
시리즈 목차를 보면 아시겠지만 사실 오래전에 다뤘던 내용들입니다.
그런데 왜 또 다루게 되었냐면 프로젝트를 진행하면서 개념이 약한 부분이 DB와 관련된 부분이라고 느껴졌기 때문에 핵심만 간략하게 추려서 정리하면서 다시 DB에 대한 내용을 상기하고자 다시 몇 개의 포스트에 걸쳐서 DB(정확히는 RDBM/RDBMS)를 다뤄보려고 합니다. (+ 예전 포스팅의 퀄리티 업도 더해서)
데이터베이스 포스팅은
MySQL을 기준으로 작성되었음을 알립니다.
관계 데이터 모델 - 기본 개념
관계 데이터 모델은 데이터를 흔히 표라고 하는 2차원의 테이블 형태로 표현하는 방식입니다. 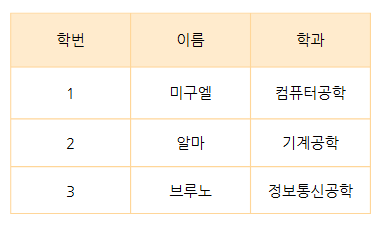 이렇게 표현된 테이블에
이렇게 표현된 테이블에 제약 조건과 관계대수를 정의함으로써 관계 데이터 모델이 정의되게 됩니다.
이제 각 용어들에 대해 더 자세히 알아보면서 관계 데이터 모델을 이해해보도록 합시다.
릴레이션 relation
릴레이션 relation은 행(row)과 열(column)으로 이루어진 2차원 테이블을 의미합니다. 릴레이션은 테이블이라고 부르기도 합니다.
이하 문단들에서 이 릴레이션(테이블)의 명칭을
학생 테이블이라고 지칭하겠습니다.
참고로,
행(row)는 가로. 즉, [1, 미구엘, 컴퓨터공학]이 되고열(column)은 학번 [1, 2, 3]이 됩니다.
[1, 미구엘, 컴퓨터공학]이라는 데이터를 이미지의 테이블 형태로 삽입하는 방식이 보통 릴레이션을 시각화하고자 할 때 이용하는 방식입니다.
스키마와 인스턴스
릴레이션은 다시 스키마 Schema와 인스턴스 Instance로 구성됩니다.
스키마는 릴레이션이 어떤 데이터를 담고있는지에 대한 구조를 정의하고, 인스턴스는 릴레이션 내에 실제로 저장되는 데이터의 집합을 의미합니다.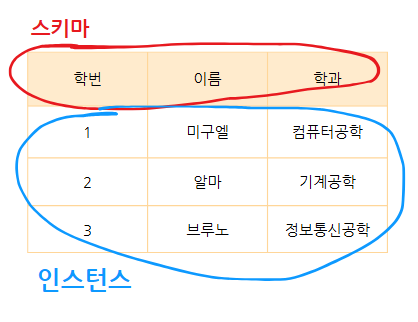
스키마
스키마의 각 열인 학번, 이름, 학과는 속성 attribute라고 부릅니다.
속성은 의미나 맥락에 대해 프로그래머는 속성을 보고 알 수 있지만 컴퓨터는 의미나 맥락을 파악하지 못하기 때문에 도메인 Domain을 통해서 해당 속성이 어떤 타입의 값을 갖는지 명시하게 됩니다.
추가적으로 릴레이션이 몇 개의 스키마를 가졌는지 나타내는 표현으로 차수 Degree를 사용합니다.
학생 테이블의 스키마를 표현할 때 다음과 같이 표현하게 됩니다.
학생(학번: 1 이상의 숫자, 이름: 문자열, 학과: 문자열)
인스턴스
[1, 미구엘, 컴퓨터공학], [2, 알마, 기계공학], [3, 브루노, 정보통신공학]과 같이 학생 테이블에 저장된 실제 데이터들을 인스턴스라고 부릅니다. 이 데이터 집합에서 한 행, 즉 [1, 미구엘, 컴퓨터공학]을 튜플 Tuple이라고 부릅니다.
각 튜플의 차수는 스키마의 차수와 동일하며 스키마에 정의된 도메인의 값을 속성 값으로 가지게 됩니다. 즉, 도메인을 1 이상의 숫자로 지정한 학번에 저장되는 데이터로 문자열이나 0, 음수가 올 수 없다라는 것 입니다. 또한 튜플은 중복될 수 없다라는 특징도 있습니다.
릴레이션 내에 저장된 튜플의 총 개수를 카디널리티 Cardinality라고 부릅니다.
릴레이션 용어 정리
지금까지 릴레이션에 사용되는 용어들을 알아봤는데요. 용어가 나오기도 많이 나왔고 제가 릴레이션을 계속 테이블이라고 부르듯이 하나의 용어가 관점에 따라 다양한 용어로 불리기도 합니다.
그래서 릴레이션에서 사용되는 주요 용어와 동의어들을 표로 정리해봤습니다.
| 릴레이션 용어 | 실제 구현에서 사용되는 용어 | 파일 시스템 용어 |
|---|---|---|
| 릴레이션 | 테이블 | 파일 |
| 스키마 | 내포 | 헤더 |
| 인스턴스 | 외연 | 데이터 |
| 튜플 | 행 | 레코드 |
| 속성 | 열 | 필드 |
원래 용어인 릴레이션과 실제 구현에서 부르는 명칭이 달라진 원인은 릴레이션은 수학적인 관계 개념에서 출발한 것이고, 실제 구현에서는 사용자가 이해하기 직관적이도록 2차원 구조로 나타내다 표현했기 때문입니다.
학생 테이블을 예로 들어
{ [1, 미구엘, 컴퓨터공학], [2, 알마, 기계공학], [3, 브루노, 정보통신공학] }튜플의 집합으로 구성된 릴레이션을 직관적인 2차원 표 형태로 나타내는 과정에서 테이블 개념의 명칭으로 부르게되었다고 할 수 있습니다.
릴레이션 특징
릴레이션이 수학적 정의에서 출발한 개념이니만큼 수학적 표현에 따라 몇 가지 특징을 가지고 있습니다.
- 속성을 단일 값을 갖는다.
각 속성은 하나의 값을 갖습니다. 예를들어 학번을 1번을 가졌는데 2번이라는 또 다른 학번을 가질 수 없습니다.
- 속성은 서로 다른 명칭을 갖는다.
- 한 속성의 값들은 모두 같은 도메인을 가진다.
- 속성의 순서는 상관없다.
학생(학번, 이름, 학과)와학생(학과, 학번, 이름)은 동일한 릴레이션입니다. - 한 릴레이션 내에서 중복된 튜플을 허용하지 않는다.
- 튜플의 순서는 상관없다.
{ [1, 미구엘, 컴퓨터공학], [2, 알마, 기계공학], [3, 브루노, 정보통신공학] }에서{ [2, 알마, 기계공학], [3, 브루노, 정보통신공학], [1, 미구엘, 컴퓨터공학] }가 되어도 동일한 릴레이션입니다.
관계 데이터 모델 - 제약조건
제약조건은 테이블에 데이터를 저장할 때 스키마, 도메인 등에 따른 조건을 만족하는 데이터만을 넣기 위한 조건입니다.
이때 저장되는 데이터의 일관성과 정확성을 지키는 것을 데이터 무결성이라고 하며, 데이터 무결성을 지키기 위해 릴레이션에 제약조건을 걸고 준수하게 만드는데요. 데이터 무결성을 지키기위한 제약조건을 무결성 제약조건이라고 부릅니다.
무결성 제약조건
무결성 제약조건은 데이터 조작 과정에서 최소한의 기본적인 제약조건을 DBMS가 처리할 수 있도록 만들어서 코드 상에서 최소한의 데이터 검증 처리를 거치게 만들어줍니다.
무결성 제약조건에는 다음 세 가지의 종류가 존재합니다.
도메인 무결성 제약조건
도메인 무결성 제약조건은 릴레이션 내부의 튜플들이 각 속성 도메인에 지정된 값만을 가지도록 하는 제약조건입니다.
위 예시에서 학번의 경우 1 이상의 숫자라는 도메인을 두었기 때문에 학번에 저장되는 값으로는 오직 1 이상의 숫자만이 오게 됩니다.
도메인은 보통 자료형(type), NULL/NOT NULL, DEFAULT, CHECK와 같은 키워드를 사용해서 지정하게 됩니다.
개체 무결성 제약조건
개체 무결성 제약조건은 릴레이션에 기본키를 지정하고 기본키는 NOT NULL, 하나만 존재하는 조건을 갖습니다.
릴레이션 내부에서 NULL이 아니면서 오직 단 하나의 유일한 값을 갖기 때문에 튜플 식별에 있어서 중요한 제약조건이라고 할 수 있습니다.
참조 무결성 제약조건
참조 무결성 제약조건은 부모-자식 관계의 릴레이션에서 자식 릴레이션이 부모 릴레이션의 기본키를 참조하는 외래키를 두어 두 릴레이션의 관계를 나타내는 제약조건입니다.
이때 외래키는 부모 릴레이션의 기본키이므로 해당 기본키의 제약조건을 그대로 따릅니다.
관계 데이터 모델 - 키
키 Key는 릴레이션에서 특정한 튜플을 식별하고자 사용되는 특수한 속성입니다. 키는 NULL이 올 수 없고 중복된 값을 허용하지 않기 때문에 튜플을 식별할 수 있는 중요한 개념이기도 합니다.
또한 키는 튜플 식별 외에도 릴레이션 간의 관계를 맺을 때도 사용되는 속성입니다.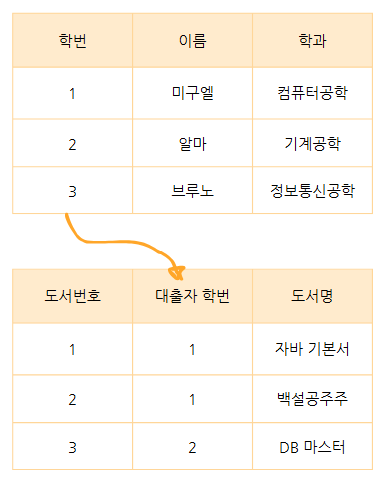 아래의 도서 대출 테이블에서는 위의 학생 테이블 학번 기본키를 외래키로 삼고 있습니다. 이런식으로 학생 테이블과 도서 대출 테이블이 관계를 맺고있음을 키를 통해 나타내게 됩니다.
아래의 도서 대출 테이블에서는 위의 학생 테이블 학번 기본키를 외래키로 삼고 있습니다. 이런식으로 학생 테이블과 도서 대출 테이블이 관계를 맺고있음을 키를 통해 나타내게 됩니다.
키들은 또 다시 여러 종류로 나뉘어집니다.
슈퍼키 Super Key
슈퍼키는 튜플을 식별할 수 있는 속성(들)의 집합들을 의미합니다.
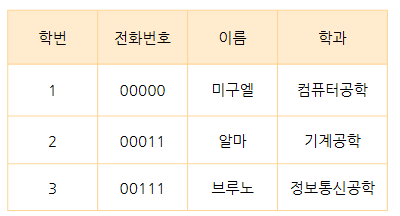 학번과 전화번호는 학생 튜플을 식별할 수 있는 중복되지않는 속성이기 때문에 이들이 들어간 속성 또는 둘 중 하나라도 들어간 속성 집합이 슈퍼키가 됩니다.
학번과 전화번호는 학생 튜플을 식별할 수 있는 중복되지않는 속성이기 때문에 이들이 들어간 속성 또는 둘 중 하나라도 들어간 속성 집합이 슈퍼키가 됩니다.
학생 테이블의 슈퍼키 일부 예시들
(학번), (학번, 이름), (학번, 이름, 학과), (학번, 전화번호), (전화번호), (전화번호, 학과) ...
두 개 이상의 속성이 들어가 있는 키를복합키라고 부르기도 합니다.
전화번호는 실제로는 한 사람이 여러 개를 개통해서 쓴다던가 하기 때문에 실제 구현에서 식별 속성으로 쓰기 어렵습니다. 여기서는 쉬운 예시를 위해 중복이 없는 간단한 데이터로 사용되었습니다.
후보키 Candidate Key
후보키는 튜플을 유일하게 식별하게 만드는 속성의 최소 집합입니다. 위 슈퍼키 예시들에서 유일한 튜플을 식별할 수 있는 학번 or 전화번호가 학생 테이블의 후보키가 됩니다.
슈퍼키 중에서
(학번, 이름)의 경우 학번이라는 식별가능한 키가 있으나 이름이라는 불필요한 키가 있으므로 후보키에서 제외됩니다.
기본키 PK, Primary Key
기본키는 후보키 중에서 대표로 삼는 키를 의미합니다.
위 학생 테이블 예시에서 후보키가 학번 또는 전화번호였는데, 학생 테이블에 어울리는 기본키로 삼기 위한 후보키는 학번이 되므로 학생 테이블의 기본키는 학번을 지정하게 됩니다.
이처럼 기본키는 후보키들 중에서 릴레이션의 특징에 맞춰서 지정하거나 후보키가 하나라면 해당 키를 기본키로 삼으면 됩니다.
전화번호의 경우 학생 테이블과 연관짓기 어렵고 교수나 행정 직원 등 다른 사람들도 전화번호를 가지고 있으며, 변경될 확률이 있기 때문에 기본키로 지정하기에 어려움이 있습니다.
기본키는 중요하며 유일한 키이기 때문에 다음과 같은 제약조건이 걸려있습니다.
- 릴레이션 내부에서 튜플을 유일하게 식별할 수 있어야한다.
- NULL 값이 올 수 없다.
- 키 값이 변동되서는 안된다.
- 최대한 적은 수의 속성을 가지고 있어야한다.
- 키를 사용한 조작 과정에서 문제가 발생할 소지가 없어야한다.
기본키 표현시 해당 속성 밑에 밑줄을 그어 표시합니다.
학생(학번, 전화번호, 이름, 학과)
대리키 Surrogate Key
대리키(또는 인조키 Artificial Key)는 기본키를 사용할 때 특정 데이터를 나타내기보단 보안이나 복합 속성 표현, 적합한 데이터가 없어 일련번호 사용의 경우 가상의 속성-값을 만들어 기본키로 사용하는 것을 의미합니다.
대체키 Alternate Key
대체키는 기본키로 선정되지 않은 후보키를 의미합니다.
위의 예시에서 기본키로 선정된 학번 외의 후보키인 전화번호가 대체키가 됩니다.
외래키 FK, Foreign Key
외래키는 한 릴레이션에서 다른 릴레이션의 기본키를 참조한 키를 의미합니다. 릴레이션 간의 관계를 표현하기 위해서 사용됩니다.
외래키는 다른 테이블의 기본키를 참조하여 해당 기본키의 제약조건을 따르지만 NULL 값이 오거나 중복된 값이 올 수 있다는 특징이 있습니다.
아래 도서 대출 테이블에서 대출자 학번이 학생 테이블의 기본키를 참조하므로 도서 대출 테이블의 기본키 PK는 도서번호가 되고, 외래키 FK는 대출자 학번이 됩니다.
이 외래키 관계를 통해 도서 대출 테이블은 학생 테이블과 어떤 관계를 맺고 있다라는 사실을 알 수 있습니다. (관계에 대해서는 추후에 더 자세히 다룹니다.)
외래키는 다음과 같은 특징을 갖습니다.
- 릴레이션 간의 관계를 표현한다.
- 다른 릴레이션의 기본키를 참조한다.
- 참조되는 기본키와 참조하는 외래키의 도메인이 동일해야한다.
- 기본키가 변경되면 외래키도 변경된다.
- NULL, 중복이 허용된다.
- 자기 자신의 기본키를 참조하는 형태의 외래키도 사용가능하다.
- 외래키가 기본키의 일부일 수도 있다.
관계 데이터 모델 - 관계대수
관계대수는 릴레이션을 조작하기 위한 질의 언어입니다.
릴레이션에 관계대수 연산자를 사용해서 결과 릴레이션을 얻고 해당 결과 릴레이션에서 원하는 데이터 등을 얻어내는 식으로 동작합니다.
이 과정을 대화문 형식으로 읽고쓰기 좋게 만든것이
SQL입니다.
다음 이미지의 연산자들을 통해서 릴레이션에 대한 연산을 진행합니다.

이미지 출처
예를들어 σ는 릴레이션에서 지정한 조건을 만족하는 튜플을 Select하는 연산자입니다.
σ 학과 = '컴퓨터공학' (Students)이런식으로 관계대수로 표현을 하면 [1, 00000, 미구엘, 컴퓨터공학] 튜플을 결과로 표시하게 됩니다
각 연산에 대해 깔끔하게 설명한 외국 블로그가 있어서 추가적으로 링크를 남깁니다.
