BeautifulSoup for web data
BeautifulSoup은 HTML과 XML과 같은 마크업 언어를 분석하기 위한 파이썬 라이브러리로, 크롤링 작업을 쉽게 수행할 수 있도록 도와준다.
BeautifulSoup의 주요 기능
파싱(Parsing): HTML 및 XML 문서를 파싱하여 파이썬 객체로 변환
검색(Searching): HTML 및 XML 문서에서 원하는 데이터를 검색할 수 있다.
필터링(Filtering): 검색한 데이터를 필터링하여 원하는 데이터만 추출할 수 있다.
탐색(Navigation): 추출한 데이터의 상하관계를 파악하여 탐색할 수 있다.
수정(Modifying): 추출한 데이터를 수정하거나 새로운 데이터를 추가할 수 있다.
출력(Outputting): 수정한 데이터를 다시 HTML 또는 XML 문서로 출력할 수 있다.
BeautifulSoup Basic
- conda install -c anaconda beautifulsoup4
- pip install beautifulsoup4
from bs4 import BeautifulSoup
page = open("../data/03. zerobase.html", "r").read()
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
<!DOCTYPE html>
<html>
<head>
<title>
ZeroBase
</title>
</head>
<body>
<div>
<p class="inner-text first-item" id="first">
Happy ZeroBase.
<a href="http://www.pinkwink.kr" id="pw-link">
PinkWink
</a>
</p>
<p class="innter-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link" target="_blink">
Python
</a>
</p>
</div>
<p class="outer-text first-item" id="second">
<b>
Data Science is funny.
</b>
</p>
<p class="outer-text">
<i>
All I need is Love.
</i>
</p>
</body>
</html>
soup.head
<head>
<title>ZeroBase</title>
</head>
soup.body
<body>
<div>
<p class="inner-text first-item" id="first">
Happy ZeroBase.
<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>
</p>
<p class="innter-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link" target="_blink">Python</a>
</p>
</div>
<p class="outer-text first-item" id="second">
<b>Data Science is funny.</b>
</p>
<p class="outer-text">
<i>All I need is Love.</i>
</p>
</body>
soup.p
<p class="inner-text first-item" id="first">
Happy ZeroBase.
<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>
</p>
soup.find("p")
<p class="inner-text first-item" id="first">
Happy ZeroBase.
<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>
</p>
soup.find("p", class_="innter-text second-item")
<p class="innter-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link" target="_blink">Python</a>
</p>
soup.find("p", {"class":"outer-text first-item"}).text.strip()
'Data Science is funny.'
soup.find("p", {"class":"inner-text first-item", "id":"first"})
<p class="inner-text first-item" id="first">
Happy ZeroBase.
<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>
</p>
soup.find_all("p")
[<p class="inner-text first-item" id="first">
Happy ZeroBase.
<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>
</p>,
<p class="innter-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link" target="_blink">Python</a>
</p>,
<p class="outer-text first-item" id="second">
<b>Data Science is funny.</b>
</p>,
<p class="outer-text">
<i>All I need is Love.</i>
</p>]
soup.find_all(id="pw-link")[0].text
'PinkWink'
soup.find_all("p", class_="innter-text second-item")
[<p class="innter-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link" target="_blink">Python</a>
</p>]
len(soup.find_all("p"))
4
print(soup.find_all("p")[0].text)
print(soup.find_all("p")[1].string)
print(soup.find_all("p")[1].get_text())
Happy ZeroBase.
PinkWink
None
Happy Data Science.
Python
for each_tag in soup.find_all("p"):
print("=" * 50)
print(each_tag.text)
==================================================
Happy ZeroBase.
PinkWink
==================================================
Happy Data Science.
Python
==================================================
Data Science is funny.
==================================================
All I need is Love.
links = soup.find_all("a")
links[0].get("href"), links[1]["href"]
('http://www.pinkwink.kr', 'https://www.python.org')
for each in links:
href = each.get("href") href"]
text = each.get_text()
print(text + "=>" + href)
PinkWink=>http://www.pinkwink.kr
Python=>https://www.python.org
BeautifulSoup 예제 1-1 - 네이버 금융
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
response = urlopen(url)
response
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
soup.find_all("span", "value"), len(soup.find_all("span", "value"))
([<span class="value">1,171.10</span>,
<span class="value">1,064.01</span>,
<span class="value">1,383.48</span>,
<span class="value">181.73</span>,
<span class="value">109.9200</span>,
<span class="value">1.1810</span>,
<span class="value">1.3849</span>,
<span class="value">92.6500</span>,
<span class="value">70.45</span>,
<span class="value">1641.73</span>,
<span class="value">1792.0</span>,
<span class="value">67506.13</span>],
12)
soup.find_all("span", class_="value"), len(soup.find_all("span", "value"))
([<span class="value">1,171.10</span>,
<span class="value">1,064.01</span>,
<span class="value">1,383.48</span>,
<span class="value">181.73</span>,
<span class="value">109.9200</span>,
<span class="value">1.1810</span>,
<span class="value">1.3849</span>,
<span class="value">92.6500</span>,
<span class="value">70.45</span>,
<span class="value">1641.73</span>,
<span class="value">1792.0</span>,
<span class="value">67506.13</span>],
12)
soup.find_all("span", {"class":"value"}), len(soup.find_all("span", {"class":"value"}))
([<span class="value">1,171.10</span>,
<span class="value">1,064.01</span>,
<span class="value">1,383.48</span>,
<span class="value">181.73</span>,
<span class="value">109.9200</span>,
<span class="value">1.1810</span>,
<span class="value">1.3849</span>,
<span class="value">92.6500</span>,
<span class="value">70.45</span>,
<span class="value">1641.73</span>,
<span class="value">1792.0</span>,
<span class="value">67506.13</span>],
12)
soup.find_all("span", {"class":"value"})[0].text, soup.find_all("span", {"class":"value"})[0].string, soup.find_all("span", {"class":"value"})[0].get_text()
('1,171.10', '1,171.10', '1,171.10')
BeautifulSoup 예제1-2 - 네이버 금융
- !pip install requests
- find, find_all
- select, select_one
- find, select_one : 단일 선택
- select, find_all : 다중 선택
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
print(soup.prettify())
exchangeList = soup.select("#exchangeList > li")
len(exchangeList), exchangeList
title = exchangeList[0].select_one(".h_lst").text
exchange = exchangeList[0].select_one(".value").text
change = exchangeList[0].select_one(".change").text
updown = exchangeList[0].select_one(".head_info.point_dn > .blind").text
title, exchange, change, updown
('미국 USD', '1,171.20', ' 3.80', '하락')
[<span class="value">1,171.20</span>,
<span class="value">1,063.81</span>,
<span class="value">1,382.95</span>,
<span class="value">181.70</span>]
baseUrl = "https://finance.naver.com"
baseUrl + exchangeList[0].select_one("a").get("href")
'https://finance.naver.com/marketindex/exchangeDetail.nhn?marketindexCd=FX_USDKRW'
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title": item.select_one(".h_lst").text,
"exchnage": item.select_one(".value").text,
"change": item.select_one(".change").text,
"updown": item.select_one(".head_info.point_dn > .blind").text,
"link": baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx", encoding="utf-8")
BeautifulSoup 예제2 - 위키백과 문서 정보 가져오기
import urllib
from urllib.request import urlopen, Request
html = "https://ko.wikipedia.org/wiki/{search_words}"
req = Request(html.format(search_words=urllib.parse.quote("여명의_눈동자")))
response = urlopen(req)
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify())
n = 0
for each in soup.find_all("ul"):
print("=>" + str(n) + "========================")
print(each.get_text())
n += 1
=>0========================
계정 만들기
=>1========================
토론기여
=>2========================
대문최근 바뀜요즘 화제임의의 문서로기부
=>3========================
사랑방사용자 모임관리 요청
=>4========================
도움말정책과 지침질문방
=>5========================
여기를 가리키는 문서가리키는 글의 최근 바뀜파일 올리기특수 문서 목록고유 링크문서 정보이 문서 인용하기위키데이터 항목
=>6========================
책 만들기PDF로 다운로드인쇄용 판
=>7========================
문서토론
=>8========================
=>9========================
읽기편집역사 보기
=>10========================
=>11========================
EnglishفارسیKreyòl ayisyenMagyarBahasa IndonesiaItaliano日本語PolskiPortuguês吴语中文
=>12========================
소설《여명의 눈동자》
=>13========================
1 개요
2 등장 인물
2.1 주요 인물
2.2 여옥의 주변 인물
2.3 하림의 주변 인물
2.4 그 외
3 제작진
4 시청률
5 본방송 편성 변경
6 재방송 결방 사유 및 편성 변경
7 수상 경력
8 OST
9 참고 사항
10 고증 오류
11 주해
12 각주
13 외부 링크
=>14========================
2.1 주요 인물
2.2 여옥의 주변 인물
2.3 하림의 주변 인물
2.4 그 외
=>15========================
채시라 : 윤여옥 역 (아역: 김민정)
박상원 : 장하림(하리모토 나츠오) 역 (아역: 김태진)
최재성 : 최대치(사카이) 역 (아역: 장덕수)
=>16========================
최불암 : 윤홍철 역 - 윤여옥의 아버지
한차돌 : 최대운 역 - 최대치와 윤여옥의 아들
오연수 : 봉순 역
=>17========================
김소원 : 장하림의 어머니 역
김동현 : 장경림 역 - 장하림의 형 (아역: 이민우)
안해숙 : 장경림의 아내 역
=>18========================
박근형 : 최두일(스즈키) 역
이정길 : 김기문 역
장항선 : 오오에 오장 역
박인환 : 구보다 일병 역
임현식 : 황성철 역
홍승옥 : 성철 처 역
김흥기 : 미다 요시노리 대위 역
고현정 : 안명지 역
최현미 : 이경애 역
심양홍 : 박창석 변호사 역
남성훈 : 백인수 역
이창환 : 이승만 대통령 역
민지환 : 관동군 731부대장 이시이 시로 중장 역
김기주 : 일본군 15군 사령관 무다구치 렌야 중장 역
김두삼 : 조선인 마루타 역
김두삼 : 일본군 헌병 역
전운 : 황 대장 역
김인문 : 이민섭 역
국정환 : 김덕재[3] 역
윤여정 : 허정숙 역
정대홍 : 박태원 역
신동훈 : 조장 역
박용수 : 이주환 역
변희봉 : 박춘금 역
홍성민 : 곽춘부 역
이원재 : 조문귀 역
김영옥 : 김 노인 역
김지영 : 안씨 역
김수미 : 강씨 역
최상훈 : 김 대장 역
정진 : 고창대 역
남포동 : 부태종 역
유승봉 : 김정식 역
이대로 : 안재홍 역
최명수 : 조병옥 역
박웅 : 노일영 역
이효정 : 김익렬 역
최병학 : 문 경찰국장 역
박영지 : 오 형사 역
김영석 : 송 순경 역
박세준 : 문 중위 역
정동환 : 김승원 검사 역
정한헌 : 니시하라 역
김홍석 : 오오와쿠 역
임대호 : 겐지 역
김상순 : 관동군사령관 히라따 중장 역
김세준 : 관동군사령관 전속부관 요시하루 소좌 역
윤철형 : 관동군 731부대 다무라 중위 역
이희도 : 관동군 731부대 미술병 오하라 일병 역
홍순창 : 관동군 731부대 동물반 이사키 역
윤문식 : 고가 역
정성모 : 이성도 역
정호근 : 권동진 역
정명환 : 강균 역
송경철 : OSS요원 박일국 역
유명순 : 일국 모 역
김주영 : 서강천 역
김현주 : 장하림의 하숙집 주인 애인 가즈꼬 역
전미선 : 오순애 역
이영달 : 순애의 할아버지 역
김나운 : 매란 역
곽진영 : 임갑생 역
정옥선 : 고씨 부인 역
이성웅 : 일본 경시청 고등계 야마다 형사 역
맹상훈 : 곤노 역
이미경 : 하나꼬 역
권은아 : 민희 역
김길호 : 가즈꼬 아버지 역
남영진 : 권중구 역
황범식 : 최성근 역
임문수 : 공산당 간부 역
김기현 : 김기문을 비판하는 공산당 간부 역
노영국 : 김호 역
한석규 : 서북청년단 단원 1 역
차광수 : 서북청년단 단원 2 역
임창정 : 길수 역
한규희 : 임화 역
홍성선 : 완장 청년 역
서영애 : 여사 상범 역
문미봉 : 김 노파 역
김복희 : 송 노파 역
데니스 크리스틴 : 아얄티 중령 역
한은진 : 금 노파 역
정애란 : 방 노파 역
김윤형 : 김 대장 역
나영진 : 인민위원장 역
문용철 : 인민위원회 부위원장 역
박영태 : 한규희 역
김동완 : 관동군 731부대 군의관 역
한태일 : 관동군 731부대 장교 역
이도련 : 조선군 17방면군 대위 역
유퉁 : 관동군 58사령부 참모 역
이치우 : 군조 역
최용민 : 히로히토 역
천호진 : 푸이 역
박종관 : 정백 역
차재홍 : 강 형사 역
안진수 : 최천 역
김명수 : 종훈 역
박경현 : 엄 취조관 역
김성일 : 푸제 역
송영웅 : 야스히토 역
신국 : 영친왕 이은 선생 역
서권순 : 이은 선생 부인 역
오승룡 : 관징량 역
양택조 : 위안커딩 역
김성겸 : 장제스 역
이은철 : 장징궈 역
신윤정 : 장팡량 역
김환교 : 장웨이궈 역
박주미 : 스징이 역
송재호 : 쑨커 역
윤순홍 : 쑹쯔안 역
신귀식 : 다이지타오 역
최재호 : 다이안궈 역
박종설 : 일본군 헌병 역
박종설 : 빨치산 대원 역
이진우 : 홍성백 역 - 상하이 주재 일본군 헌병대 이탈 조선인 학도병
김찬우 : 진공팔 역 - 히라따 관동군사령관에게 밉보여 뺨을 맞는 조선인 학도병
오승명 : 배급소 소장 역
황윤걸 : 공산당 당원 1 역
심우창 : 공산당 당원 2 역
이성호 : 공산당 당원 3 역
이병식 : 공산당 취조관 1 역
김동현 : 공산당 취조관 2 역
김동수 : 전남 여수 청년 역
차윤회 : 제주도 사내 역
박형준 : 반민특위 사무실 항의하러온 청년 역
구보석 : 빨치산 대원 역
=>19========================
박용수
이정훈
=>20========================
기획 - 최종수
원작 - 김성종
극본 - 송지나
작·편곡 - 최경식
편집 - 조인형
촬영 - 임이랑, 한숙동, 서득원, 조수현
촬영보 - 연석돌, 유종수, 최안식
조명 - 송문섭
조명보 - 김근수, 강호일, 이범호
무대 디자인 - 서정남, 성철중, 전진권, 유현상, 백성흠
그래픽 디자인 - 김양배
타이틀 제작 - 제일기획
미술지원 - 김종수, 이영우, 마봉두
장치 - 권오룡, 박오순, 전인수
사식 - 우상원
분장 - 유재영, 김봉천, 장 진
미용 - 오순심, 김명춘
의상 - 이혜란, 박근성
장신구 - 신 걸
소도구 - 백공기, 송재호, 강홍대, 이건무
특수효과 - 박광남, 민치순, 오희윤
기술감독 - 최 천
VCR 편집 - 이현미
중국 촬영협조 - 장보영, Li Production
필리핀 촬영협조 - Video Cinema Resources
녹화 - 강자중
음향 - 김완식
영상 - 정원식
녹음 - 신기옥, 고희철
음악 - 정용국
효과 - 김주식, 황창욱, 이종렬, 김기수, 최석봉
기록 - 이현미, 권왕례
행정 - 이종태, 윤병철
섭외 - 박창식
진행 - 서정민, 민완식, 정흠문
제작지휘 - 이강훈
조연출 - 이창순, 이광훈
연출 - 김종학
해설 - 이봉준
=>21========================
평균 시청률 44.3%를 기록하며 역대 드라마 평균 시청률 8위에 올랐으며, 편당최고 시청률 58.4%를 기록했다.[4]
=>22========================
이례적으로 2주 분량인 4회분이 월요일부터 목요일까지(1991년 10월 7일 ~ 10일) 연속 방영되었고, 5회부터는 수·목요일에 정규 방영되었다.[5]
마지막회는 1시간 40분 분량으로 방영되었다.
=>23========================
1992년 11월 28일 : 5시부터 MBC 특별기획 《어린이에게 새생명을》 편성 관계로 3시 50분에 방영 (《토요일 토요일은 즐거워》, 《특종! TV연예》, 《아들과 딸》 결방)
1992년 11월 29일 : 7시부터 《아들과 딸》 17회, 18회 연속 편성으로 4시 40분에 방영 (《일요일 일요일 밤에》는 5시 40분에 방영)
1992년 12월 5일 : 5시 40분부터 선거방송 《민자당 연설원 연설》 편성 관계로 6시에 방영
1992년 12월 12일 : 5시 30분부터 《MBC 대학가요제》 1~3부가 편성되어 3시에 방영 (《특종! TV연예》는 4시 30분에 방영)
1992년 12월 19일 : 4시부터 특선영화 《별이 빛나는 밤에》 편성 관계로 3시에 방영
1992년 12월 26일 : 6시 40분부터 《MBC 방송대상》 편성 관계로 3시 30분에 방영 (《특종! TV연예》는 4시 40분에 방영)
1993년 1월 2일 : 특선 코미디 《미스터 빈》 2부 편성으로 인해 결방
1993년 1월 3일 : 특선 코미디 《미스터 빈》 3부 편성으로 인해 결방
1993년 2월 7일 : 4시부터 특집 《MBC 권투 세계 헤비급 타이틀전》 편성으로 3시에 방영
1993년 3월 7일 : 5시 10분부터 세계 청소년축구 《한국 VS 영국》 중계방송으로 인해 결방
1993년 3월 27일 : 5시 10분에 방영
=>24========================
1991년 MBC 연기대상 남자 최우수상 - 최재성
1991년 MBC 연기대상 여자 최우수상 - 채시라
1992년 제28회 백상예술대상 TV부문 대상
1992년 제28회 백상예술대상 TV부문 작품상
1992년 제28회 백상예술대상 TV부문 남자 연기상 - 최재성
1992년 제28회 백상예술대상 TV부문 여자 연기상 - 채시라
1992년 제28회 백상예술대상 TV부문 연출상 - 김종학
1992년 제28회 백상예술대상 TV부문 기술상(촬영) - 조수현
1992년 제28회 백상예술대상 TV부문 남자 인기상 - 박상원
1992년 제19회 한국방송대상 드라마TV부문 최우수 작품상
1992년 제19회 한국방송대상 TV부문 프로듀서상 - 김종학
1992년 제19회 한국방송대상 TV부문 미술상 - 윤상준
=>25========================
당초 윤여옥 역은 김미숙, 안명지 역은 배종옥이 맡을 뻔 했지만 개인사정으로 고사하였다.
줄곧 KBS 드라마에 출연해 오던 최재성이 1990년 KBS 사태 후 다른 방송사로 옮겨 처음 출연한 드라마이기도 했으며[7] 최재성은 《여명의 눈동자》 이후 타방송사에서만 활동해 오다가 <아씨>로 KBS 복귀를 했다.
총 제작기간이 2년 4개월, 출연자와 엑스트라가 모두 21,000명이다.
처음으로 제주4.3사건, 위안부 등을 다루었으며 또한 연출기법 등에 화제가 되었다.[8]
극중 최대치가 뱀을 뜯어먹는 장면은 실제로 배우 최재성이 살아있는 뱀을 뜯는 법을 배워서 직접 껍질을 벗기면서 먹는 장면을 촬영하였으며, 그 후 뱀의 비린내로 고생하였다 한다.
최대치와 윤여옥이 난징에서 헤어지기 전 철조망을 사이에 두고 나눈 키스신, 소위 '철조망 키스신'은 아직까지도 많은 이들로부터 명장면으로 꼽힌다.[9][10]
1992년 2월 25일 채시라는 모교 동국대학교 졸업식에서 '여옥 역을 맡아 학교의 명예를 드높인 점'을 인정받아 민병천 당시 동국대 총장으로부터 공로상을 받았다.[11]
한 고등학교에서는 시청을 권장하는 내용의 훈화가 있었으며, 일부 학교에서는 역사교육 자료의 일환으로 녹화테이프 제공 요청이 있었다.[12]
4·3항쟁을 다룬 내용이 방영된 뒤 문화방송에 제주도민들로부터 “이 사건을 TV에서 다루어준 것만으로도 감사한다”라는 격려의 전화가 쇄도하였다.[13]
극 중 일본어, 중국어, 영어가 나올 때 자막처리를 함으로써 ‘국제적 수준의 드라마로구나’라는 쾌감을 느끼게 했다는 평가도 있다.[13] 당시 《여명의 눈동자》 스페셜 다큐멘터리에 출연해 인터뷰를 한 중앙대학교 영화학과 김정옥 교수는 시간에 쫓기지 않고 미리 3분의 2 이상의 분량을 만들어서 완벽성을 추구하려 했다는 점에서 높은 점수를 주었다고 말했다.
구성에 있어서는 몇 가지 상투적 기법이 사용되었고, 또한 위안부의 모습을 너무 감상적으로 그렸다는 평가까지 나왔다. 또한 당시 흔하지 않았던 드라마 속의 키스신, 731부대의 잔인한 생체실험 장면이나, 뱀을 산 채로 뜯어먹는 등의 자극적이고 참혹한 장면이 과연 안방드라마로 적합한가에 대한 논란이 있었으며 방송위원회가 각종 제재조치를 가하기도 했다.[13]
소설가 김성종의 《여명의 눈동자》를 원작으로 제작되었다. 총 36부작으로 회당 50분 내외로 방영되었지만 중국과 필리핀 등에서 현지 로케이션으로 총 제작비 72억 원, 회당 제작비 2억 원이 들었다.[2]
대한민국-일본 공동 케이블 KNTV를 통해서 방송된 바 있다.
=>26========================
일제 강점기인 1940년대 일제의 강제징용 이야기를 그렸지만, 8.15 광복 묘사[주해 1], 부민관 의거, 해방 후 좌우 대립 등의 고증 관련 오류가 있다.
현준혁은 조만식과 함께 소련군정장관 로마넨코(A.A. Romanenko)가 있는 사령부에 들렀다가 돌아가던 중 평양시청 앞에서 백의사의 백관옥에게 암살당했지만 극중에서 군중들 사이에 연설 중 저격 맞는 것으로 나온다.
9월 총파업 당시 농성중이던 철도노동자 1,00명 검거, 간부 3명이 사망했지만, 극중에서 전평계 노조간부 16명 검거, 노동자 1,200명 검거, 2명 사망, 노동자들에 의해 스스로 미군정에 대한 항쟁한 것으로 나온다.
1945년 7월 부민관 사건은 다이너마이트를 설치해서 폭파하면서 사망한 사람이 없이 대회장을 아수라장이 된 사건이자만 극중에서 OSS의 지시[14] 로 폭탄을 투척하여 사망 1명, 중경상 2명으로 나오며 부민관 건물 고증도 틀리게 나온다.
=>27========================
(한국어) iMBC 드라마 다시보기 여명의 눈동자
여명의 눈동자 - MBCClassic, 유튜브
《스페셜 다큐멘터리 - 여명의 눈동자는 이렇게 만들어졌다》- MBC 문화방송, 1992년 5월 15일 방영.
=>28========================
vte
=>29========================
"계백"
"광개토태왕"
"근초고왕"
"대왕의 꿈"
"대조영"
"바람의 나라"
"삼국기"
"서동요"
"선덕여왕"
"연개소문"
"자명고"
"주몽"
"천년지애"
"천하무적 이평강"
"태왕사신기"
"화랑"
=>30========================
"해신"
"개국"
"기황후"
"대풍수"
"달의 연인 - 보보경심 려"
"달이 뜨는 강"
"도깨비"
"무신"
"무인시대"
"비천무"
"빛나거나 미치거나"
"신돈"
"신의"
"왕은 사랑한다"
"제국의 아침"
"직지"
"천추태후"
"태조 왕건"
"환생: 넥스트"
=>31========================
"7일의 왕비"
"가시리잇고"
"간택 - 여인들의 전쟁"
"객주"
"거상 김만덕"
"구가의 서"
"구르미 그린 달빛"
"구암 허준"
"궁중잔혹사 꽃들의 전쟁"
"꽃파당: 조선혼담공작소"
"너희가 나라를 아느냐"
"다모"
"대군 - 사랑을 그리다"
"대명"
"대박"
"대왕 세종"
"대왕의 길"
"대장금"
"덕혜"
"독립문"
"돌아온 일지매"
"동의보감"
"동이"
"마녀보감"
"마의"
"명가"
"명성황후"
"무사 백동수"
"미스터 션샤인"
"바람과 구름과 비 (1989)"
"바람과 구름과 비 (2020)"
"바람의 화원"
"밤을 걷는 선비"
"불멸의 이순신"
"불의 여신 정이"
"비밀의 문: 의궤 살인 사건"
"뿌리깊은 나무"
"사임당, 빛의 일기"
"삼총사"
"상도"
"서궁"
"성균관 스캔들"
"소설 목민심서"
"식객"
"아랑사또전"
"아무렴 그렇지, 그렇고 말고"
"야차"
"어사 박문수"
"여인천하"
"오포졸"
"옥중화"
"왕과 나"
"왕과 비"
"왕도"
"왕의 얼굴"
"왕의 여자"
"용의 눈물"
"유심초"
"육룡이 나르샤"
"이산"
"일지매 (1993)"
"일지매 (2008)"
"임꺽정"
"임진왜란 1592"
"장길산"
"장녹수"
"장사의 신 - 객주 2015"
"장영실"
"장옥정, 사랑에 살다"
"장희빈 (1971)"
"장희빈 (1995)"
"장희빈 (2002)"
"정도전"
"정조암살 미스터리: 8일"
"조광조"
"조선 과학수사대 별순검"
"조선생존기"
"조선에서 왔소이다"
"조선X파일 기찰비록"
"조선왕조 오백년"
"조선 총잡이"
"집념"
"징비록"
"찬란한 여명"
"천둥소리"
"천명"
"천명: 조선판 도망자 이야기"
"철인왕후"
"최강칠우"
"추노"
"쾌걸춘향"
"쾌도 홍길동"
"탐나는도다"
"태양인 이제마"
"파천무"
"풍운"
"하녀들"
"하늘아 하늘아"
"한명회"
"한성별곡"
"해치"
"허준"
"홍국영"
"화정"
"환생: 넥스트"
"황진이"
=>32========================
"각시탈"
"감격시대: 투신의 탄생"
"경성스캔들"
"김구"
"덕혜"
"도둑놈, 도둑님"
"동양극장"
"백범일지"
"불꽃 속으로"
"서울 1945"
"야인시대"
"영웅시대"
"여명의 눈동자"
"왕초"
"을화"
"자유인 이회영"
"전쟁과 사랑"
"절정"
"최승희"
"한국인"
"환생: 넥스트"
"황금시대"
=>33========================
"THE K2"
"2004 인간시장"
"가시리잇고"
"가을동화"
"갑동이"
"경숙이 경숙아버지"
"구가의 서"
"국희"
"그녀는 예뻤다"
"그해 겨울은 따뜻했네"
"끝없는 사랑"
"김치 치즈 스마일"
"내 마음이 들리니"
"누나의 3월"
"대장금이 보고있다"
"덕이"
"도둑놈, 도둑님"
"도깨비"
"돈의 화신"
"동네의 영웅"
"땅"
"라이벌"
"라이프 온 마스"
"러브스토리 인 하버드"
"로드 넘버원"
"모래시계"
"무풍지대"
"마성의 기쁨"
"미스코리아"
"베토벤 바이러스"
"보고싶다"
"본 어게인"
"불꽃 속으로"
"비밀"
"빛과 그림자"
"사임당, 빛의 일기"
"삼김시대"
"서울 1945"
"소문난 여자"
"순수청년 박종철"
"술의 나라"
"쓰리 데이즈"
"식객"
"아름다운 나의 신부"
"야망의 세월"
"야망의 전설"
"야인시대"
"에덴의 동쪽"
"엔젤 아이즈"
"여명의 눈동자"
"영웅시대"
"오남매"
"옥이 이모"
"올인"
"웬만해선 그들을 막을 수 없다"
"유리화"
"유혹"
"육남매"
"은실이"
"은희"
"응급남녀"
"응답하라 1988"
"응답하라 1994"
"응답하라 1997"
"인간시장"
"자이언트"
"저스티스"
"전우 (1975)"
"전우 (1983)"
"전우 (2010)"
"제1공화국"
"제2공화국"
"제3공화국"
"제4공화국"
"제5공화국"
"조선생존기"
"조선에서 왔소이다"
"천국의 계단"
"천년지애"
"천하무적 이평강"
"철인왕후"
"코리아게이트"
"쾌걸춘향"
"터널"
"투윅스"
"패션 70's"
"풀하우스 TAKE 2"
"환생: 넥스트"
"황금의 제국"
"훈남정음"
"빨강구두"
=>34========================
vte
=>35========================
- (1974)
- (1975)
- (1976)
- (1977)
- (1978)
김혜자, 정혜선, 김영옥(행복을 팝니다) (1979)
=>36========================
김민자(고독한 관계) (1980)
을화 (1981)
등신불 (1982)
풍운 (1983)
신 왕오천축국전 (1984)
한국의 나비 (1985)
신봉승(조선왕조 오백년) (1986)
생인손 (1987)
사랑과 야망 (1988)
김혜자(모래성, 겨울 안개) (1989)
=>37========================
평화 멀지만 가야할 길, 사랑이 꽃피는 나무 (1990)
제2공화국 (1991)
여명의 눈동자 (1992)
고두심(남편의 여자), 김희애(아들과 딸) (1993)
박철(엄마의 바다) (1994)
모래시계 (1995)
한국의 파충류 (1996)
세상에서 가장 아름다운 이별 (1997)
이장수(새끼) (1998)
장수봉(흐르는 것이 세월뿐이랴) (1999)
=>38========================
국희 (2000)
김수현(은사시나무) (2001)
태조 왕건 (2002)
올인 (2003)
김희애(완전한 사랑) (2004)
파리의 연인 (2005)
내 이름은 김삼순 (2006)
주몽 (2007)
강호동(해피선데이) (2008)
김혜자(엄마가 뿔났다) (2009)
=>39========================
고현정(선덕여왕) (2010)
현빈(시크릿 가든) (2011)
뿌리깊은 나무 (2012)
유재석(런닝맨, 무한도전, 해피투게더) (2013)
전지현(별에서 온 그대) (2014)
나영석(삼시세끼, 꽃보다 시리즈) (2015)
태양의 후예 (2016)
김은숙(도깨비) (2017)
비밀의 숲 (2018)
김혜자(눈이 부시게) (2019)
=>40========================
동백꽃 필 무렵 (2020)
유재석 (2021)
=>41========================
vte
=>42========================
수상작 없음 (1974)
수사반장 (1975)
집념 (1976)
KBS 무대 - 한국 단편 문학 순례 시리즈 (1977)
부부 (1978)
6.25 (1979)
=>43========================
한국인 (1980)
TV문학관 - 을화 (1981)
TV문학관 - 등신불 (1982)
풍운 (1983)
베스트셀러극장, 불타는 바다 (1984)
전원일기 (1985)
억새풀 (1986)
생인손 (1987)
사랑과 야망 (1988)
사로잡힌 영혼 (1989)
=>44========================
수상작 없음(1980 ~ 1984)
한국의 나비 (1985)
사람과 사람 (1986)
장애인 도심 정복 훈련 - 이제는 파란불이다 (1987)
천적의 세계 (1988)
한국의 자생 약초 (1989)
=>45========================
사랑이 꽃피는 나무 (1990)
제2공화국 (1991)
여명의 눈동자 (1992)
억새 바람 (1993)
엄마의 바다 (1994)
모래시계 (1995)
연애의 기초 (1996)
세상에서 가장 아름다운 이별 (1997)
달팽이 (1998)
흐르는 것이 세월뿐이랴 (1999)
=>46========================
평화, 멀지만 가야할 길 (1990)
러시아 동구의 문학과 예술 (1991)
백로와 소년 (1992)
잊혀진 전쟁, 종군위안부, 베트남전쟁 그후 17년, 그것이 알고 싶다 (1993)
PD수첩, 독도 365일 (1994)
신인간시대 (1995)
한국의 파충류 (1996)
자연다큐멘터리 게 (1997)
일요스페셜 (1998)
21세기 위원회 (1999)
=>47========================
가요무대 (1990)
일요일 일요일 밤에 (1991)
토요대행진, 토요일! 토요일은 즐거워 (1992)
노영심의 작은 음악회 (1993)
열린음악회 (1994)
일요일 일요일 밤에 (1995)
샘이 깊은 물 (1996)
테마게임 (1997)
이홍렬쇼 (1998)
21세기 위원회 (1999)
=>48========================
국희 (2000)
아줌마 (2001)
피아노 (2002)
네 멋대로 해라 (2003)
꽃보다 아름다워 (2004)
미안하다, 사랑한다 (2005)
토지 (2006)
서울 1945 (2007)
쩐의 전쟁 (2008)
엄마가 뿔났다 (2009)
=>49========================
역사스페셜 (2000)
영상기록 병원 24시 (2001)
MBC 스페셜 - 이슬람 (2002)
야생의 초원, 세렝게티 (2003)
환경의 역습 (2004)
지금도 마로니에는 (2005)
나는 가요, 도쿄 제2의 여름학교 (2006)
긴급출동 SOS 24 (2007)
차마고도 (2008)
그것이 알고 싶다 (2009)
=>50========================
개그콘서트 (2000)
진실게임, 코미디 하우스 (2001)
일요일 일요일 밤에 (2002)
느낌표 (2003)
코미디하우스 (2004)
안녕, 프란체스카 (2005)
상상플러스 (2006)
미녀들의 수다 (2007)
무한도전 (2008)
개그콘서트 (2009)
=>51========================
아이리스 (2010)
시크릿 가든 (2011)
해를 품은 달 (2012)
추적자 THE CHASER (2013)
굿 닥터 (2014)
풍문으로 들었소 (2015)
시그널 (2016)
디어 마이 프렌즈 (2017)
마더 (2018)
나의 아저씨 (2019)
=>52========================
아마존의 눈물 (2010)
학교란 무엇인가 (2011)
다큐프라임 - 문명과 수학 (2012)
한국인의 밥상 (2013)
그것이 알고싶다 (2014)
요리인류키친 (2015)
다큐프라임 - 시험 (2016)
썰전 (2017)
땐뽀걸즈 (2018)
저널리즘 토크쇼 J (2019)
=>53========================
지붕뚫고 하이킥! (2010)
놀러와 - 쎄시봉 콘서트 (2011)
개그콘서트 (2012)
런닝맨, 정글의 법칙, 일밤 - 아빠! 어디가?(2013)
꽃보다 할배 (2014)
비정상회담 (2015)
미스터리 음악쇼 복면가왕 (2016)
미운 우리 새끼 (2017)
효리네 민박 (2018)
전지적 참견 시점 (2019)
=>54========================
스토브리그 (2020)
괴물 (2021)
=>55========================
자이언트 펭TV (2020)
아카이브 프로젝트 - 모던코리아2 (2021)
=>56========================
내일은 미스터트롯 (2020)
놀면 뭐하니? (2021)
=>57========================
백상예술대상 TV부문 대상 수상자(작)백상예술대상 TV부문 작품상1991년 드라마문화방송 수목 미니시리즈문화방송의 역사 드라마일제 강점기 역사 드라마한국 현대사 드라마소설의 텔레비전 프로그램화 작품김종학 프로덕션 텔레비전 프로그램송지나 시나리오 작품1991년에 시작한 대한민국 TV 프로그램1992년에 종료한 대한민국 TV 프로그램한국의 반일 감정
=>58========================
인용 오류 - 지원되지 않는 변수 무시됨깨진 링크를 가지고 있는 문서인용 오류 - URL 없이 확인날짜를 사용함
=>59========================
이 문서는 2021년 7월 21일 (수) 11:16에 마지막으로 편집되었습니다.
모든 문서는 크리에이티브 커먼즈 저작자표시-동일조건변경허락 3.0에 따라 사용할 수 있으며, 추가적인 조건이 적용될 수 있습니다. 자세한 내용은 이용 약관을 참고하십시오.Wikipedia®는 미국 및 다른 국가에 등록되어 있는 Wikimedia Foundation, Inc. 소유의 등록 상표입니다.
=>60========================
개인정보처리방침
위키백과 소개
면책 조항
모바일 보기
개발자
통계
쿠키 정책
=>61========================
soup.find_all("ul")[15].text.strip().replace("\xa0", "").replace("\n", "")
'채시라: 윤여옥 역 (아역: 김민정)박상원: 장하림(하리모토 나츠오) 역 (아역: 김태진)최재성: 최대치(사카이) 역 (아역: 장덕수)'
Python List 데이터형
colors = ["red", "blue", "green"]
colors[0], colors[1], colors[2]
('red', 'blue', 'green')
b = colors
b
['red', 'blue', 'green']
b[1] = "black"
b
['red', 'black', 'green']
colors
['red', 'black', 'green']
c = colors.copy()
c
['red', 'black', 'green']
c[1] = "yellow"
c
['red', 'yellow', 'green']
colors
['red', 'black', 'green']
for color in colors:
print(color)
red
black
green
if "white" in colors:
print("True")
movies = ["라라랜드", "먼 훗날 우리", "어벤저스", "다크나이트"]
print(movies)
['라라랜드', '먼 훗날 우리', '어벤저스', '다크나이트']
movies.append("타이타닉")
movies
['라라랜드', '먼 훗날 우리', '어벤저스', '다크나이트', '타이타닉']
- pop: 리스트 제일 뒤부터 자료를 하나씩 삭제
movies.pop()
movies
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
/var/folders/8c/jb57288j6xlb3s_tkmys1kj00000gn/T/ipykernel_3807/662002098.py in <module>
----> 1 movies.pop()
2 movies
IndexError: pop from empty list
movies.extend(["위대한쇼맨", "인셉션", "터미네이터"])
movies
['라라랜드', '먼 훗날 우리', '어벤저스', '다크나이트', '위대한쇼맨', '인셉션', '터미네이터']
movies.remove("어벤저스")
movies
['라라랜드', '먼 훗날 우리', '다크나이트', '위대한쇼맨', '인셉션', '터미네이터']
movies[3:5]
['위대한쇼맨', '인셉션']
favorite_movies = movies[3:5]
favorite_movies
['위대한쇼맨', '인셉션']
favorite_movies.insert(1, 9.60)
favorite_movies
['위대한쇼맨', 9.6, '인셉션']
favorite_movies.insert(3, 9.50)
favorite_movies
['위대한쇼맨', 9.6, '인셉션', 9.5]
favorite_movies.insert(5, ["레오나르도 디카프리오", "조용하"])
favorite_movies
['위대한쇼맨', 9.6, '인셉션', 9.5, ['레오나르도 디카프리오', '조용하']]
- isinstance: 자료형 True/False
isinstance(favorite_movies, list)
True
favorite_movies
['위대한쇼맨', 9.6, '인셉션', 9.5, ['레오나르도 디카프리오', '조용하']]
for each_item in favorite_movies:
if isinstance(each_item, list):
for nested_item in each_item:
print("nested_item", nested_item)
else:
print("each_item", each_item)
each_item 위대한쇼맨
each_item 9.6
each_item 인셉션
each_item 9.5
nested_item 레오나르도 디카프리오
nested_item 조용하
2. 시카고 맛집 데이터 분석 - 개요
최종목표
총 51개 페이지에서 각 가게의 정보를 가져온다
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소
3. 시카고 맛집 데이터 분석 - 메인페이지
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/"
url = url_base + url_sub
ua = UserAgent()
req = Request(url, headers={"user-agent": ua.ie})
html = urlopen(req)
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())
soup.find_all("div", "sammy"), len(soup.find_all("div", "sammy"))
tmp_one= soup.find_all("div", "sammy")[0]
type(tmp_one)
bs4.element.Tag
tmp_one.find(class_="sammyRank").get_text()
'1'
tmp_one
<div class="sammy" style="position: relative;">
<div class="sammyRank">1</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
</div>
tmp_one.find("div", {"class":"sammyListing"}).get_text()
'BLT\nOld Oak Tap\nRead more '
tmp_one.find("a")["href"]
'/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
import re
tmp_string = tmp_one.find(class_="sammyListing").get_text()
re.split(("\n|\r\n"), tmp_string)
['BLT', 'Old Oak Tap', 'Read more ']
print(re.split(("\n|\r\n"), tmp_string)[0])
print(re.split(("\n|\r\n"), tmp_string)[1])
BLT
Old Oak Tap
from urllib.parse import urljoin
url_base = "http://www.chicagomag.com"
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div", "sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
url_add.append(urljoin(url_base, item.find("a")["href"]))
len(rank), len(main_menu), len(cafe_name), len(url_add)
(50, 50, 50, 50)
rank[:5]
['1', '2', '3', '4', '5']
main_menu[:5]
['BLT', 'Fried Bologna', 'Woodland Mushroom', 'Roast Beef', 'PB&L']
cafe_name[:5]
['Old Oak Tap', 'Au Cheval', 'Xoco', 'Al’s Deli', 'Publican Quality Meats']
url_add[:5]
['http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Au-Cheval-Fried-Bologna/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Xoco-Woodland-Mushroom/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Als-Deli-Roast-Beef/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Publican-Quality-Meats-PB-L/']
import pandas as pd
data = {
"Rank": rank,
"Menu": main_menu,
"Cafe": cafe_name,
"URL": url_add,
}
df = pd.DataFrame(data)
df.tail(2)
|
Rank |
Menu |
Cafe |
URL |
| 48 |
49 |
Le Végétarien |
Toni Patisserie |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 49 |
50 |
The Gatsby |
Phoebe’s Bakery |
https://www.chicagomag.com/Chicago-Magazine/No... |
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
df.tail()
|
Rank |
Cafe |
Menu |
URL |
| 45 |
46 |
Chickpea |
Kufta |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 46 |
47 |
The Goddess and Grocer |
Debbie’s Egg Salad |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 47 |
48 |
Zenwich |
Beef Curry |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 48 |
49 |
Toni Patisserie |
Le Végétarien |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 49 |
50 |
Phoebe’s Bakery |
The Gatsby |
https://www.chicagomag.com/Chicago-Magazine/No... |
df.to_csv(
"../data/03. best_sandwiches_list_chicago.csv", sep=",", encoding="utf-8"
)
4. 시카고 맛집 데이터 분석 - 하위페이지
import pandas as pd
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
df = pd.read_csv("../data/03. best_sandwiches_list_chicago.csv", index_col=0)
df.tail()
|
Rank |
Cafe |
Menu |
URL |
| 45 |
46 |
Chickpea |
Kufta |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 46 |
47 |
The Goddess and Grocer |
Debbie’s Egg Salad |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 47 |
48 |
Zenwich |
Beef Curry |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 48 |
49 |
Toni Patisserie |
Le Végétarien |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 49 |
50 |
Phoebe’s Bakery |
The Gatsby |
https://www.chicagomag.com/Chicago-Magazine/No... |
df["URL"][0]
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
req = Request(df["URL"][0], headers={"user-agent":ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
soup_tmp.find("p", "addy")
<p class="addy">
<em>$10. 2109 W. Chicago Ave., 773-772-0406, <a href="http://www.theoldoaktap.com/">theoldoaktap.com</a></em></p>
price_tmp = soup_tmp.find("p", "addy").text
price_tmp
'\n$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'
import re
re.split(".,", price_tmp)
['\n$10. 2109 W. Chicago Ave', ' 773-772-040', ' theoldoaktap.com']
price_tmp = re.split(".,", price_tmp)[0]
price_tmp
'\n$10. 2109 W. Chicago Ave'
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price_tmp[len(tmp) + 2:]
'2109 W. Chicago Ave'
from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df[:5].iterrows()):
req = Request(row["URL"], headers={"user-agent":ua.ie})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2:])
print(idx)
0it [00:00, ?it/s]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/opt/homebrew/Caskroom/miniforge/base/envs/ds_study/lib/python3.8/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3360 try:
-> 3361 return self._engine.get_loc(casted_key)
3362 except KeyError as err:
/opt/homebrew/Caskroom/miniforge/base/envs/ds_study/lib/python3.8/site-packages/pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
/opt/homebrew/Caskroom/miniforge/base/envs/ds_study/lib/python3.8/site-packages/pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 'URL'
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
/var/folders/8c/jb57288j6xlb3s_tkmys1kj00000gn/T/ipykernel_3807/3911232756.py in <module>
5
6 for idx, row in tqdm(df[:5].iterrows()):
----> 7 req = Request(row["URL"], headers={"user-agent":ua.ie})
8 html = urlopen(req).read()
9 soup_tmp = BeautifulSoup(html, "html.parser")
/opt/homebrew/Caskroom/miniforge/base/envs/ds_study/lib/python3.8/site-packages/pandas/core/series.py in __getitem__(self, key)
940
941 elif key_is_scalar:
--> 942 return self._get_value(key)
943
944 if is_hashable(key):
/opt/homebrew/Caskroom/miniforge/base/envs/ds_study/lib/python3.8/site-packages/pandas/core/series.py in _get_value(self, label, takeable)
1049
1050 # Similar to Index.get_value, but we do not fall back to positional
-> 1051 loc = self.index.get_loc(label)
1052 return self.index._get_values_for_loc(self, loc, label)
1053
/opt/homebrew/Caskroom/miniforge/base/envs/ds_study/lib/python3.8/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3361 return self._engine.get_loc(casted_key)
3362 except KeyError as err:
-> 3363 raise KeyError(key) from err
3364
3365 if is_scalar(key) and isna(key) and not self.hasnans:
KeyError: 'URL'
len(price), len(address)
(50, 50)
price[:5]
['$10.', '$9.', '$9.50', '$9.40', '$10.']
address[:5]
['2109 W. Chicago Ave',
'800 W. Randolph St',
' 445 N. Clark St',
' 914 Noyes St',
'825 W. Fulton Mkt']
df.tail(2)
|
Rank |
Cafe |
Menu |
URL |
| 48 |
49 |
Toni Patisserie |
Le Végétarien |
https://www.chicagomag.com/Chicago-Magazine/No... |
| 49 |
50 |
Phoebe’s Bakery |
The Gatsby |
https://www.chicagomag.com/Chicago-Magazine/No... |
df["Price"] = price
df["Address"] = address
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]
df.set_index("Rank", inplace=True)
df.head()
|
Cafe |
Menu |
Price |
Address |
| Rank |
|
|
|
|
| 1 |
Old Oak Tap |
BLT |
$10. |
2109 W. Chicago Ave |
| 2 |
Au Cheval |
Fried Bologna |
$9. |
800 W. Randolph St |
| 3 |
Xoco |
Woodland Mushroom |
$9.50 |
445 N. Clark St |
| 4 |
Al’s Deli |
Roast Beef |
$9.40 |
914 Noyes St |
| 5 |
Publican Quality Meats |
PB&L |
$10. |
825 W. Fulton Mkt |
df.to_csv(
"../data/03. best_sandwiches_list_chicago2.csv", sep=",", encoding="UTF-8"
)
pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)
|
Cafe |
Menu |
Price |
Address |
| Rank |
|
|
|
|
| 1 |
Old Oak Tap |
BLT |
$10. |
2109 W. Chicago Ave |
| 2 |
Au Cheval |
Fried Bologna |
$9. |
800 W. Randolph St |
| 3 |
Xoco |
Woodland Mushroom |
$9.50 |
445 N. Clark St |
| 4 |
Al’s Deli |
Roast Beef |
$9.40 |
914 Noyes St |
| 5 |
Publican Quality Meats |
PB&L |
$10. |
825 W. Fulton Mkt |
| 6 |
Hendrickx Belgian Bread Crafter |
Belgian Chicken Curry Salad |
$7.25 |
100 E. Walton St |
| 7 |
Acadia |
Lobster Roll |
$16. |
1639 S. Wabash Ave |
| 8 |
Birchwood Kitchen |
Smoked Salmon Salad |
$10. |
2211 W. North Ave |
| 9 |
Cemitas Puebla |
Atomica Cemitas |
$9. |
3619 W. North Ave |
| 10 |
Nana |
Grilled Laughing Bird Shrimp and Fried Po’ Boy |
$17. |
3267 S. Halsted St |
| 11 |
Lula Cafe |
Ham and Raclette Panino |
$11. |
2537 N. Kedzie Blvd |
| 12 |
Ricobene’s |
Breaded Steak |
$5.49 |
Multiple location |
| 13 |
Frog n Snail |
The Hawkeye |
$14. |
3124 N. Broadwa |
| 14 |
Crosby’s Kitchen |
Chicken Dip |
$10. |
3455 N. Southport Ave |
| 15 |
Longman & Eagle |
Wild Boar Sloppy Joe |
$13. |
2657 N. Kedzie Ave |
| 16 |
Bari |
Meatball Sub |
$4.50 |
1120 W. Grand Ave |
| 17 |
Manny’s |
Corned Beef |
$11.95 |
1141 S. Jefferson St |
| 18 |
Eggy’s |
Turkey Club |
$11.50 |
333 E. Benton Pl |
| 19 |
Old Jerusalem |
Falafel |
$6.25 |
1411 N. Wells St |
| 20 |
Mindy’s HotChocolate |
Crab Cake |
$15. |
1747 N. Damen Ave |
| 21 |
Olga’s Delicatessen |
Chicken Schnitzel |
$5. |
3209 W. Irving Park Rd |
| 22 |
Dawali Mediterranean Kitchen |
Shawarma |
$6. |
Multiple location |
| 23 |
Big Jones |
Toasted Pimiento Cheese |
$8. |
5347 N. Clark St |
| 24 |
La Pane |
Vegetarian Panino |
$5.99 |
2954 W. Irving Park Rd |
| 25 |
Pastoral |
Cali Chèvre |
$7.52 |
Multiple location |
| 26 |
Max’s Deli |
Pastrami |
$11.95 |
191 Skokie Valley Rd |
| 27 |
Lucky’s Sandwich Co. |
The Fredo |
$7.50 |
Multiple location |
| 28 |
City Provisions |
Smoked Ham |
$12.95 |
1818 W. Wilson Ave |
| 29 |
Papa’s Cache Sabroso |
Jibarito |
$7. |
2517 W. Division St |
| 30 |
Bavette’s Bar & Boeuf |
Shaved Prime Rib |
$21. |
218 W. Kinzie St |
| 31 |
Hannah’s Bretzel |
Serrano Ham and Manchego Cheese |
$9.79 |
Multiple location |
| 32 |
La Fournette |
Tuna Salad |
$9.75 |
1547 N. Wells St |
| 33 |
Paramount Room |
Paramount Reuben |
$13. |
415 N. Milwaukee Ave |
| 34 |
Melt Sandwich Shoppe |
The Istanbul |
$7.95 |
1840 N. Damen Ave |
| 35 |
Floriole Cafe & Bakery |
B.A.D. |
$9. |
1220 W. Webster Ave |
| 36 |
First Slice Pie Café |
Duck Confit and Mozzarella |
$9. |
5357 N. Ashland Ave |
| 37 |
Troquet |
Croque Monsieur |
$8. |
1834 W. Montrose Ave |
| 38 |
Grahamwich |
Green Garbanzo |
$8. |
615 N. State St |
| 39 |
Saigon Sisters |
The Hen House |
$7. |
Multiple location |
| 40 |
Rosalia’s Deli |
Tuscan Chicken |
$6. |
241 N. York Rd |
| 41 |
Z&H MarketCafe |
The Marty |
$7.25 |
1323 E. 57th St |
| 42 |
Market House on the Square |
Whitefish |
$11. |
655 Forest Ave |
| 43 |
Elaine’s Coffee Call |
Oat Bread, Pecan Butter, and Fruit Jam |
$6. |
Hotel Lincol |
| 44 |
Marion Street Cheese Market |
Cauliflower Melt |
$9. |
100 S. Marion St |
| 45 |
Cafecito |
Cubana |
$5.49 |
26 E. Congress Pkwy |
| 46 |
Chickpea |
Kufta |
$8. |
2018 W. Chicago Ave |
| 47 |
The Goddess and Grocer |
Debbie’s Egg Salad |
$6.50 |
25 E. Delaware Pl |
| 48 |
Zenwich |
Beef Curry |
$7.50 |
416 N. York St |
| 49 |
Toni Patisserie |
Le Végétarien |
$8.75 |
65 E. Washington St |
| 50 |
Phoebe’s Bakery |
The Gatsby |
$6.85 |
3351 N. Broadwa |
5. 시카고 맛집 데이터 지도 시각화
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdm
df = pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)
df.tail(10)
|
Cafe |
Menu |
Price |
Address |
| Rank |
|
|
|
|
| 41 |
Z&H MarketCafe |
The Marty |
$7.25 |
1323 E. 57th St |
| 42 |
Market House on the Square |
Whitefish |
$11. |
655 Forest Ave |
| 43 |
Elaine’s Coffee Call |
Oat Bread, Pecan Butter, and Fruit Jam |
$6. |
Hotel Lincol |
| 44 |
Marion Street Cheese Market |
Cauliflower Melt |
$9. |
100 S. Marion St |
| 45 |
Cafecito |
Cubana |
$5.49 |
26 E. Congress Pkwy |
| 46 |
Chickpea |
Kufta |
$8. |
2018 W. Chicago Ave |
| 47 |
The Goddess and Grocer |
Debbie’s Egg Salad |
$6.50 |
25 E. Delaware Pl |
| 48 |
Zenwich |
Beef Curry |
$7.50 |
416 N. York St |
| 49 |
Toni Patisserie |
Le Végétarien |
$8.75 |
65 E. Washington St |
| 50 |
Phoebe’s Bakery |
The Gatsby |
$6.85 |
3351 N. Broadwa |
gmaps_key = ""
gmaps = googlemaps.Client(key=gmaps_key)
lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
gmaps_output = gmaps.geocode(target_name)
location_ouput = gmaps_output[0].get("geometry")
lat.append(location_ouput["location"]["lat"])
lng.append(location_ouput["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)
50it [00:17, 2.85it/s]
len(lat), len(lng)
(50, 50)
df.tail()
|
Cafe |
Menu |
Price |
Address |
| Rank |
|
|
|
|
| 46 |
Chickpea |
Kufta |
$8. |
2018 W. Chicago Ave |
| 47 |
The Goddess and Grocer |
Debbie’s Egg Salad |
$6.50 |
25 E. Delaware Pl |
| 48 |
Zenwich |
Beef Curry |
$7.50 |
416 N. York St |
| 49 |
Toni Patisserie |
Le Végétarien |
$8.75 |
65 E. Washington St |
| 50 |
Phoebe’s Bakery |
The Gatsby |
$6.85 |
3351 N. Broadwa |
df["lat"] = lat
df["lng"] = lng
df.tail()
|
Cafe |
Menu |
Price |
Address |
lat |
lng |
| Rank |
|
|
|
|
|
|
| 46 |
Chickpea |
Kufta |
$8. |
2018 W. Chicago Ave |
41.896113 |
-87.677857 |
| 47 |
The Goddess and Grocer |
Debbie’s Egg Salad |
$6.50 |
25 E. Delaware Pl |
41.898979 |
-87.627393 |
| 48 |
Zenwich |
Beef Curry |
$7.50 |
416 N. York St |
41.910583 |
-87.940488 |
| 49 |
Toni Patisserie |
Le Végétarien |
$8.75 |
65 E. Washington St |
41.883106 |
-87.625438 |
| 50 |
Phoebe’s Bakery |
The Gatsby |
$6.85 |
3351 N. Broadwa |
41.943163 |
-87.644507 |
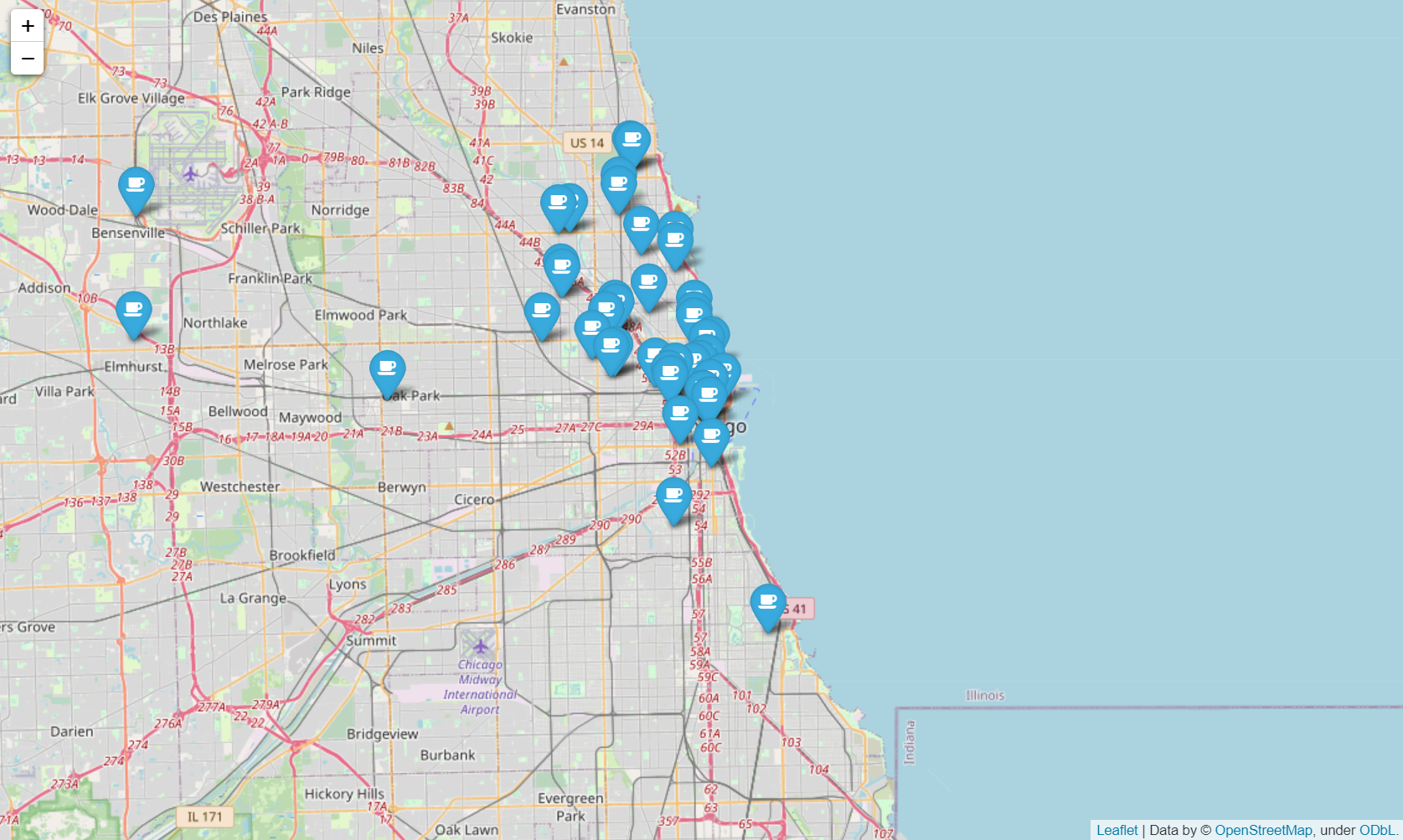
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup=row["Cafe"],
tooltip=row["Menu"],
icon=folium.Icon(
icon="coffee",
prefix="fa"
)
).add_to(mapping)
mapping