10.4 Page Replacement (페이지 교체)
- 메모리 과할당
-
다중 프로그래밍 정도를 올렸을 때 발생
ex) 40개의 프레임과, 10개의 페이지 중 5개만을 사용하는 프로세스 6개.
→ 이 경우 40 - (5*6) = 10개의 프레임을 남기고 높은 CPU 활용률과 처리율을 얻을 수 있음.But. 만약 이 프로세스들이 10페이지를 모두 사용해야 한다면?
→ 60프레임을 필요로 하게 된다.
-
- 메모리 과할당의 발생 순서
- 프로세스가 실행하는 동안 페이지 폴트 발생
- 운영체제가 필요로 하는 페이지가 보조 저장장치에 저장된 위치를 알아냄
- 가용할 수 있는 프레임이 없음을 발견
→ 이 경우 페이지 교체가 수행되어야 한다.
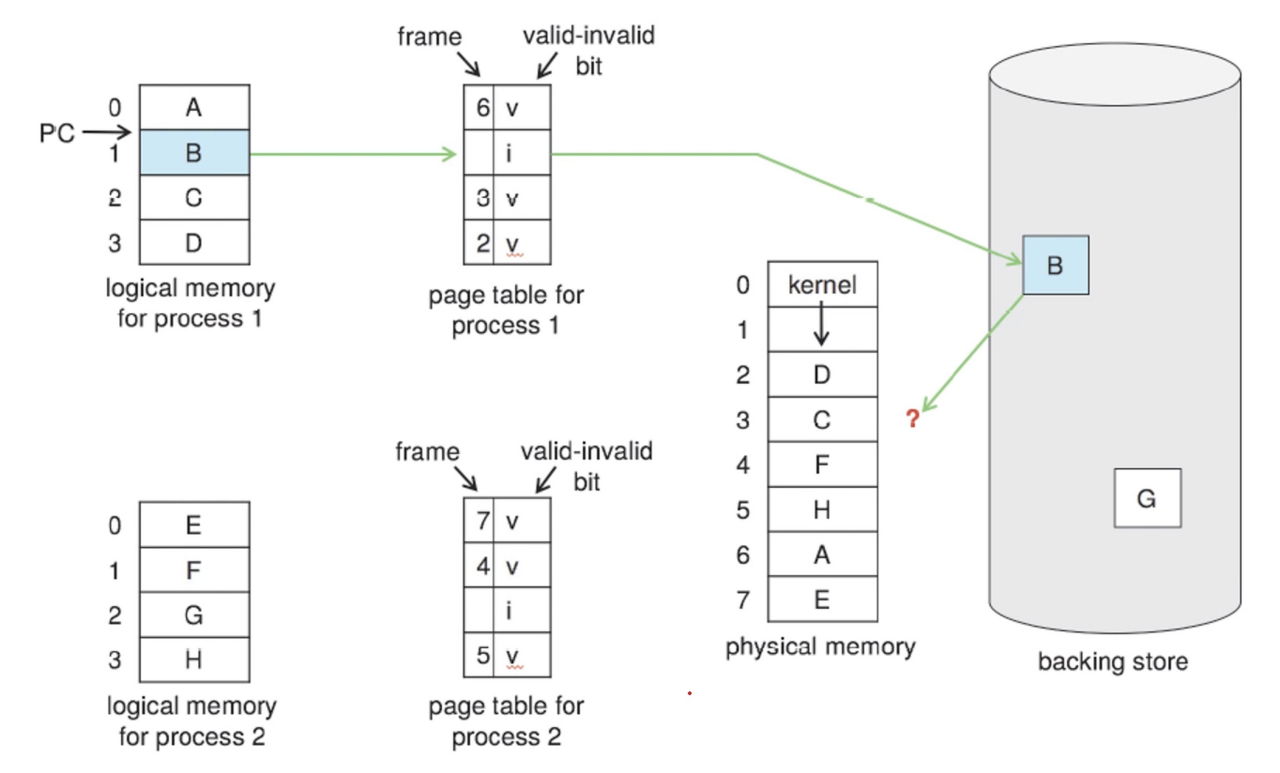
10.4.1 Basic Page Replacement (기본적인 페이지 교체)
-
보조 저장장치에서 필요한 페이지의 위치를 알아냄
-
빈 페이지 프레임을 찾음
a. 비어 있는 프레임이 있다면 그것을 사용함
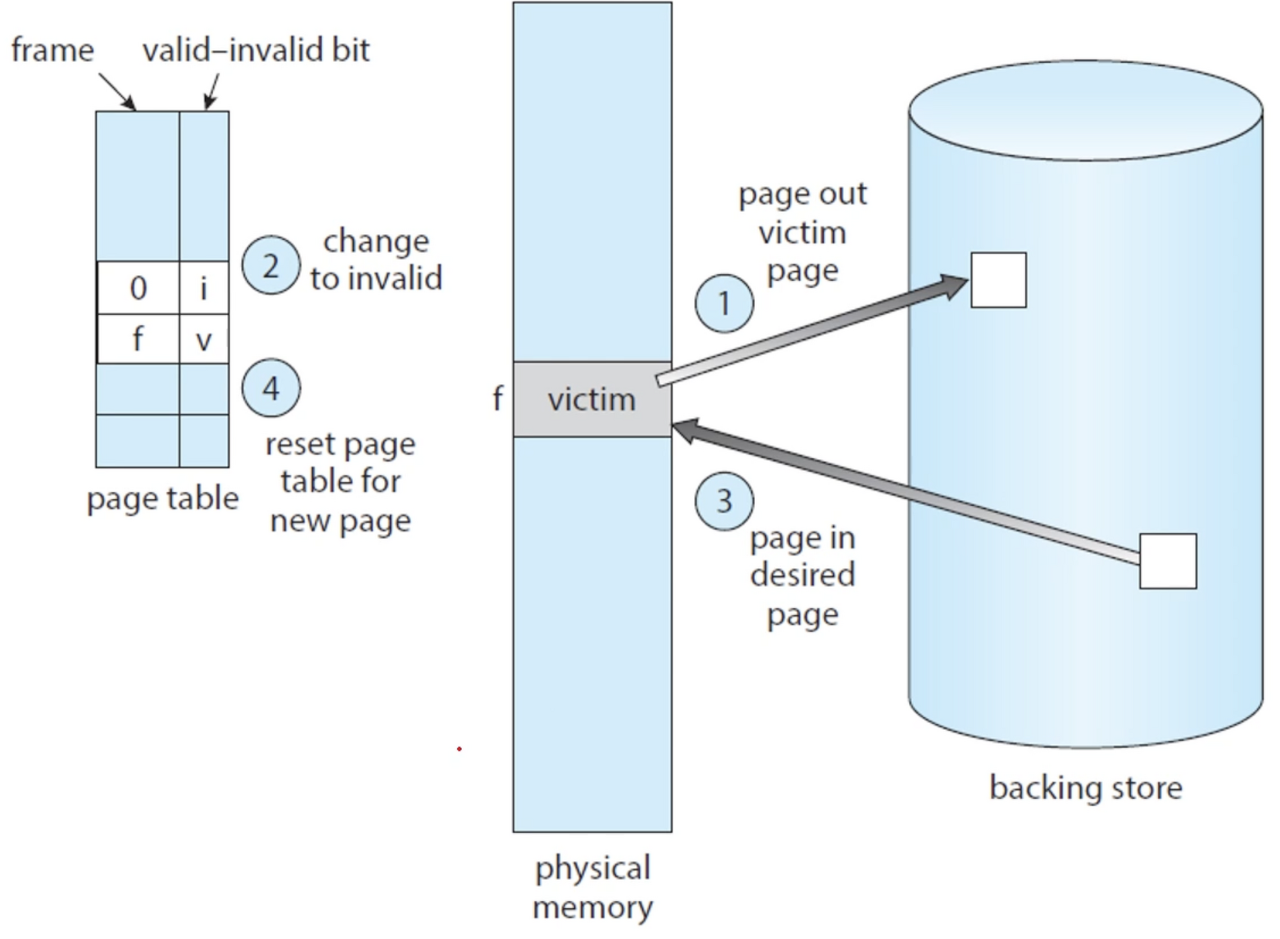
b. 비어 있는 프레임이 없다면 희생될(victim) 프레임을 선정하기 위하여 페이지 교체 알고리즘을 가동 시킴
c. victim 페이지를 보조 저장장치에 기록하고, 관련 테이블을 수정 -
빼앗은 프레임에 새 페이지를 읽어오고 테이블을 수정
-
페이지 폴트가 발생한 지점에서부 프로세스를 계속
10.4.2 FIFO Page Replacement (FIFO 페이지 교체)
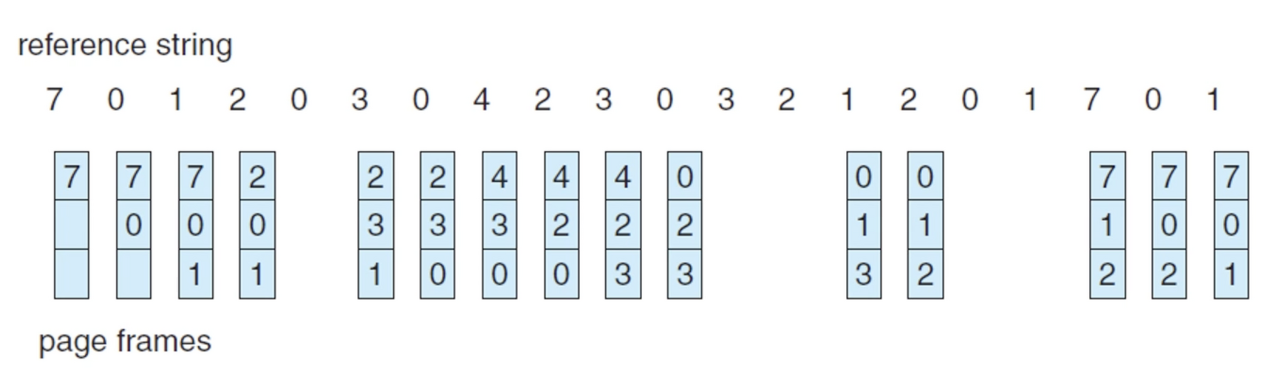
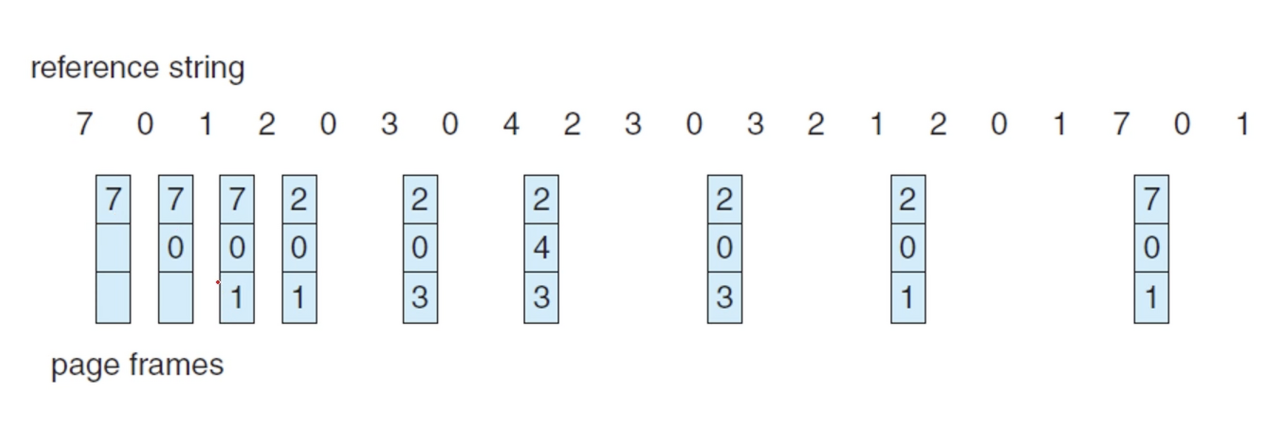
FIFO는 가장 단순한 페이지 교체 알고리즘으로, 메모리에 옮겨진 메모리들 중 가장 오래된 페이지를 Victim으로 선택한다.
그림에서 처음 7, 0, 1번 페이지에 대해 페이지 결함이 발생하고, 이들 페이지는 순서대로 프레임이 할당된다.
다음으로 2번 페이지의 요청에서 페이지 결함이 발생하고, FIFO 알고리즘에서는 가장 먼저 프레임을 할당받았던 7번 페이지를 Victim으로 선택해, 7번 페이지를 디스크에 기록하고 원래 7번이 할당받은 프레임을 2번 페이지에 새로 할당한다.
- Belady의 모순
프로세스에 프레임을 더 주었는데 오히려 페이지 폴트가 더 증가하는 현상 ex) 위 그래프에서 3개의 프레임 할당 시 페이지 폴트가 9번 일어나지만, 4개의 프레임 할당 시 페이지 폴트가 10번 일어난다.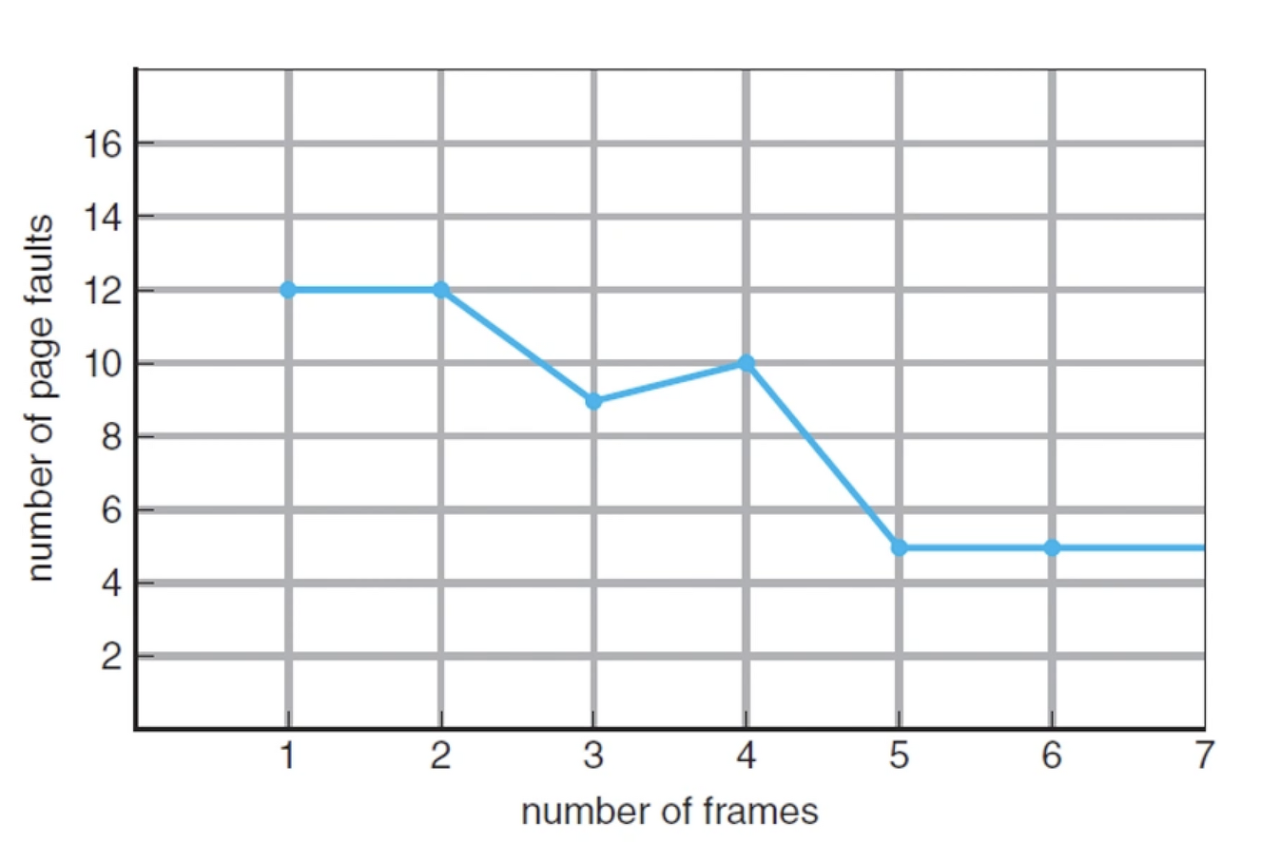
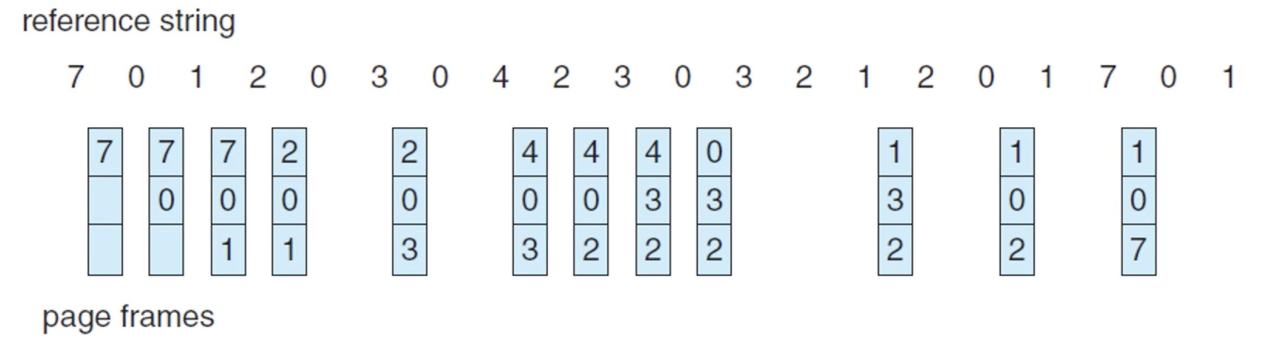
10.4.3 Optimal Page Replacement (최적 페이지 교체)
Belady's Anomaly가 발견된 후, 결과적으로 모든 알고리즘 중 가장 적은 페이지 결함을 나타내고 Belady's Anomaly가 발생하지 않는 최적의 페이지 교체 알고리즘이 연구되었다.
OPT 페이지 교체 알고리즘은 가장 오랫동안 사용되지 않을 페이지를 Victim으로 선택한다.
프로세스 스케줄링의 SJF 알고리즘과 마찬가지로, Optimal 페이지 교체 알고리즘은 참조 문자열의 미래 내용을 알고 있어야 한다는 전제가 필요해 구현하기가 어렵다는 단점이 있다.
→ 최적 페이지 교체를 통해 페이지 폴트 수를 계산해, 특정 알고리즘이 얼마나 효율적인지 계산하는 용도로 사용됨.
10.4.4 LRU Page Replacement (LRU 페이지 교체)
FIFO 알고리즘은 페이지가 메모리에 옮겨지는 시간을 사용하고, OPT는 페이지가 실제로 사용된 시간을 사용한다.
→ 과거 참조 내용을 통해 미래의 참조를 추정한다.
LRU 알고리즘은 각 페이지가 마지막으로 사용된 시간을 사용한다. 페이지 교체가 필요할 때, 지금까지 가장 오랜 기간동안 사용하지 않은 페이지를 Victim으로 선택한다.
- LRU 알고리즘의 2가지 구현 방법
- Counter를 사용한 구현
- 각 페이지 항목마다 사용 시간 필드를 넣고 CPU에 논리적인 시계나 계수기를 추가
- 메모리가 접근될 때마다 시간은 증가
- 페이지에 대한 참조가 일어날 때마다 페이지의 사용 시간 필드에 시간 레지스터의 내용이 복사됨
- 이렇게 각 페이지의 마지막 참조 시간을 유지할 수 있음
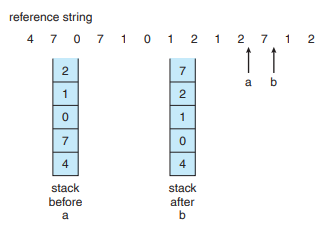
- Stack을 사용한 구현
- 페이지가 참조될 때 마다 페이지 번호는 스택의 중간에서 제거되어 스택 꼭대기에 놓임
- 스택의 꼭대기는 항상 가장 최근에 사용된 페이지임
- 스택의 밑바닥은 항상 가장 오랫동안 이용되지 않은 페이지
- 스택의 중간에서 항목을 제거할 필요가 있으므로 doubly linked list로 구현
- Counter를 사용한 구현
10.4.5 LRU Approximation Page Replacement (LRU 근사 페이지 교체)
-
LRU 알고리즘 지원을 충분히 할 수 있는 하드웨어는 많지 않다.
-
많은 시스템들은 참조 비트(Referenct bit)를 지원한다.
-
참조 비트는 페이지 테이블 항목에 존재하며, 페이지가 참조될 때 하드웨어에 의해 설정된다.
-
참조 비트는 최초 0으로 초기화되어 있으며, 사용자 프로세스가 실행되면 각 참조되는 페이지들에 대한 참조 비트는 1로 설정된다.
-
이 참조 비트를 통해 어떤 페이지가 프레임에 할당된 후 사용되지 않았는지 알 수 있지만, 페이지가 사용된 순서는 알 수 없다. 이 정보가 많은 LRU-Approximation 페이지 교체 알고리즘의 기반이 된다.
10.4.5.1 Second-Chance Algorithm (2차 기회 알고리즘)
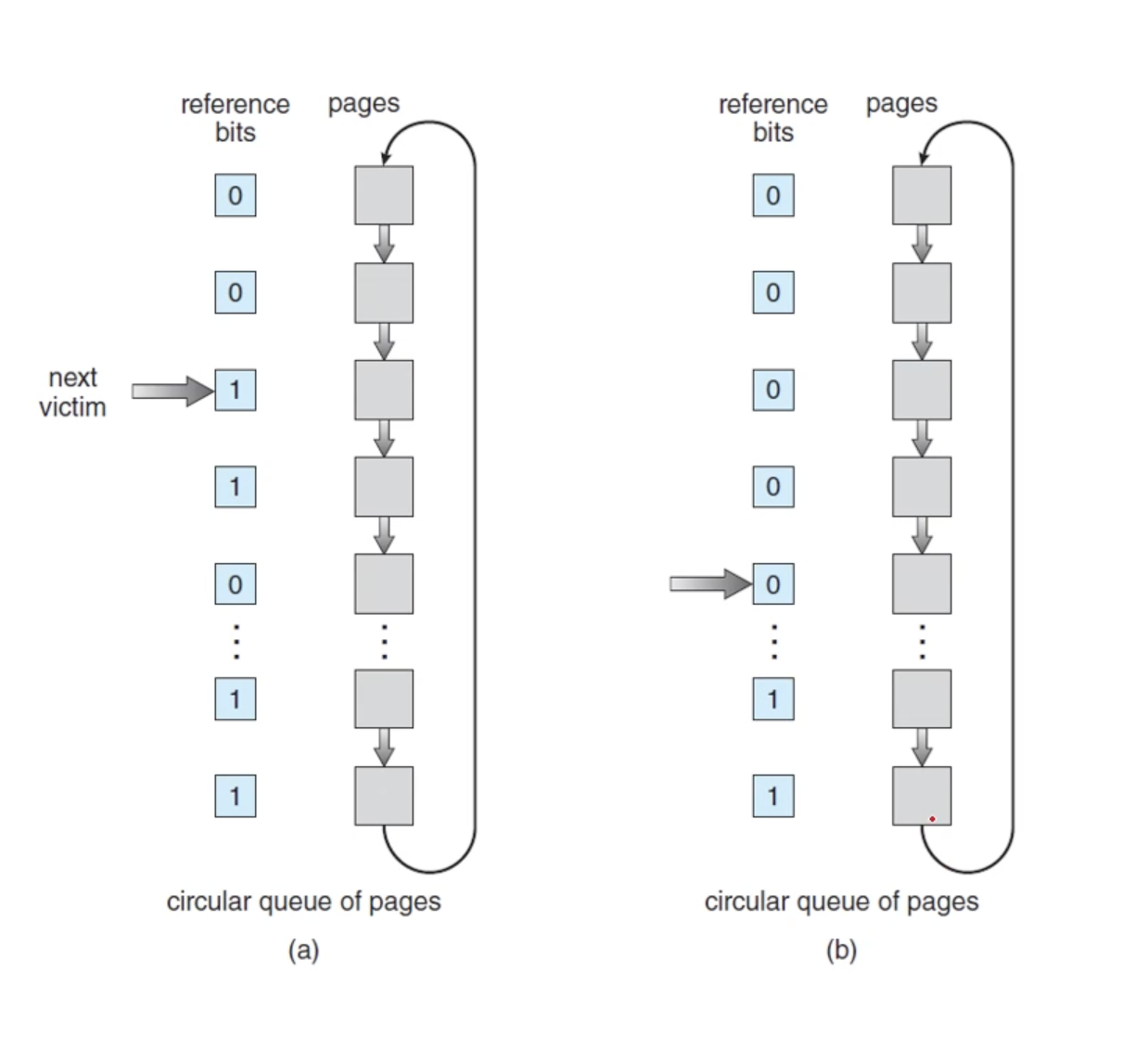
- 2차 기회 알고리즘의 기본은 FIFO 알고리즘 → But. 페이지 선택 시 참조 비트를 확인
- 참조 비트가 0이면 페이지를 교체하고, 1이면 다시 한번 기회를 주고 다음 페이지로 넘어감
- 어떤 프레임을 빼앗아야 할 일이 필요해지면 포인터는 0값의 참조 비트를 가진 페이지를 발견할 때 까지 큐를 뒤지고 참조 비트 값들이 1은 0으로 바꿈
- 0을 가지고 있는 victim 페이지를 발견하면 그 페이지는 교체되고 새로운 페이지는 큐의 해당 위치에 삽입됨
10.5 Allocation of Frames (프레임의 할당)
Q) N개의 프로세스에 M개의 프레임 분할
- 할당 비율을 다르게 하는 방법
- 균등 할당
각 프로세스에 M//N 프레임씩 나눠준다. - 비례 할당
각 프로세스의 크기 비율에 맞춰 프레임을 나눠준다.
- 균등 할당
- 프레임 할당을 위해 경쟁하는 환경을 다르게 하는 방법
- 지역 교체
- 각 프로세스가 자신에게 할당된 프레임 중에서 교체될 희생자를 선택
- 전역 교체
- 각 프로세스가 다른 프로세스에 속한 프레임을 포함해 모든 프레임을 대상으로 교체될 희생자를 선택
- 지역 교체
10.6 Trashing (스래싱)
프로세스에 충분한 프레임이 없어 과도한 페이징 작업을 하게 되어 실제 실행보다 더 많은 시간을 페이징에 사용하고 있는 현상
10.6.1 Cause of Thrashing (스래싱의 원인)
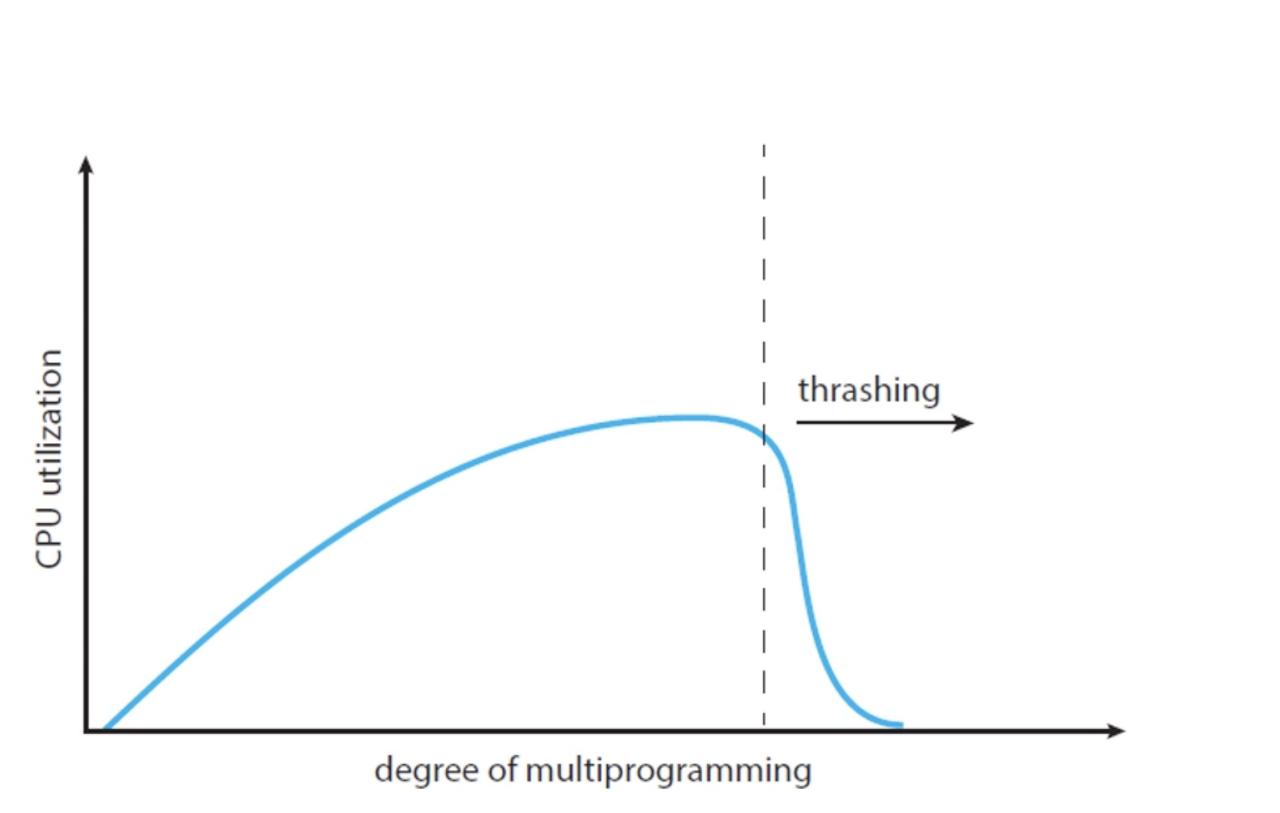
CPU의 사용률이 낮다면, 새로운 프로세스를 생성해 멀티프로그래밍의 정도를 높여 CPU의 사용률을 높이려 할 것이다.
하지만 어느 정도를 넘으면 스레싱이 발생해 오히려 사용률이 떨어져 스레싱이 발생한다. 이 경우에는 다시 멀티프로그래밍의 정도를 낮춰야 한다.
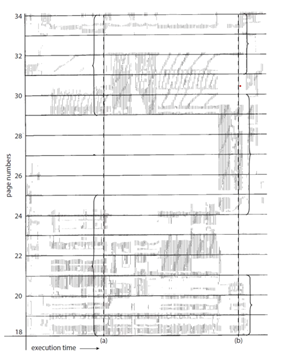
위 그림을 보면 페이지가 지역성을 보이는 것을 확인할 수 있다.
(프로세스 실행 시 특정 지역에서만 메모리를 집중적으로 참조)
→ 지역 교체 알고리즘을 사용해 스래싱의 영향을 제한할 수 있다.
10.6.2 Working-Set Model (작업 집합 모델)
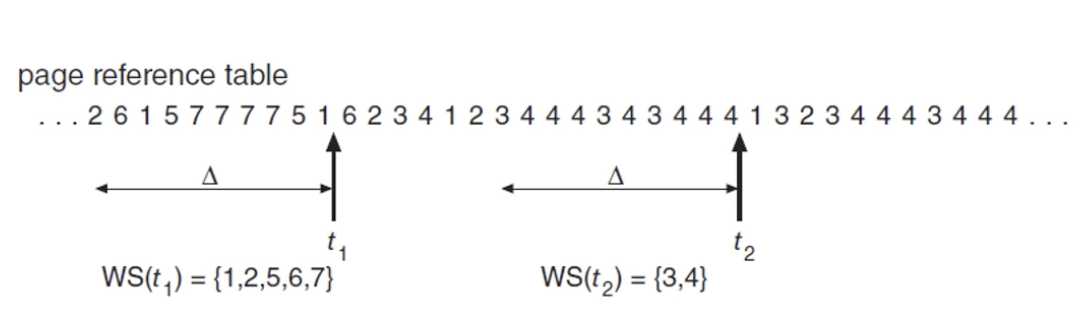
지역성을 토대로 하고, 창(Window)를 가지고 있다.
- 한 프로세스가 최근 Δ 페이지를 참조했다면 그 안에 들어있는 서로 다른 페이지들의 집합을 작업 집합이라고 부른다.
- 페이지가 더 사용되지 않게 되면 마지막 참조로부터 Δ만큼의 페이지 후에는 작업 집합에서 제외된다.
지역성이 있는 페이지들의 집합을 작업 집합이라 하고, 작업 집합 단위로 페이지를 관리한다.
참고 :
Silberschatz et al. 『Operating System Concepts』. WILEY, 2020.
