
✍ 해당 시리즈 포스팅은 미시간 대학의 EECS 498-007 강의 내용을 정리한 글입니다. cs231n 강의와 유사하여 해당 시리즈 포스팅과 겹치는 부분이 많이 있을 수 있습니다.
Learning Rate Schedules
SGD, Momentum, AdaGrad, RMSProp, Adam 모두 learning rate가 중요한 하이퍼파라미터라는 사실은 변하지 않는다. 따라서 learning rate를 정하는 데에도 다양한 방법이 있다.

learning rate가 적당히 높다면 학습 초반엔 loss가 급격히 줄어들지만 진행될수록 최적점을 찾기 힘들고, 적당히 낮다면 최적점을 찾을 순 있지만 loss값은 천천히 줄어든다.
그렇다면 위 슬라이드에서 빨간 선의 결과를 보여줄 수 있는 최적의 learning rate는 어떻게 찾을 수 있을까?
→ 처음엔 큰 learning rate에서 시작해서 점점 낮춰나가는 방법을 사용해 보자.
Step Schedule

이전 슬라이드에서 처음엔 초록 선을 따라 최적화 되다가, 파란 선과의 교차점 이후 epoch부터는 파란 선을 따라 최적화가 이루어진다고 생각하면, epoch에 따른 loss의 변화는 왼쪽 플롯과 같이 그려질 수 있다.
특정 epoch마다 learning rate에 0.1을 곱하여 구현 가능하고, 해당 epoch마다 loss는 급격히 줄어드는 형태를 보이기에 전체 플롯을 보면 위와 같이 계단 형태를 보일 수 있다. 이를 step schedule이라고 한다. 하지만 이 방식은 heuristic해서 시간이 촉박할 때 사용하기엔 어렵다는 단점이 있다.

여담으로 ResNet paper에서 볼 수 있는 error plot도 step schedule을 사용해서 계단 형식으로 나타난다.
Cosine Schedule

Initial rate인 와 학습을 수행할 epoch 두 개의 하이퍼파라미터를 통해 코사인 함수 그래프 형태로 learning rate를 감소시키는 방법이다. 애초에 학습을 하려면 epoch과 initial learning rate는 필수로 선택을 해야 하기에, learning rate scheduling 자체에서 새로운 하이퍼파라미터를 추가할 필요가 없다는 장점이 있다.
오래 학습할수록 잘 동작하는 경향이 있고, initial learning rate만 잘 정해주면 된다.
Cosine 모양은 그저 learning rate를 적절히 줄여가는 모양 중 하나일 뿐이고, 이에 따라 learning rate를 줄여가는 방법은 아래와 같은 다양한 방법들이 더 있다.
Linear Schedule

Linear Schedule은 단순히 learning rate를 선형적으로 감소시키는 방법이다. Learning rate를 선형으로 감소시키기에, initial learning rate와 전체 epoch 간 균형이 맞지 않는다면 learning_rate가 0이 될 수도 있기에, 이를 고려해서 설정하거나 대비책을 두어야 한다.
다양한 scheduling 방식이 있지만, 어떤 방식이 더 잘 동작한다에 대한 명확한 근거는 없고, 전통적으로 컴퓨터 비전에서는 cosine schedule을, NLP에서는 linear schedule을 사용한다는 것 같다.
Inverse Sqrt Schedule

Epoch이 지남에 따라 시점에서 로 나누어주는 방법이다. 그 유명한 Attention is all you need 논문에서도 쓰였다. 학습 초기에만 높은 learning rate를 가진다는 특징이 있으며, 많이 사용되진 않는다고 한다.
Constant Learning Rate

Learning rate를 단지 상수로 설정하는 것인데(그냥 scheduling을 안 한다고 보면 될 듯) SOTA 달성을 위한 것이 목표가 아닌, 단순히 빠르게 무언가를 학습할 때는 constant learning rate를 써도 괜찮고, momentum 계열이 아닌 Adam , RMSProp같이 learning rate를 보정해주는 최적화 기법을 사용할 땐 굳이 다른 scheduling 기법을 사용하지 않아도 괜찮다.
Early Stopping

Train accuracy와 valid accuracy의 차이가 점점 증가할 때 학습을 멈춤으로써 과적합이 일어나는 것을 방지하는 기법이다. 보통 코드로 구현할 땐 patience를 설정해서 validation score에 대한 업데이트가 특정 epoch 이상 발생하지 않으면 학습을 중단하도록 한다. 무조건 사용!
Choosing Hyperparameters
이제 모델의 하이퍼파라미터 선택법에 대해 알아보자.
Grid Search

탐색할 하이퍼파라미터 및 그 후보들을 선택하여 가능한 모든 조합으로 모델을 각각 학습한 후 평가하는 방식이다. 하이퍼파라미터의 수가 늘어날수록, 학습해야 하는 모델 경우의 수도 기하급수적으로 증가하기 때문에 현실성이 떨어지는 방법이다.
Random Search

탐색할 하이퍼파라미터와 범위를 설정한 후, 그 범위 사이의 랜덤 값들로 조합하여 모델 학습 및 평가를 진행한다. Grid Search보단 훨씬 많이 쓰이는 방법이다.

Grid Search는 하이퍼파라미터를 고정된 값과 간격으로 샘플링 방식인데, 이보다는 위 코드 예시로 활용하였던 특정 범위 내 uniform distribution에서 랜덤 샘플링을 하는 Random Search가 대체로 효과적이다.
→ 내 모델이 예를 들어 위 그림에서 노란색 하이퍼파라미터 보다는 초록색 하이퍼파라미터의 변화에 더 민감하다고 했을 때, Random Search는 이 초록색 하이퍼파라미터로 인해 변화하는 함수를 더 잘 찾을 수 있다. 결과적으로 더 중요한 변수에서 더 다양한 값을 샘플링 가능하다.
Steps in Hyperparameter Selection
우리에겐 막대한 양의 GPU로 학습할 기회가 거의 주어지지 않으므로, 최소한의 GPU 자원으로 하이퍼파라미터를 선택하려면 아래와 같은 단계를 거치면 좋다.

- Weight Decay를 끄고, 초기 loss(학습 한 번만 수행)의 sanity check을 진행한다.
- 학습 데이터의 매우 작은 샘플에 overfitting을 적용해본다.
- 5~10개의 미니배치(train set)에 대해서 정확도 100%를 보이도록 한다. (정규화 적용x)
- Architecture, learning rate, weight initialization 등을 조정해가며 진행한다.
- 2번에서 얻은 아키텍처를 정규화를 추가하여 전체 train set에 대한 학습을 진행한다.
- 100번 이내의 iteration에서 loss가 떨어지도록 만드는 learning rate를 찾는다.
- 보통 1e-1, 1e-2, 1e-3, 1e-4중에서 시도
- 3번에서 선택한 learning rate와 weight decay 범위 내에서 Coarse grid로 1~5 epoch정도 학습시켜본다.
- Weight decay는 0, 1e-4, 1e-5로 시도하면 좋다.
- 4번까지 얻은 setting으로 learning rate decay 없이 10~20 epoch을 학습시켜본다.
- 5번의 Learning curve를 지켜보고 이전에 얻은 하이퍼파라미터 grid를 조정한다.
- 5~6 반복
아래는 learning curve의 형태 별 의심되는 정황들이니 참고하자.

- Weight initialization이 적절하지 않은 경우

- Learning rate decay를 넣어야 하는 경우

- Learning rate decay를 너무 빨리 적용한 경우

- Train이든 validation이든 정확도가 계속해서 증가한다면, 학습을 오래 해야 한다.

- Train과 validation의 gap이 벌어지면 과적합이 발생한 것이고, regularization을 더 적용하거나 데이터 수를 늘려야 한다.

- Train과 validation의 gap이 없다는 건 underfitting이다. 학습을 오래하거나 더 큰 모델을 선택해야 한다. 또는 regularization을 줄여보자.

학습이 잘 되는지 관리할 땐 요즘엔 Tesorboard 등을 활용하거나, 가중치의 값과 업데이트 비율을 살펴보는 empirical한 방법을 쓸 수도 있다.
이제 동적으로 learning rate를 scheduling하거나 hyperparameter optimization을 모두 마쳤다면, 모델 학습 후엔 무엇을 할 수 있을까?
Model Ensembles

여러 개의 독립적인 모델을 학습 시키고, test 시에는 각 결과의 평균을 사용하는 기법이다. Final test case에서 1~2% 더 나은 결과를 얻을 수 있다.
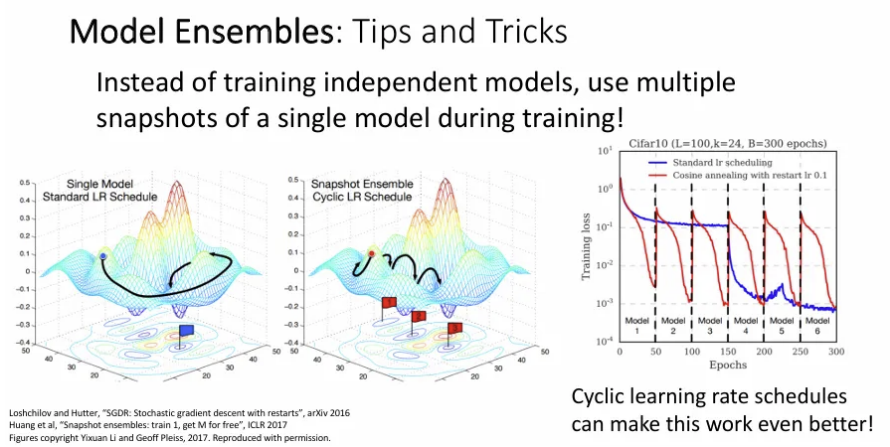
앙상블 중에는 굳이 여러 개의 독립적인 모델을 학습 시키는 것이 아닌, 하나의 모델 학습 때 여러 체크 포인트를 저장 후 그 체크 포인트를 평균 내는 방법이나, Batch norm 때 parameter의 지수 평균과 분산을 유지하고 테스트 시 이를 사용하는 Polyak Averaging 방법도 있다.
Transfer Learning
Overfitting이 일어날 수 있는 상황 중 하나는 충분한 데이터가 없을 때인데, 충분한 데이터가 없어도 기존에 거대한 데이터 셋에서 학습된 모델을 우리가 가진 새로운 데이터 셋에 적용하는 것이다. Image Classification task 뿐 아니라 아주 다양한 task들에 방대하게 사용 가능

기존에 특정 CNN Architecture에 ImageNet으로 1000개의 카테고리를 분류하는 학습을 한 후 매우 적은 데이터의 10 종의 강아지 분류를 하고자 한다. 가장 마지막의 Fully Connected Layer는 최종 feature와 class scores 간의 연결인데 이는 4096 x 1000 행렬을 4096 x 10으로 바꿔주고 초기화 시킨다. 위 이미지의 경우 마지막 FC-4096차원의 벡터를 general feature representation으로 사용하는 것이다.
그리고 이전의 나머지 layer들의 가중치는 freeze 한 후 학습을 진행하면 마지막 layer만 갖고 학습을 시켜주는 것과 같다.
이는 image classification task 뿐 아니라, 기타 다양한 computer vision tasks에서도 잘 동작할 수 있다.

만약 우리에게 주어진 데이터가 좀 더 크다면, 전체 네트워크를 모두 얼리지 않고 일부는 업데이트를 허용해서 학습할 수도 있다(Fine-Tuning). 말 그대로 미세 조정 단계이기 때문에, 이 때 learning rate는 기존보다는 낮춰서 사용한다.

Transfer learning에 사용되는 pre-trained CNN architecture의 성능 자체가 곧 transfer learning 성능에 중대한 영향을 끼치기 때문에, CNN architecture의 발전에 따라 자동으로 많은 downstream tasks의 성능도 좋아지게 되었다. (ImageNet에 잘 동작할수록 대체로 다른 것도 잘 함)

이를 증명하듯 pre-trained CNN architecture를 성능 좋은 최신 것을 사용한 detection architecture일 수록 COCO object detection에서 좋은 성능을 보였다.
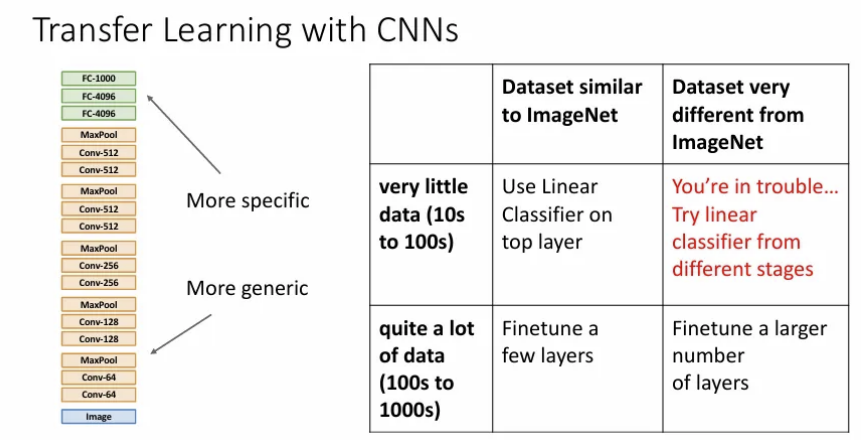
CNN으로 transfer learning을 적용하는 경우 데이터 셋의 크기와 종류에 따라 위 가이드를 따라 수행해보자.

위와 같이 다양한 task에 대한 architecture에서 이미지면 이미지, 텍스트면 텍스트에 맞게 사전 학습된 모델들이 backbone으로서 자리 잡고 있는 것을 확인 가능하다.

데이터 셋의 사이즈가 작다면 Pre-training + finetuning은 처음부터 학습시키는 것보다 훨씬 빠르면서 더 좋을 수 있다는 점은 기정 사실이다.
하지만 위 논문에서는 데이터 셋이 큰 경우에는 처음부터 학습하는 방식이 더 잘 동작할 수도 있다고 말한다. 그래도 효율 면에서는 Pre-training + finetuning을 활용하는 것이 낫다.
Distributed Training
AlexNet에 대해 배울 때, 두 대의 gpu를 활용하여 학습했던 점을 떠올려보자.

만약 위 슬라이드처럼 여러 대의 gpu에 여러 layer들을 분할해서 할당한다면 어떨까?
→ 한 gpu에서 초반 layer를 학습하는 동안 나머지 gpu는 쉬는 상황이 발생한다.

그렇다면 gpu 별로 모델을 병렬로 분리해서 학습한다면 어떨까?
→ 실제로 AlexNet을 학습시켰던 방식이지만, 여러 대의 gpu를 동기화하려면 activations와 grad activations를 서로 주고받아야 하기 때문에 매우 비싸다.

그 대신, data를 병렬화하여 gpu에 분산시켜 학습하는 방법이 있다.
- 개의 image가 있는 batch를 입력 받는다.
- 각 gpu에 모델을 복사한 후 image를 나눠서 할당하여 각각 학습하면, 각 gpu에서 독립적으로 forward pass 및 backward pass를 진행한다.
- 그 후 두 gpu끼리 통신하여 loss gradient를 교환하여 더하고, 업데이트한다.

만일 하나의 gpu로 batch size , learning rate 로 네트워크를 잘 학습할 수 있었고, 이를 대의 gpu를 활용하여 batchsize를 배 늘려서 학습하려면 그만큼 learning rate도 배 늘려서 학습해야 원활히 학습 가능하다.

하지만 처음부터 너무 높은 learning rate를 잡게 되면 첫 iter에서 loss가 폭발하게 되는 경우가 있다. 그래서 위처럼 learning rate를 0부터 선형적으로 증가 시킨 다음 scheduling을 적용하는 learning rate warmup 방법을 많이 사용한다.
Reference
유튜브 강의: https://www.youtube.com/watch?v=qcSEP17uKKY&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=4
PDF: https://web.eecs.umich.edu/~justincj/slides/eecs498/FA2020/598_FA2020_lecture11.pdf
