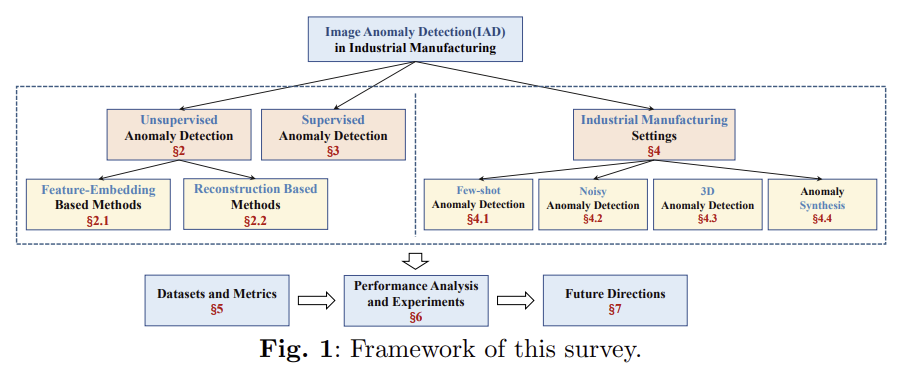
https://arxiv.org/pdf/2301.11514
1. Introduction
오늘날 제조업에서 Image Anomaly Detection(IAD)는 제조 공정의 마지막 단계에서 수행되며, 제품 결함을 식별하는 데 주력한다.
과거 사람이 직접 이상 탐지를 함으로써 발생하는 False positive, 높은 비용 등의 문제를 최근 딥러닝 기술을 통해 인력을 줄이고 생산성과 제품 품질을 향상 시키고자 한다. 본 survey 논문에서는 IAD에 대한 최근 연구 동향(dataset, metric, NN architecture 등)을 이전 survey 논문보다 더 심도 있게 다루고자 한다.
- 데이터 셋 측면에서, 본 연구는 기존 논문의 두 배에 달하는 IAD 데이터셋을 사용.
- Metric 에서는, image-level과 pixel-level metric을 모두 사용하여 가장 포괄적인 성능 분석을 수행.
- NN Architectures에 따라 다양한 정도의 supervision을 바탕으로 한 분류 체계를 개발.
- 실제 제조 환경에서 현재 IAD 알고리즘을 검토하여 학술 연구와 산업적 요구 간의 격차를 줄이고자 함.
Challenging Issues
산업용 이상 탐지에서 해결해야 할 주요 과제들은 아래와 같이 요약할 수 있다.
- 실제 제조 라인에서 수집된 real-world anomalous dataset이 필요하다. (연구실에서 수집 되었거나 정상 이미지에서 생성된 이상 이미지 말고)
- 현실적인 제조 공정을 simulate 하기 위해, multi domain IAD dataset이 필요하다.
- image-level과 pixel-level 모두에서 평가 가능한 통일된 metric 필요.
- 현실적인 제조 시나리오에서는 실제 이상 데이터가 제한되어있는데 여태까지의 연구는 semi-supervised보다 unsupervised에서 더 좋은 성능을 보인다. labelled와 unlabelled 데이터를 효율적으로 활용하기 위해 feature extraction과 loss function 설계에 더 주의할 필요가 있다.
2. Unsupervised Anomaly Detection
실제로 이상 샘플을 수집하는 데 막대한 비용이 들기 때문에, test set에서는 이상 샘플과 정상 샘플이 섞여있고, train set에서는 정상 샘플만 있다고 가정하는 Unsupervised 방식이 있고, 크게는 feature-embedding과 reconstructed-based로 나뉜다.
2.1 Feature Embedding based Methods
2.1.1 Teacher-Student Architecture
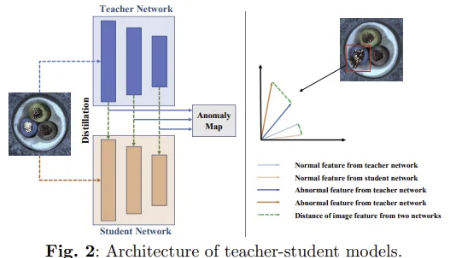
Knowledge distillation을 활용하여 사전 학습된 backbone network에서 일부 계층의 파라미터를 고정하여 teacher model로 선정하고, Student model에게 정상 샘플의 feature를 추출하는 지식을 전달한다.
Inference 시 test image를 두 모델에 넣어서 특징을 추출하는데, 그렇게 되면 normal image에서 얻은 두 특징은 유사한 반면, abnormal image에서 얻은 두 특징은 좀 다른 결과를 보인다. 그리고 이 두 네트워크로부터 생성된 feature map들을 비교하여 anomaly score map을 얻고, 이 map을 input image와 같은 사이즈로 맞춰주면 이미지에서 이상 위치의 anomaly score를 얻을 수 있고, 이를 바탕으로 test set에서의 비정상 유무를 판단할 수 있다.

MKD
- Student network structure를 Teacher network structure보다 가벼운 것을 써야 효과가 좋음을 입증하였다.
RSTPM
- STPM을 기반으로 두 쌍의 Teacher-Student network를 구성한다. 새로운 Teacher network는 original teacher-student network의 뒤에 붙어 feature를 재구성한다.
- anomalous image가 들어오면, student network는 teacher network와 구분되는 normal feature를 재구성한다.
- Teacher network에서 Student network로 feature를 전송하는 메커니즘으로 feature 재구성을 더 잘할 수 있다.
RD4AD
- RSTPM처럼 Teacher에서 Student로 feature를 전송하지만, RSTPM과 달리 하나의 Teacher-Student network를 사용한다.
- Multi-scale Feature Fusion (MFF) block과 One-Class Bottleneck(OCB)로 하나의 network만으로 feature reconstruction을 효과적으로 수행할 수 있도록 한다.
AST
- 동일 구조를 갖는 Teacher, Student model에서 추출한 abnormal image feature는 유사하다는 결론을 내리고, 비대칭 Teacher-student architecture를 제안한다.
- Normalized flow를 도입하여 두 네트워크 구조 간 불일치로 인한 estimation bias를 피하고자 하였다.’
IKD
- Adaptive hard sample mining module과 Context similarity loss를 통합하여 과적합 방지
2.1.2 One-Class Classification
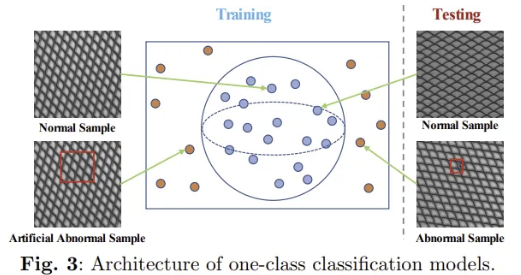
훈련 중 normal sample과 abnormal sample을 구별하기 위한 hypersphere를 찾고, 추론 시 test sample의 상대적 위치를 기반으로 정상인지 비정상인지 분류한다. 일부 방법은 hypersphere의 정확도를 높이기 위해 abnormal sample을 생성한다.
PatchSVDD
- 이미지를 균일한 패치로 나누어 모델에 입력하여 학습하여 이상 탐지 능력 향상
DSPSVDD
- SVDD 모델에 대해 hypersphere 부피 최소화 및 네트워크 재구성 에러 최소화를 동시에 고려하여, 더 효과적으로 심층 데이터 특징 추출
SE-SVDD
- Semantic Correlation Module(SCB)를 제안하여 비정상적 의미 표현과 이상 위치 탐지 정확도 향상
MOCCA
- Autoencoder로 feature를 추출하고 각 layer에서 normal feature의 경계를 찾아낸다.
FCDD
- OCC를 위해 Fully Convolutional Neural Network를 사용한다. convolution을 할 때 각 layer의 feature에서 상대적 위치는 변하지 않으므로, 해석 가능한 측면이 있다.
PANDA
- Early stopping 매커니즘을 도입하였고, 유클리디언 거리 대신 confidence-invariant angular center loss를 도입하였다.
DisAug CLR
- Two-stage를 갖는데, 첫 번째에서는 distribution-enhanced constrastive learning을 통해 contrastive representation의 균일성을 방해하여 이상 샘플과 정상 샘플이 잘 구분된다.
- 두 번째에서는 첫 번째 단계를 통해 학습된 representation을 기반으로 one-class classifier를 구축한다.
Contrastive Predictive Coding(CPC)
- 패치 단위의 contrastive loss를 anomaly score로 활용하여 anomaly를 localize한다.
Inspired by saliency object detection..
- saliency detection을 활용하여 anomaly detection을 수행한 다양한 방법도 존재한다.
- Bai et al. 는 이상 탐지를 위해 퓨리에 변환을 사용하였다.
- Niu et al. 는 salient object detection으로 객체의 윤곽을 얻어 이상탐지에 활용하였다.
- Qiu et al. 는 Multi-Scale Saliency Detection(MSSD) 를 제안하여 전경을 분리하고 coarse한 anomaly region을 얻은 다음, 이를 다듬어서 결과를 얻었다.
- CutPaste, CAVGA는 GradCAM을 활용하여 pixel-level anomaly localization에 활용하였다.
CutPaste
- 이름 그대로 정상 이미지의 일부를 잘라 붙여 이상 이미지를 생성하고, 이를 통해 네트워크가 이상 이미지를 구별할 수 있도록 한다.
Segmentation-based methods
- Iquebal et al. 는 이미지 레이블의 maximum posterior estimation이 연속적인 max-flow problem으로 공식화 될 수 있다고 입증하고 이미지 도메인에서 Markov random field를 사용하여 반복하여 flow를 얻어 anomaly segmentation을 수행한다.
- MemSeg 는 정상 이미지의 feature를 memory bank에 저장하여 segmentation network가 이상 영역을 잘 구분하도록 한다. 배경의 영향을 막기 위해 외부 데이터 셋의 이상치를 객체의 전경(foreground)에서만 도입한다.
2.1.3 Distribution Map
학습에 적절한 mapping objective를 필요로 하는 방법이며 mapping method에 따라 모델 성능은 영향을 받게 된다.

mapping 능력이 강한 Normalizing Flows-based method들이 SOTA를 찍고있는 추세이다. OCC-based method들은 feature boundary를 찾는 데 주력하지만, mapping-based method들은 feature들을 원하는 분포로 mapping하는 데 주력한다.
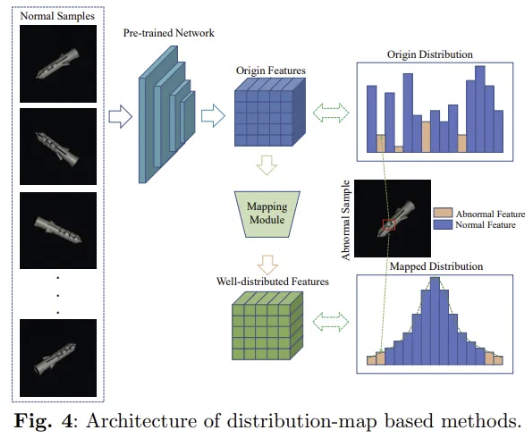
보통 framework는 Fig. 4 형태를 띤다. pre-trained network로 normal image의 feature를 추출한 뒤 mapping module을 통과시켜 feature 분포를 Gaussian 분포로 만들어준다. 이후 eval에서 이상 샘플을 받게 되면 그 분포는 해당 분포에서 벗어나게 되고, 그 정도에 따라 abnormal probability가 계산된다.
Tailanian et al.
- patch PCA와 ResNet을 사용하여 만든 feature map에 통계분석을 적용하였다.
Rippel et al.
- pre-trained network의 feature representation에 다변량 가우시안을 적용하여 정상성 모델을 구축하였지만, catastrophic forgetting이 해결되지 않았다.
- 이후, generative/discriminative modeling 간 관계를 기반으로 정상 클래스에 대한 다변량 가우시안 분포를 생성하고, Deep SVDD와 FCDD를 이용하여 catastrophic forgetting 문제를 해결하였다.
PEDENet
- Patch Embedding, Density Estimation, Location Prediction networks를 사용하여 patch embedding의 상대적 위치를 예측하고, inference 땐 예측된 결과와 실제 결과 간 차이에 기반하여 이상 판단한다.
Pre-trained Feature Mapping(PFM)
- feature mapping의 성능을 높이기 위해 양방향 / 다계층 양방향 pre-trained feature mapping을 제안한다.
Wan et al.
- PFM에 position encoding을 추가한 Position Encoding enhanced Feature Mapping을 제안한다.
FYD
- 처음으로 산업 이미지 이상 탐지에 registration을 도입했으며, 객체의 전경을 image level에서 정렬하는 coarse-to-fine alignment method를 제안하였다.
- refinement alignment 단계에서는 non-contrastive learning으로 배치 내 모든 대응되는 위치 간 feature들의 유사도를 높였다.
Normalizing Flows-based methods
확률 분포를 가역 mapping을 통해 복잡한 분포를 만드는 기술이다.
정상 샘플에서 pre-trained model로 feature를 추출하고 학습 시 feature 분포를 가우시안 분포로 변형한다. test 시 비정상 샘플이 NF를 지나면 가우시안 분포로부터 벗어나있다는 점을 이용한다.
DifferNet
- 최초로 이미지 이상탐지에 NF를 도입
CS-Flow
- NF에 cross-convolution block을 포함하여 확률을 할당하고 multi-scale feature map 간 맥락을 활용하여 DifferNet을 개선.
CFlow-AD
- Conditional normalizing flow에 positional encoding을 추가하여 좋은 성능을 보였다.
- 이전 모델에서 다변량 가우시안 가정이 타당함을 심층 분석하였다.
- 일반적인 NF 프레임워크가 적은 계산량으로 유사한 결과에 수렴하는 이유를 설명
FastFlow
- 크고 작은 convolutional kernel을 교차로 stacking하는 방식을 도입하여 전체적이고 지역적인 분포를 효과적으로 모델링한다.
CAINNFlow
- NF module에 attention mechanism인 CBAM을 도입하여 성능을 향상시켰다.
AltUB
- CFlow-AD와 FastFlow의 feature distribution 중심이 0이 아니기 때문에 성능이 불안정하다는 점을 개선하고자 NF의 base distribution을 update하기 위해 alternating training을 제안하였다.
2.1.4 Memory Bank
학습 시 loss function이 필요하지 않고, 모델은 빠르게 구축된다. 강건한 pre-training network와 추가적인 메모리 공간에 의해 성능이 보장되고, IAD task에서 가장 효과적인 방법이다.
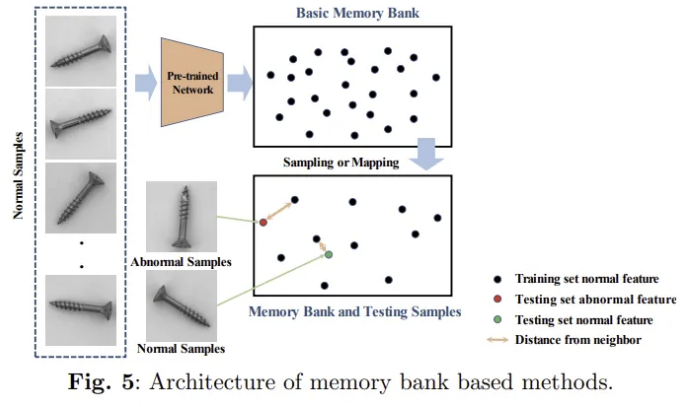
OCC-based method와 memory bank-based method의 가장 큰 차이는 image feature를 저장하기 위한 추가적인 메모리 공간을 사용하느냐 이다.
네트워크 훈련은 최소화하고, 추론을 위한 정상 샘플 feature을 sampling하거나 mapping이 필요하다.
추론 시에는 test image의 feature를 memory bank의 feature들과 비교한다. 이상 확률은 memory bank의 normal feature들과의 spatial distance 그 자체가 된다.

Semantic Pyramid Anomaly Detection (SPADE)
- KNN 으로 multi-resolution feature pyramid 기반 pixel-level anomaly segmentation 결과를 얻는다.
PaDim
- 정상 클래스의 probabilistic representation을 얻기 위하여 다변량 가우시안 분포를 사용하고, 결과적으로 memory bank의 크기는 train set 크기가 아닌 이미지 해상도의 영향을 받게 된다.
- 다차원 공분산 텐서의 배치를 역으로 계산해야하기 때문에 feature size가 큰 large CNN으로의 확장이 어렵다.
- 이후 Kim et al. 은 semi-orthogonal embedding에 random feature selection을 일반화하여 계산 비용으로 세 배 감소 시켰다.
SOMAD
- multi-scale features에 기반한 topological memory로 normal characteristics를 보존한다.
GCPF
- SOMAD와 마찬가지로 normal feature를 보존한다.
- standard characteristics를 multiple independent multivariate Gaussian clustering으로 변환한다.
PatchCore
- MVTec AD 데이터에서 큰 성과를 거둔 method.
- inference 시간을 낮추기 위해 memory bank를 coreset-subsampled로 샘플링하여 사용
- Test sample의 feature와 Memory bank에서 가장 가까운 feature 간 거리를 통해 anomaly score를 계산하는데, reweighting 기법도 추가하여 robust 하다.
CFA
- Memory bank에서 transfer learning을 통해 hypersphere의 중점과 표면을 얻고, test feature와, 결합된 hypersphere 간의 위치적 관계를 활용하여 이상을 탐지
FAPM
- 다양한 위치에 patch 단위 및 layer 단위 memory bank들로 구성되고, inference 때 feature들을 각 memory bank에서 독립적으로 계산하여 속도가 빠르다.
N-pad
- 인접 픽셀과 타겟 픽셀 feature 로 픽셀 단위의 nominal distribution을 추정하고 작은 정렬 오류의 가능성을 허용한다.
- 타겟 픽셀과 추정된 분포 간 마할라노비스 거리와 유클리디안 거리를 모두 사용하여 anomaly score가 계산된다.
Bae et al.
- 위치 정보를 조건부 확률로 사용하여 누적 히스토그램을 모델링하고, 이웃 정보를 통해 normal feature distribution을 구축한다.
- Anomaly detection, localization problem에서 최초로 refinement를 사용하였다. 이는 합성된 이상 이미지를 활용하여 input image 기반의 anomaly map을 개선하고, 분포를 추정하기 위해 이웃/위치 정보를 활용한다.
Tsai et al.
- embedding position information을 학습하고 inference 때 추출된 feature를 normal embedding과 비교한다.
Zou et al.
- backbone network를 학습하기 위해 contrastive learning을 활용하고 SPD라는 새로운 data augmentation을 적용하는데, 이는 네트워크가 미세한 차이를 가진 두 이미지 간 구별을 강화하도록 한다.
- backbone network로써의 PatchCore의 능력을 입증했다.
2.2 Reconstruction-based methods
Encoder와 decoder를 자체적으로 학습하여 이미지를 재구성하고 이상 탐지를 수행한다. 이는 pre-trained model에 대한 의존도를 낮추고 이상탐지 능력을 향상시킨다. 하지만 high-level의 semantic feature를 효과적으로 추출할 수 없어서 이미지 분류 성능은 상대적으로 낮은 편이다.
대체로 손실 함수는 유사하지만 모델 paradigm과 이상 샘플 생성 방법 차이로 인해 성능이 달라진다.
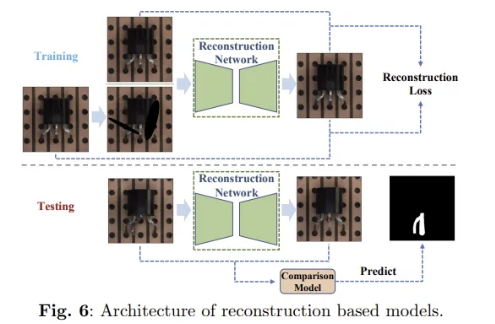
학습 과정에서는 정상/비정상 샘플들이 reconstruction network로 보내지고, reconstruction loss function을 통해 학습된다. 최종으로 reconstruction network가 기존의 정상 이미지와 유사하게 이미지를 복원시킨다.
추론 시에는 비교 모델이 원본 이미지와 복원된 이미지를 비교하여 예측을 수행한다.
다양한 feature embedding based 방식들에 비해, reconsturction-based 방식들은 reconstruction network의 구조만 다른 경우가 많고, pixel-level에서 성능이 좋다. 그러나 pre-trained model을 사용하지 않고 처음부터 학습을 하기 때문에 image-level feature embedding보다 성능이 낮은 경우가 많다.
2.2.1 Autoencoder
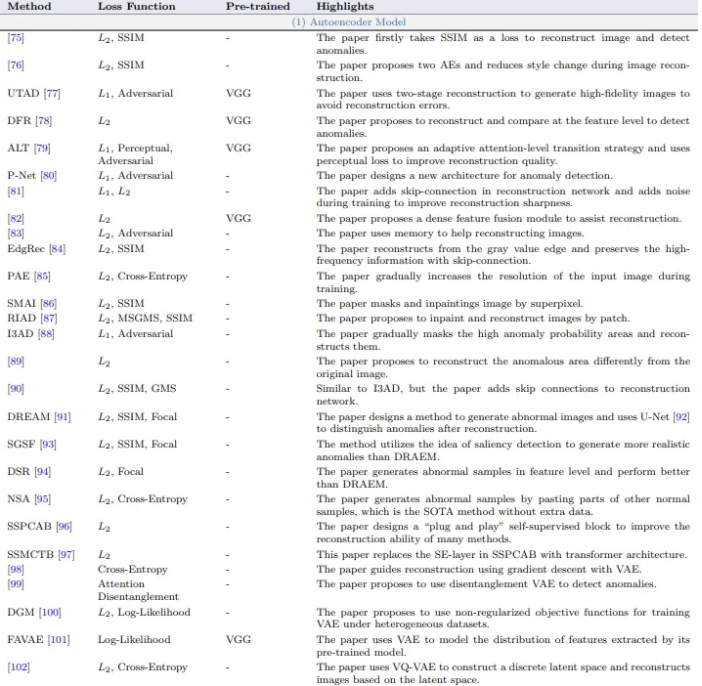
이상탐지 reconstruction-based methods 중 가장 널리 사용되는 네트워크로, 다른 reconstruction-based networks 또한 encoder와 decoder로 구성 된 경우가 많다.
Bergmann et al.
- AE reconstruction과 anomaly segmentation에서 Structure Similarity Index Measure (SSIM)와 loss의 영향을 조사하여 향후 연구를 위한 여러 제안을 제시하였다.
Chung et al.
- AE의 style translation을 보존하고 content translation을 억제하여 over-detection을 피하고자, Outlier-Exposed Style Distillation Network(OE-SDN)을 제안하였다.
- Anomaly prediction에서 원본 이미지와 AE로 복원된 이미지를 비교하는 대신, OE-SDN으로 복원 된 이미지와 AE로 복원된 이미지를 비교하는 방식으로 대체하였다.
UTAD
- IE-Net과 Expert-Net을 도입하여 anomaly-free하고 high-fidelity(고품질) reconstruction을 위한 impression을 추출하고 이용하여 framework에 해석가능성을 제공한다.
DFR
- pre-trained network에서 multiple spatial context-aware representation을 얻은 후 convolutional AE로 feature를 재구성한다. 그리고 original feature와 비교하여 anomalous region을 얻는다.
MLIR
- 다양한 해상도에서 이미지의 denoising 작업을 거쳐 이미지를 재구성한다.
- 전체적인 구조의 이상과 디테일한 이상을 모두 탐지 가능하다.
P-Net
- 원본 이미지와 재구성 된 이미지의 구조를 비교하고자 하였다.
Collin et al.
- 재구성의 sharpness를 개선하기 위해 encoder와 decoder 사이에 skip connection을 추가하였다.
- network가 동일한 패턴을 반복적으로 mapping하는 것을 막기 위해 synthetic noise model로 이미지를 훼손하였고, 이를 위해 Stain noise model을 소개하였다.
Tao et al.
- Dense feature module로 두 개의 input의 dense feature representation을 얻어 dual-Siamese framework에서 재구성을 지원하였다.
Hou et al.
- Collin et al. 과 마찬가지로 skip connection으로 재구성의 질을 높였다.
- skip connection에 memory module을 추가하였다.
Liu et al.
- 회색값 edge로부터 원본 RGB 이미지를 재구성하며, skip connection으로 이미지의 고주파 정보를 보존하여 재구성에 더 좋은 가이드를 주었다.
PAE
- Progressive learning과 수정된 CutPaste 증강으로 재구성 성능을 향상시켰다.
- Progressive learning : 학습 시 점차 input image의 해상도를 높이는 것
SMAI
- 이미지를 여러 superpixel 블록으로 나누고, 마스크 내 superpixel을 재구성하기 위해 inpainting module을 학습시킨다.
- Inference 시에는 테스트 이미지에 대해 superpixel 단위로 masking과 inpainting을 수행한 후 재구성 된 이미지와 테스트 이미지를 비교하여 이상 영역을 판별한다.
I3AD
- Anomaly map에 기반하여 부분 영역을 재구성한다.
- 이미지에서 inpainting mask만 재구성하고 이상 확률이 높은 영역만 masking함으로써 재구성 퀄리티를 높였다.
SSM
- Reconstruction network에 skip connection을 추가하고, 마스크 영역을 학습 대상으로 한다. 컨셉은 I3AD 와 유사
RIAD
- 학습 이미지를 패치 단위로 랜덤하게 마스킹하고 U-Net의 encoder-decoder network를 사용하여 재구성한다.
- 추론 시에는 다양한 랜덤 마스크와 재구성 패치를 결합하여 재구성 이미지를 만든 후, 이를 원본 이미지와 비교한다.
- Multi-Scale Gradient Magnitude Similarity(MSGMS) 는 이상 점수로써 SSIM보다 우수하다고 한다.
DRAEM
- 외부 데이터 셋을 활용해 비정상 이미지를 합성하여 정상 이미지로 재구성하는 방식을 사용하였고, 이는 reconstruction network의 일반화 능력을 향상 시켰다.
- 원본 이미지와 재구성 된 이미지를 segmentation network에 넣어 이상 영역을 예측하여, 모델의 이상 영역 segmentation 성능을 향상시켰다.
- near-in-distribution anomalies를 합성할 때 실패할 가능성이 있다.
- Xing et al.은 더 현실적인 이상 이미지를 합성하도록 Saliency Augmentation Module을 제안하여 더 나은 성능을 보일 수 있었다.
DSR
- image level의 anomaly 생성 없이도 작동 가능한 아키텍처를 제안한다.
- Quantized(양자화) feature space representation과 dual decoder에 기반하여, 학습된 quantized feature space에서 feature level로 샘플링하여 near-in-distribution anomaly를 제어된 방식으로 생성한다. (DRAEM 단점 해결)
NSA
- 외부 데이터를 사용하여 data augmentation을 하는 대신 다양한 data augmentation 방식을 채택하여, 추가 데이터셋을 쓸 필요 없이 앞서 언급한 methods보다 뛰어난 성능을 보였다.
Bauer
- 이상 이미지를 정상 이미지로 재구성하려는 시도와 다르게, 이미지의 비정상 영역을 원본 이미지의 외형에서 벗어나도록 재구성하였다.
SSPCAB
- 재구성 기반 기능을 Self-Supervised Predictive Architectural Building Block (SSPCAB) 에 통합하고, 이 SSPCAB는 DRAEM이나 CutPaste같은 모델에 결합되어 사용될 수 있다.
SSMCTB
- SSPCAB의 SE-layer를 channel-wise transformer block으로 바꾼 방식
아래는 VAE (Variational Autoencoder) 기반 방식
Dehaene et al.
- 재구성 손실로 정의된 에너지를 사용하여 gradient descent로 재구성을 반복적으로 가이드하여 VAE가 blurry(흐릿한) 재구성을 만드는 것을 해결하고, 정상적인 고주파 구조를 유지하였다.
Liu et al.
- Attention disentanglement loss로 VAE를 학습시킨다. 이 VAE는 gradient backprop과 attention generation 시 가우시안 분포에서 벗어나는 latent variable을 만들어내고, 이를 통해 이상 위치를 알아낼 수 있다.
Matsubara et al.
- 데이터셋이 정규화되지 않은 이질적인 경우가 많고, 이런 데이터셋에서 VAE를 학습하려면 정규화되지 않은 목적 함수가 더 적합함을 주장했다.
FAVAE
- pre-trained model에서 추출된 feature 분포를 모델링하기 위해 VAE를 활용하였고, 더 풍부한 이상을 시뮬레이션하고 모델 일반화 성능을 강화했다.
VQ-VAE
- Discrete(이산) latent space를 만들고, 정규 분포에서 벗어난 discrete latent space를 리샘플링 후 이를 이용하여 이미지를 재구성한다. Training set의 정상 이미지에 근접한 이미지를 재구성하게 된다.
2.2.2 Generative Adversarial Networks
Autoencoder 기반 모델에 비해 안정성이 떨어지는 경우가 많지만, discriminant network이 특정 면에서 더 나은 성능을 보일 수도 있다.

SCADN
- GAN을 이용하여 이미지의 특정 부분을 마스킹하고 재구성한다.
- 입력 이미지와 재구성 이미지를 비교하여 이상을 탐지한다.
AnoSeg
- 이상 샘플을 만들기 위해 hard augmentation, adversarial learning, channel concatenation을 활용한다.
- 이후 GAN이 정상 샘플을 만들어내도록 학습시킨다.
- AE 기반 모델과의 차이점은 reconstruction loss와 adversarial loss를 모두 사용한다는 점.
OCR-GAN
- Frequency Decoupling module로 이미지를 다양한 주파수 조합으로 분리한 후, 재구성 이미지를 만들기 위해 이 주파수들의 정보를 재구성한다.
- 추론 시 모델은 정상 이미지와 비정상 이미지 간 주파수 분포의 통계적으로 유의한 차이를 식별할 수 있다.
2.2.3 Transformer
Global information을 갖는 높은 수용력을 가지고 있으며, 이러한 특징으로 Anomaly Detection에서도 AE를 뛰어넘을 수 있는 잠재력을 가지고 있다.

Mishra et al.
- Transformer-based framework로 patch level 이미지를 재구성하고, gaussian mixture density network로 이상 영역을 localizing한다.
You et al.
- ADTR을 제안하여 pre-trained features를 재구성하고자 하였다.
- Transformer를 사용하면 잘못 재구성된 이상 데이터를 방지할 수 있어서 재구성이 실패할 경우 이상을 쉽게 식별할 수 있다고 주장하였다.
Lee et al.
- Vision Transformer-based AnoViT를 제안하여 CNN-based 모델인 CAE보다 우수함을 보였다.
HaloAE
- HaloNet에 Transformer를 도입하여 MVTec AD 데이터셋에서 좋은 결과를 보였다.
Pirnay et al.
- 전통적인 CNN architecture들은 global context information을 추출하기 어렵다는 점을 극복하고자, input image로부터 더 넓은 영역의 정보를 포함하는 Inpainting Transformer(InTra) 를 제안하였다.
MSTUNet
- InTra와 유사하지만, 이상을 시뮬레이션 할 때 추가적인 개선으로 좋은 결과를 얻었다.
De et al.
- 마스킹 된 패치를 재구성하기 위해 이웃 패치를 활용하였고 좋은 성능을 얻었다.
2.2.4 Diffusion Model
최근 인기를 얻고 있는 생성 모델로, 이상 탐지에서도 연구가 진행되고 있다.

AnoDDPM
- 산업용 이미지 이상 탐지에 가장 먼저 diffusion model을 사용하였다.
- 단순 노이즈로 대규모 데이터 셋 없이도 큰 이상 영역을 잘 포착할 수 있다.
Teng et al.
- Reconstruction loss 대신, 시간 의존적인 정상 데이터 분포의 gradient 값을 결함 측정을 위한 새로운 지표로 사용하였다.
- T-scales method로 반복 횟수를 줄이고 추론 과정을 가속화 하였다.
3. Supervised Anomaly Detection
비정상 데이터는 다양하고 수집하기도 어렵지만, 여전히 real-world 시나리오에서는 비정상 샘플 수집이 가능하다. 따라서, 적은 양의 비정상 샘플과 많은 양의 정상 샘플을 활용하여 학습하려는 연구도 진행되고 있다.
Chu et al.
- 데이터 불균형 상태에서 이상 탐지를 위한 semi-supervised framework를 제안
- 학습 중 loss 값의 변화를 feature로 사용하여 비정상 데이터를 식별할 수 있다고 가정
- 강화 학습 기반의 neural batch sampler를 학습 시켜 비정상 영역과 정상 영역의 손실 곡선 차이를 증폭 시켰다.
CAVGA
- Convolutional Adversarial Variational Autoencoder with Guided Attention
- Attention expansion loss로 모든 정상 영역에 집중하도록 유도된다.
- Weakly supervised setting에서는 비정상 영역을 최소화하면서 정상 영역에 집중하도록 상호보완적인 guided attention loss를 사용한다.
Bovzivc
- 동일한 딥러닝 프레임워크 내에서 표면 결함 탐지 작업에 대한 image-level supervision information, mixed supervision information, pixel-level supervision information의 각 영향에 대해 조사하였다.
- 소수의 pixel-level annotation이 모델이 full supervision에 비교 가능한 성능을 보여준다는 것을 발견하였다.
DevNet
- 소수의 비정상 샘플을 활용하여 fine-grained end-to-end differentiable learning을 실현하였다.
Wan et al.
- 불균형 데이터 분포에서 Logit Inducing Loss 를 도입하여 학습하였고, 비정상 feature를 특성화하기 위한 Abnormality Capturing Module을 제안하여 적은 양의 이상 정보를 효과적으로 활용하였다.
DRA
- 관찰된, 가상으로 생성된, 잠재적 잔여 이상들이 얽힌 표현을 학습하여 시각적/비시각적 이상을 모두 탐지하고자 하였다.
아래 연구들은 정상/비정상 샘플의 불균형 분포를 고려하지 않고, 주로 비정상 샘플에 의존한 supervised learning
Singdagi et al.
- 다양한 setting의 anomaly detection을 위한 데이터셋의 domain transfer 문제를 조사하였다.
Qiu et al.
- 이미지 정합 및 표면 결함 탐지를 위한 Dual Weighted PCA (DWPCA)를 제안
Bhattacharya et al.
- An interleaved Deep Artifacts-aware Attention Mechanism (iDAAM)을 제안하여 비정상 이미지에서 다중 객체 / 다중 클래스 결함을 분류
Zeng et al.
- Anomaly Detection을 Target Detection의 하위로 보고, 템플릿 참조/컨텍스트 참조를 사용하여 이상탐지를 하는 Reference-based Defect Detection Network (RDDN) 를 제안하였다.
Song et al.
- 이상 영역을 이미지의 saliency(주목) 영역으로 생각하고 효과적인 saliency propagation 알고리즘을 제안하였다.
Long et al.
- 촉각 이미지에서의 이상 탐지를 조사하여 직물 결함 탐지에 이점을 제공하였다.
아래는 Semantic segmentation의 컨셉을 참조한 방법
Hu et al.
- 혼합 다차원 공간 및 시간 분할 모델 제안
Ferguson et al.
- Mask Region-based CNN architecture로 X-ray 이미지에서 결함을 동시에 탐지/분할한다.
이 외에도 다양한 full supervision 방식과 weakly supervision 방식이 있음.
4. Industrial Manufacturing Setting
해당 섹션에서는 few-shot anomaly detection, noisy anomaly detection, anomaly synthesis, 3D anomaly detection 등 산업 현장에 적합한 분류 기준 및 응용 세팅을 소개한다.
4.1 Few-Shot Anomaly Detection
Few shot learning을 활용하면 아래와 같은 장점이 있다.
- 산업 제품의 데이터 수집 및 주석 비용을 줄일 수 있다.
- 데이터의 관점에서 문제를 해결 가능하고, 산업용 이상 탐지에서 어떤 종류의 데이터가 가장 가치 있는지 알 수 있다.
대표적으로 아래 두 가지 세팅이 있다.
4.1.1 Meta-Learning
Meta-Training dataset으로써 아주 많은 양의 이미지를 필요로 한다.
MetaFormer
- 메타 학습된 파라미터를 이용하여 높은 모델 적응력을 달성하고, instance-aware attention을 통해 이상 영역을 localizing한다.
RegAD
- 카테고리와 무관한 이상을 탐지하도록 학습된다.
- 테스트 단계에서, 테스트 이미지와 해당 정상 이미지의 등록된 feature를 비교하여 이상을 탐지한다.
4.1.2 Vanilla Zero/Few-shot Image Learning
PatchCore, SPADE, PaDim 모두 16개 정상 학습 샘플에 대한 ablation study를 진행했지만, few-shot anomaly detection에 특화되어있진 않다. 따라서 본질적인 few-shot anomaly detection에 중점을 둔 알고리즘들이 개발 될 필요가 있다.
또, 최근엔 Zero-shot Anomaly Detection(ZSAD) 세팅을 Few-shot Anomaly Detection(FSAD) 세팅을 넘어 확장하였다. 이는 대규모 모델의 일반화 능력을 활용하여 학습 없이 이상 탐지 문제를 해결하여 데이터 수집 및 주석 비용을 완전히 없애고자 한다.
MAEDAY
- 사전 학습된 Mask autoencoder로 해당 문제에 접근한다. 이미지 일부를 랜덤 마스킹 후 이를 MAE로 복원하여, 마스킹 이전 영역과 다르다면 이상으로 판별한다.
WinCLIP
- 대규모 모델 CLIP의 image encoder로 image feature를 추출한다.
- “A photo of a damaged object” 라는 텍스트를 CLIP text encoder에 넣어 해당 설명의 feature를 얻는다.
- 이후 두 feature를 비교하여 유사도가 높으면 정상으로, 낮다면 비정상으로 판별한다.
4.2 Noisy Anomaly Detection
Anomaly Detection에서 고전적인 문제 중 하나이다. Noisy learning을 통해 레이블 오류로 인한 성능 저하를 방지하고, 이상 탐지에서의 false detection을 줄일 수 있다.
Tan et al.
- 새로운 신뢰 영역 메모리 업데이트 방식으로 memory bank에서 noise feature point를 멀리 떨어트린다.
Yoon et al.
- OOC model의 성능을 개선하기 위해 data refinement(데이터 정제) 접근법을 사용하였다.
Qiu et al.
- 레이블 되지 않은 이상 데이터가 있는 상황에서 detector를 학습시키기 위한 전략을 제안하며 이는 모델의 광범위한 클래스와 호환된다.
- 레이블 된 이상 샘플을 합성하고, 정상 데이터와 합성 이상 데이터로 손실 함수를 최적화한다.
Chen et al.
- Interpolated Gaussian Descriptor를 도입하여 적대적 보간 학습 샘플로 one-class Gaussian anomaly classifier를 학습시킨다.
하지만 위 방법들은 real industrial image datasets에서는 검증되지 않았다.
4.3 3D Anomaly Detection
3D anomaly detection은 RGB image의 더 많은 공간 정보를 활용할 수 있다. 몇몇 특정 조명 환경이나 색상 정보에 민감하지 않은 이상탐지에서 좋은 효과를 보여줄 수 있다. 현재 학계에서 주목받는 방향이다.
Bergmann et al.
- Teacher-Student 모델을 활용하였다.
- Teacher network는 학습을 통해 local receptive fields를 다시 만듦으로써 일반적인 local gemetric descriptors를 얻는다.
- Student network는 사전 학습된 teacher network의 local 3D descriptors와 일치하도록 학습된다.
BTF
- FPFH 같은 수작업으로 만든 3D representation과 PatchCore 같은 2D feature representation 방식을 결합하였다.
Reiss et al
- 3D anomaly detection에서 현재로서는 self-supervised 방식보단 수작업 된 feature 표현 능력이 우세하다고 주장하였다.
- 하지만 대규모 3D anomaly detection 데이터를 활용하면 self-supervised 방식은 여전히 큰 잠재력을 지닌다.
AST
- depth 정보를 포함한 RGB 이미지를 활용하였다.
- 하지만 대부분의 3D IAD 방법은 RGB-D 이미지에 특화되어있으며, 실제 산업 제조 환경의 3D 데이터셋은 point clouds로 구성되어있다. 이는 아직 3D IAD 방법 이 실제 산업 제조 환경에 직접적으로 활용되기엔 어렵다는 점을 의미한다.
→ 따라서 아직 발전 가능성이 많다.
4.4 Anomaly Synthesis
인공으로 이상 데이터를 합성하는 방식은 Few-shot learning 연구를 보완하는 연구가 될 수 있다. Few-shot learning은 고정된 데이터에서 모델 성능을 향상시키는 반면, anomaly synthesis는 고정된 모델에서 신뢰할 수 있는 데이터를 인위적으로 증가시켜 성능을 개선한다.
여러 unsupervised anomaly detection은 데이터 증강을 활용하여 합성된 이상 이미지를 생성하여 성능을 향상시켰다. CutPaste, DRAEM, MemSeg가 대표적이다.
Liu et al.
- Semantic Segmentation 학습을 위해, 결함이 없는 직물 이미지에서 결함을 만들도록 모델을 디자인하였다.
rippel et al.
- ResNet과 U-Net을 generator로 사용하는 CycleGAN 을 기본 구조로하여 결함을 한 직물에서 다른 직물로 전이하는 방식을 활용
SDGAN
- Style transfer network를 개선하여 CycleGAN보다 성능을 향상시켰다.
Wei et al. (DST)
- DST라는 모델을 통해 결함 샘플을 시뮬레이션 하고자 하였다.
- 먼저 결함이 없는 이미지에 빈 마스크 영역을 생성하고, masked histogram matching module을 통해 빈 마스크 영역의 색을 이미지의 전반적인 색과 일치시킨다.
- 마지막으로 DST는 U-Net을 이용해서, 생성된 이미지를 더 현실적으로 만들기 위해 style transfer를 수행한다.
Wei et al. (DSS)
- 전통적인 GAN으로 이상 없는 샘플의 지정된 영역에 defect structure를 재구성하는 DSS 라는 모델을 제안한다.
- 그 후 DST를 활용하여 결함을 배경에 자연스럽게 섞었다.
Jain et al.
- DCGAN, ACGCN, InfoGAN으로 노이즈를 더해 결함 이미지를 생성하여 분류 정확도를 높이고자 하였다.
Wang et al.
- StarGANv2에 기반한 DTGAN을 제안했으며, 이는 전경-배경 decoupling과 style control을 추가하고, Frechet inception distance와 kernel inception distance를 사용하여 생성 이미지의 품질을 평가하였다.
DefectGAN
- 결함과 정상 배경을 layer로 분리할 수 있으며(결함이 전경), 결함 전경과 그 공간 분포를 style transfer 형태로 생성한다.
해당 분야는 상당 연구가 진행되고 있지만, 방향이 잘 정립되어있지 않아 여전히 추가적인 발전 가능성이 많다.
5. Datasets and Metrics
Datasets
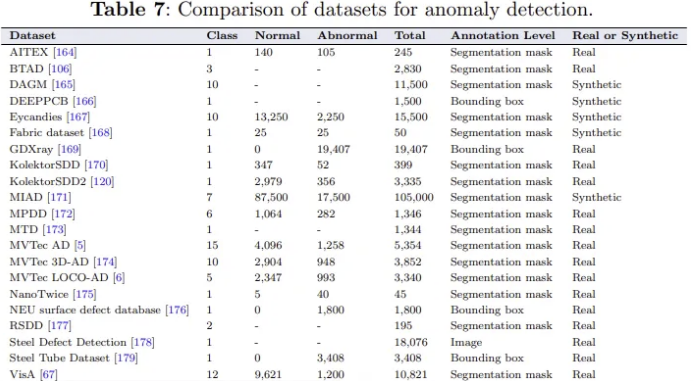
IAD 데이터 셋은 크기나 수가 점점 증가하고 있지만, 대부분은 실제 생산 라인에서 만들어진 것이 아니다. 이에 대한 유망한 대안은 산업 시뮬레이터를 최대한 활용하여 이상 이미지를 최대한 잘 생성하여 학문 연구와 산업 제조 요구 간 격차를 최대한 줄이는 것이다.
Metrics

Level 컬럼에서 화살표가 위를 향한다면 값이 클수록 성능이 좋고, 아래를 향한다면 그 반대이다.
대부분의 지표는 natural image의 Segmentation 및 Detection 지표의 변형에서 나온 것들이다(F1 score, AU-ROC, AU-PR). 하지만 이는 작은 크기의 이상 탐지 성능을 정확히 반영하지 못할 수 있다. 이(작은 크기의 이상 탐지)는 이상이 없는 영역보다 이상 영역에 더 큰 가중치를 주어야 하기 때문. 따라서 위 metric들에 대한 타당성도 계속 검토되어야 한다.
6. Total Performance Analysis
Table 9, 10 은 크기가 너무 크고 빽빽해서 논문에서 직접 확대하여 보는 방법을 추천.
각 표에 대한 심층 분석은 아래와 같다.
- Image-level Anomaly Detection
- Memory bank 기반 방법이 가장 효과적이지만, pixel-level에서는 부족
- 앙상블을 통해 SOTA 방법들의 성능을 올릴 수 있음
- SSPCAB
- 최신 기법에 매끄럽게 통합될 수 있으며, reconstruction-based 방법의 성능을 향상시킬 수 있다.
- Few-shot IAD와 vanilla IAD 간 격차 감소
- Data distillation 알고리즘으로 이상 탐지에 필요한 데이터 셋의 양을 줄일 수 있다.
- Segmentation 모듈은 강력하다.
- MemSeg는 U-Net 프레임워크를 사용하여 앙상블 없이도 image-level AD에서 SOTA 달성
- DRAEM도 U-Net을 사용하여 pixel-level anomaly segmentation에서 우수
- 인공으로 생성된 이상 데이터에서 학습 된 모델이 실제 이상 데이터로 학습된 모델보다 성능이 안 좋더라도, 그래도 여전히 좋은 성능 보인다.
- AU-PR vs AU-ROC
- pixel-level segmentation tasks에서는 AU-PR이 더 나음
- Reconstruction-based 방법들은 AU-PR 지표에서 아주 굿
- 그림 7(아래)을 통해 DRAEM의 탐지 결과가 실제 값에 가장 근접한 결과를 보임.

7. Future Directions
마지막으로 저자들은 아래와 같은 몇 가지 future directions를 제공한다.
- Multi-modality 기반 IAD 데이터 셋 구축 필요
- 실제 조립 라인에서 RGB 이미지 만으로는 이상 탐지를 수행하기에 충분치 않고, X-ray나 초음파 등 추가적인 modality 정보를 활용할 필요가 있다.
-
실시간 예측 요구
- 산업 제조 환경에서는 Inference 속도가 아주 중요함. Multi-objective evolutionary neural architecture search 알고리즘으로 최적 균형점을 찾을 필요가 있다.
-
산업 이미지를 위한 pre-trained model 구축 필요
- 대부분 IAD 방법은 imageNet에서 사전학습된 모델을 사용함. 이는 Feature drift 문제를 야기할 수 있음.
- Unsupervised/Supervised 학습의 상호 보완 필요
- Unsupervised learning은 segmentation-based 방법들의 발전을 제한함. pixel-level 주석을 포함한 full supervised anomaly detection dataset을 구축할 필요가 있음.
- 비정상 샘플 합성 방식에 시간 투자 필요
- 정상 샘플에 대한 데이터 증강 연구는 많이 이루어졌지만, 비정상 샘플 합성에는 많은 연구가 진행되지 않음. CutPaste, DREAM, MemSeg같이 비정상 합성 방식에도 관심을 가져야 함.
- 경량화 필요
- 현재 IAD는 정확도에 초점을 맞추어 연구됨. 실제 생산 현장에서 적용되려면 경량화된 모델 설계가 필요함.
- 산업/의료 이미지 이상 탐지의 통합 가능성 탐구 필요
- 산업/의료 이미지의 이상 탐지 연구는 각각 활발히 진행되었고 데이터와 실험 측면에서 많은 유사점이 있지만 둘을 통합하는 연구는 X
- Domain differences와 비교를 위한 좋은 baseline과 benchmark가 없기 때문. 둘을 통합한 프레임워크 개발 필요
