ch8.3 BOW (Bag of Words) 모델
-
BOW 모델이란 ?
BOW 모델은 문서가 가지는 모든 단어를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여하여 피처 값을 추출하는 모델이다. -
BOW 모델 프로세스
- 문장1과 문장2가 있다고 가정하자.
- 두 문장에 있는 모든 단어에서 중복을 제거하고, 각 단어 (= feature, term) 를 칼럼 형태로 나타낸다.
- 이후 각 단어에 고유의 인덱스를 부여한다.
- 개별 문장에서 해당 단어가 나타나는 횟수를 각 단어에 기재한다. 결과는 아래와 같다.
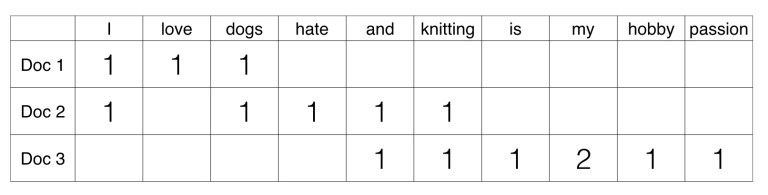
-
BOW 모델 장점
- 쉽고 빠른 구축 가능
- 단순히 단어의 발생 횟수에 기반하고 있지만, 이는 예상보다 문서의 특징을 잘 나타낼 수 있는 모델이어서 전통적으로 여러 분야에서 활용도가 높음
-
BOW 모델 단점
- 문맥 의미 (Semantic Context) 반영 부족
n-gram 기법을 활용할 수는 있지만, 제한적인 부분에 그침 - 희소 행렬 문제
매우 많은 문서에서 단어의 총 개수는 수만 ~ 수십만 개가 될 수 있지만, 하나의 문서에 있는 단어는 이 중 극히 일부분에 해당함
이처럼 대규모의 칼럼으로 구성된 행렬에서 대부분의 값이 0으로 채워지는 행렬을 희소 행렬 (Sparse Matrix) 이라고 함
이는 머신러닝 알고리즘의 수행 시간과 예측 성능을 떨어뜨리기 때문에 희소 행렬을 위한 특별한 기법을 마련하여 적용해야 함
- 문맥 의미 (Semantic Context) 반영 부족
ch8.3 BOW 피처 벡터화
BOW 모델의 피처 벡터화는
1) 각 문서의 텍스트를 단어로 추출하여 피처로 할당
예 - M개의 문서가 있을 때, 이 문서들에 있는 모든 단어 (N개라고 가정) 를 추출하여 나열 후 피처로 할당
2) 각 단어의 발생 빈도 같은 값을 해당 피처에 부여하여 벡터로 만듦
예 - M * N 크기의 행렬 생성
과정으로 진행된다.
ch8.3 BOW 피처 벡터화 방식
- 카운트 기반의 벡터화
- 단어 피처에 값을 부여할 때, 각 문서에서 해당 단어가 나타나는 횟수, 즉 Count 를 부여하는 경우를 카운트 벡터화라고 함
- 카운트 값이 높을수록 중요한 단어로 인식
- TF-IDF (Term Frequency - Inverse Document Frequency) 기반의 벡터화
- 카운트 기반의 벡터화의 문제라고 할 수 있는 빈도수 - 중요도 비례 문제를 보완하고자 도입
- 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 패널티를 주는 방식으로 값을 부여

ch8.3 BOW 의 Count, TF-IDF 구현
- Count (
CountVectorizer) - TF-IDF (
TfidfVectorizer)
ch8.3 희소 행렬 문제 해결 기법
사이킷런에서 제공하는 CountVectorizer 또는 TfidfVectorizer 를 사용하여 텍스트를 피처 단위로 벡터화해 변환하고 CSR 형태 (희소 행렬 문제 해결 기법 적용) 의 희소 행렬을 반환할 수 있다.
희소 행렬은 많은 메모리 공간을 필요로 하며, 행렬의 크기가 커서 연산 시에도 데이터 액세스를 위한 시간이 많이 소모된다.
이러한 희소 행렬을 물리적으로 적은 메모리 공간을 차지할 수 있도록 변환해야 하는데, 대표적인 방법으로 COO 형식과 CSR 형식이 있다. 일반적으로 큰 희소 행렬을 저장하고 계산을 수행하는 능력이 CSR 이 더 뛰어나기 때문에 CSR 이 COO 보다 많이 선호된다.
희소 행렬 변환을 위해서 주로 사이파이 (Scipy) 를 이용한다.
- 희소 행렬의 COO 형식
-
0이 아닌 데이터만 별도의 데이터 배열에 저장하고, 그 데이터를 가리키는 행과 열의 위치를 별도의 배열로 저장하는 방식
-
COO 형식 예시
- 가령 [3, 0, 1], [0, 2, 0]] 의 2차원 데이터가 있다고 가정하자.
- 0이 아닌 데이터가 있는 위치를 표현해보면, (0, 0), (0, 2), (1, 1) 이다.
- 이때, 행과 열을 별도의 배열로 저장하면 [0, 0, 1], [0, 2, 1] 이 된다.
-
사이파이
coo_matrix를 이용하여 희소 행렬을 COO 형태로 변환
import numpy as np
dense = np.array([[3, 0, 1], [0, 2, 0]])from scipy import sparse
## 0 이 아닌 데이터 추출
data = np.array([3, 1, 2])
## 행 위치와 열 위치를 각각 array로 생성
row_pos = np.array([0, 0, 1])
col_pos = np.array([0, 2, 1])
## sparse 패키지의 coo_matrix를 이용하여 COO 형식으로 희소 행렬 생성
sparse_coo = sparse.coo_matrix((data, (row_pos, col_pos))) ## sparse_coo = COO 형식의 희소 행렬sparse_coo.toarray() ## COO 형식의 희소 행렬 => 다시 밀집 형태의 행렬로 출력array([[3, 0, 1],
[0, 2, 0]])- 희소 행렬의 CSR 형식
-
CSR 형식은 COO 형식이 행과 열의 위치를 나타내기 위해 반복적인 위치 데이터를 사용해야 하는 문제점을 해결한 방식
-
CSR 형식 예시
- 가령 [3, 0, 1], [0, 2, 0]] 의 2차원 데이터가 있다고 가정하자.
- 0이 아닌 데이터가 있는 위치를 표현해보면, (0, 0), (0, 2), (1, 1) 이다.
- 이때, 행과 열을 별도의 배열로 저장하면 [0, 0, 1], [0, 2, 1] 이 된다. (여기까지 COO 형식과 동일)
- CSR 형식은 이때 행 위치 배열이 0부터 순차적으로 증가하는 값으로 이뤄졌다는 특성을 고려하여 해당 값과 그 시작 위치만을 표기하는 방법으로 반복을 제거함
- 따라서 행 위치 표기 결과는 [0, 2, 3] (마지막 숫자 3은 데이터의 총 항목 개수를 표기)
-
사이파이
csr_matrix를 이용하여 희소 행렬을 CSR 형태로 변환
from scipy import sparse
dense2 = np.array([[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]])## 0 이 아닌 데이터 추출
data2 = np.array([1, 5, 1, 4, 3, 2, 5, 6, 3, 2, 7, 8, 1])
## 행 위치와 열 위치를 각각 array로 생성
row_pos = np.array([0, 0, 1, 1, 1, 1, 1, 2, 2, 3, 4, 4, 5])
col_pos = np.array([2, 5, 0, 1, 3, 4, 5, 1, 3, 0, 3, 5, 0])
## COO 형식으로 변환
sparse_coo = sparse.coo_matrix((data2, (row_pos,col_pos)))
## 행 위치 배열의 고유한 값들의 시작 위치 인덱스를 배열로 생성
row_pos_ind = np.array([0, 2, 7, 9, 10, 12, 13])
## CSR 형식으로 변환
sparse_csr = sparse.csr_matrix((data2, col_pos, row_pos_ind))
print('COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_coo.toarray())
print('CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_csr.toarray())COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
[[0 0 1 0 0 5]
[1 4 0 3 2 5]
[0 6 0 3 0 0]
[2 0 0 0 0 0]
[0 0 0 7 0 8]
[1 0 0 0 0 0]]
CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
[[0 0 1 0 0 5]
[1 4 0 3 2 5]
[0 6 0 3 0 0]
[2 0 0 0 0 0]
[0 0 0 7 0 8]
[1 0 0 0 0 0]]- COO 형식과 CSR 형식 예제
dense3 = np.array([[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]])
coo = sparse.coo_matrix(dense3)
csr = sparse.csr_matrix(dense3)## COO 형식
coo<6x6 sparse matrix of type '<class 'numpy.int64'>'
with 13 stored elements in COOrdinate format>## COO 형식을 다시 Dense로 출력
coo.toarray()array([[0, 0, 1, 0, 0, 5],
[1, 4, 0, 3, 2, 5],
[0, 6, 0, 3, 0, 0],
[2, 0, 0, 0, 0, 0],
[0, 0, 0, 7, 0, 8],
[1, 0, 0, 0, 0, 0]])## CSR 형식
csr<6x6 sparse matrix of type '<class 'numpy.int64'>'
with 13 stored elements in Compressed Sparse Row format>## CSR 형식을 다시 Dense로 출력
csr.toarray()array([[0, 0, 1, 0, 0, 5],
[1, 4, 0, 3, 2, 5],
[0, 6, 0, 3, 0, 0],
[2, 0, 0, 0, 0, 0],
[0, 0, 0, 7, 0, 8],
[1, 0, 0, 0, 0, 0]])정리
텍스트 전처리 후, BOW 모델을 이용하여 피처 벡터화를 수행할 수 있다.
BOW 모델은 문서들이 가지는 모든 단어를 피처로 할당하고, 각 단어의 빈도와 같은 값을 피처의 값으로 할당하여 벡터를 생성하는 모델이다.
BOW 피처 벡터화 방식은 1) 카운트 기반의 벡터화와 2) TF-IDF 기반의 벡터화 이렇게 두 가지가 있다.
위 두 가지 방법은 기본적으로 희소 행렬 해결 기법인 1) COO 형식과 2) CSR 형식 중 CSR 형식으로 희소 행렬을 반환한다.
References
