
완전 쉽게 파이썬으로 텍스트 및 이미지 크롤링하기
https://youtu.be/ZTJjW7XuHIY
크롤링(Crawling)
인터넷에 있는 정보 중 우리가 원하는 것만 골라서 자동으로 수집해주는 기술
크롤링(Crawling) = 파싱(Parsing) = 스크래핑(Scraping) = 스파이더링(Spidering)
크롤링의 원리
우리가 정보를 가져오려는 사이트를 불러와서
거기서 원하는 정보를 찾고
그 정보를 가져오게 하는 코드를 작성하면 끝
크롤링 관련 라이브러리는 보통 어느 언어에서나 있음
여기서는 파이썬으로 해보겠음
이제 텍스트와 이미지를 크롤링 하는 방법에 대해서 배워보자
BeautifulSoup 이라는 라이브러리를 사용하도록 한다.
BeautifulSoup은 HTML 및 XML 구문을 분석하기 위한 파이썬 패키지(라이브러리)이다.
굉장히 많이 쓰이는 라이브러리라서 참고할 문서들이 많다.
위키백과로 들어가본다.
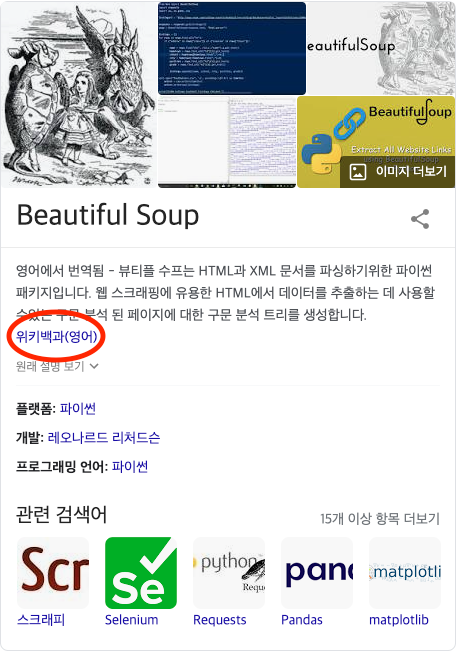
설명과 함께 예제 코드가 나와있다. 그대로 사용해본다.
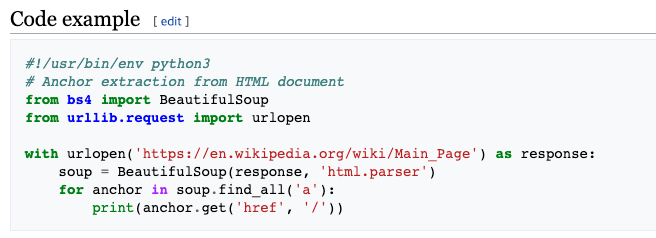
전체를 복사해서 붙여넣어 주고 실행해본다.
ModuleNotFoundError 에러가 떴다.
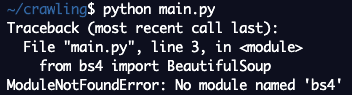
bs4 라는 모듈을 불러오지 못했다는 건데 BeautifulSoup4 버전이 설치되어 있지 않아서 생긴 문제이다.
설치하는 방법은 매우 간단하다.
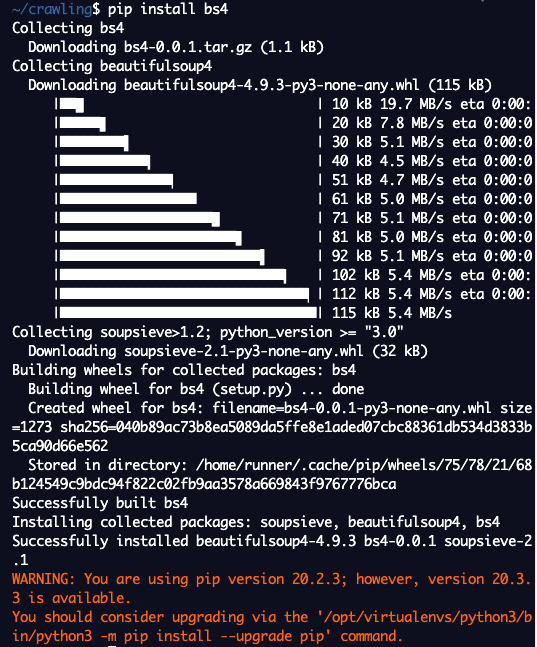
명령어 입력 창에 pip install bs4를 입력하면 된다.
자동으로 다운받고 설치까지 완벽하게 진행된다.
패키지(라이브러리)
우리가 윈도우 PC를 사용할 때 발표자료를 제작해야 된다면 PPT를 다운 받아서 설치해 사용하고 우리가 문서를 작성해야 되면 Word를 다운 받아서 설치해서 사용한다. 이런 것처럼 윈도우에서는 이런 설치파일을 이용해서 프로그램을 설치해서 원하는 기능을 사용하는데 마찬가지로 파이썬을 하나의 컴퓨터라고 생각을 하면 파이썬에서 사용할 수 있는 라이브러리들이 있다. 크롤링에 사용할 라이브러리를 설치해서 쓰고 데이터 분석을 할 때는 pandas라는 걸 설치해서 쓰고 이런 것처럼 어떤 이미 만들어진 기능 프로그램을 설치하여 사용할 때 (여기서는 패키지) 파이썬의 경우에는 파이썬 패키지 관리자 pip를 이용해서 명령어에 pip install 패키지명만 입력하면 자동으로 이 프로그램을 다운 받고 설치하는 것까지 모두 하게 된다.
이런 개념은 파이썬에만 있는 게 아니고 거의 모든 언어에 다 있다. Ruby Gem도 같은 개념이고 Node.js에서 다루는 npm도 같은 개념이다.
우리가 윈도우 컴퓨터를 이용할 때 윈도우에 있는 기본 기능만 사용하는 게 아니고 당연히 외부 프로그램을 설치해서 사용하듯이, 마찬가지로 어떤 언어로 프로그램을 작성할 때 그 언어 자체 기능으로 구현할 수도 있겠지만 같은 기능을 만들어 놓은 라이브러리가 있다면 무조건 가져다 쓰는 편이 훨씬 빠르고 효율적이다.
이제 설치가 완료 됐으니 다시 한 번 실행해본다.
Shell에 python main.py 입력
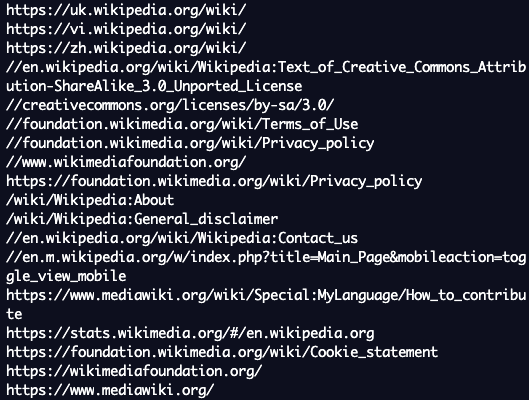
결과가 잘 나온 것을 볼 수 있다.
어떻게 이런 결과가 나왔는지 코드를 한 줄씩 살펴보자.
#!/usr/bin/env python3
# Anchor extraction from HTML document
from bs4 import BeautifulSoup
from urllib.request import urlopen
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))from bs4 import BeautifulSoup
👉 라이브러리를 불러오는 코드
BeautifulSoup 이라는 라이브러리를 불러온다는 뜻
이렇게 불러온 라이브러리는 하단의 어느 부분에서나 불러와서 BeautifulSoup의 기능을 사용할 수 있다.
from urllib.request import urlopen
👉 라이브러리를 불러오는 코드
urlopen이라는 기능을 가져와서 아래에서 쓰겠다 라는 의미
외울 필요는 없고 복붙해서 쓰면 된다
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:
👉 urlopen을 사용해서 입력한 주소로 들어가서 response라는 곳에 담겠다 라는 의미
with문을 직관적으로 바꿔보면 아래와 같다.
response = urlopen('https://en.wikipedia.org/wiki/Main_Page')
입력한 url을 열어서 response라는 변수에 담겠다는 의미
from bs4 import BeautifulSoup
from urllib.request import urlopen
response = urlopen('https://en.wikipedia.org/wiki/Main_Page')
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))soup = BeautifulSoup(response, 'html.parser')
👉 BeautifulSoup이라는 함수를 이용해서 아까 만든 response를 html.parser를 이용해서 분석을 한 다음 soup라는 변수에 담겠다는 의미
for anchor in soup.find_all('a'):
👉 (파이썬 반복문: for 변수 in 배열)
soup에서 모든 a 태그를 찾아서 anchor라는 변수에 차례대로 대입해준다
print(anchor.get('href', '/'))
👉 하나씩 대입되는 anchor에서 href(주소)들을 가져와서 프린트한다.
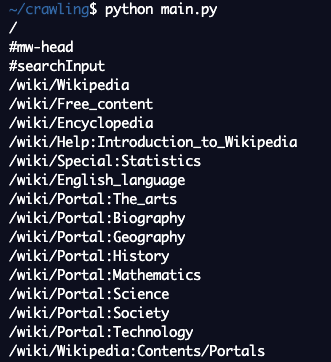
네이버 실시간 검색어 순위를 크롤링하는 예제를 만들어보자.
네이버 전체 사이트에서 실시간 검색어 부분만 골라서 텍스트를 가져와야 되기 때문에 이 부분이 어떻게 생겼는지 그 특징을 파악하고 여기를 선택해서 가져오도록 만들어야 한다.
검사 실행하고 저 화살표 눌러준다. 👇
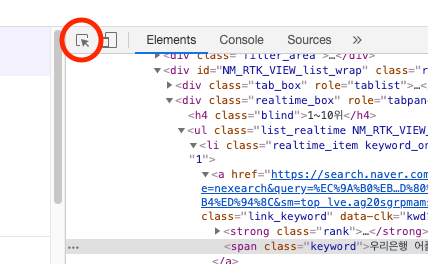
검색 순위 코드가 어떻게 생겼는지 그 규칙을 파악해본다.

다양한 방법으로 규칙성을 찾을 수 있는데 검색어들을 보면 공통적으로 span 태그 안에 감싸져 있다.
그렇다고 span 태그를 모두 가져오면 다른 곳에 있는 span들도 가져오게 되기 때문에 점점 범위를 좁혀서 그 부분만 선택되도록 해야 한다.
좀 더 검색어만 가지고 있는 특징을 보자
span의 class명이 모두 keyword로 되어 있는 걸 볼 수 있다.
span 태그면서 class명이 "keyword"인 걸 가져오면 모두 검색어일 가능성이 높다.
이걸 코드로 작성해보자.
URL에 위키피디아 대신 네이버를 넣는다.
response = urlopen('https://www.naver.com/')
구글에 BeautifulSoup 검색하면 공식 문서 사이트에 들어갈 수 있다.
Beautiful Soup Documentation
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
공식문서에서는 BeautifulSoup을 이용해서 HTML 요소를 선택할 수 있는 다양한 방법들이 나온다.
이 중에서 우리가 자주 사용하는 개념이
CSS selectors
https://www.crummy.com/software/BeautifulSoup/bs4/doc/#css-selectors
CSS selectors 안쪽에 보면 .select 라는 함수를 굉장히 많이 사용한다. 다양한 방법으로 선택을 할 수 있게 해주는데 CSS에서 어떤 요소를 선택하고 꾸며줄지 결정하는 문법이랑 똑같다.
soup.select("title") 👈 태그로 찾기
soup.select("p:nth-of-type(3)") 👈 p태그로 된 3번째 자식
soup.select("body a") 👈 body태그 안에 있는 모든 a태그
soup.select(".sister") 👈 클래스명이 sister인 태그
for anchor in soup.find_all('span', {'class': 'keyword'}):
for anchor in soup.select("span.keyword"):
👉 span태그 중에 클래스명이 keyword인 것
soup.get_text()
👉 텍스트만 가져오기
from bs4 import BeautifulSoup
from urllib.request import urlopen
response = urlopen('https://www.naver.com/')
soup = BeautifulSoup(response, 'html.parser')
i =1
for span in soup.select("span.keyword"):
print(str(i) + "위: " + span.get_text())
i = i + 1텍스트 파일로 저장하는 것까지 해보자
구글에 'python write text file' 검색
구글에 (언어이름) + (할 것) 검색하면 됨

코드 전체 복사해서 가져온다.
f = open("C:/doit/새파일.txt", 'w')
for i in range(1, 11):
data = "%d번째 줄입니다.\n" % i
f.write(data)
f.close()f = open("새파일.txt", 'w')
👉 경로 설정을 안 하면 실행파일과 같은 위치에 생긴다.
data = str(i) + "위: " + span.get_text()
👉 print 지우고 data = 입력
f.write(data)
f.close()
from bs4 import BeautifulSoup
from urllib.request import urlopen
response = urlopen('https://www.naver.com/')
soup = BeautifulSoup(response, 'html.parser')
i =1
f = open("새파일.txt", 'w')
for span in soup.select("span.keyword"):
data = str(i) + "위: " + span.get_text()
i = i + 1
f.write(data)
f.close() 실행해보면 새파일.txt 라는 파일이 새로 만들어진 걸 볼 수 있다.
한 줄씩 깔끔하게 나오게 하기 위해 "\n"(줄바꿈 문자) 입력
data = str(i) + "위: " + span.get_text() + "\n"
다시 실행해보면 깔끔하게 한 줄씩 내용이 들어간 걸 볼 수 있다.
from bs4 import BeautifulSoup
from urllib.request import urlopen
response = urlopen('https://www.naver.com/')
soup = BeautifulSoup(response, 'html.parser')
i =1
f = open("새파일.txt", 'w')
for span in soup.select("span.keyword"):
data = str(i) + "위: " + span.get_text() + "\n"
i = i + 1
f.write(data)
f.close()구글에 'python google image search and download' 검색
👉 구글에 (언어이름) + (할 일) 검색
google_images_download 2.8.0
https://pypi.org/project/google_images_download/
google_images_download 라는 라이브러리가 이미 만들어져 있다.
이 라이브러리를 사용하면 간편하게 이미지를 다운받을 수 있다.
라이브러리를 설치하는 문장을 복사해서 터미널에 붙여넣기 해준다.

라이브러리가 자동으로 다운 받아지고 설치가 완료되었다.
Examples and Code Samples 클릭
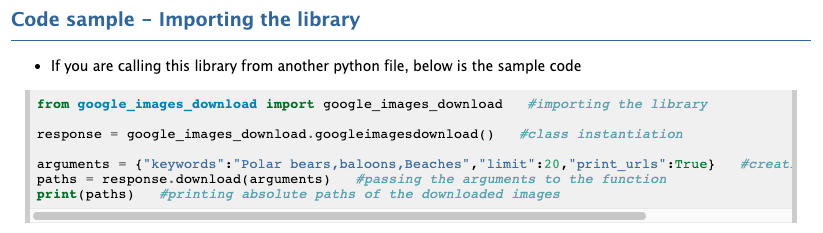
Code sample 코드를 그대로 가져온다.
google.py 파일을 새로 만들어준다.
google.py에 아까 복사한 코드를 붙여넣어 준다.
from google_images_download import google_images_download #importing the library
response = google_images_download.googleimagesdownload() #class instantiation
arguments = {"keywords":"Polar bears,baloons,Beaches","limit":20,"print_urls":True} #creating list of arguments
paths = response.download(arguments) #passing the arguments to the function
print(paths) #printing absolute paths of the downloaded images라이브러리도 설치되어 있으니 바로 실행해본다.
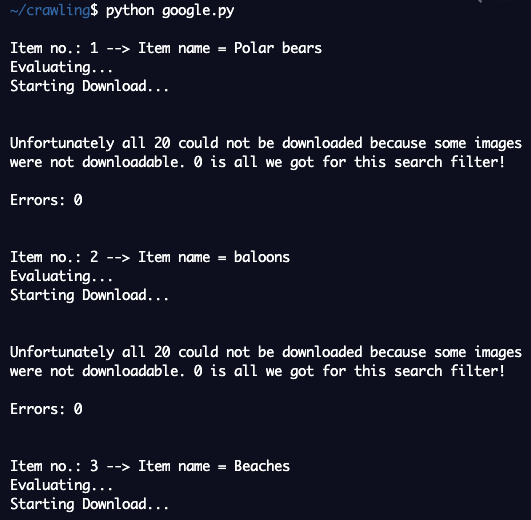
downloads 라는 폴더가 새로 생겼다.
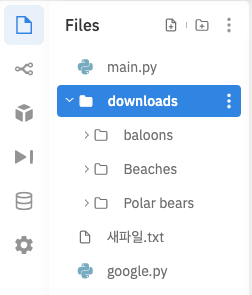
arguments = {"keywords":"Polar bears, baloons, Beaches","limit":20,"print_urls":True}
👉 keywords에 적혀있는 것들이 폴더로 나뉘어서 20장씩 다운로드가 되었다.
keywords만 변경하면 다른 걸 가져올 수 있고
"limit":20을 변경하면 이미지 개수를 변경해서 가져올 수 있다.
잘 되어 있는 라이브러리를 사용하면
복사, 붙여넣기만 해도 코드를 하나도 고치지 않아도 바로 원하는 대로 사용할 수 있다.

친절하고 상세한 설명 감사합니다. 좀 막막했는데 도움도 되고 용기가 납니다!