
✍ 해당 시리즈 포스팅은 스탠포드 대학의 cs231n 강의 내용을 정리한 글입니다.
Optimizations
Problems with SGD

이전에 배웠던 Stochastic Gradient Descent(SGD)의 코드이다. 단순히 미니배치의 데이터에서 loss를 계산한 후, gradient의 반대 방향(내려가는 방향)을 이용해서 파라미터 벡터를 업데이트 한다. 이 간단한 알고리즘을 적용하게 되면 실제로 발생하는 문제들이 있다.
Poor Conditioning

만약 손실함수가 위처럼 생겼고, 가운데 최적점에 도달하려 할 때, 수평 축의 가중치는 변해도 loss가 아주 천천히 줄어들고, 수직 방향의 가중치 변화에 훨씬 더 민감하게 된다. 이런 경우 loss는 bad condition number를 갖고 있다고 하고, 이는 이계도함수를 행렬로 표현한 Hessian matrix의 최대/최소 singular values들 값이 비율이 매우 안 좋다는 것이다.

이런 경우 loss의 gradient 방향이 고르지 못하여 지그재그 형태를 띠면서 가중치 업데이트가 이루어지게 되고, 이렇게 되면 최적화에 시간이 오래 걸린다. 그리고 이런 현상은 고차원 공간에서 훨씬 자주 발생한다.
Local Minima
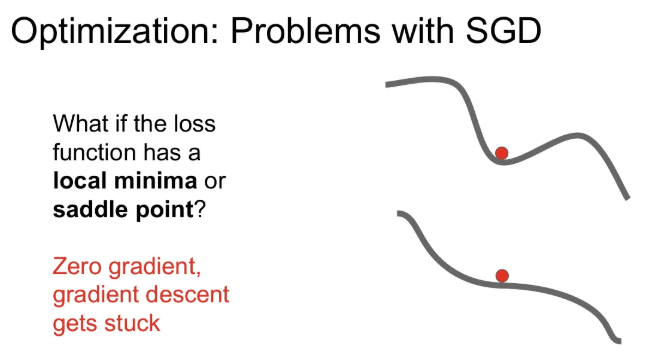
위 그림처럼 손실 함수에서 local minima를 만나게 되면 gradient는 0이 되고, 학습은 멈추게 된다.
Saddle Point

local minima는 아니지만, 아래 그림처럼 평탄한 지역에 빠지게 된다면, 이런 saddle point에서도 gradient 값이 0이 되어 학습이 멈추는 경우가 발생할 수 있다.
차원이 훨씬 더 증가하게 된다면, 이 Saddle point는 local minima보다 훨씬 빈번하게 발생하여 Neural Network를 취약하게 만드는 공신이다.
그리고 이는 saddle point 뿐 아니라, 그 근처에서도 기울기가 매우 작기 때문에 업데이트가 매우 느리게 진행된다.
Noisy Gradients
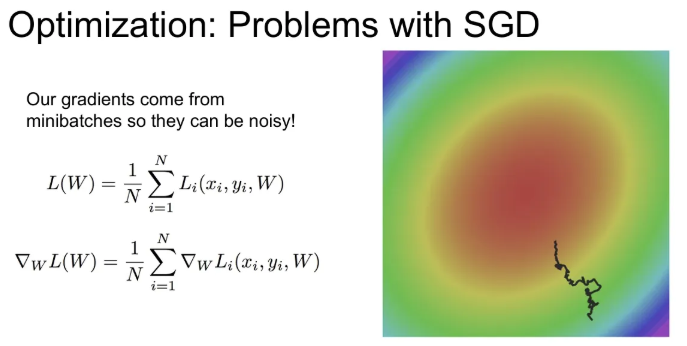
데이터 셋 전체의 loss를 계산하려면 시간이 너무 오래 걸리기 때문에 미니배치의 데이터로 실제 loss를 추정하기만 하는데, 이는 gradient의 부정확한 추정값(noise estimate)을 구하는 것이 되고, 이로 인해 학습 방향이 자주 왜곡될 수 있다. 이로 인해 학습 시간이 늘어나게 된다.
위 단점들은 사실 Full Batch Gradient Descent 방식을 쓴다고 해도 완벽히 해결될 수 없다곤 한다.
SGD + Momentum

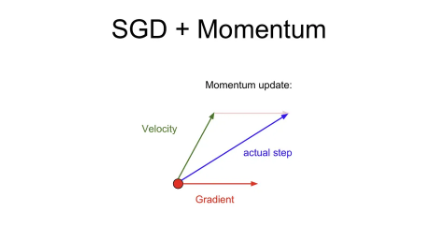
SGD에서 현재 미니 배치의 gradient 방향만 고려하는 것이 아니라 velocity(속도)도 같이 고려하는 것. 라는 하이퍼파라미터를 추가하여 이에 대한 비율도 조절이 가능하다. (보통 0.9나 0.99의 높은 값으로 설정) exponential moving average 방식
velocity의 비율()을 곱해주고 현재 gradient를 더함. 따라서 gradient vector 그대로의 방향이 아닌 velocity vector의 방향으로 나아가게 된다.
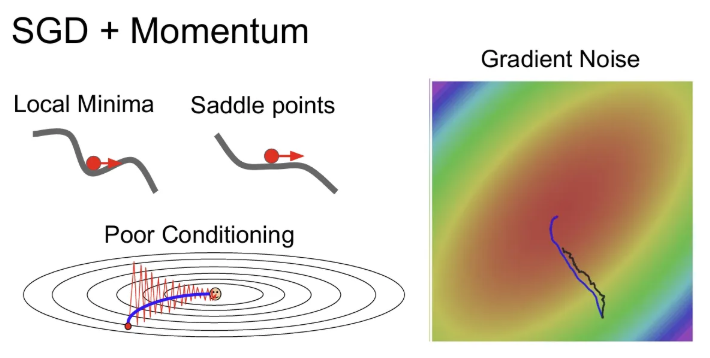
- 실제로 경사면에서 공을 굴릴 때를 대입해서 생각해보면, 이전 예시와 같은 local minima와 saddle point의 경우에 도달해도 위에서 굴러오던 속도가 아직 남아있고, 따라서 gradient는 0이어도 아직 속도 값이 남아서 learning rate와 곱한 뒤 에 더해지기 때문에 학습이 바로 멈추진 않게 된다. → local minima, saddle points 해결
- Momentum이 지그재그 변동을 서로 상쇄 시켜주고, 이를 통해 loss에 민감한 수직 방향의 변동은 줄여주고 수평 방향의 움직임은 가속화 된다. → Poor Conditioning 해결
- velocity가 생기게 되면 결국 noise가 평균화 되어 SGD보다 훨씬 부드럽게 minima를 향해 움직인다. → Noisy gradients 해결
Nesterov Momentum
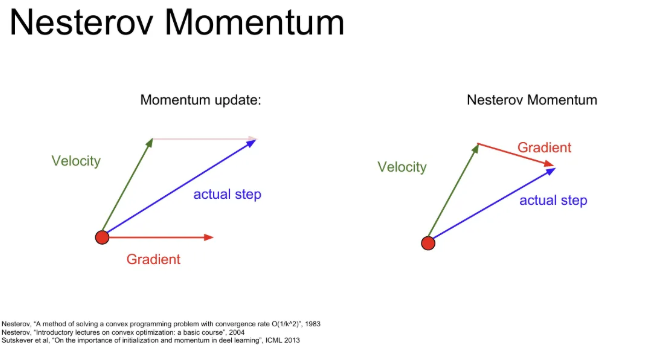
SGD + Momentum과 유사하지만, 계산 순서만 바뀌었다. 기본 SGD + Momentum은 현재 지점에서의 gradient를 계산한 뒤 velocity와 합해주지만, Nesterov Momenum은 우선 velocity 방향으로 움직여준 후, 그 지점에서의 gradient를 계산한다. 그리고 다시 원점에서 그 둘을 합해준다.
velocity와 gradient 두 정보를 약간 더 섞어준다고 생각할 수 있고, velocity의 방향이 잘못되었을 경우 현재 gradient의 방향을 좀 더 활용할 수 있도록 해준다.
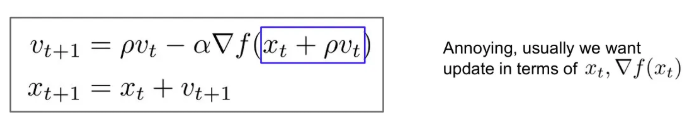
velocity를 업데이트 할 때 이전 시점의 velocity와 에서의 gradient를 계산하고, step update는 방금 구한 를 활용해서 구한다.
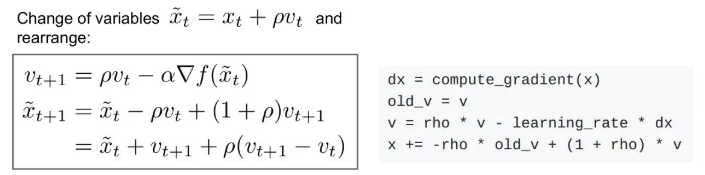
이제 를 로 치환해서 수식을 조금 변경해보면 아래와 같이 나타낼 수 있다. 유도 과정은 아래와 같다.

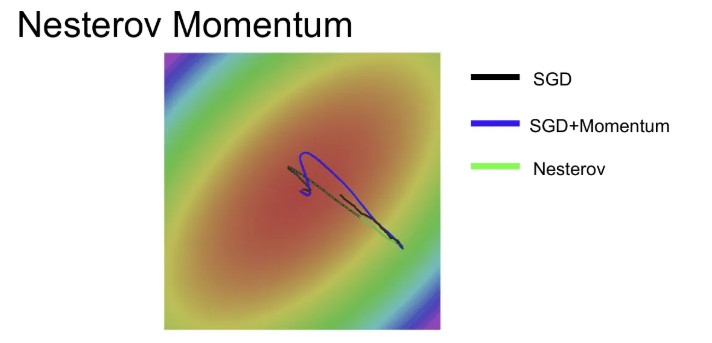
기존 SGD 방식은 속도가 느린 편이고, Momentum 계열은 이전 velocity의 영향을 받아 minima를 그냥 지나쳐 버리는 경향이 있기는 하지만, 결국 다시 돌아와서 minima에 수렴하는 경향이 있다.
→ 만일 minima가 좁고 깊다면 minima를 지나쳐서 다시 돌아오지 못하는 경우가 발생할 수도 있다. 하지만, 이런 좁고 깊은 minima는 심한 overfitting 문제를 가져올 수 있기 때문에 애초에 선호되지 않는 minima이고(평평한 minima가 일반화를 잘 함), 데이터의 크기가 커질수록 이런 민감한 유형의 minima는 줄어든다고 한다.
AdaGrad

- 훈련 도중 계산되는 gradient를 제곱하여 gradient squared term에 계속해서 더한다.
- 그리고 업데이트 시에는 이 gradient squared term의 제곱근을 update term에 나눈 값으로 업데이트 해준다.

Poor Conditioning이 존재하는 경우, 작은 차원에서는 gradient 제곱을 합한 값이 작아지게 되고, update term에 그만큼 작은 값을 나눠주기 때문에 비교적 업데이트가 크게 이루어지고, 반대로 큰 차원에서는 update term에 큰 값을 나눠주기 때문에 업데이트가 작게 된다.
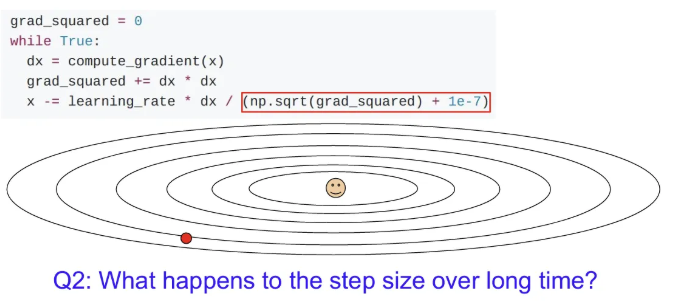
하지만 학습 횟수가 증가하게 된다면 gradient squared term의 값은 점점 커지기 때문에, step size는 점점 작아지게 된다. 이는 Convex(볼록)한 경우에는 장점이 될 수 있지만, saddle point 같은 지점이 존재한다면 학습이 멈추게 될 수 있다. 이는 RMSProp에서 개선되었다.
RMSProp
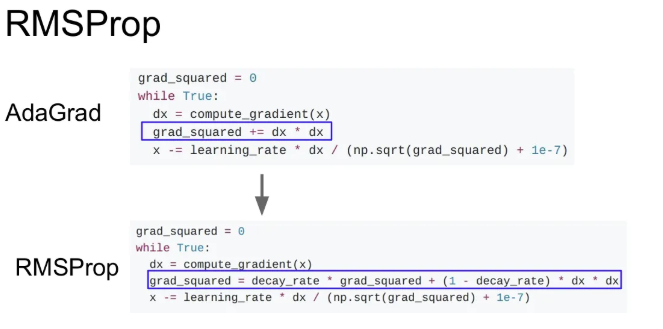
AdaGrad에서 gradient squared term을 그대로 사용하지만, 단순한 gradient 제곱의 누적이 아니라, 기존 누적 값에 decay_rate를 곱한 값에 현재 gradient 제곱에 1-decay_rate를 곱한 값을 더한다. decay_rate는 보통 0.9 또는 0.99를 사용하고, Momentum처럼 exponential moving average 방식이다.
Adam
여태까지 Momentum 계열과 Ada 계열의 방식들을 살펴보았는데, 두 방식을 합한 알고리즘이 바로 Adam 이다.

위 코드는 완전한 Adam 방식은 아니고, 우선 Momentum과 RMSProp을 섞은 형태이다. 여기서 first moment는 gradient의 가중 합이고, velocity를 담당한다. second moment는 gradient의 제곱을 이용한다.
이 때 초기 second moment를 0으로 초기화 하고 업데이트를 진행해보면, beta2(decay_rate)는 1에 가까운 값이기 때문에 1회 업데이트를 진행해도 여전히 second moment는 0에 가깝다. 그리고 를 업데이트 시에 이 0에 가까운 second_moment로 나눠주게 되면 초기 step이 너무 큰 값이 될 수 있다. 따라서 Adam에서는 이를 해결하기 위한 term을 추가했다.

그래서 완전한 Adam의 형태는 first, second moment 들을 업데이트 해준 후, Bias correction을 추가해준다. 이 과정은 현재 step(t) 에 맞는 unbiased term을 계산해준다.
Adam 알고리즘은 보통 beta1은 0.9, beta2는 0.999, learning rate는 1e-3나 1e-4로 설정해주면 웬만한 아키텍쳐에서 잘 동작한다고 한다.
Optimizing Learning Rate
SGD, Momentum, AdaGrad, RMSProp, Adam 모두 learning rate가 중요한 하이퍼파라미터라는 사실은 변하지 않는다. 따라서 learning rate를 정하는 데에도 다양한 방법이 있다.
Learning rates decay

learning rate가 적당히 높다면 학습 초반엔 loss가 급격히 줄어들지만 진행될수록 최적점을 찾기 힘들고, 적당히 낮다면 최적점을 찾을 순 있지만 loss값은 천천히 줄어든다.
각각의 learning rates의 특성을 적절히 이용해서, 처음에는 learning rate를 높게 설정해서 학습이 진행될수록 점점 낮추는 방법이다.
Adam보다는 Momentum 방식에서 잘 동작한다고 한다. 그래도 우선 decay 없이 최대한 learning rate를 잘 설정해서 학습해보는 것이 중요하고, loss curve를 잘 살펴보면서 필요하면 활용하는 것이 좋다.
step decay, exponential decay, 1/t decay 방식이 있다.
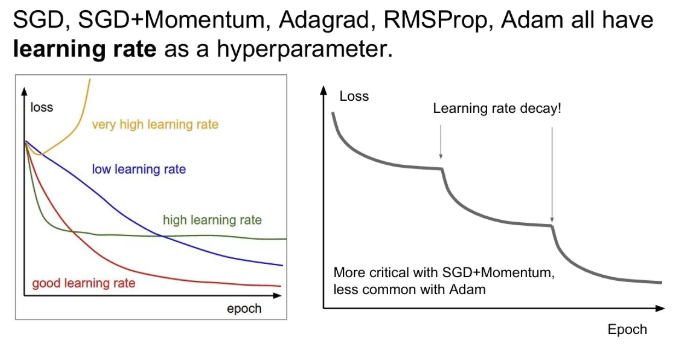
ResNet 논문에서도 step decay 방식을 사용하였는데, loss가 갑자기 하락하는 구간이 learning rate를 낮추는 구간이다.
딥러닝 논문들을 처음 읽어볼 때 쯤 ResNet 논문을 읽었었고, 1년이 넘게 지난 시점이어서 오랜만에 그림을 다시 보았다. 당시에는 그냥 loss가 잘 줄어드는구나~ 만 생각하고 특정 구간에서 대폭 줄어드는 이유에 대해선 딱히 의문을 가지지 않았는데, 이제서야 이유를 알았다…
Second-Order Optimization
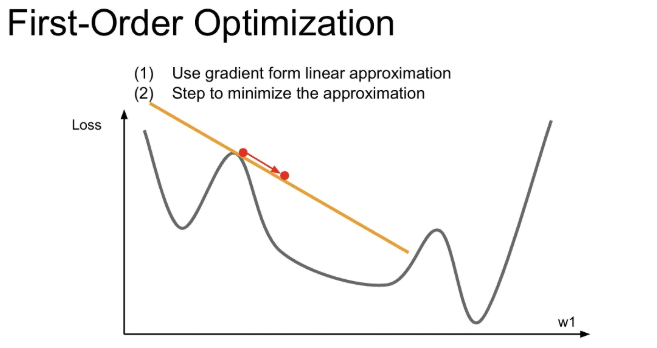
지금껏 1차 미분값을 사용하는 방법은 손실함수를 선형함수로 근사시켜서 step을 내려가는 방법이었다.
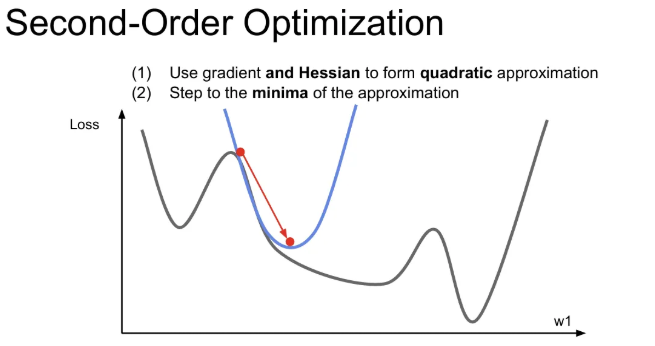
이에 추가로 2차 근사 정보를 활용하는 방식이 second-order optimization이다. 이는 2차 테일러 근사 함수가 되고, 2차 함수의 모양을 보인다. 이를 활용해서 minima에 더 잘 근접할 수 있다는 idea이다.
2차 미분값들로 된 행렬인 Hessian matrix의 역행렬을 이용해서 실제 함수의 2차 근사를 이용하여 minima로 곧장 이동한다.

second-order optimization 기본 버전의 장점은 learning rate가 없다는 점이다. 하지만 정확히는 minima로 이동하는 것이 아니라, minima의 방향으로 이동하는 것이기 때문에 이 2차 근사도 완벽하다고 볼 순 없다.


하지만 불행히도 헤시안 행렬의 크기는 (은 파라미터 수)이 되고, 계산하기엔 너무 큰 값이 될 수도 있기 때문에, Quasi-Newton methods를 활용하여 전체 헤시안 행렬을 그대로 사용하진 않고 근사시켜서 활용할 수 있다.
대표적인 방법으로 L-BFGS(Limited memory BFGS)가 있는데, 2차 근사가 stochastic case에서 잘 작동하지 않고, non-convex 문제에도 적합하지 않기 때문에(딥러닝은 대부분 non-convex), 사실상 DNN에서는 잘 사용되진 않는다고 한다.
Beyond Training Error
Train set이 아닌, 한 번도 보지 못했던 데이터(test set)에서의 성능을 올리기 위한 방법들에는 어떤 방법들이 있을까?
Model Ensembles

다양한 독립적인 모델들을 학습 시킨 후 평균을 결과로 이용하는 방법인데, 모델 수가 증가할수록 overfitting은 줄어들고 성능이 향상될 수 있다. (대회 같은 경우 쥐어짜기할 때 많이 쓰임)
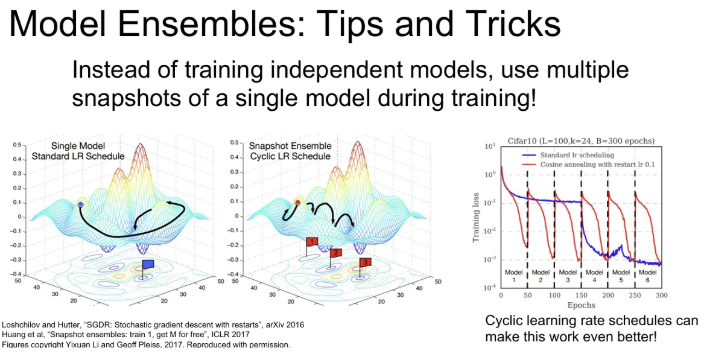
단순히 n개의 독립적인 모델을 학습 시키는 방식이 아닌, 단일 모델에서 학습 중간 중간 모델을 저장(snapshots)하고, 이들을 앙상블 하는 방식도 있다. Learning rate를 엄청 낮췄다가 높혔다가를 반복하면서 손실함수의 다양한 minima에 수렴할 수 있도록 할 수 있다. 물론 학습은 한 번만 시켜도 됨.
Regularization
앙상블 없이 단일 모델의 test set에 대한 성능을 최대한 끌어올리고자 추가하여 모델이 training data에 fit 하는 것을 막아준다.
Add Term To Loss

Loss에 추가적인 Regularization term을 추가한다.
- L2 Regularization
- L1 Regularization
- Elastic Net
하지만 위와 같은 regularization 기법들은 Neural Network와는 잘 어울리진 않아서 아래와 같은 기법들이 주로 사용된다.
Dropout
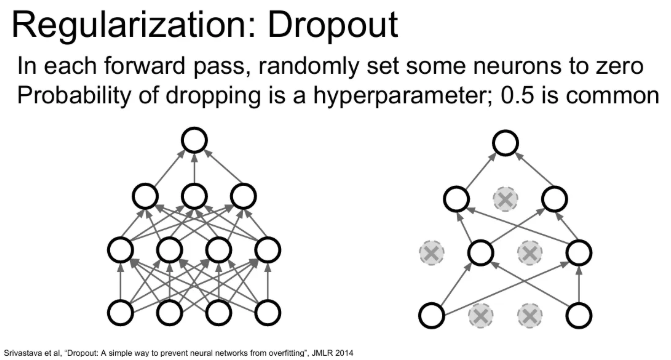
- Forward pass 과정에서 일부 뉴런을 임의로 0으로 만드는 방법이다. (오른쪽)
- 대체로 확률은 0.5로 설정한다. (하이퍼파라미터)
- Conv Net의 경우 전체 feature map에서 dropout을 실행한다.
- feature 간 상호작용(co-adaptation)을 방지한다.
- 각 step마다 업데이트되는 파라미터의 수가 줄어들기 때문에 학습 시간은 늘어난다.
- Batch Normalization도 비슷한 역할을 수행해줄 수 있기 때문에 둘을 함께 사용하진 않는다. 대신 Dropout에는 조절 가능한 하이퍼파라미터 가 있다.
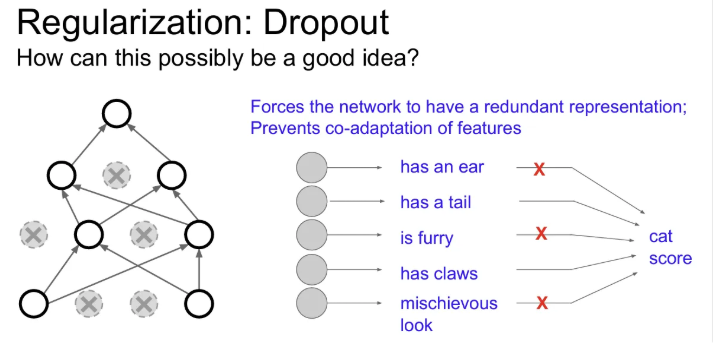
만약 고양이 이미지를 분류하는 Network를 만들고 각 뉴런 별로 각기 다른 고양이의 특징들을 학습하였을 때, 특정 feature들에만 의존하는 것을 방지하고 예측에 다양한 feature들을 골고루 이용할 수 있도록 해주는 역할이 가능하다. 그리고 이런 역할은 당연히 overfitting을 방지해줄 수 있다.
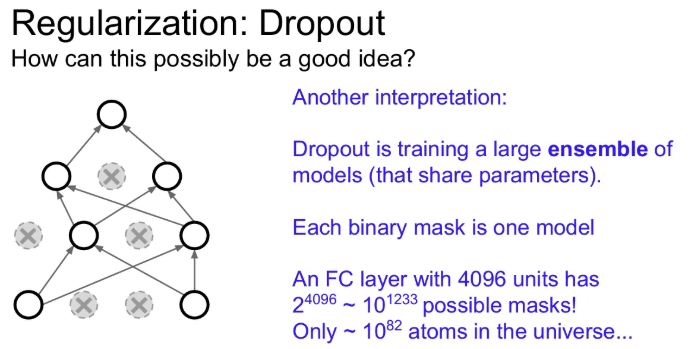
그리고 어떤 관점에 따라서는 Dropout이 단일 모델에 서로 파라미터를 공유하는 서브 네트워크 앙상블들을 동시에 학습시키는 것으로 생각할 수도 있다.

하지만 Test 시에도 dropout을 사용하게 되면 입력 와 가중치 를 받아서 함수에 통과시켜 결과를 얻는 방식에 random dropout mask인 라는 입력이 추가된다. 이런 임의성(stochasticity)을 띄는 값은 test 시에 주는 것은 좋지 않고, 대신 를 여러 번 샘플링해서 test time에 average out 시키는 방법을 쓸 수 있지만 이 역시 랜덤성을 만들 수 있다.

와 라는 두 개의 input을 받아서 각각 과 와 곱해서 를 얻는다고 할 때, test 시에는 의 기댓값을 갖지만 train 시에는 이 절반만큼의 기댓값을 갖게 된다. 그래서 간단히 test 시에 stochasticity를 사용하지 않고 싸게 사용할 수 있는 방법은 단순히 test 출력에 dropout probability를 곱해주는 것이다.
Data Augmentation
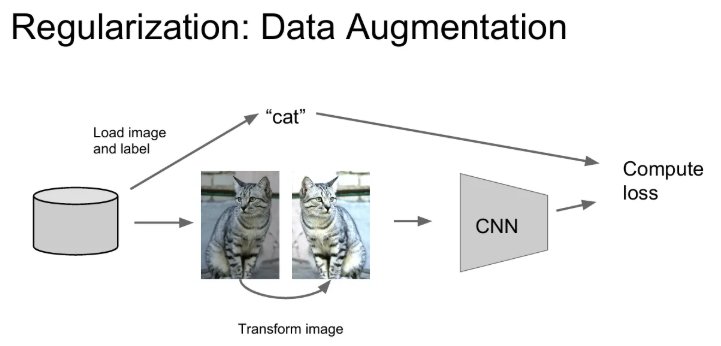
우리가 가진 데이터에서 레이블은 그대로 둔 채 변형시킨 이미지도 함께 학습에 활용하는 방법이다. Train time에 입력 데이터에 임의의 변환을 시켜주면 학습 시엔stochasticity가 추가되고 test 시에는 marginalize out(관심있는 변수에 집)이 되기 때문에 regularization 효과가 있다. 아래와 같은 기법들이 있다.
- Horizontal flips
- Random crops and scales
- Color jitter
- 그 외에도 rotation, translation, stretching, shearing, 등등의 다양한 조합 가능
Horizontal Flips
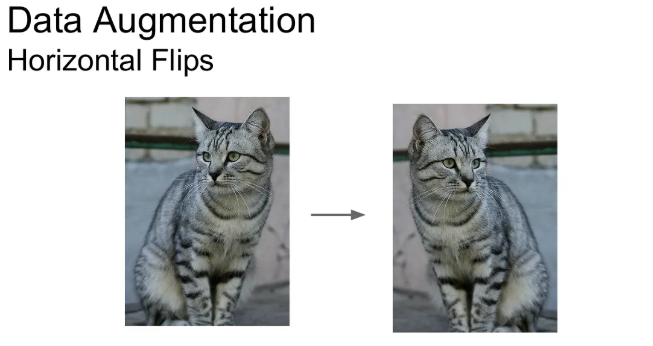
→ 이미지를 좌우 반전 시키는 방법
Random Crops and Scales

→ 이미지를 임의의 다양한 사이즈로 잘라서 활용하는 방법
Color Jittering

→ 학습 시 이미지의 contrast, brightness를 바꿔주는 방법. PCA의 방향을 고려하여 color offset을 조절하는 방법도 있다.
DropConnect
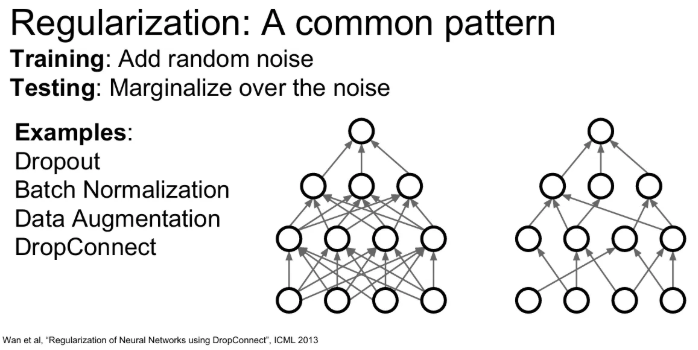
activation이 아니라 weight matrix를 임의적으로 0으로 만들어주는 방법으로, Dropout과 동작이 아주 비슷하다.
Fractional Max Pooling
기존의 2x2 max pooling에서 처럼 고정된 2x2 지역에서 pooling을 하는 것이 아니라, 임의의 지역에서 pooling 연산을 한다.
Stochastic Depth
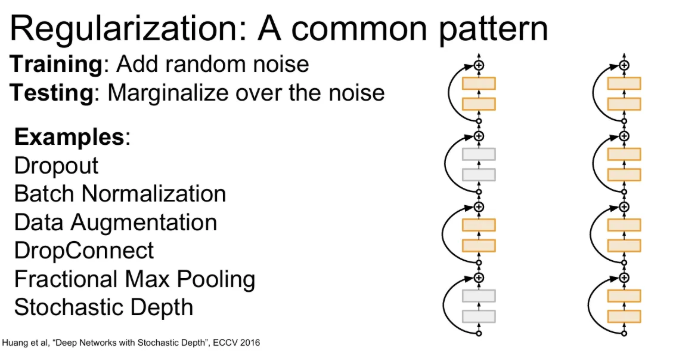
Train time에 layer 중 일부를 제거하고 나머지 일부만 사용해서 학습하고, test 시에는 전체 네트워크를 다 사용한다.
이렇게 다양한 Regularization 방법들이 있지만, 대체로 Batch Normalization만으로도 충분하고, overfitting이 발생한다 싶으면 다른 기법을 추가해주는 게 일반적이라고 한다.
Transfer Learning
Overfitting이 일어날 수 있는 상황 중 하나는 충분한 데이터가 없을 때인데, 충분한 데이터가 없어도 기존에 거대한 데이터 셋에서 학습된 모델을 우리가 가진 새로운 데이터 셋에 적용하는 것이다. Image Classification task 뿐 아니라 아주 다양한 task들에 방대하게 사용 가능
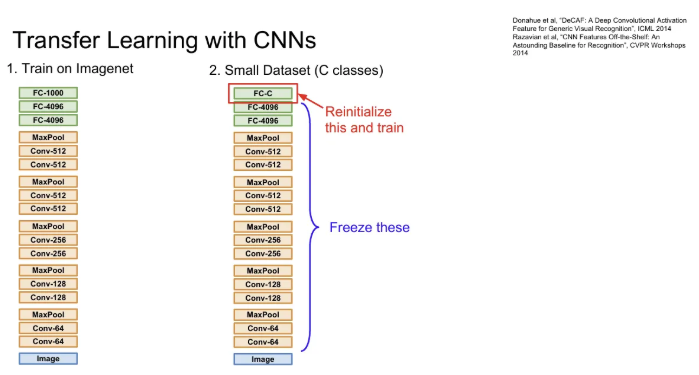
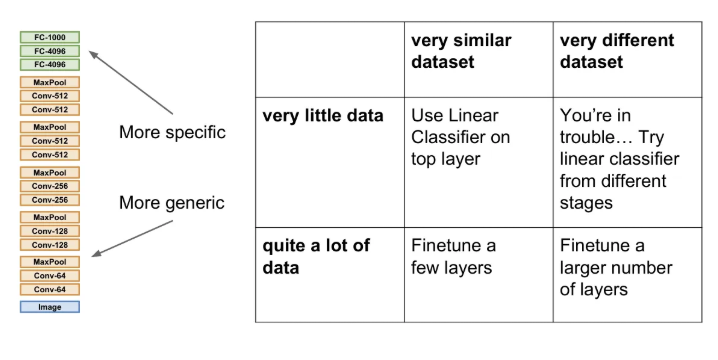
기존에 특정 CNN Architecture에 ImageNet으로 1000개의 카테고리를 분류하는 학습을 한 후 매우 적은 데이터의 10 종의 강아지 분류를 하고자 한다. 가장 마지막의 Fully Connected Layer는 최종 feature와 class scores 간의 연결인데 이는 4096 x 1000 행렬을 4096 x 10으로 바꿔주고 초기화 시킨다. 그리고 이전의 나머지 layer들의 가중치는 freeze 한 후 학습을 진행하면 마지막 layer만 갖고 학습을 시켜주는 것과 같다.
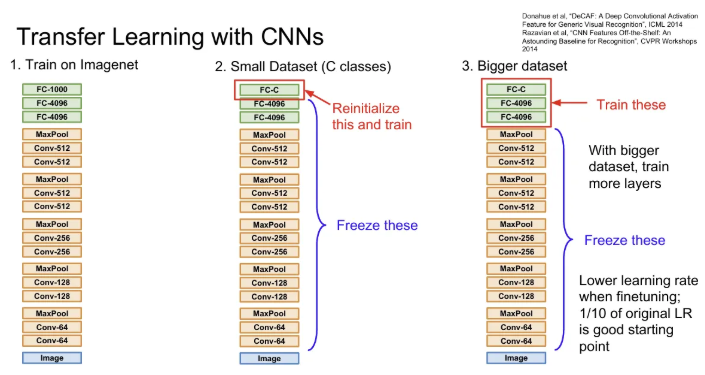
만약 좀 더 큰 데이터가 있다면, 전체 네트워크를 모두 얼리지 않고 일부는 업데이트를 허용해서 학습할 수도 있다. 이 때 learning rate는 기존보다는 낮춰서 사용한다.
아래 그림을 보고 경우에 맞춰서 활용해주면 된다.
Reference
