https://arxiv.org/pdf/2406.09246
1. Introduction
- 로봇 조작을 위한 학습된 정책의 주요 약점은 훈련 데이터를 넘어선 일반화에 어려움을 겪는다는 것임.
- 기존 policy들은 특정 기술이나 언어 지시에는 효과적이지만, 새로운 객체나 환경의 방해물에 대한 견고성이 부족하며, 경험하지 못한 작업을 수행하는 데 한계가 있음
- 이러한 한계를 극복하기 위해 이전 연구는 대규모 데이터로 사전 학습된 CLIP, SigLIP, Llama 2와 같은 비전 및 언어 파운데이션 모델의 잠재력에 주목하였음.
- 최근에는 Vision-Language-Action (VLA)이 로봇 제어에 통합되어 큰 진전을 이루었으나, 아래와 같은 한계를 지님
- 대부분 closed-source여서 아키텍처, 학습 절차, 데이터 혼합에 대한 정보가 제한적
- 새로운 로봇, 환경, 작업에 효율적으로 적응시키기 위한 fine-tuning 방법에 대한 가이드라인이 부족
- 저자들은 이러한 한계에 대응하기 위해 OpenVLA를 소개함. Llama 2 언어 모델을 기반으로 하며, DINOv2와 SigLIP에서 사전 학습된 특징을 융합하는 vision encoder를 통해 구축됨
- OpenVLA는 Open X-Embodiment 데이터셋의 97만 개의 로봇 에피소드를 포함하는 대규모의 다양한 실제 로봇 데모 데이터를 사용하여 학습되었으며, 모델 파라미터가 7배 적음에도 불구하고 550억개의 파라미터를 가진 RT-2-X보다 좋은 성능을 보여주었음
- 또한, 본 논문은 OpenVLA가 최신 low-rank adaptation (LoRA)을 통해 소비자용 GPU에서도 fine-tuning될 수 있으며, 성능 저하 없이 양자화를 통해 효율적으로 서비스될 수 있음을 보여줌
2. Related Work
Visually-Conditioned Language Models
- VLMs는 이미지 입력과 언어 프롬프트로부터 자연어를 생성하도록 인터넷 규모 데이터로 학습됨
- 최근 VLMs의 핵심 발전은 사전 학습된 시각 인코더(e.g., CLIP, SigLIP, DINOv2)와 사전 학습된 언어 모델(e.g., Llama2)의 특징을 통합하는 모델 아키텍처
- 대부분의 VLM은 patch-as-token 접근 방식을 사용하며, 시각적 특징을 언어 모델의 입력 공간으로 투영
- OpenVLA는 Prismatic-7B VLM을 backbone으로 활용함. 이는 SigLIP과 DINOv2를 결합한 이중 vision encoder를 사용하여, 특히 로봇 제어에 유용한 향상된 공간 추론 능력을 제공함
Generalist Robot Policies
- 최근 로봇 공학 연구는 대규모의 다양한 로봇 데이터셋을 기반으로 multi-task “generalist” 로봇 정책을 학습하는 방향으로 나아가고 있음
- 이러한 접근 방식은 언어 임베딩이나 시각 인코더와 같은 사전 학습된 구성 요소를 스크래치에서 초기화된 추가 모델 구성 요소와 결합하고, 학습 과정에서 이를 stitch(연결)함.
- OpenVLA는 end-to-end 방식을 채택하여, VLM을 직접 fine-tuning하여 로봇 액션을 언어 모델의 어휘에서 토큰으로 간주하여 생성
- 이는 단순하지만 확장 가능한 파이프라인이 기존 generalist 정책보다 성능과 일반화 능력을 향상시킨다고 함
Vision-Language-Action Models
- 이 분야는 사전 학습된 대규모 VLM을 로봇 액션 예측을 위해 직접 fine-tuning하는 연구를 포함
- VLA의 연구는 아래와 같은 특성을 지님
- 인터넷 규모의 시각-언어 데이터셋에서 시각 및 언어 구성 요소의 정렬을 수행
- 로봇 제어에 특화되지 않은 일반적인 아키텍처를 사용하여 VLM 학습의 확장 가능한 인프라를 활용
- VLM의 빠른 발전에 로봇 공학이 직접적인 혜택을 받을 수 있도록 함
- OpenVLA는 기존 연구와 아래 차별점을 가짐
- 대부분의 기존 연구(e.g., RT-2-X)는 폐쇄적이거나 단일 로봇/시뮬레이션 환경에 초점을 맞추어 일반성이 부족
- RT-2-X와 비교하여, OpenVLA는 파라미터 수가 대략 8배 부족함에도 더 나은 성능 달성
- RT-2-X가 탐구하지 않은 fine-tuning 효율성을 심층적으로 연구
- OpenVLA는 첫 번째 오픈소스 generalist VLA로서, 미래 VLA 연구와 개발을 지원하는 것을 목표로 함
3. The OpenVLA Model
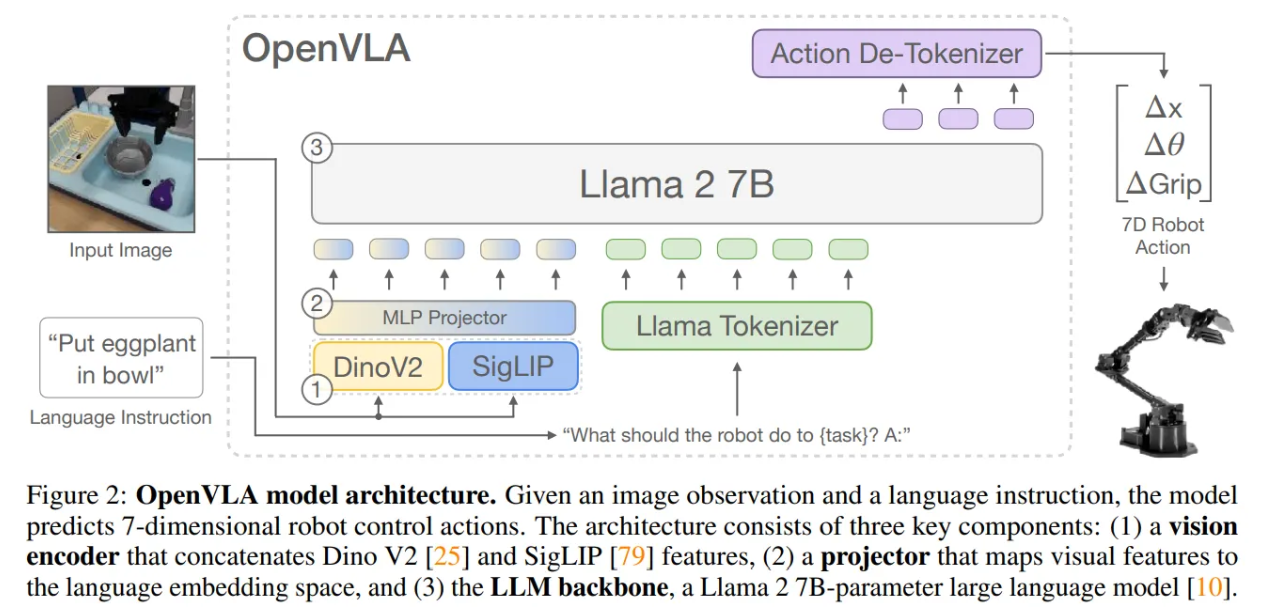
OpenVLA는 97만 개의 Open X-embodiment 데이터셋으로 학습된 70억 개(7B)의 파라미터를 가진 VLA 모델임. 해당 섹션은 OpenVLA 개발을 위한 핵심 학습 사항들을 중심으로 모델의 기초부터 실제 적용까지를 다룸
3.1. Preliminaries: Vision-Language Models
- 대부분의 최신 VLM은 세 가지 주요 부분으로 구성
- Visual encoder: 입력 이미지를 여러 “이미지 패치 임베딩”으로 매핑
- Projector: Visual encoder의 출력을 언어 모델의 입력 공간으로 매핑
- LLM backbone: 학습 시 다음 텍스트 토큰 예측 목표로 시각 및 언어 데이터에 대해 end-to-end 학습됨
- OpenVLA는 Prismatic-7B VLM을 backbone으로써 사용함
- 6억 개의 파라미터를 가진 visual encoder, 작은 2-layer MLP projector, 그리고 70억 개의 파라미터를 가진 Llama 2 언어 모델 백본으로 구성됨
- 이는 입력 이미지 패치들을 SigLIP과 DINOv2 인코더를 개별적으로 거친 후 channe-wise로 연결됨. 이는 공간 추론 능력(DINOv2)와 고수준 의미론(SigLIP)을 융합하여 로봇 제어에 특히 유용
3.2. OpenVLA Training Procedure
-
사전 학습된 Prismatic-7B VLM backbone을 로봇 액션 예측을 위해 fine-tuning
-
액션 예측 문제를 입력 이미지와 자연어 작업 지시를 받아 예측된 로봇 액션 문자열로 매핑하는 “vision-language” task로 공식화
- VLM이 본래 “입력 이미지 + 텍스트 프롬프트 → 자연어 텍스트”를 생성하도록 학습되었던 것을 감안할 때, 그 출력 형식을 “자연어 텍스트 → 로봇 액션 토큰 시퀀스”로 전환하는 것
-
LLM backbone이 로봇 액션을 이해할 수 있도록, 연속적인 로봇 액션을 LLM의 토크나이저가 사용하는 이산적인 토큰으로 매핑
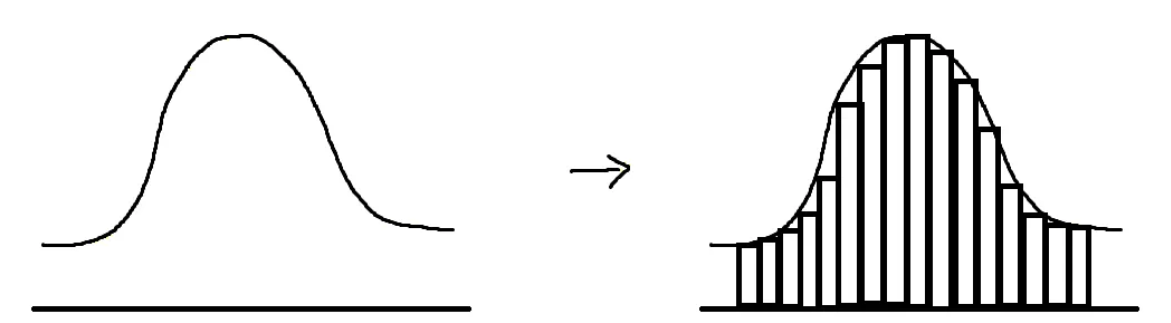
- LLM은 기본적으로 이산적인 토큰을 생성하지만, 로봇의 동작은 연속적인 실수 값으로 표현되기 때문에, 연속적인 로봇 액션을 LLM의 출력 공간에 맞게 이산적인 형태로 변환시키는
- 각 로봇 액션 차원을 256개의 bin으로 이산화. 이 빈 폭은 학습 데이터의 1~99백분위수 사이 간격을 균등하게 나누어 min-max 방식을 쓸 때보다 outlier에 덜 민감하도록 함
-
Llama 토크나이저의 어휘 중 가장 적게 사용되는 256개의 토큰을 액션 토큰으로 덮어씀
- 이산화된 액션은 0부터 255까지의 정수 값임. 이것들을 LLM의 “토큰”으로써 사용해야 하는데, OpenVLA의 LLM backbone인 Llama 2는 fine-tuning 과정에서 도입될 수 있는 special token 수가 100개로 제한되어 있음 → Llama 토크나이저의 어휘 중 가장 적게 사용되는 256개의 토큰을 0부터 255까지의 이산값인 액션토큰으로 overwrite 하는 것
- 이산화된 액션은 0부터 255까지의 정수 값임. 이것들을 LLM의 “토큰”으로써 사용해야 하는데, OpenVLA의 LLM backbone인 Llama 2는 fine-tuning 과정에서 도입될 수 있는 special token 수가 100개로 제한되어 있음 → Llama 토크나이저의 어휘 중 가장 적게 사용되는 256개의 토큰을 0부터 255까지의 이산값인 액션토큰으로 overwrite 하는 것
-
학습 목표는 standard next-token prediction 목표로 학습하며, 예측된 액션 토큰에 대해서만 cross-entropy loss를 평가
3.3. Training Data
- 다양한 로봇 형태, 장면, 작업에 대한 일반화 능력을 확보하기 위해 Open X-embodiment 데이터셋을 기반으로 데이터를 curation
- 모든 데이터셋에 걸쳐 일관된 입출력 공간
- 균형 잡힌 형태, 작업, 장면 혼합을 위함
- Octo의 데이터 혼합 가중치를 활용하여 데이터셋을 선택하고 가중치를 부여
- Droid 데이터셋과 같은 새로운 데이터셋도 포함하여 실험했으나, 최종 모델의 품질을 위해 후반부엔 제거
3.4. OpenVLA Design Decisions
본 섹션에서는 소규모 실험을 통해 얻은 주요 학습 사항을 소개
- VLM Backbone
- Prismatic이 LLaVA, IDEFICS-1보다 더 강한 language grounding 및 공간 추론 능력을 보임
- Image Resolution
- 224x224와 384x384를 비교한 결과, 성능 차이가 없어 224x224를 사용하여 비용 절감
- Fine-Tuning Vision Encoder
- VLM 사전 학습에서는 visual encoder를 고정하는 것이 일반적이지만, OpenVLA 학습에서는 isual encoder를 fine-tuning 하는 것이 VLA 성능에 결정적임을 발견
- Training Epochs
- 일반 LLM/VLM과 달리, VLA 학습에서는 학습 데이터셋을 훨씬 더 많이 반복하는 것이 중요(최종 27 에폭)
- Learning Rate
- VLM 사전 학습과 동일한 학습률 2e-5에서 최상의 결과를 보임
3.5. Infrastructure for Training and Inference
- 학습: 64개의 A100 GPU 클러스터에서 14일 동안 학습
- 추론: bfloat16 precision 로드 시 15GB GPU 메모리 소모, NVIDIA RTX 4090에서 약 6Hz로 실행
- 메모리 효율성을위해 양자화를 지원하며, 실시간 로봇 제어를 위한 원격 VLA 추론 서버도 구현하여 오픈소스로 공개
4. The OpenVLA Codebase
- https://openvla.github.io 에서 코드를 확인할 수 있으며, 이는 PyTorch 기반의 모듈식 코드베이스
- 단일 GPU에서의 파인튜닝부터 여러 노드의 GPU 클러스터를 활용한 수십억 개의 파라미터를 가진 VLA 학습까지의 확장을 지원
- 최신 학습 기술들을 지원
- PyTorch의 AMP 기능을 활용하여 학습 속도를 높이고 메모리 사용량을 줄임
- FlashAttention을 통해 어텐션 메커니즘의 계산 효율성을 개선하여 학습 속도를 향상
- Fully Sharded Data Parallelism으로 대규모 모델 학습 시 메모리 제약 문제를 해결하기 위해 모델 파라미터를 여러 장치에 분산하여 처리
- Open X-Embodiment 데이터셋을 통한 학습을 완벽하게 지원
- Huggingface의 AutoModel 클래스와 통합되어 모델 다운로드 및 fine-tuning이 용이
- QLoRA와 같은 양자화 기법을 사용하여 모델의 메모리 사용량을 줄이고 소비자용 GPU에서도 효율적인 추론이 가능하도록 함
- 로봇 제어를 위해 강력한 로컬 컴퓨팅 장치가 필요 없도록, 액션 예측을 로봇에 실시간으로 스트리밍하는 원격 VLA 추론 서버 솔루션 또한 제공
5. Experiments
실험 평가의 목표는 OpenVLA가 즉시 사용 가능한(out-of-the-box) 강력한 multi-robot 제어 정책으로 기능하는 능력과 새로운 로봇 작업에 대한 fine-tuning을 위한 좋은 initialization 역할을 하는지를 테스트하는 것.
저자들은 세가지 질문에 답하고자 함
- 다수의 로봇과 다양한 유형의 일반화에 대해 평가할 때, OpenVLA는 기존의 generalist 로봇 정책과 어떻게 비교되는가?
- OpenVLA는 새로운 로봇 설정 및 작업에 대해 효과적으로 fine-tuning될 수 있으며, 최첨단 데이터 효율적 모방 학습 접근 방식과 어떻게 비교되는가?
- Parameter-efficient한 fine-tuning 및 양자화를 사용하여 OpenVLA 모델의 학습 및 추론에 필요한 계산 요구 사항을 줄이고 더 접근 가능하게 만들 수 있는가? 성능-계산 trade-offs는 무엇인가?
5.1. Direct Evaluations on Multiple Robot Platforms
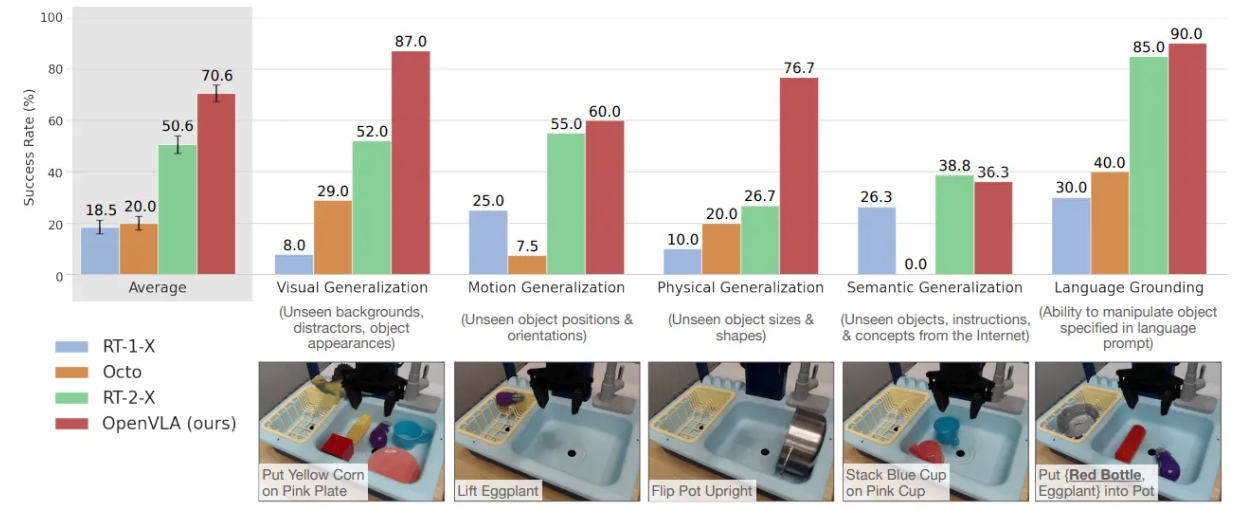
- BridgeData V2 WidowX 로봇 평가 작업 및 주요 결과(시각적 일반화, 움직임 일반화, 물리적 일반화, 의미적 일반화, 언어 기반 이해 능력 등)를 요약하여 보여줌.
- OpenVLA가 RT-2-X를 포함한 다른 generalist 로봇 정책들보다 BridgeData V2 환경에서 전반적으로 뛰어난 성능을 보여줌
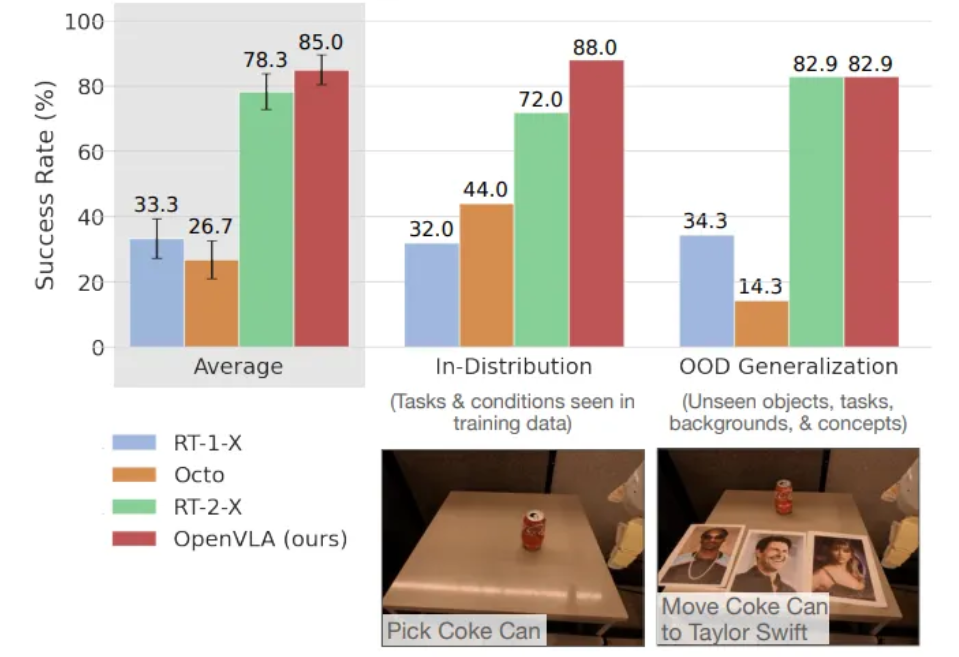
- Google 로봇 평가 작업을 보여주며, in-distribution 및 out-of-distribution (OOD) 조건에서의 주요 성능 비교 결과를 보여줌
- Google 로봇 환경에서 OpenVLA와 RT-2-X가 유사한 최상위 성능을 달성하며 RT-1-X 및 Octo를 크게 능가함을 보여줌
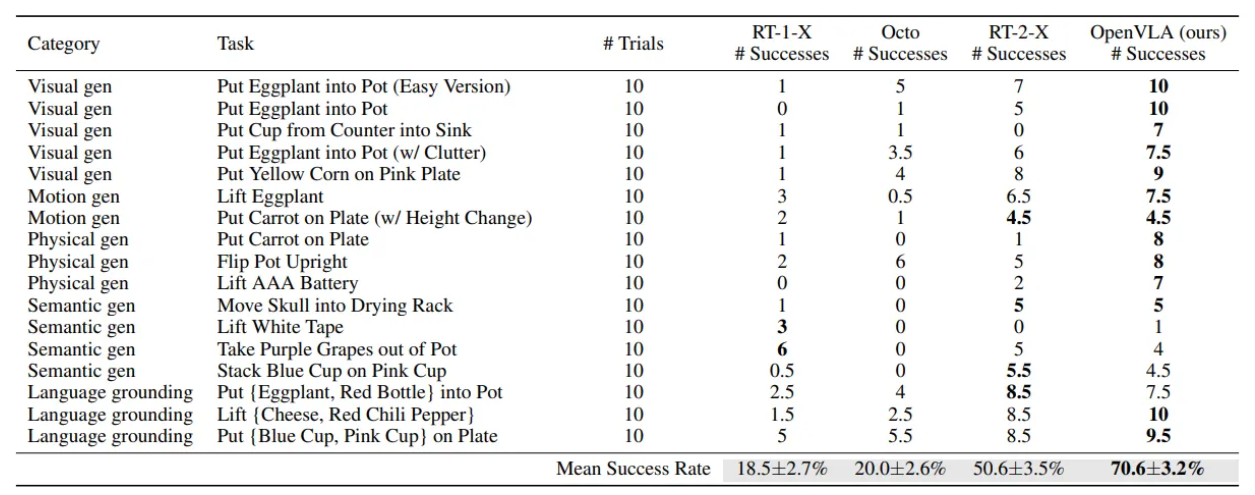
- BridgeData V2 WidowX 환경에서의 상세 평가 결과를 보여줌. 각 작업별 성공 횟수와 평균 성공률을 비교
- OpenVLA가 대부분의 작업에서 가장 강력한 성능을 보이며 전반적인 성공률에서 다른 모델들을 능가하는 성능을 보여주었음
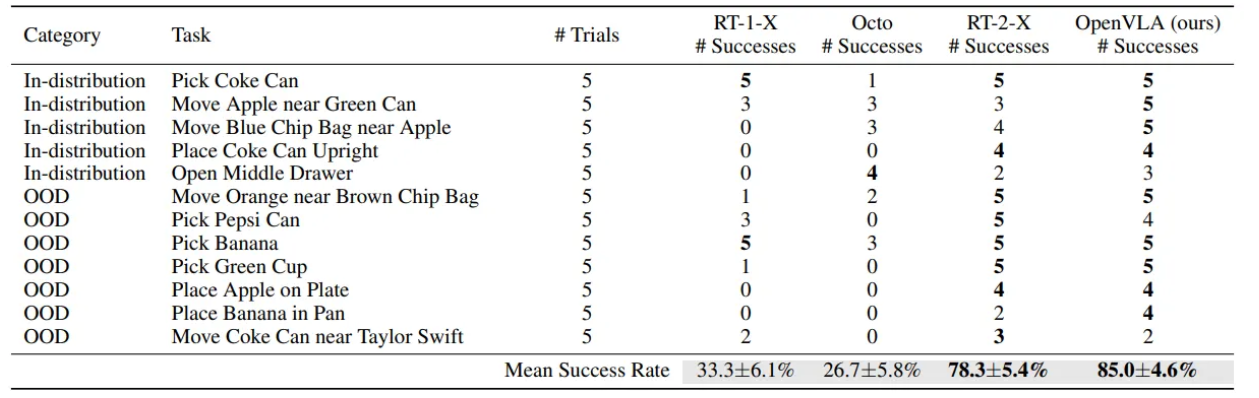
- Google 로봇 환경에서의 상세 평가 결과를 보여줌. 각 작업 별 성공 횟수와 평균 성공률을 비교
- OpenVLA와 RT-2-X가 RT-1-X 및 Octo에 비해 모든 작업에서 일관되게 높은 성공률을 보임
5.2. Data-Efficient Adaptation to New Robot Setups
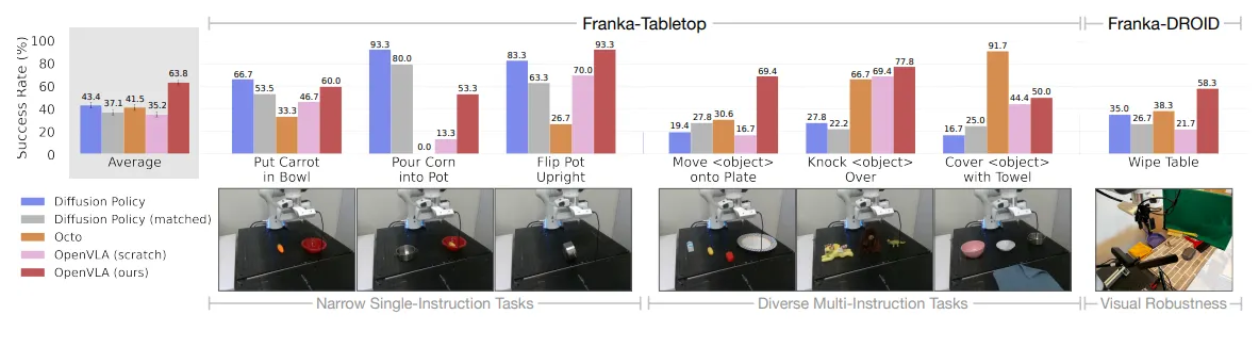
- Franka-Tabletop 및 Franka-DROID와 같은 새로운 로봇 설정에 OpenVLA를 적용했을 때의 주요 결과를 요약하여 보여줌
- OpenVLA가 새로운 로봇 설정에서 fine-tuning 시 Diffusion Policy 및 Octo보다 전반적으로 가장 높은 평균 성능을 달성함을 시사
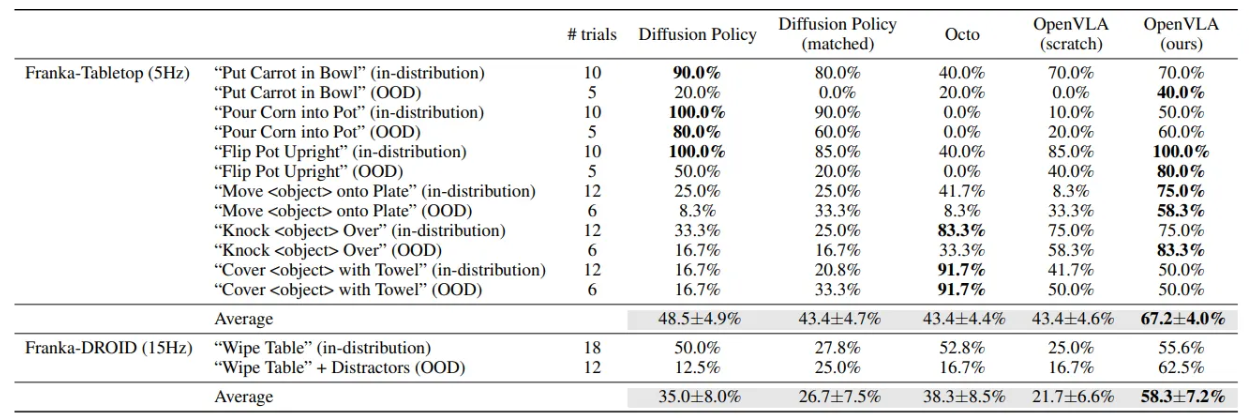
- Franka-Tabletop 및 Franka-DROID 환경에서의 상세 fine-tuning 평가 결과를 보여줌
- OpenVLA가 단일 지시 작업(”Put ~”, “Pour ~”)에서는 Diffusion Policy와 비슷하고 다중 지시 작업(”Move~”, “Knock~”, “Cover~”, “Wipe~”)에서는 더 우수한 성능을 보이며, 전반적으로 가장 높은 평균 성능을 달성
5.3. Parameter-Efficient Fine-Tuning
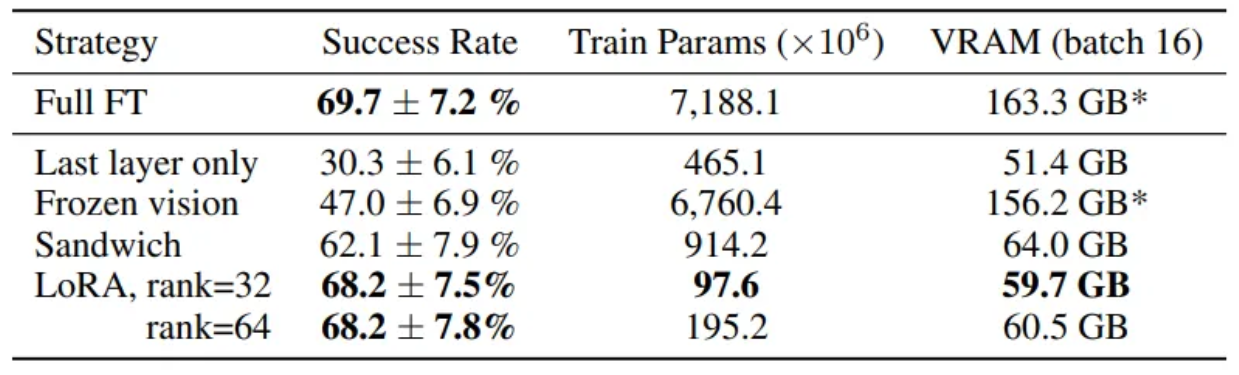
- 다양한 parameter-efficient fine-tuning 전략의 성능-계산 tradeoff를 요약하여 보여줌
- LoRA fine-tuning이 극히 일부만 훈련하면서도 full fine-tuning과 유사한 성능을 달성하여 최상의 성능-계산 tradeoff를 제공

- Parameter-efficient fine-tuning 실험의 상세 결과를 보여줌
- LoRA가 다른 PEFT 방법들보다 훨씬 좋은 성능을 보이며, full fine-tuning에 근접한 성능을 보임
5.4. Memory-Efficient Inference via Quantization
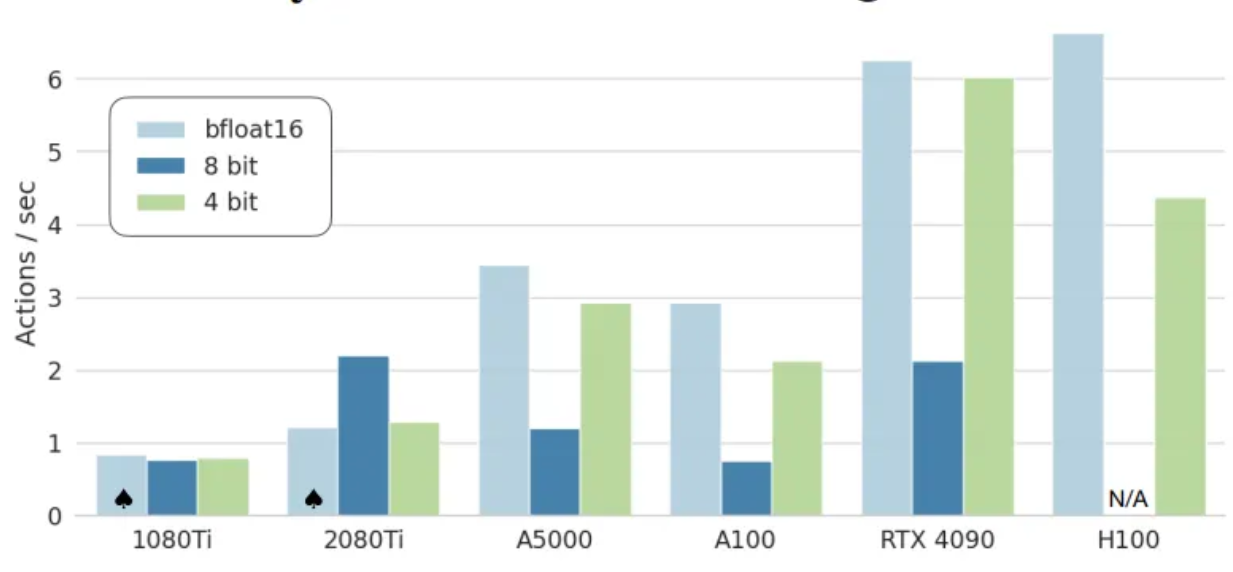
- 다양한 소비자 및 서버 급 GPU에서 OpenVLA의 추론 속도를 보여줌
- RTX 4090 및 H100과 같은 최신 GPU에서 bfloat16 및 int4 양자화 모델이 높은 처리량을 달성
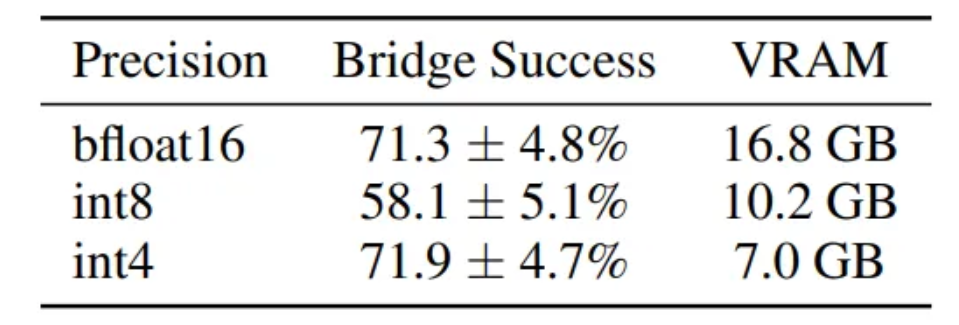
- 양자화된 추론(bfloat16, int8, int4)의 성능과 VRAM 사용량을 요약
- 4비트 양자화가 bfloat16과 거의 동일한 성능을 유지하면서도 GPU 메모리 사용량을 절반 이상 줄여 접근성을 높임을 보여줌
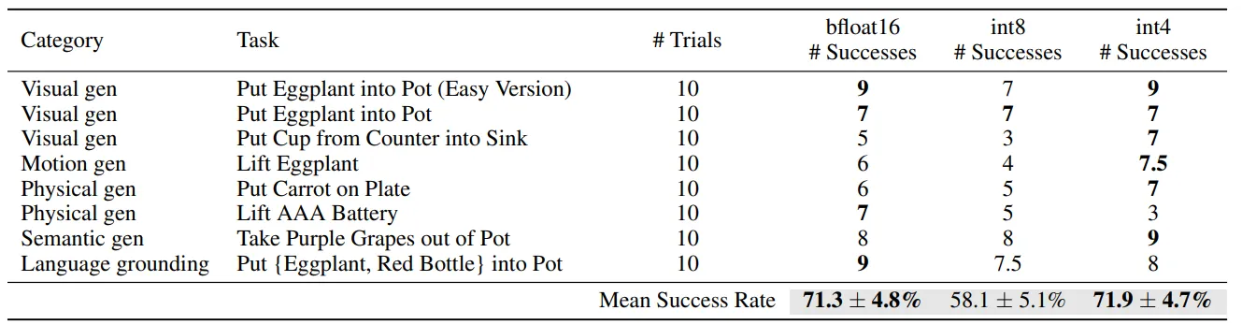
- 앞 테이블에 대한 상세 결과로, BridgeData V2 작업에서의 성공 횟수를 비교
- int4 양자화가 bfloat16과 유사한 성공률을 보이며, int8 양자화는 추론 속도 저하로 인해 성능이 감소할 수 있음을 보여줌
