는 것이다. 백본(Backbone) 라우터는 영역(Area)는 라우터 간 중계 역할을 수행한다.
OSPF의 동작 원리 구성도
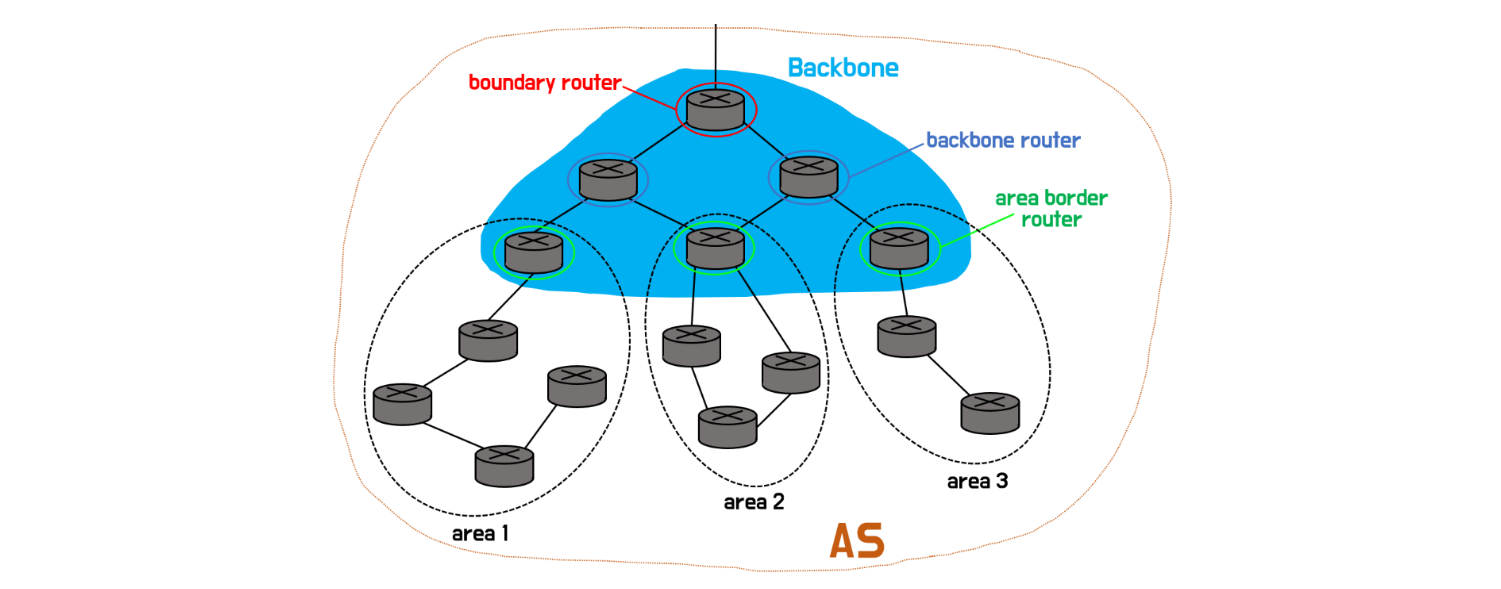
ABR(Area Border Router, 영역 경계 라우터) : Area에 백본망을 연결해주는 라우터
ASBR(Autonomous System Boundary Router, 자율 시스템 경계 라우터) : 다른 AS(Autonomous System)에 속한 라우터와 경로 정보를 교환
IR(Interal Router, 내부 라우터) : Area에 접속한 라우터
BR(Backbone Router, 백본 라우터) : 백본망에 접속한 모든 라우터
ICMP(Internet Control Message Protocol)
ICMP 개요
TCP/IP에서 오류를 제어하는 프로토콜이다
호스트 및 라우터는 다른 호스트나 라우터가 현재 도달 가능한지의 여부를 결정한다.
라우터는 특정 목적지 네트워크로 후속 IP 데이터그램을 보내는 데 사용할 수 있는 더 좋은 경로가 있음을 근원지 호스트에게 통지한다.
호스트나 라우터는 그들이 처리하기 너무 빠른 IP 데이터그램이 도착하면 이를 다른 시스템에게 통보한다.
ICMP의 주요 기능
IP 패킷 처리 도중 발견된 문제를 보고한다.
다른 호스트로부터 특정 정보를 획득하기 위해 사용한다.
TCP/IP 프로토콜에서 두 호스트 간에 에러 처리를 담당한다.
통신이 정상적으로 이루어지는지 확인한다.
ICMP 메시지 구조

Type: ICMP 메시지 유형 표시
Code : Type과 같이 사용되며 세부적인 유형을 표현
Check Sum : IP Datagram Checksum
ICMP 메시지의 종류
3, Destination Unreachable
Router가 목적지를 찾지 못할 경우 보내는 메시지
4, Source Quench
패킷을 너무 빨리 보내 네트워크에 무리를 주는 호스트를 제지할 때 사용
5, Redirection
패킷 Routing 경로를 수정, Smurf 공격에서 사용
8 or 10, Echo Request or Reply
Host의 존재를 확인
11 , Time Exceeded
패킷을 보냈으나 시간이 경과하여 Packet이 삭제되었을 때 보내는 메시지
12, Parameter Problem
IP Header Field에 잘못된 정보가 있다는 것을 알림
13 or 14, Timestamp Request and Reply
Echo와 비슷하나 시간에 대한 정보가 추가
TTL(Time To Live)의 역할
ICMP는 TTL이 설정된다. TTL 값은 라우터를 통과할 때마다 1씩 감소하게 된다.
TTL이 0이 되면 패킷(Packet)은 자동으로 폐기된다.
패킷이 정해진 시간 내에 도착하지 않으면 ICMP는 시간초과(Time Exceed) 메시지를 보고한다.
데이터 전송 방식
데이터 전송 방식은 송신자와 수신자 간에 어떻게 데이터를 보낼 것인지를 의미한다. 즉, 1대 1로 데이터를 전송하는 것은 유니캐스트(Unicast)이고 1대 N으로 모두에게 전송하는 것은 전송하는 것은 브로드캐스트(Broadcast)라고 한다. 멀티캐스트(Multicast)는 1:N 전송에서 특정 사용자에게만 데이터를 전송하는 방식이다.
데이터 전송 방식
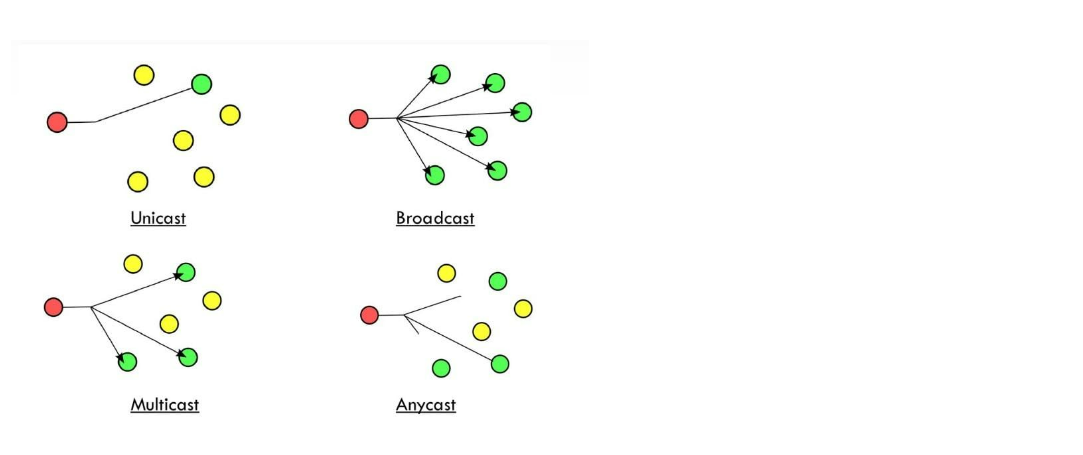
Unicast
1:1 전송 방식
Broadcast
1:N 전송 방식
(동일한 서브넷 상의 모든 수신자에게 전송)
Multicast
M:N 전송 방식
(하나 이상의 송신자들이 특정 그룹의 수신자에게 전송)
Anycast는 IPv6에 새롭게 등장하는 것으로 그룹에 등록된 노드 중에서 최단 경로 노드 한 개에만 전송하는 기술이다. 그리고 IPv6부터 Broadcast가 없어졌다.
멀티캐스트와 IGMP
멀티캐스트 개요
멀티캐스트 그룹에 등록된 사용자에게만 데이터를 전송하는 것이다. 그럼 그룹에 등록된 사용자를 관리해야 하는데 등록된 사용자를 관리하는 프로토콜이 IGMP이다.
IGMP 특징
멀티캐스트 시에 멀티캐스트에 참석하는 수신자 정보를 제공한다.
1대 N 방식으로 멀티캐스트 그룹에 메시지를 전송한다.
호스트와 라우터 사이에 이루어지며 TTL(Time To Live)이 제공된다.
시작 호스트에서 수신을 받을 목적지 호스트들에게 메시지를 전송한다.
IGMP 메시지 구조
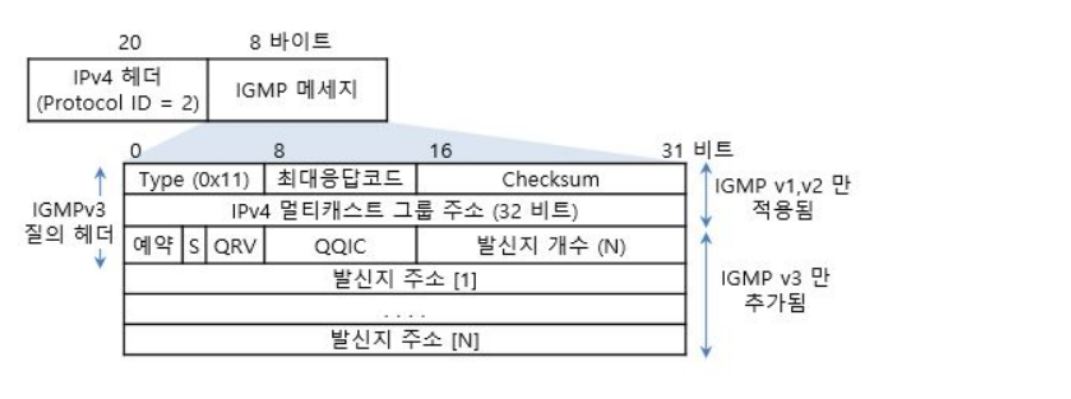
8Byte로 구성된다.
Version : IGMP 프로토콜의 버전 표시, 현재 IGMP Version 2이다.
Type : 메시지 유형, 1=보고, 2=질의 메시지이다.
Group id : 보고메시지의 경우 호스트에서 신규 가입하고자 하는 멀티캐스트 서비스의 group id이다.
NAT(Network Address Translation)
NAT 개요
사설 IP를 라우팅이 될 수 있는 공인 IP로 변경하는 주소 변환을 NAT이라고 한다.
NAT 장점
공인 IP 부족 해결 : 내부 방에서는 사설 IP. 외부 망에서는 공인 IP를 사용한다.
보안성 : 내부를 사설망으로 해서 공인 망으로부터 보호한다.
ISP(Internet Service Provider) 변경에 따른 내부 IP 변경을 최소화한다.
NAT의 종류
Normal NAT
N개의 사설 IP를 한 개의 공인 IP로 변환
Reverse NAT(Static)
Normal NAT 설정만으로 외부에서 내부 네트워크 로 접속할 수 있다.
Normal NAT로 설정된 외부 IP로 요청하여 N개의 사설 IP의 어떤 값에 매핑할 수 없다.
이러한 경우 Reverse NAT는 1:1 매핑, Static 매핑
Redirect NAT
목적지 주소를 재 지정할 경우 사용(장애시 사용)
Exclude NAT
특정 목적지로 접속할 경우 설정된 NAT를 적용 받지 않도록 할 때 사용
Dynamic NAT
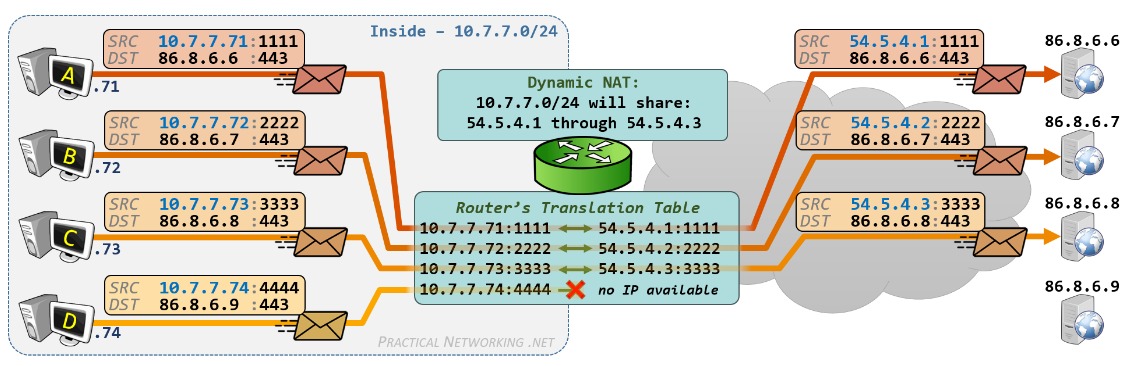
내부의 사설 IP가 라우터 혹은 NAT 소프트웨어에 의해서 미리 정해진 공인 IP로 랜덤하게 매핑되는 방법이다. 정해진 공인 IP가 모두 사용 중일 경우 나머지 사설 IP는 공인 IP로 사용할 수 없다.
Static NAT
특정 사설 IP가 특정 공인 IP만 사용하도록 관리자가 미리 지정하는 방법
PAT
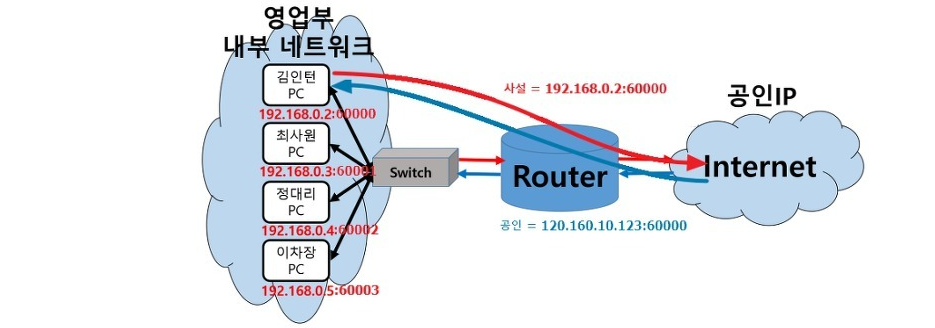
Static NAT 및 Dynamic NAT의 경우 사용할 수 있는 공인 IP보다 사설 IP의 수가 많다면 부족한 만큼 외부로 나갈 수 없는 사설 IP가 많아진다. 하지만 PAT는 포트 변환을 통해서 공인 IP 하나만 있어도 많은 수의 사설 IP가 외부로 나갈 수 있음. 즉 사설 IP들은 각각 포트를 다르게 사용한다.
ARP
ARP 개요
ARP 프로토콜은 IP 주소를 물리적인 하드웨어 주소인 MAC 주소로 변경하는 프로토콜이다. ARP Request와 ARP Reply을 통해서 ARP Cache Table을 유지해서 인접 컴퓨터의 IP주소와 MAC 주소를 가지고 있게 된다.
인터넷 주소(IP)를 물리적 하드웨어 주소(MAC)로 매핑한다.
IP주소와 이에 해당하는 물리적 네트워크 주소 정보는 각 IP 호스트의 ARP 캐시라 불리는 메모리에 테이블 형태로 저장된 후 다음 패킷 전송 시에 다시 사용한다.
ARP Cache Table은 MAC 주소와 IP 주소를 보유하고 있는 매핑 테이블이다.
ARP 동작 방식
실제 네트워크 패킷을 모니터링 해서 ARP 프로토콜이 어떻게 동작하는지 알아보자.
이미지처럼 ARP Request 패킷이 발송되면 ARP Reply으로 응답하고 Opcode는 2가 된다.
ARP Operation Code
1 : ARP Request
2 : ARP Reply
3 : RARP Request
4 : RARP Reply
5 : DRARP Request
6 : DRARP Reply
7 : DRARP Error
8 : InARP Request
9 : InARP Reply
ARP 명령어
RARP
RARP는 Diskless Host에서 사용하는 것으로 이것은 운영체제도 없는 일종의 더미 터미널이다. 더미 터미널에서 자신의 물리적 주소인 MAC 주소를 서버에 전송하고 IP주소를 수신 받아서 기동하는 것이다.
물리적인 주소 MAC를 기반으로 논리적인 주소 IP를 알아오는 프로토콜이다.
하나의 호스트를 RARP 서버로 지정한다.
디스크가 없는 워크스테이션은 RARP Request 패킷을 전송한다.
RARP 서버는 디스크가 없는 워크스테이션들이 물리적 하드웨어 주소(MAC)를 인터넷 주소로 매핑한다.
RARP 서버는 인터넷 주소를 포함한 RARP Response 패킷으로 응답한다.
RARP 요청 메시지는 브로드캐스트 전송하고, RARP 응답 메시지는 유니캐스트로 전송한다(요청 메시지에 송신자의 주소가 포함)
네트워크 접근 계층(Network Access)
네트워크 접근 계층은 LAN 카드의 물리적 주소인 MAC 주소를 가지고 전기적인 비트 신호로 메시지를 전송하는 계층이다.
Physical Layer가 이해할 수 있는 헤더를 붙여주는 Layer, Frame 단위, MAC Address 를 사용하는 계층이다.
통신기가 사이에 연결 및 데이터 전송 기능을 지원한다.
프레임(Frame) 구조
네트워크 접근 계층은 프레임을 단위로 전송한다.
프레임(Frame) 구조
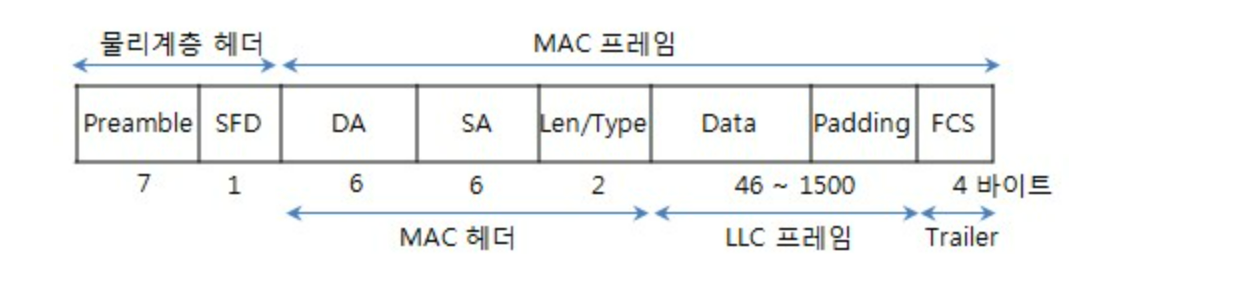
Preamble : 동기화 정보를 가지고 있다.
SOF(Starting Frame Delimiter) : 프레임 시작을 알리는 구분자이다
Destination Address : 수신자(목적지)의 물리적 MAC 주소이다.
Source Address : 송신자의 물리적 MAC 주소이다.
Type : 상위 계층의 프로토콜 종류를 의미한다
PAD : 프레임 길이를 맞추기 위한 영역으로 64Byte 길이를 만족하지 못하면 나머지 부분은 0으로 채워진다
FCS(Frame Check Sequence) : 비트율의 오류를 검사하기 위해서 사용된다.
Section 03. 응용 프로토콜
Telnet과 SSH
Telnet은 원격으로 서버에 로그인하여 작업을 할 때 많이 사용되는 프로그램이다. Telnet은 TCP 프로토콜을 사용해서 원격 연결을 시도하고 포트 번호는 23번 포트를 기본적으로 사용한다.
Telnet은 원격서버에 연결할 때는 사용자 ID와 패스워드를 입력하고 사용자 ID는 패스워드가 올바르면 로그인이 완료된다.
services 파일
리눅스 시스템에서 사용하는 포트 번호는 /etc/services 파일에 등록되어 있다. /etc/services파일을 vi로 열어서 확인해 보면 Telnet 프로그램이 사용하는 포트 번호를 확인할 수 있다. 즉 23번 포트를 사용하고 있으며 사용자가 이 포트번호를 변경할 수 있다. 23번 포트는 이미 알려진 포트이므로 보안을 위해서 의도적으로 알려지지 않은 임의의 포트로 변경된다.
SSH
Telnet의 가장 큰 문제는 통신에서 송신 및 수신되는 모든 데이터가 암호화되지 않은 평문으로 전송되는 것이다. 그렇기 때문에 스니핑(Sniffing)으로 패킷(Packet)을 캡처하면 누구나 모든 내용을 확인할 수 있다. 이에 따라 Telnet을 사용하지 않고 송신 및 수신되는 모든 데이터를 암호화하는 SSH를 많이 사용한다.
SSH를 사용하려면 서버에서 SSH 서비스를 실행시켜 주어야 하는데 이를 실행하기 위해서 service ssh start 명령을 실행한다. 그리고 Putty 프로그램을 사용해서 SSH 연결을 시도한다.
SSH로 연결한 후에 Wireshark라는 스니핑 프로그램으로 패킷을 확인해보면 전송되는 모든 데이터가 암호화되어서 전송되는 것을 확인할 수 있다.
HTTP
우리가 사용하는 인터넷은 HTTP라는 W3C 표준 프로토콜을 사용해서 웹 브라우저와 웹 서버 사이에 메시지를 송신하거나 수신하는 프로토콜이다. HTTP 프로토콜은 개방형 프로토콜(Open Protocol)로 송수신되는 메시지의 구조가 공개되어 있다. 또한 HTTP 프로토콜은 송신과 수신을 할 때 TCP라는 프로토콜을 사용해서 신뢰성 있게 데이터를 송수신한다. 하지만 HTTP 프로토콜은 TCP의 연결을 지속적으로 유지하고 있는 것이 아니라 요청이 있을 때 연결하고 메시지를 처리한 후에 연결을 종료하는 방식이며, 이러한 특성을 State-less 프로토콜이라고 한다.
HTTP 프로토콜은 80번 포트를 사용하고 80번 포트는 오직 root 사용자만 오픈하여 사용할 수 있다. 따라서 서버 관련 프로세스(Process)는 root 사용자의 권한으로 기동된다. 물론 모든 프로세스가 root로 기동되는 것은 아니고 한 개의 프로세스만 root로 기동해서 80번 포트를 점유하고 자식 프로세스를 생성하는 형태로 실행되는 것이다.
HTTP(Hyper Text Transfer Protocol) 쉽게 이해하기
WWW(World Wide Web) 상에서 웹 서버와 사용자의 인터넷 브라우저 사이에 문서를 전송하기 위해서 사용되는 통신 프로토콜이다.
TCP 기반 프로토콜의 80 Port 사용하고 Request 및 Response 구조를 가진다.
State - less로 프로토콜을 구성한다.
HTTP 프로토콜의 구조
HTTP는 Header와 Body로 구분되면 Header와 Body 사이에 개행문자가 존재한다.
개행문자는 "\r\n\r\n"으로 구분된다.
HTTP Request Method
Request Method에서 GET은 URL에 입력 파라미터를 넣어서 요청하는 것이고 POST는 요청 파라미터를 HTTP Body에 넣어서 전송하기 때문에 전송 크기에 제한이 없다. 그리고 Head는 응답 메시지 없이 전송되는 것이고 PUT은 메시지 Body에 데이터를 지정한 URL에 이름이 지정된다. 마치 FTF PUT 기능과 동일하다
DELETE는 서버에서 요구하는 URL에 지정된 자원을 지울 수 있고 TRACE는 요구 메시지가 최종 수신되는 경로를 기록하는 기능으로 사용할 수 있다.
HTTP 요청 방식(Request Method)
Get 방식
서버에서 전달할 때 데이터를 URL에 포함시켜서 요청
전송할 수 있는 데이터의 양이 제한됨(4Kilo byte)
ex. Get Login.php?userid=imbest&password=test
Post 방식
서버에 전달할 때 데이터를 Request Body에 포함시킨다.
데이터 전송량의 제한이 없다
ex.
Post login.php
Userid=imbest:password=test
FTP
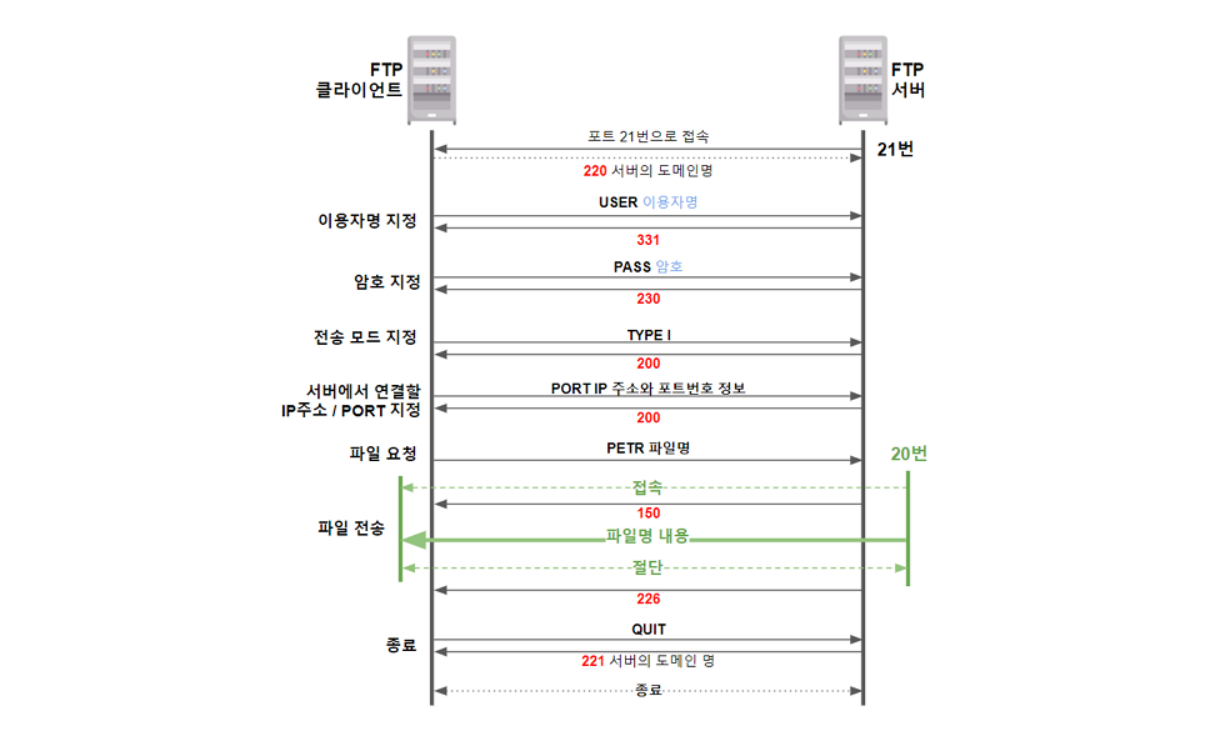
FTP 개요
FTP는 서버(Server)에 파일을 올리거나 다운로드하는 인터넷 표준 프로토콜로 내부적으로 TCP 프로토콜을 사용한다.
FTP는 FTP 클라이언트 프로그램을 사용해서 TCP로 접속하고 접속한 이후에 사용자 ID와 패스워드를 입력 받아 인증을 수행한다.
FTP 특징
FTP의 특징은 포트(Port)를 2개 사용하는 것이다. 즉 USER, PASS, GET 등의 FTP 서버에 전송하기 위한 명령포트(21번 고정)와 실제 파일을 업로드하거나 다운로드하기 위해서 데이터 포트를 사용한다. FTP에서 명령포트는 고정되어 있지만, 데이터 포트는 전송모드에 따라 변하게 된다. 예를 들어 Active Mode인 경우 데이터 포트는 20번을 사용하고 Passive Mode는 FTP 서버가 FTP 서버의 데이터 포트를 결정해서 FTP 클라이언트에게 서버 데이터 포트 번호를 보내준다.
FTP 클라이언트의 데이터 포트는 FTP 클라이언트 자신이 결정한다.
명령 채널과 데이터 전송 채널이 독립적으로 동작한다.
클라이언트가 명령 채널을 통해 서버에게 파일 전송을 요구하면 서버는 데이터 전송 채널을 통해 데이터를 전송하는 방식으로 동작한다.
FTP 로그인 과정
먼저 FTP 서버의 로그인 과정을 간략히 도식화해본다.
FTP 클라이언트느느 FTP 서버를 호출하고 USER와 PASS 명령으로 사용자 ID로 패스워드를 입력한다. FTP 서버는 로그인에 성공하면 응답코드 230번을 FTP 클라이언트에게 전송해서 로그인 성공을 알린다.
FTP 클라이언트 프로그램을 실행해서 devsmile.com이라는 FTP 서버로 접속한다. 그리고 devtest 과 smile@12 패스워드를 입력하고 로그인에 성공한다. 전송 모드를 Passive Mode로 변경하고 get 명령을 실행해서 aa.html 파일을 FTP 클라이언트로 다운로드 받는다.
FTP Active Mode와 Passive Mode
Active Mode
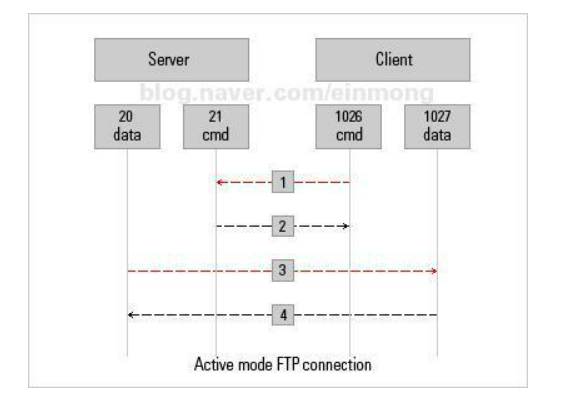
FTP Client에서 FTP Server 21번 포트로 접속
FTP Client에서 FTP Server 20번 포트로 데이터를 전송
Passive Mode
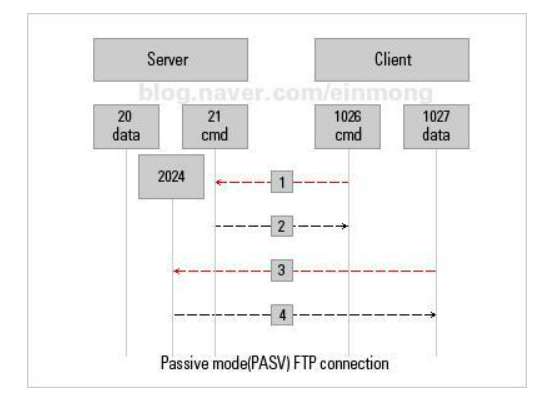
FTP Client에서 FTP server 21번 포트에 접속
FTP Server가 FTP Client로 데이터 송수신을 위해서 1024 ~ 65535 범위의 Random 포트를 선택한다.
FTP Client에서 데이터 송수신을 위해서 Random 포트를 사용
FTP 종류
FTP : ID 및 Password 인증을 수행하고 TCP 프로토콜을 사용하여 사용자의 데이터를 송수신
TFTP : 인증 과정 없이 UDP 기반으로 데이터를 빠르게 송수신한다. 69번 포트 사용
SFTP : 전송 구간에 암호화 기법을 사용하여 기밀성을 제공
DNS
DNS(Domain Name Service)
DNS 개요
인터넷 네트워크 상에서 컴퓨터의 이름을 IP 주소로 변환하거나 해석하는데 사용되는 분산 네이밍 시스템이다.
DNS(Domain Name Service)는 www.naver.com이라는 URL 주소에 대해서 IP 주소를 알려준느 서비스이다.
DNS를 간단하게 확인하는 방법은 nslookup이라는 도구를 사용해서 확인할 수 있다. 다음의 예는 www.naver.com이라는 URL에 대해서 125.209.222.142의 IP 주소를 얻어 온 것이다.
DNS가 어떻게 이름을 풀어내는지 확인해본다. DNS를 먼저 DNS Cache 테이블에서 이름을 해것한다.
만약 DNS Cache 테이블이 없으면 hosts 파일을 사용해서 이름을 해석한다.
hosts 파일에서도 해당 URL에 대한 IP 주소가 없으면 DNS 서버에서 해석을 의뢰하고 이것을 순환쿼리(Recursive Query)라고 한다. DNS 서버는 DNS Cache 테이블을 유지하고 있기 때문에 DNS 서버의 Cache 테이블에 등록되어 있으면 바로 IP 주소를 DNS Response 메시지로 전달한다.
만약 DNS가 이름을 해석할 수 없다면 다음과 같이 Top Level 도메인부터 Second Level로 이름 해석을 의뢰하고 이것을 반복쿼리(Iterative Query)라고 한다.
DNS 구조
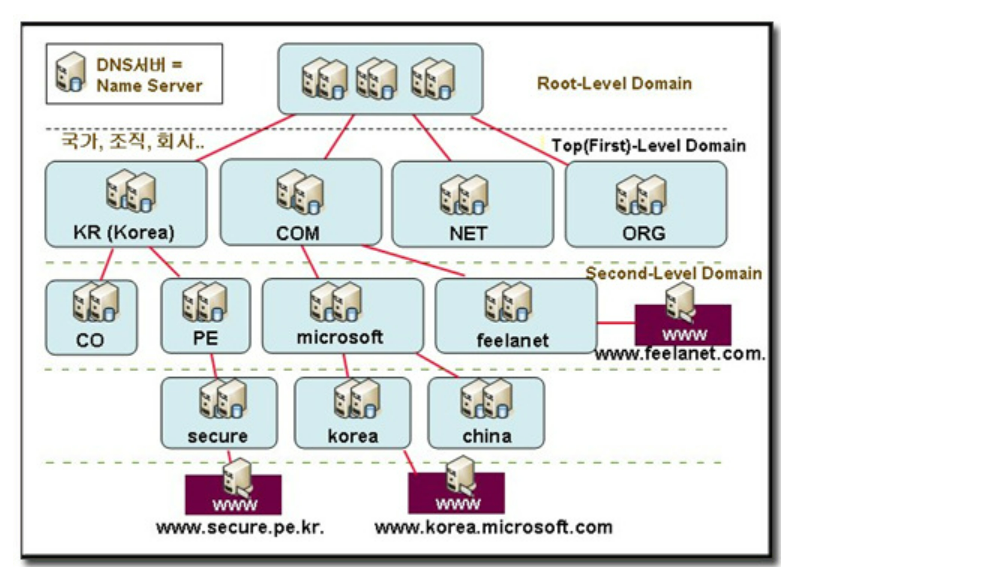
Root Domain() : 모든 도메인의 근본이 되는 최상 Root Level Domain
Top Level Domain : com, org, kr 등 국가, 지역을 나타낸다
Second Level : 사용자가 도메인 명을 신청해서 등록할 수 있는 영역
DNS 서비스 방식
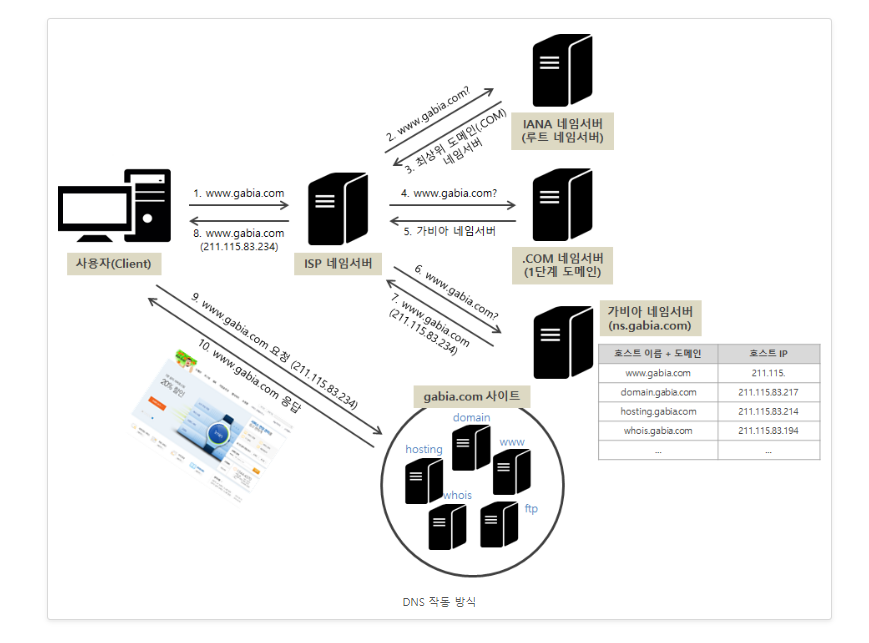
DNS Query의 종류
Recursive Query(순환쿼리) : Local DNS 서버에 Query를 보내 완성된 답을 요청한다.
Iterative Query(반복쿼리) : Local DNS 서버가 다른 DNS 서버에게 Query를 보내어 답을 요청하고, 외부 도메인에서 개별적인 작업을 통해 정보를 얻어와 종합해서 알려준다.
DNS Query
DNS 레코드
그럼, 실제 DNS에 어떻게 Query를 요청하고 응답되는지 확인해보자
DNS 서버에 요청은 클라이언트가 UDP로 DNS Request를 DNS Server에 전송한다. DNS Request를 보낼 때 type이라는 필드에 요청하는 레코드의 구분자를 넣는다. 즉 A는 IPv4 주소를 요청한다는 것이고, AAAA은 IPv6 주소를 요청한다는 의미이다.
DNS 서버는 DNS Request에 대해서 DNS Request로 응답한다. DNS Response은 요청한 IP 주소를 넣어서 보내준다.
DNS 레코드의 종류
Address :
단일 호스트의 이름에 해당하는 IP주소가 여러 개 있을 수 있으며, 각각의 동일한 IP 주소에 해당되는 여러 개의 호스트 이름이 있을 수 있다. 이때 사용되는 레코드가 A(Address)임(호스트 이름을 IPv4주소로 매핑)
AAAA(IPv6 주소)
호스트 이름을 IPv6 주소로 매핑
PTR(Ponter)
특수 이름이 도메인의 일부 다른 위치를 가리킬 수 있다.
인터넷의 주호의 PTR 레코드는 정확히 1개만 있어야 한다.
역방향 조회때 사용
NS(Name Server)
도메인에는 해당 이름 서비스 레코드가 적어도 한 개 이상 있어야 하며 DNS 서버를 가리킨다.
MX(Mail Exchange)
도메인 이름으로 보낸 메일을 받도록 구성되는 호스트 목록을 지정
CNAME(Canonical Name)
호스트의 다른 이름을 정의하는데 사용
SOA(Start of Authority)
도메인에 대한 권한을 갖는 서버를 표시한다
도메인에서 가장 큰 권한을 부여 받은 호스트를 선언
Any(ALL)
위의 모든 레코드를 표시
SMTP(Simple Mail Transfer Protocol)
SMTP 개요
RFC 821에 명시되어 있는 인터넷 전자 우편 프로토콜이다.
Store - and - Forward 방식으로 메시지를 전달한다.
SMTP 기본 동작 방식
SMTP는 전자우편을 전송하는 프로토콜이다.
메일 서버는 수신자의 전자우편 주소를 분석하고 최단 경로를 찾아 근접한 메일 서버에서 편지를 전달한다.
최종 수신자 측 메일 서버에 도착하기까지 연속적으로 전달하는 중계 작업을 수행한다.
SMTP 구성 요소
MTA(Mail Transfer Agent) : 메일을 전송하는 서버
MDA(Mail Delivery Agent) : 수신 측 고용된 우체부의 역할, MTA에게 받은 메일을 사용자에게 전달
MUA(Mail User Agent) : 사용자들이 사용하는 클라이언트 애플리케이션
POP3와 IMAP 및 IMAP3
POP3
TCP 110번으로 메일 서버에 접속하여 저장된 메일을 내려 받는 MDA 프로그램
메시지를 읽은 후 메일 서버에서 해당 메일을 삭제한다
IMAP 및 IMAP3
POP과 달리 메일을 내려받아도 메일 서버에 원본을 계속 저장
IMAP 143 Port
SNMP(Simple Network Management Protocol)
SNMP 개요
운영되는 네트워크의 안정성, 효율성을 높이기 위해서 구성, 장애, 통계, 상태 정보를 실시간으로 수집 및 분석하는 네트워크 관리 시스템이다.
NMS(Network Management System)는 SNMP 프로토콜을 사용해서 네트워크 정보를 수집한다.
SNMP 동작 방식
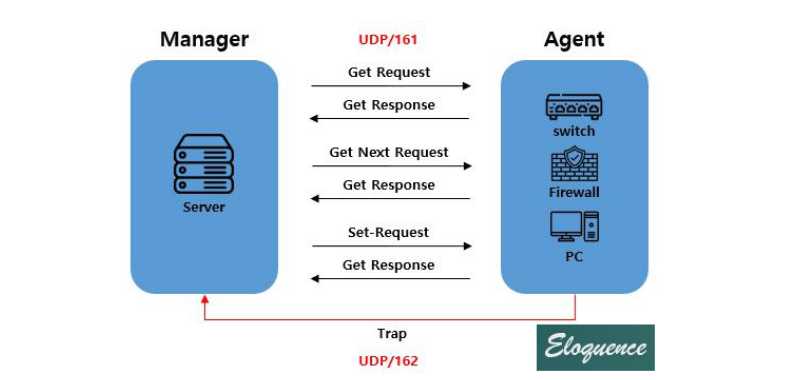
MIB(Management Information Base)는 SNMP에서 모니터링해야 하는 객체(Object) 정보를 가지고 있다.
SNMP 명령어
Get : 장비의 상태 및 기동 시간 등의 관리 정보를 읽기
Get - Next : 정보가 계층적 구조를 가지므로 관리자가 장비에 조회를 해서 해당 트리보다 하위 층 정보를 읽기
Set : 장비 MIB를 조작하여 장비 제어, 관리자는 요청을 보내 초기화 혹은 장비 재구성
Trap : 관리자에게 보고하는 Event, Agent는 경고, 고장 통지 등 미리 설정된 유형의 보고서를 생성
DHCP(Dynamic Host Configuration Protocol)
DHCP 개요
IP 주소와 서브넷 마스크, 게이트위에 주소 등을 고정하지 않고 네트워크에 처음 연결될 때 동적으로 설정된다.
DHCP는 IP 주소를 동적으로 할당하는 표준 프로토콜이다.
DHCP 기능
DHCP 서버가 관리하는 주소 목록에서 접속한 컴퓨터 시스템에 IP 주소를 할당한다.
기업 내의 IP 주소를 중앙에서 관리하는 프로토콜이다.
임대 DHCP는 DHCP로 할당한 IP 주소를 일정한 시간 동안만 사용하게 된다.
DHCP 서버가 관리하는 IP 주소보다 더 많은 컴퓨터 시스템이 접속하면 임대 DHCP를 사용해서 특정한 시간 동안만 IP 주소를 사용하게 한다.
DHCP Protocol 동작 방법
Client
1. DHCP
DHCP Discover 메시지를 브로드 캐스트하여 DHCP server를 검색
3. DHCP Request
PC는 IP 주소를 임대하기 위해 브로드캐스팅을 통해 DHCP Server에게 IP 주소를 요청, 브로드캐스트로 요청하기 때문에 서브넷에 있는 PC와 서버에게 요청하게 된다.
DHCP Server
2. DHCP Offer
자신의 IP를 알려주고 PC에게 임의의 IP주소를 할당해 줄 수 있다는 메시지를 전달하기 위해 브로드캐스팅으로 만든 PC에게 전달
4. DHCP ACK
PC에게 임대용 IP 주소와 임대 기간을 정해 전송함 브로드캐스팅 방식과 유니캐스팅 방식을 사용할 수 있다. Flag =1은 브로드캐스트 Flag = 0은 유니캐스트이다.
PART 03. NOS(Network Operating System)
Section 01. 윈도우 시스템
윈도우 시스템
01. 윈도우 시스템 개요
윈도우 운영체제는 과거 단일 사용자 운영체제인 DOS로부터 시작되었으며 현재는 GUI(Graph Usr Interface) 및 다중 사용자, 다중 프로세스 구조를 지원하는 운영체제이다. 윈도우는 손쉬운 사용자 인터페이스로 개인용 PC에 가장 많이 사용된다.
02. 윈도우 시스템 내부 내용
윈도우 운영체제는 다양한 하드웨어를 자동으로 인식하여 사용할 수 있는 Plug & Play 기능 하드웨어를 표준화된 인터페이스를 통해서 개발하면 윈도우의 HAL(Hardeare Abstraction Layer) 계층이 하드웨어를 인식하게 된다. 이러한 하드웨어는 윈도우의 운영체제에 해당하는 Micro Kernel이 관리하게 된다.
HAL(Hardware Abstraction Layer :
새로운 하드웨어가 개발되어 시스템에 장착되어도 드라이버 개발자가 HAL 표준을 준수하면 하드웨어와 시스템 간 원활한 통신이 가능
Micro Kernell :
Manager에게 작업을 분담시키고 하드웨어를 제어
IO Manager :
시스템 입출력을 제어, 장치 드라이버 사이에서 메시지를 전달, 응용 프로그램이 하드웨어와 통신할 수 있는 통로를 제공
Object Manager :
파일, 포트, 프로세스, 스레드와 같은 각 객체에 대한 정보를 제공
Security Reference Manager:
데이터 및 시스템 자원의 제어를 허가 및 거부함으로써 강제적으로 시스템의 보안 설정을 책임짐
Process Manager :
프로세스 및 스레드를 생성하고 요청에 따른 작업을 처리
Local Procedure Call :
프로세스는 서로의 메모리 공간을 침범하지 못하기 때문에 프로세스 간에 통신이 필요한 경우 이를 처리하는 장치
Virtual Memory Manager :
응용 프로그램의 요청에 따라 RAM 메모리를 할당, 가상 메모리의 Paging을 제어
Win32/64 Sub System :
윈도우의 기본 서버 시스템, 32비트 및 64비트 응용 프로그램이 동작할 수 있도록 지원한다.
POSIX :
유닉스 운영체제에 기반을 두고 있는 일련의 표준 운영체제 인터페이스
Security Sub System :
사용자가 로그인 할 떄 데이터를 보호하고 운영체제가 이를 제어할 수 있도록 만든 서브 시스템
03. 윈도우 파일 시스템
윈도우 파일 시스템의 경우 FAT(File Allocation Table)과 NTFS(NT File System)를 지원한다. FAT는 과거 DOS를 기반으로 하는 파일 시스템으로 작은 파일 시스템에 사용되고 NTFS는 대용량 파일과 긴 파일명, 압축, 저널링 정보를 통한 오류 처리 등을 지원한다.
윈도우 파일 시스템
FAT(File Allocation Table
FAT16
도스(DOS)와 윈도우 95의 첫 버전으로 최대 디스크 지원 용량이 2G
NTFS, FAT로 변경, 변환 가능
FAT32
2G 이상의 파티션 지원 및 대용량 디스크 지원 가능
NTFS로 변환(Convert) 가능, FAT로 변경로 변경 변환은 불가능하다
사용되는 OS : 윈도우 95 OSR2, 윈도우 98, 윈도우 2000, 윈도우 XP
NTFS(NT File System)
파일 암호화(File Encryption) 및 파일 레벨 보안 지원
디스크 압축 및 파티션 단위로 쿼터(Quota) 지원
FAT16이나 FAT32로 변환 불가능하다.
사용되는 운영체제 : 윈도우 NT, 윈도우 2000, 윈도우 XP
긴 파일명 지원 및 저널링 시스템을 지원한다.
계정 관리
01. 윈도우 계정 관리(Account Management)
(1) 계정 관리 개요
윈도우 계정 관리는 윈도우 운영체제의 사용자를 생성하거나 패스워드를 설정하고 접근 권한 등을 할당 및 해제한다.
(2) 윈도우 계정 관리 특징
윈도우 운영체제는 다중 사용자(Multi User)를 지원한다. 다중 사용자를 위해서 사용자 계정을 생성, 변경, 삭제할 수 있다.
윈도우 계정은 내장 사용자 계정, 로컬 사용자 계정, 도메인 사용자 계정으로 분류되고 관리한다.
로컬 사용자 계정은 사용자가 생성한 계정으로 그룹에 의해서 관리할 수 있다.
(3) 윈도우 계정 관리 활동
사용자 별로 1인 1ID를 할당하고 관리해야 한다.
패스워드 작성 규칙을 3가지(영문 소문자, 영문 대문자, 숫자, 특수문자) 이상 조합하여 8자 이상 설정 또는 2가지 이상 조합하여 10자 이상으로 패스워드를 설정하도록 한다.
주기적으로 사용자 패스워드를 변경하게 한다.
사용자 계정에 맞는 권한을 할당하여 통제해야 한다.
(4) 윈도우 계정의 종류
1) 내장 사용자 계정(Built in User Account)
윈도우 운영체제를 설치하면 기본적으로 생성되는 계정이다.
Administrator(관리자) 계정은 자동으로 생성되고 관리자 계정은 삭제할 수 없다.
Guest, IUSER_XXX, IWAM_XXX 등의 계정이 있다.
2) 로컬 사용자 계정(Local User Account)
로컬 사용자 계정은 윈도우 운영체제로 로그인하는 계정이다.
로컬 사용자 계정은 해당 윈도우 운영체제로마 로그인을 한다.
3) 도메인 사용자 계정(Domain User Account)
윈도우 운영체제에 로그인할 때 Active Directory에 관리하는 도메인 콘트롤러(Domain Controller)로 인증 후 로그인 한다.
윈도우 서버에 도메인 컨트롤러가 설정되어야 한다.
4) 윈도우 서버의 내장형 계정
Administrators :
윈도우 시스템을 관리하고 모든 권한을 가지고 있다
삭제할 수 없는 계정
Guest :
익명의 사용자 접속을 허용할 때 사용
관리자에 의해서 허락된 자원에 대해서 접근만 가능
IUSR_XXX :
웹을 사용해서 익명으로 접속
ISS 서버에서 제공하는 웹 사이트에 접속
IWAM_XXX :
ISS 서버의 홈페이지를 실행시킬 때 사용하는 계정
- 윈도우 그룹 관리(Group Management)
(1) 그룹 관리 개요
사용자 권한 관리를 위해서 그룹을 생성하고 해당 그룹으로 사용자를 묶는다.
그룹에 권한을 부여하거나 해제하여 권한 관리를 한다
(2) 내장형 그룹 종류
Administrators :
관리자와 동등한 권한을 가진 그룹
시스템 전체에 대한 관리가 가능
Backup Operators :
윈도우 백업을 이용하여 모든 도메인의 컨트롤러에 있는 파일과 폴더를 백업하고 복구할 수 있는 권한이 있다.
Power Users :
그 컴퓨터에서 로컬 사용자 계정을 생성하고 수정할 수 있는 권한을 갖고 있으며 지원을 공유하거나 멈출 수 있다.
시스템에 대한 전체 권한은 없으나 시스템 관리를 할 수 있는 권한이 부여된 그룹
Users :
기본적인 권한은 가지고 있지 않다
컴퓨터에서 생성되는 로컬 사용자 계정을 포함
Domain Users 글로벌 그룹이 구성원으로 포함
Guests :
관리자에 의해 하락된 자원과 권한 만을 사용하여 네트워크 자원에 접근 가능
Everyone :
시스템에 접근한 모든 사용자를 의미
NTFS 파일 시스템
01. NTFS 파일 시스템 개요
NTFS 파일 시스템은 기존 FAT(File Allocation Table) 파일 시스템을 개선하고 윈도우 서버용으로 사용하기 위해서 개발된 파일 시스템이다.
02. NTFS 파일 시스템의 특징
USN 저널
Update Sequence Number Journal
저널링 기능을 제공하는 것으로 파일 시스템이 변경될 때 그 내용을 기록하여 복구(Rollback) 할 수 있다.
ADS(Alternate Data Stream)
MAC 파일 시스템과 호환성을 위해서 만든 공간으로 다중 데이터 스트림을 지원한다.
Sparse 파일
파일 데이터가 대부분 0일 경우에 실제 데이터 기록 없이 정보를 기록하는 기능
파일 압축
LZ77의 변형된 데이터 압축 알고리즘을 지원
VSS :
Volume Shadow Copy Service
대칭 키 기법으로 파일 데이터를 암호화함
Quotas :
사용자 별 디스크 사용 용량을 제한할 수 있다.
Unicode :
다국어를 지원
동적 Bad 클러스터 할당 :
Bad Sector가 발생한 클러스터를 자동으로 재할당함
대용량 지원 :
2 Tera Byte가 넘는 대용량 볼륨을 지원
공유 폴더
윈도우 공유 폴더 만들기
윈도우의 공유 폴더 기능은 자신의 컴퓨터에 있는 폴더를 다른 컴퓨터와 공유할 수 있는 기능으로 파일을 같이 공유하면서 업무를 처리할 때 아주 유용한 기능이다
자신의 폴더를 공유 폴더로 만드는 방법은 윈도우 탐색기에서 마우스 오른쪽 버튼을 눌러서 누구나 쉽게 공유 폴더를 만들 수 있다.
공유 폴더 확인
공유 폴더를 만들었으며 제대로 공유 폴더가 만들어졌는지 확인해 본다. 공유 폴더 목록 확인은 net share 명령으로 간단하게 확인할 수 있다.
공유 폴더 삭제
이때 생성된 공유 폴더를 삭제해본다. 공유 폴더의 삭제는 /delete 옵션을 사용하면 된다.
윈도우 운영체제는 별다른 설정을 하지 않아도 기본적으로 공유되어 있는 것들이 있다. 그것은 C, IPC는 네트워크 프로그램 간에 통신을 위해서 파이프를 사용하고 네트워크 서버 원격 관리를 위해서 사용된다. 즉, 네트워크 서버를 원격 관리하기 위한 용도로 사용한다.
NETBIOS
컴퓨터상에 있는 애플리케이션들이 근거리 통신망(LAN : Local Area Network) 내에서 서로 통신을 할 수 있게 해주는 프로그램이다. NETBIOS는 그 자체로 라우팅 기능(경로 설정)을 지원하지 않고 광역통신망에서 통신하는 애플리케이션은 반드시 TCP와 같은 다른 Transport 매커니즘을 추가해서 사용해야 한다.
Section 02. 윈도우 서버
윈도우 사용자 계정
01. 내장형 사용자 계정
(1) 계정 관리(Account Management) 개요
내장형 사용자 계정은 윈도우 서버를 설치하면 자동적으로 생성되는 사용자 계정으로 Administrator와 Guest 계정이 있다. Administrator 계정은 모든 윈도우에는 반드시 있어야 하는 계정으로 관리자 권한을 가지고 있다. Administrator 계정은 관리자에 의해서 삭제될 수 없다.
Guest 계정은 윈도우 서버에 로그인할 수 있는 계정으로 최소한의 권한만 가지고 있다. Guest 계정은 자동으로 생성되지만 초기에는 계정이 활성화되어 있지 않기 때문에 사용할 수 없다. 계정 관리에서 Guest 계정을 활성화하면 그 때부터 가능하다.
(2) 계정 관리(Account Management) 기능
윈도우 제어판에서 계정 관리를 실행한다.
현재 생성되어 있는 모든 계정 리스트를 확인할 수 있다.
사용자 계정 추가를 클릭해서 새로운 윈도우 사용자 계정을 생성할 수 있다.
02. 새로운 사용자 생성
(1) 사용자 추가
계정 관리에서 사용자 추가를 하면 새로운 윈도우 계정을 생성할 수 있다. 사용자를 추가하면 사용자 이름, 암호, 암호 힌트를 입력해야 한다. 암호는 암호 정책을 준수해서 입력해야 한다. 즉, 8자 이상을 영문자, 숫자, 특수문자로 입력해야 한다. 물론 암호 정책을 변경하면 단순히 입력할 수도 있다.
마침 버튼을 누르면 Limbest 계정 생성이 완료된다.
(2) 계정 유형 변경
사용자 계정이 생성되고 사용자 계정에서 관리자 권한을 부여하려면 계정 유형 변경을 하면 된다. 계정 유형은 표준과 관리자로 나누어지고, 표준은 PC와 보안 부분에 영향을 주는 변경을 할 수 없고 관리자 계층은 모든 작업을 다 할 수 있는 권한이다.
(3) 사용자 계정 유형
표준(Standard)
소프트웨어를 사용할 수 있지만 시스템이나 보안과 관련 있는 설정은 변경할 수 없다.
관리자(Administor)
관리자는 윈도우 서버를 관리할 수 있는 모든 권한을 가지고 있다.
03. 사용자 프로필
(1) 사용자 프로필 개요
사용자 프로필이란, 윈도우 시스템 사용자들의 설정 및 데이터를 보관하는 데이터이다.
사용자 바탕화면, 응용 프로그램 사용 정보, 시스템 설정 정보 등을 제공한다.
네트워크를 통해서 사용자 프로필을 제공하면 사용자가 사용한 환경을 제공한다.
(2) 사용자 프로필 장점
원격으로 윈도우 서버에 접속하여 저장된 사용자 프로필을 사용할 수 있다.
사용자 프로필을 통해서 항상 일관된 바탕화면 및 설정을 사용할 수 있다.
사용자 프로필 종류
로컬 사용자 프로필
윈도우 시스템에 직접 로그인하는 사용자 정보
사용자 로그인 구성 정보, 인터넷 환경, 바탕 화면 등의 정보를 제공
C:\Documents and Settings\사용자 ID에 저장
로밍 사용자 프로필
사용자 프로필을 윈도우 서버에 저장
사용자 프로필을 사용해서 어떤 윈도우 클라이언트를 사용해도 같은 환경을 제공
강제 사용자 프로필
윈도우 시스템의 바탕화면 및 시스템 환경을 변경할 수 없다.
공통된 환경을 제공한다.
윈도우 서버 관리
01. 컴퓨터 관리
(1) 컴퓨터 관리 개요
개인용 PC에 설치되는 윈도우와 윈도우 서버 모두 컴퓨터 관리라는 프로그램이 있다. 컴퓨터 관리는 윈도우 시스템을 관리하기 위한 대부분의 기능을 포함하고 있다.
(2) 컴퓨터 관리 기능
작업 스케줄러 정해진 기간에 작업을 수행하는 역할을 한다.
이벤트 뷰어는 윈도우에서 발생한 로그 정보를 기록하고 있다.
공유폴더는 폴더 공유를 설정하거나 공유를 해제, 세션을 관리한다.
로컬 사용자 및 그룹은 기본 사용자 및 그룹 리스트를 가지고 있고 새로운 그룹을 생성할 수 있다.
성능은 윈도우 시스템의 CPU 사용률, 메모리 사용률, 디스크 사용률 등을 모니터링 할 수 있다.
장치 관리자는 윈도우 시스템이 사용하는 CPU, Memory, Bus, Disk, NIC 카드, 마우스, 키보드, CDROM 등의 하드웨어를 관리한다.
저장소는 파일 시스템 정보와 디스크 할당에 관한 정보를 알 수 있다.
서비스 및 응용 프로그램은 등록된 서비스와 설치되어 있는 프로그램을 관리한다.
02. 이벤트 뷰(Event View)
(1) 이벤트 뷰 개요
윈도우 이벤트 뷰는 윈도우 시스템 사용에서 발생하는 각종 이벤트 정보를 볼 수 있는 프로그램이다. 이벤트 뷰는 응용 프로그램, 보안, 시스템 이벤트로 분류되어서 애플리케이션 사용, 시스템 부팅 및 종료, 사용자 로그인, 사용자 계정 생성과 같은 로그를 기록하고 있다.
위의 예를 보면 사용자 계정으로 LimBest 사용자 계정을 생성하면 로그 정보가 보안 이벤트에 기록되어 있는 것들을 확인할 수 있다.
(2) 로그 속성 설정
이벤트 정보는 덮어쓰기 형식으로 관리한다. 즉 최대 로그 크기를 초과해서 이벤트가 발생하면 이벤트 정보를 덮어쓴다. 이러한 이벤트 파일명과 최대 로그 크기, 덮어쓰기 옵션을 로그 속성 설정 메뉴에서 설정할 수 있다.
보안 정책
01. 보안 정책 개요
윈도우 서버 보안 정책은 로컬 정책 프로그램을 실행해서 관리할 수 있다. 로컬 보안 정책은 계정에 대한 암호 정책, 계정 잠금 선택, 로컬 정책, 윈도우 방화벽 정책 등을 설정할 수 있다.
02. 암호 정책 관리
계정 정책에서 암호 정책을 클릭하면 암호 복잡성 설정, 최근 암호 기억, 암호 사용 기간 등을 설정할 수 있다.
03. 사용자 권한 할당
사용자 권한 할당은 감사 및 모안 로그 관리, 로컬 로그온, 보안 감사 생성 등을 관리할 수 있는 윈도우 사용자를 설정하는 것이다.
PowerShell
01. PowerShell 개요
리눅스에서 사용하던 셀(Shell)의 기능을 윈도우에서 사용할 수 있도록 셀 기능을 추가했다.
명령 라인(Command line)을 기반으로 시스템 및 서비스 등의 상태를 모니터링할 수 있다.
Microsoft.Net Framework을 기반으로 개발되어서 셀 기능을 지원한다.
과거 DOS와 호환성을 가지고 있으므로 DOS 명령을 사용할 수 있다.
관리자는 쉽게 명령라인으로 윈도우 서버를 관리할 수 있다.
Windows 7부터는 개인용 PC에도 Power Shell을 지원한다.
02. PowerShell의 특징
(1) 파이프라인 지원
파이프라인 문자를 사용해서 첫 번째 명령의 결과를 다음 명령의 입력으로 전달한다.
(2) 자동 탭 완성 기능
리눅스 탭(TAB) 기능을 사용해서 자동 완성 기능을 지원한다.
(3) 다중라인 입력
세미콜론(:)을 사용해서 다중 명령을 실행한다.
(4) .NET Framework 언어
.NET Framework 기반으로 개발되어서 동작한다.
Section 03. IIS 서버
IIS 웹 서버 설치
01. 웹 서버
윈도우 서버에서 IIS(Internet Information Server)라는 웹 서버를 설치한다. IIS는 웹 서버의 역할을 수행하는 Microsoft 사의 프로그램으로 ASP(Active Server Page)라는 스크립트를 지원하며 .NET Framework를 기반으로 개발되어 있다.
웹 서버(Web Server)는 무엇인가
웹 브라우저는 HTML 문서를 보여주는 프로그램이다. HTML 문서는 태그(Tag) 형식으로 되어 있어서 "임베스트" 형태로 되어 있다. 웹 서버는 웹 브라우저와 이러한 HTML 형식 문서를 송신하고 프로그램이며 이 때 사용되는 통신 프로토콜은 HTTP라는 프로토콜이다.
또 웹 브라우저는 여러 명이 접속하지만, 웹 서버는 한 대의 서버가 여러 명의 웹 브라우저의 연결을 관리해야 한다. 따라서 웹 서버는 이러한 웹 브라우저의 세션(Session)을 관리해야 하는데 이러한 프로그램을 웹 서버라 하며 윈도우에서 사용되는 대표적인 웹 서버에슨 IIS 서버가 있고 리눅스 계열에서 사용되는 웹 서버에는 Apache가 있다.
02. IIS 웹 서버 설치
IIS 서버를 설치는 윈도우 서버에서 제공하는 서버 관리자라는 프로그램을 사용해서 설치할 수 있다. 서버 관리자 프로그램에서 관리 메뉴, 역할 및 기능 추가 메뉴를 선택하면 된다.
역할 서비스 및 기능에 대한 기본적인 안내문이 나온다. 다음 버튼을 선택해서 그대로 넘어간다.
단일 서버를 기반으로 구축하는 경우 역할 기반 또는 기능 기반 설치를 체크하고 다음 버튼을 클릭한다.
서버 풀은 해당 서버의 스토리지(Storage)에 IIS를 선택하는 것을 의미한다.
역할 리스트에 웹 서버(IIS)를 선택하면 IIS를 설치하게 된다. 만약 Active Directory 및 DHCP 서버, DNS 서버 등도 설치를 원하면 모두 체크하면 된다.
ASP를 지원하기 위해서 ASP.NET을 체크한다.
역할 서비스에서 IIS 웹 서버에 필요한 서비스를 선택한다.
FTP 서비스를 구축하기 원하면 FTP 서버를 선택하면 된다.
여기까지 진행이 완료되면 설치가 시작된다. 기능설치가 완료되면 IIS 웹 서버를 사용할 수 있다.
IIS 웹 서버가 설치되면 설치된 앱 목록에 IIS 인터넷 정보 서버라는 것이 있다.
IIS 웹 서버를 설치하였으므로 localhost(127.0.0.1)로 웹 브라우저로 접속하면 IIS 홈 페이지가 보여지게 된다. 홈 페이지가 보여진다는 것은 정상적으로 IIS 웹 서버가 설치된 것을 의미한다.
IIS 웹 서버 사용
01. IIS(Internet Information Server) 기능
웹 브라우저의 HTTP Request에 대해서 HTTP Response로 HTML을 전송한다.
HTTP 리디렉션 기능을 특정 주소로 바로 연결되게 한다.
HTTP 상태 코드를 통해서 오류를 관리한다.
HTTP로 로깅 정보를 기록하고 관리한다.
ASP 및 .NET 언어를 지원한다.
SSL 인증서를 등록해서 SSL 보안을 지원한다.
IIS 웹 서버를 설치하면 IIS 관리자 프로그램으로 IIS 기능 리스트를 확인할 수 있다. IIS 기능 리스트는 IIS 형식에서 지원하는 기능으로 HTTP 리디렉션, HTTP 응답헤더, ISAPI 및 CGI지원, ISAPI 필터, MIME 형식 등의 기능을 지원한다.
02. 웹 사이트 추가
웹 사이트 추가 기능을 사용해서 해당 웹 사이트 정보를 등록한다.
실제 경로는 웹 사이트의 홈 디렉터리이고 웹 사이트는 기본저긍로 80번 포트를 사용하지만 포트 번호는 변경이 가능하다. 호스트 이름은 URL 주소를 입력한다.
웹 사이트가 등록되면 등록된 웹 사이트 리스트를 확인할 수 있다.
추가된 웹 사이트 정보는 고급 설정으로 확인이 가능하다.
설정된 정보인 웹 사이트 주소, 포트 번호, 프로토콜 등이 확인 가능하다.
03. HTTP 리디렉션
홈 페이지의 주소로 접속할 때 자동으로 연결한 페이지를 등록한다. 즉 www.baonteam.com을 웹 브라우저에서 입력하면 자동으로 www.boanteam.com/baon/boan.jsp로 연결하게 한다.
04. 오류 페이지
웹 페이지에서 발생하는 오류 정보를 노출하지 않고 전용 에러 페이지를 등록하는 것이다. 즉 HTTP 상태코드에 따라서 에러가 발생하면 웹 브라우저에게 전송할 페이지를 등록한다.
05. 가상 디렉터리
가상 디렉터리 실제 페이지 경로를 URL을 보이지 않게 해서 보안을 향상시킨다. 즉 실제로 존재하지 않는 디렉터리에 웹 페이지나 파일 등을 올려놓고 관리하는 것이다.
Section 04. DNS 서버
윈도우 DNS 서버
01. 윈도우 DNS 서버
윈도우 서버는 DDNS(Dynamic Domain Name Service)라는 DNS 서버를 관리할 수 있으며 윈도우 DNS 서버는 사용자 PC에 IP를 동적으로 할당하는 DHCP 서버와 연동해서 관리할 수 있는 기능을 제공한다.
02. 윈도우 DNS 서버의 기능
사용자 PC는 DNS Request로 도메인 주소를 전송하면 DNS 서버는 해당 도메인에 대한 IP주소를 얻은 후 사용자 PC에게 DNS Response로 IP주소를 전송한다.
IP 주소를 DNS 서버에 전송하면 해당하는 도메인 주소를 전송한다.
DNS는 TCP와 UDP 프로토콜을 사용하고 53번 포트를 사용한다.
DNS Cache
DNS 서버는 도메인 주소에 대해서 IP주소를 알려주는 서비스이다. 그러나 사용자 PC가 요청할 때마다 DNS 서버가 도메인을 해석하면 DNS 서버는 많은 부하가 발생할 것이다. 그래서 최근에 자주 참조하는 도메인명과 IP 주소를 메모리에 유지하고 있다가 동일한 요청이 오면 메모리에서 조회 수에 사용자 PC에게 응답한다. 이를 DNS Cache라고 하고 DNS Cache는 사용자 PC에도 존재하고 DNS 서버에도 존재한다.
03. 주 영역 DNS와 보조 영역 DNS
DNS 서버에 장애가 발생하면 도메인 주소를 해석할 수 없기 때문에 도메인을 사용할 수 없다. 그래서 DNS 서버는 주(Primary) 영역 DNS 서버와 보조(Second) 영역 DNS로 이중화를 시킨다. 즉, 주 영역 DNS 서버 장애 시에 보조 영역 DNS가 서비스를 계속한다.
중 영역과 보조 영역 DNS
주(Primary) 영역 DNS
DNS 서버로서 도메인을 해석하고 DNS 서버에 영역(Zone)을 등록
등록된 영역 정보는 Zone Transfer를 통해서 보조 영역 DNS에게 전송
보조(Secondary) 영역 DNS
주 영역 DNS 서버 장애 시에 DNS 서버의 역할을 수행
주 영역 DNS에서 Zone Transfer를 통해서 영역 정보를 수신 받음
영역(Zone)이라는 것은 DNS에서 도메인 주소를 관리하는 기본 관리 단위이다. 그리고 영역 전송을 전송하는 것을 Zone Transfer라고 한다.
DNS 영역
01. 정방향 영역(Public Domain Zone)
정방향 영역은 DNS 서버에 도메인 주소를 전송하면 IP 주소를 전송하는 것으로 DNS 질의(Query)에 대해서 형태의 IP 주소(IPv4, IPv6)로 응답할지를 결정한다.
윈도우의 DNS 관리자에서 정방향 조회 영역을 선택하고 마우스 오른쪽 버튼을 누르고 새 영역 메뉴가 나타난다.
새 영역 마법사를 시작한다. 다음 버튼을 클릭하고 넘어간다.
영역 형식에서 주 영역을 선택하고 다음 버튼을 클릭한다.
영역 이름에는 도메인 주소를 입력한다.
영역 파일은 도메인 주소에 자동적으로 DNS가 것이 붙여진다. 물론 영역 파일명을 변경해도 된다.
동적 업데이트 허용 여부를 결정한다.
여기까지 하면 정방향 영역 생성이 완료된다.
DNS 관리자에서 정방향 조회 영역을 보면 추가된 정방향 조회 영역을 확인할 수 있다.
02. 역방향 영역(Inverse Domain Zone)
역방향 영역은 사용자 PC에서 IP 주소를 전송하면 DNS 서버가 도메인 주소를 응답하는 서비스이다.
윈도우의 DNS 관리자에서 역방향 조회 영역을 선택하고 마우스 오른쪽 버튼을 누르면 새 영역 메뉴가 나타난다.
새 영역 마법사를 시작한다. 다음 버튼을 클릭하고 넘어간다.
역방향 조회 영역은 IP주소로 응답하기 때문에 IPv4 형식으로 사용자 PC에게 전송할 것인지 IPv6 형식으로 전송할 것인지를 선택한다.
C Class의 네트워크는 IP 주소 3영역만 입력하고 다음을 클릭한다.
영역 파일은 IP주소에 자동적으로 dns라는 것이 붙어진다. 물론 영역 파일명을 변경해도 된다.
동적 업데이트를 허용 여부를 결정한다.
여기까지 하면 역방향 영역 생성이 완료된다.
DNS 관리자에서 역방향 조회 영역을 보면 추가된 역방향 조회 영역을 확인할 수 있다.
DNS 레코드(Record)
01. 호스트
(1) 호스트 등록
사용자가 www.boanteam.com이라고 입력을 하면 DNS 서버는 어떤 형식으로 응답을 해야 할지를 모른다. 그래서 호스트 등록을 통해서 사용자에게 어떤 형식의 정보를 응답할지를 결정한다. 이때 응답 정보로 사용되는 것이 레코드(Record)이다. 예를 들어 A레코드를 등록하면 www.boanteam.com에 대해서 IPv4 주소 형식으로 응답하게 된다.
여기서 호스트는 www가 된다.
(2) 호스트 등록 방법
DNS 관리자 프로그램에서 등록된 정방향 조회 영역 도메인을 선택한 후에 마우스 오른쪽 버튼을 누르면 새 호스트라는 메뉴가 나온다.
새 호스트를 선택하면 해당 도메인 주소에 대해서 IP주소를 입력해야 한다.
여기까지 실행하면 해당 도메인 주소에 대해서 응답되는 IP주소의 형식과 IP 주소가 등록된것이다.
02. 메일(Mail Exchanger) 레코드
메일 레코드는 DNS 서버가 전자우편을 전달하기 위해서 사용되는 레코드로 lim@limbest.com이라는 전자우편에 limbest.com의 도메인에 메일을 어떤 형식으로 전송할 것인지 알려준다.
03. PTR(Pointer) 레코드
PTR 레코드는 역방향 조회 영역에서 사용자 PC가 IP 주소를 전송하면 도메인 주소로 변경하기 위해서 등록하는 레코드이다.
역방향 조회 영역에서만 사용된다.
IP 주소에 대해서 역방향 조회 영역을 추가한다.
04. SOA(Start Of Authority) 레코드
(1) SOA 레코드
SOA 레코드는 도메인 영역의 등록 정보를 가지고 있는 기본 레코드이다. 주 영역 DNS 서버와 보조 영역 DNS 서버 간의 동기화 정보, DNS 정보 보유에 대한 시간 정보 등을 가지고 있으며 SOA 레코드는 영역(Zone) 생성 시에 자동으로 생성된다.
(2) SOA 영역
일련 번호 : 영역 변경 시에 증가하는 번호로 해당 영역의 파일의 개정 번호이다. 보조 영역 DNS 서버에 전송한다.
주 서버 : 해당 영역이 초기에 설정되는 서버로 주 영역 DNS 서버의 도메인 주소이다.
책임자 : 책임자의 전자우편 주소이다, 메일 주소는 도메인 형식으로 기입한다.
새로 고침 간격 : 주 영역 DNS 서버와 보조 영역 DNS 서버 간에 통신 간격이다.
다시 시도 간격 : 주 영역 DNS 서버와 보조 영역 DNS 서버 간에 통신 장애가 발생하면 재 시도하는 간격이다.
다음 날짜 이후에 만료 : 설정기간을 초과하여 통신 두절 시 동작 정지 정보이다.
최소(기본값) TTL : 레코드의 캐시 시간을 지정한다.
이 레코드의 TTL : SOA 레코드의 TTL이 지정된다.
03. CNAME 레코드
같은 IP 주소를 가지고 있는 여러 개의 호스트가 있을 때 용이하다
A 레코드가 비슷하지만 별명(Alias)을 입력한다
A 레코드에 비해서 속도가 빠르다
호스트 이름을 등록해서 관리한다.
Section 05. 엑티브 디렉터리
엑티브 디렉터리(Active Directory)
중앙에서 통합적으로 관리하기 위해서 네트워크 정보를 등록하는 서비스이다
네트워크, 사용자, 그룹에 대한 정보를 통합 관리한다.
01 엑티브 디렉터리 개요
우선, 윈도우 탐색기에서 내 컴퓨터 속성에 들어가면 다음과 같은 화면을 볼 수 있을 것이다. 다음의 화면을 보면 워크그룹(Workgroup)과 도메인(Domain)이 있는 것을 확인할 수 있다.
우선 워크그룹은 자신의 PC에 저장되어 있는 데이터베이스로 작은 규모의 데이터베이스로 작은 규모의 네트워크 환경에서 자신의 시스템으로 관리할 때 사용하는 기능으로 각각의 사용자 계정으로 자신이 관리하는 것이다. 도메인이라는 것은 기업 내에서 모든 컴퓨터 및 사용자 계층을 컴퓨터마다 생성하지 않고 하나의 마스터 서버(Domain Controller)에 의해서 생성 관리할 수 있는 중앙 집중적인 관리를 수행한다. 마스터 서버에는 전체 컴퓨터의 디렉터리 데이터베이스(Database)를 가지고 있어서 중앙에서 모든 것을 관리할 수 있다. 하지만 소규모 네트워크 규모에서는 이러한 관리가 불편할 수 있다. 그러므로 소규모 네트워크에서는 도메인을 관리하는 액티브 디렉터리를 사용하지 않고 워크그룹으로 자신이 관리하면 된다.
여기서 디렉터리 데이터베이스 혹은 디렉터리 서비스(Directory Service)라는 것은 네트워크 내에 있는 자원을 관리하기 위해서 추가, 삭제 변경, 검색을 수행할 수 있는 서비스의 기능을 의미한다.
02 엑티브 디렉터리의 기능
사용자 계정 관리를 중앙에서 통합적으로 관리한다.
사용자에 대한 일관된 보안 정책을 적용한다.
사용자 데스크톱 환경에 대해서 보안 설정을 관리한다.
공유자원에 대한 접근 권한 할당이 가능하다
응용 프로그램에 대해서 디렉터리 서비스를 제공한다.
LDAP(Lightweight Directory Access Protocol)
LDAP은 TCP/IP를 기반으로 디렉터리 데이터베이스에 접속하기 위한 통신규약이다.
디렉터리 정보의 등록, 갱신, 건색, 삭제를 실행하며 네트워크를 사용해서 사용자 정보를 검색한다.
액티브 디렉터리(Active Directory) 구조
01 엑티브 디렉터리 구조
엑티브 디렉터리 서비스는 네트워크 상의 모든 정보를 계층형 디렉터리에 저장해서 편리하게 관리할 수 있는 서비스이다. 이는 네트워크 서버(Network Resource)을 디렉터리에 저장해서 사용자들이 자원을 쉽게 검색할 수 있게하고 관리자는 관리의 편의성을 향상시키는 서비스이다.
엑티브 디렉터리는 네트워크에 대한 모든 정보를 보유하고 보유한 정보를 검색하기 위해서 이름 공간(Name Space)에서 검색할 수 있게 한다. 객체(Object)란 엑티브 디렉터리에서 자원의 최소 단위이다.
객체에는 특정 컴퓨터 정보를 가지는 컴퓨터, 구성원에게 메일을 보내기 위한 연락처, 자원에 대한 권한을 부여할 때 사용할 수 있는 그룹, 자원을 관리하기 위한 조직단위, 로그인 할 때 사용하는 이름인 사용자 계정, 공유 폴더 지점을 가지고 있는 공유 폴더 등이 일반적일 객체가 된다.
02. 엑티브 디렉터리 논리적 구조와 물리적 구조
엑티브 디렉터리는 논리적 구조와 물리적 구조로 분류된다.
(1) 액티브 디렉터리 논리적 구조
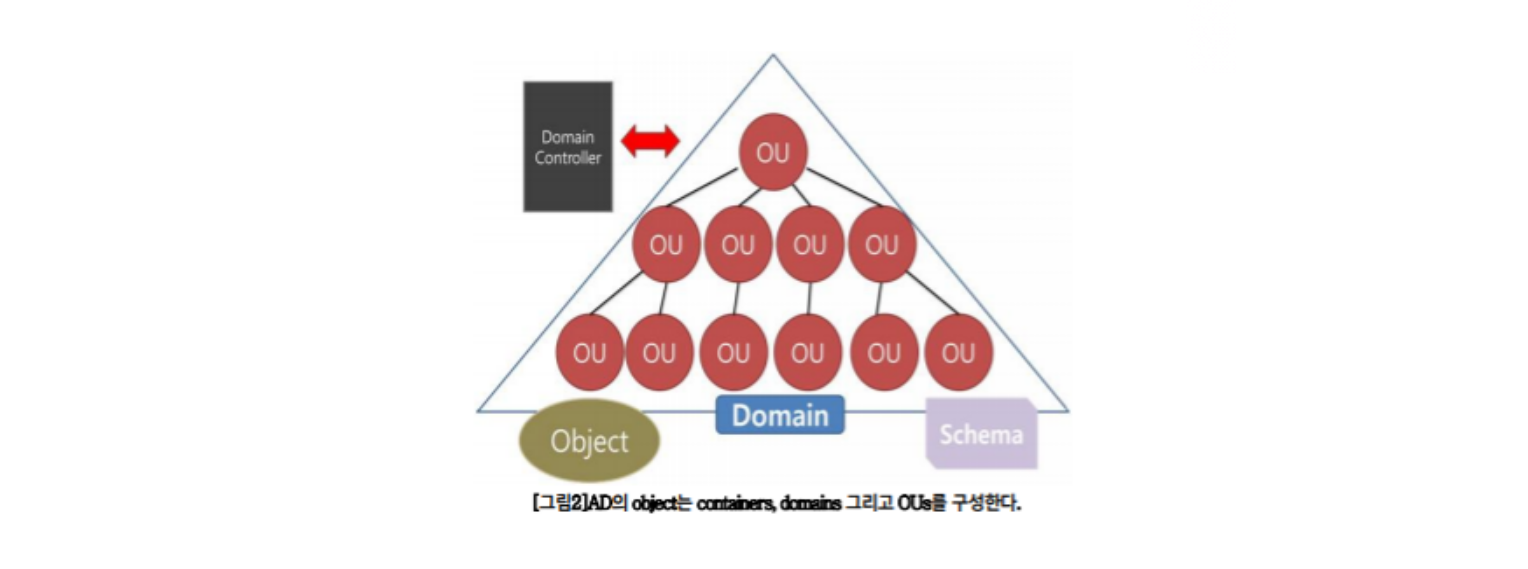
논리적 구조 상세 내용
도메인(Domain)
엑티브 디렉터리를 관리하기 위한 단위이며 조직 구성의 그룹
사용자 계정, 컴퓨터, 프린터 등을 포함하고 있다
네트워크의 모든 객체는 도메인에 소속되며 도메인은 고유한 보안 정책을 보유한다
도메인은 하나 이상의 도메인 컨트롤러를 가져야 한다.
조직 구성(Organizational Units)
도메인 내에 객체를 관리하기 위한 그룹으로 하나의 도메인은 여러 개의 조직 구성을 가진다
관리를 위한 것으로 계층형 형태로 구성
트리(Tree)
도메인의 계층 구조를 의미하며 하나의 도메인으로 구성
트리는 Root 도메인과 트리 내의 도메인 간에 양방향 신뢰 관계를 확립하고 있다.
트리 내에 같은 도메인은 같은 스키마(Schema)를 가지고 스키마는 액티브 디렉터리 내에 저장할 수 있는 객체의 모든 형태를 의미
포리스트(Forest)
도메인 트리들이 모두 양방향 전이 신뢰관계를 가진 그룹
(2) 액티브 디렉터리 물리적 구조
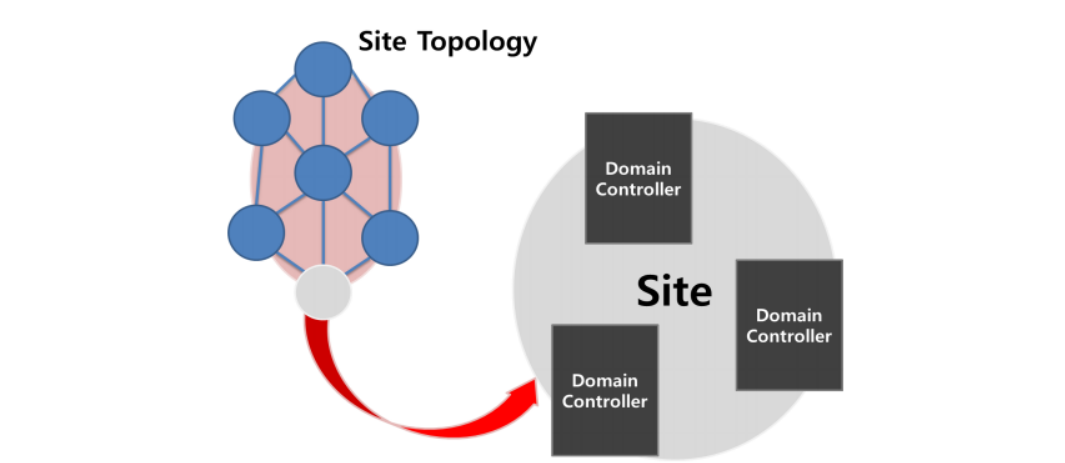
물리적 구조 상세 내용
도메인 콘트롤러(Domain Controller)
도메인 내에 있는 액티브 디렉터리 데이터베이스를 가지고 있는 컴퓨터
도메인 컨트롤러는 보안 정책, 사용자 인증 데이터, 네트워크 디렉터리 정보를 저장하고 있다.
사이트(Site)
하나의 사이트는 하나의 IP 서브넷으로 물리적 연결을 의미한다.
하나의 도메인에는 여러 개의 사이트가 연결됨
03 엑티브 디렉터리 보안 기능
접근 통제(Access Control List)
어떤 사용자에게 어떤 권한으로 객체를 접근할 수 있는지 지정
권한 위임(Delegation)
관리자가 특정 개인 혹은 그룹에게 권한 관리를 위임
상속(Inheritence)
컨테이너 객체에 대한 상속을 통해서 하위 자식 컨테이너가 상위 객체의 정의를 그래도 적용
신뢰 관계(Trust Relationships)
한 도메인 내의 사용자가 다른 도메인의 자원에 접근하려면 신뢰관계가 이루어져야 가능하다
스키마, 환경, 글로벌 카탈로그 서버를 공유
Section 06. FTP Server
FTP 사이트 추가
윈도우 서버는 FTP 서버를 구축 해서 윈도우 서버로 파일을 올리거나 다운로드 받을 수 있다. FTP 서버는 IIS 관리자 프로그램에서 FTP 사이트 추가 메뉴로 구축한다.
FTP 사이트 추가를 클릭하면 FTP 사이트 이름과 FTP 서버의 디렉터리를 지정할 수 있다.
IP 주소 바인딩은 특정 IP에 대해서만 접근이 가능하도록 지정할 수 있다. 바인딩을 지정하려면 IP주소를 입력하면 된다. 그리고 FTP 서버는 명령을 송신 및 수신하기 위해서 21번 포트 번호를 사용한다. 또한 SSL을 사용해서 암호화를 수행할 수 있다. SSL을 사용하려면 먼저 인증 기관으로부터 SSL 인증서를 받아야 한다.
익명의 사용자 접속 가능 여부를 체크하고 FTP 서버에서 읽기, 쓰기 권한을 설정한다.
여기까지 완료하면 FTP 서버는 모두 구축된 것이다.
윈도우에서 FTP 사용
이제 개인용 PC에서 FTP 서버로 연결을 시도한다. FTP 서버로 연결하기 위해서 알드라이브라는 FTP 클라이언트를 설치해야 한다. 알드라이브는 네이버에서 조회하면 간단하게 설치할 수 있다.
FTP 클라이언트가 설치되면 FTP 서버의 IP 주소와 아이디, 비밀번호를 입력한다.
리눅스에서 FTP 사용
이제 리눅스에서 윈도우 서버로 FTP를 연결해본다. 리눅스에서 FTP 프로그램을 실행하면 사용자 ID와 패스워드를 요구한다. 사용자 ID와 패스워드를 입력하면 바로 로그인이 만료된다.
리눅수에서 윈도우 FTP 서버로 로그인을 하면 "FTP 현재 세션"에 FTP 연결 세션 정보가 확인된다. 그리고 nestat 명령어를 실행하면 FTP 연결을 확인할 수 있다. 세션 정보에서 ESTABLISHED라는 것이 있는데 이 의미는 TCP가 연결을 확립했다는 것이다.
FTP 서버 로깅 정보
IIS 관리자에서 FTP를 선택한다. 그리고 FTP 로깅 메뉴를 클릭한다.
FTP 로깅 정보를 보면 로그파일을 기록할 디렉터리 위치와 로그 파일을 어떻게 생성할 것인지를 설정한다.
그리고 FTP로 연결하고 해당 로그 디렉토리에서 로그 파일을 열어보면 접속 일자와 시간, 접속 IP 주소, 사용자 실행한 명령 등을 모두 확인할 수 있다.
FTP 현재 세션 메뉴를 확인 해보면 현재 연결된 FTP 사용자를 확인할 수 있다.
Section 07. 리눅스(Linux)
리눅스 개요
리눅스
리눅스의 윈도우, 유닉스, ios와 같은 운영체제의 한 종류로 컴퓨터 시스템의 하드웨어를 효율적으로 관리한 시스템 소프트웨어이다. 리눅스는 1989년 핀란드 헬싱키 대학에 재학 중이던 리누스 토르발스(Linus Torvlads)가 개발한 것으로 유닉스를 기반으로 개발하였으며 공개용(Open Source) 운영체제이다.
리눅스는 기존 유닉스와 다르게 대형 서버를 위해서 개발된 운영체제가 아니라 개인용 컴퓨터나 워크스테이션을 위해서 개발되었으므로 소스코드부터 운영체제 사용까지 모두 무료로 공개된 운영체제이다. 그러미르ㅗ 리눅스 설치하고 사용자(End User)가 자신 운영체제를 수정하여 사용할 수도 있다.
리눅스의 특징
다중 사용자(Multi User)
리눅스는 여러 명의 사용자가 네트워크를 통해서 접속하여 컴퓨터 시스템을 사용할 수 있는 다중 사용자를 지원한다. 다중 지원자를 지원하기 때문에 사용자 별 권한 관리와 지원 관리를 지원한다.
다중 작업(Multi-Tasking)
다중 작업은 운영체제 내에서 여러 개의 프로세스(Process)를 동시에 실행시켜 CPU를 스케줄링하여 사용할 수 있다. 여러 개의 프로세스가 동시에 실행되기 때문에 각 프로세스 간에 작업순서 조정과 같은 스케줄링 기능을 가지고 있다. 이러한 스케줄링은 기본적으로 시간(Time Slice) 사용량만큼 자원을 할당하여 사용할 수 있게 하는 시분할 시스템(Time Sharing System)을 지원한다.
다중 처리기(Multi-Processor)
컴퓨터 시스템에 한 개 이상의 CPU가 탑재되어 있는 경우 여러 개의 CPU를 지원해주는 다중 처리기를 지원하여 작업을 병렬적으로 처리하여 시스템을 효율적으로 사용한다.
다중 플랫폼(Multi-Platform)
리눅스 여러 종류의 CPU를 지원한다. 즉, 인텍, Sun Sparc, Power PC 등을 모두 지원하여 대부분의 플랫폼을 지원하고 성능을 낼 수 있다.
계층형 파일 시스템(File System)
리눅스 파일 시스템은 계층형 구조로 되어 있어 루트(Root)를 기반으로 하위 디렉터리를 이루는 계층형 파일 시스템으로 이루어져 있어서 디렉터리를 쉽게 추가하고 관리할 수 있어서 파일 시스템을 효율적으로 관리할 수 있다. 계층형 파일 시스템은 리눅스 뿐만 아니라 윈도우, 유닉스 모두 계층형 파일 시스템으로 되어 있다.
POSIX과 호환
POSIX은 유닉스 시스템의 표준 인터페이스를 정의한 것으로 리눅스는 POSIX 표준을 따른다.
POSIX
다양한 유닉스 계열의 운영체제의 공통적인 API를 제시하여 유닉스 계열 시스템 간에 이식성을 높이기 위해서 IEEE가 지정한 인터페이스 규격이다.
우수한 네트워킹(Networking)
리눅스의 강력한 네트워킹 기능은 TCP/IP, IPX/SPC, Appletalk, Bluetooth 등 다양한 프로토콜을 지원하며 리눅스 설치 이후에 IP 주소, 게이트웨어(Gateway), 서브넷(Subnet) 등을 설정하면 바로 네트워크를 사용할 수 있다.
가상 콘솔(Virtual Console)
리눅스는 기본적으로 6개의 가상 콘솔이 있으며 이를 통해 각 창마다 서로 다른 작업을 수행할 수 있어서 물리적 모니터의 한계를 극복한다.
가상 기억 장치(Virtual Memory)
주기억장치(Main Memory)의 한계를 극복하기 위해 보조 기억장치를 마치 주기억장치처럼 사용할 수 있게 하여 주 기억장치의 공간을 증대하는 방법이 가상 기억장치이다. 가상 기억장치는 기억 공간을 확대하여 기억장치를 효율적으로 사용할 수 있어서 시스템을 안정적으로 사용할 수 있다.
리눅스의 구조
리눅스는 운영체제(Operating System)의 한 종류이다. 그러므로 운영체제가 가지는 기능은 기본적으로 모두 가지고 있다. 즉, 프로세스 관리, 메모리 관리, 입출력 장치 관리, 프로세스 관리, 사용자 관리, 보안 관리, 로그 관리 및 하드웨어 관리 등의 파일 시스템을 가지고 있다.
커널(Kernel)
리눅스는 커널(Kernel), 셀(Shell), 파일 시스템(File System)으로 구성되며 커널은 운영체제의 핵심 기능으로 프로세서, 프로세스, 메모리 입출력 장치의 기능을 수행하는 것으로 운영체제에서 가장 중요한 역할을 수행한다.
커널(Kernel)의 기능
프로세서(Processor) 사용을 관리한다
주 기억장치(Main Memory) 사용을 관리한다
실행 중인 프로세스(Process Management)를 관리한다
주변 장치(Device Management)와 입출력을 관리한다.
셀(Shell)
셀(Shell)은 사용자의 명령을 입력 받아서 실행하기 위한 인터프리터(Interpreter) 기능을 수행하는 것으로 사용자가 ps라면 명령어를 입력하면 프로세스 정보를 출력해주는 역할 같은 것을 수행하는 것이다.
셀(Shell)의 기능
사용자의 명령어를 실행한다
사용자가 명령어를 입력하면 바로 실행시키면 인터프리터 기능을 제공한다
리눅스 표준 셀은 bash이며 이외에도C Shell, Korn Shell 등 다양한 셀을 제공한다.
파일 시스템(File System)
파일 시스템은 저장장치(디스크, USB, SSD)에 보관되어 있는 파일을 관리하기 위한 것으로 디렉터리를 생성, 변경, 삭제하고 디렉터리 내에 파일을 생성, 변경, 삭제 등을 할 수 있다.
파일 시스템(File System)의 기능
사용자 파일과 디렉터리를 관리한다
파일과 디렉터리 등에 권한을 설정하고 해제한다
파일의 연결 정보인 링크를 관리한다
파일의 소유자, 그룹, 파일 생성 일자, 변경 일자 등을 관리한다
이러한 파일 시스템은 루트 디렉터리를 중심으로 하위 디렉터리로 구성되며 이러한 형태를 계층형 파일 시스템이라고 한다.
리눅스 계층
커널(Kernell)
주기억 장치에 상주하여 사용자 프로그램을 관리하며, 리눅스 운영체제의 핵심
커널 구성 : 프로세스, 메모리 입출력(I/O), 파일 관리
셀(Shell)
명령어 해석기/번역기로 사용자 명령의 입출력을 수행하며 프로그램을 실행
종류 : Bourne 셀, C 셀, Korn 셀 등
파일 시스템(File System)
여러 가지 정보를 저장하는 기본적인 구조이며, 시스템 관리를 위한 기본 환경을 제공하는 계층적인 트리
구조 형태(디렉터리, 서브 디렉터리 파일 등)
리눅스 파일 시스템
파일 시스템을 생성하기 위해서는 하드 디스크를 초기화하고 필요하면 파티션(Partition)을 수행하여 하드 디스크를 분할해야 한다. 그 때 파티션을 수행하는 리눅스 명령어가 바로 fdisk이다
이 부분은 쉽게 생각하면 윈도우의 C 드라이브, D 드라이브와 마찬가지 기능으로 한 개의 하드 디스크를 여러 개로 분리하여 분리 공간에 따라 다른 용도로 사용하는 것이다.
fdisk
fdisk 명령은 하드 디스크 초기화 및 파티션을 생성하는 것ㅇ으로 fdisk [-l][-v][-s 파티션][장치명] 형태로 실행한다.
fdisk 옵션
-l : 현재 파일 시스템 목록 확인
-v : 버전 정보 확인
-s 장치명 : 입력 장치 크기를 출력
-d : 파티션 삭제
-n : 새로운 파티션 생성
-p : 현재 파티션 설정 상태 확인
mkfs
하드 디스크를 파티션 했으면 해당 파티션에 파일 시스템을 생성해야 한다. 하드 디스크를 생성하기 위해서 mkfs 명령어를 실행하면 된다.
mkfs는 리눅스에서 파일 시스템을 생성하는 명령어로 mkfs[옵션][장치이름]으로 실행한다.
mkfs 옵션
-V : 실행되는 파일 시스템의 특정 명령어 등 모든 정보를 출력
-t : 파일 시스템 형식 선택
-c : Bad Block 검사, Bad Block 리스트를 초기화
-l : 파일로부터 초기 Bad Block을 읽음
-v : 현재 진행 사항 출력
파일 시스템 생성 예제
#mkfs -t ext4/dev/sdb1
ext4 파일 시스템을 생성함
또한 mkfs이외에도 mke2fs는 ext2, ext3, ext4 파일 시스템을 생성하는 명령이다. 위의 예에서 mke2fs -j 옵션 저널링 파일 시스템을 ext3로 생성하는 것이다.
fsck
fsck는 파일 시스템의 무결성을 검사하는 명령어로 파일 시스템에는 상위 디렉터리, 하위 디렉터리 그리고 파일 간의 링크 정보(심볼릭 링크) 등을 가지고 있어야 한다. 이러한 정보에 오류가 발생되면 파일 시승템의 구조를 파악할 수 없다. 그럴 때 리눅스는 fsck를 통해서 파일 시스템의 무결성을 검사하고 오류가 발생하면 수정할 수 있다. fsck는 기본적으로 부팅 단계에서 자동적으로 실행하게 되고 필요에 따라서 직접 실행할 수도 있다.
fsck 옵션
-s : 대화형 모드에서 여러 파일 시스템을 점검할 때 fsck 동작을 시리얼화 한다
-t : 검사를 수행할 파일 시스템을 지정
-A : /etc/fstab 파일에 기술된 파일 시스템을 모두 검사
-N : 검사는 수행하지 않고 수행될 내용을 출력한다
-P : 병렬 처리를 수행하여 루트 파일 시스템 점검
-R : 루트 파일 시스템은 제외
-V : 명령을 포함하여 세부 내역을 출력한다
파일 시스템 옵션
-a : 무결성 검사 후에 자동 검사 수행
-r : 대화형 모드를 수행하며 오류를 수정한다
-n : 오류를 수정하지 않고 표준 출력으로 출력한다
-y : 특정 파일 시스템에 대해서 오류를 자동 수정한다
mount
리눅스 컴퓨터 시스템 A에 tmp라는 디렉터리가 있다고 가정하자. 그러면 tmp 디렉터리를 리눅스 컴퓨터 시스템 B에서 연결하고 사용하는 것이 바로 마운트(Mount)라는 것이다. 이러한 것은 단순하게 디렉터리만 연결하여 사용하는 것이 아니라 CDROM, USB 등과 같은 장치를 연결할 때도 사용되는 것이고 mount라는 명령어를 실행하여 연결을 수행할 수 있다.
즉, 리눅스에서 특정 디렉터리를 연결할 경우 mount 명령을 사용한다. 또, -a 옵션은 명시된 파일 시스템에 대해서 마운트를 수행한다.
mount 명령
mount [-hV]
mount -a [-fnvw] [-t 파일 시스템 유형]
mount [-fnvw] [-o옵션]] 장치 | 디렉터리
mount [-fnvw] [-t 파일 시스템 유형] [-o 옵션] 장치 디렉터리
mount 명령 옵션
-v : 자세한 정보 출력 모드
-t : 마운트를 할 수 있는지 점검
-n : /etc/mtab 파일에 쓰기 작업을 하지 않고 마운트
-r : 읽기만 가능하도록 마운트 한다
-w : 읽기 및 쓰기 모드로 마운트 한다
-t vtstype : -t 다음에 쓰이는 인수로 파일 시스템 유형 저장
fstab 파일은 mount을 수행할 때 참조하는 파일로 파일 시스템 마운트에 관한 정보를 가지고 있다.
[파일 시스템 장치][마운트 포인트][파일 시스템 공유][옵션][덤프][파일 점검 옵션]
fstab 파일의 필드
1. 파일 시스템 장치(레이블명)
2. 마운트 포인터(디렉터리 명)
3. 파일 시스템 형식(ext2, ext3)
4. 옵션(Read Only 및 Read Write)
5. 파일 점검 옴션(0,1)
fstab 옵션
default : 일반적인 파일 시스템
auto : 부팅 시에 자동으로 마운트한다
exec : 실행 파일이 실행되게 허용
suid : setuid와 setgid를 허용
ro : 읽기 전용 파일 시스템
rw : 읽고 쓰기가 가능한 파일 시스템
user : 일반 사용자도 마운트할 수 있는 파일 시스템
nouser : root만 마운트할 수 있는 파일 시스템
noauto : 부팅 시에 자동으로 마운트하지 않는다
noexec : 실행 파일이 실행되지 않는다
nosuid : setuid와 setgid를 허용하지 않는다
usrquota : 개별 사용자의 쿼터 설정이 가능한 파일 시스템을 의미
grpquota : 그룹별 쿼터 설정이 가능한 파일 시스템
덤프(dumpt)는 0혹은 1로 0은 덤프가 실행되지 않고 1은 백업을 위해서 덤프가 가능한 파일 시스템이다.
파일점검 옵션은 0이면 부팅 시에 fsck가 실행되지 않고 1은 루트 파일 시스템이며 2는 루트 파일 시스템을 제외한 나머지 파일 시스템을 의미한다. 이것으로 fsck의 순서가 결정된다.
반대로 umount는 마운트를 해제하는 명령어로 umount[-nv] 장치 혹은 디렉터리명 형태로 사용한다.
umount 옵션
-n : /etc/mtab 파일을 변경하지 않고 마운트를 해제
-v : 정보 출력
-a : /etc/mtab 파일에 지정된 파일 시스템을 모두 해제
-t 파일 시스템명 : 지정된 파일 시스템을 해제
CDROM 과 같은 하드웨어는 마운트를 수행해서 사용할 수 있다. 만약 CDROM에서 CD를 빼려면 마운트를 해제하고 eject 명령을 실행하면 된다. 만약 /mnt/cdrom으로 마운트되어 있다면 umount/mnt/cdrom을 실행하고 eject를 실행한다.
CDROM mount, umount, eject 실행
#mount /dev/cdrom/mnt/cdrom CDROM마운트한다
#umount /mnt/cdrom CDROM을 마운트 해제한다
#ejectCD를 꺼낸다.
리눅스 파일 시스템
파일 시스템(File System)
리눅스 파일 시스템
리눅스 파일 시스템은 ext(extend) 2, ext 3, ext 4가 있으며 현재 대부분의 리눅스는 ext4를 지원한다. ext4 파일 시스템은 대용량의 파일을 저장 관리할 수 있으며 큰 Extend 단위로 파일 시스템을 할당하거나 삭제할 수 있다. 파일 시스템에 오류가 없는지 확인하는 fsck를 지원한다.
ext2 파일 시스템
단일 파일의 크기가 최대 2 Giga byte
파일명은 최대 256 Byte
최대 지원 파일 시스템 크기 4 Tera Byte
디렉터리당 저장 가능한 최대 파일 수는 약 25,500개
ext3 파일 시스템
단일 파일의 크기 제한은 4 Giga Byte
파일명은 최대 256 Byte
최대 파일 시스템의 크기는 16 Tera Byte
디렉터리당 저장 가능한 최대 파일 수는 65,565개
저널링 파일 시스템을 지원한다
ext3에서 저널링 파일 시스템이란 파일 시스템 오류 수정을 위한 파일 시스템으로 ext2는 저널링 파일 시스템을 지원하지 않는다.
ext4 파일 시스템
리눅스 파일 시스템 ext4의 특징
대용량 파일 지원 : 1 exa byte 블록 지원, 단일 파일 크기가 16 tera byte 지원
호환성 : ext 2 및 ext 3 호환성, 마운트 가능
fsck : 파일 무결성 오류 시에 실행되는 fcsk 성능 향상
Extends 지원 : 큰 사이즈 파일을 삭제할 때 시간을 단축한다
하위 디렉터리 : 하위 디렉터리 수 제한이 32,000개에서 2배 확대 되었다.
조작모음 : ext3 저널링 파일 시스템에서 발생되는 단편화를 조작모음으로 개선함
파일 시스템 디렉터리(Directory) 구조
디렉터리(Directory)라는 것은 운영체제(Operating System)의 파일을 관리하기 위한 구조로 사용자는 디렉터리를 만들어서 파일을 저장하고 사용할 수 있다. 디렉터리는 리눅스를 설치하면 기본적으로 생성되는 것이 있으며 해당 디렉터리는 그 용도가 정해져 있다. 즉 모든 디렉터리는 루트(Root, /) 디렉터리를 기반으로 bin, boot, dev 등의 디렉터리가 생성되게 한다.
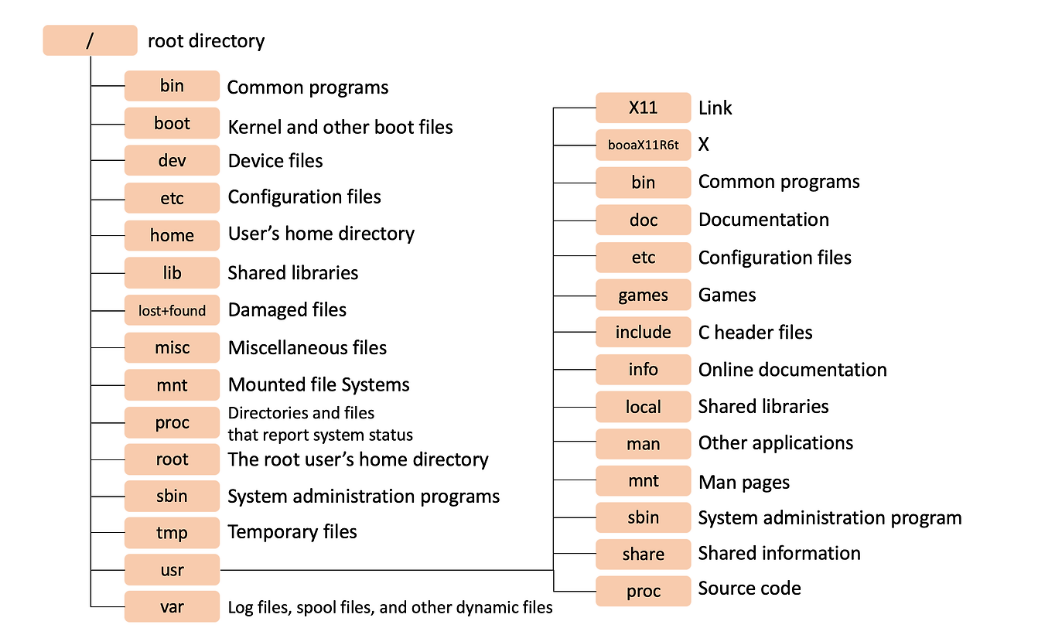
리눅스 디렉터리는 계층형 파일 시스템으로 이루어져 있으며 사용자 별로 자신의 디렉터리를 생성하여 사용할 수 있다. 특히 bin은 기본적인 실행 파일을 가지고 있고 boot는 리눅스 부트 프로그램인 LILO 파일을 가지고 있다.
etc 디렉터리는 환경설정에 관련된 파일을 가지고 있어서 사용자 패스워드 정보를 가지고 있는 passwd 파일, shadow 파일과 프로토콜 및 서비스 저옵를 보유한 protocol, service 파일 등을 가지고 있다.
리눅스는 다중 사용자를 제공하고 있으므로 각 사용자 별로디렉터리를 생성한다. 사용자 디렉터리는 home 디렉터리 하위에 생성되게 한다.
리눅스 디렉터리 구조
/ : 루트 디렉터리
/bin : 기본적인 실행 명령
/boot : LILO 등 부팅에 관련된 파일
/dev : 장치 파일 모음
/etc : 시스템 설정 파일
/home : 사용자 홈 디렉터리
/lib : C 라이브러리
/mnt : 임시 마운트용 디렉터리
/proc : 시스템 정보를 가진 가상 디렉터리
/roof : 루트 사용자의 홈 디렉터리
/sbin : 시스템 관리용 실행 파일
/tmp : 임시파일 디렉터리
/usr : 애플리케이션이 설치되는 디렉터리
/var : 시스템에서 운영되는 임시파일 및 로그 파일
dev는 주변장치와 관련된 장치정보를 가지고 있다. 예를 들어 CDROM, USB, Printer등과 같은 장치 파일 시스템이 있다.
리눅스 dev 파일 시스템(장치 파일 시스템)
/dev/td : 플로피 디스크
/dev/had : 마스크 IDE 하드 디스크
/dev/sda : SCSI 및 SATA 하드 디스크
/dev/cdrom : CD ROM 드라이버
/dev/mouse : 마우스
/dev/hdb : 슬레이브 IDE 하드 디스크
/dev/hd : 하드 디스크
proc 디렉터리는 실행 중인 리눅스 정보를 가지고 있는 디렉터리로 CPU 및 메모리 사용량, 파티션 정보, 입출력 DMA 등과 같은 정보와 현재 운영체제의 정보를 가지고 있다.
셀(Shell)
셀 개요
셀은 운영체제와 사용자 간에 대화식 인터페이스를 제공하는 것으로 리눅스 표준 셀은 bash이다. 즉 셀은 커널을 호출하여 커널에게 명령을 실행하고 그 결과를 출력한다.
셀 기능
시그널을 처리한다.
프로그램을 실행한다.
파이프, 리다이렉션, 백그라운드 프로세스를 설정한다.
입력된 내용을 파악해서 명령 줄을 분석한다.
와일드 카드, 히스토리 문자, 특수 문자를 분석한다.
만약 셀 환경 정보를 확인하고 싶다면 env 명령어를 실행하면 된고 환경 변수를 설정하고 싶다면 set 명령어를 실행한다.
셀의 종류
리눅스에서 지원되는 셀의 종류를 알고 싶다면 /etc/shells 파일을 보면 확인할 수 있다.
C Shell(Berkely 유닉스 C Shell)
사용자의 작업 환경을 편리성을 위하여 cshrc 파일에 필요한 환경 변수를 저장하여 사용자가 로그인 시에 지정 명령들을 자동 수행이 가능
Boulrne shell
사용자의 편리성을 위하여 profile 파일에 환경 변수를 저장
.profile 역할은 C 셀의 .cshrc 파일과 동일 역할
Korn shell
.kshrc 또는 .profile 파일에 환경변수를 저장
C 셀 기능을 모두 제공
셀 스크립트 언어에는 Bourne 셀과 유사
Bash shell
C shell과 Korn Shell의 특징을 결합한 것으로 GNU 프로젝트에 의해서 개발된 셀
리눅스에서 가장 많이 사용
명령 편집 기능을 제공한다.
TC Shell(Icsh)
C shell의 기능을 강화한 것으로 명령 편집 기능을 제공
리눅스 계정 관리
useradd와 adduser
리눅스에서 사용자를 생성하려면 useradd 혹은 adduser 명령을 사용하면 된다. useradd 명령의 사용법은 useradd limbest와 같은 형식을 사용하면 된다.
passwd 파일과 shadow 파일
사용자는 해당 계정을 사용하기 위해서 패스워드를 입력해야 한다. 사용자가 입력한 패스워드는 /etc/passwd 파일과 /etc/shadow 파일을 참조하여 정당한 사용자(Right User)인지 확인 후 로그인을 수행시켜 주는 것이다.
/etc/passwd 파일 구조
roof : x : 0 : 0 : root : /root : /bin/bash
Login Name : 사용자 계정을 의미한다
Password : 사용자 암호가 들어갈 자리이나 /etc/shadow 파일에 저장된다.
User ID : 사용자 ID를 의미하며, root의 경우 0이 된다.
User Group ID : 사용자가 속한 그룹 ID를 의미하며, root 그룹의 경우 0이다.
Comments : 사용자의 코멘트 정보를 적는 곳이다.
Home Directory : 사용자의 홈 디렉터리를 지정한다.
Shell : 사용자가 기본으로 사용하는 셀 종류가 저장된다.
만약 패스워드 파일에 패스워드 정보가 없으면(두 번째 필드에 X로 되어 있다) 사용자 패스워드는 shadow 파일에 있는 것이다. 리눅스 패스워드는 보통 shadow 파일에 별도로 기록된다.
/etc/shadow
Root : $1$Fz4q1GjE$G : 14806 : 0 : 99999 : 7 : :
각 필드의 구분자는 콜론(:)이며, 각 필드는 아래의 의미를 가진다.
Login Name : 사용자 계정
Encrypted : 패스워드를 암호화시킨 값이다.
Last Changed : 1970년부터 1월 1일부터 패스워드가 수정된 날짜의 일수를 계산한다.
Minimum : 패스워드가 변경되기 전 최소 사용 기간(일 수)이다.
Maximum : 패스워드 변경 전 최대 사용 기간(일 수)이다.
Warn : 패스워드 사용 만기일 전에 경고 메시지를 제공하는 일 수이다.
Inactive : 로그인 접속차단 일 수이다.
Expire : 로그인 사용을 금지하는 일 수(월/일/연도)이다.
Reserved : 사용되지 않는다.
리눅스 권한관리
umask
리눅스의 권한 관리는 소유자, 그룹, 다른 사용자로 이루어진다. 그리고 각각은 읽기, 쓰기, 실행 권한을 가질 수 있으며 읽기는 r, 쓰기는 w, 실행은 x로 표기한다. 그래서 rwx라는 권한을 가지게 되면 읽기, 쓰기, 실행이 모두 가능하다는 것이고 rw-로 표시되면 읽기와 쓰기만 가능하다는 의미이다. 예를 들어 어떤 파일을 ls 명령으로 조회 했는데 rw-rw-rwx 식으로 조회가 된다면 맨 왼쪽부터 파일을 만든 소유자는 읽고 쓸 수 있고 그 다음 같은 그룹의 사용자도 읽고 쓸 수 있다는 의미이며 마지막에 다른 사용자는 읽고, 쓰고 실행이 가능하다는 것이다.
하지만 파일을 만들 때마다 사용자가 매번 권한을 부여하는 것은 귀찮은 일이다. 그래서 Default 권한이라는 것이 있는데 Default 권한 값을 가지고 있는 것은 umask 값이다. 만약 umask 값이 022라면 0은 소유자, 2는 그룹, 마지막 2는 다른 사용자를 의미하며, 이것을 6으로 빼면 그 권한을 확인할 수 있다. 즉 666 - 022 = 644가 되고 여기서 644의 6이라는 것은 r=4, w=2, x=0의 의미로 4 + 2 + 0 = 6이 되므로 소유자는 읽고, 쓰기 권한을 가지고 있다는 것이고 4의 값은 그룹과 다른 사용자는 읽기만 가능하다는 의미하다. 단 디렉터리의 경우 7에서 빼야 한다.
chmod
chmod 명령으로 사용자에게 권한을 부여 하려면 u옵션에 rwx(읽기, 쓰기, 실행) 권한을 부여하고 그룹에게 권한을 부여할 때는 g 옵션, 다른 사용자에게 부여할 때는 o 옵션을 사용한다.
chmod [옵션] 파일명 최고 권한은 777이다
각각의 형식은 읽기 쓰기 실행이 들어가며 아래 내용을 본다.
각각의 숫자를 모두 더하면777이 되며 읽기 쓰기 실행에 대하여 모든 유저가 권한을 가지게된다.
ex. #chmod 771 abc
abc 파일에 대하여 유저와 그룹은 쓰기, 읽기 실행 권한이 주어지며, 다른 사용자에게 실행 권한만 주어진다.
chmod
리눅스에서 권한을 부여하는 명령은 chmod로 부여할 수 있으며 다음의 예처럼 Limbest.txt 파일에 764라는 권한을 부여하면 소유자는 읽고, 쓰고 실행할 수 있고 그룹은 읽고 쓸 수만 있고 마지막으로 다른 사용자는 읽기만 가능하다
chmod는 명령은 위의 예처럼 숫자를 사용해서 권한을 부여할 수도 있지만 문자를 써서 권한을 부여하거나 삭제할 수도 있다.
리눅스 파일의 종류
u : user
g : group
o : other
a : all
+ : 추가
- : 삭제
r : 읽기
w : 쓰기
x : 실행
+의 의미는 권한을 추가하는 것이고 -의 의미는 권한을 회수하는 것이다. setuid는 s를 추가하면 된다.
chown
chown(Change Owner) 명령어는 파일에 대한 사용자와 그룹을 변경할 수 있는 명령어로 chown[option][UID:GID][디렉터리/파일명] 형식으로 사용된다. chown 명령에서 -R 옵션은 하위 디렉터리 및 파일 모두에 적용하라는 것을 의미한다. 또한 -c 옵션은 권한 변경 파일 내용을 출력하는 옵션이다.
chown 명령어 옵션
-R : 하위 디렉터리의 모든 권한을 변경
-c : 권한 변경 파일 내용 출력
chown 명령어 대상
u : user 권한
g : group 권한
o : other 권한
a : 모든 사용자 권한
chown 명령어 인자 값
+ : 해당 권한을 더함
- : 해당 권한을 제거
= : 해당 권한을 그대로 변경
권한
r : 읽기 권한
w : 쓰기 권한
x : 실행 권한
chgrp
chgrp 명령은 파일이나 디렉터리의 소유 그룹을 변경하는 명령어로 chgrp[옵션][그룹 파일] 형태로 사용된다.
chgrp 옵션
-c : 실제 변경된 것을 보여준다.
-h : 심볼릭 링크 자체의 그룹을 변경
-f : 그룹이 변경되지 않는 파일에 대해서 오류 메시지를 보여주지 않는다.
-v : 직업 진행 상태를 설명
-R : 하위 모든 파일도 지정한 그룹으로 변경
특수 권한
(1) setuid
setuid 권한이 설정된 파일을 다른 사용자가 실행하게 되면 실행될 때 그 파일의 소유자의 권한으로 실행되는 파일이다. 예를 들어, /etc/passwd는 root가 소유자이고 일반 사용자가 로그인 등을 수행할 때 /etc/passwd 파일을 실행하게 된다. 즉 /etc/passwd 파일을 실행할 때 root의 권한으로 실행된다는 의미이다. 그러므로 /etc/passwd 파일은 -rwsr-xr-x로 설정되어 있고 여기서 소유자 실행 권한 위치에 있는 s라는 것이 setuid가 설정되어 있음을 나타낸다. 그리고 여기서 나타나고 있는 s는 소문자인데 이것이 소문자이면 실행 권한이 있는 것이고 이것이 만약에 대문자 S라면 실행 권한이 없는 것을 의미한다. 즉 /etc/passwd 파일은 /usr/bin/passwd를 실행하여 /etc/passwd 파일의 내용을 변경할 수 있기 때문에 /usr/bin/passwd 실행 파일에 setuid가 설정되어 있는 것이다.
setuid의 설정은 8진수 4000이나 u+s를 사용해서 설정할 수 있다. 즉 chmod 4744 Limbest.txt라고 실행하면 Limbest.txt에 Setuid가 설정되고 744권한이 부여 된다. 또한 chmod u+s Limbest.txt라고 실행하면 사용자에 setuid를 추가하는 것이다. 마찬가지로 Setuid가 설정된 파일을 검색하고 싶다면 권한이 4000이 부여된 것을 find 명령으로 검색하면 모두 찾을 수 있다.
setgid
setgid는 파일 생성자의 그룹 소유권을 얻는 것으로 예를 들어 Limbest라는 사용자가 AAA의 디렉터리에서 디렉터리 생성 및 파일 생성을 할 수 없다. 하지만 root가 chmode 2277 AAA 디렉터리에 setgid를 부여하면 Limbest 사용자가 AAA 디렉터리에 하위 디렉터리를 만들거나 파일을 생성할 수 있게 된다.
setgid를 사용하는 것은 메일 박스(MBox)에서 확인할 수 있다. 예를 들어 /var/mail 디렉터리는 소유자가 root이고 그룹이 mail이면 setgid가 설정되어 잇다. 그러면 일반 사용자는 메일 계정을 생성할 때 mail 디렉터리에 자신의 디렉터리를 생성하고 메일 보관할 수 있게 된다. 또한 setgid는 2000이라는 8진수로 권한을 부여할 수 있다.
sticky bit
sticky bit는 공용 디렉터리를 만들어서 모두들 자유롭게 사용할 수 있도록 하기 위해서 만든 것으로 권한 부여는 1000으로 한다. sticky bit가 부여된 디렉터리는 누구나 자유롭게 사용할 수 있지만, 해당 디렉터리의 삭제는 해당 디렉터리 소유자만 가능하다. 즉, /tmp 디렉터리를 확인하면 drwxrwxrwt로 나타나며, 여기서 t라는 것이 sticky bit이 설정되어 있음을 의미한다.
특수 권한 파일 종류
setuid
실행 파일에서 사용 (/usr/bin/passwd)
setgid
동일한 project에 실행 권한 부여하기 위하여 setgid 사용
sticky bit
디렉터리 내에 인가된 사용자만 쓰기(Write)가 가능하도록 하기 위해서 설정
/tmp - 모든 사용자가 사용 가능하지만, 삭제는 파일의 소유자만 가능하도록 한다(root)는 제외
리눅스 명령어
디렉터리 명령어
디렉터리(Directory)는 파일을 저장하고 관리하는 저장 단위로 디렉터리를 생성할 때는 mkdir 명령어를 사용하고 디렉터리 삭제를 위해서는 rmdir 명령어를 사용한다.
mkdir 명령어는 Make Directory의 약자로 리눅스에서 디렉터리를 생성할 때 사용하며 실행 파일은 /bin/mkdir에 있다.
mkdir 옵션
-m
디렉터리 권한을 설정
기본값은 755(rwxr-xr-x)
-p
상위 경로도 함께 지정한다
-v
디렉터리 생성 후에 생성된 디렉터리에 대한 메시지를 출력한다
파일 명령어
cp(copy)
cp 명령어는 파일 혹은 디렉터리를 복사하는 명령어이다. 즉, 원본 파일과 동일한 파일을 생성하는 것으로 만약 같은 이름으로 파일을 복사하면 덮어씌울 것인지 확인한다.
cp 명령어
cp [옵션][원본파일][복사파일]
cp test test2 // test 파일을 test2 파일로 복사한다
cp 옵션
-f : 덮어쓰기를 해서 복사
-r : 하위 디렉터리 전부를 모두 복사
rm(remove)
파일을 삭제할 때는 rm 명령어를 사용하면 된다.
rm 옵션
-t : 물어보지 않고 강제로 삭제한다
-r : 디렉터리 삭제시에 파일과 하위 경로 모두 삭제
-v : 파일 삭제 정보를 출력한다.
mv(move)
mv 명령어는 파일 및 디렉터리를 이동하거나 파일의 이름을 변경할 때 사용하는 명령어로 원본 파일과 대상 파일의 이름이 다르면 변경되고 이동할 파일이 여러 개이면 이동 모드로만 동작한다.
mv 명령어
mv[옵션] 원본파일 대상파일
mv[옵션] 원본파일 디렉터리
mv[옵션] 디렉터리 디렉터리
mv 옵션
-b : 백업 파일을 생성
-f : 사용자에게 묻지 않고 파일을 덮어쓴다
-i : 덮어 쓸 경우 사용자에게 물어본다
-n : 파일이 존재하면 덮어쓰지 않는다
-S : 지정한 접미사로 백업 생성
-t : 전체 원본 파일을 대상 디렉터리로 이동
-u : 파일이 업데이트된 경우에만 이동한다
-v : 진행 상태 정보를 출력
텍스트 명령어
cat
cat 명령어 파일의 내용을 확인할 수 있는 명령어이다.
cat 명령어
#cat [옵션][파일명]
cat 명령어 실행 시에 cat -n limbest처럼 -n 옵션을 사용하면 파일의 내용을 화면에 출력할 때 행 번호를 같이 출력한다. 또한 리다이렉트를 같이 사용해서 파일을 복사할 수도 있다.
grep
grep 명령어는 특정 파일 내에 있는 문자열을 검색하는 역할을 하는 명령어이다.
grep 명령어
# grep [검색문자열][파일명]
# grep [옵션][검색문자열][파일명]
grep 옵션
-c : 검색 문자열이 속한 행 수를 출력
-H : 파일명과 함께 출력
-i : 대소문자를 구분하지 않음
-n : 검색한 문자가 속하는 행 번호와 함께 출력
-v : 검색하는 문자가 없는 행을 출력
-w : 패턴 표현식을 하나의 단어로 검색
위의 예는 test2--파일에서 "키보드"라는 문자열이 있는 행 수를 출력한다.
test200 파일에서 "키보드"라는 문자열이 있는 파일명과 해당 문자열을 출력한다.
현재 디렉터리에서 하위 디렉터리까지 모든 파일에서 aaa라는 문자열을 표함한 파일을 모두 출력한다. 정규식 표현식(Regular Expressions)은 어떤 문자열의 집합을 묘사할 때 사용하는 텍스트 스트링으로 정해진 구문 규칙을 사용해야 하며 grep 명령어에서도 정규 표현식을 사용할 수 있다.
. : 한 글자를 의미한다
* : 길이와 관계없는 문자열
^ : 행의 첫 시작
$ : 행의 마지막 위치
[] : 한 문자길이 패턴
[^] : 입력된 문자들의 집합
\ : 정규식에 사용되는 문자를 그대로 온다
\< : 단어의 시작 위치
\> : 단어의 마지막 위치
grep 정규식 표현 예제
#grep L, file : file에서 L 속한 행을 출력
#grep L, file : file에서 L 속한 행을 출력
#grep L,m. file : file에서 L,m 속한 행을 출력
네트워크 명령
nestat 명령어는 시스템과 연결된 모든 네트워크 연결을 확인하는 명령어이다.
(1) netstat
netstat 명령어는 시스템과 역결된 모든 네트워크의 연결을 확인하는 명령어이다.
nestat 옵션
-a : 모든 소켓 정보를 확인
-n : 도메인 주소를 읽지 않고 숫자로 출력
-p : PID와 사용 중인 프로그램 명을 출력
-g : 멀티캐스트 그룹 정보
netstat 상태 값
LISTEN : 접속 요청을 대기하고 있는 상태
ESTABLISHED : 연결이 확립되어 통신이 이루어지는 상태
CLOSE_WAIT : 연결 종료를 대기하고 있는 상태
TIME_WAIT : 연결이 종료되고 특정 시간동안 소켓을 열어둔 상태
CLOESE : 연결이 종료된 상태
먼저 라우터의 상태를 netstat 명령으로 확인하면 다음과 같다.
Destination gateway Flags, Ref, Use, Inteface
default 192.222.25.1 UG 1 2 eg0
224.0.0.0 192.222.2521 ㅕ 2 1 0 eg0
위의 예 Flags의 의미는 다음과 같다
U : 라우터가 Up 상태
G : Default Gateway
H : 라우터가 호스트 장비
S : 라우터가 -setsrc 옵션으로 생성
D : 라우터가 redirect로 동적으로 생성
A : 혼합된 라우팅
B : 브로드캐스트 주소
L : 호스트 로컬주소
Ref는 현재 라우터별로 활성화되어 있는 사용중인 숫자이고, Use는 전송하거나 받는 패킷을 수정한다.
(2) arp
ARP는 IP주소를 MAC 주소로 변환하는 프로토콜
-a : ARP Cache 정보에 있는 모든 호스트 정보 출력
-s : ARP Cache 저장된 특정 IP에 대해서 MAC 수정 변경
-i : 특정 Ethernet의 APP를 설정한다.
taceroute
traceroute 명령어는 네트워크를 사용해서 목적지를 찾아가는 경로 정보를 알 수 있는 명령어로 IP 주소 혹은 URL 주소를 입력하면 네트워크를 방문하면 구간별로 게이트 웨이(Gateway) 명, IP 주소, 시간 등의 정보를 표시한다.
traceroute는 내부적으로 UDP와 ICMP를 사용한다.
traceroute 명령어 사용법
traceroute[-m max_ttI][-n][-p port][-q nqueries][-r][-s src_addr][-t tos][-w]
[-w waittime]host[packetsize]
traceroute 옵션
-m :
IP 패킷의 최대 TTL(Time to Live)을 설정
기본 값이 30
-n :
홈(Hop) 주소를 출력
-p
사용되는 UDP 포트를 지정
-r
목적 호스트가 직접 로컬로 연결되었다고 지정
-s
호스트 IP를 지정
-t
패킷(Packet)에 대한 Type of Service를 지정
-v
상세 정보를 출력
-w
전송 패킷을 대기하는 시간 설정
위에서 TTL 혹은 Hop이라는 것은 같은 것으로 통과할 수 있는 라우터의 수를 의미한다. 라우터라는 것은 패킷(Packet)을 전송할 때 경로를 결정 해주는 네트워크 장비이다.
ping :
ping 명령어는 네트워크 상태를 점검하기 위한 명령어로 ICMP 프로토콜을 사용하여 ICMP echo Request를 전송하고 ICMP echo reply가 되돌아 오는지를 확인하여 네트워크의 상태를 점검하는 명령어이다
nslookup :
nslookup 명령어는 네트워크를 관리할 수 있는 도구로 도메인 명에 대한 IP주소를 확인하기 위해서 DNS(Domain Name Server)에게 질의(Query)를 실행한다. 즉 www.baon.com
에 대한 IP 주소를 확인한다.
05 리눅스 종료
리눅스를 종료하거나 재부팅하는 것은 shutdown, reboot, init6그리고 halt 명령어가 있다.
(1) shutdown
shutdown 명령어는 리눅스를 정지하기 위한 명령어이다.
-r : 재부팅을 수행
-h : shutdown 완료 수 시스템을 종료
-c : 진행 중인 shutdown을 취소
-k : 경고 메시지를 출력하고 실제로 shutdown은 수행하지 않았다.
-f : fsck를 실행하지 않고 재부팅
-n : init를 호출하지 않으면서 showdown을 실행
-t sec : 지정한 시간에 재기동한다.
-v : 상세 정보를 출력한다.
만약 5분 후에 시스템이 종료되도록 하고 싶다면 shutdown -h 5를 입력하면 된다.
(2) reboot
reboot 명령어는 리눅스를 다시 시작하는 명령어이다.
-h : 연산을 중지하고 다시 시작
-f : 강제로 다시 시작함
-p : 연산 중지 시에 전원을 종료한다.
-q : 오류가 없으면 다시 시작하지 않는다
-v : 상세 정보를 출력한다.
(3) halt
halt 명령어는 리눅스를 종료시키는 명령어이다.
-d : wtmp에 로그를 기록하지 않는다.
-f : 강제로 종료한다
-n : 종료할 때 동기화를 하지 않는다
-w : 실제로 종료하지 않고 /var/log/wtmp에 로그를 기록한다.
프로세스
01 데몬(Daemon) 프로세스
프로세스라는 프로그램(Program)이 실행되어서 프로그램이 메모리에 올라가는 것을 뜻한다. 프로세스는 메모리를 점유하고 사용자의 요청에 따라 명령을 실행한다. 프로세스를 실행한 사용자가 직접 실행할 수도 있고, 리눅스가 부팅될 때 실행될 수도 있다. 만약 리눅스가 부팅될 때 실행된다면 그것은 init 프로세스가 기동 시키는 것이다. 데몬(Daemon) 프로세스란 리눅스 서버가 부팅될 때 백그라운드에서 실행되고 있다가 클라이언트의 요구에 대한 서비스를 수행하는 프로그램이다.
데몬 프로세스
standalone 방식 :
백그라운드에서 항상 실행되고 있으며 클라이언트에게 서비스를 요청 받으면 즉시 처리를 수행한다.
inetd 방식 :
메모리에 상주되지 않고 sleep 상태로 있다가 클라이언트 요청 시에 Wake up 되어 서비스를 수행한다.
02 프로세스 모니터링
(1) ps
ps 명령어는 프로세스 상태 정보를 확인하는 명령어이다.
(2) pstree
pstree는 실행 중인 프로세스의 상태를 트리 형태로 출력하는 명령어이다. pstree 명령어는 프로세스의 부모 자식 관계를 보여주는 명령어로 프로세스 상관도를 표시한다. -n 옵션ㄴ은 PID 순으로 정렬하고 -p는 프로세스 명과 함께 PID도 출력한다.
(3) top
top은 리눅스 시스템에서 시스템 자원을 모니터링할 수 있는 소프트웨어로 CPU 사용률, 메모리 사용률, 실행 중인 프로세스 리스트 등을 확인할 수 있으며, 실행하는 중에 명령어를 입력해서 추가 기능을 수행할 수 있다.
vi 편집기
01 vi 편집기
vi는 문서를 편집할 수 있는 에디터이다. vi는 명령 실행 모드와 입력 모드로 나누어지고 입력 모드는 문서를 입력할 때 사용되는 것이며 명령 실행 모드는 편집된 문서를 저장하고 취소 등의 명령어를 실행할 때 사용된다. 입력 모드가 되려면 a, i, o를 입려하면 입력 모드로 전환되고 다시 명령 실행 모드로 전환하려면 ESC 키를 입력하면 된다. 또 명령 실행 모드에서 명령어를 입력하고 실행하려면 :, /, ?을 입력한다.
예를 들어 :wq를 저장하고 종료하라는 의미이며 명령어를 실행한 것이다.
vi 입력 모드
i : 커서 위치에서 입력 모드로 변경
a : 커서 위치 우측 한 칸에서 입력 모드로 변경
o : 커서 바로 아래의 줄을 만들고 끼어 넣음
02 vi 저장 명령어
w : 파일 저장
:w! : 무조건 파일 저장
:30, 60w newfile : 30행부터 60행까지 newfile로 저장함
:30, 60w>>file : 30행부터 60행까지 지정된 파일에 추가함
:w % new : 현재 버퍼 파일명을 file new로 저장함
Q : vi를 종료하고 ex로 전환
:e file1 : vi를 종료하지 않고 file1를 편집
:r newfile : newfile의 내용을 현재 파일에서 읽기
:n : 현재 파일을 편집
:e! : 현재 파일을 마지막으로 저장한 상태로 되돌림
:e# : 파일을 번갈아 가면서 편집함
:vi : ex에서 vi 호출
03 vi 이동 명령어
h, j, k, l : 왼쪽, 아래, 위, 오른쪽
w, W, b, B : 한 단어 오른쪽, 왼쪽 이동
e, E : 단어의 끝으로 이동
), ( : 다음 문장, 전 문장의 처음으로 이동
}, { : 다음 문단, 전 문단의 처음으로 이동
]], [[ : 다음 절, 전 절의 시작으로 이동
Enter : 다음 행의 공백이 아닌 처음으로 이동
0, $ : 현재 행의 처음과 끝으로 이동
^ : 현재 행의 공백이 아닌 처음으로 이동
+, - : 다음 행과 이전 행의 공백이 아닌 처음으로 이동
nl : 현재 행의 n째 열로 이동
H : 화면 맨 위 행으로 이동
M : 화면 중간 행으로 이동
L : 화면 맨 아래 행으로 이동
nH : 화면 맨 위 행에서 n째 행으로 이동
nL : 화면 면 아래 행에서 n째 행으로 이동
+F, +B : 한 화면 다음으로, 한 화면 이전으로 이동
+D, +U : 반 화면 아래로, 반 화면 위로 이동
+E, +Y : 화면 한 행 위, 아래로 이동
z : 커서가 있는 행을 화면의 맨 첫 행으로 이동
z. : 커서 가있는 행을 화면의 중간으로 이동
z- : 커서가 있는 행을 화면의 맨 아래로 이동
+L : 스크롤링 없이 화면을 리로드
04 vi 편집 명령어
j,a : 텍스트 커서 앞, 뒤에 입력
I, A : 텍스트 커서 행의 처음, 마지막에 입력
o, O : 커서가 있는 행위 아래, 위에 새로운 행을 입력
05 vi 삭제 및 이동 명령어
x : 커서가 위치한 문자를 삭제
X : 커서 앞의 문자를 삭제
dw : 단어 삭제
dd : 현재 행을 삭제
dmotion : 커서와 motion 대상 사이의 텍스트를 삭제
D : 커서 위치부터 그 행까지 삭제
p, P : 커서 오른쪽, 왼쪽에 지운 텍스트를 삽입
06 vi 문자열 검색
/검색할 문자열/ : 현재 위치에서 아래를 검색
?검색할 문자열? : 현재 위치에서 위를 검색
n : 찾은 문자열 다음으로 계속 검색
N : 찾은 문자열 이전으로 계속 검색
07 vi 명령행 옵션
vi 파일명 : 지정된 파일을 오픈함
vi 파일명 파일명2 : 파일1과 파일2를 순서대로 오픈함
vi -r f파일명 : 파일 복구 후에 잘못된 동작 이후부터 파일을 편집함
vi -t 태그명 : 태그를 검사하고 정의된 위치부터 편집
vi +파일명 : 파일을 열고 본문의 마지막 행에 위치시킴
vi +n 파일명 : 파일을 열고 커서를 n행에 위치시킴
vi -c Command 파일 : 파일을 열고 검색 명령 혹은 행 번호의 명령을 실행함
vi +/패턴 파일 : 패턴 위치에서 파일을 오픈함
08 vi 설정
vi는 .exrc 설정 파일로 이를 사용해서 명령을 실행할 수 있다. set은 vi 편집기에 환경설정을 수행한다. 그리고 ab를 사용하면 문자열을 치환할 수 있다.
set을 이용한 vi 설정 값
autoindent : 자동 들여쓰기 설정(기본값 : autoindent)
shiftwidth : 자동 들여쓰기의 여백 값(기본값, 8)
number : 화면에 라인 번호 나타내기(기본값 number)
tabstop : 탭의 간격을 설정(기본값 8)
showmode : 삽입모드 표시 여부(기본값 : showmode)
wrapmargin : 오른쪽 여백 설정(기본값 : 0)
.exrc 설정 예제
set number
set tabstop=8
vi set 옵션
:set ai : 윗 라인과 동일하게 자동으로 들여쓰기 한
:set si : if, for 등을 입력하고 다음 라인으로 이동할 때 자동으로 들여쓰기 함
:set paste : set si 및 set ai 옵션을 같이 사용해서 붙여넣기 할 경우 계단현상을 방지한다
:set ts = 4 : TAB 키를 입력하여 이동
:set sw = 4 : set si를 사용할 경우에 들여쓰기 하는 깊이를 설정
:set et : TAB 키를 입력할 떄 TAB에 해당하는 공간(SPACE) 이동
:set encoding = utf8 : 기본 인코딩을 설정
:set fenc = utf8 : 다른 인코딩을 설정
:set t_ti : 터미널에서 vi 종료 시에 화면 내용을 나게 하다
:set ruler: 우측 하단에 라인 및 컬럼 위치 표시함
:set tf=unix : 라인 변경 문자를 변경
:set tf=passwd> : 문서를 암호화 하다.
:set ic : 검색 패턴 사용 시 대소문자를 구별하지 않음
:set warm : 종료 시에 경고 메세지 출력
RPM 패키지
01 RPM
RPM(Redhat Package Manager)은 프로그램을 설치하기 위해서 사용되는 명령어로 프로그램 설치를 위해서 확장자가 rpm인 파일(패키지)이어야 한다. 단. 리눅스의 종류별로 패키지 관리 프로그램이 다르다.
rpm 옵션
-i : 패키지 설치
-v : 설치 과정 확인
-h : 설치 진행 과정을 # 마크로 화면에 출력
-U : 패키지 업그레이드
-e : 패키지 삭제
-qa : 설치된 모든 패키지 확인
-qc : 패키지에 의해서 설치된 파일 중 설정 파일 경로를 출력
-qd : 패키지에 의해서 설치된 파일 중 문서 파일 경로를 출력
-qi : 설치된 패키지 정보 확인
-ql : 특정 패키지로 어떤 파일이 설치되었는지 확인
-qs : 패키지로 설치된 파일 정상 여부를 확인
-qpi : 패키지 파일에 어떤 파일이 포함되었는지 확인
-V : 패키지 검사
02 패키지 검증
rpm -V 옵션은 패키지를 검사한 것으로 패키지가 임의로 변경되었는지, 파일 크기, 심볼릭 링크, 장치 파일 변경 등을 확인하는 것이다. 여기서 심볼릭 링크라는 것은 윈도우의 바로가기라고 생각하면 된다.
rpm 검증코드(-V, -a 옵션 사용)
5 : MD5 체크섬을 변경
S : 파일 크기 변경
L : 심볼릭 링크 변경
D : 장치 파일을 변경
U : 파일 사용자, 소유자 변경
G : 파일 그룹이 변경
M : 파일 모드 변경
? : 원인을 알 수 없거나 예측하지 못한 결과
03 RPM 추가 옵션
-test : 패키지 설치 시 가능한 문제점을 점검
-force : 설치를 강제적으로 진행
-nodeps : 패키지 설치, 삭제 시 의존성을 무시하고 진행
rpm -qa -queryformat "%[NAME] ; %{Summary}\n"은 각각 패키지 설명과 설치된 패키지 리스트를 확인한다.
RPM 설치일 확인
-rpm -qa --qf '%{INSTALLTIME:date} % [NAME] - %{RELEASE}'\n grep 패키지 명
RPM 설치 용량 확인
#rpm --qa--queryformat '%[NAME] %[SIZE] \n
SAMBA
01 SAMBA 개요
리눅스 운영체제에 Microsoft의 NETBIOS 프로토콜을 제공해서 윈도우 시스템 운영체제와 자원 및 프린터를 공유하는 프로그램이다.
02 SAMBA 특징
인테넷 및 인트라넷에 서버 파일 및 프린터기를 공유할 수 있는 프리웨어(Freeware) 프로그램이다
공통 인터넷 파일 시스템(CIFS) 클라이언ㅌ, 서버 프로토콜이다.
리눅스 RPM 패키지 설치 도구를 사용해서 설치한다.
TCP/UDP 137, 139 포트를 사용한다
설정 파일은 /etc/samba/smb.conf 및 /etc/smb.cof이다.
03 SAMBA 기동
samba start : SAMBA 서버를 실행시킨다
samba stop : SAMBA 서버를 정지시킨다
smbd : SAMBA에서 NETBIOS 프로토콜로 자료를 전송한다
nmbd : SAMBA에서 NETBIOS 프로토콜의 이름을 관리한다.
Section 01. 네트워크 서버 운영
NIC(Network Interface Card)
01 NIC
NIC는 OSI 7계층에서 물리 계층에 있는 장치(Device)로 컴퓨터의 메인코드(Main Board)에 장착된다.
NIC는 LAN 케이블(UTP)과 연결되어서 네트워크와 컴퓨터 간에 통신을 수행한다.
02 NIC 특징
OSI 7계층에서 데이터 링크 계층과 물리 계층 사이에서 통신을 할 수 있게 한다
베이스밴드(Baseband)를 사용해서 디지털 신호로 변환한다.
사무실에서 사용하는 LAN, 토큰 링(Token Ring) 등의 네트워크에서 사용된다
통신을 위해서 인터페이스(Interface) 역할을 수행한다
NIC 카드에는 물리적인 하드웨어 주소인 MAC 주소가 할당되어 있다.
MAC 주소의 할당은 데이터 링크 계층에서 수행하며, MAC 주소의 상위 24비트는 제조사 번호이다.
이더넷(Ethernet)은 IEEE 802.3 표준이다.
고성능의 데이터 처리를 위해서 송수신되는 데이터를 압축한다.
03 NIC 카드 확인
04 NIC 카드 종류
이더넷(Ehternet)
IEEE 802.3 표준을 지원하고 10Mbps의 속도를 지원
고속 이더넷(Fast Ethernet)
이더넷에 비해서 10배의 성능이 향상된 카드
100Mbps의 성능으로 고속의 데이터 송신과 수신이 가능
고속 이더넷 카드를 설치하면 이더넷도 지원하여 호환성을 유지
기가비트 이더넷(Gigabit Ethernet)
기가비트 이더넷 카드는 광케이블과 연결되어서 고속의 성능을 지원
1Gbps의 성능을 지원
Token Ring
메인 프레임(Main Frame) 시스템에 설치되어서 16Mbps 정도의 성능을 지원
가격이 고가
ATM LAN
고속의 ATM 네트워크에 접속하기 위해서 사용하는 카드
05 ISA과 PCI 방식
NIC 카드와 컴퓨터의 메인 보드 간에 인터페이스 방식은 ISA 방식과 PCI 방식이 있다. 최근 컴퓨터의 인터페이스 방식은 PCI Express 방식을 사용한다.
(1) ISA(Industry Standard Architecture bus) 방식
IBM 컴퓨터의 PC/XT와 PC/AT를 위해서 개발된 인터페이스 방식이다
전송 속도는 16비트에서 3Mbps의 성능을 지원한다.
고속이 요구되는 환경에서 사용하기 어려워서 고속 환경에서 PCI 방식으로 대체되었다.
(2) PCI(Peripheral Component Interconnect bus) 방식
컴퓨터 시스템의 메인코드와 주변 장치 간에 인터페이스를 하는 버스이다.
ISA 방식보다 고속으로 32비트 및 64비트를 지원한다.
데이터 전송 속도가 다른 주변 장치가 연결되어도 버스 마스터링 기능을 처리한다.
팬티엄 PC에 장착되어 있다.
버스 마스터링(Bus Mastering)
인터럽트(Interrupt)를 사용하지 않고 해당 단말기에 직접 정보를 전송하여 DMA(Direct Memory Access) 방식을 계산하였다.
VLAN
01 VLAN(Virtual Local Area Network)
하나의 물리적 스위치(Switch)를 여러 개의 논리적 환경으로 구성해서 각각 다른 설정과 관리를 할 수 있는 네트워크 가상화 기술이다.
VLAN은 IEEE 802 위원회에서 IEEE 802.10 표준으로 지정했다.
네트워크의 성능을 향상시키기 위해서 불필요한 브로드캐스트(Broadcast)를 방지하는 기술이다.
사용자 컴퓨터에서 인터넷을 할 수 있는 것은 사용자 컴퓨터에서 LAN 카드가 있기 때문이다. 즉 사용자 컴퓨터는 LAN 카드를 통해서 인터넷과 같은 통신을 수행하는 것이고 일반적으로 사용자 컴퓨터에는 하나의 LAN 카드가 설정되어 있다. 이러한 것은 서버도 마찬가지이다. VLAN이라는 것은 물리적으로 하나 밖에 없는 LAN 카드를 마치 여러 개의 인터페이스가 있는 것처럼 보이게 하여, 각각 다른 환경 설정을 할 수 있는 네트워크 가상화 기술 중 하나이다.
02 VLAN 장점
네트워크 접속 포트 및 프로토콜의 종류, MAC 주소를 사용해서 VLAN을 구성한다.
네트워크에서 전송되는 불필요한 브로드캐스트를 차단해서 네트워크 성능을 향상시킨다.
데이터 처리 흐름을 관리해서 네트워크의 보안성을 향상시킨다.
03 VLAN 특징
브로드캐스트 제어
나의 VLAN에서 발생된 브로드캐스팅 트래픽은 VLAN으로 전달되지 않기 때문에 브로드캐스트 스톰(Broadcast Storm) 현상을 줄인다.
보안성 향상
브로드캐스팅된 프레임들은 같은 VLAN에 속한 DTE(Date Terminal Equipment : 데이터 흐름 정비/라우터)에만 전달되므로 보안이 유지된다.
트렁크(Trunk)
트렁크 링트는 장치 사이의 VLAN을 전달하고 모든 VLAN 혹은 일부를 전달하는 것을 구성할 수 있음
스위치 간을 연결하는 링크를 자동으로 트렁크로 동작하도록 예고할 때 DTP(Dynamic Trucking Protocol)라는 프로토콜을 사용한다
04 VLAN 종류
정적(Static) VLAN
포트 별로 VLAN을 구성하는 것으로 가장 일반적으로 사용하는 방식
포트 별로 VLAN을 관리하고 모니터링
동적(Dynamic) VLAN
MAC 주소를 기반으로 VLAN을 구성하는 방식으로 대행 스위치에서 사용
05 VLAN 구성
Port 기반
포트를 VLAN에 할당하는 방식으로 같은 VLAN에서 사용하는 포트끼리만 통신이 가능
가장 일반적으로 사용하는 방식
MAC 주소 기반
같은 VLAN에 속해있는 MAC 주소 간에 통신만 가능한 구성
호스트의 MAC 구소를 모두 등록해서 관리해야 한다.
Protocol 기반
같은 프로토콜을 사용하는 호스트로 VLAN을 구성하는 방식
같은 프로토콜을 사용하는 호스만 통신이 가능
Network Address 기반
네트워크 주소를 사용해서 VLAN을 구성하는 방식으로 같은 네트워크의 호스트만 통신이 가능
06 VTP(VLAN Trucking Protocol)
VTP(VLAN Trucking Protocol)은 복수 개의 스위치 간에 VLAN 설정 정보를 교환하는 프로토콜로 VTP를 사용하면 VLAN 설정의 편의성이 향상된다.
(1) VLAN Trunk 방식
ISL(Inter Switch Link)
CISCO 스위치에만 사용하는 Fast Ethernet 링크 및 Gigabit Ethernet 링크에만 사용
스위치 포트, 라우터 인터페이스, 서버 인터페이스 카드에서 서로 트렁크하기 위해서 사용될 수 있다.
IEEE 802.1q
IEEE 프레임 태킹을 위한 표준 방법
CISCO 스위치 링크와 다른 벤더의 스위치르 트렁킹하려면 IEEE 802.1q를 사용해야 한다.
LANE(LAN Emulation)
다중 VLAN을 ATM과 연결할 때 사용된다.
802.10(FDDI)
VLAN 정보를 전송할 때 VLAN을 구별하기 위해서 프레임 헤더의 SAID 필드를 사용
(2) VLAN 정보 확인
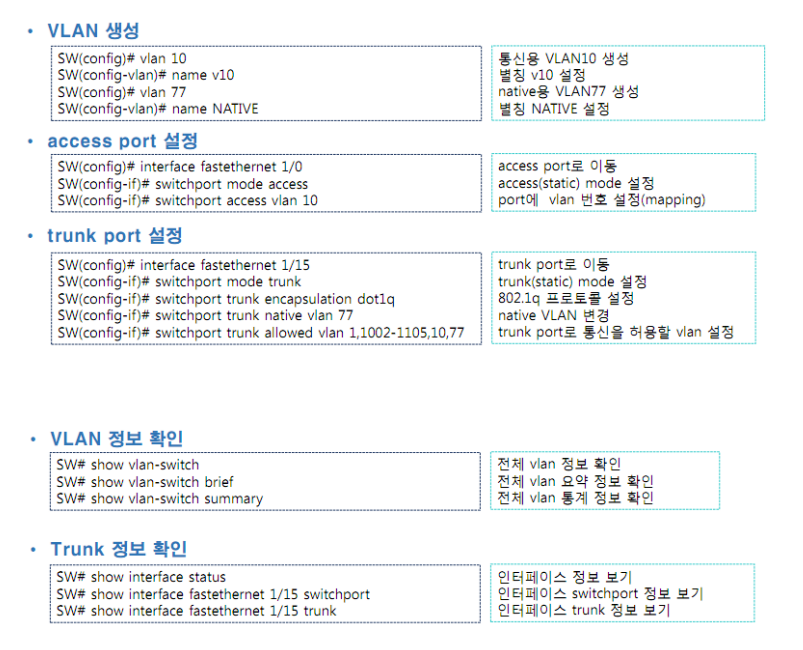
RAID(Rebundant Array of Independent Disks)
01 RAID
RAID 기법은 저용량, 저성능, 저가용성인 디스크를 배열(Array) 구조로 중복 구성함으로써 고용량, 고성능, 고가용성 디스크를 대체할 수 있다.
데이터 분산 저장에 의한 동시 엑세스가 가능하며, 병렬 데이터 채널에 의한 데이터 전송 시간을 단축하는 장점이 있다.
02 RAID 특징
디스크 배열 기술로서 여러 개의 하드 디스크를 하나의 배열로 관리한다.
논리적으로 하나의 디스크로 보인다.
하드 디스크 고장이 발생하면 즉시 백업 하드 디스크가 복구하여 가용성을 향상시킨다.
데이터를 중복해서 저장하여 많은 디스크가 필요하다. 하지만 하드 디스크 고장 시에 복구가 용이한다.
03 RAID 종류
(1) RAID 0(Stripe, Concatenate)
- 총 2개의 디스크로 구성한다.
- 작은 디스크를 모아 하나의 큰 디스크로 만드는 기술로 장애 대응이나 복구 기능은 별도로 제공되지 않는다.
- Disk Striping은 데이터를 나누어 저장하지만 중복되어서 저장하지는 않기 때문에 디스크 장애 발생 시에 복구를 할 수 없다.
(2) RAID 1(Mirroring)
DISK Mirroring은 여러 디스크에 데이터를 완전 이중화하여 저장하는 방식이라서 RAID에서 가장 좋은 방식이지만 비용이 많이 발생한다. Disk Mirroring 방식은 디스크 장애 시에 복구도 가능하고 디스크 Read와 Write가 병렬적으로 실행되어서 속도가 빠른 장점을 가진다.
(3) RAID 2(Hamming Code ECC)
ECC(Error Correction Code) 기능이 없는 디스크의 오류 복구를 위하여 개발되었다.
Hamming code를 이용한 오류 복구를 한다.
RAID 2는 별도의 디스크에 디스크 장애 시 복구를 위한 ECC를 저장하는 것을 말한다. 아래 그림에서 운영 중에 AI 디스크가 장애로 접근이 불가능한 경우가 발생했다고 가정해본다. 이 경우 기존에 A0, A1, A2, A3 디스크에 저장된 정보로 생성된 ECC 값인 Ax, Ay, Az 값을 통해 A1의 값을 재생성해 낼 수 있다.
(4) RAID 3(Parity ECC)
Parity 정보를 별도 Disk에 저장한다(Byte 단위 I/O)
1개의 디스크 장애 시 Parity를 통해 복구가 가능하다
RAID 0(Stripping)으로 구성된 데이터 디스크의 I/O 성능은 향상되나, Parity 계산 및 별도 디스크 저장으로 Write 성능이 저하된다.
1개의 디스크의 오류에도 장애 복구가 가능하며, 컨트롤러 layer에서 오류 디스크 격리 및 Hot Spare Disk를 이용해 데이터를 복구한다.
(5) RAID 4(Parity ECC, Block 단위 I/O)
Parity 정보를 별도 Disk에 저장한다
데이터는 Block 단위로 데이터 디스크에 분산 저장한다.
1개의 디스크 장애 시 Parity를 통해 복구 가능하다.
RAID 0(Stripping)으로 구성된 데이터 디스크의 I/O 성능은 향상되나, Parity 계산 및 별도 디스크 저장으로 Write 성능이 저하된다.
1개 디스크 오류에도 장애 복구가 가능하나 컨트롤러 layer에서 오류 디스크 격리 및 Hot Spare Disk를 이용해 데이터 복구가 가능하다
RAID 4는 RAID 3과 동일하나 Parity를 Block 단위로 관리하는 것만 차이가 있다.
(6) RAID 5(Parity ECC, Parity 분산 저장)
분산 Parity를 구현하여 안전성이 향상되었다.
최소 3개의 디스크가 요구된다(일반적으로 4개로 구성)
(7) RAID 6(Parity ECC, Parity 분산 복수 저장)
분산 Parity 적용된 RAID 5의 안전상 향상을 위해 Parit를 다중화하여 저장한다.
대용량 시스템에서 장애 디스크가 복구되기 이전에 추가적인 장애가 발생되면 복구가 불가했던 문제를 해결하기 위해 개발되었다.
장애 상황에서 추가적인 디스크 장애에도 정상적으로 동작한다.
Section 02. 네트워크 회선 운영
리피터(Repeater)
01 리피터
물리 계층에서 동작하는 장치로 네트워크를 통해서 전송되는 신호 감쇠 문제를 해결하기 위한 장치이다.
장거리 전송을 위해서 신호를 증폭한다.
02 리피터의 특징
신호는 거리 제약 없이 전송되는 것이 아니다. 그러므로 신호를 증폭시켜서 장거리 전송을 할 수 있게 한다.
디지털 신호에 대해서 신호를 증폭하거나 재생하는 역할을 한다.
장거리 전송을 가능하게 해서 네트워크의 규모를 확장한다.
무제한으로 신호가 연장될 수는 없다
OSI 7계층의 상위 계층은 신호 증폭에 대해서 투명성을 가진다.
별도의 리피터 방치를 사용할 수 있지만, 허브(Hub)에 리피터 기능을 가진 것이 있으므로 허브를 사용해서 리피터의 기능을 수행한다.
증폭기(Amplifier)
입력되는 에너지를 증가시켜서 출력에 큰 에너지를 출력하는 장치이다.
허브(Hub)
01 허브
여러 개의 시스템을 연결할 경우 각 포트 별로 케이블을 연결하여 사용할 수 있는 물리 계층의 장치이다.
02 허브의 특징
허브는 분배 장치의 역할을 하는 것으로 여러 개의 포트로부터 신호를 입력 받아서 다시 여러 개의 포트로 신호를 송출한다,
기본적으로 물리계층에서 동작하지만 허브 장치의 특성에 따른 데이터 링크 및 네트워크 계층에서도 동작한다.
만약 허브 장치에 장애가 발생하는 해당 허브에 연결되어 있는 시스템들은 통신을 할 수 없다. 하지만 하나의 시스템 장애는 전체 네트워크 장애를 발생시키는 않는다.
네트워크 상태를 모니터링할 수 있다.
리피터 기능을 장착하고 있어서 디지털 신호 증폭기 역할을 한다.
포트 트렁크(Port Trunk)
여러 개의 포트를 묶어서 하나의 회선으로 사용하는 방법으로 네트워크 트래픽을 해소시키는 기술이다.
03 허브의 종류
더미허브(Dummy Hub)
- 단순한 장치로 시스템과 네트워크 장치 연결만 수행
- 10Mbps 대역폭을 가진 허브에 5대의 시스템을 연결하면 5대의 시스템이 대역폭을 나누어 사용
- 연결된 시스템의 수가 증가하면 성능이 떨어진다.
- 리피터로 구성
지능형 허브(Intelligent Hub)
- SNMP 프로토콜을 사용해서 네트워크 관리 기능이 추가되어 있는 허브
- 포트에 연결된 네트워크 연결상태를 점검
스위치 허브(Switching Hub)
- 스위칭 기능이 추가되어 있어 네트워크 효율을 향상시킨다.
- 리피터가 내장되어 있다.
- 여러 개의 포트에서 입력을 받아서 특정 포트로만 데이터를 전송할 수 있다.
브리지(Bridge)
01 브리지
두 개의 LAN을 연결하는 연결장치로 송신 및 수신되는 통신량을 관리한다.
데이터 링크 계층에서 동작되며 송신 및 수신 되는 프레임(Frame)을 검사한다.
02 브리지의 특징
네트워크의 범위를 확장하고자 할 때 사용한다.
서로 다른 물리적 네트워크를 연결할 수 있다. 예를 들어 이더넷과 토큰링 네트워크를 연결한다.
네트워크에 많은 컴퓨터를 연결한다.
네트워크의 병목현상을 감소시킨다.
하드웨어 주소인 MAC 주소로 관리된다.
입력 신호를 출력으로 전송하는 포워딩(Forwardding) 기능을 수행한다.
목적지 MAC 주소를 읽어서 필터링을 수행한다.
스위치(Switch)
01 스위치
허브(Hub)와 거의 유사하지만 스위치는 허브보다 전송 속도가 향상되었다.
네트워크에서 충돌이 발생하지 않도록 목적지의 포트로 직접 전송하기 때문에 네트워크의 효율이 향상된다.
02 스위치의 특징
스위칭 허브(Switching Hub) 혹은 포트 스위칭 허브(Port Switching Hub)라고도 한다.
송신자 노드와 수신자 노드를 일대일로 연결하므로 충돌이 발생하지 않는다.
빠른 데이터 전송이 가능하다
송신 및 수신 노드의 수가 증가해도 네트워크의 속도는 저하되지 않는다.
포트 별로 일정한 속도를 가지고 전송되는 패킷(Packet)에 대해서 감청이 어렵다.
불필요한 네트워크 전송을 최소화한다.
03 스위칭 방식
Cut Through
목적지의 MAC/Address만 확인 후 해당 포트로 전송
Store and Forward
전체 Frame을 모두 저장한 후에 Error Check를 수행 후 전송
Fragment Free
Modify Cut Through
Frame의 64비트를 검사, Header의 Error를 검사한 후 전송
512Bit가 수신될 때까지 대기한 후 에러가 존재하지 않으면 전송하는 방식
라우터(Router)
01 라우터(Router) 개요
라우터는 인터네트워킹(Internetworking) 장비로 네트워크에서 IP 주소를 읽어서 경로를 결정하는 장비이다.
LAN과 LAN을 연결하고 TCP/IP 프로토콜을 지원한다.
02 라우터의 특징
OSI 7계층의 네트워크 계층에서 동작한다.
주기적인 라우팅 브로드캐스트를 사용해서 최신의 라우팅 테이블을 유지한다.
패킷에서 IP주소를 읽어서 경로를 결정한다.
특정 IP에서 유입되는 패킷이나 특정 IP로 전송되는 패킷에 대해서 필터링(Filtering)을 수행할 수 잇다.
브로드캐스트를 차단하거나 입력 인터페이스로 입력된 패킷을 출력 인터페이스로 전송하는 포워딩(Forwarding)을 수행한다.
03 route 명령어
윈도우에서 route라는 명령어를 사용해서 라우팅 테이블을 관리할 수 있다. route 명령어는 라우팅 테이블(Routing Table)에 라우팅 정보를 추가, 변경, 삭제할 수 잇고, 라우팅 테이블 정보를 출력할 수도 있다. 라우팅 정보는 IPv4 정보와 IPV6 정보로 나누엇 관리된다.
IPv4 라우팅 테이블을 보려면 PRINT 옵션에 '-4'를 추가해서 실행하면 확인할 수 있다.
라우팅 테이블에 라우팅 정보를 추가하려면 ADD 옵션을 사용하고 IP 주소, 서브넷 마스크, 게이트 웨어 주소, 메트릭스 정보를 입력하면 된다.
route DELETE 명령은 등록한 라우팅 정보를 삭제한다. 만약 변경을 하려면 CHANGE 옵션을 사용한다.
게이트웨이(Gateway)
01 게이트웨이
다른 네트워크 간의 상호 연결을 위해서 사용되는 네트워크 장비이다.
서로 다른 프로토콜 간에 변환을 수행하여 프로토콜이 달라도 통신을 가능하게 한다.
02 게이트웨이의 기능
(1) 메시지(Message) 변환
서로 다른 네트워크에서 사용하는 메시지 포맷 형식을 변환한다.
예를 들어, ASC 2 Code로 작성된 메시지를 EBCDIC 코드로 변환한다.
(2) 프로토콜(Protocol) 변환
서로 다른 종류의 프로토콜을 변환한다.
TCP/IP 프로토콜과 ATM 프로토콜 간의 상호변환을 수행한다.
(3) 주소(Address) 변환
서로 다른 주소를 변환한다
예를 들어 IPv4 주소와 IPv6의 주소 간에 변환을 수행한다.
(4) 방화벽(Firewall)
서로 다른 네트워크를 연결하여 패킷 필터링과 같은 방화벽 역할을 수행한다.
(5) 프록시 서버(Proxy Server)
프록시 서버는 중계기 역할을 수행하는 것으로 프록시 서버를 통해서 다른 네트워크로 접근한다.
