https://arxiv.org/pdf/2403.10931v2.pdf
Introduction
의료 이미지 분할(Medical image segmentation)은 헬스케어 분야에서 매우 중요한 역할을 한다. 최근 많은 사람들이 Segment Anything Model(SAM) 과 같은 사전 학습된 image segmentation model을 이에 적용하고자 하였다. 가장 인기 있는 비용 효율적인 접근중 하나는 비교적 적은 파라미터를 갖는 ‘Adapter technique’을 적용하는 방안이다. fine tuning 된 adapter를 추가함으로써 medical image와 natural image의 domain gap을 줄이고자 하는 것이다.
하지만 medical image는 natural image와는 다르게 모호한 특징을 가진다. 예를 들면, 폐의 종양을 segmenting 할 때, 다른 의료 전문가들이 각자 다른 annotation을 부여할 확률이 크고, 심지어는 같은 의료 전문가여도 하루 걸러 다른 annotation을 주기도 한다. 따라서 의료 이미지에 SAM과 같은 모델을 적용하려면 이러한 점들을 고려해야 한다.
저자들은 SAM을 medical image에 fine-tuning하기 위한 새로운 모듈 Uncertainty-aware Adapter를 제안한다.
본 논문의 기여는 아래와 같이 요약할 수 있다.
- 다양한 분할 가설을 생성하기 위해 확률적 모델을 결합한 Uncertainty-aware Adapter SAM을 제안한다. 이는 의료진에게 신뢰할 만한 의료 지원을 제공할 수 있을 것으로 기대된다.
- SAM이 medical images의 불확실성을 잘 포착할 수 있게 하는 Condition Modifies Sample module을 제안한다.
Method
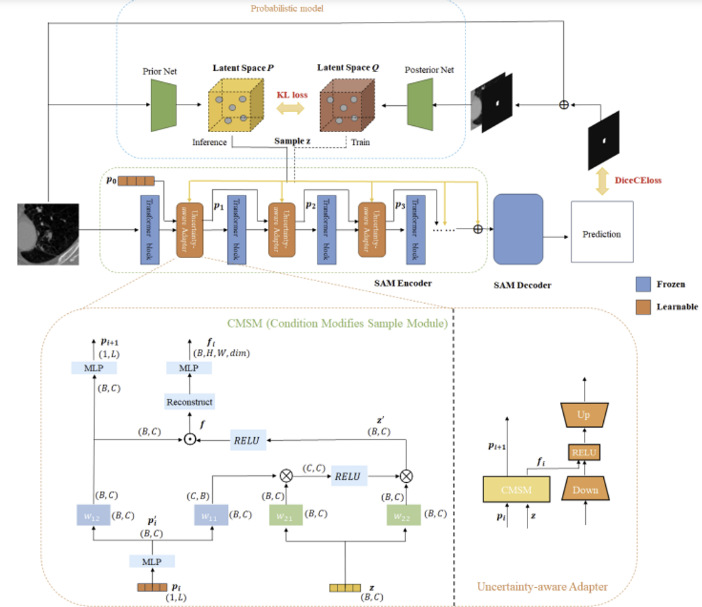
Original SAM의 자세한 구조는 아래 링크 참고
https://velog.io/@barley_15/논문-정리-Segment-Anything
Overview of UA-SAM
UA-SAM은 무제한의 uncertainty samples를 만들어내기 위한 확률적 모델을 이용한다. 그리고 segmentation model은 이 샘플들과 상호 작용하여 segmentation model은 신뢰할 수 있는 다양한 segmentation masks를 생성한다. 이 확률적 모델은 이미지를 입력으로 받고 그 분포를 모델링한 후 uncertainty samples를 생성해 낸다. 훈련 및 추론 과정에서 확률적 모델은 segmentation model에 불확실성 샘플 를 전달한다.
여기서 segmentation model은 image encoder의 Transformer block 마다 Adapters를 삽입하여 fine-tuning 된 SAM 모델이다.
Probabilistic model
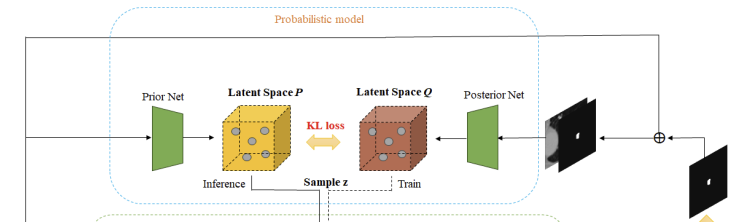
Gaussian distribution을 따르는 저차원 latent space 와 를 따로따로 구성하기 위해 Prior Net과 Posterior Net을 활용하였다. 훈련 과정에서 uncertainty sample인 는 로부터 나오고, 추론 과정은 로부터 나온다(랜덤 샘플).
동시에 loss function의 한 부분인 Kullback-Leibler divergence로 posterior distribution 와 prior distribution 의 차이를 penalizing 한다.
Architecture of Uncertainty-aware Adapter
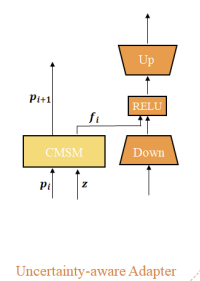
fine-tuning parameter 수를 최대한 줄이기 위해, UA-Adapter는 두 가지 요소를 추가한다.
- down-projection, ReLU activation, up-projection을 순차적으로 사용하는 bottleneck model
- uncertainty sample 와 Adapter의 상호작용을 위한 Condition Modifies Sample Module(CMSM)
Condition Modifies Sample Module(CMSM)
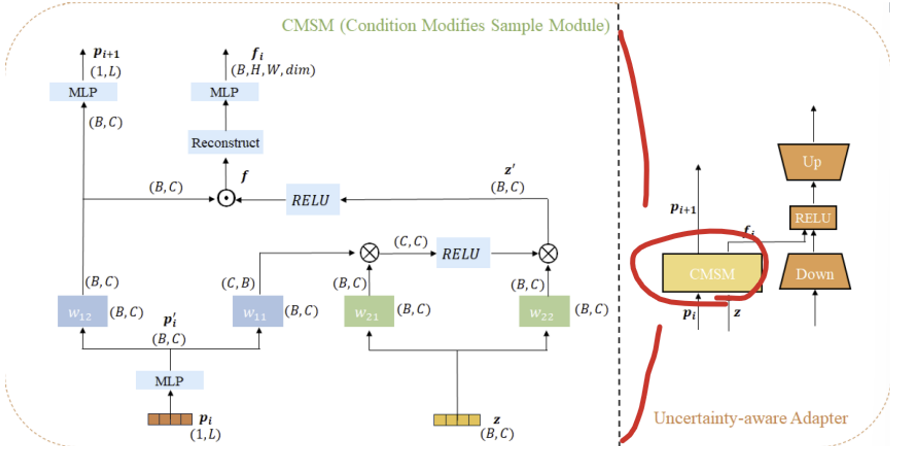
학습 가능한 position variant (1xL, L은 Adapter 수) 와 uncertainty sample (, 는 배치 사이즈, 는 latent space의 차원) 가 주어지면, CMSM은 를 의 상태를 바꾸기 위한 조건으로 활용한다. 이는 uncertainty sample이 feature extraction process와 일치하여 모델이 uncertainty sample을 효과적으로 통합할 수 있도록 해준다. 과정을 식으로 표현하면 아래와 같다.

- 여기서 는 각각 선형 변환식이다.
- ‘Trans’는 feature tensor를 계산에 적합한 shape로 변환시키도록 transpose 하는 것이다.
- ‘⊗’ 와 ‘⊙’ 는 각각 matrix multiplication과 element-wise multiplication을 의미한다.
- ‘Reconstruct’는 feature tensor를 에서 로 변환시키는 것이다(와 는 각각 image encoder로 부터 가공되는 patch embedding의 높이와 너비이고, 은 ratio와 embeddings dimension을 곱한 값)
- uncertainty sample 는 최종으로 uncertainty feature 로 변환되고, 이는 down-projection embedding과 연결된다.
- CMSM은 또한 다음 Adapter의 input으로 쓰기 위한 position variant 을 출력한다.
Loss function
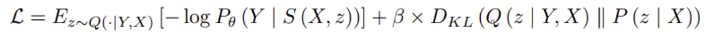
- 는 주어진 raw image, 는 ground truth segmentation, 는 예측된 segmentation
- DiceCEloss는 출력 를 픽셀 단위 범주 분포 의 매개변수화로 대함으로써 발생하고, 이는 와 간의 차이를 penalizing.
Experiment
Dataset
두 가지 multi-annotated dataset인 LIDC-IDRI와 REFUGE2로 실험 진행. 데이터셋에 대한 자세한 설명 및 전처리 과정은 논문 원문 참고
Implementation details
image encoder에는 ViT-b 버전을 활용하였다고 한다. 실험에 사용된 자세한 hyperparameter 및 optimizer에 관한 정보는 논문 원문 참고
Main results
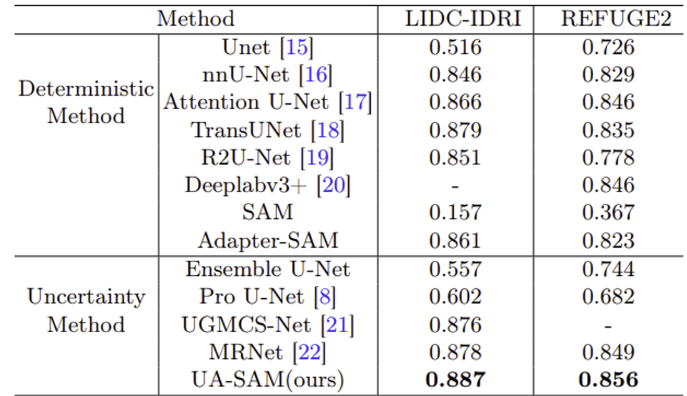
비교 method는 크게 Deterministic Method와 Uncertainty Method로 나누어 실험 진행하였다. Dice score로 평가되었고, UA-SAM이 다른 SOTA 모델에 비해 두 가지 데이터 셋에서 가장 좋은 성능을 보여주었다.
저자들이 불확실성을 잘 학습하기 위해 probabilistic model을 적용하도록 착안한 probabilistic U-Net보다도 훨씬 좋은 성능을 보여주었다.
유사하게 Adapter를 사용하는 Adapter-SAM과 Medical Sam Adapter(MSA) 보다도 좋은 결과를 보여주었다.
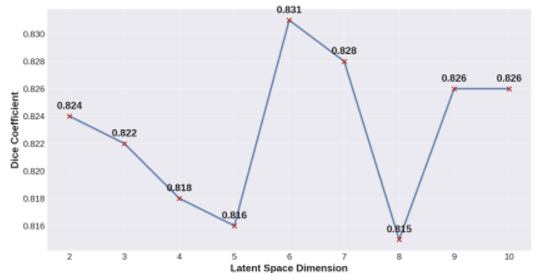
추가로 저자들은 latent space의 차원만 바꿔보는 실험도 진행하였다. 6차원일 때 최선의 결과를 내었다.
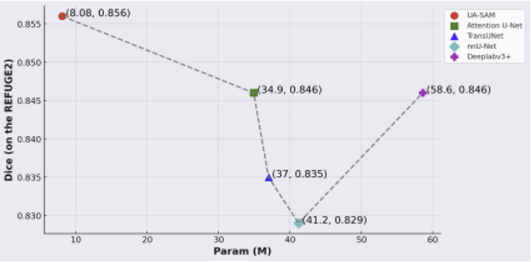
다른 모델과 파라미터 수를 비교한 결과이다. UA-SAM이 훨씬 적은 파라미터 수로 가장 높은 Dice score를 보여준다.
