논문: https://arxiv.org/abs/1511.06939
많은 전자상거래 추천 시스템(특히 소규모 소매업체)과 대부분의 뉴스 및 미디어 사이트는 사용자 ID를 장기적으로 추적하지 않는다.
따라서 실제 추천 시스템은 짧은 세션 기반 데이터만을 바탕으로 추천해야 하는 문제에 직면하며, 이 경우 행렬 분해 접근법(일반적인 추천 시스템에서 사용)은 정확도가 떨어질 수 있다.
1. INTRODUCTION
-
많은 사용자가 소규모 전자상거래 사이트에서 단 한두 번의 세션만을 가지며, 특정 도메인(예: 분류 광고 사이트)에서는 사용자 행동이 종종 세션 기반 특성을 보인다.
따라서 사용자의 후속 세션은 독립적으로 처리되어야 한다. -
대부분의 세션 기반 추천 시스템은 사용자 프로필을 사용하지 않는 비교적 간단한 방법(예: item-item 유사도 등)으로 구성된다.
그러나 이러한 방법들은 종종 사용자의 마지막 클릭이나 선택만을 고려하며, 과거 클릭 정보를 무시한다. -
RNN 모델을 활용한 세션 기반 추천에서는 사용자가 웹사이트에서 처음 클릭한 항목을 초기 입력으로 간주할 수 있다.
그 다음 초기 입력을 바탕으로 모델에 출력(추천)을 요청하고, 사용자가 클릭할 때마다 이전 클릭 데이터를 기반으로 출력(추천)을 생성한다. -
사용자가 관심을 가질 수 있는 상위 항목(Top items)에 모델링 파워를 집중시키기 위해, RNN 모델 학습에 순위 손실(Ranking loss)함수를 사용한다.
3. RECOMMENDATIONS WITH RNNS
3.1 CUSTOMIZING THE GRU MODEL
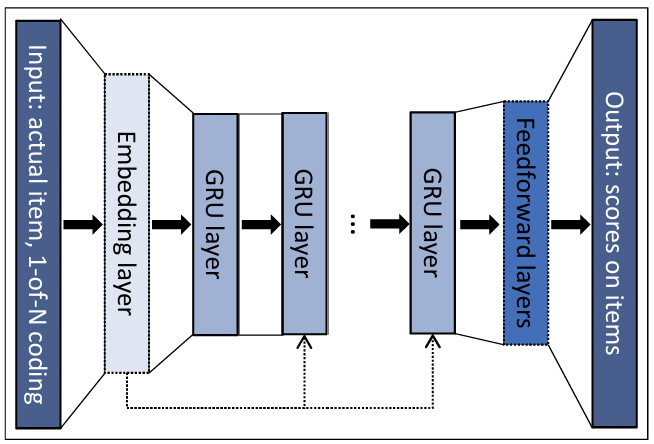
-
GRU 기반 RNN 모델을 사용했으며, 네트워크의 입력은 세션의 현재 상태이고 출력은 각 항목이 세션에서 다음으로 선택될 확률(선호도)이다.
- 세션의 현재 상태는 (1) 현재 이벤트의 항목이거나 (2) 세션 내의 모든 이벤트일 수 있다.
(1)에서는 1-of-N 인코딩(입력 벡터의 길이가 항목 수와 동일하며, 활성 항목에 해당하는 좌표만 1이고 나머지는 0인 방식)이 사용되고, (2)에서는 이러한 표현의 가중합을 사용하며 이전에
발생한 이벤트는 가중치가 감소한다. - 추후 실험 결과에서 세션 내 모든 이벤트를 입력으로 넣는 것이 현재 이벤트 항목만을 입력으로 넣는 것에 비해 추가적인 정확도 향상을 가져오지 않는 것이 드러났다.
(GRU가 LSTM의 특성을 가지기에 어찌 보면 당연한 것)
- 세션의 현재 상태는 (1) 현재 이벤트의 항목이거나 (2) 세션 내의 모든 이벤트일 수 있다.
-
입력에서 이후에 임베딩 레이어를 추가할 수 있다.
- 추후 실험 결과에서 항목의 임베딩을 사용하는 것이 약간 더 나쁜 결과를 보여주었기에, 1-of-N 인코딩을 유지했다고 한다.
-
여러 개의 GRU layers를 사용할 경우, 이전 레이어의 은닉 상태가 다음 레이어의 입력으로 사용된다. 또한, 입력은 선택적으로 네트워크의 더 깊은 GRU 레이어에 연결될 수 있으며, 이는 성능 향상에 기여하는 것으로 확인되었다.
- 추후 실험 결과에서 단일 GRU 레이어가 가장 우수한 성능을 보였다.
(일반적으로 세션의 수명이 짧아 다양한 해상도의 여러 시간 스케일이 적절히 표현될 필요가 없기 때문으로 추정된다) - GRU 레이어의 크기를 늘리는 것은 성능을 향상시켰음을 확인했다.
- 추후 실험 결과에서 단일 GRU 레이어가 가장 우수한 성능을 보였다.
-
Feedforward layers를 마지막 레이어와 출력 사이에 추가할 수 있다.
- 추후 실험 결과에서 GRU 레이어 이후에 추가적인 Feedforward layers을 추가하는 것은 도움이 되지 않았다고 한다.
- 출력 레이어의 활성화 함수로 tanh를 사용하는 것이 유익함을 발견했다.
3.1.1 SESSION-PARALLEL MINI-BATCHES
- 자연어 처리에서의 순차적 미니 배치는 본 연구에 적합하지 않다.
따라서 세션 병렬 미니배치(session-parallel mini-batches)를 사용한다.
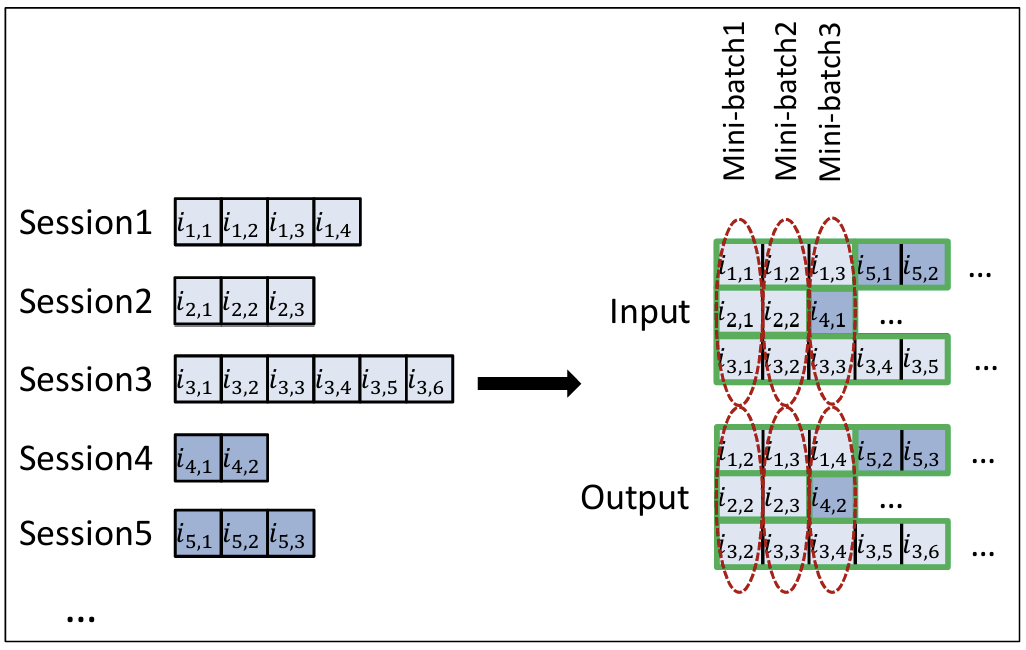
- 먼저, 세션의 순서를 생성한다.
- 그 다음, 첫 번째 미니 배치의 입력을 활성 세션의 첫 번째 이벤트()로 구성하고, 원하는 출력은 해당 세션의 두 번째 이벤트()가 된다.
- 두 번째 미니 배치는 두 번째 이벤트로 구성되며, 이러한 방식으로계속한다.
- 만약 세션이 끝나면, 다음 사용 가능한 세션을 그 자리에 배치한다.
이때 세션은 독립적인 것으로 가정하므로, 전환이 발생할 때 적절히 은닉 상태를 초기화한다.
3.1.2 SAMPLING ON THE OUTPUT
-
모든 항목에 대해 점수를 계산하는 것은 알고리즘 복잡도 증가(→ 시간 증가)로 인해 실효성이 떨어진다.
-
따라서 출력에서 샘플링을 수행하여 항목의 작은 하위 집합에 대해서만 점수를 계산해야 한다.
-
이로 인해, 일부 가중치만 업데이트 되므로, 원하는 출력(positive examples) 외에도 몇몇 부정적인 예제(negative examples)에 대한 점수를 계산하고 원하는 출력이 높은 순위를 갖도록 가중치를 조정해야 한다.
- 임의의 누락된 이벤트에 대한 자연스러운 해석은 ‘사용자가 해당 항목의 존재를 알지 못했기 때문에 상호작용이 없었다’이다.
- 그러나 항목이 인기있을수록 사용자가 항목을 알고 있을 가능성이 높아지며, 누락된 이벤트가 싫어함(dislike)를 나타낼 가능성이 높다.
-
항목의 인기도에 비례하여 항목을 샘플링(popularity-based sampling)해야 한다.
- 각 학습 데이터(세션)마다 별도의 샘플링을 생성하는 대신, 미니배치의 다른 학습 데이터에서 항목을 가져와 부정적인 예제로 사용한다.
- 미니 배치의 다른 학습 데이터에 항목이 포함될 가능성이 그 항목의 인기도에 비례하기 때문이다.
- 이 접근법으로 샘플링 단계를 생략함으로써 계산 시간을 단축할 수 있다.
3.1.3 RANKING LOSS
추천 시스템의 핵심은 항목의 관련성에 기반한 순위 매기기(relevance-based ranking)이다.
-
Pointwise Ranking: 항목의 점수 또는 순위를 서로 독립적으로 추정하며, 관련 항목의 순위가 낮아야 한다(1에 가까워야)는 방식으로 손실(loss)을 정의한다.
- 추후 실험에서 Pointwise Ranking Loss(예: Cross-entropy, MRR 최적화)는 정규화를 적용했음에도 불구하고 일반적으로 불안정했다. 원하는 항목에 대해 높은 점수를 독립적으로 얻으려 하면서 부정적인 샘플에 대한 밀어내기가 작게 적용되기 때문으로 추정된다.
-
Pairwise Ranking: 긍정적 항목과 부정적 항목의 쌍을 비교하여 점수 또는 순위를 평가한다. 긍정적 항목의 순위가 부정적 항목보다 낮아야 한다는 제약을 손실로 강제한다.
-
Listwise Ranking: 모든 항목의 점수와 순위를 사용하여 이를 완벽한 순서(perfect ordering)와 비교한다. 하지만 정렬(sorting)을 포함하기 때문에 계산 비용이 크며, 일반적으로 자주 사용되지 않는다.
- 관련 항목이 하나뿐인 경우, 리스트 방식 순위 매기기(listwise ranking)는 쌍 방식 순위 매기기(pairwise ranking)를 통해 해결될 수 있다.
따라서 두 가지 Pairwise Ranking을 사용했다.
-
BPR(Bayesian Personalized Ranking):
pairwise ranking loss를 사용하는 행렬 분해(matrix factorization) 방법이다.
긍정적인 항목의 점수를 샘플링된 여러 부정적인 항목들과 비교하고 그 평균을 손실로 사용하여, 두 항목의 예측값 사이의 차이를 최대화하는 방향으로 학습한다.- : 샘플의 크기.
- : 항목 에 대한 점수.
- : 해당 세션에서 긍정적인 항목(세션의 다음 항목).
- : 부정적인 샘플들.
-
TOP1:
관련 항목의 상대적인 순위(relative rank)의 정규화된 근사값을 나타낸다.하지만 의 점수가 높아지도록 최적화하는 동안, 특정 긍정적인 항목이 부정적인 예제로 작용하면서 점수가 점점 더 높아지는 불안정성이 발생할 수 있다. 따라서 부정적인 항목의 점수를 0 근처로 유지하기 위해 손실에 정규화 항을 추가했다.
4. EXPERIMENTS
DATASET
-
RecSys Challenge 2015 (RSC15):
전자 상거래 사이트의 클릭 스트림을 포함하며, 일부는 구매 이벤트로 끝나는 경우도 있다.- 학습 세트를 이용하며, 클릭 이벤트만 유지한다.
- 길이가 1인 세션은 제거한다.
- 테스트는 이후 하루 동안의 세션을 사용한다. 이때, 각 세션은 학습 또는 테스트 세트에 할당되며, 세션 중간에서 데이터를 분할하지 않는다.
- 협업 필터링 특성 상, 테스트 세트에서 클릭된 항목이 학습 세트에 포함되지 않는 경우, 해당 클릭은 테스트 세트에서 제거한다.
-
VIDEO:
Youtube와 유사한 동영상 OTT 비디오 서비스 플랫폼에서 수집했다. 일정 시간 이상 비디오를 시청한 이벤트들을 수집했다.- Bot에 의해 생성되었을 가능성이 높은 매우 긴 세션을 필터링한다.
- 학습 세트는 수집 기간(약 2개월)의 마지막 하루를 제외한 모든 세션으로 구성하고, 테스트 세트는 수집 기간의 마지막 하루 동안의 세션으로 구성한다.
EVALUATION
-
평가는 세션의 이벤트를 하나씩 제공하고, 다음 이벤트의 항목 순위를 확인하는 방식으로 이루어졌다.
-
항목들은 점수에 따라 내림차순으로 정렬되며, 이 목록에서의 위치가 항목의 순위이다.
- RSC15 데이터셋에서는 학습 세트의 37,483개 모든 항목의 순위를 매겼다.
- VIDEO 데이터셋에서는 항목 수가 너무 많아 비실용적이었기 때문에, 원하는 항목을 상위 30,000개의 가장 인기 있는 항목과 비교하여 순위를 매겼다.
평가 지표
- Recall@20: 테스트 사례에서 원하는 항목이 상위 20개 항목에 포함된 비율. (절대적인 순서가 중요하지 않은 경우)
- MRR@20: 원하는 항목의 역순위의 평균으로 순위가 20을 초과하면 역순위는 0으로 설정. (추천 순서가 중요한 경우)
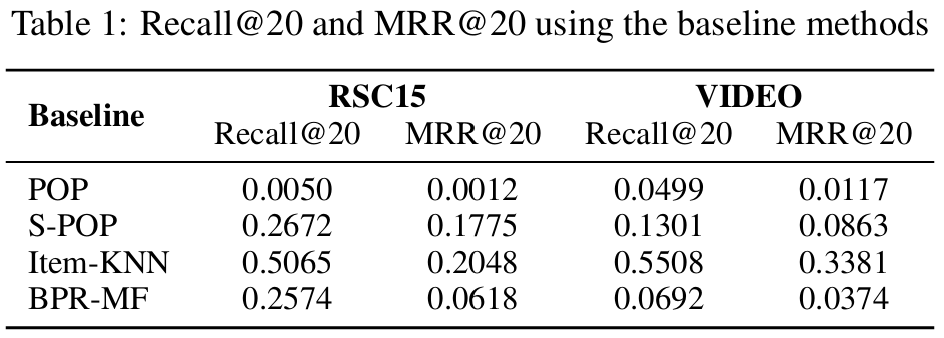
Baseline 비교
- Item-KNN이 명백하게 우수한 성능을 보였다.
4.3 RESULTS
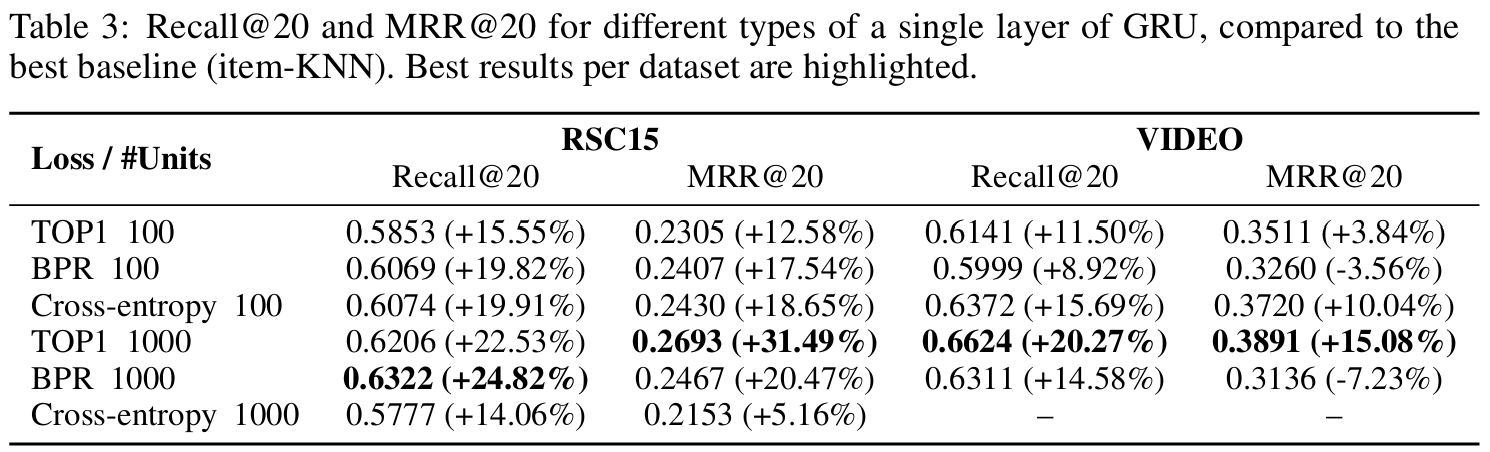
-
GRU 기반 접근법은 두 데이터 셋에서 Item-KNN에 비해 두 평가 지표 모두에서 상당한 성능 향상을 보였다.
-
은닉 유닛 수를 늘리면 Pairwise Loss(TOP1, BPR)에 대한 결과가 더욱 개선되지만, Cross-entropy의 정확도는 감소한다. 그러나 Pairwise Loss의 개선이 기존 Cross-entropy의 정확도보다 뛰어나다.
- 유닛 수를 늘리는 것이 학습 시간을 증가시키기는 하지만, GPU에서는 100 → 1000의 이동이 크게 비싸지않다.
(추천 시스템에서는 새로운 사용자와 항목이 자주 추가되기 때문에, 잦은 재학습이 필요하다) - 따라서 Pairwise Ranking Loss를 사용하는 것을 권장한다.
- 유닛 수를 늘리는 것이 학습 시간을 증가시키기는 하지만, GPU에서는 100 → 1000의 이동이 크게 비싸지않다.
-
TOP1 Loss가 두 데이터셋에서 약간 더 나은 성능을 보이며, Item-KNN에 비해 20-30%정도 정확도가 향상되었다.
