
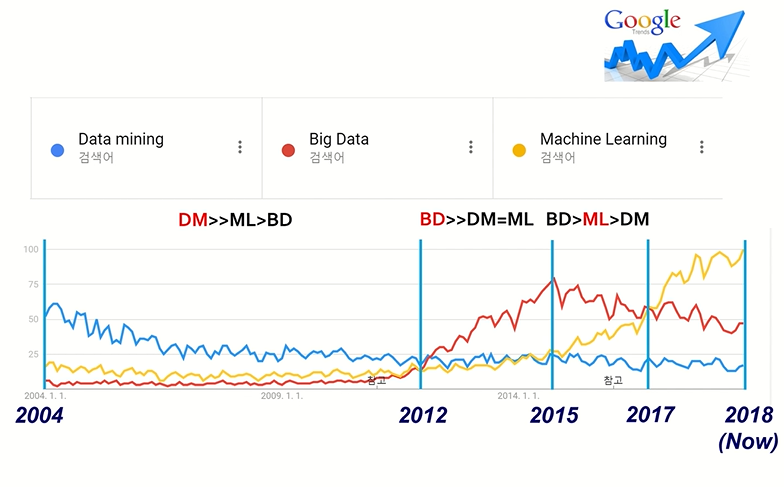
용어 트렌드
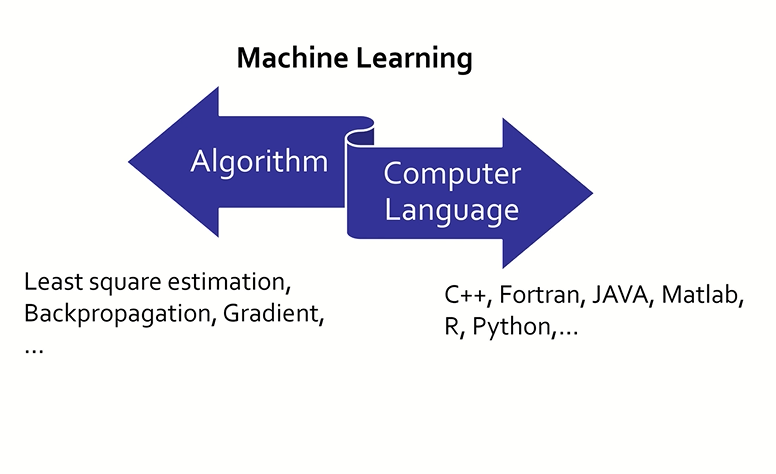
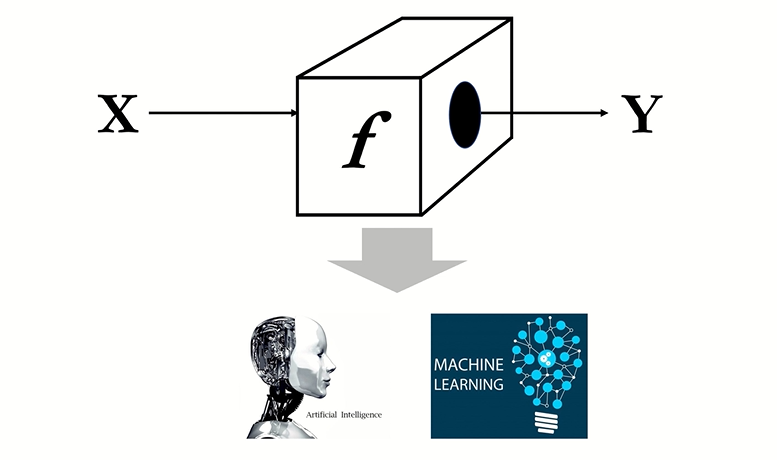
기계 학습(Machine Learning)

machine learning
기계 학습또는머신 러닝(machine learning)은 경험을 통해 통해 개선하는 컴퓨터 알고리즘의 연구이다.
방대한 데이터를 분석해 미래를 예측하는 기술이자, 인공지능의 한 분야로 간주된다.
참고로, 딥러닝은 머신러닝의 일종이다. 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야이다.
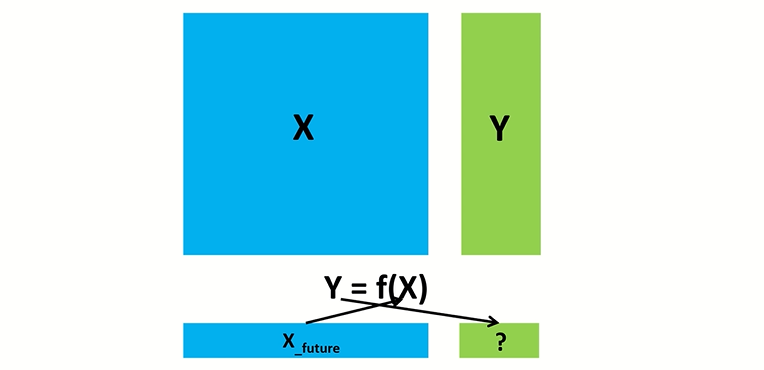
기계 학습의 핵심은표현(representation)과일반화(generalization)에 있다.표현이란 데이터의 평가이며,일반화란 아직 알 수 없는 데이터에 대한 처리이다. 이는 전산 학습 이론의 분야이기도 하다.
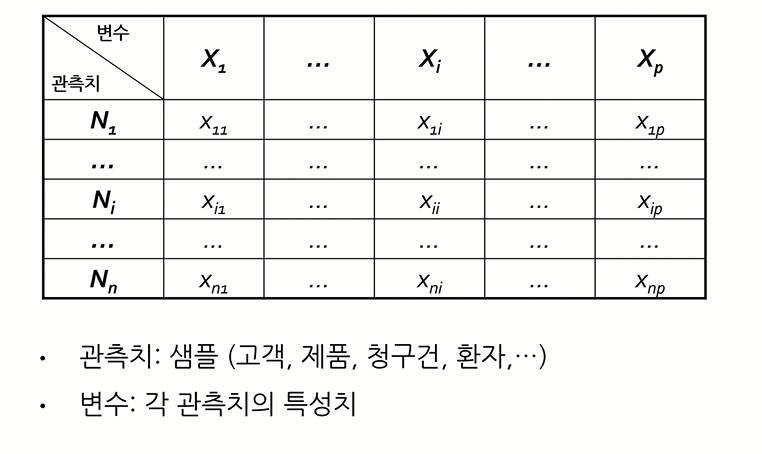
다변량 데이터
데이터 구조
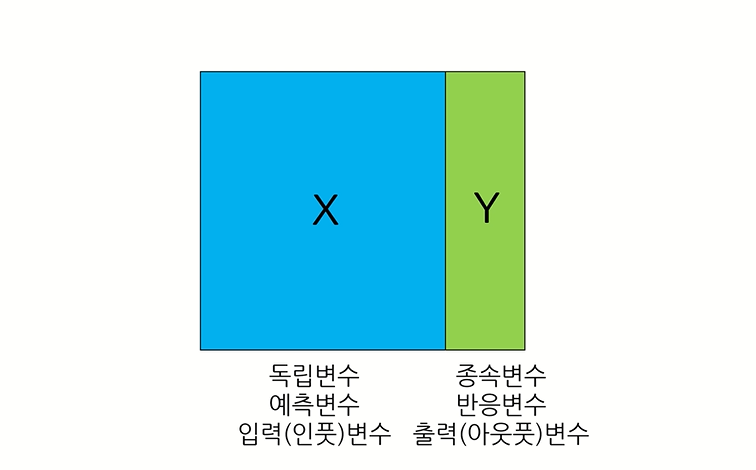
독립 변수는 연구자가 의도적으로 변화시키는 변수를 말한다.
독립 변수는Independent variable이다. 말 그대로독립적인 변수이다. 통계에서 독립적이라는 말은 다른 변수에 영향을 받지 않는다는 뜻이다. 따라서 독립 변수는 다른 변수에 영향을 받지 않는다. 오히려 종속 변수에 영향을 주는 변수를 말한다.
종속 변수는 연구자가 독립 변수의 변화에 따라 어떻게 변하는지 알고 싶어하는 변수를 말한다.
종속 변수는Dependent variable이다. 말 그대로 종속적인 또는 의존적인 변수이다. 즉 독립 변수에 영향을 받아서 변화하는 변수를 종속 변수라고 생각하면 된다.독립 변수는 연구자가 마음대로 조정할 수 있는 변수이다. 독립 변수가 어떻게 변화하느냐에 따라 종속변수가 어떻게 변화하는지 보고 싶기 때문이다. 이 때문에 독립 변수는원인 변수(Explanatory variable),예측 변수(Predictor variable)라고 부르기도 한다. 반면에 종속 변수는 연구자가 알고 싶어하는 변수이다. 연구자의 목표는 독립 변수를 조정하여 변화시킬 때 종속 변수가 어떻게 변화하는지 알아내는 것이다. 이 때문에종속 변수를응 변수(Response variable),결과 변수(Outcome variable)이라고 부르기도 한다.
다변량 데이터 예제 - 중고차 데이터
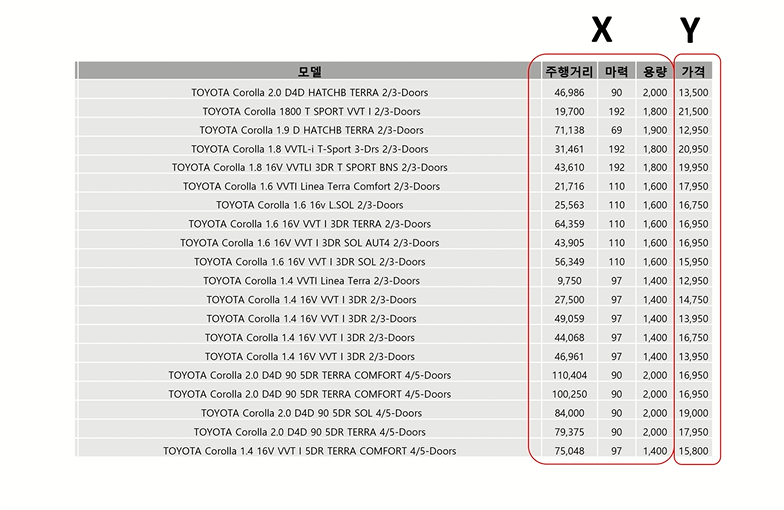
머신러닝 모델링
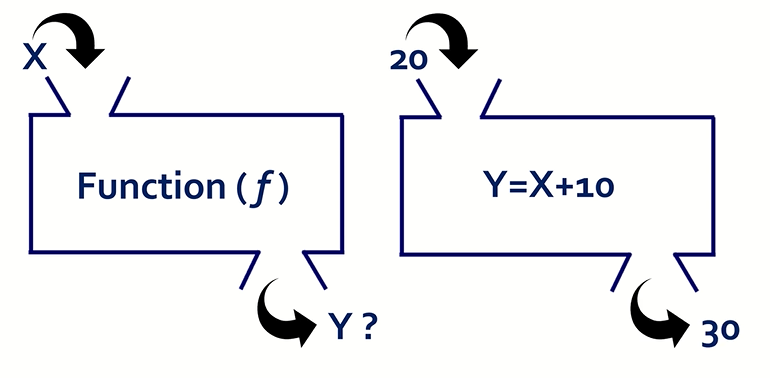
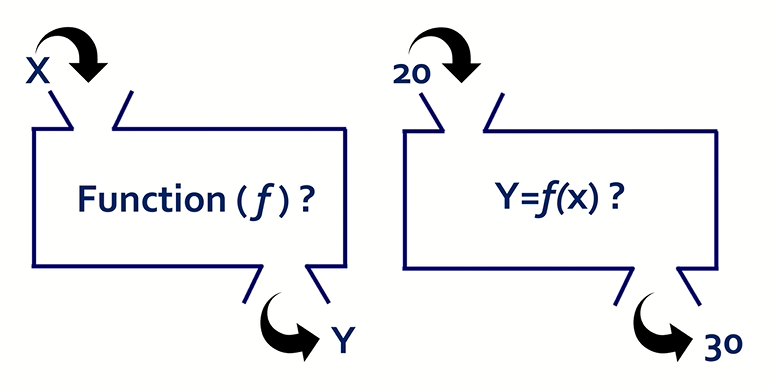
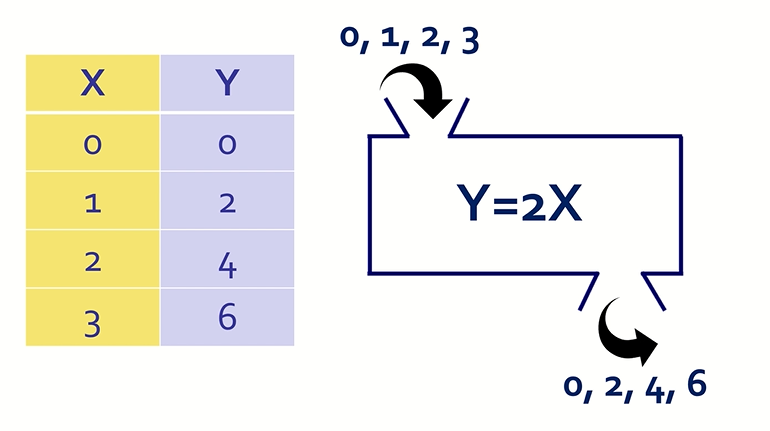
머신 러닝 모델
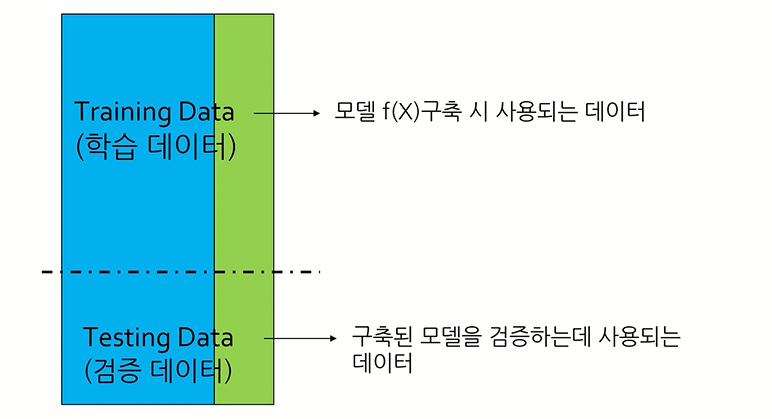
머신 러닝 모델이란 이전에 접한 적 없는 데이터 세트에서 패턴을 찾거나 이를 근거로 결정을 내릴 수 있는 프로그램이다. 예를 들어자연어 처리의 경우, 머신 러닝 모델은 파싱을 통해 이전에 접한 적 없는 문장이나 단어 조합의 배후 의도를 올바로 인식할 수 있다.이미지 인식의 경우, 머신 러닝 모델이 자동차나 개 등 사물이 인식하도록 교육할 수 있다. 머신 러닝 모델ㅇㄴ 대규모 데이터 세트로 '교육'하면 이러한 작업을 수행할 수 있게 된다. 교육을 하면서 머신 러닝 알고리즘이 데이터 세트에서 특정 패턴이나 출력(작업 종류에 따라)을 찾아내도록 최적화한다. 이 프로세스의 출력물은 대개 특정 규칙과 데이터 구조를 포함힌 컴퓨터 프로그램의 형태를 따는데, 이것을 머신 러닝 모델이라고 한다.
빅데이터 모델링 및 예측
빅 데이터 모델링
현실 상황의 과정과 결과값이 완성된 단계 이후에 그 많은 복잡한 데이터를 새롭게 정의하고, 기업이나 공공기관에서 새로운 서비스나 신 사업의 전략적 의사 결정의 중요한 가치를 창출하기 위하여 필요한 전략적 모델링이 빅데이터 모델링이다. 이 방법론은JPD 빅데이터 연구소가 독자적으로 완성한J-BSP(빅데이터전략수립) 방법론에 의하여 도출한 기술적 정의에서 출발하였다.
빅데이터는 많은 양의 데이터를 가르키는 말이지만, 빅데이터 모델링은 데이터의 양적 기준보다 2차, 3차 데이터 가공을 통한 의미있는 빅데이터가 되는 속성과 가치의 요소를 보유한 데이터 구조를 의미한다.
이러한 미래지향적이며, 지속 가능한 데이터 구조를 보유한 미래형 빅데이터를 근거로 새로운 사업과 서비스의 가치 모형을 만들어 내는 의사결정의 구조의 설계를 빅데이터 모델링이라고 한다.
인공지능

자율 주행차 아이디어
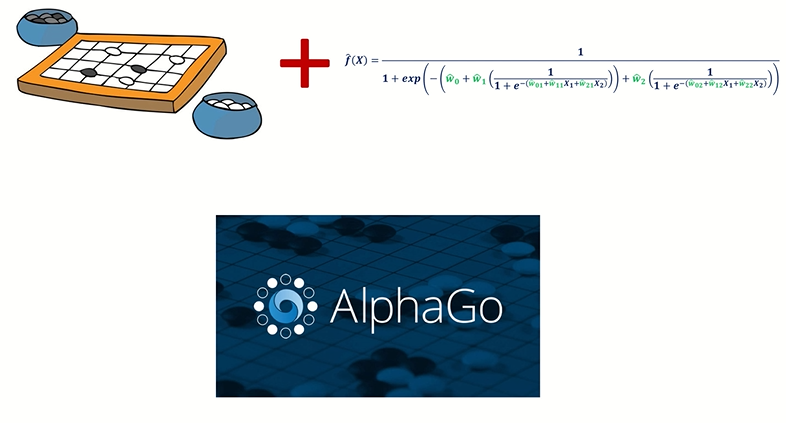
AlphaGo아이디어
인공지능
인공지능은 일반적으로 인간의 지능이 필요하거나 인간이 분석할 수 있는 것보다 규모가 큰 데이터를 포함하는 방식으로 추론, 학습 및 행동할 수 있는 컴퓨터 기계를 구축하는 것과 관련된 과학 분야이다.
AI는 컴퓨터 공학, 데이터 분석 및 통계, 하드웨어 및 소프트웨어 엔지니어링, 언어햑, 신경 과학은 물론 철학과 심리학을 포함하여 여러 학문을 포괄하는 광범위한 분야이다.
비즈니스의 운영 수준에서 AI는 주로 머신러닝과 딥 러닝을 기반으로 하는 기술 모음으로, 데이터 분석, 예상 및 예측, 객체 분류, 자연어 처리, 지능형 데이터 가져오기 등을 수행할 수 있다.
모델 (F(x))의 종류
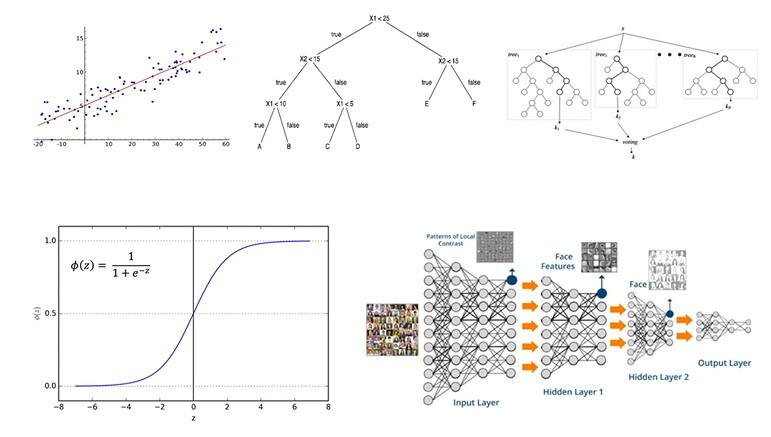
선형 회귀 모델,의사결정나무,랜덤포레스드,시그모이드 함수,
딥러닝
딥 러닝
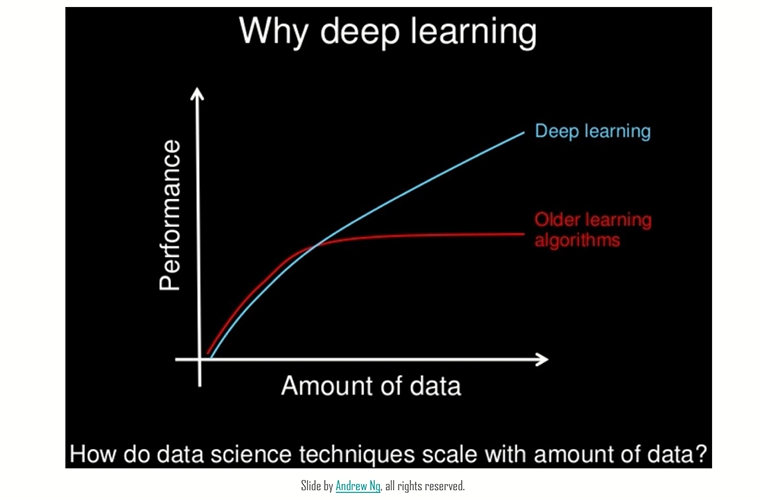
딥 러닝은 머신 러닝의 하위 분야로, 기본적으로 3개 이상의 계층으로 된 신경망이다. 이러한 신경망은 인간의 뇌의 능력에 한참 못 미치지만 인간의 뇌의 행동을 흉내내어 대량의 데이터로부터"학습"을 수행한다. 계층이 하나인 신경망도 대략적인 예측을 수행할 수 있지만, 추가로 숨겨진 계층이 있으면 최적화와 개선을 통해 정확도를 높이는 데 도움이 된다.
딥 러닝은 자동화를 제공하는 많은인공지능(AI) 애플리케이션과 서비스의 기반이 되며, 인간의 개입 없이 분석적 작업과 물리적 작업을 수행한다. 딥 러닝은 (자율주행차와 같은) 새로운 기술뿐만 아니라 (디지털 비서,음성 지원 TV 리모컨,신용카드 사기 탐지) 일상적 제품과 서비스를 뒷받침한다.
가장 많이 쓰이는 알고리즘
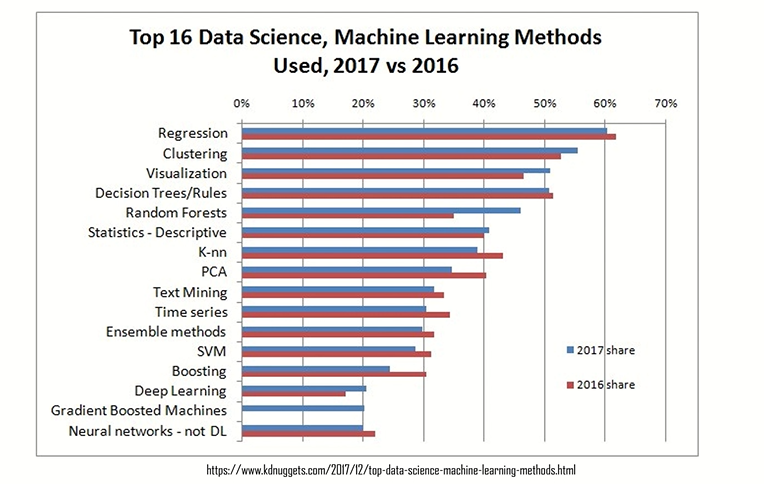
Reference
https://ko.wikipedia.org/wiki/%EA%B8%B0%EA%B3%84_%ED%95%99%EC%8A%B5
https://quickdata.tistory.com/42
https://drhongdatanote.tistory.com/14
https://www.databricks.com/kr/glossary/machine-learning-models
https://m.blog.naver.com/jpdjsj/221042671929
https://cloud.google.com/learn/what-is-artificial-intelligence?hl=ko
https://www.ibm.com/kr-ko/topics/deep-learning
[핵심 머신러닝] 머신러닝 및 인공지능 개요 강의 자료 slide 참조
