VideoMind: A Chain-of-LoRA Agent for Long Video Reasoning
Abstract
비디오는 고유한 시계열적 차원을 지니고 있어, 답변이 해석 가능한 시각적 근거와 직접적으로 연결되는 Grounded Understanding을 요구한다.LLM의 추론 능력은 비약적 발전하였으나, 멀티모달 추론(특히 비디오)는 여전히 미개척 영역으로 남아있다. 해당 논문은 시계열 근거 기반 비디오 이해를 위해 설계된 혁신적인 비디오 -언어 에이전트인 VideoMind를 소개한다. 혁신은 다음과 같다.
- Role - based agentic Workflow : 비디오 시계열 추론에 필수적인 역량을 정의하고, 각 역할을 조율하는 Planner, 시계열적 국소화를 수행하는 Grounder, 시계열 구간의 정확성을 평가하는 Verifier, 그리고 최종 답변을 도출하는 Answerer로 구성된 워크플로우 개발
- Chain-of-Lora : 이러한 다양한 역할들을 효율적으로 통합하기 위해 새로운 Chain-of-Lora 전략을 제안, 이는 경량화된 LoRA 어댑터를 통해 모델 전환 오버헤드 없이 유연하게 역할을 전환할 수 있게 하여, 효율성과 유연성 사이의 균형을 맞춘다.
14개의 공개 벤치마크를 대상으로 한 광범위한 실험을 통해, 본 에이전트가 다양한 이해과업에서 SOTA 성능을 달성함을 입증하였으며, 이는 비디오 에어전트 및 장기 시계열 추론 분야의 발전에 기여할 효과적인 방법임을 시사
핵심 요약
Objective: 비디오의 '시간적 근거(Temporal Grounding)'를 명확히 하여 추론의 신뢰도 향상.
Architecture: 4가지 논리적 역할(Planner, Grounder, Verifier, Answerer)을 분리한 에이전트 구조.
Efficiency: 여러 모델을 로드하는 대신, Chain-of-LoRA를 통해 하나의 베이스 모델에서 어댑터만 교체하며 연산 효율 극대화.
Performance: 총 14개 벤치마크에서 기존 모델들을 상회하는 성능 확인.
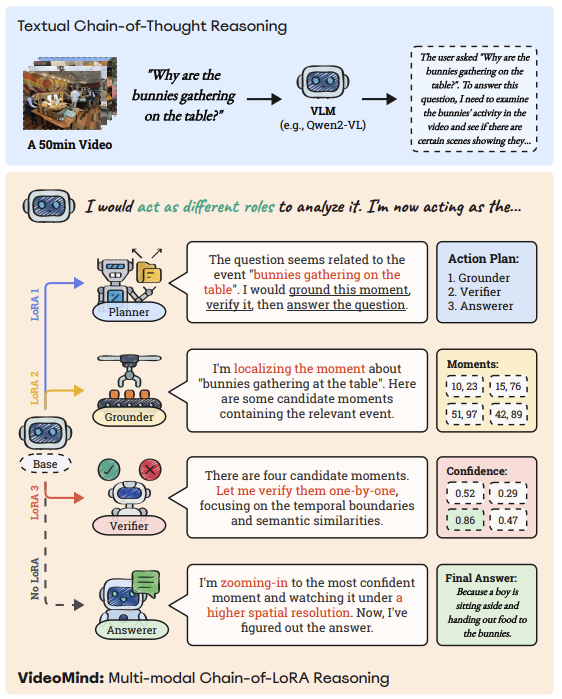
figure1.
I. Introduction
LLM의 발전은 Chain-of-Thought과 같은 추론에서 효과를 입증하며, 복장한 문제ㅐ 해결 시나리오에서 정확성과 해석 가능성을 모두 향상시켰다. 이러한 성과가 추론 능력을 시각적 수학 이해같은 멀티모달 영역으로 확장하려는 노력을 기울이고 있다.
멀티모달 입력 데이터중에서 비디오는 Temporal Dimension으로 인해 정적인 이미지나 텍스트에서는 발견되지 않는 복잡성을 지닌다. 효과적인 비디오 추론을 위해서는 단순히 외형을 인식하는 것 뿐만 아니라, 시간에 따른 Temporal Grounding에 따른 이해가 필수적이다.최근 시각정 CoT 방법론들은 정적 시각 입력에 대해 상세한 사고 과정을 생성하는데는 탁월하지만, Figure1.에서 보이듯 이전 시퀸스를 명시적으로 국소화하거나 재방문할 수 없기 때문에 비디오 분석에도 어려움이 있다.
다만, 인간은 비디오를 이해하기 쉽다. 인간은 복잡한 문제를 분해, 식별, 세부사항 살펴보기, 관찰 내용에 일관된 답변을 종합한다. 이러한 인간의 자연스러운 능력이 본 영구의 동기이며, 고급 비디오 추론을 달성하기 위해 여러 역량을 능숙하게 관리하며, 이 과정을 복제할 수 있는 AI assistant를 개발하게 되었다.
비디오 마인드 소개
- 다양한 요구사항 충족 : 비디오 이해에 필수적인 핵심 역할들을 정의, 정밀한 순간 검색을 위해 4가지 논리적 역할(Planner, Grounder, Verifier, Answerer)을 분리한 에이전트 구조를 차용했으며 예를 들어 Grounder는 강력한 시계열 근거 분석 능력을 보장하기 위해 타임스탬프 디코더를 장착하고 있습니다.
- 효율적 협업 : 단일 베이스 멀티모달 LLM(MLLM ex.Qwen2-VL)을 기반으로 구축된 새로운 Chain-0f-LoRA 전략을 제안한다. 이 접근 방식은 미니멀하면서도 유연한 설계 철학을 구현하여, 여러 개의 전체 모델을 사용하는 계산적 부담 없이 역할 간의 전환과 상호작용을 가능케 한다.
따라서 VideoMind는 효율성과 적응성을 동시에 달성하며 다양한 비디오에서 실용적이고 유연한 솔루션을 제공한다.
VideoMind의 효과를 평가하기 위해 Grounded VideoQA, VTG, VideoQA를 포함한 14개의 벤치마크에서 광범위한 실험을 수행했다. VideoMind는 시계열적 근거 기반의 증거와 정확한 답변을 동시에 제공, 복잡한 추론을 점진적으로 처리하는 능력을 입증했다. 특히 2B사이즈에서도 CG-Bench의 긴 비디오 과업에서 GPT-4o와 같은 최고 성능 모델을 능가하는 성능을 보인다. 또, VTG 및 일반 VideoQA 설정에서도 강력한 성능을 보인디ㅏ. Ablation Study 결과 설계선택의 핵심적 기여가 확인된다.
II. Related Works
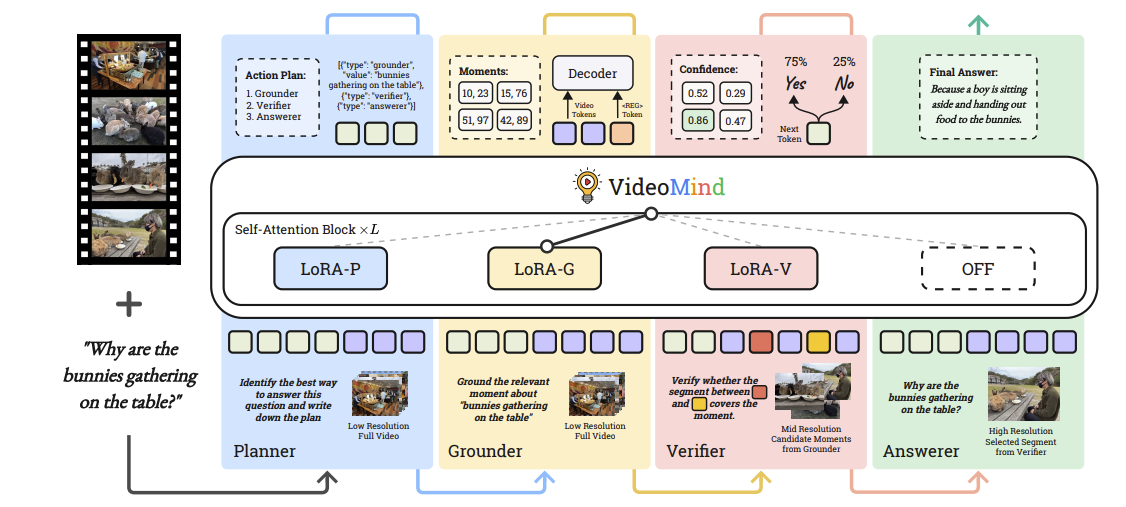
Figure2. VideoMind의 전체 워크플로우. Query가 주어지면, VideoMind는 다양한 역할(이 사례의 경우 Planner → Grounder → Verifier → Answerer)을 적응적으로 활성화하고, 개별 모듈을 호출하여 단계별 추론을 수행한다.
2.1 Temporal-grounded Video Understanding
비디오 캡셔닝, VideoQA, 비디오-텍스트 검색 등 비디오 이해 분야의 비약적인 발전은 인스턴스 수준의 이해를 강조해 왔으나, 이러한 모델들은 Visual-Grounded와의 대응성 및 해석 가능서잉 부족, 특히 긴 비디오에서 이러한 경향이 심하다.
VTG는 다양한 질의에 대해 정밀한 시계열적 국소화를 요구함으로써 이를 해결하려 하지만, 기존 회귀 기반 모델은 국소화에는 능숙하나 텍스트 기반의 해석 가능성을 제공하는데 한계가 있다. 최근 벤치마크는 복잡한 질문에 대한 추론과 세밀한 시계열 대응을 동시에 요구하며 이러한 도전을 심화한다. 기존 베이스라인들은 주로 다중 작업 목적함수나 컴포넌트들로 구성된 모듈형 에이전트에 의존해왔으나, 이는 흔히 최적화되지 못한 성능을 보이거나 시스템이 지나치게 복잡해져 효율성과 유연성을 저해한다. VideoMind는 통합된 백본위에 구축된 에이전트 워크플로우를 도입, 국소화 능력과 해석 가능성을 강화하는 동시에 여러 기능을 원활하게 통합함으로써 기존 방법론의 한계를 극복한다.
2.2 Multi-modal Reasoning
지도 학습 기반 명령어(SFT)으로 학습된 LLM은 자유 형식의 대화나 질의응답 등 일발화된 능력을 보여주지만, LLM의 추론 능력이 필수적인 복잡한 문제 해결에는 미습하다.
1. 이를 극복하기 위한 방법으로는 에어전트 기반 인터페이스를 개발하여 여러 시각적 도구의 텍스트 출력을 통합하고 LLM을 통해 언어적 추론을 가능하게 하는 것이다. Codex나 ReAct와 같은 전략을 활용하여 점진적인 실행 및 추론 과정에서 시각적 API(검출기나 캡서너)를 호출한다.
2. 다른 대안으로는 강화학습을 통한 긴 CoT 프로세스 학습으로 대표되는 순수 텍스트 기반 추론이 LLM이 주류 패러다임이라면, 일부 연구는 이를 복잡한 수학적 문제를 위한 시각적 영역으로 확장했다. 이러한 진전에도 불구, 시계열 차원을 가로지르는 비디오 추론 확장은 여전히 미해결 과제로 남아있다. 정보량이 많은 비디오의 긴 문맥 특성을 고려, 비디오 중심의 CoT는 인간과 유사한 다시보기 전략과 중간 관찰 값에 대한 자기 검증을 포함해야 한다고 판단하며, 이에 따라 비디오 추론을 위한 새로운 Chain-of-LoRA 프레임 워크를 도입한다.
2.3 Inference-time Searching
추론 시간 탐색은 로보틱스, 게임, 네비게이션 등의 분야에서 복잡한 추론 및 계획 과업을 해결하기 위한 핵심 기술로 떠오른다. 이는 학습 시 전략과 달리 학습 후 추론 과정에서 모델의 행동을 최적화한다. OpenAI o1의 등장은 제어된 디코딩, Best-of-N 샘플링, MCTS과 같은 샘플링 전략을 통합함으로써 LLM내의 이러한 추론 시간 기술을 발전시켰으며, 이를 통해 가중치 변경 없이도 출력을 반복적으로 정제하고 우수한 성능을 달성했다. 그러나 추론 시간 탐색의 잠재력은 시계열 추론이 독특한 과제를 제시하는 비디오 이해 분야에서는 활용되고 있지 않다. 본 프레임워크에서는 비디오 시계열 추론에 최적화된 MCTS 활용 방안을 탐구하며, 모델이 시계열 구간 선택에 민감하고 구간 선택이 최적이지 않을 경우 신뢰할 수 없는 예측을 생성한다는 점이 관찰됐다. 이를 해결하기 위해 비디오 모먼트 수준의 MCTS 접근법을 제안한다. 여기서 Grounder는 여러 구간 후보를 생성하고, 뒤이어 Verifier가 정확한 대응 여부를 평가 및 결정한다. 실험을 통해 이 전략이 다양한 비디오 컨텍스트에서 시계열 국소화의 정확도와 강건성을 유의미하게 향상시킴을 확인했다.
III.VideoMind
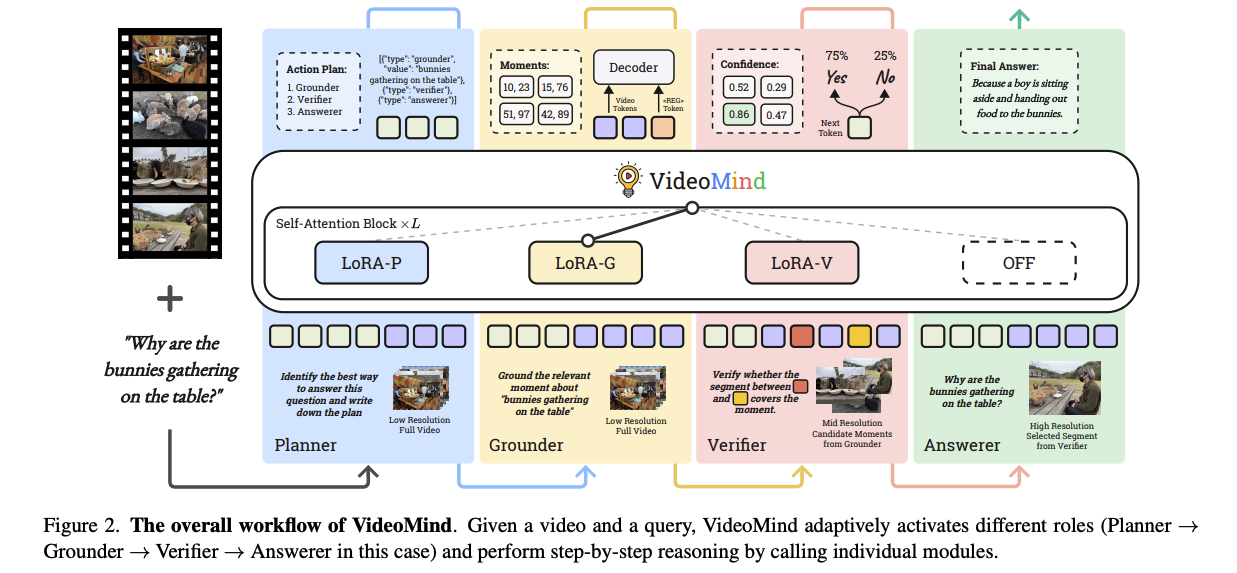
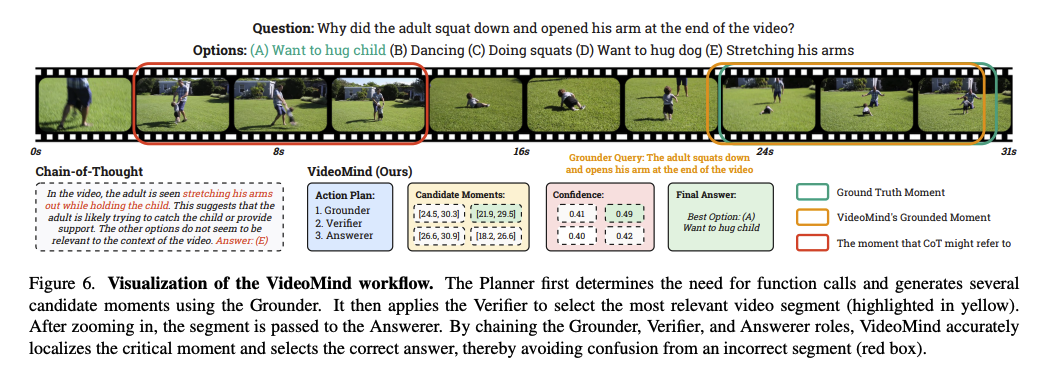
figure2는 VideoMind의 전반적인 구조를 보여준다. 본 모델은 동적 해상도 입력을 기본적으로 지원하는 ViT기반 시각 인코더와 LLM 백본으로 구성된 Qwen2-VL 아키텍처를 계승한다. 비디오 입력 V와 텍스트 질의 Q가 주어지면, 모델은 다음의 역할들을 적응적으로 활성화하여 단계별 추론을 수행한다.
Planner (플래너): 질의에 따라 이후 역할들을 동적으로 조율한다.
Grounder (그라운더): 관련 비디오 구간(Moment)을 식별하고 국소화한다
Verifier (검증기): Grounder가 찾은 구간의 유효성을 평가하고, Boolean 출력을 통해 구간을 정밀화
Answerer (응답기): 자연어로 최종 답변을 생성, 이러한 메커니즘을 통해 모델은 비디오를 여러 번 다시 보며(다양한 시간 구간 및 공간 해상도 적용) 최종 해답을 도출한다.
3.1 Planner
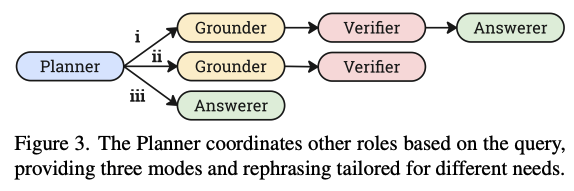
에이전트는 유연하게 다음 기능을 결정해야 한다. 이를 위해 시각적 문맥에 따라 기능 호출 순서를 결정하는 Planner 역할을 도입한다. 각 기능 호출은
{"type" : <role>, "value" : <argument>} 형태의 JSON 객체로 정의되며, Figure3과 같이 세 가지 계획 모드를 제공한다.
1. Grounding & Answering : 답변과 시간적 구간을 모두 생성한다. 예를 들어 ~~할때 소년은 무엇을 하고 있나요? 같은 느낌으로
2. Grounding Only : 구간 검색 업무에 최적화되어 타임 스탬프만 출력한다.
3. Answering Only : 질문이 단순할 때, 예를 들어 요약, 추가적인 국소화 호출 없이 비디오 전체를 보고 즉시 답변
4. Query Rehrasing : 번외로 질의가 불분명할 경우, 정확한 국소화를 위해 더 묘사적인 버전으로 질문을 재구성한다.
3.2 Grounder
텍스트 질의를 바탕으로 관련 구간을 국소화한다.
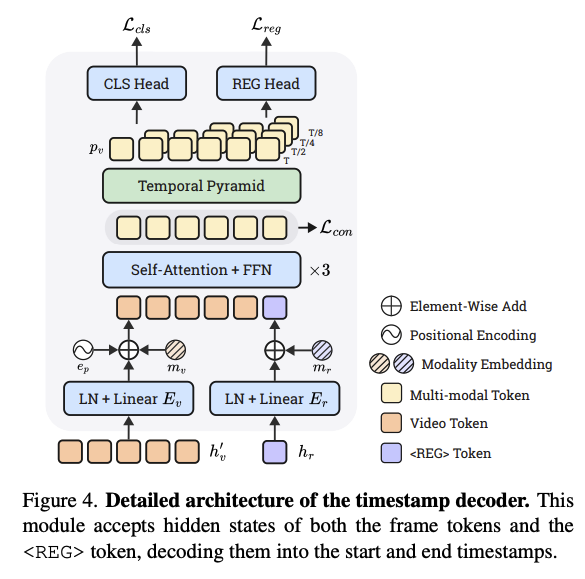
Timestamp Decoder
언어 모델링이나 특수 토큰을 통해 텍스트 형태의 타임 스탬프를 직접 예측하는 대신, LLM 위에 구축된 타임 스탬프 디코더 헤드를 개발했다. 타임 스탬프 디코딩 과정을 ㅌ용이하게 하기 위해 REG 라는 특수 토큰을 도입했다. 이 토큰이 생성되면, LLM 마지막 레이어의 REG 토큰 히든 상태와 모든 시각 토큰들이 타임스탬프 예측을 위해 디코더로 전송되어, 정규화된 시작 및 종료 타임스탬프를 나타내는 배열 즉 를 얻게된다.
Figure4.에서 보듯, 디코더는 시각 토큰의 히든 상태 를 와 REG 토큰의 히든 상태 를 입력으로 받는다.
여기서 은 각각 LLM의 다운샘플링된 프레임 수, 너비, 높이, 히든 차원이다.
- 시각 토큰 압축 : 크기의 커널과 스트라이드를 가진 1D 평균 풀링(Average Pooling)을 적용하여 시각 토큰을 프레임당 하나의 토큰으로 압축한다.
2.선형 투영: 와 은 두 개의 선형 레이어 와 에 의해 투영되어 히든 차원이 로 감소한다.
결과물인 와 은 각각 비디오 프레임과 질의에 대한 통합된 표현 역할을 한다다.
- 트랜스포머 인코딩: 정보의 효과적인 통합을 위해 학습 가능한 모달리티 임베딩을 더하고, 시퀀스 차원을 따라 연결한 후 트랜스포머로 인코딩한다.
- : 모달리티 지표 역할을 하는 무작위 초기화된 학습 가능 임베딩.
- : 시계열 인지 능력을 보존하기 위한 정규화된 사인파(Sinusoidal) 위치 인코딩.
Temporal Feature Pyramid
다양한 길이의 비디오와 구간에 대한 적응성을 높이기 위해, 를 네 단계의 다중 시계열 해상도를 가진 시계열 특징 피다미드로 매핑한다. 각 피라미드 레벨에 대해
Conv1D → LayerNorm → SiLU
블록을 가변적인 횟수로 적용하며, Conv1D는 커널 크기와 스트라이드 2를 사용하여 시퀸스를 1/2로 다운 샘플링한다.
네 단계는 각각 원본 시퀸스의 1, 1/2, 1/4, 1/8을 유지하며, 이를 (여기서 )로 표기한다.
예측 속도를 높이기 위해 모든 레벨의 시퀀스를 시계열 차원을 따라 (길이 )로 연결하여 병렬 예측이 가능하게 한다.
Training Objectives
연속적인 타임스탬프 모델링을 위해 두 개의 Dense Prediction Heads를 채택한다.
- Classification Head
-프레임 단위의 전경-배경을 분류한다. 2층 Conv1D 모듈과 Sigmoid 활성화 함수로 구성되며, 각 프레임이 대상 구간 내에 속하는지 나타내는 신뢰도 점수 를 출력합니다. Binary Focal Loss를 사용하여 최적화합니다.
()
-
Boundary Regression Head
-각 프레임에 대해 시계열 경계와의 1D오프셋 을 예측한다.
2층 컨볼루션 블록과 Exponential Function 활성화를 사용하며, L1 Loss로 지도 학습합니다.
() -
Contrastive Loss
-와 사이의 더 나은 정렬을 위해 추가적인 대조 손실을 통합한다. 모든 프레임-질의 쌍 간의 코사인 유사도 를 계산하고 양성 프레임(GT 경계 내)을 샘플링하여 최적화한다.
(: 인 프레임 인덱스, )
3.3 Verifier
Grounder가 제안한 시각적 구간들이 항상 정확하진 않다. 따라서 후보 구간들의 유효성을 평가하기 위해 Verifier 역할을 도입했다.
1. 작동 매커니즘 : Verifier는 Grounder가 생성한 각 후보 구간 를 입력으로 받는다. 모델은 해당 구간을 확대하여 더 높은 공간 해상도와 적절한 샘플링율로 시청한다.
2. 출력 : Verifier는 해당 구간의 Query와 일치하는지에 대해 YES 혹은 NO를 나타내는 Boolean 값을 출력하도록 학습되었다.
3. 데이터 생성 : 사전 학습된 Grounder의 예측 결과를 활용하여 Verifier 학습용 데이터를 구축한다. Grounder의 예측 중 Ground Truth와 IoU가 0.7 이상인 것은 YES , 0.3 미만인 것은 NO로 레이블링하여 모델이 미세한 차이를 식별하도록 훈련했다.
3.4 Answerer
Answerer는 Grounder가 사용되었을 때는 크롭된 비디오 구간을 기반으로, Planner가 직접적인 답변을 선택했을 때는 비디오 전체를 기반으로 주어진 질문에 답변하는 역할을 담당한다. 이역할의 목적은 LMM(여기서는 Qwen2-VL)의 목적과 엄밀하게 일치하기 때문에, 우리는 아키텍처 수정이나 별도의 파인튜닝 없이 사전 학습된 모델을 직접 채택해 사용한다.
모든 모듈은 동일한 백본 LMM 위에 구축되었으며, 추가적인 LoRA 어댑터와 경량 다임스탬프 디코더가 증가된 형태이다. 각 역할에 따라 서로 다른 LoRa 어댑터가 교체되며, 이를 통해 모델 아키텍처의 수정을 최소화, 각 역할에 특화된 능력을 끌어낸다.
IV. Experiments
4.1 Experimental settings
구현 세부 사항: Qwen2-VL-2B-Instruct와 Qwen2-VL-7B-Instruct를 기본 모델로 사용한다.
시각 인코더는 600MB 미만의 메모리를 사용하여 모든 비디오를 네이티브 동적 해상도로 처리한다.
학습과정은 다음 두 단계로 나뉘어진다.
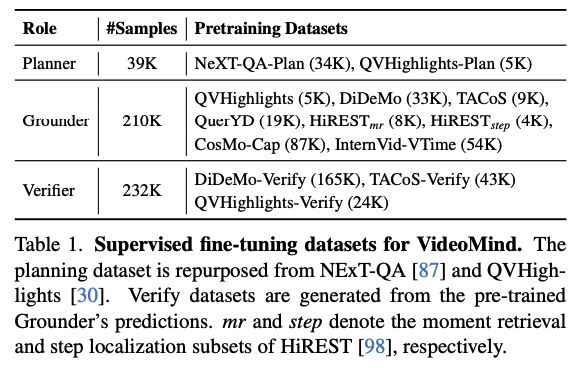
1. Pre-training : 각 역할에 대해 Table1에 나열된 데이터셋을 사용하여 모델을 학습시킨다. 이 단계에서 백본 LLM에 LoRA 어댑터를 도입하고 Grounder를 위한 타임스탬프 디코더를 최적화한다.
2. Instruction Fine-tuning: 사전 학습된 체크포인트를 바탕으로 통합된 SFT 데이터셋을 사용하여 전체 모델을 미세조정하며, 이때 각 역할에 해당하는 LoRA 어댑터가 활성화된다. 학습은 8개의 NVIDIA H100 GPU에서 수행되며, DeepSeed ZeRO-3 전략을 활용했다.
4.2 Grounded VideoQA
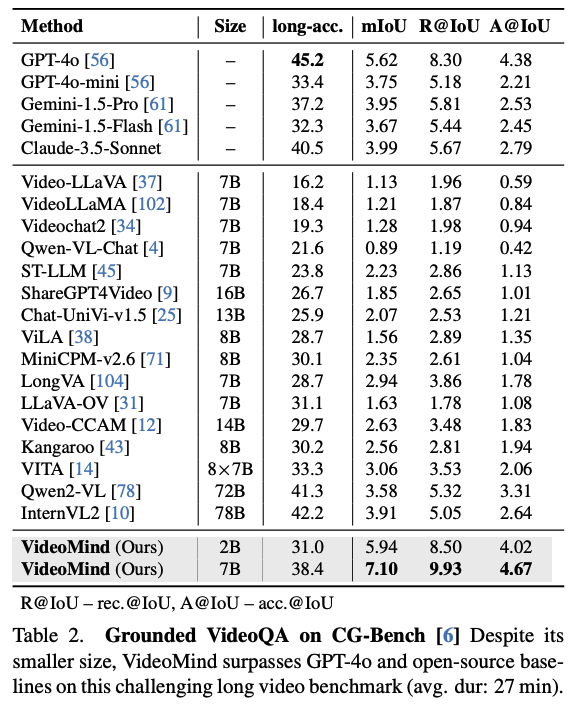
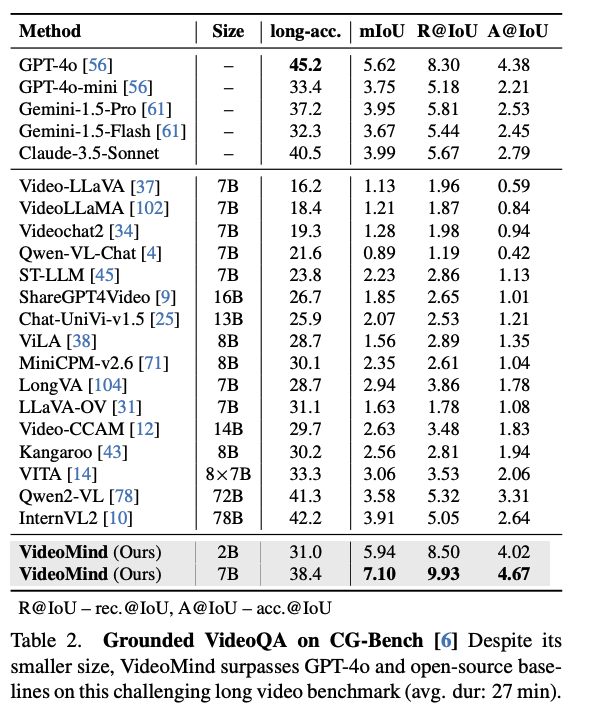
CG-Bench, RexTime,NExT-GQA 세 가지 주요 벤치마크에서 VideoMind의 성능을 평가했다. 이 과정에서 복잡한 추론뿐 아니라 Temporal Grounding을 동시에 요구한다.
-성능분석 : VideoMind는 모든 벤치마크에서 기존 SOTA 모델들을 일관되게 능가한다.
-긴 비디오 장점 : 특히 27분 이상의 긴 비디오를 포함하는 CG-Benc에서, 2B모델은 GPT-4o를 정확도 측면에서 유의미한 차이로 이기며, 이는 Chain-of-LoRA를 통한 단계별 추론 방식이 거대 모델의 단일 패스 추론보다 장편 비디오 이해에 더 효율적임을 증명한다.
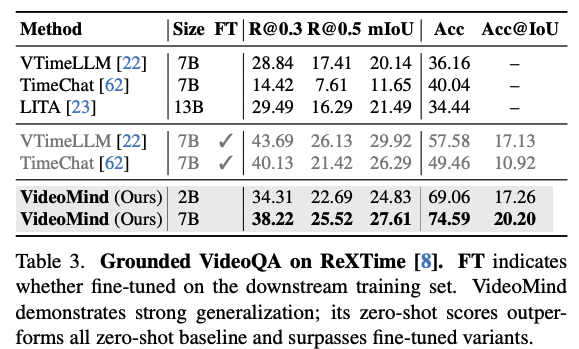
4.3 Video Temporal Grounding
VideoMind의 국소화 능력을 검증하기 위해 Charades-STA, ActivityNet-Captions, QVHighlights, TACoS, Ego4D-NLQ, ActivityNet-RTL 등 6개 데이터셋에서 실험을 수행했다.
평가지표 : 특정 IoU 임계값에서의 Recall@과 mAP 지표를 사용했다.
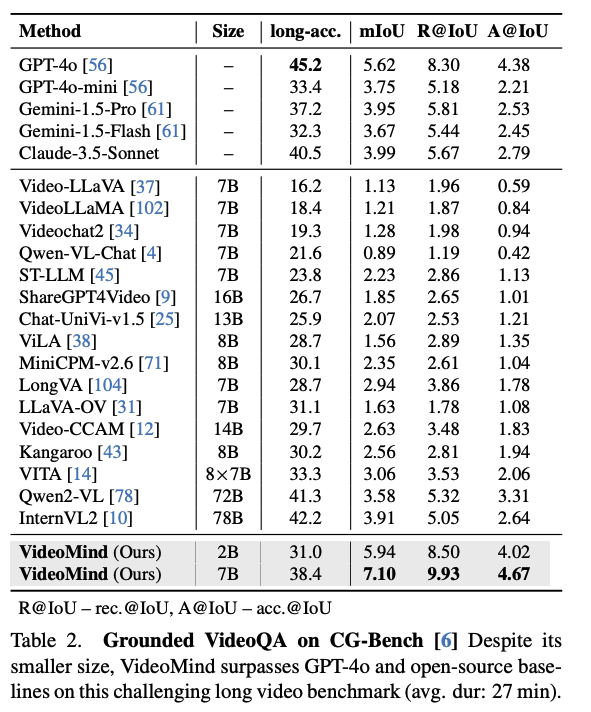
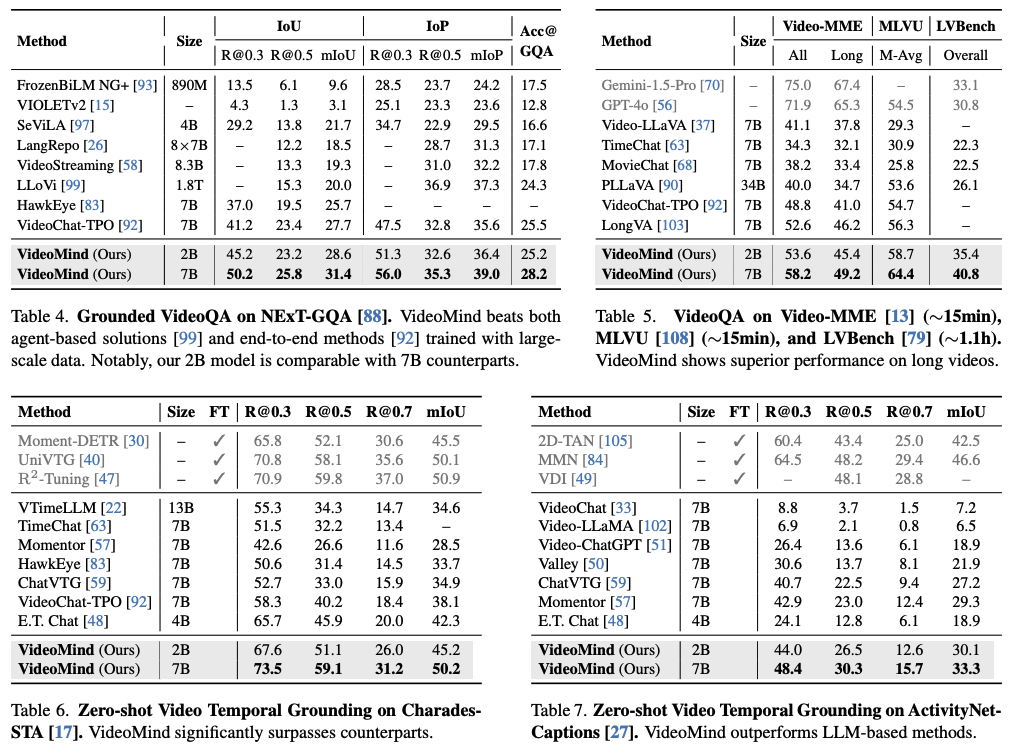
결과: VideoMind는 텍스트 질의에 대응하는 정확한 시간 구간을 찾아내는데 탁월한 성능을 보이며, 특히 복잡한 활동이 포함된 ActivityNet과 Ego4D 데이터셋에서 높은 강건성을 기록했다.
4.4 General VideoQA
국소화 정보 없이도 전체적인 비디오 이해 능력을 확인하기 위해 Video-MME, MLVU, LVBench, MVBench, LongVideoBench에서 평가를 진행했다.
결과: VideoMind는 Answerering-only에서도 기존의 강력한 LMM들과 대등하거나 그 이상의 성능을 보여주었으며, 이는 백본인 Qwen2-VL의 능력을 보존하면서도 에이전트 워크플로우를 성공적으로 통합함을 시사한다.
4.5 Ablation Studies
제안된 구성 요소들의 기여도 파악을 위해 여러 절제 실험을 수행한다.
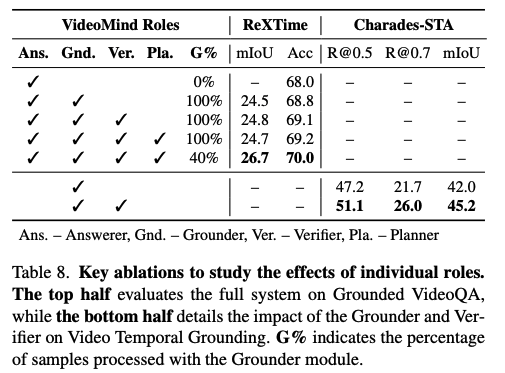
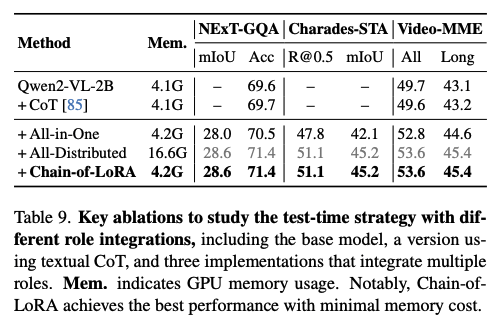
1. Chain-of-LoRA의 효과: 단일 모델로 모든 역할을 수행하는 것보다 역할별 LoRA 어댑터를 사용하는 것이 각 과업에서의 전문성을 높여 전체적인 정확도를 향상시켰다.
2. Verifier의 역할 : Verifier를 통해 후보 구간을 검증하고 재확인하는 과정이 시계열 국소화를 5%~10% 가량 향상시키는 것을 확인했다.
3. Inference-time Searching (MCTS) : MCTS 전략을 적용했을 때, 모델이 최적의 구간을 선택할 확률이 높아져 복잡한 질의에 대한 오답률이 유의미하게 감소했다.
V. Conclusion & Limitations
시계열 근거 기반의 비디오 추론을 위해 설계된 새오운 비디오-언어 에이전트인 VideoMind를 소개했다. Planner, Grounder, Verifier, Answerer로 구성된 에이전트 워크플로우를 채택하고 있으며, 이러한 역할들 사이를 효율적으로 전환하기 위해 Chain-of-LoRA 전략을 함께 사용한다.
Grounded VideoQA, VTG, 그리고 VideoQA에 걸치 광범위한 실험은 VideoMind의 효과와 중요성을 입증하고, 정밀하고 증거에 기반한 답변을 제공함으로 장편 비디오 추론에 탁월한 성과를 보인다.
본 모델이 개별 설계의 최적화와 학습 데이터 준비 측면에서 막대한 최적화를 필요로 한다는 점을 인정한다. 향후 멀티모달 비디오 에이전트 및 추론 분야의 발전에 영감을 줄 수 있기를 기대한다.
VI. 🎓 Under Graduated Student's Insight (Critical Thinking)
-
실제로 실시간(Real-time) 서비스에 적용할 때, LoRA 파라미터 스위칭에 걸리는 Latency가 전체 추론 속도에 미치는 영향은 무시할 수 있는 수준인가?
-
Grounder 성능에 대한 종속성 : 워크플로우가 Sequential하다. Grounder가 엉뚱하거나 잘못된 구간을 짚으면 이미 Verifier과 Answerer의 성능과 상관없이 오답을 찾을 가능성이 있다고 생각한다.
- Grounder가 후보 구간을 추출할 때의 Recall이 낮다면, Verifier의 검증 단계는 무의미해지지 않는가? 에이전트가 스스로 Grounding 실패를 감지하고 Planner로 되돌아가는 피드백 루프(Feedback Loop)가 부족해 보인다.
-
Training Data Curation : Verifier가 단순히 1 or 0으로 판단하는 사례로 구성된다는게 문제점이다. Grounder가 특정 유형의 비디오 야간이라던지, 잔상이 남는 영상이라던지에 취약하다면, Verifier 역시 해당 도메인의 오답 즉 0만 학습하게 되어 Generalization 성능이 떨어지 않을까?
-
실험에 대해서도 2가지 의문이 남는다.
첫번째는 Answerer의 Zero-Shot 성능이 과연 괜찮은가? Qwen2-VL을 그대로 사용하는 것으로 보인다. 다른 역할들은 LoRA로 최적화를 하는데 Answerer만은 튜닝하거나 최적화하지 않은 이유가 있을까?
두번째로는 MCTS의 효율성이 사실인가?에 대한 의문이다. MCTS는 일반적으로 많은 샘플링을 요구하는데 2B 모델로 GPT-4o를 이겼다고 하지만, 동일 시간에서 실험한다는 가정이라면 더 효율적일까? 정확도를 위해 연산량을 늘리고 시간을 엄청 쓴게 아닌가 하는 생각이 든다. -> 시간이 난다면 깃허브에서 코드를 돌려보는 것도 좋은 방법인 것 같다
