요즘엔 당연히 사용하는 방법론들의 시초격인 논문인 것 같다. 2012년도에 출간되어, 지금 기술력으로 보면 단순해 보이지만 중요한 것 같아 첫 리뷰 대상으로 정했다.
Introduction & ImageNet Dataset
- LabelMe, ImageNet 와 같은 큰 이미지 데이터 셋의 등장 → 현실적인 환경에서의 image classification
- CNN: compensation for data don't have
- 크기 조절 가능: depth & breadth
- 학습 용이: fewer parameter & connections
- 용량큼 → GPU로
- image → 규격 제각각 256 정사각형으로 맞춤
- 256 x 256 with 3 channels(RGB)
- centered each pixel(평균 빼기)
The Architecture
-
ReLU Nonlinearity
- 기존 방식: tanh 또는 sigmoid → 느리고 saturation 문제(특정값으로 수렴, 이를 막기 위해 normalization 필요)
- ReLU(rectified linear units): → much faster in big models, normalization 필요없음
-
Training on Multiple GPUs
- 3GB GPUs → 모델과 데이터 다 안들어감 (2개로 나눠서)
- 특정 layer에서만 결과 값 공유, 사실상 parallel 한 2 model
-
Local Response Normalization
-
Generalization에 도움
-
: the activity of a neuron computed by applying -th kernel at position
-
: response normalized activity
-
lateral inhibition → 번째 주변 개의 채널을 돌면서 더하고 그 값으로 나눈다. 주위 값 눈치를 보는 셈이 된다. 실제 뉴런도 비슷한 방식으로 작동한다.
-
-
Overlapping Pooling
- Pooling layers → summerize outputs of neighboring groups of neurons in the same channel. 원래는 안 겹치게 하는게 원칙이지만, 여기선 크기 과 stride 로 pooling하여 한 칸씩 겹치게 한다.
- overfitting을 어느정도 방지한다고 예측
-
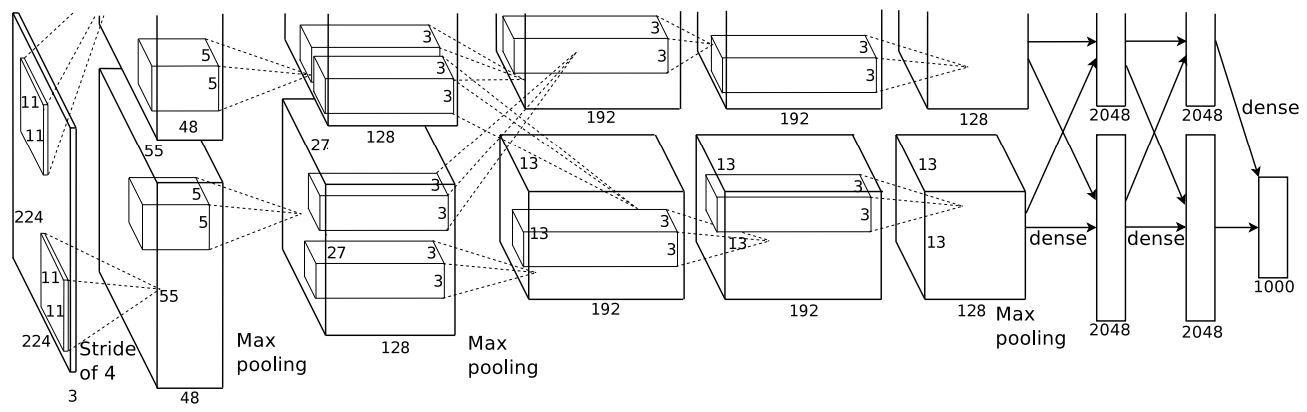
Overall Architecture
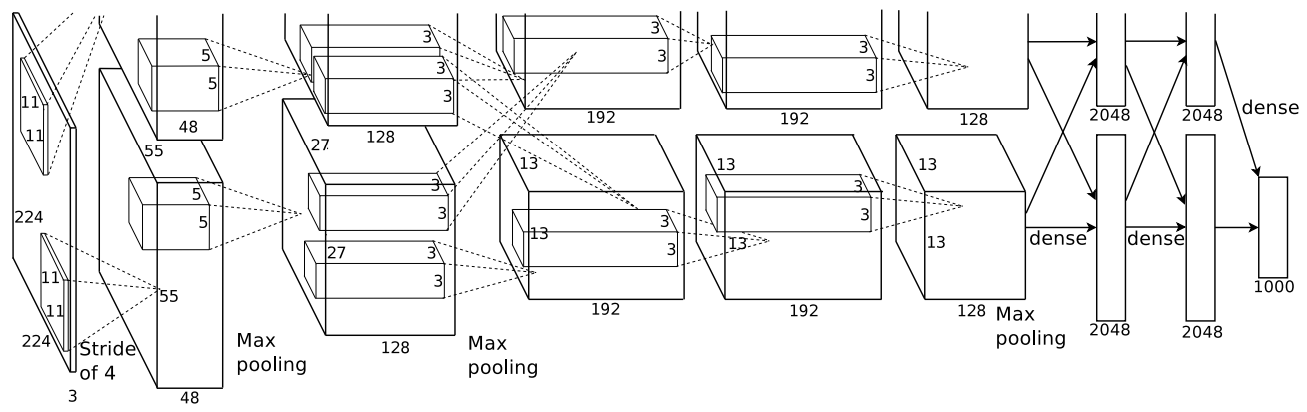
- 두 GPU에서 나눠서 모델 분포하고, 5 convolutional + 3 fully-connected + 1000-way softmax(1000 classes)로 이루어져 있다. multinomial logistic regression이 목표
- 2nd, 4th, 5th convolutional layer는 각자 GPU에서 수행한다.
- 3rd는 모든 GPU의 2번째와 연결된다.
- Response-normalization layer는 1st, 2nd conv 뒤에 온다.
- Max-pooling layer는 Response-normalization layer 뒤와 5th conv 뒤에 온다.
- 모든 conv와 fc 마지막 출력값은 ReLU를 거친다.
Reducing Overfitting
- Data Augmentation (1)
- GPU가 학습하는 동안 CPU가 이미지 가공해서 모델에 먹인다.
- 256 x 256 이미지에서 랜덤으로 224 x 224이미지를 뽑아서 데이터 추가, 그 이미지들의 상하 반전 이미지들도 추가
- 추론 시에도 주어진 이미지에서 각 모서리와 중앙에서 5개의 패치를 뽑고, 상하 반전을 시켜서 나온 10개의 결과값을 평균내서 한다.
- Data Augmentation (2)
- RGB값 조작: PCA를 찾아서 해당하는 eigenvalue()와 가우시안 분포 에서 뽑은 값()을 곱한 후 원래 이미지에 더한다.
이미지 픽셀 마다 을 더해준다. 와 는 각각 RGB채널 사이 covriance 행렬의 번째 eigenvector와 eigenvalue이다.
- RGB값 조작: PCA를 찾아서 해당하는 eigenvalue()와 가우시안 분포 에서 뽑은 값()을 곱한 후 원래 이미지에 더한다.
- Dropout
- 50프로의 확률로 hidden neuron의 출력값을 0으로 바꿔준다.
- 0으로 바뀐 뉴런은 forward pass와 backpropagation에 참여하지 않으므로, 여러 모델을 학습시켜 앙상블하는 것과 비슷한 효과를 기대한다.
- more robust features
- 첫번째와 두번째 fc 층에서 수행
Codes
-작성중-

🥔