이 글의 모든 사진 출처: https://www.youtube.com/watch?v=92NizoBL4uA
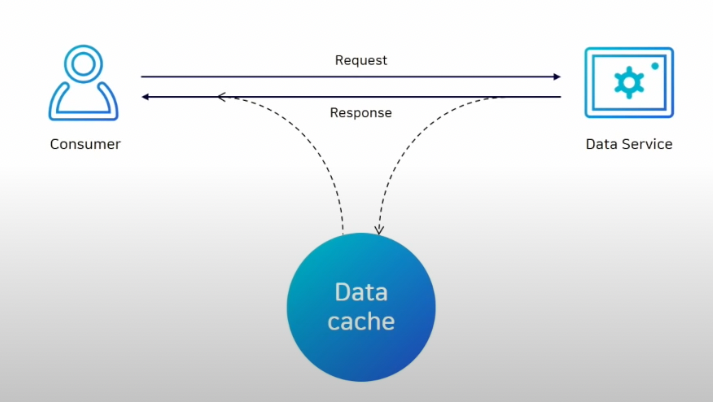
캐시란?
사용자에 입장에서 데이터를 더 빠르게, 더 효율적으로 액세스를 할 수 있는 임시 데이터 저장소를 뜻한다. 대부분의 어플리케이션에서 속도 향상을 위해 캐시를 사용한다고 한다.
캐시를 유용하게 사용되려면?
- 캐시 저장소에 접근하는 속도가 원본 데이터 저장소(운영 DB)에 접근 속도 보다 빨라야 함.
- 동일한 데이터에 대해 반복적으로 액세스하는 상황이 많을 때 사용하는 것이 좋음.
→ 즉, 데이터 재사용 횟수가 한 번 이상이어야 cache가 의미 있다. - 잘 변하지 않는 데이터일수록 cache를 사용 할 때 더 효율적.
캐시로 레디스를 선택한 이유?
-
로컬 캐시 vs 원격 캐시
- 서버가 이중화 되어있어 캐시 데이터 일관성을 위해 원격 캐시 사용!
-
사용이 간편!
- 단순한 key-value 구조
- 다양한 자료구조 지원
-
빠른 성능! (In-memory 데이터 저장소)
- 평균 작업속도 < 1 ms
- 초당 수백만 건의 작업 가능
⇒ 지연시간 감소, 처리량 증가
-
스프링에서 Redis 라이브러리 지원!
-
많은 기업들이 사용!
-
참고 자료가 많음!
캐싱 전략 (Caching Strategies)
보통 레디스를 cache로 사용할 때 레디스를 어떻게 배치하냐에 따라 시스템 전체 성능에 큰 영향을 끼친다고 한다. 그래서 레디스를 어디에 어떻게 배치할 지에 대한 전략을 세워야 하는데! 이를, 캐싱 전략(Caching Strategies)이라고 한다. 캐싱 전략은 데이터의 유형과 해당 데이터에 대한 액세스 패턴을 잘 고려해서 선택해야 한다.
크게 읽기 전략과 쓰기 전략으로 두 가지로 나뉘며, 먼저 읽기 전략부터 보자보자 어디보자!
읽기 전략 (Read Strategies)
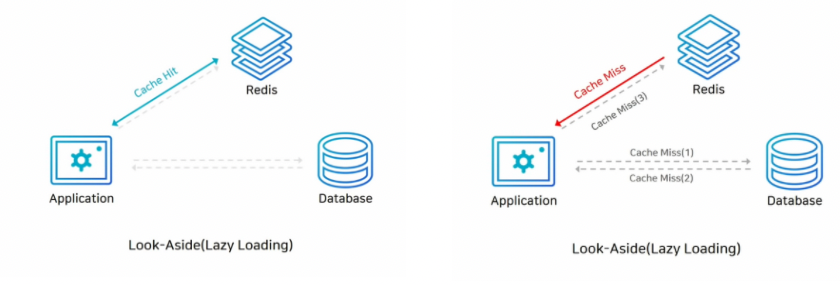
Look-aside (Lazy Loading) 전략 : 데이터를 읽는 작업이 많을 때 사용하는 전략이며, 레디스를 캐시로 쓸때 가장 많이 사용한다고 합니다.
먼저 애플리케이션이 데이터를 읽을때, 캐시를 확인하여 캐시에 데이터가 존재하면 캐시에서 데이터를 읽어온다. 만약 레디스에 찾는 데이터가 없다면 DB에 접근해서 데이터를 직접 가져와 레디스에 저장한다.
따라서, 캐시에는 찾는 데이터가 없을 때만 데이터가 캐싱되기 때문에 이를 지연로딩(Lazy Loading)이라고도 부른다. 이 구조는 레디스 장애 발생 시 시스템이 다운되지 않고, DB에서 데이터를 가지고 올 수 있다.
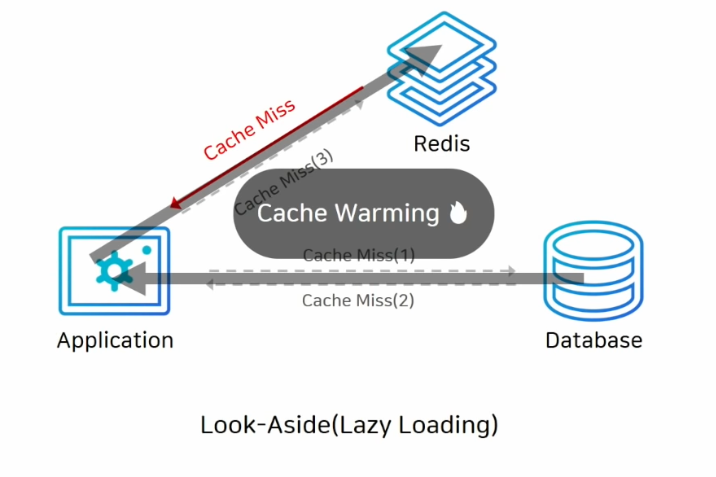
대신 캐시로 붙어있던 커넥션이 많이 있었다면 그 커넥션이 모두 데이터베이스로 붙기 때문에 DB에 많은 트래픽이 한꺼번에 몰릴 수 있다. 그래서 이런 경우에 캐시를 새로 투입하거나, DB에만 새로운 데이터를 저장했다면 캐시에 데이터가 없기 때문에 처음에 Cache miss가 지속적으로 발생해서 DB에 성능에 저하가 올 수 있다. 이럴 때에는 미리 DB에서 캐시로 데이터를 밀어 넣어주는 작업을 할 수 있는데. 이를 cache warming이라고 한다.
일례로, 티켓링크에서는 상품 오픈 전 상품의 정보를 미리 DB에서 캐시로 올려주는 작업을 매번 하고 있다고 한다. 우리 서비스에도 고려를 해봐야 겠다.. 사실 우리 서비스는 클라이언트가 만드는 데이터가 대부분이라, 캐시를 Scale-out 할 경우에 Cache warming을 고려 해봐야 겠다.
쓰기 전략 (Writing Strategies)
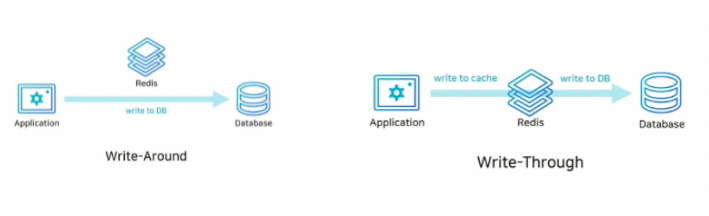
쓰기 전략에는 2가지 종류가 있다.
Write-around : DB에 데이터를 저장하고 Cache miss가 발생할 경우 DB에서 데이터를 캐싱한다. 이 경우엔 cache 내의 데이터와 DB 내의 데이터가 다를 수 있다. 왜냐하면, 캐싱된 데이터가 있을 경우 데이터를 수정할때 캐싱된 데이터를 수정하지 않고, 캐시에 데이터는 있기 때문에 새로 캐싱을 하지 않는다.
Write-through : DB에 데이터를 저장할 때 cache에도 함께 저장하는 방법이다. cache는 항상 최신 정보를 가지고 있다는 장점이 있지만 저장할 때마다 두 단계(DB에 저장, 캐시에 저장) 거쳐야 하기 때문에 상대적으로 느리다. 그리고 재사용되지 않는 데이터도 무조건 캐시에 넣어버리기 때문에 일종의 리소스 낭비를 초래 할 수 있다. 이 경우 데이터를 저장할 때는 Expire time을 설정해주는 것이 좋다고 한다.
결론
사실 이전 프로젝트에서는 전략 같은 게 있는지도 모르고 무작정 레디스를 썼었다. 나도 모르게 write-through 방식을 쓰고 있던 것이다.. 그래도 무작정 써본 덕분에 글을 작성하면서 무슨 내용인지 빠르게 이해할 수 있었다. 이번 프로젝트에서는 제공하는 서비스별로, 데이터 별로 캐싱 전략을 팀원들과 잘 정하여 사용해야겠다. 다음 글은 Spring에서 Redis 및 캐시를 사용하는 방법에 대해 적어보겠다.
출처
NHN FORWARD 2021, Redis 야무지게 사용하기
https://www.youtube.com/watch?v=92NizoBL4uA
