https://arxiv.org/pdf/2401.16402
1. Introduction
Visual Anomaly Detection (VAD)는 visual data에서 normality(정상성)의 개념에서 벗어나는 편차를 찾는 것을 목표로 한다. 본 논문에서는 VAD의 최근 발전을 종합적으로 검토하여, 세 가지 주요 도전 과제를 식별한다.
- 학습 데이터의 부족
- 실용적인 VAD 시스템은 종종 학습을 위한 풍부한 비정상 샘플을 모으는데 어려움
- 특정 응용 시나리오에서는 데이터 프라이버시 문제로 정상 데이터에도 접근 불가
- 이렇게 학습 데이터의 부족은 중요한 도전 과제를 제시하고, 부분적으로 관찰된 샘플에서 모델을 학습 시켜 open-world 환경에서 이상을 탐지해야 함
- Visual modalities의 다양성
- VAD는 컬러 카메라나 레이더 스캐너와 같은 다양한 영상 장치를 이용하여 시각 정보를 수집하는데, 이러한 다양한 영상 기술의 활용은 서로 다른 visual modalities를 도입하며 이를 효과적으로 통합해야 함.
- 계층적 이상의 복잡성
- Structural anomalies: visual scratch같은 local regions에서 발생하는 이상
- Semantic anomalies: logical mismatch같은 normal context를 이해하는 데 있어서 높은 수준의 이해를 요구
이러한 도전 과제들을 해결하기 위한 배경 및 최근 연구 트렌드를 2,3절에서 다루고, 4절에서는 잠재력 있고 급 부상 중인 future research directions에 대해 다룰 예정.
2. Background
본 섹션에서는 VAD의 배경을 간략히 살펴보고, 개념적 정의와 VAD에 대한 일반적인 공식을 포함. 그리고 주요 datasets와 metrics를 살펴보고, 이와 관련된 연구들을 소개
Concept Definition
- Visual data는 네 가지 기본 카테고리로 분류: Data point, entity, relation, frame
- Data point 는 영상 장치에 의해 포착되는 가장 작은 식별 가능한 요소를 의미(e.g. 2D 이미지에서는 픽셀, point cloud에서의 포인트)
- Entity 는 실세계 객체를 나타내는 data points의 cohesive set. 으로 표기되며 entity는 개별 data points를 포함하여 함께 의미있는 요소를 형성
- Relation function 는 여러 Entities를 입력받아 이를 결합하여 visual frame을 형성
- Frame = 는 서로 다른 entity 간 상호 관계를 캡슐화하고, 시각적 장면 내의 맥락적 정보를 포착
- Anomaly concept는 정상성의 개념에서 벗어나는 관찰을 의미. Visual data의 이상은 계층적 관계를 나타내며, low-level의 이상이 higher-level의 이상으로 전파될 수 있음. (e.g. 개별 data point 의 오류는 entity 의 형성에서 이상으로 이어질수 있음)
- Structural anomalies는 개별 data points 의 통합과 entities 내에서의 조직에 초점을 둠. 이는 의료 시각 데이터에서의 병변이나 산업 검사에서의 결함과 같은 local structure 편차를 탐지하는 데 유용
- Semantic anomalies는 더 높은 계층 level에서의 편차를 포함하며 entity, relation, frame level을 아우름. (e.g. 도로 위의 미확인 객체) 이는 entity 간 맥락적 연결의 부정확성을 포함하고, frame level에서는 전체 시각 획득에서의 비정상성을 나타내며, 일반적으로 novelty detection과 one-class classification이 포함 됨
- Visual anomaly Detection (VAD)는 시각적 이상을 탐지하기 위한 모델을 개발하는 것을 목표로 함.
- 해당 task는 학습 데이터 셋인 을 포함하며 이는 정상 frame인 과 이상 frame인 를 포함하며 각 frame에는 hard labels로 표현된 ground truth가 함께 제공됨.
- 주된 목표는 을 통해 로 매개화된 discriminative function → 를 설정하여 label이 없는 frames 에 정확한 anomaly scoes(이상 점수)를 정확히 부여하는 것.
- 최근 발전된 연구는 data point-level, entity-level, relation-level 등의 더 디테일한 anomaly scores의 필요성을 강조.
Scope of This Survey
특히, VAD는 산업 분야에서 상당한 발전을 이룸. 분야에 따른 방법론의 차이에도 VAD에 대한 기본적인 원칙은 상당한 일관성을 보여주고, 이에 따라 결과적으로 본 survey에서는 산업 시나리오 내의 VAD에 전략적으로 초점을 두어 대표 사례로 삼아서 전체 VAD에 대한 세심하고 철저한 검토를 제공하고자 함.
산업 시나리오 내의 semantic anomalies는 주로 relation-level에서 나타나며, 이를 도전 과제로 점점 더 많은 주목을 받고 있음
Datasets & Metrics
VAD의 최근 발전은 MVTec-AD, MVTec-3D, MVTec-LOCO, VisA 등 여러 데이터 셋의 영향을 크게 받고 있고, 이러한 데이터 셋이 제공하는 예측 확률 분포와 실제 확률 분포 간의 alignment(정합성)은 VAD의 성능을 평가할 수 있음.
이를 위한 다양한 Metrics이 사용되며, Area Under the Receive Operating Characteristic curve (AUROC), Area Under the Per-Region-Overlap curve (AUPRO)등이 사용됨.
Comparison to Other Surveys
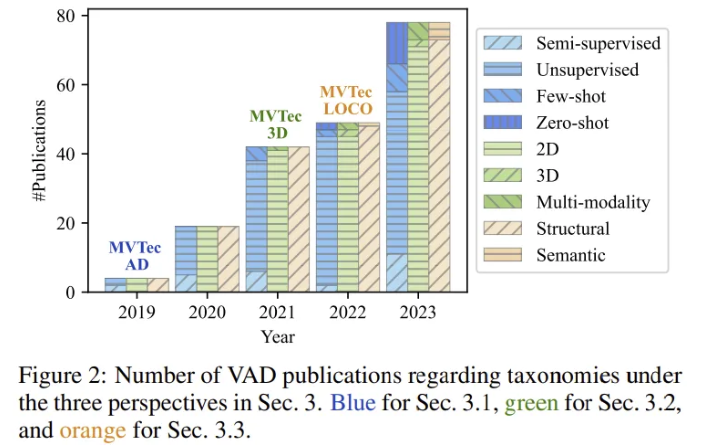
VAD의 최근 발전은 특히 structural anomalies가 있는 2D 데이터에 맞춰져 이루어졌고, 위 그림을 통해 Unsupervised 방식의 우세함도 확인 가능. 특히 MVTec AD, MVTec 3D, MVTec LOCO와 같은 milestones의 영향을 받아 앞서 언급된 세 가지 도전 과제를 다루는 sub-setting들이 유망한 발전을 많이 보여주었음.

그리고 본 survey는 논문은 위 표에서 강조된 바와 같이 이전에 작성된 survey들 보다 신흥 트렌드에 대한 검토를 더 많이 포괄하고, 종합적인 탐구를 수행하였음.
3. Taxonomy
본 섹션에서는 앞서 언급한 세 가지 관점에 대한 이전 방법론 및 그 예시들을 검토

3.1. From the Perspective of Sample Number

실제 시나리오에서 데이터의 부족이라는 도전에 직면하여, 다양한 VAD 작업은 정상 및 비정상 샘플의 수를 다양하게 고려.
Semi-supervised VAD
Semi-supervised VAD는 학습 중 정상 샘플과, 매우 적은 양의 비정상 샘플을 모두 활용하는 것을 목표로 함. 하지만 이렇게 소수의 이상 샘플에 집중하게 되면 과적합이 발생하여 일반화가 힘들다. 이를 극복하기 위해 진행 된 연구들은 아래와 같다.
- DRA (2022)
- Open-world 시나리오에서 disentanglement(분리) 전략을 사용하여 이상을 세 가지 범주(Seen anomalies, pseudo anomalies, latent residual anomalies)로 분류
- 이러한 개별 데이터 유형에 대해 특정 detection heads를 학습 시켜 해당 이상을 잘 탐지하도록 함
-
PRN (2023)
- Seen anomalies와 pseudo anomalies 모두를 활용하여 이상과 정상 패턴을 구별하는 residual features를 명시적으로 포착.
- 다양한 이상 생성 전략을 사용하며, seen / unseen 외형 변화 모두를 고려하여 가상 이상을 생성
- 이러한 이상들로부터의 학습을 통해 multi-scale prototype을 구축하고, seen anomalies에 보다는 open world에 충실한 표현을 학습함
-
BiaS (2023)
- Open-world anomalies를 seen / unseen anomalies로 분리하고 각각에 대한 specialists(전문가)의 예측 결과를 지능적으로 융합하는 전략을 활용
- BGAD (2023)
- Flow model을 통해 정상 특징 분포를 모델링하는 데 초점을 맞추며, 동시에 seen anomalies를 통합하여 정상 특징의 description boundary(설명 경계)를 최적화
→ 요약하자면, 다양한 pseudo anomalies를 도입하거나 seen anomalies를 통합하여 정상 샘플에 대한 설명 경계를 최적화함으로써 seen anomalies에 대한 과적합을 방지
Unsupervised VAD
Unsupervised VAD는 특정 카테고리에 대해 정상 샘플만으로 학습된 이상을 식별하는 데 초점을 둔다. 주된 목표는 정상 feature의 분포를 모델링하는 것으로, 일반적으로 feature extraction과 distribution modeling이라는 두 개의 하위 단계를 포함한다.
최근 발전은 주로 ResNet과 같은 사전 학습된 신경망을 feature extraction에 활용하고, distribution modeling을 위한 주요 네 가지 방법은 memory bank, reconstruction, knowledge distillation, flow-based methods로 나뉜다.
-
Memory bank-based methods
- PatchCore(2022) 와 같이 훈련 정상 샘플의 feature를 직접 저장해서, test sample과 가장 가까운 거리를 활용하여 anomaly scores를 계산
- 학습 데이터에서 대표적인 features를 선택함으로써 memory bank는 작고 대표적일 수 있어서 효율적이고 효과적인 방법이다.
-
Reconstruction-based methods
- DFR(2020) 와 같은 방법은 보조 네트워크를 이용하여 추출된 정상 features를 regression한다.
- 이러한 학습 가능한 네트워크를 autoencoders라고 한다.
-
Distillation-based methods
- RD4AD(2022), ViTAD(2023) 등과 같은 방법으로 reconstruction-based와 같이 보조 네트워크를 이용하여 추출된 정상 features를 regression하는데, 이 때의 학습 가능한 네트워크를 student networks라고 한다.
- Reconstruction-based, distillation-based methods는 정상 샘플로만 학습되기 때문에 비정상 샘플의 regression 대해 큰 오류를 생성할 것으로 예상되는 것을 이용한다.
-
Flow-based methods
- Cflow-AD(2021) 같은 방법은 정상 특징의 분포를 자동으로 묘사하고 test feature의 likelihood를 명시적으로 추정한다.
→ 그러나 위에서 언급한 VAD 방법들은 부정확한 boundary descriptions로 인해 비정상에 대한 anomaly scores가 예상 외로 낮아지는 경우가 발생하는데, 이를 over-generalization(과도한 일반화)이라고 한다.
이를 완화하기 위해서 DRAEM(2021), MRKD(2023), DAF(2023)같은 일부 방법들은 synthetic anomalies(합성 이상)을 도입하여, 정상 특징 분포를 회귀하는 것 뿐 아니라 synthetic anomalies에 대해 상당한 회귀 오류를 생성하도록 한다.
MemKD(2023)은 명시적으로 memory bank를 저장함으로써 과도한 일반화 문제를 해결하여 출력이 정상 특징만을 나타내도록 보장한다.
TFA-Net(2024)는 정상 template에 의해 명시적으로 가이드되어 정상 특징을 복원하는 방법을 제안하는데, 이는 비정상 input을 받았을 때 상당한 regression 오류를 낸다.
Few-shot VAD
Few-shot VAD는 제한된 양의 정상 데이터로 모델을 학습 시키는 데 초점을 맞춘다. 이러한 소수의 정상 샘플은 전체 정상 샘플을 충분히 대표하지 못할 수 있고, 따라서 모델은 관찰된 정상 샘플로부터 학습하여 description boundary를 설정하여 unseen 정상 샘플의 분포를 잘 설명하면서 동시에 비정상 샘플의 분포는 배제해야 하는, 매우 도전적인 과제이다.
따라서 해당 task를 수행하는 방법들은 주로 feature descriptiveness를 강화하는 데 초점을 두며, 사용 가능한 few-shot sample들을 더욱 representative한 subset으로 만들고자 한다.
- RegAD (2022)
- 표현 학습을 위해 registration-based proxy tasks를 사용하며, 기하학적 변환을 통해 같은 카테고리의 샘플들은 정렬함으로써 특징 묘사력을 향상시킨다.
- GraphCore (2023)
- 회전 불변 구조적 특징을 추출하기 위해 vision isometric invariant graph(시각 등거리 불변 그래프)를 통해 그래프 신경망을 활용하고, 이는 기하학적 변환이 있는 카테고리에 유리하다.
- FastRecon (2023)
- RegAD와 마찬가지로 few-shot 정상 샘플과 테스트 샘플을 정렬하려고 하며, 더욱 복잡한 기하학적 변환을 사용한다.
→ 요약하면, 주된 few-shot VAD 방법들은 일반적으로 샘플의 정렬(alignement)에 의존하여 특징 묘사력을 늘리고, 관찰된(seen) 정상 샘플이 전체 정상 샘플 집합을 더 잘 대표할 수 있도록 한다.
Zero-shot VAD
Zero-shot VAD는 참조할 만한 정상 샘플에 의존하지 않고 다양한 도메인에서 이상을 탐지하기 위한 통합 모델을 개발하는 것을 목표로 한다. 이는 다 용도성 측면에서 큰 잠재력을 갖지만, 대상 도메인과 관련된 구체적인 사전 정보가 없기 때문에 도전적이다. 기존 zero-shot 방법들은 외부 지식을 통합하여 이상 탐지 능력을 강화한다.
- WinCLIP (2023)
- 사전 학습된 vision-language model(VLM)인 CLIP을 활용하여 이미지 패치와 정상/비정상 text caption 간의 유사성을 계산
- CLIP은 vision-text 쌍으로 구성된 광범위한 데이터셋 으로 훈련을 통해 정상과 이상을 구별하는 암묵적 지식을 갖고 있으므로, 계산된 유사성은 효과적인 anomaly scores로 사용될 수 있음
- APRIL-GAN (2023)
- CLIP과 target VAD 데이터 간의 도메인 격차를 해결하고, 주석이 달린 보조 VAD 데이터를 사용하여 CLIP을 VAD에 adaptation하는 방법을 사용함으로써 VAD 응용에 더 적합하도록 개선
- AnomalyCLIP (2024)
- APRIL-GAN과 같은 adaptation 방식을 기반으로, 수동으로 설계된 prompt의 한계를 극복하기 위해 객체에 구애받지 않는 text prompt 학습 개념을 도입
- SAA (2023)
- 다양한 기존 VLM들을 결합한 앙상블 방식을 도입하여 VAD 시스템에 인간의 전문성을 통합할 수 있는 방법을 제공
→ 요약하면, 이러한 zero-shot 방법들은 CLIP과 같은 기존 VLM에서 얻은 외부 지식을 활용하여 임의의 카테고리에서 이상 탐지를 수행.

본 3.1절에서는 샘플 수의 관점에서 논의된 방법들을 소개하였다. Semi-supervised 방식에서 zero-shot 방식으로 전환됨에 따라 성능이 저하되는 것을 확인할 수 있는데, 샘플이 충분할 땐 성능이 이미 다양한 최근 모델에서 포화 상태에 달했지만, few-shot 및 zero-shot에서는 여전히 개선의 여지가 있다.
3.2. From the Perspective of Data Modality

해당 섹션에서는 data modality 측면에서의 VAD를 분류
2D-aware RGB Image
MVTec-AD, VisA 같은 데이터셋은 정상/비정상 데이터를 포함하는 광범위한 데이터 셋을 구축하여 RGB 이미지에 대한 VAD의 발전을 촉진시켰다. 하지만 해당 데이터셋들은 일반적으로 완벽하게 alignment된 객체와 최적의 조명을 갖춘 이상적인 촬영 상황임을 가정한다. 따라서 아래와 같은 각각의 데이터 셋 또한 도입되었다.
- Eyecandies (2022)
- 적절한 조명 조건은 anomalies의 가시성을 향상 시킬 수 있고, 이에 따라 eyecandies는 같은 객체에 대해서 네 개의 조명을 사용하여 다중 조명 이미지를 캡처하였다.
- PAD (2023)
- 객체가 다양한 자세를 취할 수 있는 실제 환경을 반영하고자 다중 자세 VAD dataset을 도입하고 자세에 구애받지 않는 VAD 작업을 공식화한다.
→ 요약하면, 기존엔 RGB 이미지에 대해 이상적인 촬영 환경을 갖춘 데이터를 대상으로 많은 연구가 진행되었고, 최근엔 비이상적인 조명과 같은 요인을 고려하여 실제 촬영 환경에서 RGB 이미지에 대한 VAD를 탐구하는 데 초점을 맞추고 있다.
3D-aware Representation
기하학적 정보는 종종 point clouds와 같은 3D data로 표현되며, 이는 visual entities의 크기와 모양을 직접적으로 나타낸다.
Point clouds VAD를 위해 설계된 데이터 셋은 MVTec 3D(2022) 와 Real 3D(2023) 가 있다. 이는 고해상도 data clouds를 포함하여 미세한 기하학적 편차를 식별하는 데 도움을 준다. 이 또한 2D image처럼 feature extration과 distribution modeling의 두 steps로 범주화될수 있지만, 기존 이미지 도메인에 반해 cloud points는 사전 학습 모델로 feature extraction을 수행하는 것에 대한 견고함이 부족하다.
- Bergmann and Sattlegger (2023)
- Anomaly detection in 3d point clouds using deep geometric descriptors
- 해당 연구에서는 point clouds VAD를 위한 더욱 견고한 feature extractor를 구축하는 것을 목표로 하고, 이후 knowledge distillation 기반 접근법으로 distribution modeling을 수행한다.
- CPMF (2023)
- Points clouds를 multi-view depth image로 변형하여 기존 이미지 사전 학습된 모델로 point clouds feature extraction을 수행한다.
- 이후 PatchCore를 distribution modeling에 통합한다.
→ 요약하면, 3D point clouds는 RGB 이미지에 대한 풍부한 기존 사전 학습 모델들이 존재하는 것과 달리 이에 대한 견고한 모델이 제한적이다.
Multi-modality
특정 시나리오에서는 multi modality 데이터를 활용하면 VAD의 포괄성이 향상된다. 예를 들어, 3D와 RGB가 공존하는 경우가 있다. 일부 연구들은 이러한 modality에서 나온 representations를 융합하기 위해 설계되었다.
- BTF (2023)
- RGB와 3D representations를 단순히 연결하여 PatchCore의 입력으로 넣는다.
- M3DM (2023)
- BTF를 기반으로 두 modality에 대한 contrastive learning을 도입한다.
- ShapeGuided (2023)
- 모양 feature에 의해 가이드 된 두 representations를 통합한다.
→ 하지만 위 방법들은 사전 학습된 network에 크게 의존하며, 특히 point clouds network의 맥락에서 견고성이 부족할 수 있다.
- AST (2022)
- 비대칭 teacher-student pair를 학습 시켜 raw data로부터 point clouds의 representations를 직접 학습한다.
- 이 쌍은 RGB, 3D 데이터를 모두 처리할 수 있어 두 modalities 간 더 나은 통합을 가능케 한다.
- EasyNet (2023), 3DSR (2024)
- 합성된 비정상 RGB 및 point clouds 데이터를 생성하여 두 modalities에 대한 견고한 feature extractor를 학습시킨다.
→ 본질적으로, multi-modality를 위한 위 방법들은 일반적으로 여러 modality에 걸친 표현의 학습과 융합을 강화하는 데 집중한다.

3.2절에서는 data modality의 측면에서 논의된 방법들을 소개하였다.
VAD를 위한 data modality는 타깃 시나리오에 따라 다양성을 보일 수 있고, 이 중 RGB와 3D가 가장 주도적이고 광범위하게 탐구되고 있다. RGB 데이터에 대한 기존 사전 학습된 모델들 덕에 2D VAD는 상당한 진전이 있었으나, 다른 modality(e.g. 3D)에 대한 사전 학습 모델의 부족으로 위 표처럼 해결해야 할 숙제로 남아있다. 또한, 여러 modality를 활용하면 real-world 정보를 더 포괄적으로 수집할 수 있고, 이는 성능 향상으로 이어질 수 있음을 보여준다.
3.3 From the Perspective of Anomaly Hierarchy

Anomalies의 계층에 기반하여 VAD는 structural anomaly, semantic anomaly 두 가지로 분류될 수 있다.
Structural Anomaly
Structural anomaly는 흠집, 왜곡된 모양 등과 같은 local structural deviations를 의미한다. 최근 몇 년간 이를 위해 맞춤화 된 VAD 방법 연구가 활발했고, 이러한 방법들은 visual entities 내의 local한 모든 구조 패턴을 포괄적으로 설명하는 fine-grained features를 학습하는 것을 목표로 한다. 사실 위에서 언급했던 거의 모든 방법들이 이에 해당한다.
- EfficientAD
- 가장 최근의 주목할 만한 방법으로 knowledge distillation을 통해 생성된 경량 encoder를 제안한다.
- 이러한 경량 encoder는 receptive field를 상대적으로 작은 영역으로 제한하여 local한 구조의 모델링을 강화하고, 효율적이고 효과적인 탐지를 수행할 수 있다.
Semantic Anomaly
개별 visual entities에서 발생하는 structural anomaly와 달리, semantic anomalies는 frame 내 여러 entity 간의 관계에서 발생한다. 이러한 연구를 발전시키기 위해 MVTec-LOCO같은 데이터 셋이 도입되었고, 이러한 데이터 셋은 일반적으로 여러 visual entities가 동시에 나타나는 경우를 포함하며, 그들의 관계에서 발생하는 비정상성을 탐지해야 한다.
한 연구 방향은 global information이 entities 간 관계를 암묵적으로 포착할 수 있다는 것을 가정한다.
- GCAD (2022)
- 두 개의 student-teacher 쌍을 통해 local-local 일관성과 global-global 일관성을 모두 동작한다.
- 작은 receptive field를 가진 쌍은 regression-based 방식으로 structural anomaly를 식별하고, 또 다른 쌍은 유사하게 global semantic features를 비교하여 semantic anomaly를 식별한다.
- DSKD (2024), GLCF (2023), EfficientAD (2024)
- GCAD를 기반으로 하여 local-local 및 global-global consisteny를 통해 정상적인 관계를 모델링한다.
- 이는 contextual affinity distillation과 local-global alignment를 포함한 다양한 전략을 활용하여 정상적인 global context에 대한 이해를 강화하고, 여기서 bottleneck 구조는 이에 중요한 역할을 하게 된다.
한 편, 일부 방법은 entity 간의 관계를 명시적으로 모델링하는 데 초점을 맞춘다.
- ComAD (2023), PSAD (2024)
- 먼저 frame 내 개별 entity를 탐지하고, entity-level의 label이 없는 경우, 일반적으로 cluster-based 방법으로 유사한 data points를 cluster로 그룹화 함으로써 entity를 탐지한다.
- 이후 histogram 분석과 같은 전략을 통해 entity 간의 관계를 모델링한다.
→ 요약하면, semantic anomaly를 다루는 기존 방법들은 global context를 이해함으로써 암묵적으로 entity 간 관계에 대한 이해를 구축하거나, entity 간 관계를 추출함으로써 명시적으로 이를 수행한다.

3.3절에서는 anomaly hierarchy의 측면에서 논의된 방법들을 소개하였다. Anomaly는 다양한 계층적 수준에서 나타날 수 있고, 초기 시도는 주로 structural VAD를 위해 local context를 모델링하는 데 초점을 맞추었지만, 점차 의미적 VAD의 인기가 높아져 visual entities 간의 비정상적인 관계를 모델링하는 데 초점을 두고 있다. 하지만 아직 현재 방법들, 특히 명시적인 방법들은 entity의 수, 위치 등과 관련된 복잡한 관계에서 이를 이해하는 능력이 부족하고, 암묵적인 방법들은 global context를 통해 비정상적인 관계를 정확히 식별하는 데 부족할 수 있다. 현재까지의 결과는 ComAD, PSAD와 같은 명시적 방법이 GLCF, EfficientAD같은 암묵적 방법보다는 효과적이지만, 여전히 entity extraction과 relation modeling은 개선의 여지가 있다.
3.4. Other Perspectives
앞서 언급한 주요 관점 외에도 탐구할 가치가 있는 다양한 설정들이 있다.
Noisy VAD
실제 응용에서 학습 샘플의 label에 오류가 포함될 수 있다고 가정하며, 이는 기존 VAD 방법의 효율성에 영향을 미칠 수 있다.
- SoftPatch (2022)
- Patch level에서 데이터의 노이즈를 제거하는 방식을 택하며, patch에 대한 soft outlier scores를 생성하여 높은 이상치를 가진 patch, 즉 노이즈 데이터를 학습에서 제외한다.
Continual VAD
점진적으로 접근 가능한 새로운 데이터를 활용하여 VAD 모델을 개선하는데, 이렇게 새로운 데이터를 활용하여 직접적으로 업데이트를 진행하면 catastrophic forgetting이 발생할 수 있고, 상당한 계산 부담을 초래할 수 있다는 점을 극복해야 한다.
- UCAD (2024)
- Key-prompt-knowledge memory space를 구축함으로써 VAD 모델에 continual learning 능력을 부여
Uniformed VAD
다양한 카테고리에 대해 통합된 VAD 모델을 구축하는 것을 목표로 한다. Zero-shot VAD가 target 카테고리의 데이터 없이 작동하는 것과 달리, uniformed VAD는 특정 범주의 샘플을 효과적으로 활용하는 데 초점을 맞춘다.
- DiAD (2024)
- Diffusion model을 사용하여 test sample에 대한 normal references를 복원하는 것을 제안한다.
- 그 다음 test sample과 복원된 normal reference 간의 feature space에서의 차이를 활용하여 anomaly scores를 매긴다.
4. Future Directions
4.1. Towards Generic VAD
최근 문헌은 다양한 시나리오에서 접근 가능한 샘플의 다양성으로 인해 서로 다른 샘플 수에 따라 VAD를 개발하는 데 초점을 맞추고 있다. 앞으로는 다른 샘플 수를 수용할 수 있는 generic VAD framework를 구축하는 방향으로 나아갈 수 있다.
Foundation Model for VAD
최근 GPT4-V(ision)과 SAM과 같은 foundation models는 뛰어난 일반화 능력을 보이며, 다양한 샘플 수에 따라 확장 가능한 성능을 입증하였다. 이러한 foundation models는 VAD에서도 어느정도 효과를 보이고 있다.
- A zero-/few-shot anomaly classification and segmentation method
- Segment any anomaly without training via hybrid prompt regularization
- Exploring grounding potential of vqa-oriented gpt-4v for zero-shot anomaly detection
또한, prompt learning과 같은 기술은 foundation model의 성능을 더욱 향상시킬 수 있다.
- Multi-modal prompt learning
그리고, 애초에 VAD에 특화된 foundation models를 학습시키는 것은 더 유망한 VAD의 성능을 가져올 수 있는데, 대조학습(contrastive learning)이나 순차 모델링(sequential modeling)같은 다양한 사전 학습 방식이 탐구 될 수 있다.
- Learning transferable visual models from natural language supervision
- Sequential modeling enables scalable learning for large vision models
Scalable Data for VAD
대규모 데이터의 가용성은 VAD를 위한 foundation models를 구축하는 데 매우 중요하다. 이를 위해 시각 데이터 수집의 실질적인 개선이 필요하다.
여기서 이상 생성(anomaly generation)은 이에 크게 기여할 수 있을 듯 한데, DFMGAN (2023) 이나 AnomalyDiffusion (2023) 등이 있었지만 일반화 능력이 좋지는 않았고, ControlNet(2023)과 같은 방법은 강력한 일반화 능력과, 생성 과정에 대한 세밀한 제어를 입증하였다.
4.2. Towards Multimodal VAD
Multi-modal 데이터는 visual entity의 정보를 포괄적으로 포함할 수 있어 VAD의 성능을 향상시킬 수 있다. 앞으로는 joint imaging parameter optimization과 multimodal learning에 더 많은 관심을 가질 수 있다.
Imaging Parameter Optimization for VAD
기존의 VAD 데이터 셋은 이상적인 촬영 상황을 조건으로 하지만, 실제로 촬영 매개변수가 일관적이지 않은 real-world 시나리오에서는 도전적이다. Eyecandies (2022)와 PAD (2023)에서는 촬영 매개변수의 영향을 탐구했지만, 이러한 촬영 과정을 최적화하는 데 있어서 포괄적인 분석은 아직 부족하다. Auto-exposure, auto-focus 등과 같은 측면을 포함하여 촬영 매개변수를 자동으로 최적화하려는 노력이 필요하다.
Multimodal Learning for VAD
VAD에서 효과적인 representations은 매우 중요하며, 이는 multi modal data에서 특히 그렇다. 이러한 다양한 modality 간 효과적인 융합을 달성하는 것은 신뢰 가능한 VAD에 있어서 필수적이다. 다른 분야에서의 modality 융합과는 달리, VAD의 기존 통합 방법은 feature concatenation처럼 상대적으로 단순하고, 실제 응용에서 VAD를 위해 여러 modality를 고려할 때 multi-modal data를 효과적으로 통합하는 아키텍처를 구축하는 것이 유망하다.
4.3. Towards Holistic VAD
Structural VAD가 좋은 성능을 보여주고 있음에도 불구하고, semantic anomaly를 탐지하는 것 또한 실용적인 VAD 시스템에 있어서 매우 중요하다. 더 넓은 관점에서, VAD 시스템은 이상을 식별할 뿐 아니라 하위 프로세스와의 연결을 구축하여 전체 성능을 개선해야 한다.
Understanding of Relations between Entities
Semantic anomaly는 구조적 표현을 요구하는 structural anomaly와 달리, VAD 모델이 entity 간의 관계를 진정으로 이해할 것을 요구한다. 이전까지 제안된 방법들은 합리적인 semantic VAD 성능을 보여주지만, 여전히 entity 간의 정상적인 관계를 진정으로 이해하는 데엔 부족하다. GPT-4V (2023)과 같은 foundation models는 이러한 논리적 추론을 보여주며, entity 간의 정상적인 관계에 대한 진정한 이해를 보여준다. 앞으로 이러한 foundation models를 semantic VAD에 통합하는 것이 유망할 것으로 보인다.
- Component-aware anomaly detection framework for adjustable and logical industrial visual inspection (ComAD)
- Vipergpt: Visual inference via python execution for reasoning
Connecting VAD with Downstream Tasks
VAD는 상호 연결된 시스템, 특히 품질 검사 파이프라인에서 중요한 역할을 한다. 하지만 현재 연구는 독립된 인식 단계를 강화하는 데만 초점을 두고, downstream 통합과 영향은 무시하고 있다.
효과적으로 최적화를 하기 위해서 VAD는 더 넓은 시스템 workflow에 통합되어야 한다. VAD가 다른 구성 요소들과 어떻게 상호작용하고 있는지, 잠재적인 feedback loop를 필요한 포괄적인 이해가 필요하다. 최근 연구는 VAD의 결과를 로봇 내비게이션, 제조 프로세스와 같은 목표에 통합함으로써 이 방향으로 탐구를 시작하였다.
- Safe robot navigation via multi-modal anomaly detection
- Toward closed-loop additive manufacturing: Paradigm shift in fabrication, inspection, and repair
