Doubly Linked List는 링크가 전노드를 가리키는 링크와 다음 노드를 카리키는 링크 두개가 있다.
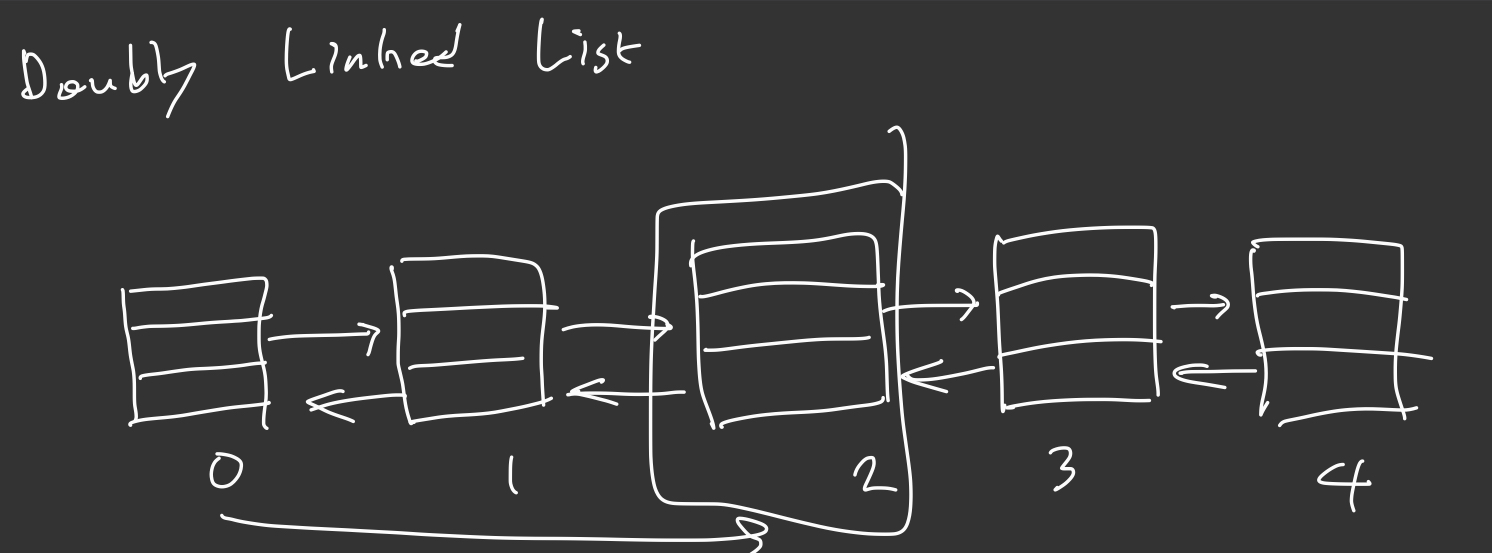
실제 자바에서의 LinkedList는 Doubly LinkedList와 같은 형식으로 구현되어 있다.
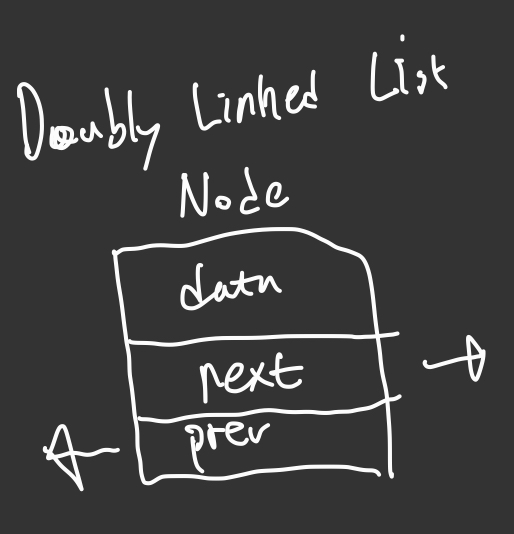
Node는 데이터와 다음 노드와 이전 노드를 가리키는 링크들로 구성되어 있다.
이렇게 양방향으로 연결된 리스트를 LinkedList 중에서 Doubly Linked List라고 한다.
이렇게 하면 Singly LinkedList보다 검색능력이
좋아진다.
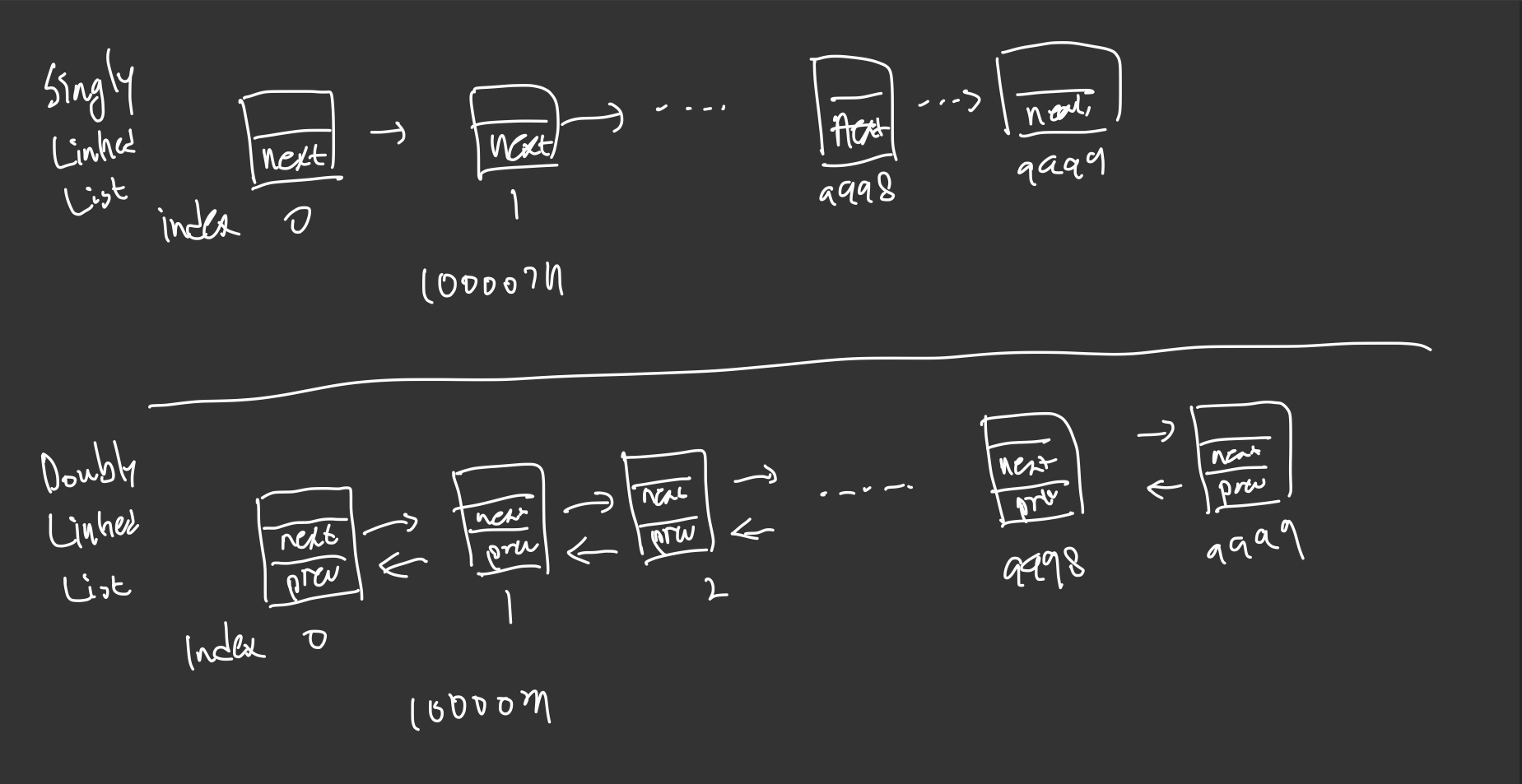
노드가 10000개 존재한다고 생각해보고 9998번 index에 위치한 요소를 찾고싶다.
Singly LinkedList는 head 즉 첫번째 요소부터 쭉 찾아가서 9998번 탐색을 할 것이다.
하지만 Doubly LinkedList는 tail(마지막 요소)에서 한번만 탐색하면 9998번 인덱스에 위치한 요소를 찾아낼 수 있다.
Doubly LinkedList는 Singly LinkedList보다 검색효율이 좋다고 말하는것이다.
Node 구현
public class Node<E> {
E data;
Node<E> next;
Node<E> prev;
public Node(E data) {
this.data = data;
this.next = null;
this.prev = null;
}
}data : 데이터가 들어간다
next : 다음 노드를 가리키는 링크
prev : 이전 노드를 가리키는 링크
Doubly LinkedList 구현
- 클래스 및 생성자 구성
- search 메소드 구현
- add 메소드 구현
- get, set, indexOf, contains 메소드 구현
- remove 메소드 구현
- size, isEmpty, clear 메소드 구현
클래스 및 생성자 구성
public class MyDLinkedList<E> implements List<E> {
private Node<E> head;
private Node<E> tail;
private int size;
public MyDLinkedList(){
head = null;
tail = null;
this.size = 0;
}head : 첫번째 노드를 가리킨다
tail : 마지막 노드를 가리킨다
size : 요소의 개수이다.
search 메소드 구현
private Node<E> search(int index){
if(index < 0 || index >= size){
throw new IndexOutOfBoundsException();
}
Node<E> x;
if( index + 1 < size/2 ){
x = head;
for(int i = 0; i < index; i++){
x = x.next;
}
}else { // index + 1 >= size/2 절반 이상에 있을경우
x = tail;
for(int i = size -1; i > index; i--){
x = x.prev;
}
}
return x;
}Singly LinkedList와 비교해보면 Singly LinkedList는 head부터 탐색하였지만
Doubly LinkedList는 노드의 위치에 따라 검색하는 방향이 달라진다. 개수의 절반을 기준으로 절반보다 작은 위치에 존재한다면 head부터 탐색하고 절반보다 큰 위치에 존재하면 tail부터 탐색한다.
검색효율이 좋은 이유이다!
add 메소드 구현
add 크게 3가지 종류가 있다.
첫번째 위치에 추가
중간 위치에 추가
마지막 위치에 추가
이 3종류를 기억하고 구현해보자.
addFirst
public void addFirst(E element){
Node<E> node = new Node<>(element);
// size 가 0인경우
if(size == 0){
head = tail = node;
size++;
return;
}
// size > 0 인경우
head.prev = node;
node.next = head;
head = node;
size++;
}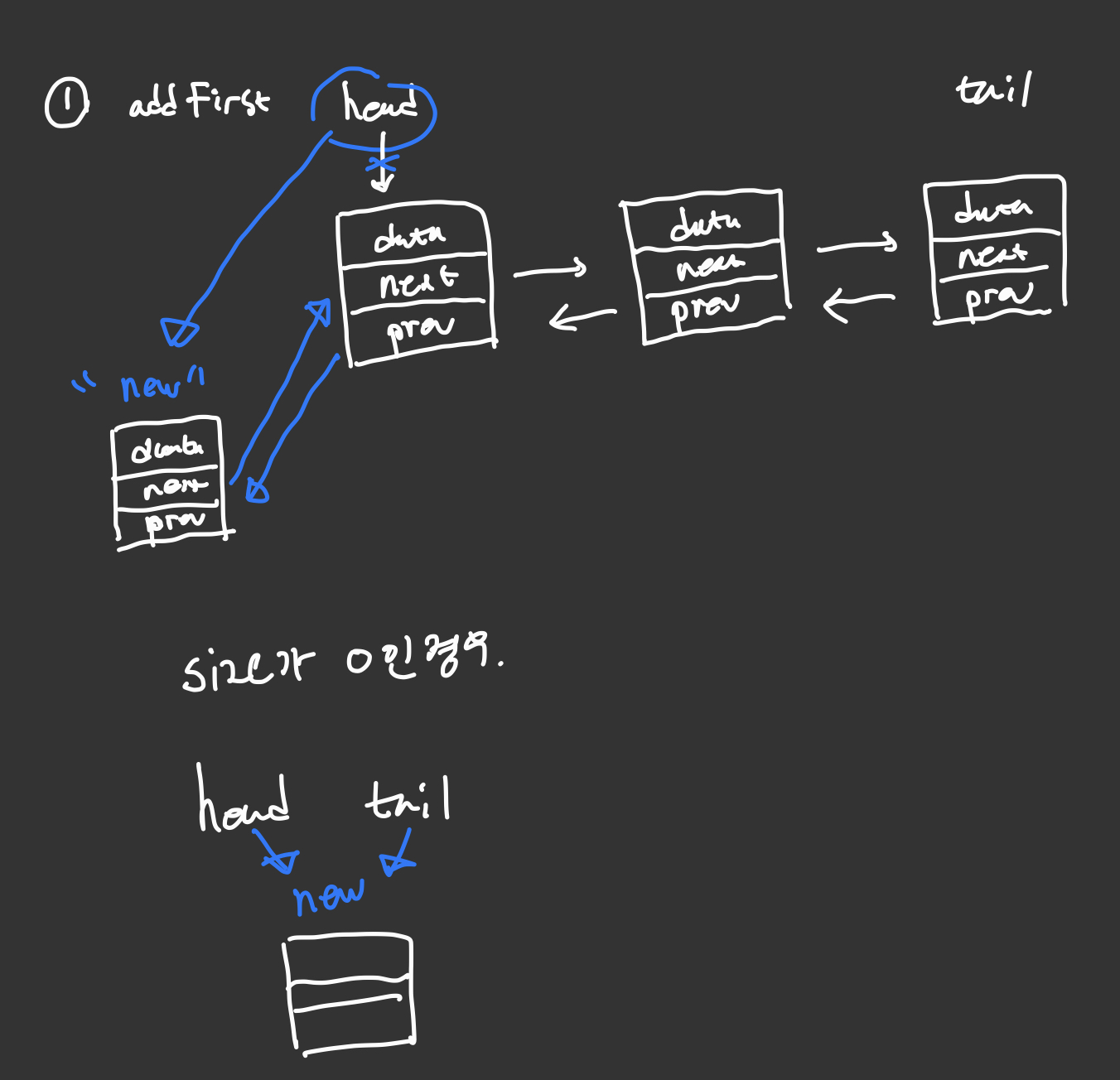
첫번째 위치에 넣을경우는 head의 prev를 새로운 노드를 가리키게 만들고 새로운 노드의 next를 head를 가리키게 하고 head를 새로운 노드로 옮겨주면 끝난다.
addLast
public void addLast(E element){
Node<E> node = new Node<>(element);
// size 가 0인경우
if(size == 0){
addFirst(element);
}
// size > 0 인경우
node.prev = tail;
tail.next = node;
tail = node;
size++;
}
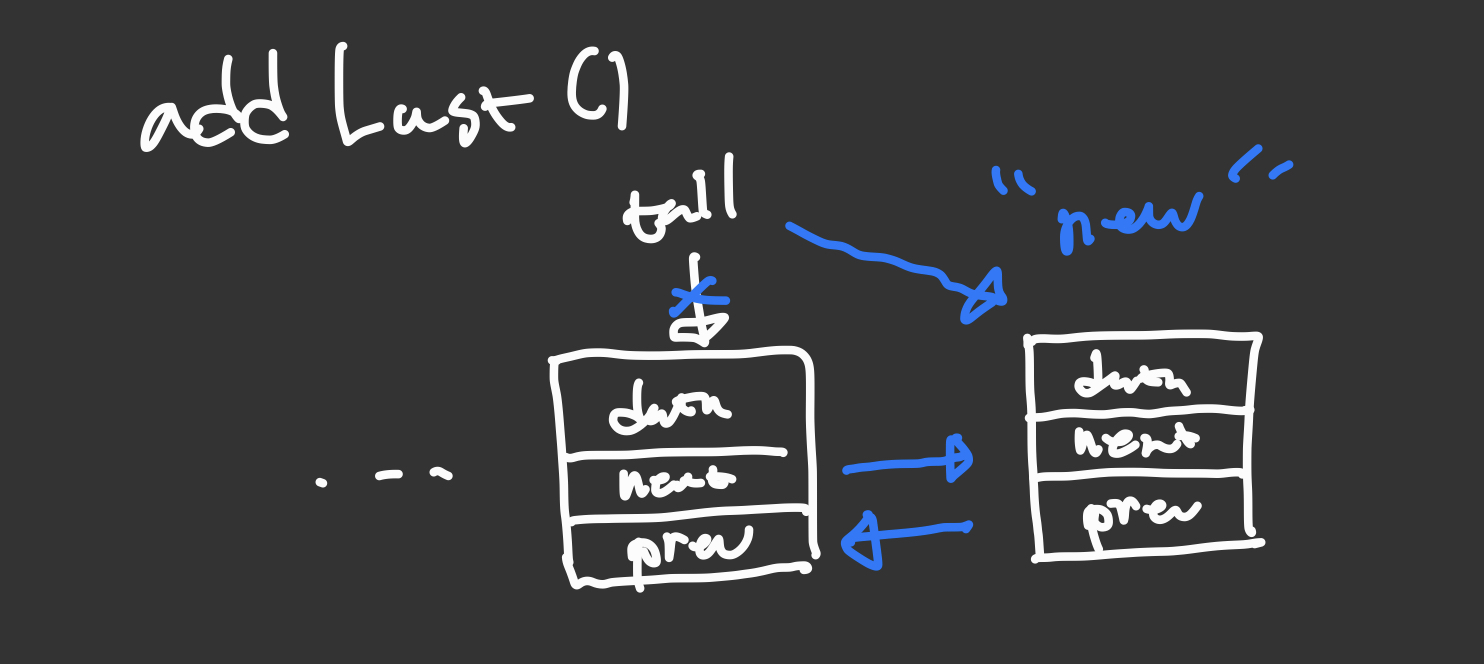
tail의 next를 새로운 노드를 가리키게 하고 새로운 노드의 prev를 tail을 가리키게 한 후 tail을 새로운 노드로 바꿔주면 된다.
add 중간에 추가
@Override
public void add(int index, E element) {
if(index < 0 || index > size){
throw new IndexOutOfBoundsException();
}
// 처음에 넣는거
if(index == 0){
addFirst(element);
return;
}
// 마지막에 넣는거
if(index == size){
addLast(element);
return;
}
Node<E> node = new Node<>(element);
// 중간에 추가하는것
Node<E> search = search(index - 1);
node.next = search.next;
search.next = node;
node.next.prev = node;
node.prev = search;
size++;
} 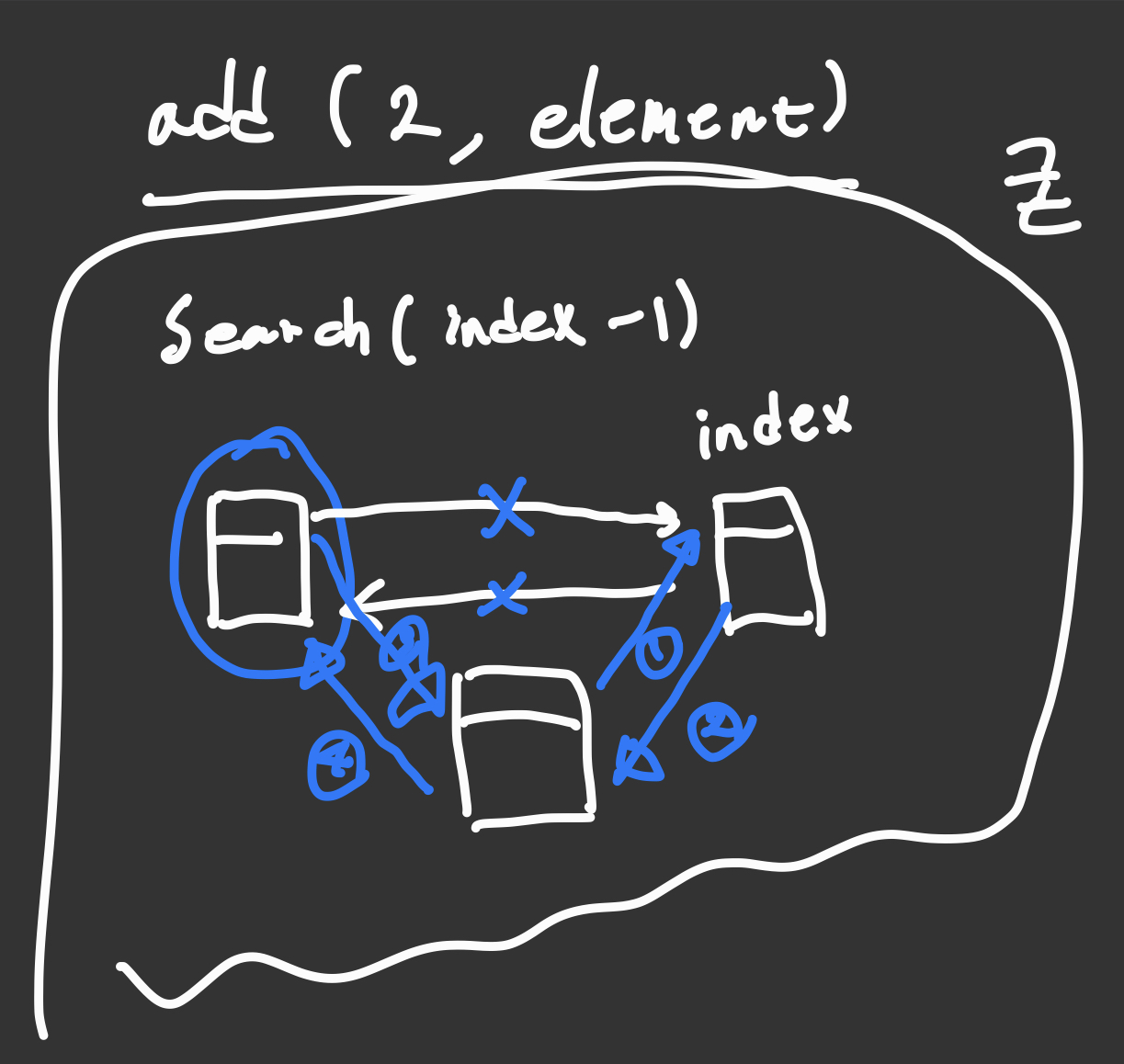
2번 index에 요소를 추가하고싶다면 1번째 요소뒤에 추가해주면 된다. 그림에 나온대로 링크가 끊어지지 않게끔 연결해주면 끝난다.
get, set, indexOf, contains 메소드 구현
@Override
public E get(int index) {
return search(index).data;
}
@Override
public E set(int index, E value) {
E data = search(index).data;
search(index).data = value;
return data;
}
@Override
public boolean contains(Object value) {
return indexOf(value) >= 0;
}
@Override
public int indexOf(Object o) {
Node<E> x = head;
int index = 0;
for(int i = 0; x != null; x = x.next){
if(o.equals(x.data)){
return index;
}
index ++;
}
return -1;
}천천히 읽어보면 답이나온다!
remove 메소드 구현
remove도 3가지로 나눠보겠다
가장 앞의 요소 삭제 - remove()
특정 인덱스의 요소 삭제 - remove(int index)
특정 요소 삭제 - remove(Object value)
가장 앞의 요소 삭제 - remove()

자바 공식문서를 보면 remove()는 리스트는 첫번째 요소를 삭제한다고 나와있다.
public E remove(){
if(head == null){
throw new NoSuchElementException();
}
Node<E> removed = head;
E data = removed.data;
Node<E> next_node = head.next;
head.next = null;
head.data = null;
// 다음 노드가 있을경우
if(next_node != null){
next_node.prev = null;
}
// next_node가 null이면 head = null 이 들어간다.
head = next_node;
size --;
//
if(size == 0){
tail = null;
}
return data;
}remove는 첫번째 요소를 삭제한다. 신경써야할 부분은 head의 다음 노드이다. 요소가 2개 이상 있다고 가정하자(next_node가 존재). head의 다음 노드를 next_node로 잡고 next_node.prev = null을 넣는다 즉 next_node와 첫번째 요소의 연결을 끊는다. 그 후 head에 있는 next_node와의 연결을 끊은 후 head 를 next_node로 옮기면 된다.
remove의 첫번째 부분으로 돌아가서 요소가 하나밖에 없어서 next_node가 null이라면 NullPointException이 발생할 것이다. 이것을 막기위해 next_node가 null이 아닐때만 next_node.prev에 null을 넣는다.
요소가 하나밖에 없을경우에는 head = null이 들어간다.
마지막으로 체크할 부분은 size가 0일 때 이다. 요소가 하나도 없다면 tail은 아직 삭제된 노드를 가리키고 있다. 그래서 tail에도 null을 넣어준다.
특정 인덱스의 요소 삭제 - remove(int index)
@Override
public E remove(int index) {
if(index < 0 || index >= size){
throw new IndexOutOfBoundsException();
}
//처음 삭제
if(index == 0){
return remove();
}
//마지막 삭제
if(index == size - 1){
Node<E> removed = tail;
tail = tail.prev;
removed.prev = null;
removed.next = null;
tail.next = null;
size--;
return removed.data;
}
// 중간 삭제
Node<E> search = search(index - 1);
Node<E> removed = search.next;
search.next = removed.next;
search.next.prev = search;
size--;
return removed.data;
}세개로 나누어 보았다. 첫번째 요소 삭제, 중간 요소 삭제, 마지막 요소삭제 이다.
index가 0이라면 첫번째 요소 삭제이다. 그건 remove()로 구현해두었으니 함수를 부른다.
index가 size-1이라면 마지막 요소를 삭제이니 tail을 이용하여 삭제해준다.
그리고 중간노드 삭제는 삭제할 노드의 이전노드를 찾아내어 링크들을 끊어버린다.
size, isEmpty, clear 메소드 구현
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
return size == 0;
}
@Override
public void clear() {
head = tail = null;
size = 0;
}