논문 정보
Title: PERSONA: Personalized Whole-Body 3D Avatar with Pose-Driven Deformations from a Single Image
Authors: Geonhee Sim, Gyeongsik Moon (Korea Univ.)
Conference: ICCV 2025
Project Page: https://mks0601.github.io/PERSONA
1. Abstract:3줄 핵심 요약
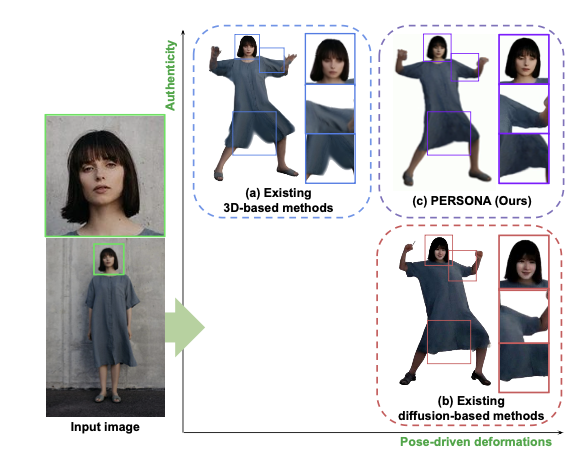
- Problem Formulation: Single Image 기반 3D Avatar 생성은 Identity Preservation과 Pose-Driven Deformation 사이의 Trade-off 문제에 직면해 있음. 기존 3D 방식은 데이터 부족으로 옷의 변형을 학습하지 못하고, Diffusion 방식은 시간적 일관성과 Identity가 무너짐.
- Proposed Method: PERSONA는 Diffusion Model의 Generative Prior를 3D Optimization 과정에 Distill하는 프레임워크를 제안.
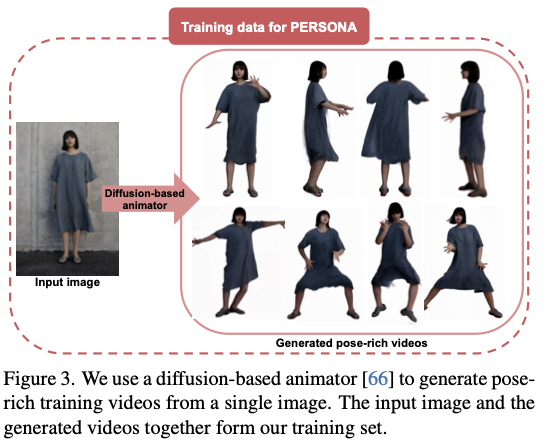
Data augment: Diffusion 기반으로 Pose-rich video를 생성하여 Motion Prior 확보.
Optimization: Synthetic Data의 품질 저하를 방어하기 위한 Balanced Sampling과 Texture/Geometry의 신뢰도를 분리한 Geometry-Weighted Optimization 도입. - Contribution: 단일 이미지 입력만으로도 Canonical Space 내에서 Disentangled Representation(Pose와 Identity 분리)을 달성하고, 펄럭이는 옷자락 같은 Non-rigid motion을 물리적으로 그럴듯하게 재현함.
2. Prerequisites: 이론적 배경
이 논문을 깊이 이해하려면 Parametric Model과 Neural Rendering의 결합, 그리고 Synthetic Data 활용 시 발생하는 도메인 격차 문제를 알아야 한다.
머신러닝의 가장 대표적인 책인 머피의 머신러닝에서는 아래와 같이 정의한다.
Parametric model: Linear regression, Logistic regression, Bayesian inference, Neural network(CNN, RNN 등) 등. 모델이 학습해야 하는 것이 명확히 정해져 있기 때문에 속도가 빠르고, 모델을 이해하기가 쉽다는 장점이 있다. 하지만 데이터의 분포가 특정한 분포를 따른다는 가정을 해야 하기 때문에 flexibility가 낮고, 간단한 문제를 푸는 데에 더 적합하다는 단점을 가진다.
Non-parametric model: Decision tree, Random forest, K-nearest neighbor classifier 등. 데이터가 특정한 분포를 따른다는 가정을 하지 않기 때문에 더 flexible하다는 장점이 있다. 하지만 속도가 느린 경우가 많고, 더 큰 데이터를 필요로 하는 경우가 있으며 모델이 왜 그런 형태가 되었는지에 대한 명확한 설명을 하기가 쉽지 않다.
2.1. Hybrid Representation (SMPL-X + 3DGS)
최근 Human Avatar 연구의 트렌드는 SMPL-X와 같은 Parametric Model의 제약(Rigid)을 3D Gaussian Splatting(3DGS)의 표현력으로 보완하는 것
- SMPL-X: (Shape), (Pose) 파라미터로 사람의 기본 골격과 스킨을 정의. 하지만 옷의 주름이나 펄럭임 같은 High-frequency detail은 표현 불가.
- 3DGS: 3D 공간에 Gaussian 분포를 뿌려 렌더링. Texture 표현력이 좋지만, 그 자체로는 Animation이 불가능.
- Combination: SMPL-X Mesh의 Vertex마다 Gaussian을 바인딩하고, LBS(Linear Blend Skinning)로 큰 움직임을 제어하되, 세부 변형은 별도의 Network로 학습
2.2. The Curse of Single-View & Prior Distillation
Single-view Reconstruction은 본질적으로 Ill-posed Problem입니다. 뒷모습이나 측면 정보가 없기 때문
- 최근 연구들은 Video Diffusion Model이 학습한 방대한 2D Motion Prior를 3D 모델로 전이(Distillation)시키는 접근을 취한다
- 하지만 Diffusion이 생성한 비디오는 Identity Shift(얼굴이 바뀜)와 Inconsistent Texture(옷 무늬가 변함) 문제를 가진다. 이 논문은 이 "Noise가 섞인 Prior"를 어떻게 정제해서 3D 모델에 주입할 것인가에 대한 해답
3. Method: PERSONA Framework
PERSONA의 파이프라인은 크게 (1) Pose-rich Video Generation과 (2) Physics-aware 3D Optimization으로 나뉩니다. 특히 3DGS의 파라미터 업데이트 전략이 이론적으로 중요
3.1. Representation & Deformation Module
Canonical Space(T-pose와 유사)에 정의된 Gaussian들을 Target Pose로 변형시키기 위해 Deformation MLP를 설계
-
Canonical Gaussians: 초기에 SMPL-X 메쉬 위에 바인딩 됨.
-
(Mean Offsets): MLP가 예측하는 값. 여기서 흥미로운 점은 Scale()이나 Rotation() Offset은 예측하지 않고, 오직 위치(Mean, ) Offset만 예측한다는 점
- Theoretical Insight: Scale Offset을 학습하면 모델이 옷의 주름을 표현할 때 Gaussian을 찢거나 늘려서(Blurry) 표현하려는 경향이 생긴다. Shift만해야 텍스처의 선명도(Sharpness)를 유지하면서 기하학적 변형을 모사할 수 있다
3.2. Balanced Sampling (Handling Distribution Shift)
Diffusion으로 생성된 비디오 데이터셋 과 원본 이미지 사이에는 Distribution Gap이 존재. 은 포즈는 다양하지만 Identity 정보()가 훼손되어 있다.
학습 Loop 내에서 Oversampling 전략을 통해 이를 보정
- Training Batch 구성 시, 의 샘플링 비율을 인위적으로 높여 Authenticity(Identity)를 강제한다.
- 이때 발생하는 Baked-in Artifacts(원본의 그림자나 가려진 부분이 3D 텍스처에 고착되는 현상)를 막기 위해, Canonical Space에서 렌더링된 Positional Map에 Sobel Filter를 적용, Seam Boundary를 검출하여 가려진 영역의 학습을 분리.
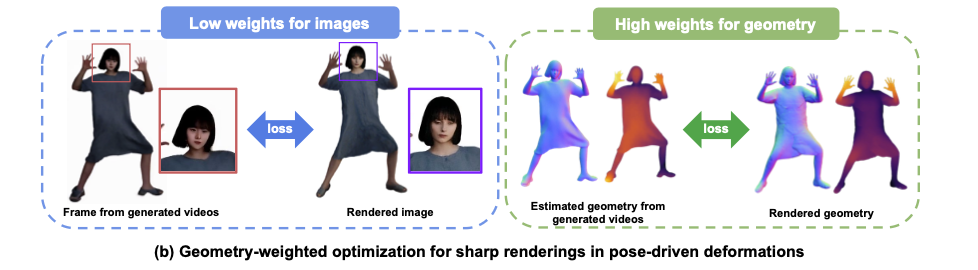
3.3. Geometry-Weighted Optimization (Loss Landscape Shaping)
이 논문의 핵심이론으로 생성된 비디오 프레임 은 텍스처 품질은 낮지만(Low-fidelity Texture), 사람의 실루엣이나 깊이 정보는 꽤 정확하다.
따라서 Optimization 과정에서 Image Loss와 Geometry Loss의 가중치를 비대칭적으로 설정
- For Generated Frames ():
- : 생성된 비디오의 픽셀 색상은 신뢰하지 않음 (Blurry Texture 방지).
- : 생성된 비디오의 Mask, Depth, Normal Map은 신뢰함. 이를 통해 "옷이 펄럭이는 물리적 움직임"만 학습.
- For Input Image ():
- : 원본의 텍스처를 3DGS의 SH(Spherical Harmonics) 파라미터에 확실히 각인시킴.
즉, Geometry는 Diffusion Prior에서 배우고, Appearance는 Input Image에서 배우는 최적화 전략
4. Experiments: Analysis
4.1. Comparison with SOTA (Quantitative)
NeuMan 및 X-Humans 데이터셋에서의 평가 결과
| Method | Approach | PSNR | LPIPS | Pose-Driven Deform |
|---|---|---|---|---|
| AniGS | 3D (4DGS) | 27.46 | 0.043 | (Baked-in) |
| Champ | Diffusion | 25.19 | 0.057 | (High Consistency) |
| PERSONA | Hybrid | 29.79 | 0.035 |
- Analysis: PERSONA는 LPIPS(지각적 유사도)에서 압도적인 성능을 보인다. 이는 Balanced Sampling이 Identity를 잘 보존하고 있음을 수치적으로 증명
- 특히 기존 3D 방식(AniGS)이 Input Image의 주름을 모든 포즈에 복사(Baked-in)하는 반면, PERSONA는 포즈에 따른 옷의 인장/수축을 반영
4.2. Ablation Study: Why Geometry-Weighted?
논문의 Figure 6은 Geometry-Weighted Optimization의 필요성을 명확히 보여줍니다.

- High Image Loss Weight: 생성된 비디오의 흐릿한 텍스처까지 3DGS가 억지로 학습하려다 보니 전체적인 렌더링 퀄리티가 망가진다 (Blurry).
- Ours: Geometry Loss에 집중함으로써, 텍스처는 선명하게 유지하되->이미지, 실루엣->동영상 은 역동적으로 변하는 결과를 얻는다.
5. Conclusion & Discussion
Summary
PERSONA는 Single Image Avatar 생성 문제에서 Generative Prior를 3D Geometry로 효과적으로 전이시키는 방법론을 제시
단순히 데이터를 늘리는 것이 아니라, Synthetic Data의 Noise(Texture)와 Signal(Geometry)을 분리하여 Loss Function에 반영한 연구이다.
🎓 Graduate Student's Insight (Critical Thinking)
논문을 읽으며 든 생각과 한계점은 다음과 같습니다.
- 업스트림 모델에 종속된 결과들이 나올 것 같다: 결국 성능의 상한선이MimicMotion과 같은 비디오 생성 모델의 성능에 종속된다고 생각합니다.
- Scalability to Loose Clothing: 논문에서 제시한 것처럼 드레스나 디테일이 많은 옷처럼 SMPL-X 메쉬(Body Topology)와 Topological 차이가 큰 의상의 경우, Vertex Binding 기반의 접근법이 얼마나 유효할지 의문Gaussian이 메쉬에서 너무 멀어지면 Density Control이 어려울 것 같다. -> 코드를 한번 돌려봐야겠당
- 실시간 반영성이 높을 것 같다: 3DGS를 기반으로 하므로 학습 후 렌더링 속도는 매우 빠를 것으로 예상됩니다. 이는 VR/AR 어플리케이션 관점에서 NeRF 기반 방식보다 확실한 우위일 것 같다.
다음에는 이 논문에서 사용된 MimicMotion이나 3DGS의 Deformation Model에 대해 더 깊게 파봐야 될 것 같다고 생각합니다.
References
- [1] Sim et al., "PERSONA: Personalized Whole-Body 3D Avatar with Pose-Driven Deformations from a Single Image", ICCV 2025.
- [2] Moon et al., "Expressive Whole-Body 3D Gaussian Avatar", ECCV 2024.
- [3] Zhang et al., "MimicMotion: High-Quality Human Motion Video Generation", CVPR 2024.
