[논문 리뷰] ReplayCAD: Generative Diffusion Replay for Continual Anomaly Detection (IJCAI 2025)
논문리뷰
https://arxiv.org/pdf/2505.06603
1. Introduction
- 오늘날 Unsupervised Anomaly Detection (UAD)는 현대 제조에서 매우 중요하며 이미지 및 픽셀 레벨에서 샘플의 결함을 자동으로 식별하여 생산 효율성과 제품 품질을 향상시키는 중요한 기술임
- 하지만 실제 산업 생산에서는 생성 계획의 변화로 인해 이전 클래스에 대한 지식을 잊지 않으면서 새로운 클래스 샘플에서 지식을 학습해야하기 때문에, Continual Anomaly Detection (CAD)가 필요함
- 이러한 과정에서 두 가지 주요 문제가 발생
- Catastrophic forgetting으로 인해 새로운 데이터를 학습할 때 과거 지식을 잊어버리는 경향이 있음
- CAD는 이미지 수준의 이상 탐지 뿐만 아니라 픽셀 수준에서 작은 이상 영역을 정확히 분할해야 하며, 이를 위해서는 과거 샘플의 상세한 픽셀 수준 특징을 기억하는 것이 중요
- 기존의 Continual Learning 방법들은 상세 특징 보존에 중점을 두지 않아 CAD에는 비효과적이며, DNE와 UCAD와 같은 최신 CAD 방법들은 특징을 압축하여 저장함으로써 망각을 완화하려 하지만, 픽셀 수준의 상세 특징을 보존하지 못해 분할 성능엔 한계가 있음
- 이러한 한계를 극복하기 위해 본 논문은 ReplayCAD라는 Diffusion 기반 generative replay 프레임워크를 제안
- 핵심은 고품질의 다양하고 실제와 같은 과거 데이터를 replay하여 픽셀 수준의 상세 특징을 효과적으로 보존하는 것
2. Related Work
2.1. Unsupervised Anomaly Detection
기존 UAD 방법들은 크게 세 가지로 분류됨
- Embedding-based : 정상 샘플의 특징 분포를 모델링하고, 이 분포에서 벗어나는 이상 샘플을 감지
- Reconstruction-based : 정상 이미지를 재구성하도록 모델을 학습하고, 입력 이미지와 재구성된 이미지 간의 차이를 통해 이상을 감지
- Synthesizing-based : 정상 이미지에 인공적으로 이상을 합성하여 모델의 이상 탐지 능력을 향상
→ 이 방법들은 실세계 산업 환경에서 새로운 종류의 데이터가 지속적으로 등장하는 시나리오, 즉 “Continual Learning” 능력은 부족함. 본 논문의 목표는 기존 이상 탐지 모델에 continual learning 능력을 부여하는 것
2.2. Continual Learning
기존 CL 방법들은 Catastrophic Foregetting 문제를 완화하기 위해 다음과 같은 여러 전략을 사용함
- Regularization-based : 모델 파라미터에 제약을 가하여 이전 태스크 지식의 망각을 방지
- Replay-based : 과거 태스크의 데이터나 특징을 재사용하여 이전 지식을 유지
- Architecture-based : 각 태스크에 특정 파라미터를 할당하여 간섭을 최소화
→ 하지만 기존 CL 방법들은 CAD에 필요한 “과거 샘플의 상세 특징 보존”에 특별히 초점을 맞추지 않았기 때문에, AD 모델에 직접 사용하기에는 부적합
2.3. Continual Anomaly Detection
CAD에 대한 현재 연구는 크게 두 가지 접근 방식으로 나뉨
- Feature Replay-based : 이전 클래스 샘플의 특징 임베딩을 저장하고, 테스트 샘플 특징과 비교하여 이상을 찾음
- 픽셀 수준의 상세 특징을 저장할 수 없기 때문에, 이상 영역 분할 성능이 저하됨
- Regularization-based : 이전 클래스에 대한 파라미터 업데이트를 제한하여 지식 망각을 방지
- 긴 클래스 시퀀스에서는 성능이 저하되는 문제 발생
→ 본 논문은 이러한 기존 CAD 방법들의 한계점을 해결하기 위해 “데이터 자체”에 초점을 맞추어 상세 특징을 기억하고자 함
3. Problem Definition
일반적인 AD 작업과 달리, CAD는 모델이 학습 시점에 모든 클래스를 알지 못하는 환경에서 작동함. 대신, 새로운 클래스가 지속적으로 나타남에 따라 모델은 이들을 점진적으로 학습해야 하는 Class-Incremental Learning의 한 형태임
- 총 개의 클래스를 가진 이상 탐지 데이터셋이 있다고 가정할 때, 각 클래스의 학습 데이터는 , 테스트 데이터는 로 표현
- 모델이 번째 클래스를 학습할 때, 오직 현재 클래스의 학습 데이터 에만 접근할 수 있고, 이전 클래스의 데이터인 에는 접근 불가
- 테스트는 누적 방식으로 진행. 모델이 번째 클래스 학습을 마친 후에는 이전 모든 클래스 에 대해 테스트를 수행해야 함
→ 목표는 각 클래스의 학습 데이터에 대해 순차적으로 학습한 후, 최종적으로 전체 테스트 데이터 셋에 대해 평가하여, 모델이 새로운 지식을 학습하면서도 이전에 학습한 클래스에 대한 지식을 유지해야 함을 의미
4. Methods
4.1. Overview
ReplayCAD는 크게 두 단계로 구성
- Feature-guided data compression stage
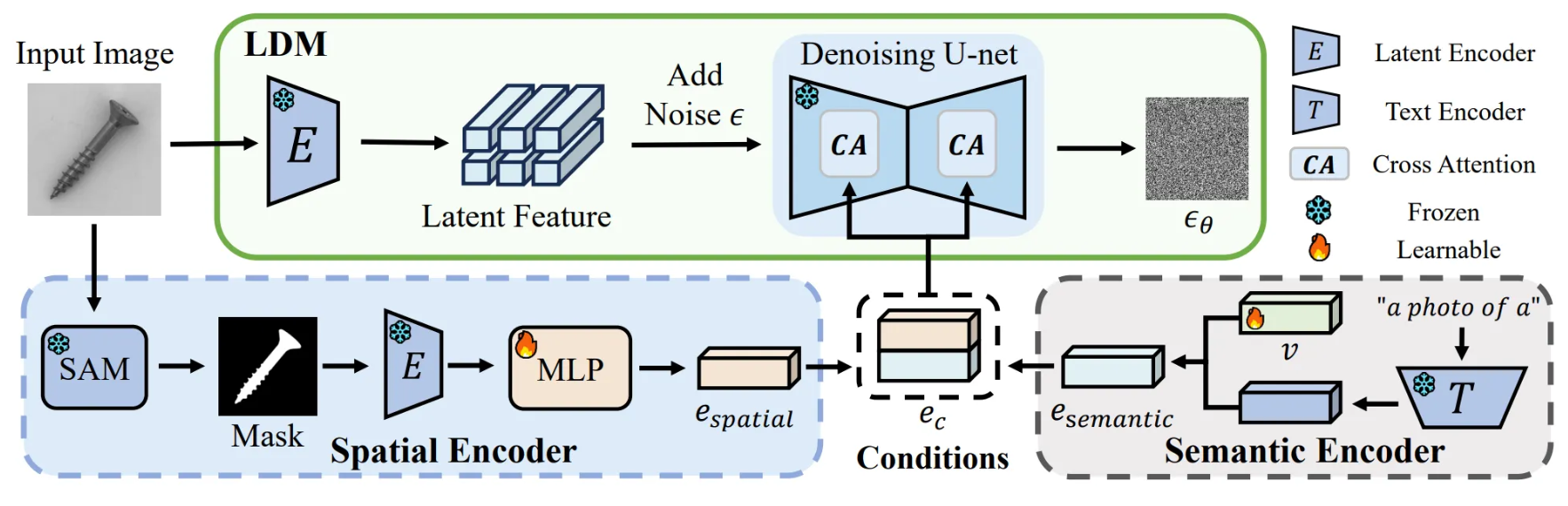
- Semantic Features: 사전 학습된 Latent Diffusion Model (LDM)의 조건부 공간에서 클래스 의미론적 임베딩을 찾음
- Spatial Features: SAM (Segment Anything Model)을 통해 얻은 샘플의 마스크 정보를 공간적 특징으로 활용. 이 마스크는 이미지 내 샘플의 위치 및 형태와 관련된 공간 정보를 나타내며, LDM이 공간적으로 다양한 데이터를 생성하도록 도움
→ 이 두 가지 features를 모두 사용하여 과거 데이터의 세부적인 픽셀 수준 특징과 다양성을 보존
- Replay-enhanced anomaly detection stage
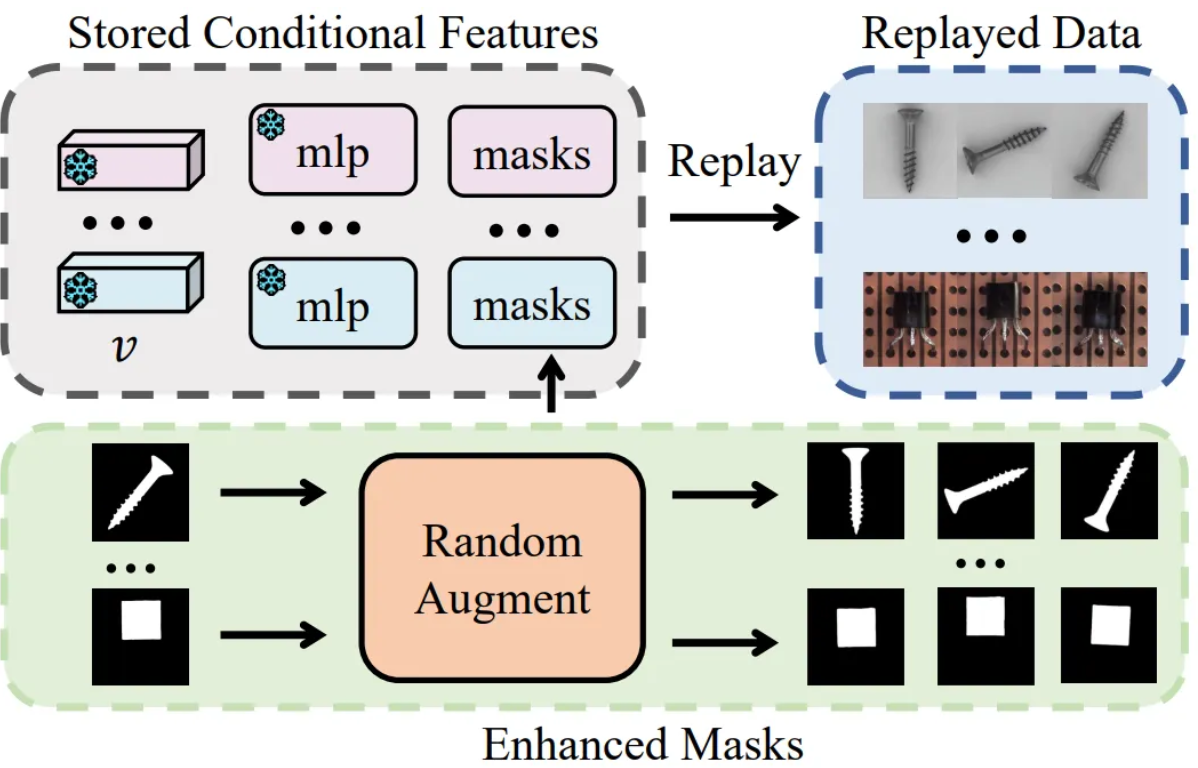
- 첫 번째 단계에서 추출하고 저장한 조건부 특징을 바탕으로 과거 클래스에 해당하는 데이터를 고품질로 replay
- 재생된 과거 데이터와 현재 학습 중인 새로운 클래스 데이터를 함께 사용하여 이상 탐지 모델을 학습
- 이는 모델이 새로운 정보를 학습하면서도 과거 지식을 잊는 catastrophic forgetting을 완화하는 데 기여
4.2. Semantic-Aware Generative Replay
Latent Diffusion Model (LDM)
- LDM은 고차원 픽셀 공간에서 직접 작업한느 대신 저차원 잠재 공간에서 denoising을 통해 데이터를 생성
- 이 접근 방식은 계산 효율성을 크게 향상시키면서도 필수적인 의미론적 정보를 보존하여 고품질 출력을 보장함
- LDM은 텍스트 설명, 이미지 마스크 또는 클래스 레이블과 같은 조건을 사용하여 생성 프로세스를 안내하는 conditional guide 메커니즘을 통합
LDM의 최적화 함수는 아래와 같음
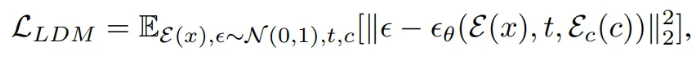
- : 입력 이미지 를 잠재 공간으로 인코딩한 것
- : 정규 분포에서 추출한 랜덤 노이즈
- : Denoising time step
- : 조건부 입력
- : 노이즈를 예측하는 LDM의 U-Net 모델 (파라미터 )
- : 조건을 잠재 공간으로 인코딩한 것
→ 이 함수는 예측된 노이즈 와 실제 노이즈 사이의 차이를 최소화하여 LDM의 데이터를 정확하게 생성하도록 학습시킴
Semantic Feature Compression
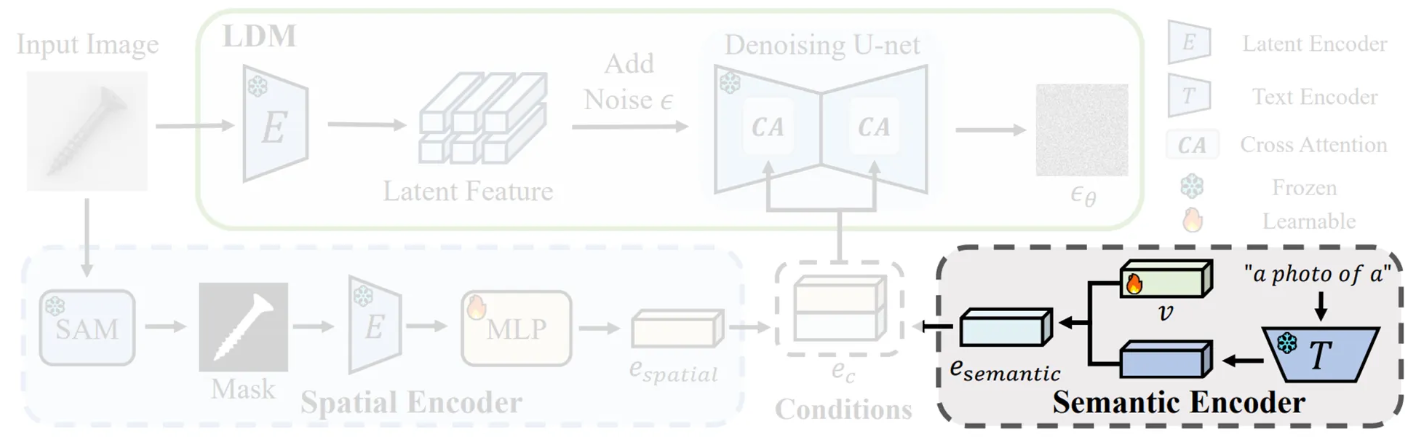
- ReplayCAD는 LDM을 직접 핛습하는 대신, LDM이 특정 클래스의 샘플을 생성하도록 안내하는 조건부 특징을 학습함.
- 의미론적 특징을 나타내기 위해, 먼저 학습 가능한 임베딩 를 무작위로 초기화
- “a photo of a” 와 같은 텍스트 프롬프트 를 고정된 텍스트 인코더 에 입력하여 인코딩한 후, 의미론적 임베딩 와 연결하여 최종 의미론적 특징 를 형성
- 이 은 LDM의 노이즈 제거 프로세스를 안내하며, 최적화 목표는 LDM의 손실 함수를 최소화하는 를 찾는 것
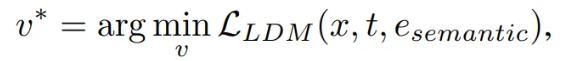
- 학습된 semantic 임베딩 는 각 클래스별로 저장
Replay & AD training
- 새로운 클래스 데이터가 나타나면, 저장된 의미론적 임베딩을 사용하여 LDM이 과거 클래스 데이터를 재생하도록 가이드
- 재생된 과거 클래스 데이터와 새로운 클래스 데이터를 통합하여 Anomaly Detection 모델을 학습
- 이러한 데이터 replay는 과거 클래스 지식을 잃어버리는 catastrophic forgetting 문제를 효과적으로 완화
- 본 연구에서는 InvAD를 기본 AD 모델로 사용
4.3. Spatially-Enhanced Diverse Generation

- 샘플은 의미론적 특징 뿐 아니라 위치, 각도 등 공간적 특징(spatial features)도 포함함
- 의미론적 특징에만 의존하여 데이터를 압축하면, 생성된 데이터가 특정 예시에 과적합되어 공간적 다양성이 부족할 수 있음
→ 따라서 SAM을 통한 zero-shot 마스크를 획득하여 각 샘플의 마스크를 생성하고, 이를 공간적 특징으로써 나타냄
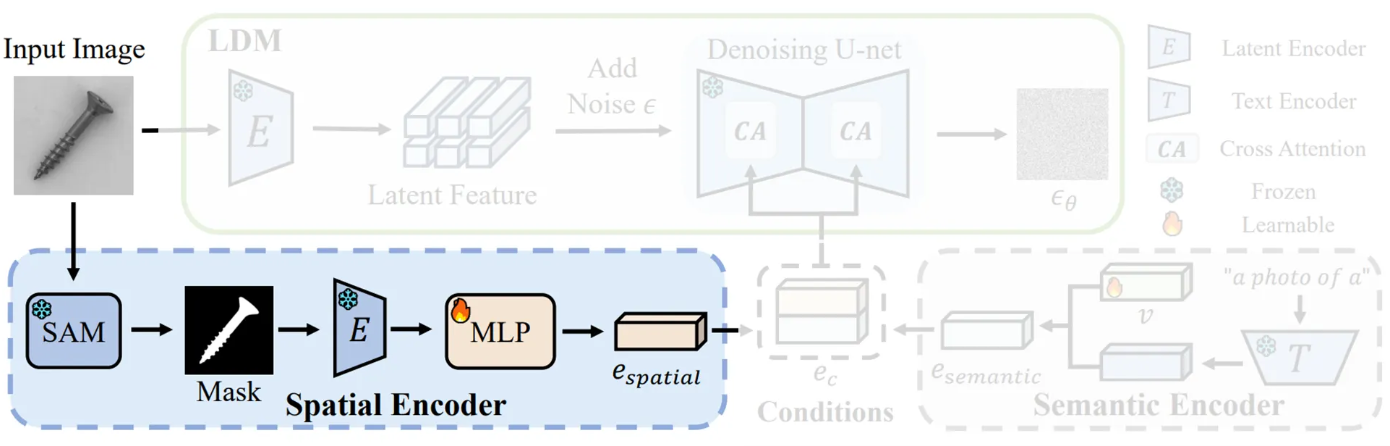
- LDM의 latent encoder는 마스크 정보를 직접 해석할 수 없기 때문에, MLP 레이어를 최적화하여 마스크로부터 공간적 특징으로의 매핑 관계를 학습
- 이 학습된 MLP는 LDM의 denoising 과정을 안내하는 데 사용됨
이후 추출된 의미론적 특징 과 공간적 특징 을 결합하여 LDM을 안내하는 최종 condition 를 생성
각 클래스에 대한 최적의 의미론적 임베딩 와, spatial encoder의 MLP layer 를 찾는 것이 최적화 목표가 되고, 이는 LDM 최적화 함수를 통해 이루어짐
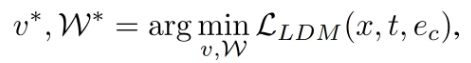
추가로, 데이터 replay 시 저장된 마스크에 임의의 회전 및 이동 augmentation을 적용하여 공간적 다양성을 확보함으로써 ReplayCAD는 실제적이고 다양한 과거 데이터를 생성하여 픽셀 수준의 상세 특징을 더욱 효과적으로 보존
→ 각 과거 클래스에 대해 Semantic Embedding , MLP layer , 그리고 개의 마스크 이미지가 저장됨
5. Experiments
5.1. Experiments Setup
Datasets
Visual Anomaly Detection에서 가장 많이 쓰이는 MVTec AD, VisA 데이터셋 사용
Compared Methods
- CAD Methods
- 이전에 제안된 SOTA 방법들 (CDAD, IUF, UCAD, DNE)와, DNE 프레임워크를 PANDA 및 CutPaste에 적용한 변형을 비교
- AD Methods
- SOTA UAD 방법들 (PatchCore, SimpleNet, MambaAD, InvAD)을 CAD 시나리오에 직접 적용하여 비교
- 새로운 클래스 데이터가 들어올 때 이전 모델을 fine tuning
- AD + CL Methods
-
SimpleNet 및 MambaAD에 EWC (Elastic Weight Consolidation) 및 MAS (Memory Aware Synapses)와 같은 기존의 CL 기법을 적용
-
Metrics
Image-level 분류 성능은 AUROC, Pixel-level segmentation 성능은 Pixel-AP 사용하였으며, 모델이 이전 클래스 지식을 얼마나 잊어버리는지에 대한 Forgetting Measure를 사용
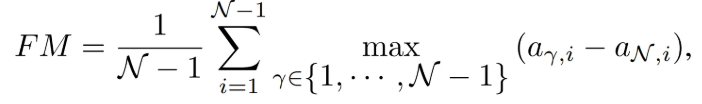
Implementation Details
- Semantic embedding 를 위한 토큰 수는 20으로 설정
- VisA 데이터셋은 사전 학습된 Stable Diffusion 1.5 가중치를 사용하며, 입력 해상도는 512x512, semantic 및 spatial 특징의 차원은 768이고, MLP layer 크기는 (128, 196)
- MVTec AD 데이터셋은 사전 학습된 LDM 가중치를 사용하며, 입력 해상도는 256x256, semantic 및 spatial 특징의 차원은 1280이고 MLP layer 크기는 (128, 200)
- 각 클래스마다 800개의 샘플이 생성되어 이상 탐지 모델 학습에 사용됨
- 다중 클래스 이상 탐지 모델인 InvAD를 베이스라인으로 사용하며, 모든 설정은 원본 논문과 동일하게 유지
5.2. Experiment Performance
Quantitative Evaluation
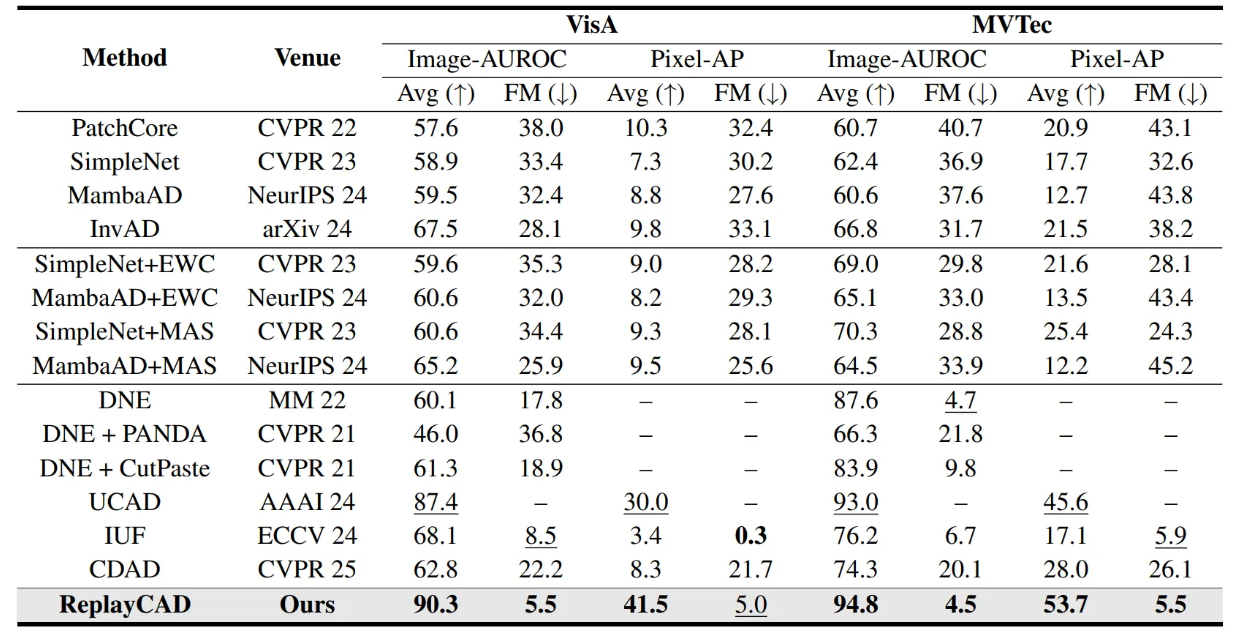
- ReplayCAD는 VisA 및 MVTec AD 두 데이터 셋 모두에서 Image-level 및 Pixel-level 지표에서 SOTA를 달성
- 특히 pixel-level segmentation에서 VisA에서 11.5%, MVTec AD에서 8.1% 정도의 성능 개선을 보이며, 이는 ReplayCAD가 과거 데이터의 세부적인 pixel-level 특징을 효과적으로 보존한다는 주장을 뒷받침
- 또한, forgetting measure 또한 다른 방법론 대비 매우 낮은 성능을 보였음.
- IUF의 경우 낮은 FM을 보였지만, 이는 새로운 클래스 학습 시 과거 클래스 특징과의 충돌로 인해 실제 잠재력보다 좋은 성능을 보이는 feature conflicts 현상 때문으로 분석

- ReplayCAD는 과거 클래스의 데이터를 semantic & spatial features로 압축하여 저장
- 기존에 패치 수준 특징을 저장(UCAD)하거나 그래디언트 정보를 저장(CDAD)하는 것에 비해 훨씬 적은 추가 메모리 공간을 사용하였음
Qualitative Evaluation

- 기존 AD 및 AD+CL 방법들이 catastrophic forgetting으로 인해 종종 넓은 영역의 잘못된 예측이나 놓친 탐지를 보이는 반면, ReplayCAD는 탐지에서 높은 정확도를 보임

- Replay된 데이터와 실제 데이터를 비교
- Replay된 데이터가 실제 데이터와 매우 유사하며, 이는 ReplayCAD의 generative replay 프레임워크가 고품질의 사실적인 데이터를 생성하는 데 효과적임을 검증
5.3. Analysis
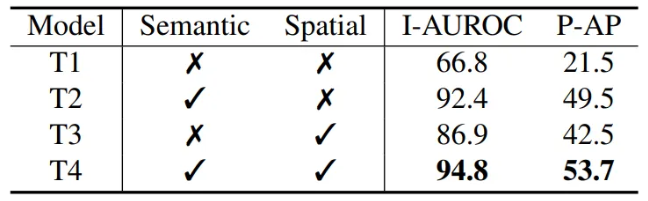
- Semantic 및 Spatial 특징의 영향을 분석하는 ablation study
- 결과적으로, ReplayCAD가 과거 데이터의 semantic 및 spatial 특징을 모두 활용하여 데이터를 재생하는 것이 catastrophic forgetting을 효과적으로 완화하는 것을 입증
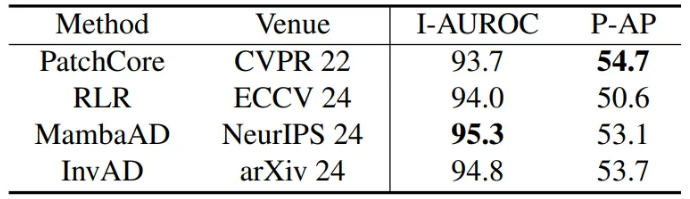
- ReplayCAD가 생성한 데이터를 사용하여 SOTA AD 모델을 학습했을 때의 성능 결과
- ReplayCAD는 특정 AD 모델에 종속되지 않고, 여러 최신 AD 기술의 성능을 향상시킬 수 있는 범용적인 데이터 생성 능력을 가짐을 입증
