
✍ 해당 시리즈 포스팅은 스탠포드 대학의 cs231n 강의 내용을 정리한 글입니다.
CPU vs GPU
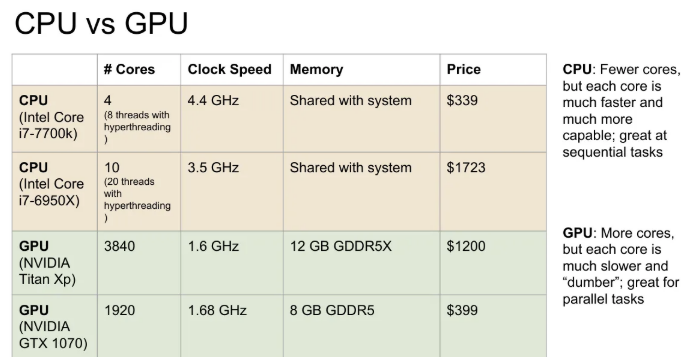
CPU
- Core의 수가 적다.
- hyperthreading 기술로 8~20개의 스레드를 동시에 실행시킬 수 있다. 이는 한 번에 여러가지 일을 할 수 있다는 것을 의미.
- 모든 CPU 명령어들은 독립적으로 수행.
- 캐시가 있지만 비교적 작기 때문에 RAM에서 대부분의 메모리를 끌어다 씀.
- 범용 처리에 적합하다.
GPU
- CPU에 비해 아주 많은 Core가 존재한다.
- 각각의 코어가 CPU에 비해 느리고, 많은 일을 하진 못함.
- 수많은 코어들이 하나의 task를 병렬적으로 수행함.
- 실제 RAM과 GPU 간 통신이 상당한 bottleneck을 초래하기 때문에 칩 안에 자체적으로 RAM을 내장하고 있음.
- 병렬 처리에 적합하다.
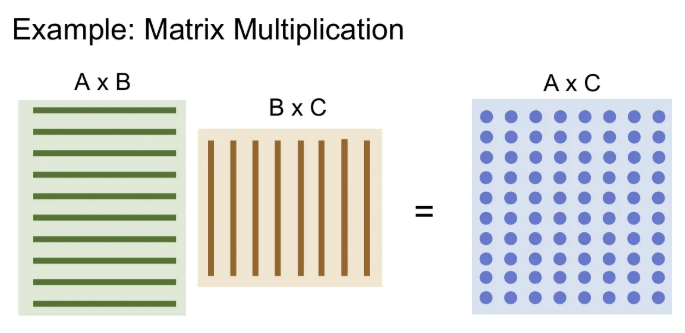
행렬 곱 연산을 수행할 때, GPU는 각 내적 연산을 각 core에 분배후 병렬로 계산 가능하여 CPU보다 훨씬 빠른 결과를 낼 수 있다. (행렬의 크기가 클 수록 차이는 많이 난다.)
Programming GPUs

우리 스스로 GPU의 성능을 전부 짜낼 수 있는 코드를 작성하려면 메모리 구조 관리(cache misses, branch mispredictions 고려)를 잘 해야하기 때문에 무리가 있다. 따라서 우리는 NVIDIA에서 배포한 다양한 라이브러리를 활용하면 된다.
- CUDA (NVIDIA GPU만 가능)
- cuBLAS → 다양한 행렬 곱을 비롯한 연산들을 제공하고, 이는 아주 고도로 최적화 되어있다.
- cuDNN → convolution, forward/backward pass, batch norm, RNN 등 딥러닝에서 필수적인 기본 연산들을 거의 모두 제공한다.
- cuBLAS → 다양한 행렬 곱을 비롯한 연산들을 제공하고, 이는 아주 고도로 최적화 되어있다.
이 외에도 OpenCL은 NVIDIA GPU가 아니어도 동작할 수 있지만, 강의 시점인 2017년 기준에서 딥러닝에 최적화된 연산이나 라이브러리가 개발되진 않아서 NVIDIA가 딥러닝의 선두 주자라고 한다. 이는 포스팅을 작성중인 2024년 기준에서도 마찬가지인 듯 하다. 직접 CUDA 코드를 짜지는 못하더라도, 어떤 방식으로 동작하는지는 알아두자!
CPU vs GPU in practice
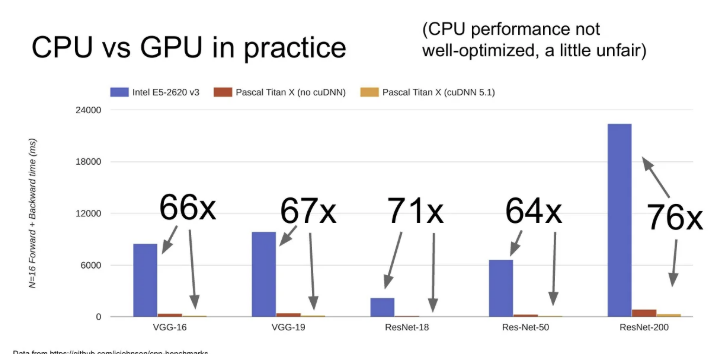
다양한 ResNet과 VGGNet 아키텍쳐를 학습시킬 때 CPU와 GPU(cuDNN 사용)의 속도차이는 위 슬라이드와 같이 어마어마하다. (물론 CPU로 학습시킬 때 성능을 극대화 시키진 않았지만, 했더라도 매우 유의미한 차이가 났을 것이다.)
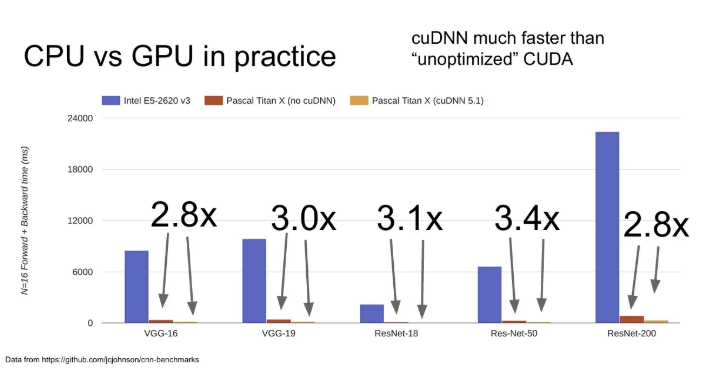
그리고 같은 GPU와 딥러닝 프레임워크를 사용하더라도, 일반 CUDA를 사용할 때와 cuDNN(convolution 연산에 최적화)을 사용할 때의 차이도 명확했다. cuDNN 사용하자!
CPU / GPU Communication

딥러닝 학습 시 우리의 모델과 가중치들을 모두 GPU RAM에 있지만, 데이터는 SSD에 있다는 사실을 알고, 이를 읽어들일 때 bottleneck이 발생하지 않도록 세심하게 신경 써야 한다.
- 데이터 셋이 작거나, 서버의 RAM 용량이 큰 경우에는 RAM에 데이터를 올려두기
- HDD대신 SSD를 사용.
- CPU의 다중 스레드를 이용해서 RAM에 미리 올려두기(pre-fetching)
Deep Learning Frameworks
다양한 딥러닝 프레임워크가 있고, 저마다 뚜렷한 장단점이 있다. 연구에 있어서는 Pytorch나 Tensorflow를 주로 사용한다. 이들을 활용하면 아래와 같은 공통적인 장점을 가진다.
- 복잡한 계산 그래프를 우리가 직접 만들지 않아도 된다.
- loss에 부합하는 weight의 gradient 계산을 쉽게 할 수 있다. (forward pass만 잘 구현해 놓으면 backpropagation은 알아서 구성된다!)
- GPU를 효율적으로 사용할 수 있다.
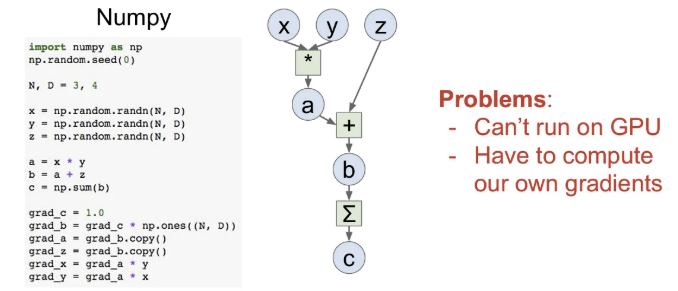
간단한 계산 그래프는 numpy로도 구현이 가능하긴 하겠지만, backward pass도 직접 구현해야하는 번거로움이 있고, numpy는 CPU에서만 동작한다.
따라서 딥러닝 프레임워크의 목표는 우리가 forward pass를 작성해 놓으면 이것이 GPU에서도 동작하고, gradient도 알아서 계산할 수 있도록 함이다.

같은 계산 그래프를 Pytorch로 구현한 예시를 보면, .cuda() 메서드를 통해서 GPU를 사용할지 CPU를 사용할지 지정 가능하고, backward() 메서드로는 모든 gradient를 계산할 수 있다.
강의에서는 이제 간단한 two-layer neural net을 Tensorflow, Keras, PyTorch에서 작성한 코드를 각각 비교하는데, 필자는 일단 주로 PyTorch를 활용하기에, 일단 PyTorch만 정리하였다.
PyTorch

PyTorch는 세 가지 추상화 레벨을 정의해 놓았다.
- Tensor
- Numpy array와 비슷하면서 imperative(명령형) 배열이고, gpu에서 동작한다. Numpy + GPU 라고 생각하면 됨.
- Variable
- 그래프의 노드라고 할 수 있다. 그래프를 구성하고 gradient 등을 계산 가능하다.
- Module
- Neural Network를 구성하는 layer들로 학습 가능한 가중치들을 저장한다.
아래에서 더 자세히 알아보자.
Tensor

PyTorch에서 Tensor는 Numpy array와 비슷하지만, Numpy array와 달리 이는 GPU에서도 동작한다는 큰 차이점이 있다.

방금 전 코드를 GPU에서 실행시키려면, data type만 torch.cuda.FloatTensor로 변경해주면 된다.
Autograd

Variable은 계산 그래프를 만들고, 이를 통해 gradient를 자동으로 계산하려는 등의 목적으로 사용한다.
위 코드에서 x가 Variable일 때 x.data는 그 값을 갖는 tensor이고, x.grad는 어떤 스칼라 값에 대한 x의 gradient를 담는 또 다른 Variable이고, 따라서 x.grad.data에 gradient가 담겨있다.

PyTorch의 Tensor와 Variable은 같은 API를 공유하기 때문에, PyTorch Tensor로도 동작하는 모든 코드는 Variable로도 만들 수 있다. 이렇게 되면 imperative한 연산자들이 수행되는 것이 아니라, 계산 그래프를 만드는 것이 된다.

이 때 requires_grad를 통해서 해당 Variable에 대한 gradient를 계산할 것인지 지정할 수 있다.

위와 같은 forward pass의 경우 아까 전 x를 Tensor로 정의했을 때와 똑같이 코드를 사용할 수 있다. (Tensor와 Variable은 같은 API를 공유하므로) loss는 L2 distance를 사용했다.

그리고 아래에서 loss.backwards() 함수를 호출하면 gradient가 반환 된다.

그리고 w.grad.data 값으로 w을 업데이트 해준다.

그리고 PyTorch에서는 torch.autograd.Function을 상속받아 우리만의 autograd 함수를 정의해서 사용할 수도 있다.

이렇게 직접 구현한 ReLU를 오른쪽 코드와 같이 계산 그래프에 적용할 수 있다. 그래도 대부분 필요한 연산들은 이미 PyTorch의 nn 패키지에 구현이 되어있다. 위에서 정의한 ReLU 클래스는 PyTorch에서 제공하는 torch.nn.ReLU와 같은 연산을 수행한다.
nn

PyTorch의 nn 패키지는 신경망과 관련된 high level wrappers를 제공해준다.

model에는 Linear/ReLU layer들을 순차적으로 갖는 Sequential 객체를 정의하고, loss_fn에는 mean squared error loss를 정의하였다.

그리고 매 반복마다 forward pass를 수행해서 예측 결과를 얻고, loss를 구한다.

그리고 loss.backward()를 호출하여 매 반복마다 gradient를 계산하고,

모델 업데이트를 위해 gradient descent step을 명시적으로 수행한다. 위와 같이 수행하면 각 파라미터에 대한 업데이트를 수행하게 된다. PyTorch에서는 forward pass를 할 때마다 새로운 계산 그래프를 만들어주는 것이 된다.
Optim

가중치 업데이트 시 Optimizer를 사용하려면, 슬라이드와 같이 optimizer를 추가해주고, 가중치 업데이트 부분을 추상화 하여 적용해줄 수 있다. 마지막에 optimizer.step()을 호출하면 optimizer에 맞추어 가중치 업데이트가 이루어진다.
nn.Module

그리고 이제 전체 네트워크 모델이 정의되어있는 클래스를 torch.nn.Module을 상속받아 우리만의 nn modules를 정의하여 사용할 수도 있다.
module은 일종의 network layer이고, 다른 module이 포함될 수도 있으며 학습 가능한 가중치도 포함 될 수 있다.

생성자를 보면 두개의 Linear module을 저장하고 있다.

그리고 forward pass를 보면, 앞서 생성자에서 정의한 linear1, linear2 모듈을 활용 가능하고, 다양한 autograd도 사용 가능하다.

아래에서는 마찬가지로 optimizer를 구성하고 반복문을 돌면서 데이터를 넣고, loss.backwards() 로 gradient를 구한 후 optimizer.step()으로 가중치 업데이트를 한다.
DataLoaders

DataLoader는 미니배치 관리에 용이하다. 학습 도중 disk에서 미니배치를 가져오는 일련의 작업들을 multi-threading을 통해서 알아서 관리해준다.

loader에 우리 데이터를 batch size 8의 TensorDataset으로 명시하여 작성해주면, 이 학습이 진행되는 동안 이 loader 객체를 순회하면서 매 반복마다 적절히 x_batch와 y_batch에 전체 데이터의 미니배치를 반환해준다. 내부적으로 data shuffling이나 multithreaded dataloading 등을 알아서 관리해준다.
Pretrained Models

유명한 CNN 아키텍쳐들을 불러오는 방법도 아주 간단하다. torchvision을 import하고 위와 같이 불러주면 된다. 이 때 사전학습 된 모델들로 불러오고 싶다면, pretrained=True로 지정해주면 된다.
Static vs Dynamic Graphs
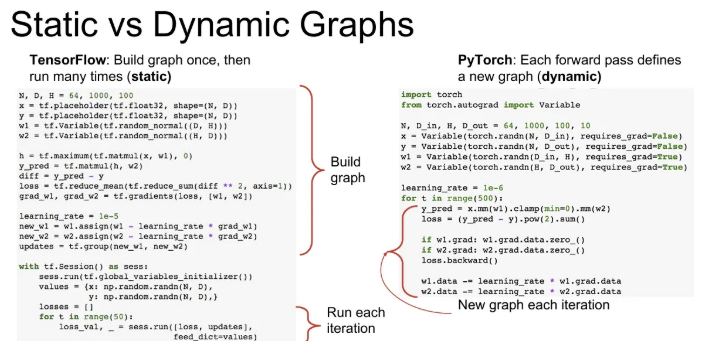
Tensorflow는 static(정적)이고, PyTorch는 dynamic(동적)이다. Tensorflow는 계산 그래프를 사전에 만들어 놓고 학습을 시키는 반면, PyTorch는 매 반복 시 새로운 계산 그래프를 만들어 내는 방식이다.
Static graph 장점
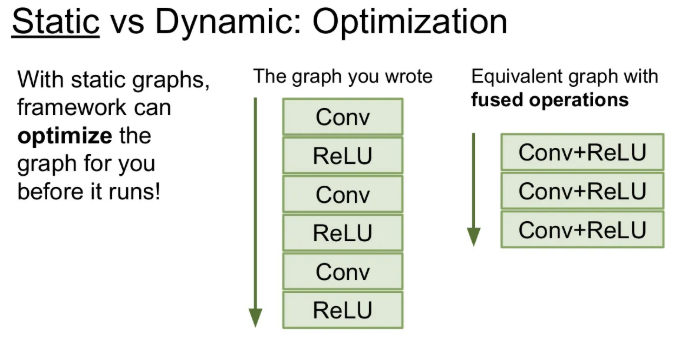
그래프를 한 번 구성해 놓으면 학습 시에 같은 그래프를 계속해서 재사용한다. 이는 일부 연산들을 합쳐버리고 재배열 시키는 등으로 그 그래프를 최적화시킬 기회가 주어지는 것이다.
그래프 하나만 가지고 아주 여러 번 사용하므로 처음 최적화 작업이 오래 걸릴 순 있어도, 최적화 된 그래프를 여러 번 사용하는 것을 고려하면 이는 그다지 신경 쓸 필요 없다.

static graph를 사용하여 그래프를 구성할 때 그래프를 한 번 구성해 놓으면 메모리 내에서 그 네트워클 구조를 가지고 있다. 그렇다면 전체 네트워크 구조를 파일 형태로 저장할 수 있고, 원본 코드 없이도 그래프를 다시 불러올 수 있다.
이는 파이썬으로 학습시킨 네트워크를 serialize 하게 되면 c++ 환경에서도 쉽게 동작시킬 수 있도록 한다. 그래프를 구성하는데 기존 코드가 필요 없다.
Dynamic graph 장점

만약 위 슬라이드와 같이 값에 따라 다른 연산이 주어진다면, PyTorch의 경우 매번 새로운 그래프를 만들기 때문에 현재 forward pass에 적절한 하나를 선택하면 되지만, Tensorflow의 경우 그래프를 하나 더 만들어서 명시적으로 조건부 연산을 정의해야 한다. 이는 Tensorflow의 if문 역할을 한다. 즉, Static 방식에서는 가능한 모든 control flow를 미리 고려해서 그래프를 실제로 실행시키기 전 그래프 내에 한 번에 넣어줘야 한다. 이 때 간단한 python 문법이 아닌, tf.cond같은 특수한 연산자가 필요하게 된다.
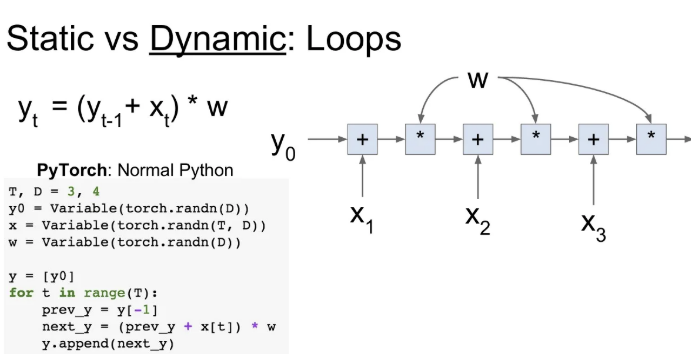
Dynamic graph는 재귀적인 연산이 필요한 경우, 데이터의 sequence 길이를 신경쓰지 않고 연산이 가능하다. for문으로 쉽게 그래프를 만들 수 있고, 이는 backpropagation에도 지장이 없다. Tensorflow는 명시적으로 loop를 넣어줘야만 한다.
Recommendation

본 포스팅에서는 Tensorflow나 Caffe에 대한 정리를 따로 하지는 않았지만, 큰 틀에서 장단점을 뽑아보자면,
- PyTorch는 연구에 적합하고, Dynamic graph가 필요한 task들에 강세를 보인다.
- Caffe는 제품 개발에 적합하다.
- Tensorflow는 두 경우 모두 좋지만, 기본적으로 static graph이기 때문에 하나의 그래프 형태만 사용하는 경우에 좋다.
Reference
