
Redis 소개
레디스(Redis)는 메모리 기반의 데이터 저장소이다. 키-밸류(key-value) 데이터 구조에 기반한 다양한 형태의 자료 구조를 제공하며, 데이터들을 저장할 수 있는 저장소이다. 최신 버전의 레디스는 PUB/SUB 형태의 기능을 제공하여 메세지를 전달할 수 있다. 즉, 데이터 저장 뿐만 아니라 다양한 목적으로 사용할 수 있다.레디스는 메모리에 데이터를 저장하기 때문에 저장 공간에 제약이 있어, 주로 보조 데이터 저장소로 사용한다. 이를 극복하기 위해 레디스 클러스터 기능을 제공하고 있어 저장 공간을 확장할 수 있다. 또한 저장된 데이터를 영구적으로 디스크에 저장할 수 있는 백업 기능을 제공하므로 애플리케이션의 주 저장소로도 사용할 수 있다. 또한 메모리에 데이터를 저장하기 때문에 빠른 처리 속도가 장점이다. 레디스 내부에서 명령어를 처리하는 부분은 싱글 스레드 아키텍처로 구현되어 있다. 멀티 스레드 아키텍처보다 구조가 단단하게 설계되어 여러 장점이 있다. - “스프링 부트로 개발하는 MSA 컴포넌트 - 김병부“
⇒ 장점은 빠른 처리 속도, 단점은 저장 공간 제약
Redis 데이터 백업 방식
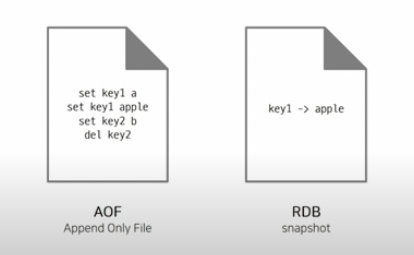
출처 : NHN FORWORD 2021 레디스 야무지게 사용하기! https://www.youtube.com/watch?v=92NizoBL4uA
메모리에 데이터를 관리하므로 매우 빠른 속도로 데이터를 저장 및 조회할 수 있다. 하지만 메모리 특성상 저장된 데이터는 사라질(휘발성) 가능성이 있다. 이를 보완하고자 레디스는 관리하고 있는 데이터에 영속성을 제공한다. 즉, 메모리에 있는 데이터를 디스크에 백업하는 기능을 제공하며, RDB 방식이나, AOF 방식으로 백업할 수 있다.
1) RDB (Redis Database) : 메모리에 있는 데이터 전체에서 스냅샷을 작성하고, 이를 디스크로 저장하는 방식
- 특정 시간마다 여러 개의 스냅샷을 생성하고, 데이터를 복원해야 한다면 스냅샷 파일을 그대로 로딩만 하면 됨.
- 하지만, 스냅샷 이후 변경된 데이터는 복구할 수 없음. → 데이터 유실(loss)
2) AOF (Append Only File) : 데이터가 변경되는 이벤트가 발생하면 이를 모두 로그에 저장하는 방식
- 데이터를 생성, 수정, 삭제하는 이벤트를 초 단위로 취합 및 로그 파일에 작성
- 모든 데이터의 변경 기록들을 보관하고 있으므로 최신 데이터 정보를 백업 가능
- RDB 방식에 비해 데이터 유실량이 적음(초 단위 데이터는 유실 가능).
- RDB 방식보다 로딩 속도가 느리고 와 파일 크기가 큰 것이 단점
⇒ 일부 데이터 손실에 영향을 받지 않는 경우(캐시로만 사용할 때), RDB
⇒ 장애 상황 직전까지의 모든 데이터가 보장되어야 할 경우, AOF
⇒ 강력한 내구성이 필요한 경우, RDB + AOF
⇒ 레디스는 일반적으로 AOF와 RDB를 동시에 사용하여 데이터를 백업한다.
- 예를 들면, 매일 7시마다 RDB 스냅샷을 생성하고, RDB 생성 이후에 변경되는 데이터는 AOF로 백업.
Redis 백업 방식 설정
1) RDB
- 자동 : Redis.conf 파일 → SAVE 옵션 설정 (시간 기준)
- 수동 : redis-cli에서 BGSAVE 커맨드를 이용하여 수동으로 RDB 파일 저장
- SAVE 커맨드는 절대 사용 X (레디스는 싱글 스레드, 저장하는 동안 다른 작업 수행 불가)
2) AOF
- 자동 : redis.conf 파일 → auto-aof-rewrite-percentage 옵션 설정 (크기 기준)
- 수동 : redis-cli에서 BGREWRITEAOF 커맨드를 이용하여 수동으로 AOF 파일 재작성
Redis single thread
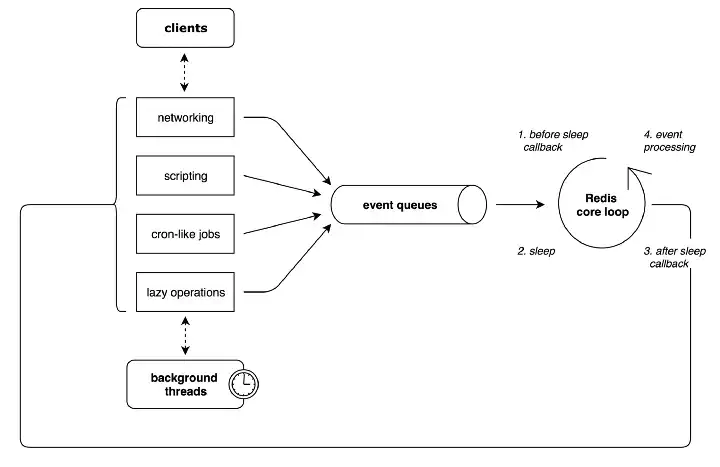
출처 : https://medium.com/fluence-network/porting-redis-to-webassembly-with-clang-wasi-af99b264ca8
레디스의 코어스레드는 싱글스레드!
레디스는 사용자들이 실행한 명령어들을 이벤트 루프(event loop) 방식으로 처리한다. 즉, 클라이언트가 실행한 명령어들을 Event Queue에 적재하고 싱글 스레드로 하나씩 처리한다. 메모리를 사용하기 때문에 싱글 스레드로 데이터를 빠르게 처리할 수 있다.
장점
- 멀티 스레드 환경이 아니라 Context Switch 발생 X → 효율적인 시스템 리소스 사용 가능
- 1번과 같은 이유로 Deadlock 발생 X
단점
-
싱글 스레드 이므로 전체 데이터 스캔과 같은 오버헤드가 큰 명령어를 처리하는 동안 다른 명령어를 처리 불가.
-
이 때, 다른 명령어들은 이벤트 큐에 저장되어 있는 시간이 길어짐. → 응답 속도 저하
또한, 멀티 스레드 환경이 아니라 Context Switch가 발생하지 않으므로 효율적으로 시스템 리소스를 사용할 수 있다. 또한 Dead lock 같은 현상이 발생하지 않는다.
Redis 사용 용도
지금까지 설명한 특징들 때문에 레디스를 다음 목적으로 사용할 수 있다.
- 주 데이터 저장소 : AOF, RDB 백업 기능과 레디스 아키텍처를 사용하여 주 저장소로 데이터를 저장할 수 있다. 하지만 메모리 특성상 용량이 큰 데이터 저장소로는 적절하지 않다.
- 데이터 캐시 : 인메모리 데이터 저장소이므로 주 저장소의 데이터를 캐시하여 빠르게 데이터를 읽을 수 있다. 캐시된 데이터는 한곳에 저장되는 중앙 집중형 구조로 구성한다. → 데이터 일관성 유지 가능
- 분산 락(distributed lock) : 분산 환경에서 여러 시스템이 동시에 데이터를 처리 할 때는 특정 공유 자원의 사용 여부를 검증하여 데드 락을 방지할 필요가 있다. 이때 레디스를 분산 락으로 사용할 수 있다.
- 순위 계산 : 레디스에서 제공하는 ZSet(Sorted Set) 자료 구조를 이용하여 순위 계산 용도로 사용하기도 한다. ZSet은 정렬 기능이 포함된 Set 자료 구조이므로 쉽고 빠르게 순위를 계산할 수 있다.
Redis 아키텍처
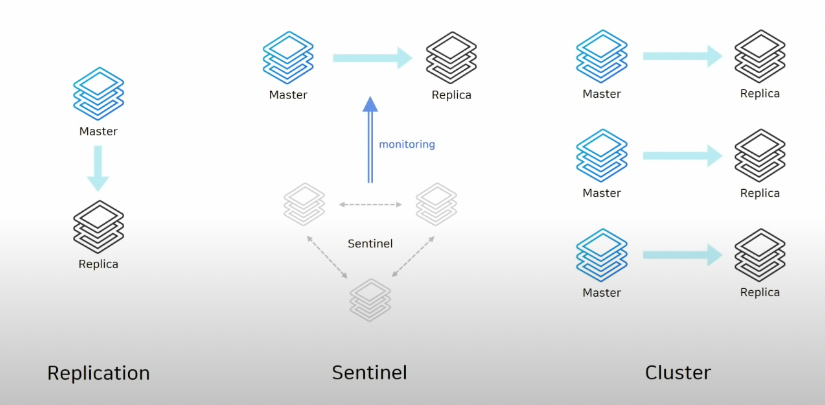
출처 : NHN FORWORD 2021 레디스 야무지게 사용하기! https://www.youtube.com/watch?v=92NizoBL4uA
레디스는 3가지 아키텍처로 나누어서 볼 수 있다.
-
Replication 아키텍처 : Master와 Replica로 구성
- 단순한 복제 연결 시 사용한다. (relicaof 커맨드 이용)
- 비동기식 복제 (복제가 잘 됐는지 확인하지 않음)
- HA(고가용성) 기능이 없으므로 장애 상황 시 수동으로 복구한다.
- 장애 상황 시 스프링에서 새로운 Redis 서버의 연결 정보를 변경 해주어야 함.
-
Sentinel 아키텍처 : Sentinel, Master, Replica로 구성, 자동 Failover가 가능한 HA(High Availability) 구성
레디스 센티넬은 레디스 서버들(Master, Replica)을 관리한다. 센티넬은 주기적으로 레디스 서버들을 모니터링한다. 마스터 서버가 서비스할 수 없는 상태가 되면 다른 레플리카를 마스터 서버로 변경한다.
- Sentinel 노드가 Redis 마스터와 레플리카 노드를 감시
- Master가 비정상 상태일 때 자동으로 Failover(자동 복구)
- 애플리케이션은 Sentinel과 연결하기 때문에, 장애 상황 발생 시 연결 정보 변경 필요 없음
- Sentinel 노드도 장애 상황이 발생할 수 있기 때문에 반드시 3대 이상의 홀수로 존재해야 함.
- 과반수 이상의 Sentinel이 동의(Quorum based)가 있어야 Failover 진행
- 많은 리소스가 필요하므로 Sentinel과 Master 혹은 Replica를 같은 서버에 올려 사용하기도 함.
-
Cluster 아키텍처 : 레디스 3.0 버전 이후부터 제공, 클러스터에 포함된 노드들이 서로 통신하는 구조
레디스 클러스터는 클러스터에 포함된 노드들이 서로 통신하면서 HA를 유지한다. 거기에 샤딩 기능까지 기본 기능으로 사용할 수 있다. 클러스터 내부에는 센티넬과 동일하게 마스터와 레플리카는 짝을 이루어 데이터를 복제한다. 클러스터 내부의 모든 노드는 모두 서로 연결되어 있는 메시(Mesh) 구조로 되어 있으며, 가십 프로토콜(gossip protocol)을 사용하여 서로 모니터링 한다.
- 센티넬과 동일하게 Master와 Replica는 짝을 이루어 데이터를 복제
- 클러스터를 구성하기 위해 세 개의 마스터 노드는 반드시 필요.
- 레플리카 노드의 개수는 0개 혹은 그 이상으로 설정 가능.
- 고가용성을 위해 반드시 한 개 이상의 레플리카를 설정하는 것이 좋음
- 데이터를 마스터 노드들에 샤딩
- 해시 함수를 사용하여 데이터 분배, 데이터의 키 값을 해시 함수로 넘긴 후 리턴 값을 사용하여 어떤 노드에 저장할지 결정한다. * 리턴 값은 항상 0 ~ 16383 값을 리턴
- 클러스터에 노드를 추가하거나 제거할 경우 레디스 명령어를 사용하여 해시 함수 값 범위를 조정 가능
- 리밸런싱(Rebalancing) & 리샤딩(Re-shard)
- 조정된 범위에 포함되는 레디스 데이터들은 자동으로 재분배되어 설정된 위치로 이동한다.
- 애플리케이션은 레디스 클러스터의 노드 중 하나라도 연결되면 클러스터의 전체 상태 정보를 확인 가능
- 장애 상황 발생 또는 노드 확장(Scale out) 시 애플리케이션의 Redis 서버 연결 정보 변경 필요 X
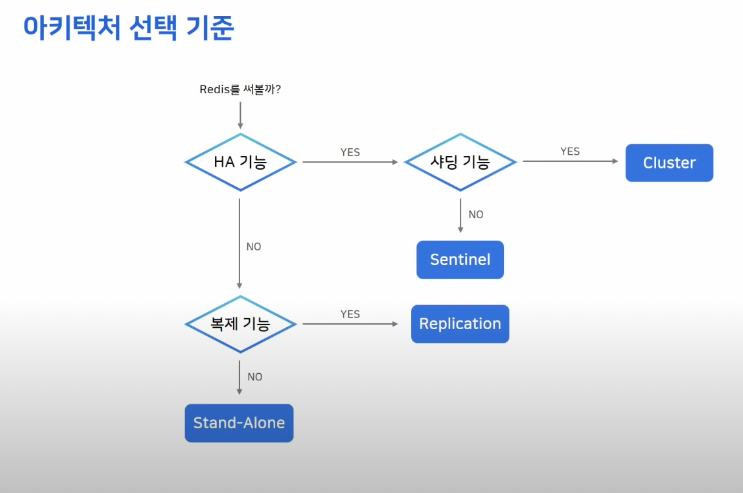
출처 : NHN FORWORD 2021 레디스 야무지게 사용하기! https://www.youtube.com/watch?v=92NizoBL4uA
레디스 아키텍처 선택 시 참고 하면 좋을 자료 같다..
나는 레디스를 캐시로써 사용할 것이기 때문에 Stand-Alone 혹은 Replication을 사용하면 될 것 같은데.. Redis는 싱글 스레드 이기 때문에 쓰기/수정 작업 시 읽기 작업은 불가하므로, 성능을 고려하여 Replication으로 진행 해봐야 겠다.
Redis 자료 구조
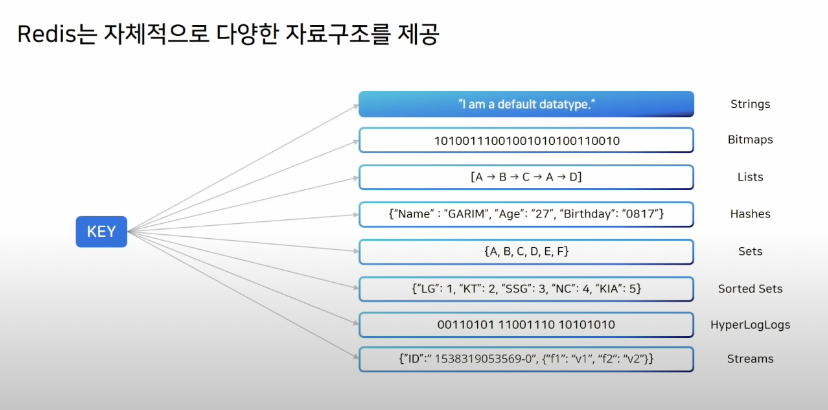
출처 : NHN FORWORD 2021 레디스 야무지게 사용하기! https://www.youtube.com/watch?v=92NizoBL4uA
레디스는 다양한 형태의 자료 구조를 제공한다. 기본적으로 키-밸류(Key-Value) 형태의 구조를 띠며, 밸류가 사용하는 자료 구조에 따라 여러 기능을 사용할 수 있다. 즉, 어떤 형태의 자료 구조를 사용하더라도 키는 반드시 필요하다는 말씀!
- String : 문자열 데이터를 저장 및 조회할 수 있는 기본 자료 구조
- 단순 증감 연산으로 사용 가능 (INCR / INCRBY / INCRBYFLOAT / HINCRBY / HINCRBYFLAOT / ZINCRBY)
- Bitmap : 비트 연산을 사용할 수 있는 자료 구조
- List : 리스트 데이터, 그림과 같이 리스트 아이템은 링크드 리스트(Linked List) 형태로 서로 연결되어 있다.
- Hashe : 해시 자료 구조. 해시 필드(field)와 밸류(value)로 구성된다. 해시 데이터는 레디스 키와 매핑되어 있으므로 해시 밸류를 생성 및 조회 하려면 레디스 키와 필드를 동시에 사용해야 한다.
- Set : 리스트와 비슷한 집합 데이터, 중복을 허용하지 않는 자료 구조이다.
- Sorted Set(ZSet) : Set과 비슷한 집합 데이터, 정렬 기능을 제공한다. 중복을 허용하지 않으며, 이 때 데이터는 스코어와 함께 저장할 수 있다. Sorted Set은 스코어 값을 사용하여 정렬하고, 스코어 값이 중복되면 사전 순으로 정렬한다.
- Hypperloglog : 집합의 데이터 개수를 추정할 수 있는 알고리즘 이름이자 이를 사용할 수 있는 레디스 자료 구조이다. 이 알고리즘은 비트 패턴을 분석하여 비교적 정확한 추정 값(오차 0.81%)을 계산할 수 있다.
- 예를 들어, 특정 상품의 조회수를 1만 239회라고 정확하게 계산할 때는 시스템 부하가 발생한다. 대신 추정 값을 계산하는데 최적화되어 1만 회 같은 근사 값을 조회할 수 있다. 중복된 값을 제거 가능하며, 저장 공간이 작아 카운트에 적합하다.
- Stream : 레디스 5.0 버전부터 제공하는 기능, 이벤트성 로그를 처리할 수 있다. 일종의 메세지 서비스 기능. 스트림 키 이름과 값, 필드를 사용할 수 있는 자료 구조 형태를 띤다.
앞서 말한 자료구조들의 몇가지 Best Practice를 살펴보자.
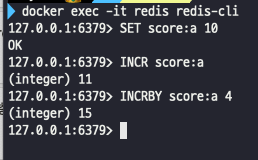
Counting이 필요한 상황
-
String 사용 : INCR / INCRBY / INCRBYFLOAT / HINCRBY / HINCRBYFLAOT / ZINCRBY
-
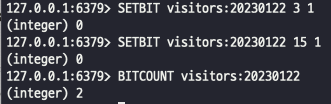
Bits 사용 : 데이터 저장공간 절약, 정수로 된 데이터만 카운팅 가능
-
예를 들어, 오늘 서비스 접속 유저 수를 저장하고 싶을 때 비트연산자 사용! (유저아이디가 정수일 경우)
오늘 날짜를 키값으로 두고 유저아이디에 해당하는 비트자리를 1로 설정한다. 즉, 한 명의 유저는 1개의 비트를 의미. 접속한 유저가 천만 명일 경우 천만 자리 수의 비트가 필요 → 1.2MB 차지
-
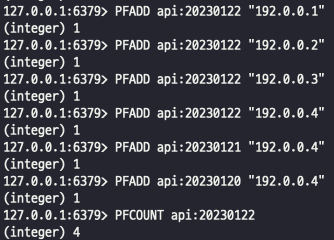
- HyperLogLogs 사용 : 대용량 데이터를 카운팅 할 때 적절 (오차 0.81%)
-
Set과 비슷하게 모든 String 데이터 값을 유니크하게 구별 가능, 저장되는 용량은 매우 작음(12KB 고정)
-
한 번 저장된 데이터는 다시 확인할 수 없음
-
예를들어, API 호출 한 유니크 한 IP 개수, 검색엔진에서 사용된 검색어가 몇개인지 확인할 때 사용 가능
-
PFADD - 데이터 저장, PFCOUNT - 데이터 카운트, PFMERGE - 여러 데이터를 종합하여 카운트
-
PFMERGE는 일별로 데이터를 저장했는데, 월별 데이터를 보고 싶은 경우 사용 가능
-
Redis 유효 기간
레디스에 저장되는 모든 데이터는 유효 기간을 설정할 수 있다. 유효 기간이 지난 데이터는 레디스가 해당 데이터를 메모리에서 삭제한다. ⇒ 메모리를 효율적으로 사용 가능
레디스는 다양한 방법으로 유효기간을 설정할 수 있다.
-
EXPIRE 명령어를 사용하여 이미 생성된 데이터에 유효 기간을 설정.
-
데이터를 생성할 때 EX 옵션을 사용하여 생성과 동시에 유효 기간을 설정.
- 이 옵션은 자료구조에 따라 지원하지 않는 경우도 있으니 확인해야 함.
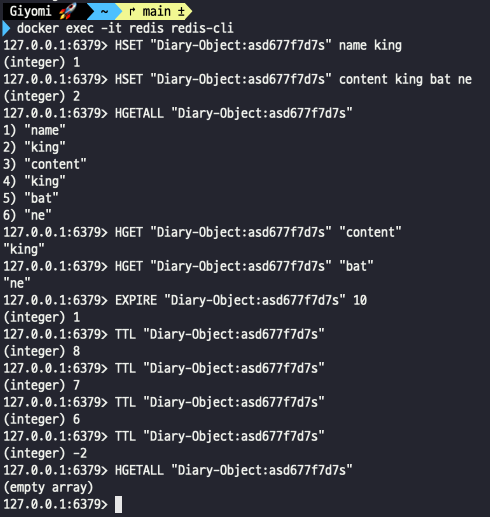
레디스는 메모리에 데이터를 저장하므로 저장 공간이 한정적이다. 그래서 레디스에 데이터를 저장할 때는 데이터의 유효 기간을 설정하는 것을 권장한다. 만약, 유효기간을 설정하지 않는다면 직접 데이터를 삭제할 때까지 영원히 유지된다.
결론
현재 프로젝트에 원격 캐시로 레디스를 사용하고자 레디스에 대해 알아보았다. 레디스의 코어 스레드가 싱글 스레드인 점을 처음 알게되었고, 이로 인해 발생하는 장점 및 단점을 알 수 있었다. 또한 레디스를 사용할 때 어떤 점에 주의 해야 하는지 어떤 점을 활용해야 하는지 알 수 있었고, 다양한 아이디어가 떠오른다!!!!!!😈 빨리 적용해보고 싶다!! 이 밖에도 레디스를 캐시로 이용할 때 유의해야 할 점이 있다고 한다. 다음 글에서는 레디스를 캐시로 이용할 때 고려해야할 부분에 대해서 작성 해야겠다.
출처
- 저서 '스프링부트로 개발하는 MSA 컴포넌트' Chapter 10 - 김병부 지음.
- NHN FORWARD 2021, Redis 야무지게 사용하기 https://www.youtube.com/watch?v=92NizoBL4uA

2개의 댓글

이 글은 Redis에 대해 매우 체계적이고 명확하게 설명하고 있어, Redis를 처음 접하는 사람들에게 큰 도움이 될 것 같습니다. 특히 Redis의 정의부터 저장 방식, 아키텍처, 자료 구조, 유효 기간까지 중요한 개념들을 한눈에 정리해 주어서 Redis의 전반적인 이해를 돕고 있습니다.
싱글 스레드 아키텍처의 장점과 클러스터 기능, 그리고 데이터 영구 저장 옵션에 대한 설명도 매우 유익합니다. Redis의 빠른 처리 속도와 다양한 기능을 활용하여 어떻게 효율적인 시스템을 구축할 수 있을지 많은 인사이트를 얻을 수 있네요. 좋은 정보 감사합니다! https://make-a-calendar.com/
글 좋네요 잘읽고 갑니다.