[논문 리뷰] ClipSAM: CLIP and SAM Collaboration for Zero-Shot Anomaly Segmentation (Neurocomputing 2025)
논문리뷰
Arxiv
https://arxiv.org/abs/2401.12665
Neurocomputing 2025
https://www.sciencedirect.com/science/article/pii/S0925231224018939
1. Introduction
Zero-Shot Anomaly Segmentation (ZSAS)은 이미지 분석 및 산업 품질 검사 등의 다양한 분야에서 중요한 작업임.
-
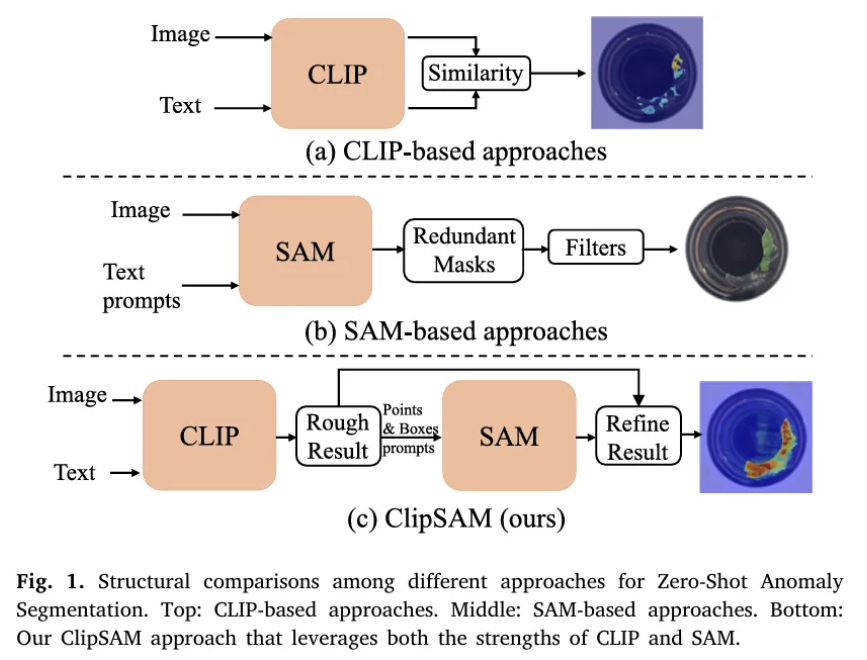
CLIP 기반의 접근법은 image patch tokens와 text tokens 간 유사도를 비교함으로써 패치의 이상 분류를 수행한다. CLIP은 강력한 semantic understanding 능력을 보여주지만, 이는 language와 vision 간 global features를 aligning함으로써 수행되고, 이는 세밀한 segmentation tasks에는 적합하지 못하다.
→ 이상 영역은 주로 객체의 특정 영역에서 일관적으로 나타나고, CLIP이 가지는 global semantic consistency로는 이렇게 local anomalies의 정확한 edge를 식별하기 어렵다.
- SAM 기반의 접근법은 포인트, 박스, 텍스트를 포함한 다양한 프롬프트를 constraints로써 받아 적절한 segmentation을 수행할 수 있다. 하지만, prompt로 text를 받게 될 경우 적절하지 않은 마스크가 생성되는 경우가 많다.
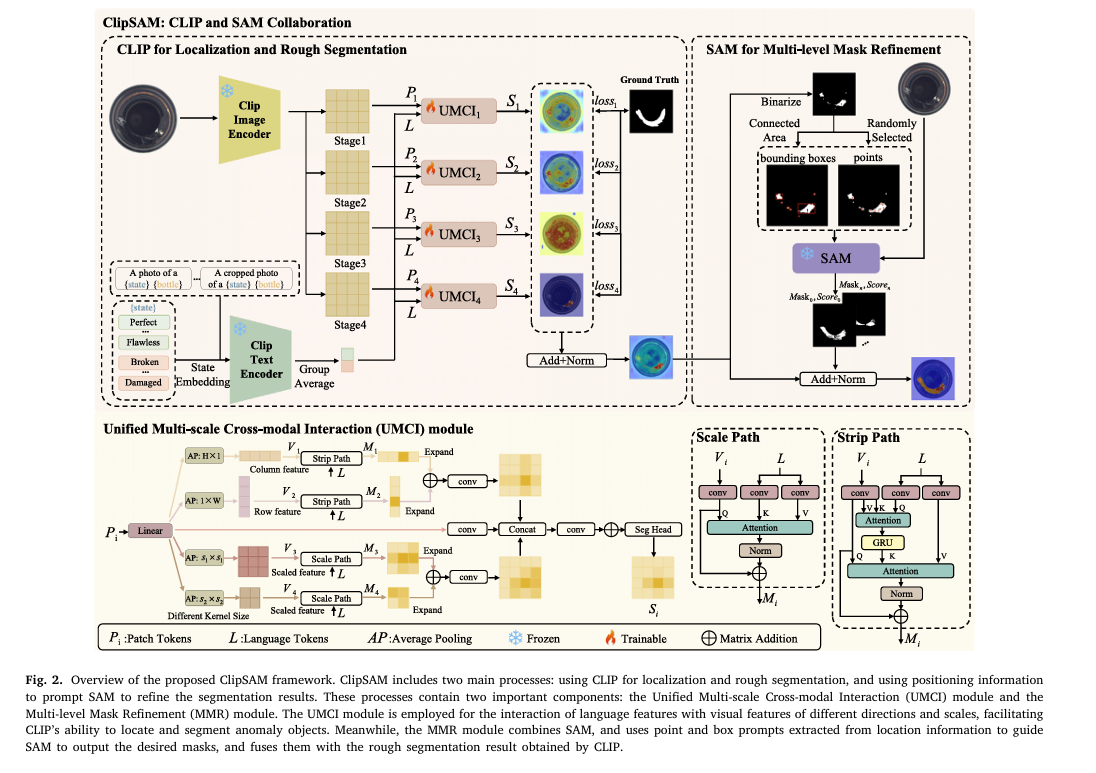
따라서 본 논문에서는 먼저 CLIP을 사용하여 anomaly localization 및 대략적인 segmentation을 진행 후, SAM과 localization 정보를 사용하여 anomaly segmentation results를 정제하는 프레임워크를 제안한다.
이 때 앞선 연구에서 영감을 받아, text와 visual features를 row-column 및 multi-scale levels에서 상호작용하도록 촉진하는 Unified Multi-scale Cross-modal Interaction (UMCI) 모듈을 적용하여 CLIP이 원하는 localization 및 segmentation을 더 잘 수행하도록 한다. 여기서 얻은 localization information에서 점과 박스를 추출하여 SAM이 더 정확한 마스크를 만들 수 있도록 Multi-level Mask Refinement (MMR) 모듈을 설계하여 CLIP과 SAM의 collaboration인 ClipSAM을 제안한다.
2. Related work
2.1. Traditional anomaly segmentation
전통적인 anomaly segmentation 기법들은 크게 두 가지 유형으로 나뉠 수 있다.
- Representation-based methods
- PatchCore는 각 카테고리에 대한 normal sample features를 저장하고, test 시 feature comparison을 통해 이상을 segment한다.
- DFC는 서로 다른 receptive fields에서 normal feature 간 거리는 최소화하고, anomalous feature 간 거리를 최대화한다.
- Reconstruction-based methods
- DREAM은 정상 샘플을 재구성하는 것을 목표로 하며, 그 결과와 input 간 차이를 평가하여 anomaly segmentation을 수행한다.
전통적인 방법들은 일반적으로 모델이 normal features에 적합하도록 하며, 이는 unseen dataset에 대해 좋지 않은 성능을 보이는 결과를 초래하기도 한다. 반면, zero-shot anomaly segmentation은 사전의 target sample에 대한 접근 없이도 정확한 anomaly segmentation을 수행할 수 있다.
2.2. Zero-shot anomaly segmentation
ZSAS 방법도 주로 두 가지 유형으로 나뉜다.
- CLIP based methods
- WinCLIP은 image patch tokens와 text features 간 유사도를 계산한다.
- APRIL-GAN은 다른 modalities 간 alignment를 더 잘 수행하기 위해 linear layers를 사용한다.
- AnoVL은 prompt template에 추가적인 domain 관련 단어를 통합하여 adaptation을 개선하였다.
- AnomalyCLIP은 고정된 prompt templates을 learnable token으로 대체하여 text generalization을 개선하였다.
- SAM based methods
- SAA는 text prompt를 활용하여 candidate masks를 생성하고 복잡한 평가 매커니즘을 활용하여 부적절한 마스크는 걸러낸다.
2.3. Foundation models
최근 foundation model들은 다양한 downstream tasks에서 좋은 성능을 보여주었다. 그 중에서도 CLIP은 classification에서, SAM은 segmentation에서 각각 훌륭한 zero-shot 추론 능력을 지닌 모델들로 부상했다.
CLIP은 multi-modal features를 정렬하고 language와 vision 모두에 대한 강한 이해 능력을 가지고, SAM은 다양한 프롬프트를 기반으로 fine-grained segmentation이 가능하다.
- SP-SAM은 CLIP의 text encoder를 활용하여 SAM의 fine-grained semantics 이해 능력을 향상시켰다.
- SAM-CLIP은 SAM과 CLIP 각각의 기존 강점을 유지하면서 두 가지 image encoders를 통합하여 semantic segmentation같은 추가 작업을 가능하게 하였다.
- SaLIP은 CLIP을 활용하여 대상 객체의 text 설명을 기반으로 SAM이 생성한 candidate masks를 검색하도록 한다.
2.4. Cross-modal interaction
Multi-modal learning 분야에서 cross-modal interaction은 점점 더 중요해지고 있다.
- STEP은 이미지의 중요한 영역과 텍스트의 관련 키워드 간의 correlation을 설정하여 cross-modal information의 융합을 강화한다.
- BRINet은 encoder의 서로 다른 block 간에 cross-modal information을 교환하여 image segmentation을 가능하게 한다.
- Bi-STN-YOLO는 YOLO 내에서 cross-stage spatial connections를 이용하여 multi-scaled outputs 간 feature transfer가 가능해지고, feature fusion의 다양성을 증가시킨다.
본 연구에서는 text와 row-column / multi-scaled visual features 간 상호작용을 고려한 Unified Multi-scale Cross-modal Interaction module을 도입한다.
3. Methodology
3.1. CLIP and SAM collaboration
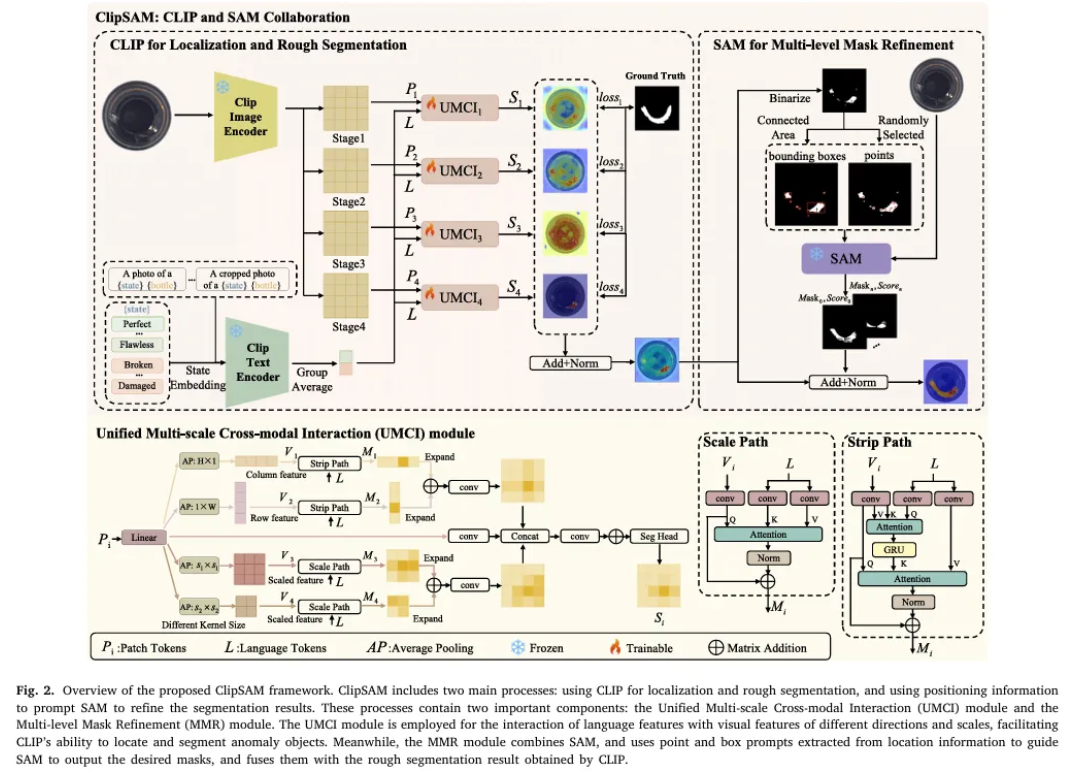
먼저 CLIP을 활용하여 대략적인 segmentation을 수행한 다음 이를 constraints로 활용하여 SAM의 결과를 개선하는 순서로 프레임워크는 구성되어있다.
추가적인 Unified Multi-scale Cross-modal Interaction (UMCI) module과 Multi-level Mask Refinement (MMR) module은 각각 3.3절과 3.4절에서 설명될 예정
3.2. Description text

ClipSAM의 prompts는 위 그림처럼 WinCLIP과 유사하게 설정된다. Template + state words + class names로 구성되고, state words는 perfect~, damaged~ 등으로 나뉘어 정상/비정상을 설명한다. 각 샘플의 카테고리는 알고 있다고 가정하여, 세 가지 요소들을 조합하여 설명 문장을 얻을 수 있다.
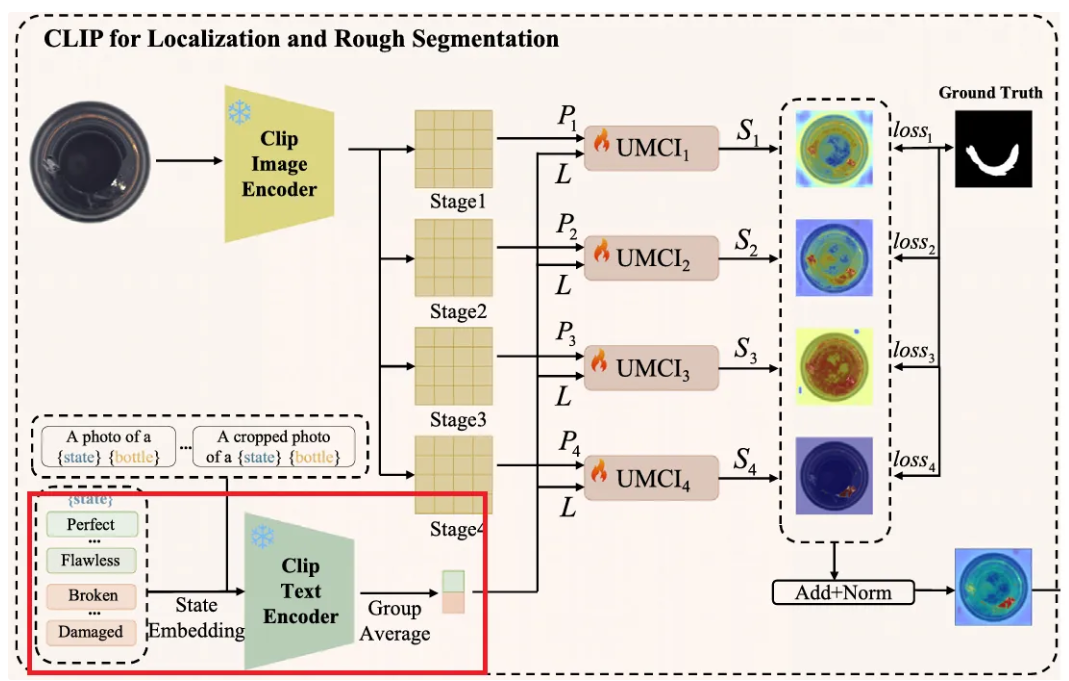
이후 CLIP의 text encoder를 사용하여 feature를 추출하는데, 정상 객체를 설명하는 개와 이상 객체를 설명하는 개의 features를 얻었다고 가정하면, 각각에 대해서 평균을 취한 뒤 연결하여 를 얻는다. 여기서 는 feature dimension이고, 2는 정상과 비정상 두 가지 상태를 나타낸다.
3.3. Unified multi-scale cross-modal interaction
이렇게 특정 샘플에 대해서 CLIP의 encoder는 text embedding인 과, visual embedding인 를 얻는다. 는 encoder의 번째 단계에서 얻어진 patch token을 의미한다. 는 patch 수를 의미하고, 는 visual features의 차원을 의미한다. 이후 각 와 을 함께 UMCI 모듈에 집어넣는다.
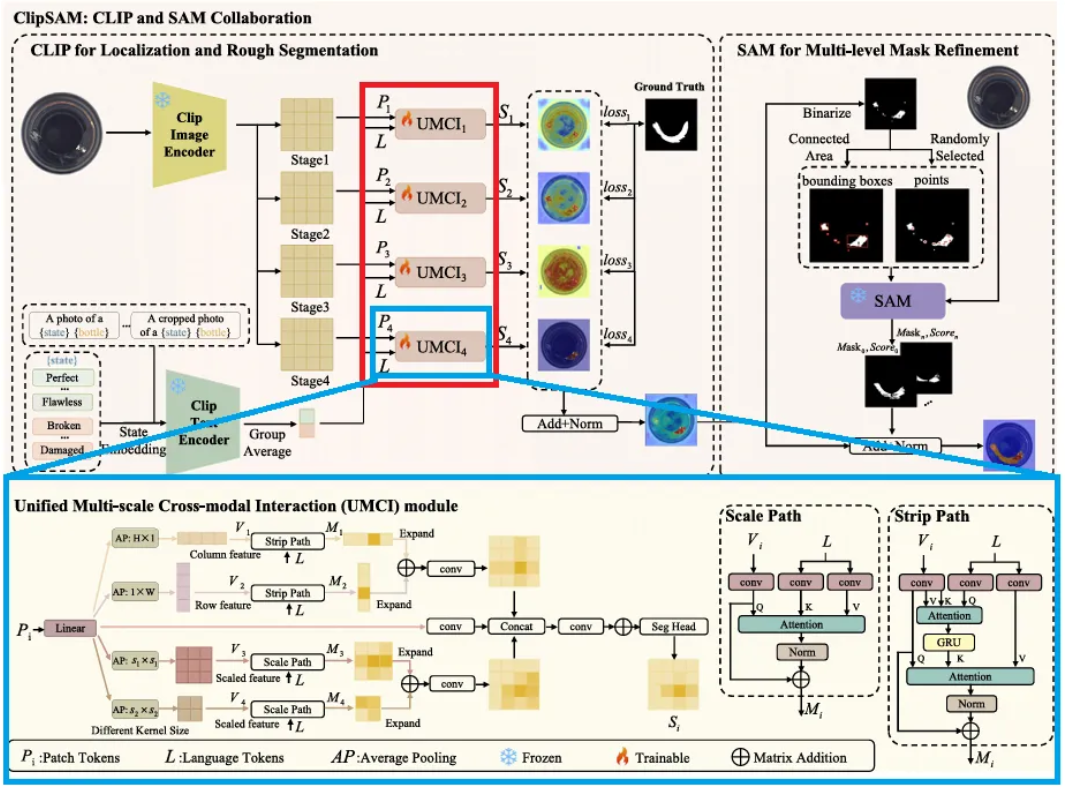
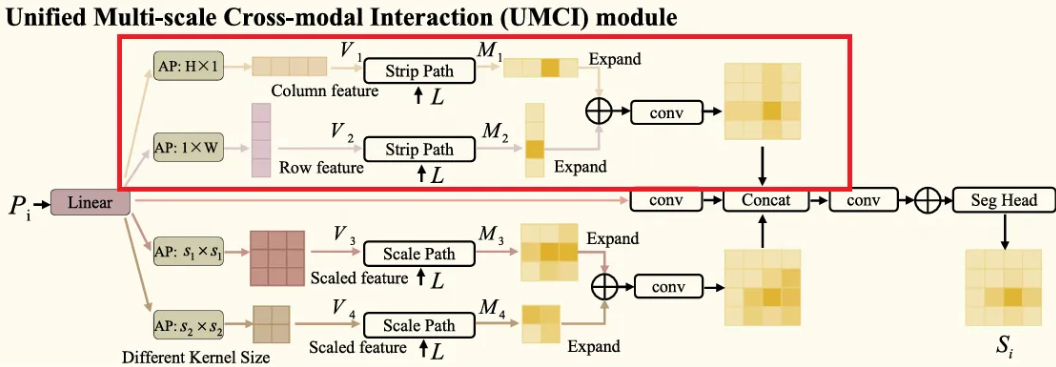
UMCI module은 두 개의 평행한 path인 Strip Path와 Scale Path를 가지는데, Strip path는 패치 토큰의 row-level 및 column-level features를 두 축을 따라 포착하여 위치를 정확히 파악하고, Scale Path는 다양한 scale의 이미지의 global features를 잘 포착하여 anomaly에 대한 포괄적인 이해를 가능하게 한다. 자세히 살펴보자.
Strip Path
- UMCI module의 input을 textual feature vector인 과 vision patch tokens인 라고 할 때, 과 의 차원을 정렬하여 를 얻는다.
- 이후 와 커널 사이즈의 average pooling을 하나씩 적용하여 아래처럼 row-level 및 column-level features를 얻는다.
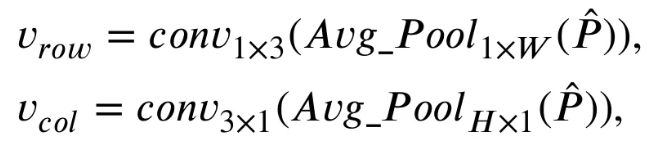
여기서 , 이고, 와 는 각각 vertical feature와 height와 horizontal feature의 width를 의미하고, 는 convolutional layer의 차원이다.
이제 각각의 와 는 Strip Path의 내부 프로세스를 거치게 된다.
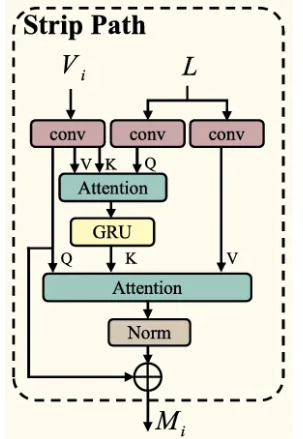
- 를 예시로 들어 설명하자면, 우선 에 convolution을 거쳐 , 를 얻고, 이는 이후 Scaled Dot-Product Attention mechanism의 text feature inputs가 된다.
- 의 픽셀이 정상 또는 비정상 언어 feature에 대해 인식하는 것을 효율적으로 예측하기 위해 two-step attention mechanism을 활용한다.
- 첫 번째는 각각의 language features와 연관된 visual features를 잘 포착하기 위해 디자인된다.
- 이후 GRU를 통해 learned visual features와 original language features를 병합하여 visual information이 풍부한 language features를 얻는다.
- 이렇게 얻은 새로운 language feature와 original visual / language features를 각각 로 하는 attention 계산을 통해 효과적으로 features를 집계한다.
- 마지막으로 를 더해주는 residual method를 통해 를 얻는다.
위와같은 과정이 에도 마찬가지로 적용되어 를 얻고, 각각 bilinear interpolation 를 통해 각각의 original scale에 맞추어 upscaling 되고, 둘을 더해주어 아래와 같이 을 얻는다.
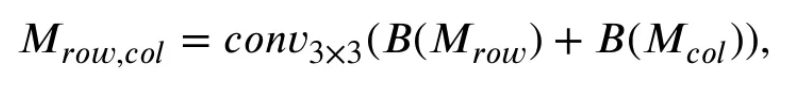
해당 프로세스에 대한 pseudo code는 아래와 같다.

Scale Path
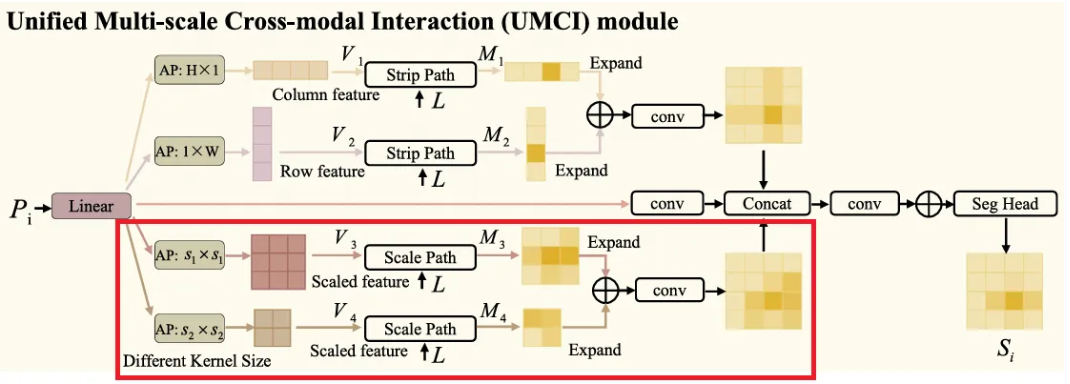
- Scale path에서는 image feature가 로 projection 된 후, kernel size 과 두 개의 average pooling layers를 거치게 된다.
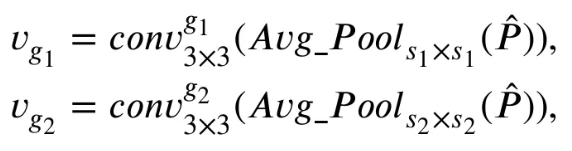
여기서 는 다른 크기의 visual features이다.
마찬가지로 각각의 와 는 scale path의 내부를 거치게 된다.
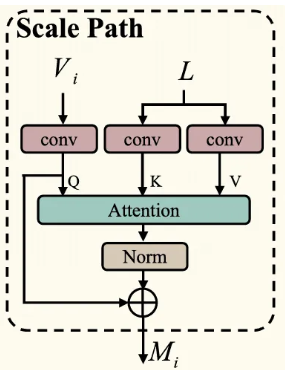
- 을 예시로 설명하면, Text features인 은 convolutional layers를 거쳐서 를 얻고, 을 query로 하여 attention mechanism을 통해 픽셀의 language perception인 을 얻는다. (도 마찬가지로 수행하여 획득)
- Strip Path와 유사하게 bilinear interpolation으로 resize 후 과 를 결합한다.
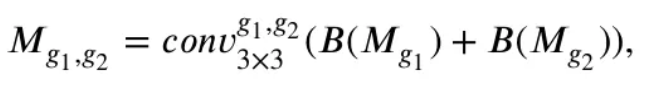
해당 프로세스의 pseudo code는 아래와 같다.
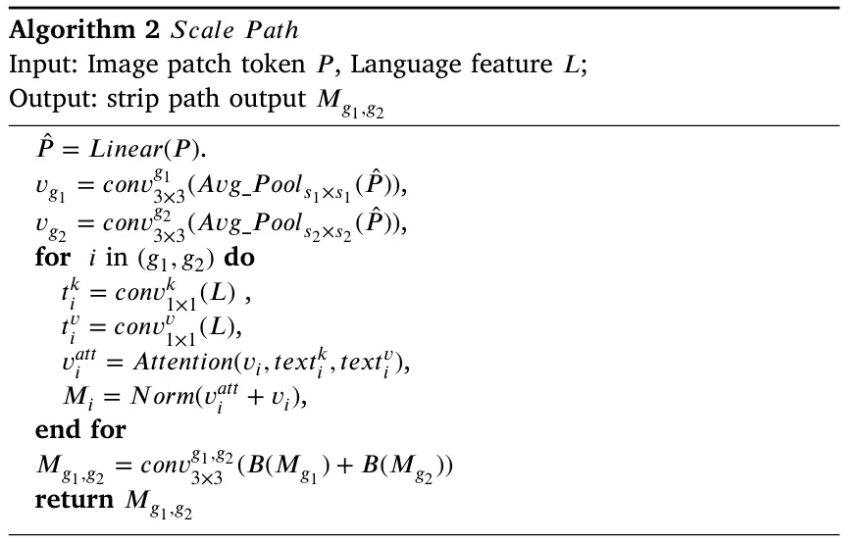
Dual-path Fusion
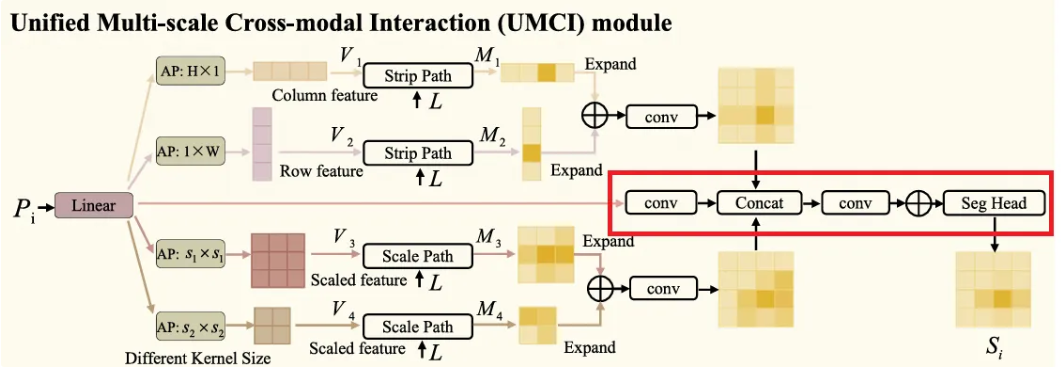
- Strip path와 scale path를 거친 후, 우리에게는 포괄적인 위치 및 의미 정보를 갖는 pixel-wise predictions 와 가 주어지고, UMCI module의 마지막 step은 이러한 결과들을 결합하여 이상 부위에 대한 대략적인 segmentation mask를 얻는 것이다.
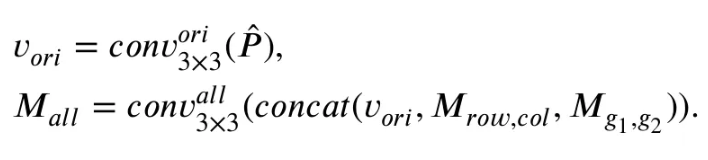
이에는 input patch token 에 대한 residual connection을 추가하여 convolution layer를 거친 값도 함께 합쳐진다.
- 이후 multi-layer perceptron을 segmentation head로써 사용하여 이상 부위의 rough segmentation 결과를 얻는다.
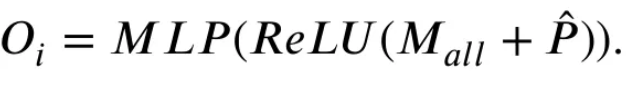
여기서 는 stage 번째 UMCI module의 segmentation 결과이고, 차원이 2인 이유는 anomalous parts인 전경과 배경에 대한 분류를 의미한다. UMCI module 내 모든 convolutional layers는 독립적이다.
- encoder에 개의 stage가 있다고 가정한다면 최종 segmentation 결과는 로 계산된다.
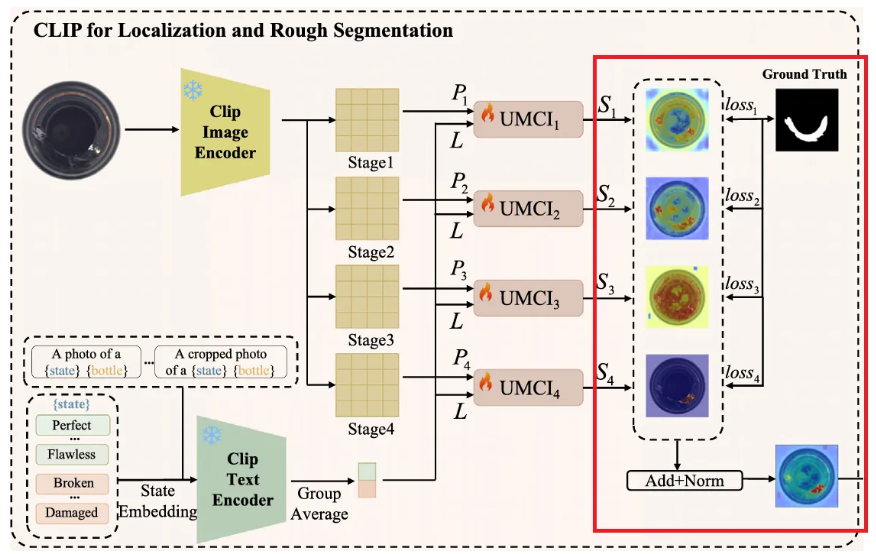
3.4. Multi-level mask refinement
CLIP phase에서 얻은 rough segmentation 를 갖고 Multi-level Mask Refinement (MMR) phase를 수행한다.
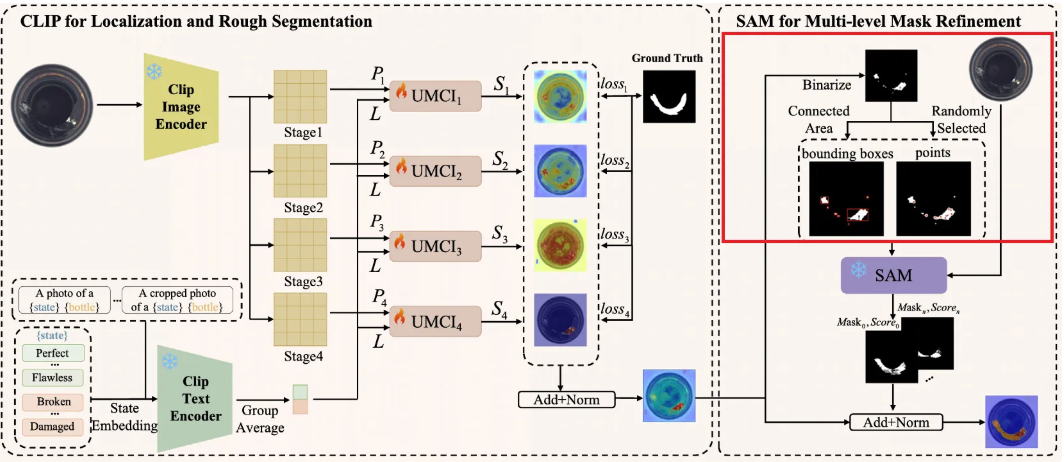
- 여기서는 를 활용하여 SAM이 제대로 된 mask를 생성해낼 수 있는 가이드인 포인트와 박스들을 추출한다.
- 먼저 rough segmentation의 foreground인 는 binary mask인 를 얻기 위해 binarization step을 거친다.
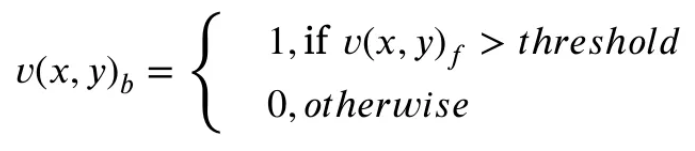
이는 threshold를 설정해서 넘기면 1, 못넘기면 0으로 mapping하는 방식.
- 이후 해당 binary mask의 connected area로부터 SAM의 spatial prompts가 될 박스와 포인트를 식별한다.
- 포인트를 선택할 땐 개의 랜덤 포인트를 선택하고, 이는 로 표현된다.
- 박스는 binary mask에서 연결된 영역 크기에 따라 생성되며, 번째 박스는 로 표현되고, 전체 개의 박스는 집합으로 나타낼 수 있다.
- 이렇게 얻은 포인트 프롬프트 집합 와 박스 프롬프트 집합 를 통해 우리는 SAM을 위한 최적의 프롬프트 집합을 얻어야 한다.
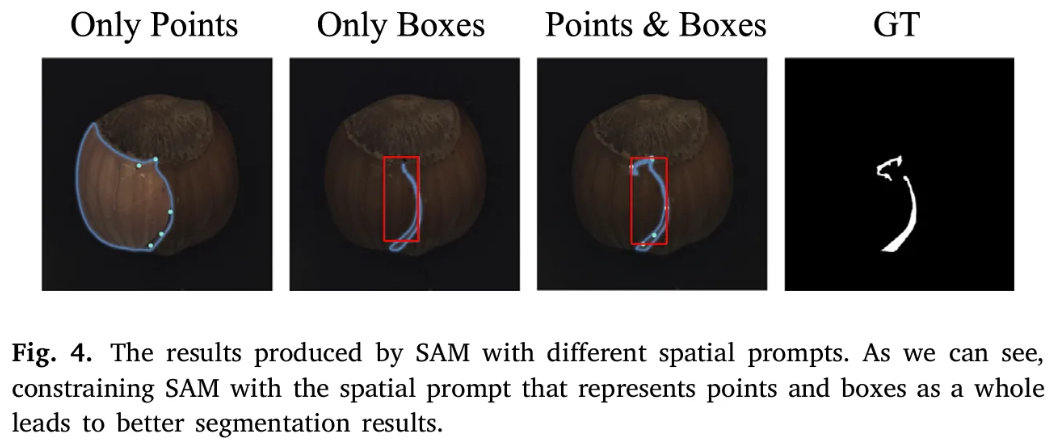
- 위 그림처럼 포인트나 박스 prompts를 각각 쓰면 biased results를 낳기에, 를 최종 프롬프트로 활용한다.
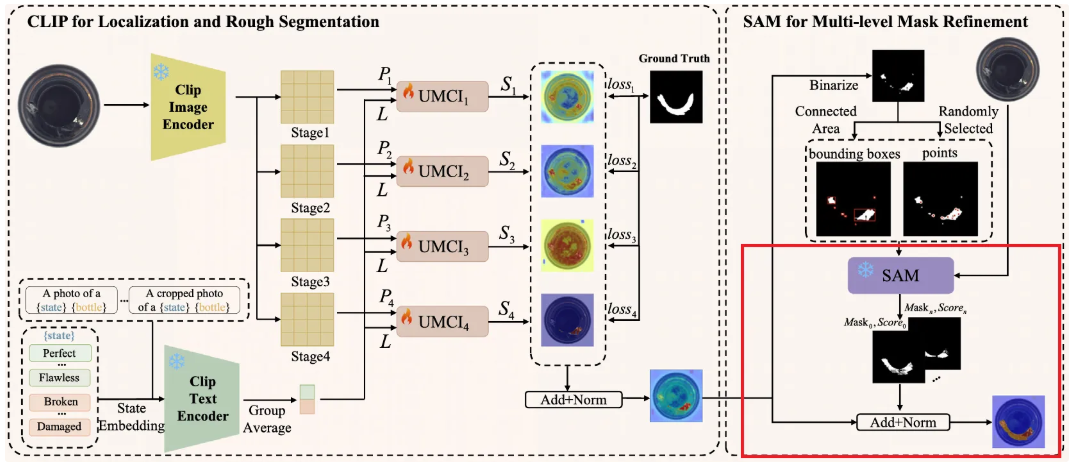
- Original image 와 spatial prompts 를 입력으로 받아서 SAM은 인코딩된 features인 와 를 생성하고, 이후 decoder를 거쳐서 refined masks와 이에 대한 confidence scores를 아래와 같이 얻는다.
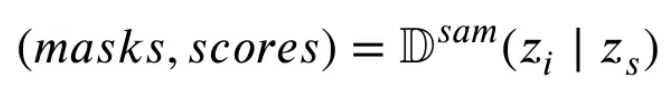
- 위에서 설명한 전략에 따르면 한 이미지 당 생성되는 각 박스들은 같은 point constraints를 공유하며, 이에 따라 박스 당 하나의 마스크가 출력으로 나오게 된다.
- SAM의 특징 중 하나는 같은 이미지와 프롬프트를 입력받아서 여러개의 마스크를 생성할 수 있다는 점인데, ClipSAM에서도 하나의 박스 프롬프트 당 3개의 마스크()와 각각의 confidence scores()를 얻는다.
- 이제 개의 각 박스로 생성된 mask들과 그에 대응하는 confidence scores를 곱한 것과 rough segmentation 를 더한 뒤 Min-Max normalization을 수행하여 최종 fine-grained result 를 얻는다.
3.5. Objective function
Focal Loss
Focal loss는 segmentation tasks에서 클래스 불균형 문제를 다룰 때 많이 쓰이는 loss이다. Anomaly segmentation에서 이상 영역은 전체 이미지에서 극히 일부인 경우가 많기 때문에 적절한 loss이다.
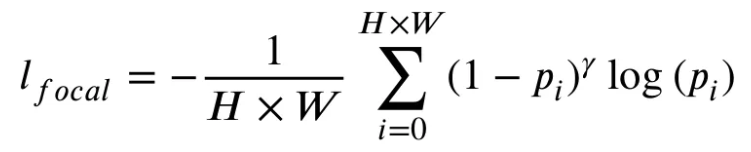
여기서 는 픽셀의 예측된 이상 확률을 의미하며 는 tunable parameter이다. (본 논문에서는 2로 설정)
Dice Loss
Dice loss는 target area와 model의 출력이 겹치는 부분에 대한 score를 계산하며 이 또한 클래스 불균형 문제에서 많이 사용되는 loss이다.
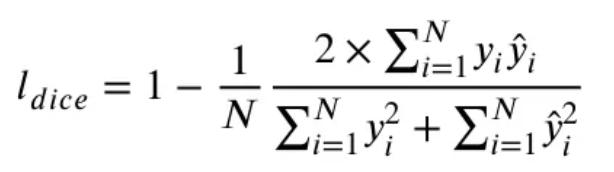
여기서 는 ground truth, 는 예측된 확률을 의미한다. 는 features의 전체 픽셀을 의미한다.
Total Loss
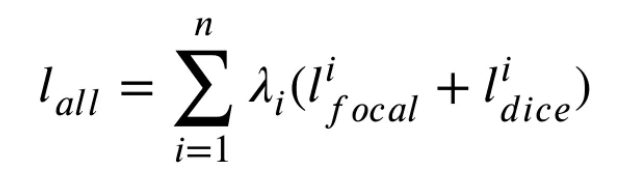
Focal loss와 dice loss를 조합하여 전체 loss는 위와 같이 설정되고, 는 각 stage의 index를, 는 각 stage의 loss weight이다. 본 논문에서 사용한 CLIP encoder의 stage는 총 4개로 구성되었고, 각 는 0.1, 0.1, 0.1, 0.7로 설정되었다.
4. Experiments
4.1. Experimental setup
datasets
산업용 이상탐지에 일반적으로 사용되는 MVTec-AD와 VisA를 대상으로 실험을 수행하였고, 일반화 성능을 확인하기 위해 MTD, KSDD2 데이터셋에대한 실험도 추가 진행하였다.
Metrics
WinCLIP을 따라 널리 사용되는 AUROC, AP, F1-max, PRO를 사용하였다.
Implementation Details
- OpenAI에서 제공하는 pretrained ViT-L/14-336 CLIP encoder를 사용하였고, 24개의 layers 중 6, 12, 18, 24로 stage를 4개로 나누었다.
- Text features의 차원은 768
그 외 사항들은 논문 원문 참고
4.2. Experiments on MVTec-AD and VisA
Comparison with State-Of-The-Art Approaches
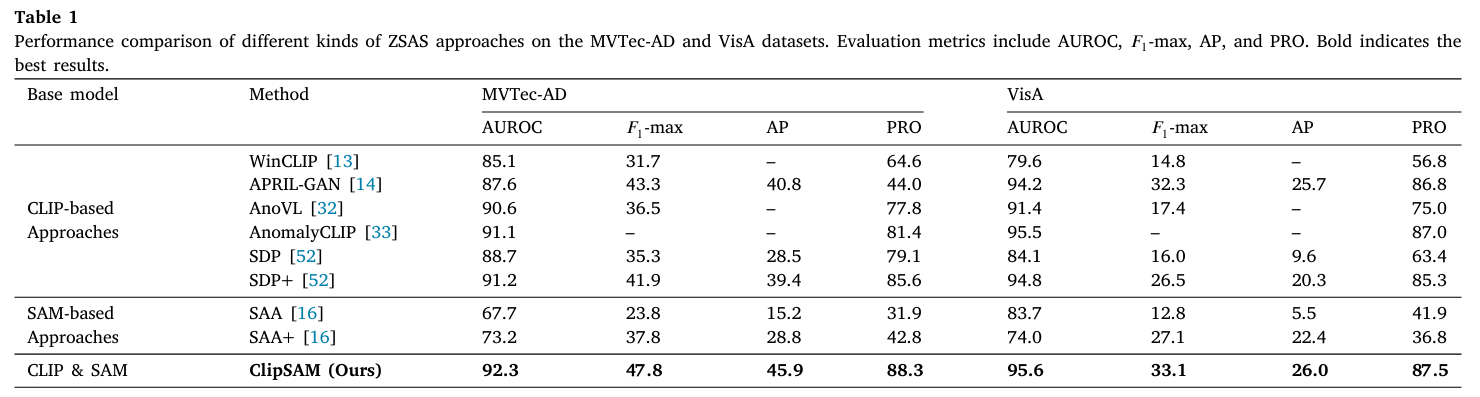
MVTec-AD와 VisA에서 다양한 Metrics에 대한 평가 모두 ClipSAM이 기타 CLIP-based 및 SAM-based 모델들과 비교하여 가장 좋은 성능을 보여주었다.
Qualitative Comparisons
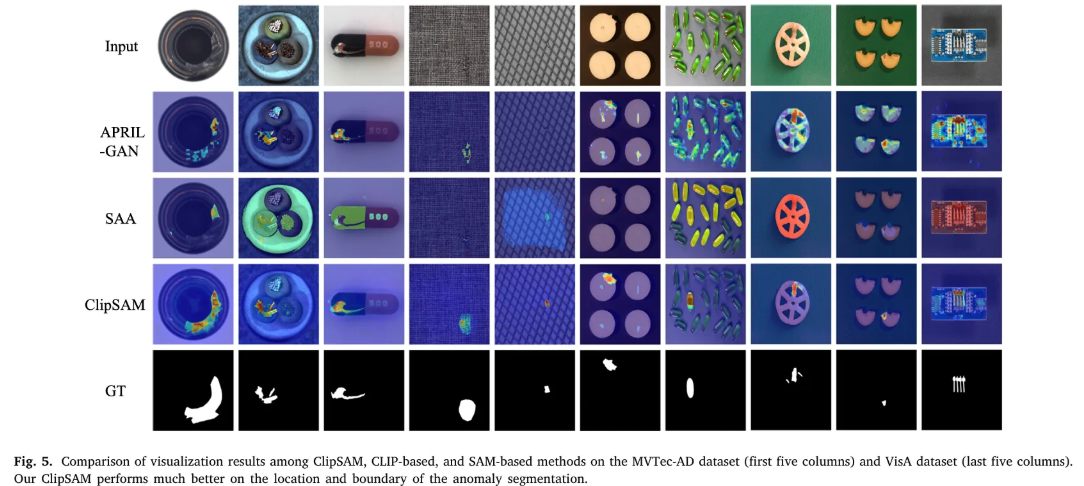
APRIL-GAN, SAA, ClipSAM에 대한 정성적 평가를 진행하였을 때, SAA는 많은 실패 사례들을 보여주지만, ClipSAM은 정확한 detection 및 segmentation 결과를 보여준다.
4.3. Ablation studies
해당 섹션에서는 MVTec-AD 데이터셋으로 다양한 요소와 hyperparameters 설정에서의 ClipSAM의 결과를 살펴보고, 다른 방법과 비교하여 계산 효율성을 평가한다.
Effectiveness of Components
본 연구에서 핵심 모듈이 되는 MMR과 UMCI, 그리고 그 내부에서도 strip path와 scale path에 대한 ablation을 진행하고, scale path에서도 하나의 average pooling을 적용할 때에 대한 실험, strip path에서 row-level만 사용하거나 column-level만 사용할 때 등 다양한 경우에 대한 ablation을 진행하였고, MMR에서 사용되는 프롬프트도 box만 쓰거나 point만 쓰는 경우의 성능 하락을 보았다.
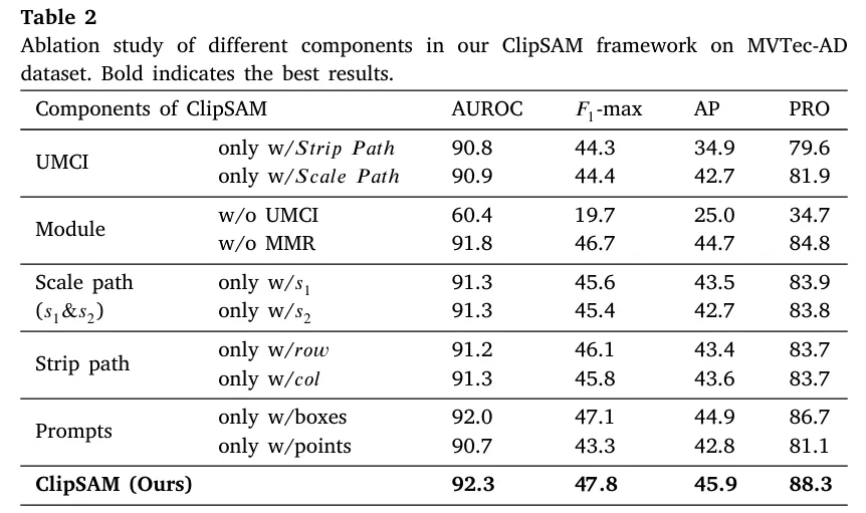
- UMCI에서 하나의 path를 제거하면 성능 저하가 확실히 발생하며, 두 path를 결합하는 것이 필수적임을 보여준다.
- MMR 모듈을 제거하였을 때 성능이 약간 저하되었고, UMCI 모듈의 제거는 성능 붕괴로 이어졌다.
- Scale path에서 단일 scale transformation을 사용하면(각각 3x3, 9x9) 성능이 유사하게 떨어졌다.
- Strip path에서 row-level 또는 column-level visual features만을 사용하여도 성능이 감소하였다.
- MMR에서 프롬프트를 Box만 사용하거나 point만 사용하는 경우 성능이 하락하였다.
Effectiveness of Hyperparameters
본 섹션은 다양한 하이퍼파라미터의 효과를 살펴본다.
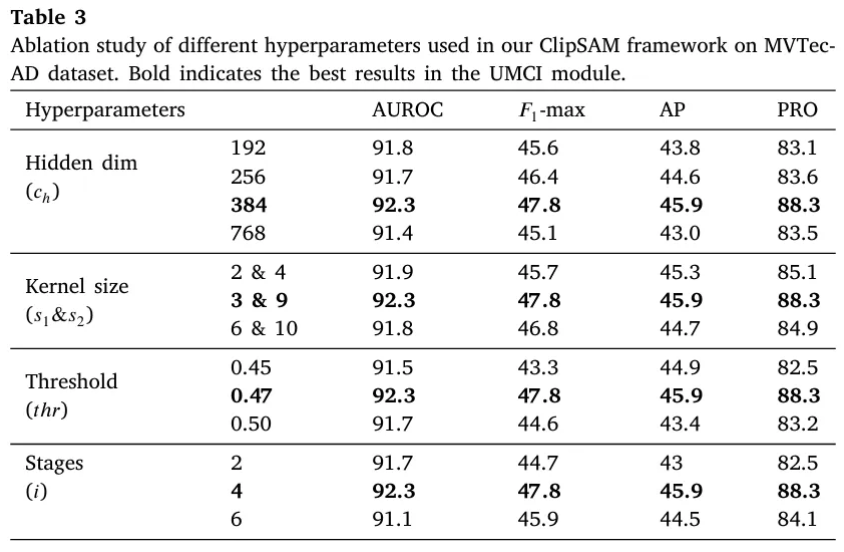
- Convolution layer의 출력 차원인 Hidden dimension()은 384였을 때 가장 성능이 좋았다.
- Scale path의 과 의 크기는 각각 3, 9일 때 가장 성능이 좋았다.
- MMR에서 binarization의 threshold는 0.47에서 가장 좋은 성능을 보여주었다.
- CLIP image encoder는 4 stages로 나누는게 가장 성능이 좋았고, 각 stage 별로 UMCI는 각각 학습되기 때문에, 너무 많이 stage를 나누면 오히려 학습 파라미터 수가 증가하고, 서로 다른 depth의 features에 대한 이해가 떨어지게 된다.
Efficiency of ClipSAM
실제 산업 분야에서 anomaly segmentation을 적용할 때 요구되는 것을 고려하여, 모델의 효율성에 대한 실험을 추가로 진행하였다.
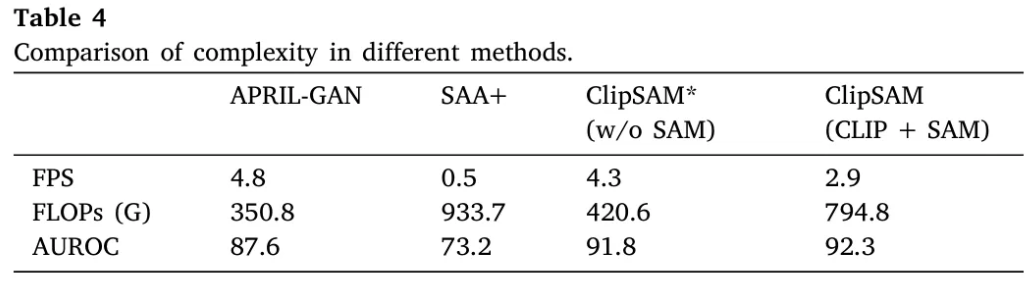
- ClipSAM에서 SAM을 제거한 ClipSAM*는 APRIL-GAN과 비슷한 계산 효율을 보이면서도 정확도의 큰 향상을 보여주었다.
- SAM을 다시 추가하여도 SAA+보다 높은 효율성을 유지하면서 0.5%의 정확도를 높일 수 있었다.
추가로 SAM의 크기가 ClipSAM의 효율성 및 정확도에 미치는 영향에 대해 실험하였다.
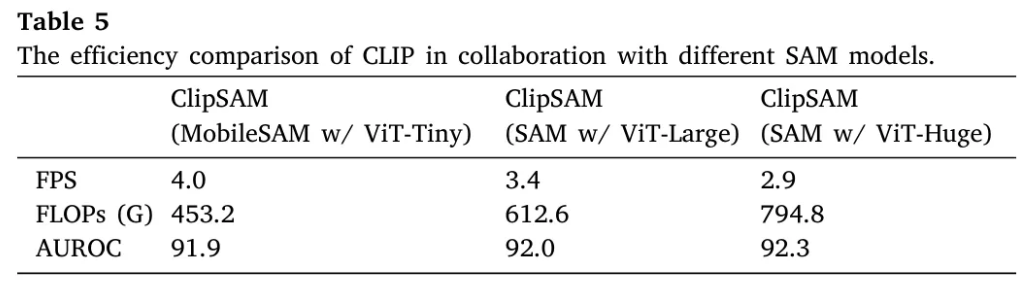
- ViT-Tiny를 사용하는 MobileSAM을 사용하였을 때 효율성은 좋지만 필연적으로 약간의 성능 저하가 발생하였다.
- ViT-Huge를 사용하는 SAM은 더 많은 computational overhead가 발생하지만 최적의 정확도를 보여주었다.
Effectiveness of Extra Strategy
본 섹션은 ClipSAM의 계산 과정에서 추가적인 strategies를 논의한다.
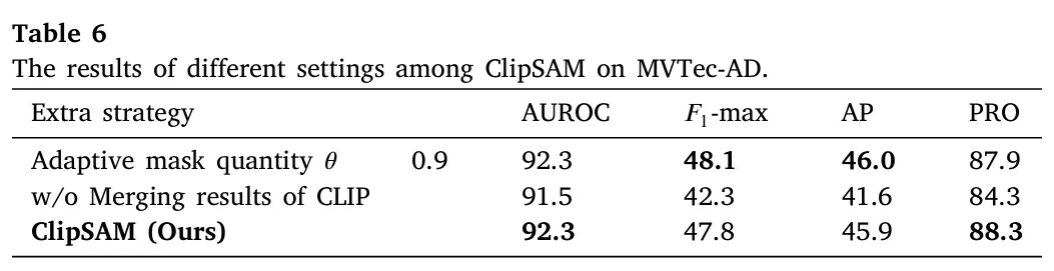
- 실제 SAM에서 하나의 프롬프트에 대해서 출력하는 segmentation mask 수는 hyperparameter로써 정해질 수 있고 보통 세 가지 마스크를 설정하는 것이 디폴트이다. 저자들은 여기서 고정된 상위 3개 대신, confidence가 0.9 이상인 마스크들을 사용하거나 CLIP의 result를 더하지 않았을 때의 경우와 비교하였고, 기존 방식이 여전히 강건하게 성능이 잘 나오는 것을 보여주었다.
4.4. Experiments on MTD and KSDD2
Comparison with State-Of-The-Art Approaches
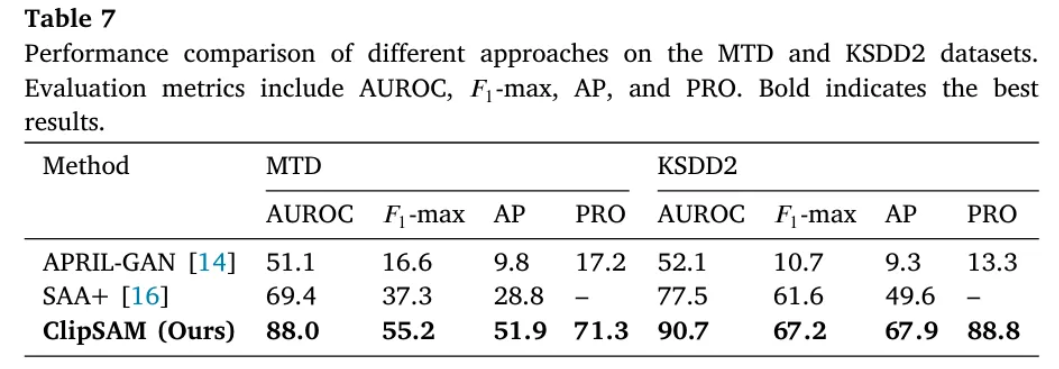
Single object category와 다양한 이상 유형을 포함하는 MTD와 KSDD2 데이터셋에서도 ClipSAM은 기존 SOTA인 APRIL-GAN과 SAA+에 비교하여 ZSAS에서 더 좋은 성능을 보여주었다.
Qualitative Comparisons
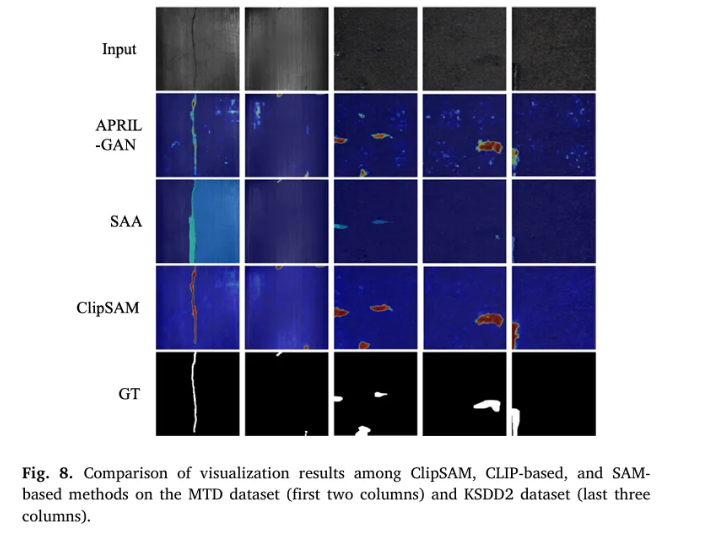
MTD dataset에 대해서 정성적 평가를 진행하였을 때, ClipSAM은 마찬가지로 좋은 결과를 보여주었다.
5. Conclusion
본 연구에서는 zero-shot anomaly segmentation 문제를 해결하기 위해 CLIP과 SAM의 협력 프레임워크를 제안한다. CLIP 부분은 UMCI module을 추가하여 multi-scale에서 이상을 탐지하고 rough segmentation을 얻고, MMR module을 통해서 이를 더 적절한 prompt로 변환하는 방법을 통해 좋은 성능을 보여줄 수 있었다.
