SOPT 34기 SERVER 2주차 🔑keyword🔑 과제

목차
1️⃣ 데이터의 멱등성에 대하여
2️⃣ Spring Boot 구동 원리
3️⃣ ordinal에 대하여
4️⃣ 스프링 빈의 생명 주기
1️⃣데이터의 멱등성에 대하여
📌 HTTP 메소드
2차 세미나에서 HTTP 메소드에 대한 내용이 언급되었다.
HTTP 메소드에는 총 9가지가 존재하는데,
GET / POST / PUT / PETCH / DELETE / HEAD / OPTIONS / CONNECT / TRACE
의 역할을 정리하면 다음과 같다.
| 메소드 이름 | 메소드 역할 |
|---|---|
| GET | read 리소스를 조회한다. |
| POST | create 요청받은 데이터를 처리하는데, 주로 '데이터를 등록'할 때 사용한다. |
| PUT | update 리소스를 대체할 때 사용하는데, 만약 해당 리소스가 없다면 생성한다. |
| PETCH | 리소스를 일부만 변경할 때 사용한다. |
| DELETE | delete 리소스를 삭제할 때 사용한다. |
| HEAD | GET과 동일하지만 메시지 부분을 제외하고, 상태 줄과 헤더만 반환한다. |
| OPTIONS | 대상 리소스에 대한 통신 가능 옵션을 설명할 때 사용하며, 주로 * CORS에서 사용한다. |
| CONNECT | 대상 자원으로 식별되는 서버에 대한 터널을 설정 |
| TRACE | 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행 |
* CORS란?
: Cross-Origin Resource Sharing, 교차 출처 리소스 공유
CORS를 설정한다는 건 ‘출처가 다른 서버 간의 리소스 공유’를 허용한다는 것
📌 POST와 PUT 어떤 차이점이 있을까?
POST는 resource를 create하는 거고, PUT은 resource를 update하는 것
예시를 살펴보면 이해하는 데 도움이 된다.
POST 활용 예시
POST/shoes : HTTP Body에 있는 정보로 새로운 Shoe의 하위 Resource를 생성하는 요청
POST 활용 예시
PUT/shoes/{이미 존재하는 SHOE ID} : 이미 존재하는 SHOE ID에 존재하던 정보를 덮어쓰기(overwrite)하여 정보를 갱신하는 요청
PUT/shoes/{존재하지 않는 SHOE ID} : 존재하지 않는 SHOE ID로 새로운 Resource를 생성하는 요청
POST vs PUT
| POST | PUT | |
|---|---|---|
| Resource Identifier의 유무 | x | o |
| Idempotent( * 멱등)한가? | x | o |
| Resource를 Caching해도 되는가? | o(대신 300으로 표시해야함) | x |
* 멱등 : 데이터의 멱등성은 POST와 PUT을 구분할 때 중요한 개념이다. 바로 다음의 항목에서 자세히 살펴보고자 한다.
POST vs PUT 결론
POST는 요청 URL에 /Collection URI 까지만 포함되지만,
PUT은 Collection URI/{Resource Identifier}가 포함된다.
요청 값의 결과를 보면 POST는 Idempotent하지 않은 각 요청마다 새로운 결과 값을 제공하며,
PUT은 Idempotent한 결과 값을 제공한다.
즉, resource의 create를 위해 POST를 사용했다면 N개의 생성 요청에 N개의 resource가 생성된다.
PUT을 사용한다면 요청 client가 생성할 resource의 identifier를 지정해줘야하며, N개의 요청을 보내더라도 하나의 resource만 생성된 채로 정보를 계속 '덮어쓰게'된다.
📌 데이터의 멱등성이란?
우선 '멱등'이라는 단어를 먼저 알아보면,
- 멱등(冪等) : 연산을 여러 번 적용하더라도 결괏값이 달라지지 않는 일. (출처 : 네이버 국어사전)
간단히 말하자면, '반복해서 호출할 때 동일한 결과를 생성하는 작업'을 보고 멱등성이 있다고 하는 것.
❗️우리가 헷갈리는 이유는 동일한 결과라는 말 때문인데, 동일한 '반환 값'이 아니라 동일한 '반환 형식'에 집중해서 생각하면 된다.
예를 들어봅시다. 우리가 한국어로 "지금 몇 시죠?"라고 질문을 한다고 하면,
"11시입니다." 라고 대답을 한다. 물론, 물어보는 시간에 따라 "3시입니다.", "5시입니다." 등
답변의 '내용'은 변할 수 있지만 응답하는 형식은 동일할 것이다.
갑자기 "지금 몇 시죠?"라는 질문에 "아메리카노."라고 대답하는 사람은 없을 것이다.
즉, 응답 값에 관계 없이 "알려지고, 예상되는 방식으로" 값을 반환해야한다는 것.
코드로 예시를 들어보겠습니다.
/student 라는 URI가 있다고 할 때, 해당 URI에 대해서 POST,PUT이 작동하는 방식은 다음과 같습니다.
먼저 POST 메소드로 홍길동이라는 이름을 가진 학생을 생성하고자 할 때 다음과 같이 요청하면,
구분값인 id를 1로 설정하여 '뽀로로'라는 학생이 생성된다.
HttpRequest
Post /student
{
"name": "홍길동",
"grade": 1
}
HttpResponse
HTTP/1.1 200 OK
{
"id": 1,
"name": "홍길동",
"grade": 1
}이제 PUT을 통해 뽀로로의 grade를 2로 변경하려고 한다.
HttpRequest
PUT /student/1
{
"grade": 2"
}
HttpResponse
HTTP/1.1 200 OK
{
"id": 1,
"name": "홍길동",
"grade": 2
}그럼 중복된 요청을 한다면?
먼저 POST 메서드로 홍길동 학생을 생성해달라고 2번 요청한다면?
POST /student
{
"name": 홍길동,
"grade": 1
}
HTTP/1.1 200 OK
{"id": 1, "name": "홍길동", "grade": 1}
HTTP/1.1 200 OK
{"id": 2, "name": "홍길동", "grade": 1}아이디가 1과 2인 홍길동이 두 개 생기는 것을 확인할 수 있다.
(name이 unique key가 아닌 경우)
PUT으로 같은 요청을 2번 한다면?
PUT /student/3
{
"name": 동길홍,
"grade": 2
}
HTTP/1.1 200 OK
{"id": 3, "name": "동길홍", "grade": 2}nnnn번 요청을 보내도 같은 응답을 반환한다.
그러니까 PUT은 멱등한데, POST는 멱등하지 않다는 것이고 이게 이 둘을 구분하는 큰 차이점인 것.
하지만, 멱등하다, "Idempotent"하다는 것이 꼭 안전하다, "Safe"하다는 것을 의미하는 것은 아니다
🔽 HTTP 메소드의 멱등성과 안전성을 나타낸 표🔽
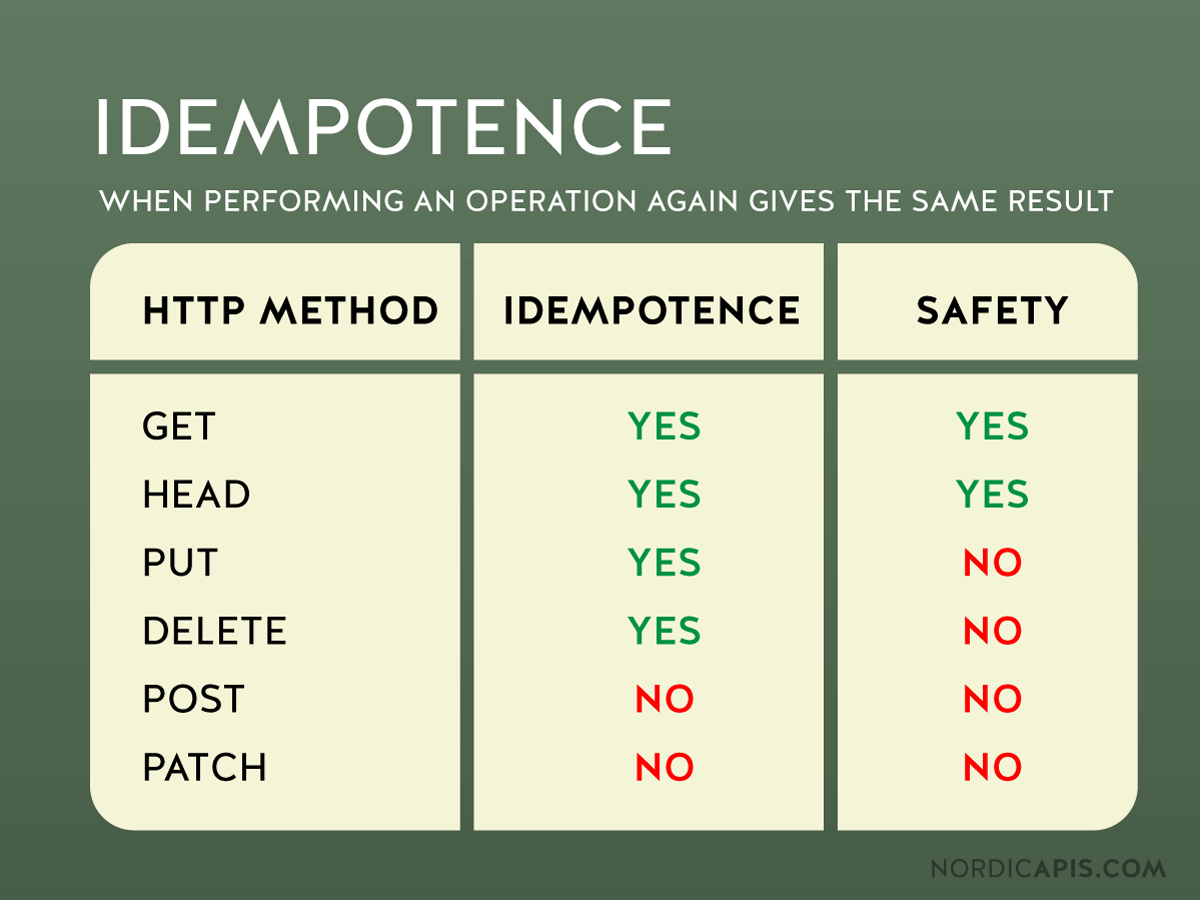
Q. 전부 멱등하게 만들지 않는 이유가 있나요?
A. 어떠한 경우에는 그 '형식'을 수정해야하기 때문입니다.
POST의 경우를 생각해봅시다. POST의 역할이 뭐였죠? create
그런데 POST가 멱등하다면 어떻게 될까요?
웹 서버에 보내고 수락한 모든 항목은 동일한 코드와 값으로 응답해야할 것입니다. 그러니까, 서버에 이미 존재해야하는 것이죠.
2️⃣ Spring Boot 구동 원리
먼저, 스프링 부트(Spring Boot)는 스프링(Spring)으로 애플리케이션을 만들 때에 필요한 설정을 간편하게 처리해주는 별되의 프레임워크를 말한다.
이제 그 스프링부트의 구동 원리에 대해 살펴보고자 한다.
📌 자동 구성(Auto-configuration)
스프링 부트에서의 Auto-configuration은 일반적으로 자주 사용하는 빈들을 자동으로 등록해주는 기능이다.
가장 대표적인 예시가 *spring-boot-starter-web이다.
* spring-boot-starter-web
웹 애플리케이션 개발을 위한 스타터 패키지로, 이 패키지에는 Spring MVC, Tomcat, Jackson과 같은 웹 개발에 필요한 대부분의 라이브러리가 포함되어 있다.
- Spring MVC : Spring Web MVC는 서블릿 API 위에 구축된 원래의 웹 프레임 워크로, 사용자가 HTTP 요청을 처리하는 데 필요한 모든 도구를 제공한다.
- Tomcat : 가장 널리 사용되는 Java Servlet Container이다. Tomcat은 웹 서버 및 Java의 실행 환경인 Java Servlet, Java Server Pages(JSP), Java Expression Language, Java WebSocket 등을 제공하는 오픈 소스의 구현이다.
- Jackson : JSON을 Java 객체로 변환하거나 Java 객체를 JSON으로 변환하는 데 사용되는 JSON 처리 라이브러리이다.
자동구성(특히 Spring Boot Starter Web), 어떤 점이 좋을까?
- Spring Boot Starter Web을 사용하면, 기본적으로 임베디드 톰캣이 구성되어 웹 서버로 사용할 수 있다. 뿐만 아니라 스프링 MVC를 활용하여 컨트롤러를 정의하고 HTTP 요청을 처리할 수 있다.
- 또한, RESTful 서비스를 구축하는 데 필요한 모든 의존성을 제공하기 때문에 REST API를 손쉽게 개발할 수 있다.
- 개발자가 직접 세부 구성을 정의하지 않아도 되게 하여 개발 편의성을 향상시킨다.
📌 내장 서버 사용
내장 서버에 대해 알아보기 전에 웹 서버와 웹 컨테이너에 대해 알아보자.
- 웹서버 : 클라이언트가 요청하는 정적 컨텐츠를 전달하는 서버
- 웹 컨테이너 : Servlet, jsp를 실행할 수 있는 소프트웨어, 서블릿 컨테이너라고도 한다. 톰캣은 서블릿 컨테이너 중 하나
- 요청을 받을 때 서블릿 컨테이너(톰캣)가 request, response 객체를 생성한다.
(톰캣에서 BufferedWriter, BufferedReader를 통해 요청으로부터 가변길이의 문자를 받고 request, response 객체를 생성한다.) - 이후 요청에 매핑된 서블릿이나 프론트 컨트롤러로 전달한다.
- 요청을 받을 때 서블릿 컨테이너(톰캣)가 request, response 객체를 생성한다.
[서블릿이란?]
javax.servlet package에 정의된 인터페이스
클라이언트의 요청을 처리하고 그 결과를 다시 클라이언트에게 응답하는 Servlet 클래스의 구현 규칙을 지킨 자바 프로그램이다.
다음과 같은 세 가지 메소드를 정의한다.
- init() - 초기화
- service() - 요청
- destroy() - 파괴
[서블릿 컨테이너란?]
- 서블릿들을 위한 상자(Container)
- 서블릿들의 생성, 실행, 파괴를 담당
클라이언트의 Request를 받아주고 Response를 보내주며 정적인 웹페이지 생성을 위해 존재한다.
서블릿의 생명 주기를 관리해준다.
=> 웹 애플리케이션 서버(WAS)라고도 불리며 대표적인 서블릿 컨테이너는 톰캣이다.
내장서버 확인하기
auto configurer의 spring.factories에서 자동 설정 파일들을 확인할 수 있다.
만약, tomcat이 아닌 jetty로 컨테이너를 변경하고 싶다면,
tomcat dependency를 빼고 -> jetty dependency를 추가하고 -> non-web-application으로 변경 -> random port사용(server.port=0)
-> EvenListner 호출
📌 의존성 관리(Dependencies Management)
어떤 한 라이브러리를 다운로드 받을 때 해당 라이브러리가 의존하는 다른 라이브러리들도 같이 다운로드 할 수 있도록 하는 것
앞서 살펴보았던 자동구성과 마찬가지로 스프링부트가 이 의존성 관리를 해준다면, 우리(개발자)가 직접 관리해야 할 의존성의 수가 줄어든다는 점에서 장점을 가진다.
스프링부트가 의존성을 관리해주면 의존성들간의 버전을 신경쓰지 않아도 된다.
만약, 특정 버전을 사용하려고 한다면 명시해주면 된다.(pom.xml의 경우 properties에 / build.gradle의 경우 dependencies에)
3️⃣ ordinal에 대하여(단점)
이펙티브 자바(Effective Java)의 규칙에도 등장하는 ordinal
Effective Java 아이템 #35 : enum ordinal 대신 인스턴스 필드를 사용하라
📌 열거체(enumeration type)
- JDK 1.5 이후부터 사용 가능해진 Enum 클래스
- 장점 1) 열거체를 비교할 때 실제 값 뿐만 아니라 '타입'까지 체크 가능
- 장점 2) 열거체의 상숫값이 재정의되더라도 다시 컴파일 할 필요 없음
📌 ordinal() 메소드
ordinal() 메소드는 해당 열거체 상수가 열거체 정의에서 정의된 순서(0부터 시작)를 반환한다.
-> 몇 번째 위치인지 알려주겠다는 것.
(❗주의할 점 ❗️: 정의된 순서를 반환하는 거지 상수값 자체를 반환하는 게 아니다.)
- 대부분의 열거 타입 상수는 자연스럽게 하나의 정수값에 대응된다.
- 모든 열거 타입은 ordinal() 메소드를 제공한다.
- 열거 타입 상수와 연결된 정수값이 필요할 때 ordinal() 사용하는 경우가 있다. => 이걸 하지 말라는 것!
enum Rainbow { RED, ORANGE, YELLOW, GREEN, BLUE, INDIGO, VIOLET }
public class Enum {
public static void main(String[] args){
int index = Rainbow.YELLOW.ordinal();
Systme.out.println(index);
}
}실행결과 : 2
📌 왜 ordinal()을 사용하지 말라고 하는 걸까?
예를 들어 아래와 같은 코드가 있다고 하자.
enum Ensemble {
SOLO, DUET, TRIO, QUARTET, QUINTET, SEXTET,
SEPTET, OCTET, NONET, DECTET;
int numberOfMusicians() { return ordinal() + 1; }
}- 더 이상 enum이 변경되지 않고 간단하게 사용할 때는 문제가 없을 수 있다.
- (유지보수의 어려움) enum 상수 사이에 값을 추가하거나 이미 사용한 정수에 대응되는 새로운 enum 상수 값을 사용할 수 없다.(단점)
- 만약 상수 선언 순서를 바꾼다면
numberOfMusicians가 오작동하게 된다. - 이미 사용중인 정수와 값이 같은 상수는 추가할 방법이 없다.
- 값을 중간에 비워둘 수 없다.
(ex : 12명이 연주하는 상수를 추가한다면 11명이 연주하는 상수는 비어있게 된다. 따라서 실제로 쓰이지는 않는 11명짜리 상수를 더미 데이터로 끼우게 된다.)
- 만약 상수 선언 순서를 바꾼다면
- (가독성)
ordinal()값이 특정한 의미를 지닌 상수를 대체하는 경우, 다른 개발자로 하여금 이해하기 어렵게 만든다.
추천하는 방식인 객체 필드에 따로 저장하는 방식을 사용하면 아래와 같다.
enum Ensemble {
SOLO(1), DUET(2), TRIO(3), QUARTET(4), QUINTET(5), SEXTET(6),
SEPTET(7), OCTET(8), DOUBLE_QUARTET(8), NONET(9), DECTET(10);
private final int numberOfMusicians;
Ensemble(int size) { this.numberOfMusicians = size; }
int numberOfMusicians() { return numberOfMusicians; }
}4️⃣ 스프링 빈의 생명 주기
스프링 빈을 관리하는 건? 스프링 컨테이너.
따라서, 가장 처음에는 스프링 컨테이너가 만들어진다.

(이미지출처 : #4-1)
스프링 컨테이너 생성 -> 스프링 빈 생성 -> 의존관계 주입 -> 초기화 콜백 -> 사용 -> 소멸 전 콜백 -> 스프링 종료
스프링은 빈의 의존관계 주입이 완료 되면 콜백 메서드를 통해 초기화 시점을 알려주는 다양한 기능을 제공한다.
마찬가지로 스프링 컨테이너가 소멸 되기 전에도 소멸 콜백을 제공한다.
- 초기화 콜백 : 빈이 생성되고, 빈의 의존관계 주입이 완료된 후 호출
- 소멸 전 콜백 : 빈이 소멸되기 직전에 호출
📌 스프링 빈 생명주기 콜백
(#4-3)
- 스프링 인터페이스 사용
- 설정 정보 활용
- @PostConstruct / @PreDestroy 어노테이션 사용
1) 스프링 인터페이스 사용
- 스프링 전용 인터페이스. 따라서 코드가 스프링에 의존한다.
- 메서드의 이름을 변경할 수 없다.
- 외부 라이브러리에 적용이 불가능하다.
2) @Bean 어노테이션의 attribute 사용
- 인터페이스 사용과 달리 메서드 이름을 자유롭게 지정 가능 && 스프링 코드에 의존하지 않아도 된다.
- 설정 정보를 이용하므로 코드 변경이 불가한 외부 라이브러리에도 초기화 및 종료 메서드 적용 가능
3) @PostConstruct/@PreDestroy 어노테이션 사용
- 최신 스프링에서 가장 권장하는 방법
- 스프링 종속적이지 않다. JSR-250 자바 표준에 속한 어노테이션이기 때문
- 외부 라이브러리는 적용할 수 없다.
- 외부 라이브러리에 콜백을 사용하려면 @Bean attribute 기능을 함께 사용해야한다.
어노테이션 정리
5️⃣ @RequiredArgsConstructor
스프링에서 DI(의존성주입)의 방법 중에, Lombok으로 생성자 주입을 임의의 코드 없이 자동으로 설정해주는 어노테이션
- 초기화되지 않은 final 필드나 @NonNull이 붙은 필드에 대해 생성자를 생성해준다.
- 새로운 필드를 추가할 때 다시 생성자를 만들어서 관리해야하는 번거로움을 없애준다.
- (@Autowired를 사용하지 않고 의존성 주입)
- 의존성 주입 방식 중 생성자 주입에 해당됨
- 스프링에서 가장 권장하는 것이 생성자 주입이지만 번거로움이 있는데, 이 어노테이션을 통해 생성자를 자동으로 등록할 수 있음!!
🔽 example 🔽
@RestController
@RequiredArgsConstructor
public class DiaryController {
private final DiaryService diaryService;
private final UserService userService;
}6️⃣ @AllArgsConstructor
클래스의 모든 필드 값을 파라미터로 받는 생성자를 자동으로 생성
클래스의 모든 필드를 한 번에 초기화 할 수 있음
🔽 example 🔽
@AllArgsConstructor
public class Person {
private String name;
private int age;
// getters and setters
}요랬는데
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}요래됐숨당
7️⃣ @RequestMapping
특정 URI에 들어온 요청을 특정 메서드와 매핑하기 위해 사용
- RequestMapping에서 가장 많이 사용하는 부분 : value와 method
- value : 요청받을 url을 설정
- method : 어떤 요청으로 받을지 정의(GET, POST, PUT, DELETE 등)
ex)@RequestMapping(value = "/hello", method = RequestMethod.GET)
🔽 example 🔽
/hello라는 내용으로 GET, POST, PUT, DELETE를 만든다고 하자.
@RestController
public class HelloController {
@RequestMapping(value = "/hello", method = RequestMethod.GET)
public String helloGet(...) {
...
}
@RequestMapping(value = "/hello", method = RequestMethod.POST)
public String helloPost(...) {
...
}
@RequestMapping(value = "/hello", method = RequestMethod.PUT)
public String helloPut(...) {
...
}
@RequestMapping(value = "/hello", method = RequestMethod.DELETE)
public String helloDelete(...) {
...
}
}요랬는데
@RestController
@RequestMapping(value = "/hello")
public class HelloController {
@GetMapping()
public String helloGet(...) {
...
}
@PostMapping()
public String helloPost(...) {
...
}
@PutMapping()
public String helloPut(...) {
...
}
@DeleteMapping()
public String helloDelete(...) {
...
}
}요래됐숨당
위의 예시처럼 공통적인 url을 class에 @RequestMapping으로 설정할 수 있다.
뒤에 추가적으로 url을 붙이고 싶다면?
@GetMapping, @PostMappign, @PutMapping, @DeleteMapping에 추가적인 url을 작성하면 된다.
(우리가 2차세미나 실습과제에서 했던 것처럼!)
🔗 참고 자료 - keyword 별
1️⃣ 데이터의 멱등성에 대하여
🔗 #1-1 사이트 - NORDIC APIS(API 설계의 멱등성과 안전성 이해)
🔗 #1-2 사이트 - 토스페이먼츠 개발자센터(CORS)
🔗 #1-3 블로그 - Studio u by kingjakeu(RESTful API POST와 PUT의 차이)
🔗 #1-4 블로그 - ELANCER.BLOG(URI와 URL, 어떤 차이점이 있나요?)
🔗 #1-5 블로그 - 53_eddy_jo.log(RESTful한 세계에서의 POST와 PUT의 차이, 거기에 PATCH까지)
2️⃣ Spring Boot 구동 원리
🔗 #2-1 블로그 - 코드 블로그(스프링과 스프링부트)
🔗 #2-2 강의 - 인프런(스프링부트 - 핵심 원리와 활용)
🔗 #2-3 블로그 - KKH_log(Spring boot Starter Web)
🔗 #2-4 블로그 - zezeg2.log(Spring Boot 동작원리)
🔗 #2-5 블로그 - dsunni.log(스프링부트 원리 - 내장서버)
🔗 #2-6 블로그 - 김용환 블로그(springboot 의존성 관리의 이해 및 응용)
3️⃣ ordinal에 대하여(단점)
🔗 #3-1 사이트 - TCP School(Enum 클래스)
🔗 #3-2 블로그 - jimin3263.log(ordinal 메서드 대신 인스턴스 필드를 사용하라)
🔗 #3-3 블로그 - 개발하는 두더지(enum ordinal 대신 객체 필드를 사용하라)
4️⃣ 스프링 빈의 생명주기
🔗 #4-1 블로그 - Gyun's 개발일지(Bean LifeCycle이란 무엇일까?)
🔗 #4-2 사이트 - spring 공식문서(Customizing the Nature of a Bean - Lifecycle Callbacks)
🔗 #4-3 블로그 - destiny1616.log(스프링 빈 생명주기)
5️⃣6️⃣7️⃣어노테이션 정리
🔗 #1 블로그 - sssungjin.log(@RequiredArgsConstructor란?)
🔗 #2 블로그 - code-10.log(롬복 @All/NoArgsConstructor 제대로 알고 사용해보자)
🔗 #3 블로그 - 멍토의 IT 블로그(@RequestMapping이란?)
