오늘도 코트카타.. 어려워서 은근 시간 많이 잡아먹음;
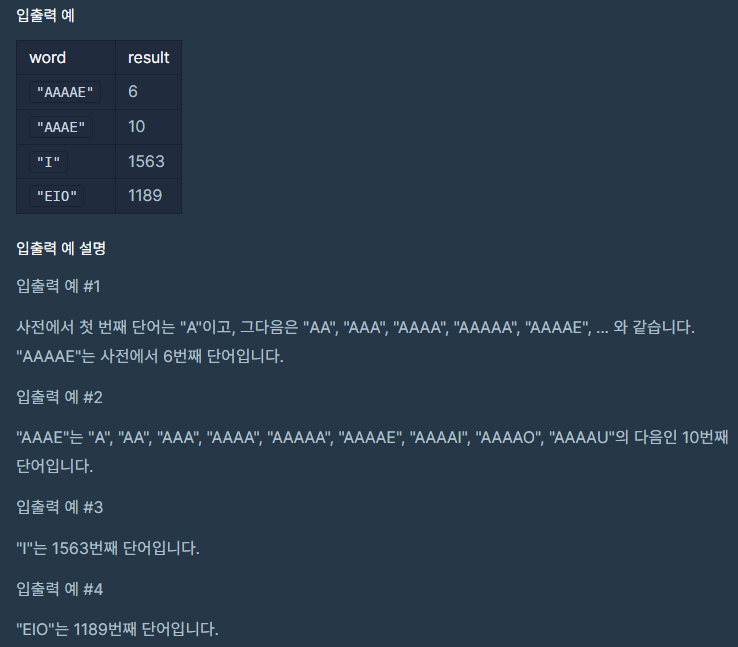
모음 사전
문제 해설
풀이 방법
- 재귀 함수를 사용해야 하므로 dfs
- 원본을 수정하지 않으므로 백트래킹x
실패 코드
//dfs
import java.util.*;
class Solution {
static String[] dict = {"A","E","I","O","U"};
static int answer;
public int solution(String word) {
answer = 0;
dfs("", 0, word);
return answer;
}
public void dfs(String str, int depth, String word) {
//조건 충족
if(str.equals(word)) {
return;
}
//글자 제한
if(depth == 5) {
return;
}
for(int i=0; i<dict.length; i++) {
str += dict[i];
answer++;
//재귀
dfs(str, depth+1, word);
}
}
}결과
테스트 1
입력값 〉 "AAAAE"
기댓값 〉 6
실행 결과 〉 실행한 결괏값 3900이 기댓값 6과 다릅니다.
테스트 2
입력값 〉 "AAAE"
기댓값 〉 10
실행 결과 〉 실행한 결괏값 3875이 기댓값 10과 다릅니다.
테스트 3
입력값 〉 "I"
기댓값 〉 1563
실행 결과 〉 실행한 결괏값 3905이 기댓값 1563과 다릅니다.
테스트 4
입력값 〉 "EIO"
기댓값 〉 1189
실행 결과 〉 실행한 결괏값 3905이 기댓값 1189과 다릅니다.띠용 난 여기서부터 늪에 빠졌었다......
이전에 풀었던 풀이를 보니 answer++대신 cnt++를 이용해 answer에 저장해서 반환했었다.
난 이해가 되지 않았다. answer나 cnt나 이름만 다른 변수인데 왜 answer++하면 저렇게 기가 찬 답이 나오고 cnt++하면 답이 맞을까......
...
난 바보였다! 사실 재귀함수에 대한 이해도가 부족해서 생긴 문제가 아닐까 싶다
결론부터 말하자면 word와 일치한 값을 찾았을 때 return은 이전 함수를 호출하는 것이다. 즉, 함수가 끝나지 않았다는 것!
그럼 계속 재귀함수가 돌테고 그때마다 answer++의 값이 늘어난다. 그렇기에 저런 어마무시한 답이 나왔던 것이다.
정답 코드
import java.util.*;
class Solution {
static String[] alpha = {"A","E","I","O","U"};
static int cnt = 0;
static int answer = 0;
static boolean fin = false;
public int solution(String word) {
dfs(word, "", 0);
return answer;
}
public void dfs(String word, String w, int depth) {
//효율성을 위해 추가적인 재귀함수 호출x
if(fin) {
return;
}
if(w.equals(word)) {
answer = cnt;
fin = true;
return;
}
if(depth == 5) {
return;
}
for(int i=0; i<alpha.length; i++) {
cnt++;
dfs(word, w+alpha[i], depth+1);
}
}
}그래서 단어를 생성할 때 마다 cnt라는 변수에 +1을 해주고 word와 일치하는 값을 찾았을 때 그 cnt값을 answer에 저장해준다.
그럼 여기서 생긴 의문. 정답을 찾았는데도 계속 재귀함수가 돈다.. 그럼 효율성이 안좋은거 아닌가?
//효율성을 위해 추가적인 재귀함수 호출x
if(fin) {
return;
}그래서 boolean 변수를 만들었다. 정답을 찾았을 때 fin변수에 true를 저장하여 이전 dfs를 호출했을 때 for문까지 가지않고 끝을 내버렸다.
효율성이 좋아진게 맞는건지는... 잘 모르겠지만 우선 이렇게 정답!
dfs, bfs 싫어
