https://arxiv.org/pdf/2304.09148.pdf
Introduction
최근 AI 연구는 대규모 데이터를 이용하여 학습된 모델로의 패러다임 변화를 겪고 있다. 현재 잘 알려진 BERT, DALL-E, GPT-3 등에 더불어, generic image segmentation 을 위한 Segment Anything(SAM) 이라는 foundation model아 있다.
그러나 SAM은 camouflaged object detection(위장 객체 탐지)나 shadow detection에서는 약한 성능을 보이고 있다. 따라서 저자들은 SAM-Adapter를 소개한다. SAM을 downstream task에 더 좋은 성능으로 적용시키기 위한 목적으로 연구가 이루어졌고, 결과적으로 다양한 task의 customized dataset에 잘 적용되고(Generalizable), 다중 조건 제어로 간편하게 SAM을 fine tuning 하는 것이 가능하다고 한다(Composable).
저자들은 해당 연구가 다음과 같은 contributions를 갖는다고 말한다.
- foundation model로서의 SAM의 불완전성을 분석하고 downstream task에 잘 이용할 수 있는 방법을 제안한다.
- general knowledge와 task-specific knowledge를 통합하는 SAM-adapter를 제안한다.
- 두가지 downstream tasks에 특화된 구조가 없음에도, 성능은 SOTA를 달성했다.
Method
Using SAM as the Backbone
SAM으로 부터 학습된 지식을 활용하기 위해, SAM을 segmentation network의 backbone으로 사용하였다. SAM의 image encoder는 14x14 창 크기의 attention에 4개의 equally-spaced global attention block들을 갖춘 ViT-H/16 모델이다. encoder의 pretrained weight는 유지한다(frozen).
저자들은 또한 변형된 transformer decoder block을 포함하는, SAM의 mask decoder(뒤에 dynamic mask prediction head가 붙음)를 이용한다.
mask decoder의 weight는 사전 학습된 SAM의 weight로 초기화하고 학습 과정에서 tuning 해주었다. 저자들은 기존 mask decoder에 어떠한 프롬프트도 입력하지 않았다고 한다.
Adapters
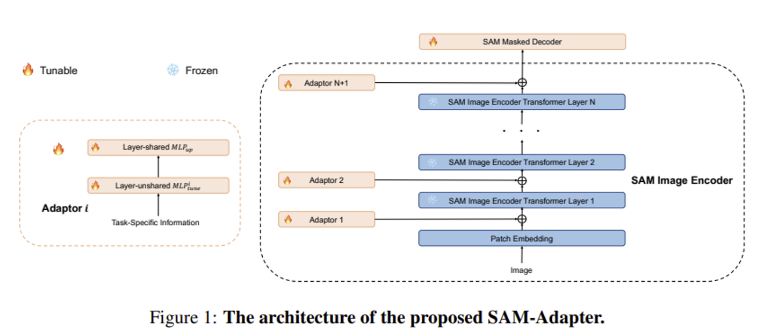
다음으로, task-specific knowledge인 가 학습되고 Adapter를 이용하여 주입된다. foundation model은 대규모의 데이터 셋으로 학습되었기 때문에, task-specific knowledge를 적절한 prompt를 사용하여 도입한다면 annotated data가 적은 환경에서도 downstream task의 일반화 성능을 높일 수 있다.
그림 왼쪽의 Adaptor의 구조를 먼저 살펴보면, 라는 task-specific information을 받아서 두 개의 MLP layer로 흘려보낸다.
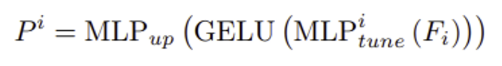
은 각각의 Adapter에 대한 task-specific prompt를 생성하기 위한 linear layer이다. 은 모든 Adapter끼리 공유되는 up-projection layer로 transformer features의 차원을 조정해준다. Adaptor 의 결과인 는 SAM의 각 transformer layer에 붙여지는 output prompt를 의미하게 된다.
Input Task-Specific Information
information 는 task에 따라 다양한 형태가 될 수 있다. 예를 들어, 특정 데이터셋의 샘플로부터 texture나 주파수 정보와 같은 형태로 추출될 수 있거나, 일부 수동으로 제작된 규칙에서 나올 수 있다. 또한, 아래와 같이 여러 가이드 정보를 포함하는 구성 형태일 수도 있다.
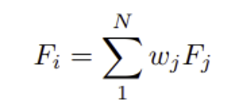
여기서 는 하나의 knowledge/features의 특정 타입이 될 수 있고, 는 composed strength를 조절하기 위한 weight이다.
Experiments
Tasks and Datasets
SAM에 어려운 두가지 low-level structural segmentation task 진행(camouflaged object detection, shadow detection) 자세한 실험 데이터 셋 및 평가 지표는 논문 원문 참고
Implementation Details
- 실험에서 저자들은 patch embedding 와 high-frequency components 라는 두 개의 visual knowledge를 선택하였다. 는 1로 설정하여 결국 이 된다.
- 은 32개의 linear layer를 갖고 있고 은 GELU activation의 출력을 각 transformer layer의 입력 수에 mapping하는 하나의 linear layer이다.
- SAM의 ViT-H version을 이용하였다.
- shadow detection에는 balanced BCE loss가 사용되었고, camouflaged object detection과 polyp segmentation에는 BCE loss와 IOU loss가 사용되었다.
- 모든 실험의 optimizer는 AdamW를 사용하였다.
- learning rate는 2e-4로 초기화하고, cosine decay가 적용되었다.
- camouflaged object segmentation의 학습 epoch은 20
- shadow segmentation의 학습 epoch은 90
- polyp segmentation의 학습 epoch은 120
- 실험은 Pytorch로 네개의 NVIDIA Tesla A100 GPUs를 이용하여 진행되었다.
Experimental Result for Camouflaged Object Detection
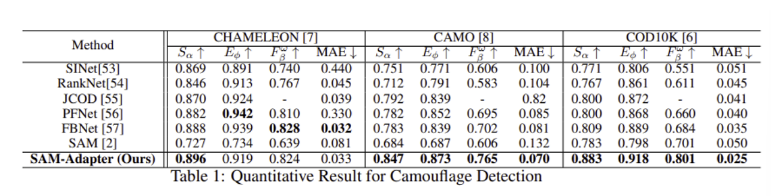

CHAMELEON, CAMO, COD10K 데이터 셋에서 SAM-adapter가 일반적인 SAM을 포함한 다른 SOTA methods에 비해 좋은 성능을 내었다.
Experimental Result for Shadow Detection
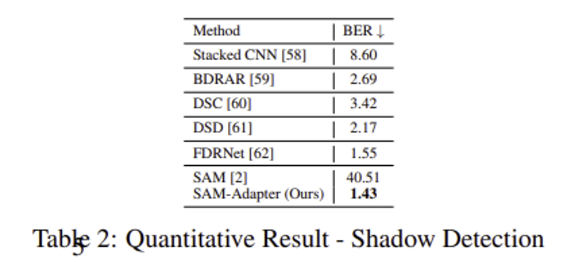
original SAM으로는 좋지 않던 성능이 SAM-Adapter를 적용하자 훨씬 좋은 결과가 나왔다.
Experimental Result for Polyp Segmentation
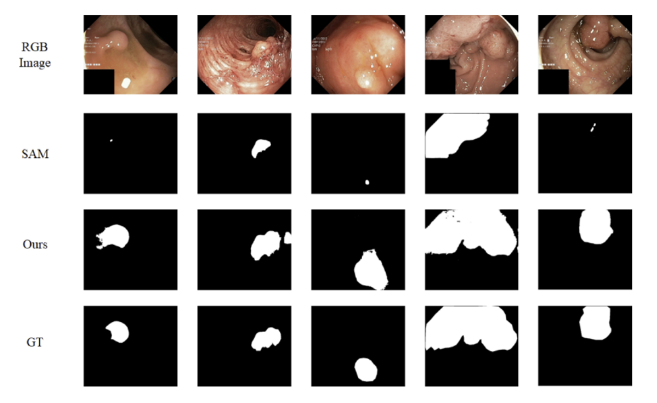
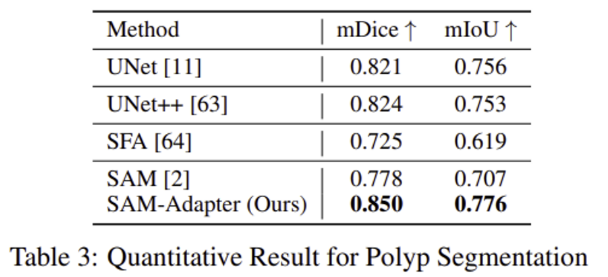
polyp은 대장경 검사 중 발견될 수 있는 악성 종양으로 저자들은 polyp segmentation에 대한 실험도 진행하였다. 다른 segmentation SOTA 모델과 비교했을 때 좋은 결과를 보여주었다.
Conclusion
Segment Anything Model(SAM)은 camouflaged object detection이나 shadow detection task 등을 수행할 때 효과적이지 못한 결과를 보여주었다. 저자들은 위와 같은 downstream task를 잘 수행할 수 있도록 SAM을 backbone으로 사용하고 adapter를 통해 customized information을 주입하는 SAM-Adapter를 제안한다. 결과적으로 간단한 구조 변화만으로도 좋은 성능을 보여줄 수 있었다.
