✍범주형 변수 인코딩 해주는 이유?
모델링을 진행할 때 범주형 변수를 그대로 넣으면 모델이 인식하지 못하고 에러를 발생시킨다. 이에 따라 범주형 변수를 수치형 변수로 인코딩하는 과정이 필요하다.
범주형(Categorical) 변수 종류
-
명목형(Nominal)
각 범주 간 순위가 없는 변수로 성별(남, 여), 국적(한국, 미국, 중국), 혈액형(A, B, O, AB) 등이 이에 속한다.
-
순서형(Ordinal)
각 범주 간 순위가 존재하는 변수이다. 단, 순위 사이 등간성이 존재한다는 보장은 없다. 학력(초졸, 중졸, 고졸, 대졸), 크기(소, 중, 대), 성적(A, B, C, D, F) 등이 속한다.
인코딩 방법
-
Label Encoding
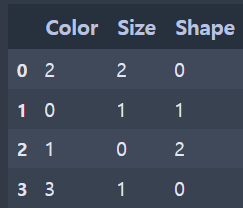
한 컬럼(변수) 내에 존재할 수 있는 n개의 특성값을 각각 0 ~ n-1 의 연속적 수치 데이터로 변환시켜주는 방법
- 크기의 의미를 부여하지 말아야 할 변수로 잘못 인코딩 하지 말아야 한다.
- 한 번에 단일 컬럼만 변환 가능하다.
- 인코딩 된 데이터 간 차이가 수치적인 차이를 의미하진 않기 때문에 cardinality(원소 개수)가 큰 변수에는 사용하지 않는 것이 좋다.
# 예시 코드
from sklearn.preprocessing import LabelEncoder
import pandas as pd
# 데이터 프레임 생성
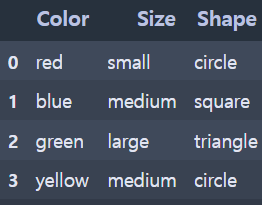
data = pd.DataFrame({'Color': ['red', 'blue', 'green', 'yellow'],
'Size': ['small', 'medium', 'large', 'medium'],
'Shape': ['circle', 'square', 'triangle', 'circle']})
# LabelEncoder 객체 생성
encoder = LabelEncoder()
# 데이터 프레임의 각 열에 대해 Label Encoding 수행
encoded_data = data.apply(encoder.fit_transform)
# 변환된 결과 출력
encoded_data
- 실행 결과
(인코딩 전)
(인코딩 후)
-
One Hot Encoding
한 컬럼(변수) 내에 존재할 수 있는 n개의 특성값들을 각각 n개의 비트 벡터로 표현하는 방식 (그만큼 차원 수는 증가)
- 한 변수에서 나온 각 더미 변수들은 k개(해당 값을 가지는 관측치 수)의 1과 n-k개의 0으로 구성
- 각 관측치 벡터는 항상 직교하여 거리 정보가 의미 없음
- 크기의 의미 값이 없는 정보량
- 라벨 인코딩과 달리 한번에 여러 범주형 변수 인코딩 가능
- 라벨링 하는 각 변수의 범주 수 만큼 차원 확대되므로 cardinality가 큰 변수를 인코딩 할 때 주의해야한다.
# 예시 코드
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# 범주형 변수를 포함한 데이터 프레임 생성
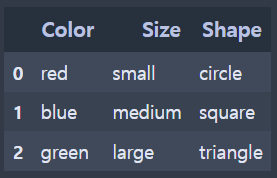
data = pd.DataFrame({'Color': ['red', 'blue', 'green'],
'Size': ['small', 'medium', 'large'],
'Shape': ['circle', 'square', 'triangle']})
# OneHotEncoder 객체 생성
encoder = OneHotEncoder()
# 범주형 변수 선택 (여기에서는 모든 열을 선택하도록 함)
categories = data[['Color', 'Size', 'Shape']]
# One-Hot Encoding 수행
encoded_categories = encoder.fit_transform(categories)
# 희소 행렬인 One-Hot Encoding 결과를 데이터 프레임으로 변환
encoded_data = pd.DataFrame(encoded_categories.toarray(), columns=encoder.get_feature_names_out(categories.columns))
# 변환된 결과 출력
encoded_data
- 실행 결과
(인코딩 전)
(인코딩 후)
Color 변수는 Color_blue, Color_green, Color_red로, Size 변수는 Size_large, Size_medium, Size_small로, Shape 변수는 Shape_circle, Shape_square, Shape_triangle로 각각 차원이 증가한 것을 확인할 수 있다.

-
Ordinal Encoding
Label Encoding과 같이 한 컬럼(변수) 내에 존재할 수 있는 n개의 특성값을 각각 0 ~ n-1 의 연속적 수치 데이터로 변환시켜주는 방법이나 차이점은 순차성 정보를 유지한다.
- 직관적인 방법이나 각 변수에 대한 사전 정보가 필수적
- Label Encoding과 마찬가지로 숫자 간의 크기 차이가 모델 학습 결과에 영향을 줄 수 있으므로 주의해야 함
# 예시 코드
from sklearn.preprocessing import OrdinalEncoder
import pandas as pd
# 데이터 프레임 생성
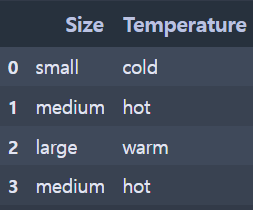
data = pd.DataFrame({'Size': ['small', 'medium', 'large', 'medium'],
'Temperature': ['cold', 'hot', 'warm', 'hot']})
# 변수의 범주 순서를 정의
size_order = ['small', 'medium', 'large']
temperature_order = ['cold', 'warm', 'hot']
# OrdinalEncoder 객체 생성
encoder = OrdinalEncoder(categories=[size_order, temperature_order])
# 데이터 프레임에 대해 Ordinal Encoding 수행
encoded_data = encoder.fit_transform(data)
# 변환된 결과 출력
encoded_df = pd.DataFrame(encoded_data, columns=data.columns)
encoded_df
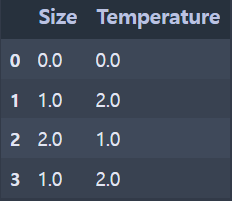
- 실행 결과
(인코딩 전)
(인코딩 후)
Binary Encoding
범주형 변수를 이진 코드(Binary Code)로 변환하는 방법
- One Hot Encoding과 유사한 방식이지만, 더 적은 수의 더미 변수들로 변환 가능
- 0과 1로 이루어진 이진 비트의 시퀀스로 표현
- 많은 수의 범주를 효과적으로 처리 가능
- 메모리 사용 효율적
# 예시 코드
import pandas as pd
import category_encoders as ce
# 데이터 프레임 생성
data = pd.DataFrame({'Color': ['red', 'blue', 'green', 'yellow']})
# BinaryEncoder 객체 생성
encoder = ce.BinaryEncoder(cols=['Color'])
# 데이터 프레임에 대해 Binary Encoding 수행
encoded_data = encoder.fit_transform(data)
# 변환된 결과 출력
print(encoded_data)
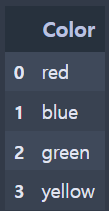
- 실행 결과
(인코딩 전)
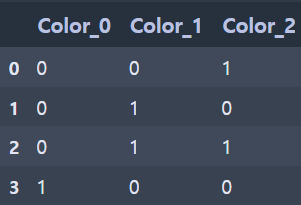
(인코딩 후)
One Hot Encoding이었다면 4차원으로 증가했을 컬럼 수가 3차원으로 비교적 적게 증가한 것을 확인할 수 있다.
Reference

큰 사람이 되겠어요