Segment Anything
https://arxiv.org/pdf/2304.02643.pdf
1. Introduction
NLP에 비해 computer vision에서의 foundation model들은 상대적으로 적게 탐구되었다. 그만큼 아직 해결해야 할 문제 범위가 넓고 이에 대한 훈련 데이터는 풍부하지 않다.
해당 연구의 목표는 promptable model을 개발하고 이것을 대용량 데이터 셋에 학습시켜 image segmentation에 대한 foundation model을 만드는 것이다. 이 plan의 성공 여부는 세 가지 요소에 달려있다.
- 어떤 task가 zero-shot generalization을 가능케 하는가?
- 해당 모델의 architecture는 무엇인가?
- 어떤 데이터가 이 task와 model에 힘을 실어줄 수 있는가?
저자들은 각 요소에 대한 해답을 아래와 같이 정하였다.
- promptable segmentation task를 정의하는 것
- flexible prompting과 실시간 segmentation mask 생성을 해줄 수 있는 model이 필요
- segmentation을 위한 web-scale data source가 없기 때문에 ‘data engine’을 만들어 데이터를 수집하고, 이를 활용하여 모델을 개선하는 과정 반복
2. Segment Anything Task
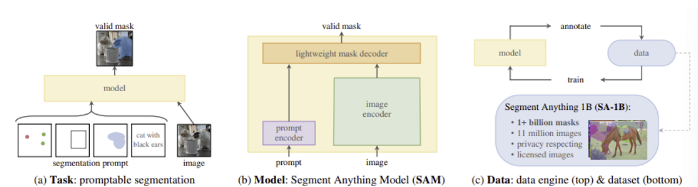
저자들은 NLP에서 다음 토큰을 예측하는 작업이 foundation model의 사전 학습과 prompt engineering을 통해 downstream task를 해결하는 데 이용되는 점에 영감을 받았다. segmentation의 foundation model을 생성하기 위해 위와 비슷한 능력을 갖춘 task를 정의하고자 하였다.
Task
NLP에서의 프롬프트 개념을 segmentation으로 이동하면서 시작한다. 여기서의 프롬프트는 전경/배경 점들의 집합, 대략적인 상자나 마스크, 자유 형식 텍스트 등 image에서 segmentation 하고 싶은 물체의 어떤 정보든 포함될 수 있다.
목표는 프롬프트가 애매한 정보를 가지고 있더라도 적어도 한 물체에 대한 ‘valid’ 마스크를 출력할 수 있어야 하는 것이다.
Pre-training
Promptable segmentation task는 각 학습 샘플에서 연속된 프롬프트(점, 박스, 마스크 등)를 simulation하고, 이를 ground truth와 비교하는 사전학습을 제안한다. interactive segmentation에서 채택한 방식이지만, 프롬프트가 모호한 상황에서도 효과적으로 사용되는 것을 목표로 한다는 점에 차이가 있다.
Zero-shot transfer
pre-training task는 추론 시 어떤 프롬프트에도 적절하게 응답하도록 해주기에, downstream tasks는 적절한 프롬프트를 설계함으로써 해결할 수 있다.
(ex. 고양이에 대한 bounding box detector가 있다면 그 output을 SAM의 프롬프트로 사용하여 고양이에 대한 instance segmentation을 수행할 수 있다.)
3. Segment Anything Model
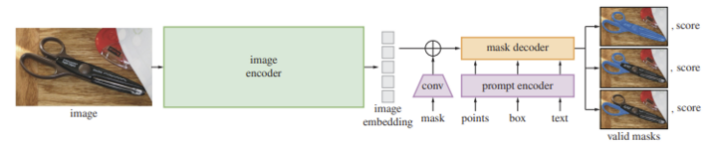
Image encoder
고해상도 입력을 처리하기 위해 최소한으로 조정된 MAE로 사전 학습된 ViT 모델을 사용한다. 이 image encoder는 각 이미지 당 한 번만 실행되고, 이는 모델에 프롬프트를 제공하기 전에 적용할 수 있기 때문에 ViT-H/16이라는 무거운 모델을 사용하였다고 한다. 출력은 input의 16배 downscaling 된 이미지 임베딩
Prompt encoder
프롬프트는 크게 두 가지로 고려될 수 있다. 첫 번째는 sparse 한 것(점, 박스, 텍스트), 두 번째는 dense 한 것(mask)이다.
- 점은 점 위치의 positional encoding과, 점이 전경 또는 배경 중 어디에 있는 지 나타내는 두 개의 학습된 임베딩 중 하나를 더한 것으로 나타낸다.
- 박스는 한 임베딩 쌍으로 표현된다.
- 왼쪽 위 모서리의 positional encoding과 ‘왼쪽 위 모서리’를 나타내는 learned embedding을 더한 것
- 오른쪽 아래 모서리의 positional encoding과 ‘오른쪽 아래 모서리’를 나타내는 learned embedding을 더한 것
- free-form text를 표현하기 위해선 CLIP의 text encoder를 사용한다.
- 마스크는 입력 이미지보다 4배 낮은 해상도로 입력하고, 2x2, stride 2의 convolution을 두 번 사용하여 추가적으로 4배 downscaling한다(그럼 이미지와 같이 16배 downscaling). 각 layer는 GELU activation과 layer normalization으로 구분된다. 이후 이미지 임베딩과 element-wise하게 더해진다.
Mask decoder
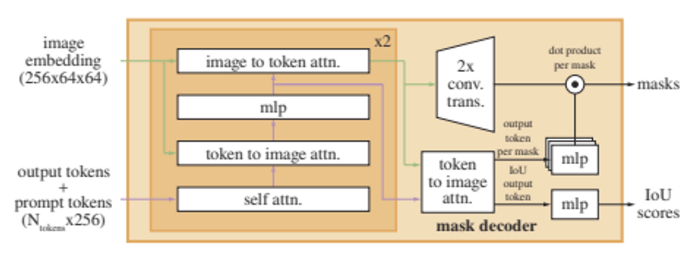
mask decoder에서는 Image embedding과 prompt embedding을 받아서 마스크를 예측한다.
두 input을 합치기 위해서는 Transformer segmentation models를 참고하였고 standard Transformer decoder를 약간 변형한 구조를 활용했다. decoder에 넣기 전에 prompt token에는 학습된 output token embedding을 삽입한다. 이를 저자들은 ‘tokens’ 라고 통칭한다.
각 decoder layer는 네 단계를 거친다.
- tokens에 self attention
- tokens를 쿼리로 하여 image embedding에 cross-attention
- point-wise MLP로 각 token을 업데이트
- image embedding을 쿼리로 하여 tokens에 cross-attention (이 단계로 image embedding을 prompt information으로 업데이트한다.)
- cross-attention동안, image embedding은 64x64 256차원의 벡터이다.
- 각각 self/cross-attention과 MLP는 residual connection을 갖고, layer normalization, dropout을 0.1로 적용하여 학습한다. 위 decoder layer는 두 번 사용된다.
decoder가 항상 중요한 위치 정보를 갖게 하기 위해, attention layer에 입력될 때 마다 Image embedding에 positional encoding을 더해 주고, 전체 original prompt token(positional encoding 포함)을 업데이트 된 token에 다시 더해준다.
decoder 수행 후, 업데이트 된 image embedding을 transposed convolutional layer를 거쳐 4배 upscaling 해준다. 다음, 한 번 더 tokens를 쿼리로 image embedding에 attention 해주고, 업데이트 된 output token embedding을 3-layer의 작은 MLP에 통과시키면 upscaled image embedding과 차원이 같아지고, 이 둘을 point-wise product 하여 마스크를 예측한다.
- Transformer는 embedding dimension으로 256을 사용한다.
- Transformer의 MLP blocks는 2048의 internal dimension을 갖지만, MLP는 비교적 작은 prompt token에만 적용된다.
- Cross-attention layers에서는 64x64의 image embedding을 사용하고, 계산 효율을 위해 queries, keys, values는 128로 두 배 줄여 사용한다.
- 모든 attention layers는 8개의 heads를 사용한다.
- upscaling을 위해 output image embedding에 적용되는 transposed convolution은 2x2, stride 2이다.
- output channel은 64와 32이며 GELU activation, layer normalization이 사용된다.
Resolving ambiguity

위 이미지처럼, 애매한 프롬프트가 주어진다면 다양한 valid mask들이 생성될 수 있다. 이러한 모호성을 해결하기 위해 저자들은 몇 개의 토큰들을 사용하여 여러 개의 마스크를 동시에 예측하였다. 기본적으로 세 개의 마스크를 예측하는데, 이는 중첩된 마스크를 설명하는 데 세 가지 layer면 보통 충분했기 때문이다(whole, part, subpart).
학습 중에는 예측된 마스크와 ground truth 사이의 loss를 계산하는데, backpropagation은 가장 loss가 적었던 마스크에 대해서만 진행한다. 이는 multiple outputs를 출력하는 모델에서 흔히 쓰이는 기법이다.
이를 응용하기 위해, 예측된 마스크의 순위를 매길 수 있는 small head를 추가하였다(additional output token에 적용된다).
여러 개의 프롬프트가 입력 될 경우에는 하나의 마스크만 예측하도록 추가 설계하였다.
Efficiency
image embedding이 미리 계산되었다면, prompt encoder와 mask encoder는 웹 브라우저에서 CPU로 50ms 내에 실행되었다.
Losses and training
마스크 예측은 Focal Loss와 Dice Loss를 20:1 비율로 선형 결합하여 사용하였다. IoU Prediction Head의 경우 IoU Prediction과 ground truth 사이의 MSE로 Loss를 계산하였다. 두 loss를 1:1로 합산하여 loss를 정의하였다.
4. Segment Anything Data Engine
인터넷에 segmentation masks가 충분하지 않기 때문에, 저자들은 data engine을 만들어 11억개의 마스크 데이터 셋인 SA-1B를 구축하였다. 과정은 세 단계로 나뉜다.
- model-assisted manual annotation stage
- semi-automatic stage
- fully-automatic stage
Assisted-manual stage
전통적인 interactive segmentation과 유사한데, 전문 Annotator들이 SAM으로 지원되는 웹 기반의 interactive segmentation tool에서 전경/배경 객체 지점을 클릭하여 마스크를 레이블링 하였다.
Annotator들에게 레이블의 의미 제약은 부과하지 않아서 같은 object를 ‘stuff’, ‘things’ 등으로 자유롭게 레이블링 하도록 했다.
이 단계의 SAM은 공개된 segmentation datasets를 통해 학습되었고, 충분한 data annotation이 수집되면 이를 이용하여 재학습 하였다. 이를 통해 image encoder는 ViT-B부터 ViT-H까지 확장될 수 있었다. 재학습은 총 6번 이루어졌고, 1단계 결과 120k개의 이미지 데이터로부터 4.3M개의 마스크를 생성했다.
Semi-automatic stage
모델의 segment anything 능력을 향상시키기 위해 마스크의 다양성을 높이고자 하였다. annotator들이 덜 두드러지는 물체에 집중할 수 있도록 하기 위해, 저자들은 먼저 confident mask를 탐지하여 이 마스크가 채워진 이미지를 annotator들에게 제공하고 주석이 달리지 않은 물체들에 추가적으로 주석을 달도록 했다.
confident mask를 탐지하는 과정은, 1단계에서 생성된 모든 마스크에서 일반적인 ‘객체’ 카테고리를 사용하여 학습했다. 이 단계에서 180k개 이미지에서 추가로 5.9M개의 마스크를 얻을 수 있었다.
1단계처럼 새로 얻은 데이터로 재학습하였다(5번 반복). 이미지 당 평균 마스크 개수는 automatic mask를 포함하여 44~72개 정도였다.
Fully automatic stage
이전 단계들에서 모델을 향상시키기에 충분한 마스크를 얻었고, ambiguity-aware 모델을 개발했기 때문에 마지막 단계에서는 annotation을 완전 자동으로 달 수 있었다.
- 모델에 32x32 regular grid 점을 프롬프팅했고, 각 점 별로 valid objects에 일치하는 마스크를 예측하도록 하였다.
- ambiguity-aware 모델을 이용하면 전체 object의 part, subpart, whole을 모두 반환해 주었다.
- IoU prediction module을 사용하여 confident mask를 선택하였다.
- 선택된 마스크 중에서도 stable한 것들만 선택하였다(probability map을 0.5 - , 0.5 + 로 thresholding 하고 비슷한 마스크를 생성하면 stable하다고 판단하였다).
- confident, stable 마스크가 선택되면, 중복을 제거하기 위해 non-maximal suppression(NMS) filtering을 하였다.
- 작은 마스크의 quality를 높이기 위해 multiple overlapping zoomed-in image crop 처리를 하였다.
위 과정을 11M개의 이미지에 적용하였고, 그 결과 1.1B개의 높은 퀄리티의 마스크를 얻을 수 있었다. 저자들은 해당 데이터 셋을 SA-1B로 이름지었다.
5. Segment Anything Dataset
위 과정에서 나온 데이터 셋, SA-1B는 11M개의 다양한 고해상도의 이미지와 1.1B개의 high-quality segmentation mask를 포함한다.
Images
이미지는 평균 3300x4950 픽셀의 고해상도이고, 데이터 사이즈를 고려해서 가장 짧은 쪽을 1500 픽셀로 downsampling하였고, 그러함에도 이미 존재하는 다양한 vision datasets보다 고해상도였다고 한다.
Masks
Data engine으로 생성된 1.1B개의 마스크 중 99퍼센트 이상이 완전 자동으로 생성되었다. 따라서 automatic mask의 품질은 중요하기에 저자들은 다양한 실험을 통하여 automatic mask가 고품질이고, 모델 학습에 충분히 효과적이라는 결론을 내었다.
Mask properties
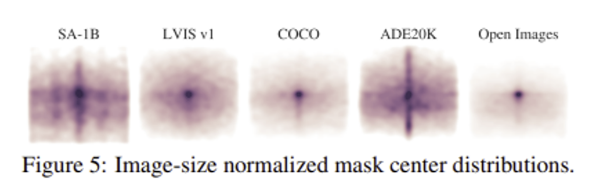
SA-1B를 포함하여 여러 오픈 데이터 셋에서 object centers의 spatial distribution을 그렸을 때, SA-1B에서는 다른 대규모 데이터 셋에 비해 center bias가 훨씬 적고 corner의 범위가 훨씬 넓게 분포함을 확인할 수 있다.
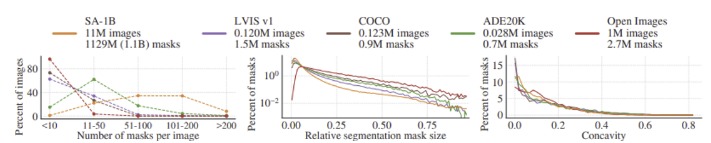
SA-1B는 이미지 당 마스크의 개수가 많으며, 비교적 작은 크기의 마스크를 더 많이 포함하고 있다. 마스크의 오목함(concavity) 분포는 다른 데이터셋과 유사하였다.
6. Segment Anything RAI Analysis
논문 원문 참고
7. Zero-Shot Transfer Experiments
Zero-Shot Single Point Valid Mask Evaluation
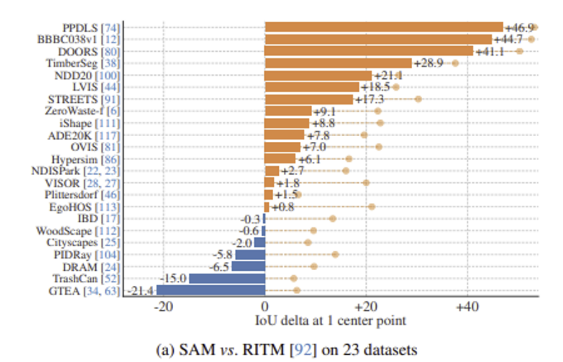
하나의 foreground point로 object segmentation 수행. 23개의 데이터 셋으로 평가했으며, 비교 모델은 RITM. 23개 중 16개 데이터 셋에서 RITM보다 우수한 결과를 내었다.
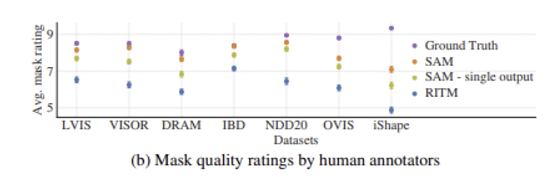
human annotators에 의해 평가된 7개 데이터 셋에 대한 mask quality.
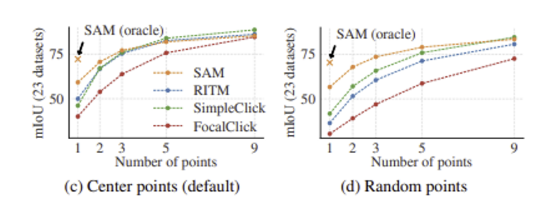
point 수를 늘림에 따른 mIoU를 보여주는 결과이다. 비교 모델에 비해 SAM이 우수한 성능을 보인다.
Zero-Shot Edge Detection

SAM이 edge detection에 대한 학습이 이뤄지지 않았음에도, Ground truth와 비교하여 훨씬 정교한 결과를 보여주었다.
Zero-Shot Object Proposals
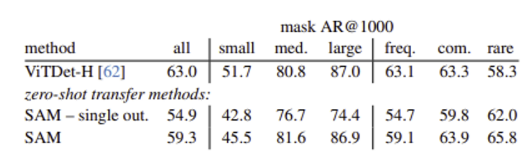
다양한 category 수를 가지는 LVIS 데이터셋에 대한 Object proposal task 결과를 실험하였다. 비교 모델은 ViTDet detector (DMP method).
중간이거나 큰 objects에 대해서는 SAM이 좋은 결과를 보였고, 작거나 빈번한 objects에 대해서는 나쁜 결과를 보였다.
Zero-Shot Instance Segmentation
위에서 나온 ViTDet로 bounding box를 얻고, 이를 다시 SAM에 입력 prompt로 하여 instance segmentation을 수행하였다. 비교 모델은 ViTDet.
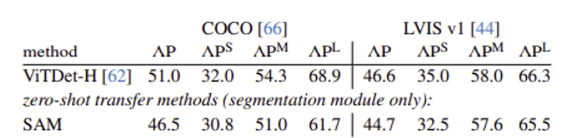
ViTDet보다는 성능이 낮았지만, 크게 뒤지지 않는 것을 확인할 수 있다.
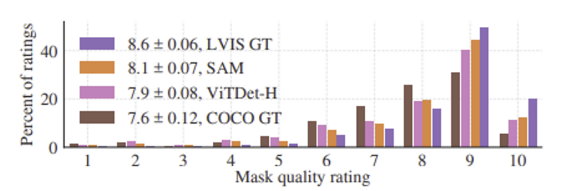
위의 Zero-Shot Single Point Valid Mask Evaluation에서와 마찬가지로 human annotators의 평가 결과 SAM이 human study에서 일관되게 ViTDet을 능가하는 것을 확인할 수 있다.
Zero-Shot Text-to-Mask
마지막으로 free-form text로부터 object를 segmenting하는 실험을 진행하였다.

free-form text prompt 만으로도 어느 정도 segmentation을 잘 수행할 수 있었으며, 실패한 경우에는 보조적인 point prompt와 함께 해결할 수 있을 것이라고 한다.

큰 사람이 될 것 같네요!