논문 정보
Title: PARTE: Part-Guided Texturing for 3D Human Reconstruction from a Single Image
Authors: Hyeongjin Nam, Donghwan Kim et al. (Seoul National Univ. & Korea Univ.)
Conference: ICCV 2025
Project Page: https://hygeniel228.github.io/PARTE/
1. Abstract: 핵심 요약
- Problem: Single Image 3D Reconstruction의 고질적인 문제는 "Texture Misalignment"다. 상의 색깔이 하의로 번지거나, 팔의 살색이 옷 위에 칠해지는 등 Boundary가 무너지는 현상이 빈번하다. 기존 방법들은 Global Context만 보고 색을 칠하기 때문이다.
- Method: PARTE라는 프레임워크를 제안한다. 핵심은 "먼저 부위(Part)를 나누고, 그 가이드(Guidance)에 맞춰 색을 칠하자"는 것이다.
1)PartSegmenter: Texture가 없는 3D Mesh 상태에서 먼저 3D Part Label(상의, 하의, 피부 등)을 추론한다.
2)PartTexturer: 추론된 Part Label을 Control Signal로 사용하여 Diffusion Model이 영역을 침범하지 않고 텍스처를 생성하도록 유도한다. - Result: 기존 SOTA(TeCH, SiTH 등) 대비 압도적인 Part IoU 성능을 달성했다. 뒷모습이나 가려진 부분에서도 상/하의 분리가 완벽하게 이루어진다.

2. Prerequisites: 이론적 배경
이 논문을 이해하기 위해서는 Invisible Region Reconstruction의 난이도와 Semantic Conditioning의 중요성을 이해해야 한다.
2.1. The Ambiguity of Single-View Reconstruction
단 한 장의 사진(Front-view)으로 3D를 만들 때, 등(Back-view)이나 팔 안쪽은 정보가 전혀 없는 미지수(Unknown Variable)다.
- Naive Approach: 기존 Regression 모델들은 이를 Neural Network의 "감"에 맡긴다. 결과적으로 네트워크는 평균적인 색상을 칠해버리는데, 이 과정에서 "상의는 여기서 끝나고 하의는 여기서 시작된다"는 구조적 정보(Structural Prior)를 무시하기 쉽다. 이를 Semantic Ambiguity라고 한다.
2.2. Score Distillation Sampling (SDS) with Constraints
최근에는 2D Diffusion Model의 강력한 Prior를 3D로 가져오는 SDS Loss를 많이 쓴다.
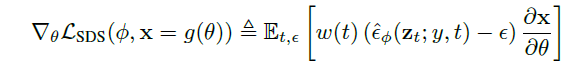
하지만 기본 SDS는 텍스트 프롬프트()만 조건으로 받는다. "A man wearing a red shirt"라고 줬을 때, 셔츠가 어디까지인지 Diffusion 모델은 정확히 모른다. 따라서 Spatial Constraint(공간적 제약)를 추가로 주어야 정확한 텍스처링이 가능하다. 이 논문은 그 제약 조건을 3D Part Segmentation으로 정의했다.
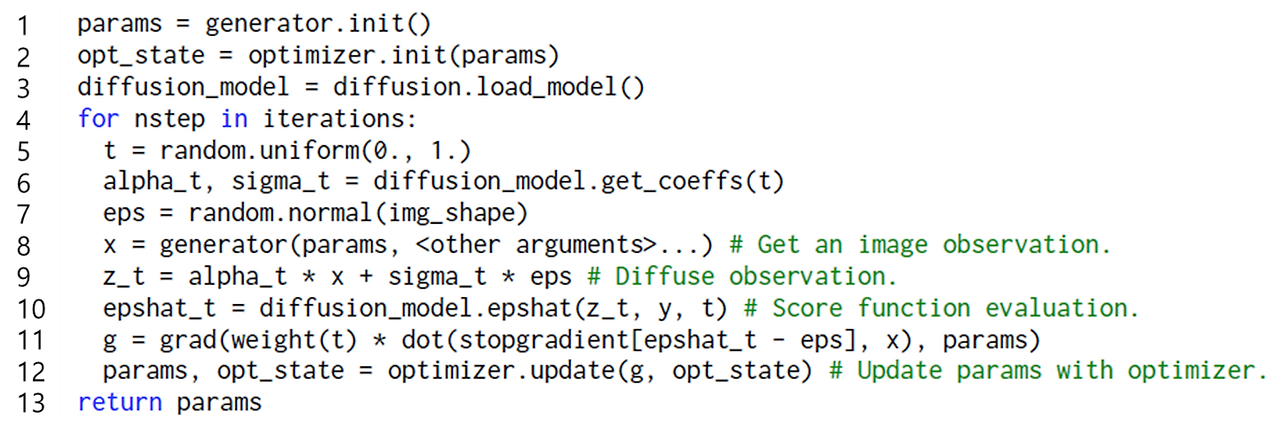
SDS Loss 수도코드 (NeRF 기준)
1~3 : NeRF generator, optimizer, diffusion model을 초기화하고 로드한다.
5 : diffusion model의 time step t가 uniform하게 정의된다.
6 : 시간 t에 따라 noise의 정도를 결정하는 alpha와 sigma가 정의된다.
7 : 이미지 크기만큼 가우시안 분포로 노이즈를 만든다.
8 : NeRF를 통해 이미지 x를 만든다.
9 : reparameterize trick을 통해 가우시안 확률분포를 계산 가능한 수식으로 만든다. z_t로 계산된다.
10 : z_t와 text embedding y, t를 입력으로 U-Net을 통과한다.
11 : 위에서 언급한 아래 수식을 계산한다. Diffusion Model은 업데이트 안하기 때문에 stopgradient가 사용된다.
DreamFusion (ICLR 2023) 논문에 해당 내용이 자세히 있으니 나중에 읽어보자...
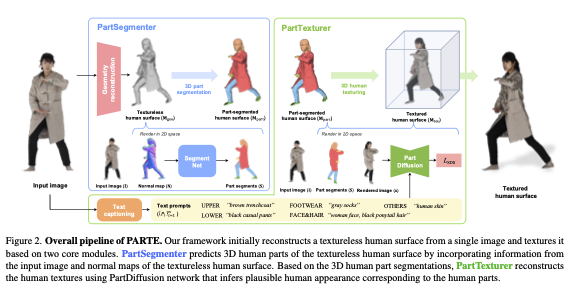
3. Method: PARTE Framework
PARTE의 파이프라인은 Geometry Reconstruction Part Segmentation Part Texturing의 순차적(Sequential) 구조를 가진다.
3.1. Geometry Reconstruction (Pre-processing)
먼저 입력 이미지로부터 Texture가 없는 Base Mesh ()를 생성한다. 이 논문에서는 SOTA인 TeCH를 사용했지만, 어떤 Reconstruction 모델을 써도 무방(Model-Agnostic)하다. 중요한 건 텍스처를 입히기 전의 "형태"다.
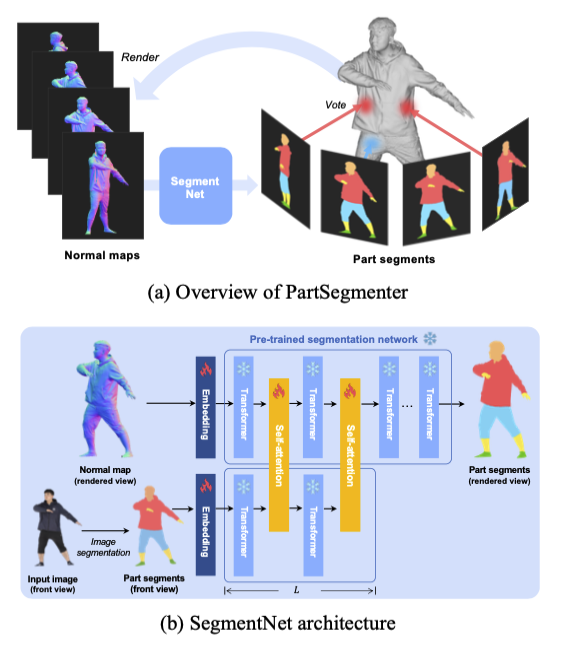
3.2. Module 1: PartSegmenter (3D Labeling)
이 모듈의 목표는 3D Mesh의 각 Vertex에 개의 라벨(Face&Hair, Upper, Lower, Footwear, Others)을 할당하는 것이다.
- Problem: 3D Segmentation 데이터셋은 부족하다. 반면 2D Segmentation 데이터셋은 풍부하다.
- Solution (Lifting 2D to 3D):
- Textureless Mesh를 여러 각도()에서 렌더링하여 Normal Map ()을 얻는다.
- SegmentNet이라는 Transformer 기반 네트워크가 이 Normal Map과 Input Image를 보고 2D Segmentation Map ()을 예측한다.
- 여러 뷰에서 예측된 2D 맵들을 3D 공간으로 역투영(Back-projection)하여 Voting 방식으로 최종 3D Part Label을 확정한다.
Why Transformer?
SegmentNet은 두 가지 Branch(Normal Map branch, Input Image branch)를 가진다. Normal Map은 "옷의 주름/경계" 같은 기하학적 정보를 주고, Input Image는 "옷의 스타일" 같은 의미론적 정보를 준다. 이 둘을 Self-Attention으로 융합(Fusion)하여 보이지 않는 뒷면의 파트까지 정확히 추론한다.
3.3. Module 2: PartTexturer (Guided Diffusion)
이제 구획이 나눠진 Mesh() 위에 색을 입힐 차례다. 저자들은 이를 위해 PartDiffusion이라는 커스텀 Diffusion 모델을 설계했다.
-
Conditioning Logic:
기존 Stable Diffusion에 Fusion Layer를 추가하여 다음 세 가지 정보를 동시에 주입한다.- Text Prompts:
BLIP으로 추출한 캡션 (Global Semantic). - Input Image: 원본 이미지의 디테일 (Local Appearance).
- Part Segments: 방금 구한 Segmentation Map (Structural Constraint).
- Text Prompts:
-
Optimization with SDS:
-
: Front-view에서는 원본 이미지와 L2 Loss로 픽셀을 맞춘다.
-
: 다른 뷰(Side, Back)에서는 PartDiffusion이 예측한 Noise 분포를 따르도록 최적화한다.
여기서 핵심은 PartDiffusion이 "Part Map"을 조건으로 받기 때문에, 렌더링된 뷰에서 상의 영역에는 무조건 상의 텍스처만 생성하도록 강제된다는 점이다. 이를 통해 Texture Bleeding을 원천 차단한다.
-
4. Experiments: Analysis
THuman2.1, HuMMan 데이터셋을 사용하여 정량적/정성적 평가를 진행했다.
4.1. Quantitative Results (Part Alignment)
가장 주목할 지표는 Part IoU와 LPIPS다.
| Method | PSNR | LPIPS | Part IoU |
|---|---|---|---|
| TeCH (SOTA) | 21.089 | 0.108 | 0.588 |
| HumanRef | 21.302 | 0.113 | 0.576 |
| PARTE (Ours) | 22.175 | 0.096 | 0.641 |
- Analysis: Part IoU가 압도적으로 높다. 이는 텍스처가 제자리에 정확히 들어갔음을 의미한다. 기존 방법들은 구조적 제약이 없어서 Part IoU가 낮게(색이 번짐) 측정된다.

4.2. Qualitative Results (Visual Fidelity)

- Comparison: SiTH나 HumanRef 같은 모델들을 보면, 뒷모습에서 상의 텍스처가 엉덩이까지 내려오거나, 반팔 소매 안쪽에 살색 대신 옷 색깔이 칠해지는 아티팩트가 보인다.
- PARTE: 정확하게 허리 라인에서 상/하의 텍스처가 분리되며, 소매 끝단과 피부의 경계가 칼같이 나눠진다. 이는 PartSegmenter가 3D 상에서 명확한 가이드라인을 그어줬기 때문이다.
5. Conclusion & Discussion
결론 요약
PARTE는 "텍스처링은 기하학적 구조에 종속되어야 한다"는 직관을 모델링한 연구다.
1. Divide and Conquer: 문제를 Segmentation과 Texturing로 쪼개서 풀었다.
2. Explicit Guidance: Diffusion Model의 생성 능력을 믿되, Part Map이라는 강력한 제약 조건을 걸어 Hallucination을 막았다.
🎓 Graduate Student's Insight (Critical Thinking)
- Structural Prior의 승리: 단순히 데이터를 많이 때려 넣어서 해결하려는 접근 대신, "사람은 파트별로 옷을 입는다"는 사전 지식을 네트워크 구조에 녹여냈다.
- Dependency Issue: 첫 단계인
Geometry Reconstruction이 망가져서 Mesh가 뭉개지면,PartSegmenter도 뭉개지고, 결국PartTexturer도 망한다. 즉, Error Propagation의 위험이 있지 않을까? - Optimization Cost: Optimization-based method(SDS 사용)이기 때문에 Inference 시간이 꽤 걸릴 것이다. Real-time application을 위해서는 방식전환이 필요할 것 같다.
앞으로 3D Human Generation 연구를 할 때, 단순히 RGB값만 예측하는 게 아니라 Semantic Map을 함께 예측하는 것이 필수가 될 것 같다는 생각이 든다.
References
- Nam et al., "PARTE: Part-Guided Texturing for 3D Human Reconstruction from a Single Image", ICCV 2025.
- Huang et al., "TeCH: Text-guided reconstruction of lifelike clothed humans", 3DV 2024.
- Khirodkar et al., "Sapiens: Foundation for human vision models", ECCV 2024.
- https://xoft.tistory.com/53 -> SDS개념 참고
