
✍ 해당 시리즈 포스팅은 미시간 대학의 EECS 498-007 강의 내용을 정리한 글입니다. cs231n 강의와 유사하여 해당 시리즈 포스팅과 겹치는 부분이 많이 있을 수 있습니다.
Review

지난 시간까지 Linear classifier의 geometric, visual viewpoint를 살펴보면서, 간단하긴 하지만 그만큼 함수 유형이나 성능이 우리가 원하는 만큼 나오긴 힘들다는 점을 살펴보았다.
만약 data space 상에서 클래스 별 샘플 feature들의 위치가 왼쪽 그림과 같다면, 직선 하나를 긋는 것 만으로는 완벽한 분류를 해낼 수 없다. 이런 한계들을 어떻게 극복할 수 있을까?
Feature Transforms
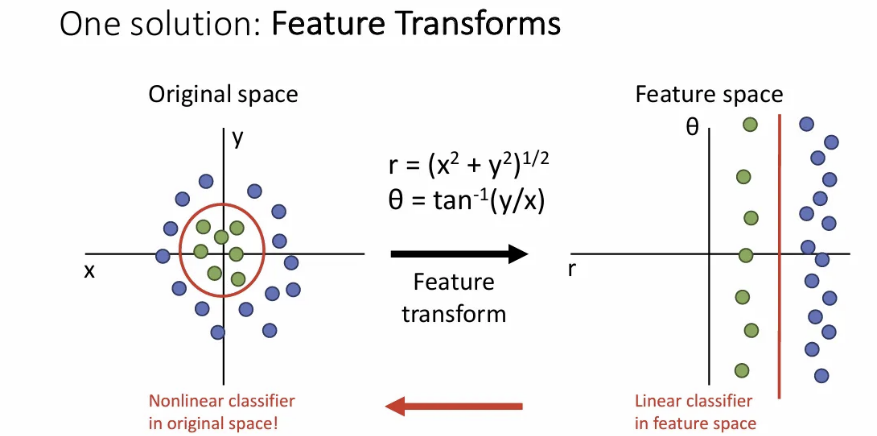
첫 번째로, feature를 변형시키는 Feature transform 방법이 있다. 데이터의 feature 자체를 분류에 적합하도록 변형시키는 방법이다.
왼쪽 그림처럼 original space 상에서는 원과 같은 비선형 분류기를 통해 완벽히 분류될 수 있던 데이터들에서 space 자체를 transform하여 오른쪽과 같이 만들게 되면, 변형된 space에서는 직선 하나 만으로도 각 샘플들을 훨씬 정확하게 분류할 수 있다.
이렇게 데이터에 적절한 변환을 선택해서 적용해주면, linear classifier의 한계를 극복해볼 수 있다. Feature transform은 컴퓨터 비전 뿐 아니라 일부 하위 도메인들에서도 널리 사용되고 있다.
Color Histogram
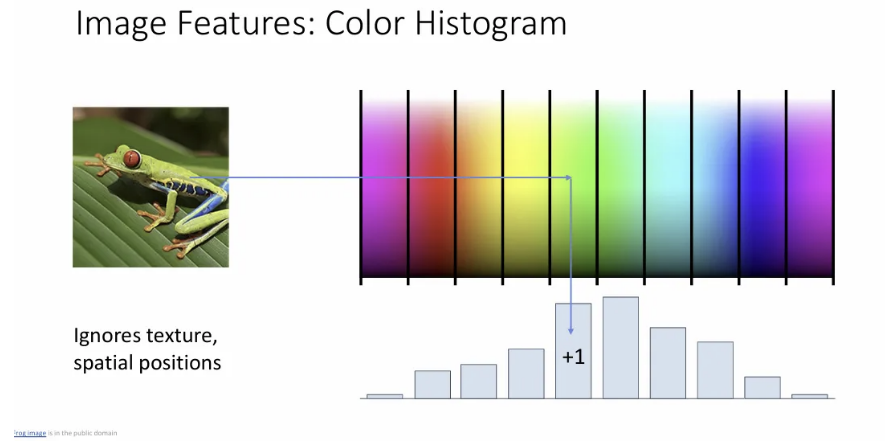
RGB feature space를 여러 개의 bin으로 나누고, input image에 대한 각 픽셀의 RGB값을 히스토그램의 대응되는 bin에 위치시키고 count한다.
단순히 input image의 색상 빈도만 활용하기 때문에 spatially invariant한 특징을 갖게 되기 때문에 개구리가 어느 위치에 있든 결과는 거의 변함이 없다.
HoG

Histogram of Oriented Gradients의 약자로 color histogram과는 달리 모든 색상 정보를 버리고 local edge 방향과 강도에만 집중한다.
예를 들어서 빨간 박스 지점은 강한 대각선 모서리(strong diagonal edges)가 있고,
파란 박스 개구리 눈 지점은 모든 방향에 edge가 있고, blurry한 노란 박스 지점은 edge가 거의 표현되지 않는다.
Color histogram이나 HoG같이 feature representation을 사용하는 경우 모두 사용자가 해당 feature representation을 통해 포착하고자 하는 것과, 적절한 feature transform을 설계하는 방법을 요구한다.
Bag of Words
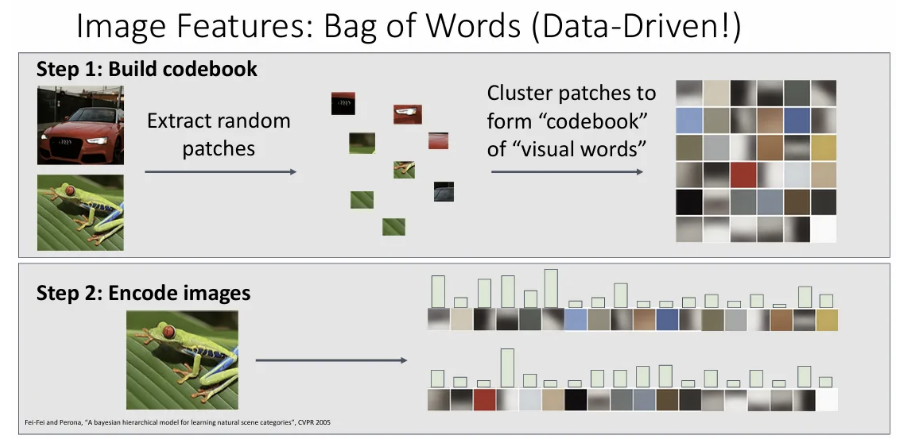
Data-Driven 방식으로, 큰 학습 데이터 셋에서 각각 random patch들을 추출하고 클러스터링하여 “codebook” 또는 “visual words”를 만들어낸다. 이를 통해 많은 학습 데이터 셋에서 흔히 관찰되는 feature structure를 통해 visual word representation을 학습하고자 한다.
학습이 끝난 후엔 input image를 받아서 해당 이미지에서 각 visual words가 얼마나 존재하는지를 히스토그램으로 표현한 후 이를 분석한다.
사용자가 feature representation에 대한 설계를 하지 않아도 전체 데이터로부터 codebook은 학습이 되기 때문에 훨씬 유연한 방식이다.
Feature Combination
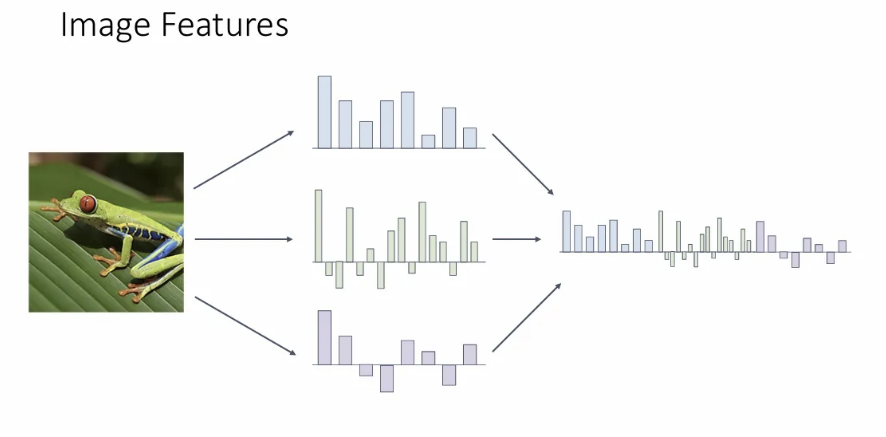
더 나아가, Input image에서 feature를 다양한 방식으로 추출한 후 이를 concat하여 하나의 새로운 long feature vector로 만드는 방식도 많이 쓰였다. 위에서 살펴본 세 가지 방법으로 얻은 feature들을 모두 고려할 수 있게 된다.
Image Features vs Neural Networks
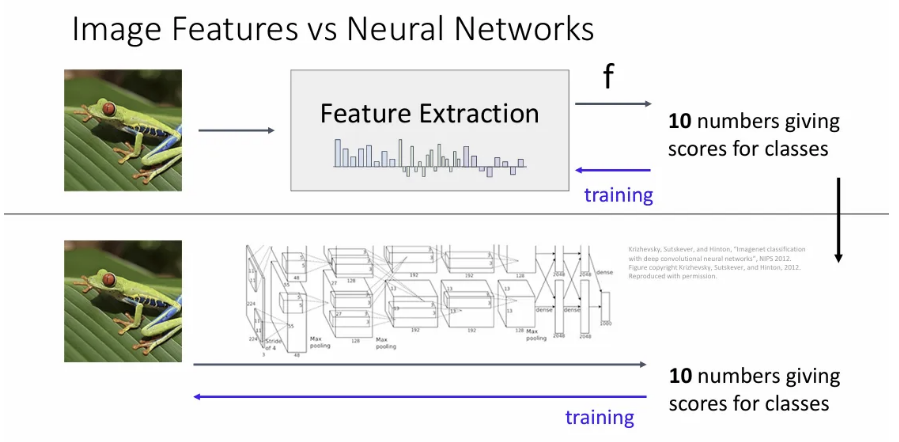
이를 머신러닝 파이프라인 관점에서 살펴보면, 결국 분류를 위해서는 사용자가 직접 feature extraction 단계에 직접 개입을 해야 했다. Bag of words에서도 마찬가지로, feature extraction을 잘 하기 위한 학습을 진행할 뿐이지, 최종 분류 성능을 높이기 위해 직접적으로 튜닝을 하진 않는다.
이런 motivation에서 나온 아이디어가 neural networks이고, feature extraction을 image classification과 연결지어 classification score를 maximize하도록 최적화는 end-to-end 파이프라인을 구축하고자 한 것이다.
Neural Networks

기존의 익숙한 linear classifier는 형태와 같이 input column vector 와 learnable weight matrix , 마지막으로 bias term인 로 이루어져 있다.

이제 간단한 신경망 구조(Two-layer)를 보자면, 기존 linear classifier 구조와 크게 다르진 않고 learnable matrix와 learnable bias term이 각각 두 개로 늘어났다. 첫 번째 matrix인 는 차원의 input vector 를 받아서 차원으로 output을 뱉게 되는데, 이 중간 output을 hidden layer라고 한다(그래서 차원으로 표기) 그리고 이 hidden layer를 input으로 받아 곱해져서 차원의 벡터를 뱉도록 하는 learnable matrix가 가 된다. (과 는 각 layer의 bias term)
중간에 max 연산을 해주는 부분은, 보통 한 개의 layer를 거칠 때마다 activation function을 적용해주는데, 그 중 ReLU라는 function을 적용해 준 것이다. (뒤에서 자세히)
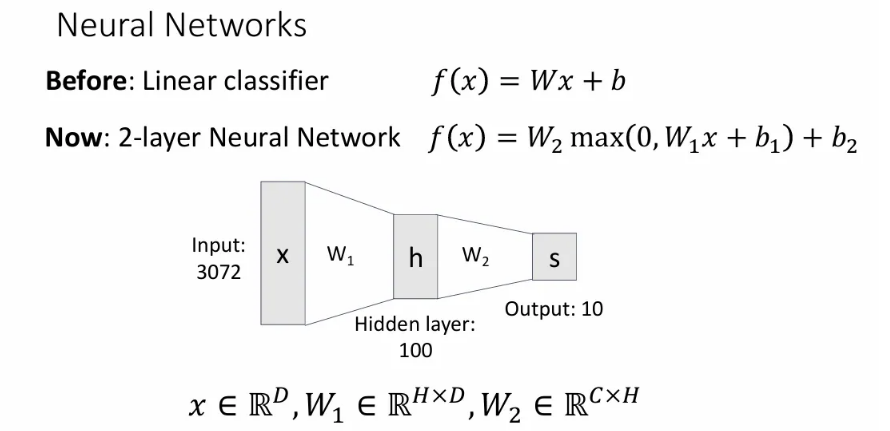
이제 이 two-layer neural network를 예시를 들어 시각화 해 본 것인데, input vector인 의 길이는 3072 (아마 32x32x3을 펼친 듯)이고, 수식에서 를 의미한다. 이후 크기의 과 곱해져서 길이 100의 hidden layer 가 만들어지는데, 따라서 는 100이라고 생각하면 된다(그림에선 bias term과 activation function은 굳이 표현하지 않았다). 그리고 마지막으로 를 와 곱하여 최종 클래스들의 score를 갖는 가 output이 된다. 여기서 의 크기는 인데, CIFAR10 데이터를 예시로 들었기 때문에 그림에서는 10이 쓰였다고 보면 된다.
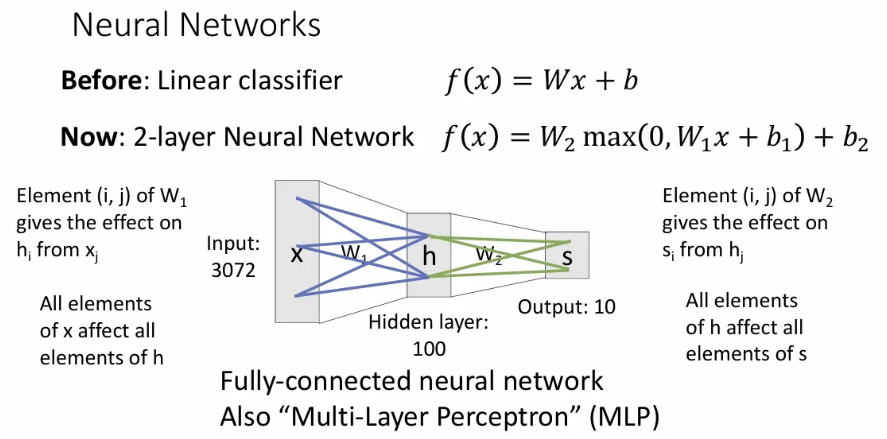
여기서 각 weight matrix 는 이전 layer가 다음 layer에 얼마나 영향을 끼칠 지를 나타내는데, 의 (i, j) 번째 값은 가 에 얼마나 영향을 끼치는 지를 의미한다.
이렇게 각 layer끼리 모든 값이 연결된 dense connectivity 패턴의 신경망을 Fully connected neural network, 또는 Multi-layer perceptron(MLP) 라고 한다.
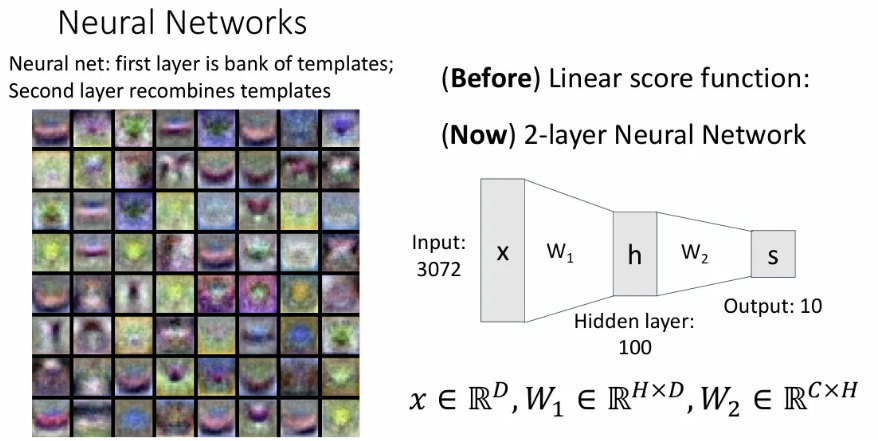
Two-layer neural network에서 첫 번째 가중치 행렬인 역시 출력()에 대한 하나하나의 템플릿을 학습하게 되는데, 이 첫번째 layer는 클래스 별 구분되는, 어떤 구조적인 템플릿을 학습하게 된다(그래서 각 템플릿이 어떤 클래스 형태인지 인간이 알아보기는 쉽지 않다). 이후 두 번째 layer에서는 이 템플릿들을 다시 조합하게 된다.
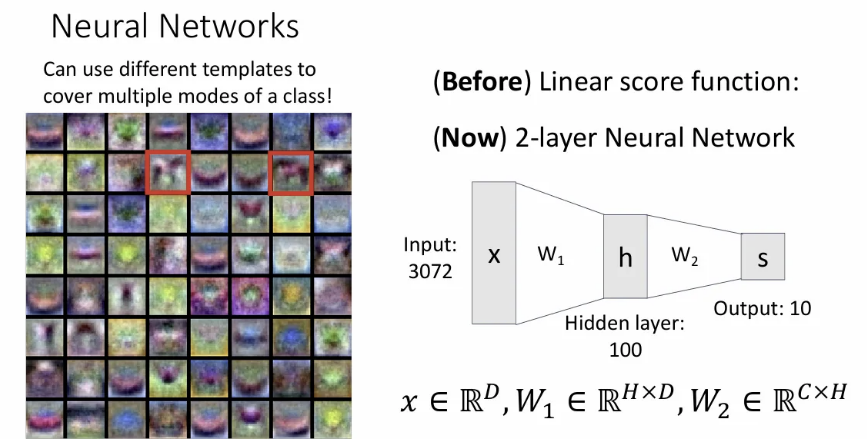
위에서 박스 친 두 개의 템플릿을 보면, 알아보기 쉽진 않지만 하나는 한 방향을 바라보는 말이고, 또 하나는 그 반대 방향을 바라보는 말의 형태이다. 즉, 한 클래스에 대응하는 여러 개의 템플릿을 학습 가능하고, 이를 두 번째 layer에서 합쳐주는 것이다. 이를 Distributed representation(분산 표현) 이라고 한다.
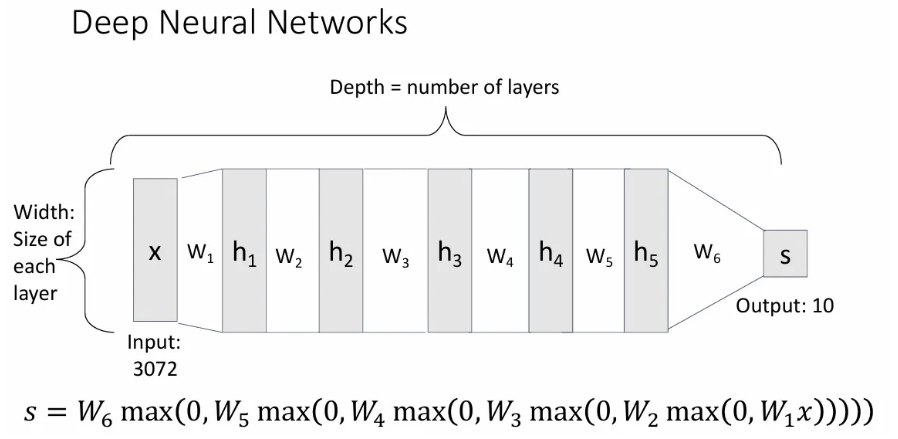
이 같은 방식으로 layer를 두개, 세개, 네개.. 깊게 쌓아나가는 것이 바로 Deep Neural Network가 되고, 당연히 층이 늘어날수록 learnable matrix 수는 그만큼 늘어나게 된다. 이 때 layer 수를 depth라고 하고, 각 layer 벡터의 사이즈를 width라고 한다.
Activation Functions

그래서 좀 전에 보았던 각 layer에서 max 연산을 취해주던 것을 activation function을 취해준 것이라고 하는데, 그 중 ReLU라는 연산을 수행한 것이다. 결과 값에서 음수는 0으로 변환하고, 양수는 그대로 통과시키는 것이다.
만약 이런 activation function을 취해주지 않는다면 이는 여전히 Linear classifier가 되기 때문에 굳이 여러 개의 층을 쌓는 의미가 없어진다. 하지만 이런 형태의 Linear deep network가 representation 측면에서는 그냥 linear classifier와 다른게 없지만, 최적화 측면에서는 역학이 실제로 훨씬 복잡하여 연구가 되기도 한다.

이런 비선형 activation function에는 ReLU 말고도 매우 많은 종류가 있지만, 사실 ReLU 이전의 sigmoid와 tanh 등은 vanishing gradient 등의 문제가 발생해서 지금은 layer 중간부분은 ReLU나 그 변형들을 많이 사용한다.

Two-layer neural network를 넘파이로 구현하는 데에는 위 슬라이드처럼 간단히 구현할 수 있다.
- weight와 input 를 정의한다.
- loss를 계산한다.
- gradient를 계산한다.
- 가중치 업데이트를 진행한다.
Neurons
잠시 우리의 artificial neural network의 모티브가 된 실제 neuron에 대해 간단히 알아보자.
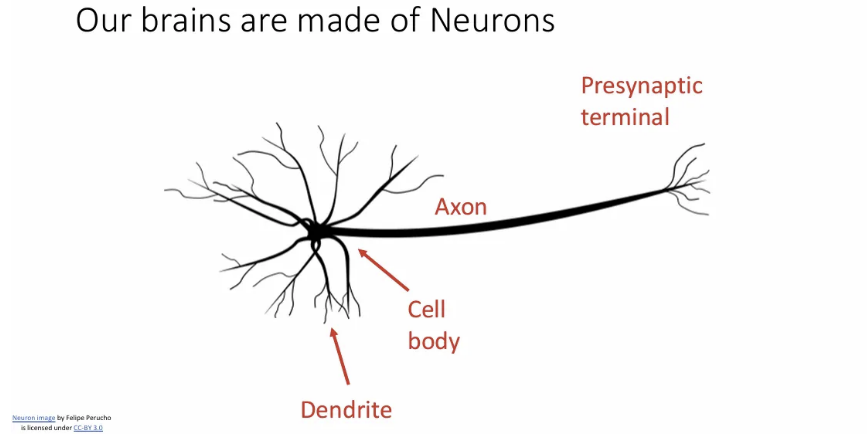
실제 우리 뇌의 뉴런인데, 위와 같은 구조이다. 중앙에는 모든 일이 일어나는 cell body가 있고, 전기적 자극의 통로인 Axon, 그리고 자극을 받아들이는 dendrite가 있다.
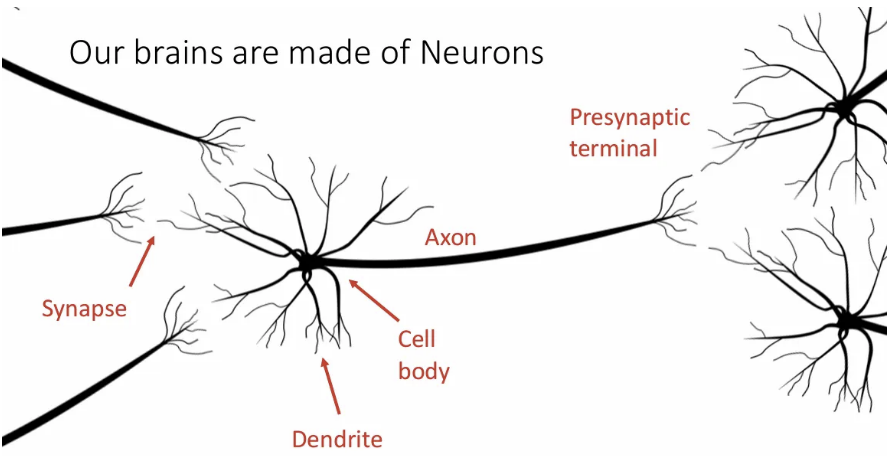
Axon을 통해 자극이 전달되면서 synapse까지 이동하게 되고, 다음 뉴런의 dendrite에서 이를 받게 된다.
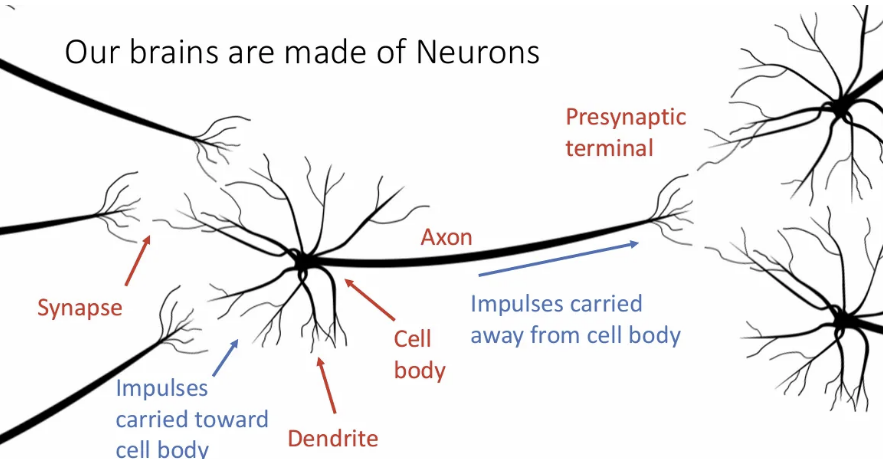
결국 하나의 뉴런에서의 cell body는 이와 연결된 이전 뉴런들의 자극을 모두 받아들이게 되고, 이를 또 다시 뒤에 연결된 뉴런들로 전달하게 된다.
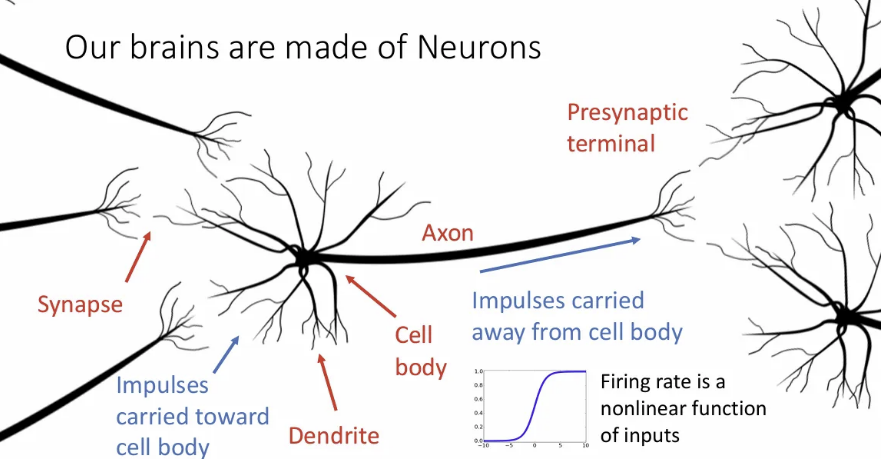
그리고 이 때의 firing rate 개념은 neural network에서의 activation function과 같다.
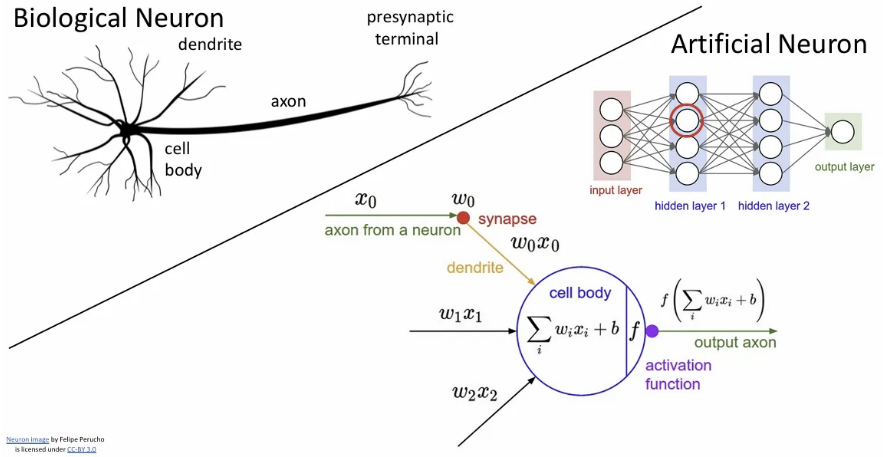
결국 요점은, 이런 생물학적 뉴런과 우리의 neural network는 매우 유사한 구조를 보인다는 점이다.

하지만 그렇다고 해서 실제 biological neuron은 우리의 인공 신경망보다는 훨씬 복잡한 구조이다. 종류도 많고, dendrite는 훨씬 복잡한 non linear activation을 수행하는 등 둘은 완전히 같다고 비유할 순 없음에 주의해야 한다.
Space Warping
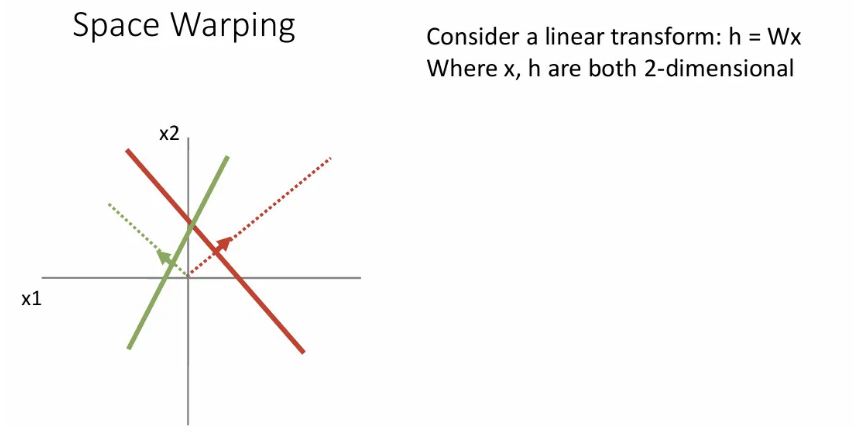
Linear classifier를 기하학적으로 생각할 때 두 클래스에 대한 템플릿에 대해 점선 방향으로 가면 점점 score가 증가했던 것을 기억할 수 있다.

여기서 만약 첫 번째 layer에서 feature transform으로 를 로 변환한다면 오른쪽과 같이 변환되는데, 여기까지가 linear classifier의 feature transform이었다면, 이는 당연히 linearly separable 하지 않다.
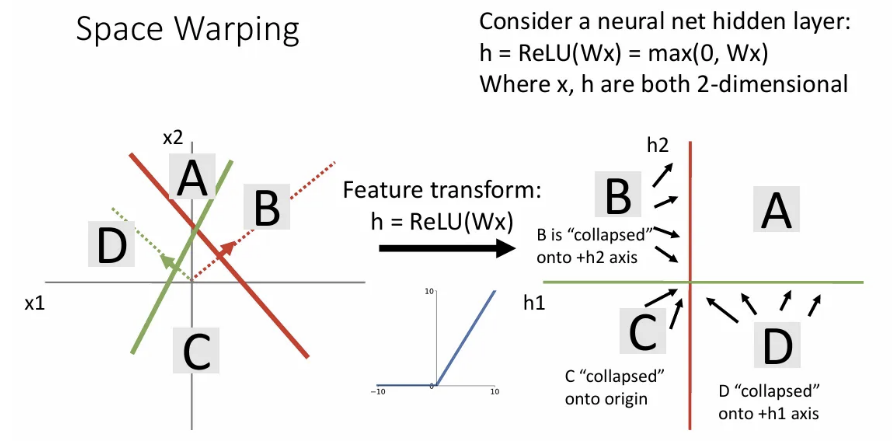
하지만 여기서 비선형 activation으로 ReLU를 적용해주면 B사분면에 있던 점들은 축으로, C사분면에 있던 점들은 원점으로, D사분면에 있던 점들은 축으로 이동된다.
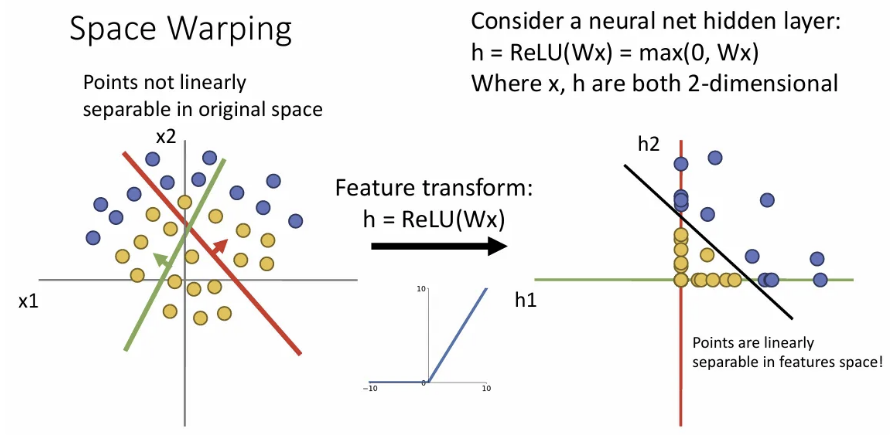
이렇게 되면 feature space에서 linearly separable 하게 된다.
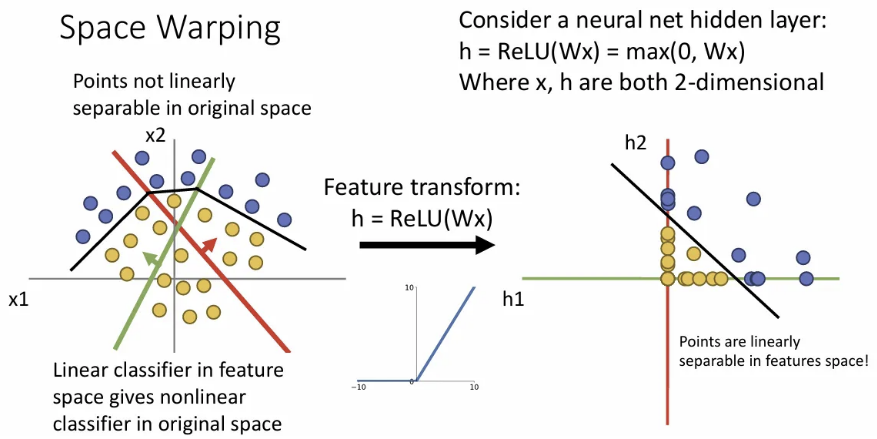
이 공간 상에서의 직선을 공간으로 되돌려보면 왼쪽과 같이 비선형으로 표현될 것이다.
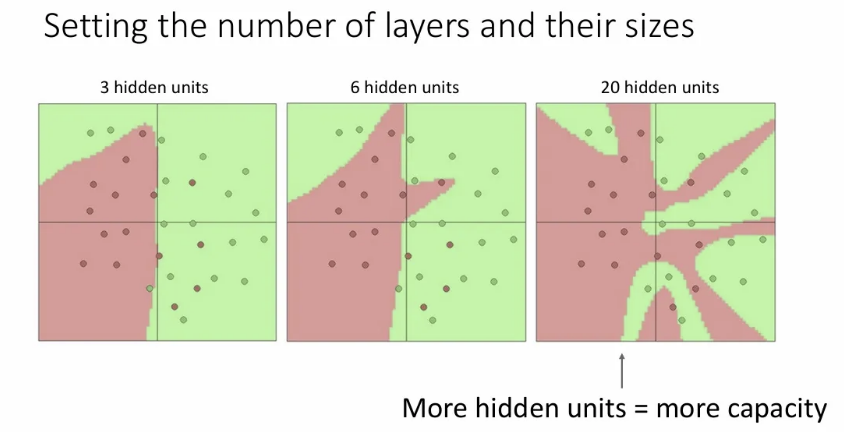
이렇게 layer가 하나씩 증가할수록(hidden unit이 증가할수록) decision boundary는 linear classifier에 비해 훨씬 유연해질 수 있다. 하지만 decision boundary가 너무 유연해지면 train set에 대한 과적합이 발생할 수 있다.
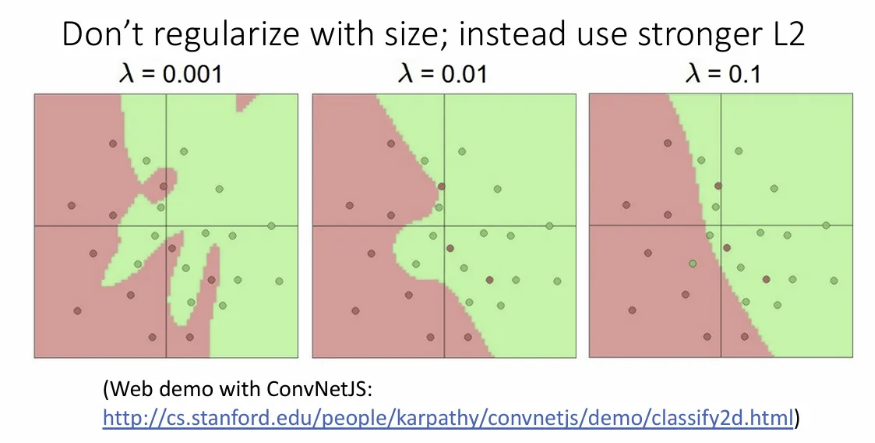
이에 대해 hidden unit을 적게 설정하는 방식으로 과적합을 방지해야겠다고 생각할 수도 있지만, 일반적으로는 hidden unit을 줄이기보단 regularization을 적용한다.
위 슬라이드를 보면 같은 hidden unit이어도 l2 regularization의 강도를 설정함에 따라 decision boundary의 유연도가 바뀌고 있다.
Universal Approximation
앞에서 Neural network가 매우 강력한 decision boundary를 형성할 수 있다는 점을 배웠고, 이런 성질을 universal approximation이라고 한다. 이는 단 하나의 hidden layer 만으로도 어떤 함수든 근사 가능하다는 것이다.
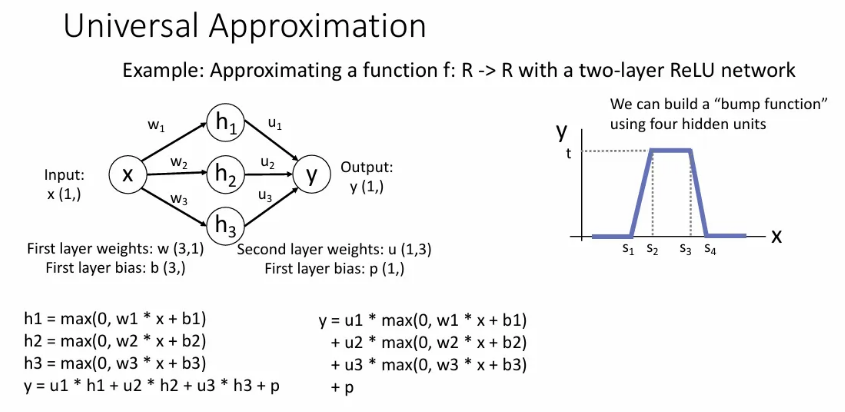
하나의 input 를 받아서 여러 hidden node와 연산하여 오른쪽과 같은 하나의 bump function을 만들어보자.
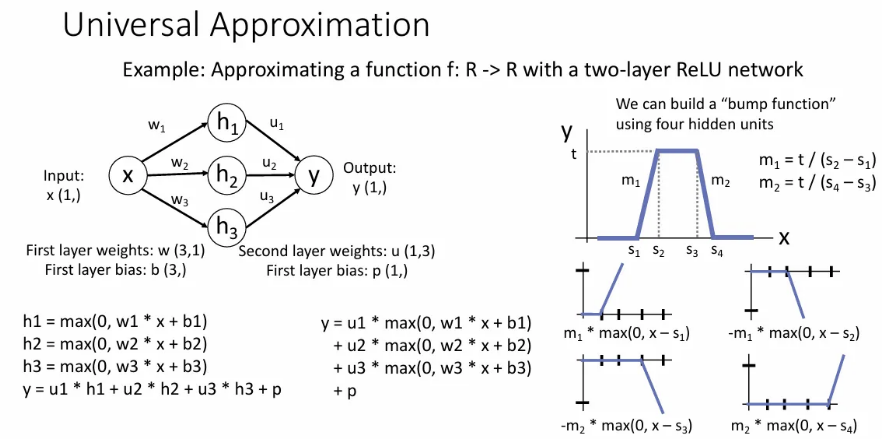
이는 사실 각 노드가 input 를 받아서 의 한 term을 형성할 때 ReLU 형태에서 shift, multiply 된 결과를 낼 수 있고, 이들을 모두 합쳤을 때 위와 같은 bump function을 만들어낼 수 있다.
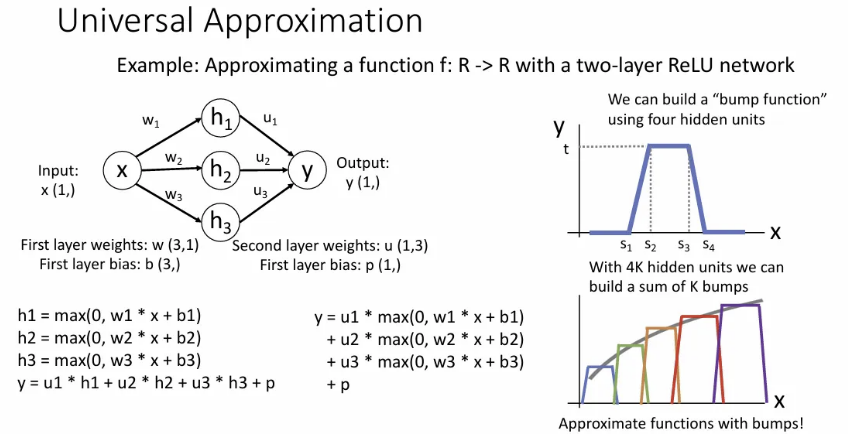
그리고 이러한 bump function을 연속적으로 만들 수 있도록 기하급수적인 수의 node를 사용하면, 하나의 hidden layer 만으로도 모든 함수에 근사할 수 있다는 이론이다. 이는 ReLU 말고 다른 activation function으로도 가능하다.
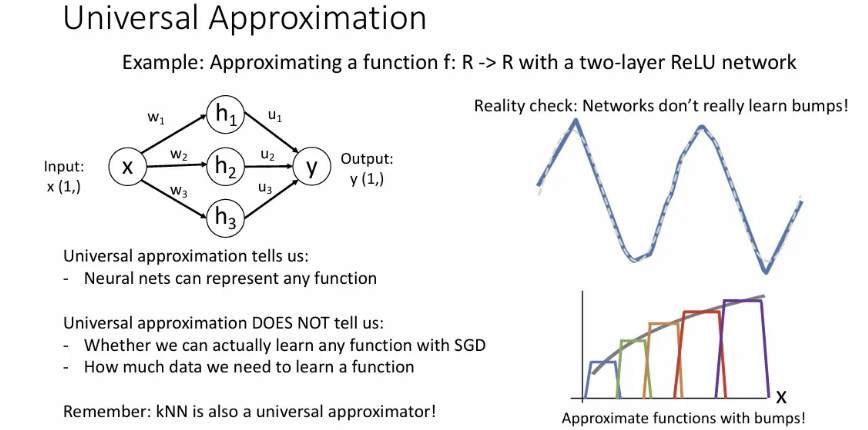
하지만 실제로 neural network가 학습할 땐 bump 로 이루어진 함수를 학습하지도 않고, 하나의 hidden layer로 위 방식으로 학습하려면 매우 많은 노드가 필요해서 hidden layer 하나로 모든 함수를 학습하는 것은 상당히 비효율적이게 돼서, 결국은 층을 더 쌓게 된다.
이 universal approximation은 그저 이론상 하나의 hidden layer 만으로도 모든 함수를 표현 가능하다는 점에 집중할 뿐임. 사실 KNN도 universal approximator이지만, 실제로 사용해보면 그다지 강력하지 않음.
Convex Functions
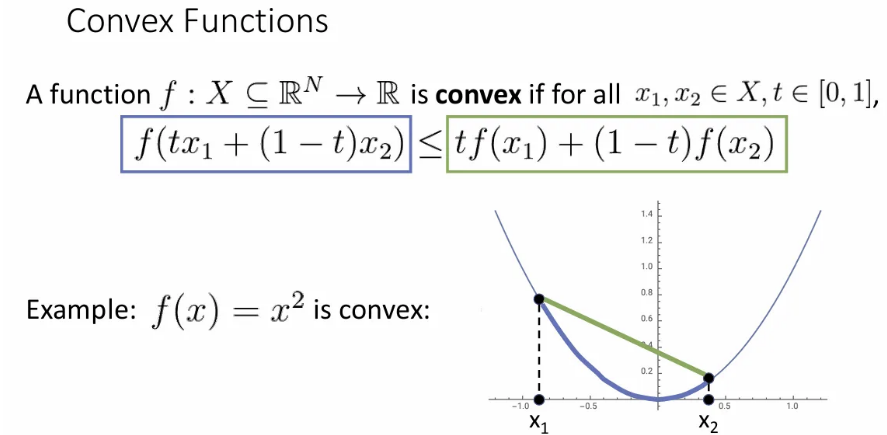
어떤 함수에서 임의의 두 점을 잇는 선분을 그었을 때, 그 사이 좌표에 해당하는 값이 모두 해당 선분 아래에 있는 함수를 convex function(볼록 함수) 라고 한다.

고차원 공간에서의 convex function은 마치 bowl shape이 되고, 기울기를 따라 내려가게 된다면 쉽게 global minimum에 도달할 수 있다(이런 경우 local minima가 global minima). 이런 convex function의 경우에는 어디서 초기화되던 항상 바닥을 향해 수렴할 수 있다.

Linear classifier를 데이터로 학습 시킬 때 그동안 우리가 다뤘던 softmax, svm loss 같은 convex function들을 최적화 하면 global minimum에 도달할 수 있다는 수렴 보장성이 있다(때로는 DNN보다 linear classifier가 선호 되는 이유).

하지만 딥러닝에서는 이러한 수렴 보장성이 없다. 고차원 loss surface의 한 단면 형태는 위와 같이 bowl shape을 보일 수도 있지만, 실제로는 아래와 같이 convex하지 않은 경우도 있게 된다.
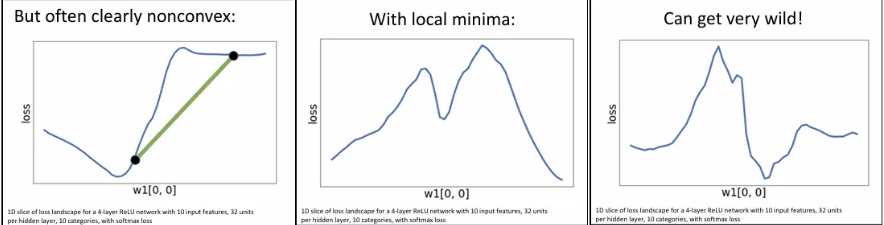
그래서 대부분 딥러닝에서의 최적화 방안은 non-convex한 함수에 대해서도 global minimum으로 수렴하도록 해야 한다. 하지만 이론적으론 수렴에 대한 보장이 없지만, 실제로 gradient descent 방식은 대체로 잘 동작한다.
References
유튜브 강의: https://www.youtube.com/watch?v=qcSEP17uKKY&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=5
PDF: https://web.eecs.umich.edu/~justincj/slides/eecs498/FA2020/598_FA2020_lecture05.pdf
