
✍ 해당 시리즈 포스팅은 미시간 대학의 EECS 498-007 강의 내용을 정리한 글입니다. cs231n 강의와 유사하여 해당 시리즈 포스팅과 겹치는 부분이 많이 있을 수 있습니다.
Intro

오늘은 다양한 computer vision tasks 중 하나인, object detection에 대해서 자세히 알아보자.
Object Detection

그동안 배웠던 image classification task 같은 경우, 단일 RGB 이미지가 주어지면 해당 이미지의 클래스를 맞추는 문제였다면, object detection에서는 단일 RGB 이미지를 받았을 때, 탐지되는 다양한 객체의 클래스를 맞힐 뿐 아니라, 그 객체의 위치 정보를 표현하는 bounding box까지 리턴해주어야 한다.

Object detection은 classification 문제에서 한 단계 더 나아가 생각해야 하는 문제들이 발생한다.
-
Multiple outputs
→ Image classification과 다르게, detected object 수가 1로 고정이 아닌, 가변적일 수 있어야 한다.
-
Multiple types of output
→ Category label과 bounding box 두 개의 다른 종류의 output을 같이 낼 수 있어야 한다.
-
Large images
→ 저해상도에서도 많이 다뤘던 image classification과는 달리, 높은 해상도의 image도 다룰 필요가 있다.
Single object to Multiple objects
우선 여러 객체가 아닌, 단일 객체에 대해 object detection의 동작 과정을 살펴보자.

우선 해당 객체의 class label을 예측할 땐, 기존에 보았던 CNN architecture와 유사하게 동작한다.
→ CNN architecture를 통해 이미지의 feacture를 뽑고, 이를 FC layer 혹은 max pooling을 거쳐 최종 class scores를 도출하고, 이를 통해 label을 예측하는 것 까지는 같다.

이번엔 해당 객체의 bounding box를 예측하는 분기를 살펴보자.
→ 이도 마지막 feature vector를 뽑는 것 까지는 똑같이 진행되지만, 이후 bbox의 정보인 x, y, w, h에 대해서 각각 regression을 진행하도록 학습된다.

이 때 class classification 과 bbox regression 각각의 loss를 잘 조합해서 새로운 하나의 loss를 만들어야 하는데, 이를 multitask loss라고 한다. 실제로 하나의 객체에 대해서 bounding box regression 을 진행할 때, 위 방법은 대체로 잘 동작한다.

하지만, 다중 객체를 모두 탐지해야 하는 경우, 이미지 별 탐지해야하는 객체 수가 각각 달라서 위 방법으로는 지금처럼 일반적으로 동작시킬 수 없다.
Sliding Window

Multiple objects를 탐지하기 위한 간단한 방법이다. 똑같이 CNN classifier를 활용하는데, 한 이미지에서 sub-windows에 대한 분류를 각각 모두 수행한다. 이 때 한 가지 다른 점은, 해당 윈도우에서 어떤 객체도 없는 경우가 대부분일 것이기에, 예측할 클래스에 background도 추가해야한다는 점이다.

위와 같은 sub-window에서의 분류 결과는 ‘dog’ 일 것이고, 이 sub-window 자체가 bounding box가 될 수 있다.

이는 매우 간단해보이는 방법이지만, 크기의 전체 이미지 내부에서 몇 개의 possible box들이 생기게 될 지 생각해보자. box size가 특정 작은 값으로 고정되어 있어도 충분히 많은 양의 sub-windows가 생길텐데, 위 이미지의 경우 강아지와 고양이의 bounding box 크기가 다르다는 점을 생각한다면, box size를 다양하게 늘려서 고려해야 한다. → 실현 불가..
Region Proposals

또 다른 전통적인 방식으로, 딥러닝을 활용하지는 않고 전통 신호 처리 방식을 활용한다. 이미지 내에서 blobby(뭉텅진) 한 곳들을 찾아서 객체가 있을 법 한 1000개의 Bbox를 제공해준다.
이 중에서도 Selective Search라는 알고리즘은 CPU를 통해 3초 내로 2000개의 Bbox를 얻을 수 있다고 한다.
R-CNN
Region Proposals을 얻어서 Region Proposal Network를 통과시키는 R-CNN 시리즈에 대해서 알아보자.

- 이미지가 주어지면 Region proposal(ROI)을 얻기 위해 Region Proposal Network를 수행한다. Selective Search라는 고정된 알고리즘을 통해 2000개의 ROI를 얻는다.

- 추출된 ROI로 CNN Classification을 수행할 때 Input size를 맞춰줘야 하기 때문에 ROI들을 같은 크기로 Warping 해준다.

- 각 ROI들을 CNN을 통과시켜서 각각 분류를 적용한다. R-CNN에서는 SVM을 사용하였다. 각각의 Conv Net은 모두 가중치를 공유

- 이 때 region proposal과, 그 안에서 감지된 객체의 전체 모습을 딱 맞게 포함하는 bbox 자체는 당연히 완벽히 일치하지 않을 수 있다. 따라서 이를 보정하기 위한 과정을 거친다.

Test-time 시 동작 순서는 아래와 같다.
- 하나의 RGB 이미지를 입력 받아서 2000개의 region proposals를 계산
- 각 region proposals를 224x224로 변환하고, 각각 독립적으로 CNN에 통과시켜 class score와 bbox transform을 예측
- 2000개 region proposals에서 구한 class score를 다양한 방식으로 소수 K개의 proposals만 남김
- GT box와 비교해서 test 성능을 판단
Metrics
이렇게 탐지한 박스를 Ground Truth와 비교하는 방법들을 알아보자.
Comparing Boxes: Intersection over Union (IoU)


IoU는 Jaccard similarity나 Jaccard index라고도 불리는 성능 지표로, 우리가 예측한 area와 Ground Truth area의 합집합을 분모로, 교집합을 분자로 하여 결과를 비교하는 방법이다. 즉, 합집합에 대한 교집합의 비율이다.
두 박스가 아예 일치하지 않을 경우 0이 되고, 완벽히 일치할 경우 1이 되므로 0부터 1사이의 값을 가질 수 있다.

IoU 값이 0.5를 넘는다면 어지간히 잘 맞춰 예측을 했다고 볼 수 있고, 0.7이 넘으면 약간의 error는 있지만 꽤 잘 예측을 했다고 보며, 0.9를 넘긴다면 거의 완벽히 잘 맞춘 것이라고 본다.
Overlapping Boxes

하지만 보통 R-CNN같은 object detection 기법들은 동일 class에 대해서 많은 output bounding boxes를 출력하게 되는데, 이렇게 겹치는 박스를 제거하기 위한 메커니즘이다. 예를 들어 위처럼 다양한 출력 박스들이 생성되면, 우리는 왼쪽 강아지에 대해서는 파란 박스만, 오른쪽 강아지에 대해서는 보라색 박스만 남기고 싶을 것이다.

이를 간단히 greedy하게 해결하는 방법인데, 아래와 같은 순서로 진행된다.
- 하나의 클래스에 대한 bounding boxes의 목록에서 가장 높은 classification score를 갖는 bounding box를 선택하고 이를 목록에서 제거 후, final boxes에 추가 (위 그림에선 파란 박스)
- 선택된 bounding box를 bounding boxes의 모든 box들과 IoU를 계산하여 threshold를 넘기는 박스는 bounding boxes 목록에서 제거
- Bounding boxes 목록에 아무것도 남아있지 않을 때까지 위 과정 반복
※ 하지만 NMS의 경우 여러 객체들이 많이 겹쳐있는 경우 잘 동작하지 않을 수 있다.
Evaluating Object Detectors: Mean Average Precision (mAP)
Object detector가 전반적으로 test set에 대해서 얼마나 잘 탐지를 수행하는 지를 평가하는 전반적인 성능 지표이다.

- Object detector를 모든 test-set image에 대해 적용하여 각 score를 얻는다. (NMS를 통해 불필요한 박스는 제거) 여기까지 진행하게 되면 test의 각 이미지에 대하여 감지된 박스가 여러 개 남고, 각 박스에는 각 클래스에 대한 classification score가 들어있다. (R-CNN에서는 각 박스 별 classification 진행하니까)
- 각 카테고리에 대하여 PR곡선 아래 영역을 의미하는 Average Precision을 구하게 되는데, 자세히 살펴보자.

위 슬라이드에 파란 박스들은 전체 test set 모든 이미지에서 detector가 감지한 모든 “dog” detection들을 의미하고, 주황 박스들은 전체 test set 모든 이미지에 존재하는 모든 ground truth “dog” 박스들을 의미한다. 우선 detector가 탐지한 “dog” 클래스로 분류된 bounding box들을 classification score를 기준으로 내림차순 정렬한다.

가장 높은 classification score를 갖는 bounding box부터 ground truth box들과 IoU를 비교하여 일정 threshold를 넘기면 positive로, 넘기지 못하면 negative로 간주한다. 참고로 이 때 ground truth인 주황색 박스들은 학습 데이터 셋 전체 이미지들에서 “dog” 클래스를 갖는 GT box 모두를 의미한다.

그리고 여기서 precision과 recall을 각각 구하는데, 말로 설명해보면 아래와 같다.
- True positive(TP) : 맞다고 분류했고, 실제로도 맞음. 즉, IoU ≥ threshold
- False positive(FP) : 맞다고 분류했지만, 실제로는 맞지 않음. 즉, IoU < threshold
- False negative(FN) : 아니라고 분류했지만, 실제로는 맞음. 아예 detect 하지 못한 경우
- True negative(TN) : 아니라고 추측했고, 실제로도 아님.

이제 가장 높은 class score를 갖는 bounding box에서 precision부터 구해보자. 이 때 precision의 분모값은 모두 count를 할 때마다 누적된다고 보면 된다.
- 가장 먼저 첫 번째 bbox의 precision을 구해보면, 탐지된 박스는 하나이므로 precision의 분모는 1이 되고, 이는 두 번째 GT box와 비교하여 positive로 예측되고, 실제로도 positive이다. 따라서 분자는 1이 된다. → 현재 precision은 1
- 이제 recall을 구해보면, 전체 GT box는 세 개이므로 분모는 3이고, 실제로 매칭된 박스는 하나이므로 분자는 1이 된다. → 현재 recall은 1/3
여기까지 됐다면 현재까지 recall에 대한 precision 값을 찍어보자.

이번엔 두 번째로 높은 classification score를 갖는 bounding box와 GT box들을 비교해보면,
- Detected box가 하나 더 증가했기 때문에 precision에서 분모는 하나 증가하고, true positive 값도 하나 증가하여 precision은 여전히 1이 된다.
- GT box 수는 그대로이고, 매칭된 TP 값이 하나 증가했으므로 분자만 1 증가하여 recall은 2/3가 된다.
그리고 현재 recall에 대한 precision도 점을 찍는다.

그리고 만약 3,4번째 bounding box와 매칭되는 GT Box가 없었다면,
- Detected box는 두 개 늘어났지만 TP는 그대로이므로 precision은 0.5까지 줄어든다.
- 마찬가지로 TP가 늘어나지 않았으므로 recall도 그대로 2/3
해당 값들 또한 점으로 찍어 표시한다.

마지막 bounding box에 대하여 GT box와 매칭이 된다면,
- Precision의 분모와 분자 모두 1씩 증가하여 최종 precision은 0.6이 된다.
- TP가 하나 증가했으므로 분자 1 증가하여 최종 recall은 1이 된다.
이제 여태껏 찍힌 recall에 대한 precision 값의 점들을 꺾은선으로 잇게 되면 이것이 바로 PR curve(Precision-recall 곡선)이 된다.

그리고 이 PR curve의 아래 구역의 넓이를 구하면 그것이 Average Precision, 즉 AP가 되고,

이를 모든 클래스에 적용하여 각각의 클래스에 대한 AP값을 평균낸 것이 바로 mAP(mean Average Precision)이라는 전체 평가 지표가 되는 것이다.
만약 한 클래스에 대한 AP 값이 1이 되려면, 탐지된 bounding box가 GT box에 모두 1대1 매칭이 되어야 한다. (Detected box 각각이 하나의 GT box와 IoU값이 충분히 크면서, False positive인 박스도 나와서는 안 됨)

실제로 사용할 땐, IoU threshold를 다양하게 설정해서 모두 평가해야 한다.
Fast R-CNN

다시 R-CNN으로 돌아와보자. 이제 R-CNN의 동작 원리 및 평가 지표에 대해서 알아보았는데, R-CNN의 치명적 단점이 있다. 바로 Region proposals를 뽑고 각각을 위해 CNN forward pass를 2000번 정도 수행해야 하기 때문에 시간이 오래 걸린다는 점이다. 이를 해결하기 위해 warping과 CNN의 순서를 바꾼것이 바로 Fast R-CNN이다.

Fast R-CNN은 input image를 받아서 CNN을 먼저 거쳐서 image features를 얻게 된다.

그렇게 생겨난 feature map 상에서 selective search 방법으로 region proposals를 얻는다. 이렇게 되면 CNN의 feature를 여러 ROI들이 공유할 수 있다. 이제 여기서 얻은 region proposals를 resize한다.

그 후 각각을 작은 CNN에 통과시켜서 똑같이 output을 얻는다. 대부분의 계산이 가장 아래의 backbone network에서 수행되고, per-region network는 매우 작아서 결과가 훨씬 빠르다고 한다.

AlexNet을 backbone으로 사용하게 된다면, image feature를 추출하는 layer까지는 제일 아래 backbone에 해당되고, 각각 2000개의 ROI에 대해서 수행해야 하는 연산은 classification을 위한 마지막 두 개의 FC Layers 및 BBox regression을 위한 layer로 구성된다.
이 때 각 ROI는 같은 fully connected layer에 입력된다. (가중치 공유됨)
Cropping Features: RoI Pool
그렇다면 Fast R-CNN의 Image feature에서 cropping은 어떤 방식으로 진행될까?

최종으로 생성된 feature의 shape이 512x20x15라면, 먼저 기존 이미지에서 region proposal을 구한 후, 이를 feature map에 맞춰 mapping하는 방식을 사용한다.

하지만 이는 feature map의 grid에 완벽히 mapping되지 않을 수 있으므로, grid cells에 맞춰서 snap (반올림)하는 과정이 필요하다.

그리고 2x2 정도의 sub regions로 나눈 후 각각의 sub region에 대하여 max pooling을 진행한다. 이 방법을 통해 각각 다른 사이즈의 region proposals 에 대해서도 같은 사이즈의 region features를 얻을 수 있다.
하지만 snapping 과정에서 약간의 정렬 오류가 생길 수 있고, 일부 sub-region 크기가 너무 크거나 작아지는 현상이 발생할 수 있다. 또한, RoI pooling은 좌표가 항상 정해진 grid cell에 snap되어 좌표 값이 미세하게 변해도 gradient가 변하지 않게 되고, 이에 따라 bounding box regression 학습 시 좌표에 대한 미분이 불가능하여 backpropagation이 불가능하다.

이러한 이유로 RoI Align을 대신 사용하는데, bilinear interpolation을 사용하여 좌표를 정확하게 보존하는 방법이라고 보면 될 것 같다. RoI pooling의 한계점을 극복한 방법인데, 일단 수업에서도 시간 관계상인지 슬라이드엔 설명이 있지만 설명을 거의 생략하고 넘어가기 때문에 본 포스팅에서도 여기까지만 언급하고 넘어간다.

Fast R-CNN의 속도를 vanilla R-CNN과 비교하여 살펴보면 훨씬 빠른 것을 확인 가능하다. 하지만 오른쪽 그래프처럼 추론 시간에서 region proposal 시간과 이를 제외한 시간을 구분 지었을 때, 이 몇 초 안되는 시간 내에서도 region proposals 과정이 매우 큰 비중을 차지하는 것을 확인할 수 있다.
Faster R-CNN

이렇게 휴리스틱한 selective search 알고리즘에 기반한 region proposals 또한 CNN으로 학습 가능하도록 하여 시간을 더 더 단축시키자는 아이디어에서 탄생한 것이 Faster R-CNN이다. 닉 값 제대로 한다고 느껴지는 R-CNN 시리즈이다.
feature map을 만드는 backbone network의 뒤에 Region Proposal Network(RPN) 이라는 네트워크를 추가하여 feature map으로부터 region proposals를 예측하고자 하는데, 그 이후론 Fast R-CNN과 같다.
Region Proposal Network (RPN)

Fast R-CNN처럼 backbone network를 통해 얻은 image features에서 고정된 크기의 anchor box를 모든 point에 대해서 배치한다.

그 후 학습 시, 각 포인트에 할당된 anchor box가 object를 포함 하는지를 예측하는 이진 분류를 학습하도록 한다.

하지만 이렇게 해서 얻은 positive box(anchor box)라고 해서 무조건 해당 object에 완벽히 fit 하는 것은 아니다. (연두색 anchor box는 고양이 객체를 담긴 하지만, 꼬리까지 포함하진 못한다.)
따라서 해당 anchor box(연두색 박스)를 object box(노란색 박스)로 변환하는 과정까지 학습하게 된다.

그리고 하나의 고정된 사이즈의 anchor box만으로는 모든 종류의 object를 잘 맞추기 쉽지 않기 때문에, feature map의 각 포인트에서 개의 다양한 anchor box를 사용한다. 이러한 설정들은 모두 하이퍼파라미터가 된다.
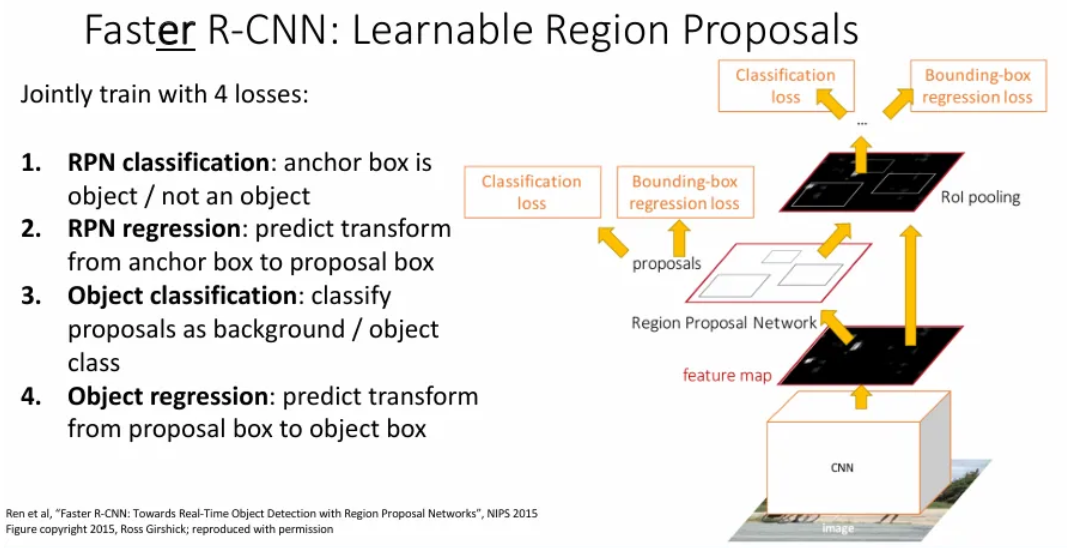
그렇게 Faster R-CNN에서 사용되는 loss는 총 4가지나 된다.
- RPN에서 anchor box에 object가 있는지 없는지를 예측하는 classification loss
- RPN에서 anchor box를 object box로 변형하는 regression loss
- RoI pooling까지 거친 후 얻은 proposals의 클래스 및 배경(인지) 예측하는 classification loss
- Proposal box를 object box로 변형하는 object regression loss
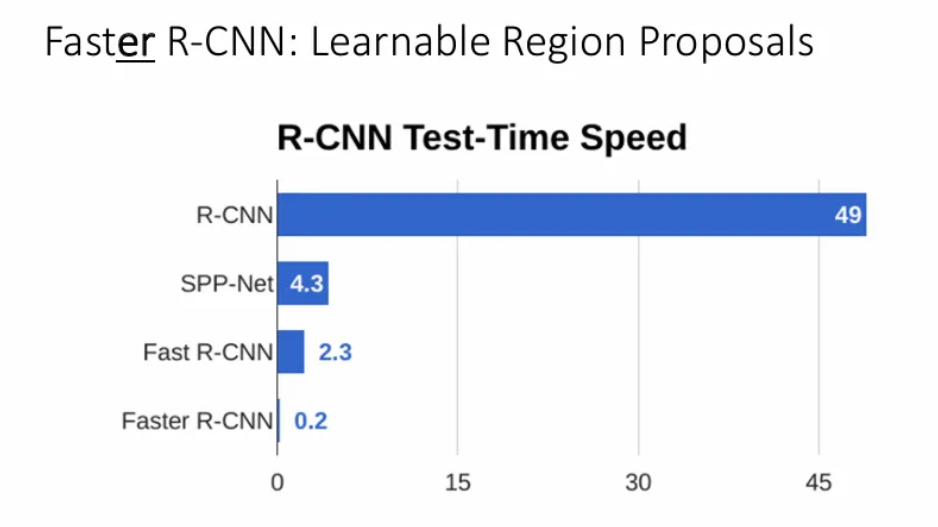
이렇게해서 selective search에서 발생하는 병목까지 해결이 되었다.

그렇게 Faster R-CNN은 두가지 단계로 나뉜다.
- 각각의 이미지에 대해서 backbone network를 거쳐 image feature를 추출한 뒤, 그 위에서 region proposal network 적용
- 1번에서 얻은 region proposals를 RoI pooling / align을 통해 크기를 맞추고, object class 예측 및 bounding box regression
그렇다면 만약 두 반째 stage를 거치지 않고 첫 번째 stage에서 다 해결할 순 없을까?

이를 적용한 방법을 single-stage object detection이라고 하는데, RPN에서 anchor box에 객체가 있는지/없는지에 대한 이진 분류를 수행하지 않고, 여기서 바로 객체의 카테고리 자체를 예측하는 것이다.
때로는 각 카테고리 별 다른 box transform을 예측하도록 학습하는 category-specific regression을 사용하기도 한다.
수업을 정리하면서 얼핏 드는 생각을 정확히 꼬집어 주셨다..
Object Detection: Lots of variables!

Object detection을 수행하는 데 있어서 매우 다양한 선택권이 있는데, 이에 대한 인사이트가 필요하다면 참조되어있는 논문을 읽어보도록 하자.

그리고 위 그림은 강의가 진행되는 시점인 2019년을 기준으로 업데이트 된 그림이다.
그림을 보기만 해도 각 모델 별 경우의 수에 대해서 정말 많은 실험을 돌렸을 흔적이 보이고, 포스팅을 작성하는 현재 시점은 2025년인데 얼마나 업데이트가 되었을 지 상상이 가질 않는다.
Reference
유튜브 강의: https://www.youtube.com/watch?v=qcSEP17uKKY&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=4
PDF: https://web.eecs.umich.edu/~justincj/slides/eecs498/FA2020/598_FA2020_lecture15.pdf
