
들어가며
이전 글에서는 스프링의 3대 요소에 대해 알아보았다. 이번 글에서는 스프링이 동작하는 원리에 관한 내용을 알아보고자 한다.
스프링의 동작원리
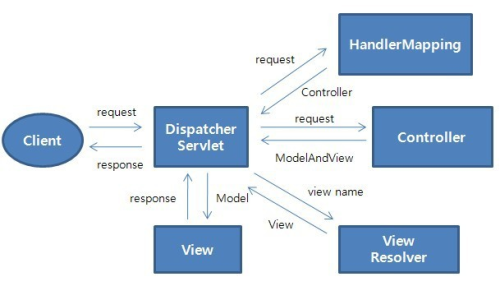
각각의 역할은 다음과 같다.
- Dispatcher Servlet
- 클라이언트에서 들어오는 모든 요청을 받는 곳
- 요청을 적절한
Controller에 전달하고 결과값을View에 전달하는 흐름을 제어한다
- Handler Mapping
- 요청을 실제로 어떤
Controller가 처리를 하는지 찾는 역할을 한다
- Controller
HttpMethod에 따라 요청을 적절히 수행한 후 결과를Dispatcher Servlet에 돌려준다
- ModelAndView
Controller가 처리한 데이터와 결과를 보여줄View를 가지고 있는 객체이다.
- View Resolver
- 실제
View를 찾아주는 역할
- View
Controller가 처리한 데이터를 보여주는 역할
Dispatcher Servlet이 클라이언트의 요청을 받으면, 이 요청을 처리해줄 적절한Controller를 찾기 위해 스프링 컨테이너에 접근한다.- 스프링 컨테이너는
Controller와 연관된Service,Repository등의 빈들을 관리하고 있으며, 필요한 빈을Controller에 주입한다. 이를 통해Controller는 요청을 처리하는 로직을 실행하고 결과를 반환한다.Controller가 반환한 모델 데이터는 다시Dispatcher Servlet에게 전달되고,Dispatcher Servlet는 이를View Resolver에게 넘겨준다.View Resolver는 반환된 뷰 이름을 기반으로 실제 뷰를 찾아, 모델 데이터를 해당 뷰에 전달한다. 이 뷰 객체 역시 스프링 컨테이너에서 관리된다.- 마지막으로, 뷰는 전달받은 모델 데이터를 사용하여 최종적인 결과를 생성하고 클라이언트에 응답을 보낸다.
즉, 스프링에서의 요청 처리 과정은 스프링 컨테이너 내에서 관리되는 빈들을 통해 이루어지며, 이 과정에서 IoC와 DI라는 스프링의 핵심 개념이 적용된다.
원리를 설명하며 스프링 컨테이너가 굉장히 자주 등장하였는데, 종종 들었던 이것은 무엇일까?
스프링 컨테이너
설명하기에 앞서, 스프링은 앞선 글을 통해 스프링의 정의, 특징에 대해서는 알고있다. 그렇다면 컨테이너가 무엇인지 짚고 넘어가자.
구글에서는 컨테이너를 다음과 같이 정의한다.
컨테이너는 어떤 환경에서나 실행하기 위해 필요한 모든 요소를 포함하는 소프트웨어 패키지
나는 스프링에 이걸 접목하여 스프링 컨테이너는 스프링이 동작하는데 필요한 모든 요소를 갖고 있는 일종의 패키지라고 이해했다.
다만, 이렇게 정의하기엔 모호한 요소(모든 요소?)들이 많아 여러 블로그와 강의들을 찾아보며 내린 결론은 다음과 같다.
스프링 컨테이너는 스프링 내 빈(객체)들의 생명주기를 관리하는 스프링의 핵심이다.

좋아 완벽하게 이해했다! 그런데, 왜 스프링 컨테이너를 쓸까? 객체의 생명주기를 관리해주니 편해서라고 하기엔 조금 납득이 가지 않았다. 단순히 편리함만을 위해? 편리함만을 추구하기엔 코드를 작성하면 편리함을 포기해야될 경우가 종종 있었다.
그래서 스프링 컨테이너를 사용하는 명확한 이유를 찾아봤다.
스프링 컨테이너를 사용하는 이유
우리가 일반적으로 프로그래밍을 할 때는 new 키워드를 사용해서 필요한 객체를 직접 생성한다. 이렇게 되면 프로그램 전체에 걸쳐 수많은 객체들이 생겨나고, 이 객체들은 서로를 직접 참조하게 된다.
그런데 이렇게 객체가 다른 객체를 직접 참조하게 되면, 그 사이에 의존성이 생기게 된다. 즉, 하나의 객체가 바뀌면 그것을 참조하는 다른 객체도 영향을 받게 되는 것이다. 이런 의존성이 많아지면 객체 간의 결합도가 높아져서 코드를 변경하거나 확장하는 것이 어렵게 된다.
이런 문제를 해결하기 위해 스프링은 스프링 컨테이너라는 것을 도입했다. 스프링 컨테이너는 필요한 객체를 대신 생성해주고, 그 사이의 의존성도 대신 관리해준다. 이를 통해 개발자는 직접 객체를 생성하거나 관리하는 대신 비즈니스 로직에 집중할 수 있게 된다.
또한, 스프링 컨테이너를 통해 의존성 주입이라는 기법을 사용하면, 객체는 더 이상 구체적인 클래스에 의존하지 않고 인터페이스에만 의존하게 된다. 이렇게 되면 코드의 결합도를 더욱 낮추고 캡슐화를 높일 수 있게 되는 것이다.
아하! 결국 스프링 컨테이너는 객체를 대신 생성하고 관리하고 의존성 주입을 통해 코드의 결합도를 낮추고 캡슐화를 높이는 이상적인 객체지향 프로그래밍을 도와주는 것이구나 라고 이해했다.
스프링 빈 (Bean)
빈은 스프링 컨테이너에 의해 관리되는 자바 객체를 의미한다.
스프링을 설명할 때, 자주 등장하는 단어인데 스프링 컨테이너에 등록된 객체를 빈이라고 이해하면 된다.
스프링 빈은 기본적으로 싱글톤 범위를 가지며, 이는 스프링 컨테이너에 의해 하나의 인스턴스만 생성되고 관리된다는 것을 의미한다. 즉, 같은 빈을 요청하면 항상 같은 인스턴스를 반환받게 된다.
싱글톤의 문제점
-
구현을 위한 코드가 많음
-
동시성 이슈
-
의존 관계상 클라이언트가 구체 클래스에 의존하는 형태 (= SOLID 중 DIP 위반)
등의 이유를 가져 단점이 꽤 치명적인데 스프링은 빈을 왜 싱글톤으로 관리할까?
💡 스프링 컨테이너
스프링 컨테이너가 바로 이 문제를 해결해준다.
1. 싱글톤 패턴을 적용하지 않아도, 객체를 싱글톤으로 관리한다.
2. 스프링 컨테이너는 요청이 들어올 때마다 새로운 스레드를 생성하고, 각 스레드는 독립적으로 처리된다. 이때 각 스레드는 싱글톤 빈의 동일한 인스턴스를 참조하지만, 싱글톤 빈의 상태를 변경하지 않는다.
이렇게 스프링 컨테이너가 싱글톤 빈의 생명주기와 동시성을 관리하므로, 우리가 싱글톤의 단점에 대한 처리를 하지 않았음에도 각 요청이 독립적으로 처리되는 이유가 바로 이것이다.
스프링 컨테이너의 종류
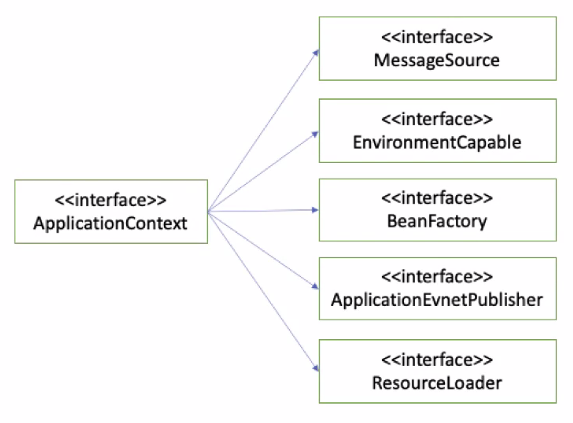
스프링 컨테이너는 크게 두 종류로 나눌 수 있는데, BeanFactory와 ApplicationContext가 대표적인 스프링 컨테이너이다. 위 그림의 인터페이스를 하나씩 살펴보면 다음과 같다.
MessageSource: 국제화 기능(다국어 메시지 처리 기능)을 제공한다.
EnvironmentCapable: 로컬환경, 개발환경, 운영환경 등을 구분하여 처리할 수 있게 해주는 환경변수와 같은 기능들을 제공한다.
BeanFactory: 스프링 빈을 관리하고 조회하는 역할을 담당한다.
ApplicationEventPublisher: 이벤트 기반의 프로그래밍을 할 때 필요한 기능을 제공한다.
ResourceLoader: 파일, 클래스패스 등 외부에서 리소스를 편리하게 조회할 수 있는 기능을 제공한다.
BeanFactory가 스프링 컨테이너의 최상위 인터페이스지만 ApplicationContext는 상속을 통해 BeanFactory의 기능을 가지면서 다른 추가적인 기능을 사용할 수 있기 때문에 대부분의 경우 ApplicationContext를 사용한다.
스프링 컨테이너의 생성과정
@Configuration
public class AppConfig {
@Bean
public SomeService someService() {
return new SomeServiceImpl();
}
}ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);-
new AnnotationConfigApplicationContext(구성정보.class)로 생성자를 호출하여 스프링 컨테이너를 생성한다. -
생성할 때 어떤 구성정보를 쓸 것인지 인자값으로 지정하는데,
AppConfig.class같은 구성정보를 전달하면 된다.
위의 과정을 거치면 스프링 컨테이너에는 다음과 같이 빈이 적재된다.
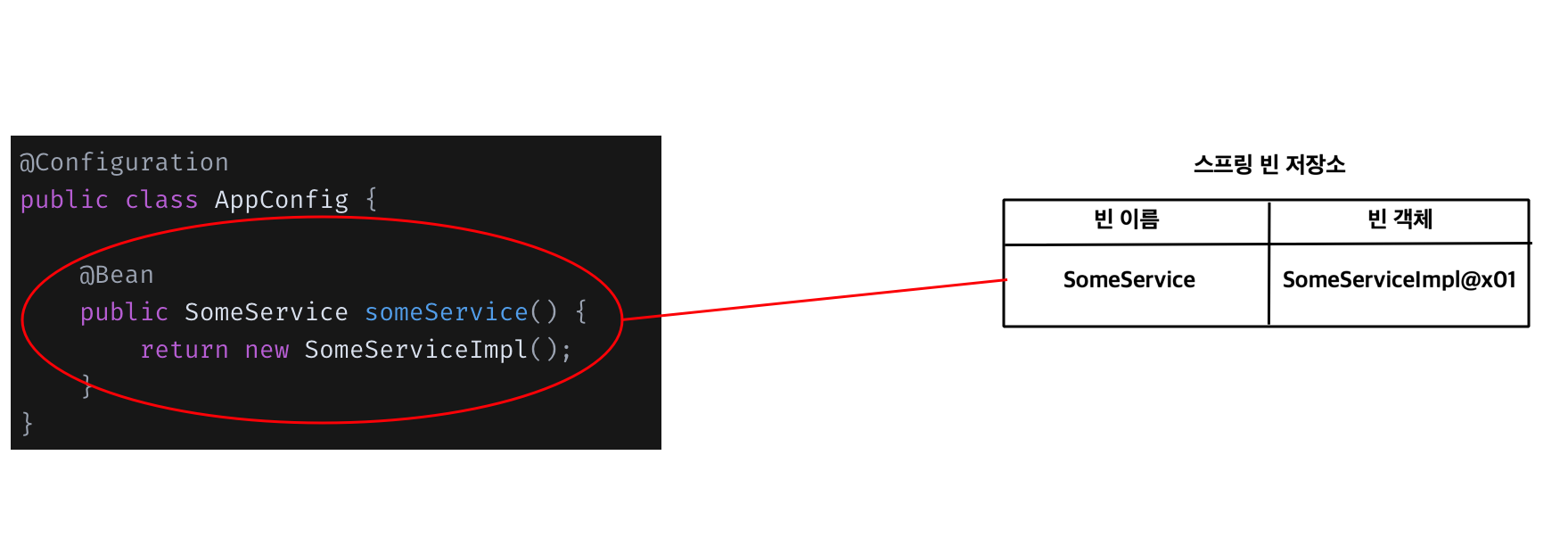
빈 이름은 기본적으로 빈으로 적재된 메소드명을 따라가는데 어노테이션의 설정을 통해 변경할 수 있다.
또한, 어노테이션 기반의 자바 설정 클래스를 이용한다면 스프링 컨테이너에서 알아서 스프링 빈을 등록하고 의존관계를 주입한다.
빈을 등록할 때 빈 이름은 중복되면 안된다. 빈 이름이 중복될 경우 다른 빈이 무시되거나 기존 빈을 덮어버리는 등의 에러가 발생할 수 있기 때문이다.
어노테이션? (Annotation)
우리는 앞선 과정을 통해 스프링 컨테이너는 객체를 빈으로 대신 관리하여 객체 지향의 원칙을 준수하고, 개발자로 하여금 비즈니스 로직에 집중하게 만들어준다는 것을 알게되었다.
빈으로 등록하는 어노테이션은 흔히 사용하는 Cotroller, Service, Repository가 있는데 이것들은 어떤 것인지 제대로 알아보도록 하자.
정의
위키 백과에서는 어노테이션을 다음과 같이 정의한다.
자바 소스 코드에 추가하여 사용할 수 있는 메타데이터의 일종이다. 보통 @ 기호를 앞에 붙여서 사용한다. JDK 1.5 버전 이상에서 사용 가능하다. 자바 애너테이션은 클래스 파일에 임베디드되어 컴파일러에 의해 생성된 후 자바 가상머신에 포함되어 작동한다.
어노테이션은 스프링 내의 기능이 아닌, 엄연한 자바의 기능이다. 어노테이션을 통해 개발자는 작성해야 할 코드의 수가 대폭 줄어들어 유지보수가 쉬워진다. 따라서, 개발자로 하여금 보다 높은 생산성을 제공해준다.
스프링 어노테이션의 종류
어노테이션은 클래스나 메소드에 부가적인 기능을 제공해준다. 이번 글에서는 많은 어노테이션 중 스프링에서 대표적으로 사용되는 어노테이션을 알아보자.
@Bean
@Configuration
public class AppConfig {
@Bean
public SomeService someService() {
return new SomeServiceImpl();
}
}@Bean 어노테이션을 사용하면 해당 메소드를 자동으로 스프링이 빈으로 등록해준다. 사용방법은 메소드 위에 @Bean를 붙이면 된다.
@Component
@Component는 개발자가 생성한 클래스를 스프링 빈으로 등록할 때 사용하는 어노테이션이다.
@Component
public class Book {
public Book() {
System.out.println("Hi!");
}
}빈과 마찬가지로 @Component를 붙이면 스프링이 자동으로 빈으로 등록해준다.
💡 Bean과 Component의 차이점
1. 기본적으로 사용하는 위치가 다르다. 빈은 메소드 레벨에서 사용되고 컴포넌트는 클래스 레벨에서 사용된다. 이는 빈과 컴노넌트 어노테이션 내부의@Target에서 확인할 수 있다.
2. 빈의 경우 개발자가 컨트롤이 불가능한 외부 라이브러리들을 빈으로 등록하고싶은 경우에 사용된다. 컴포넌트의 경우 빈과는 반대로 개발자가 직접 컨트롤할 수 있는 클래스에 사용한다.
@ComponentScan
@ComponentScan는 기본적으로는 @Component가 적용된 클래스가 있다면 해당 클래스를 스프링 컨텍스트에 빈으로 등록하는 역할을 해준다.
@Configuration, @RestController, @Controller, @Service, @Repository와 같은 어노테이션이 적용된 클래스도 @ComponentScan이 적용되어 빈으로 등록된다.
이는 각 어노테이션이 내부에
@Component를 포함하고 있기 때문이다.
@Configuration
@Configuration은 스프링 컨테이너에게 스프링 빈을 구성할 설정 클래스다 라고 알려주는 어노테이션이다.
@Configuration
public class AppConfig {
@Bean
public SomeService someService() {
return new SomeServiceImpl();
}
}앞서 작성했던 AppConfig 클래스와 같이 설정 클래스로 사용할 클래스에 @Configuration을 붙이면 된다.
@SpringBootApplication
스프링 부트를 통해 어플리케이션을 생성하면 바로 볼 수 있는 어노테이션이다.
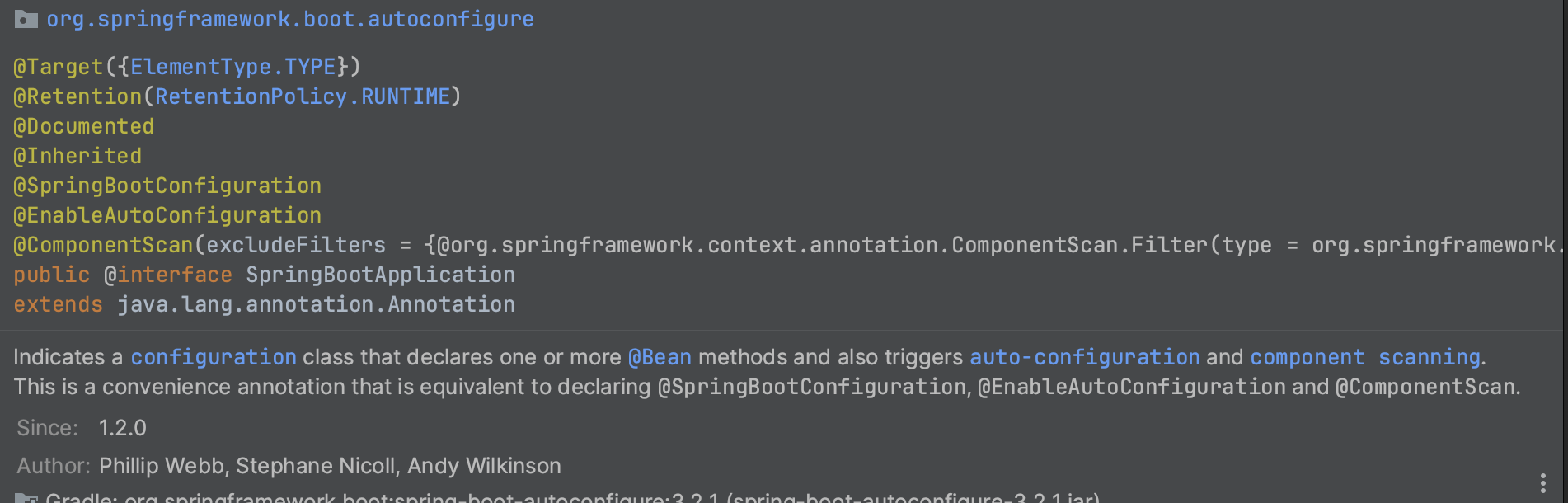
스프링 부트의 가장 기본적인 설정을 선언해주는 어노테이션으로 @EnableAutoConfiguration, @ComponentScan 어노테이션을 포함하고 있다.
@Controller
@Controller는 Spring MVC 구조에서 컨트롤러로 사용할 수 있도록 해주는 어노테이션이다.
해당 어노테이션이 적용된 클래스 내부의 메소드 반환타입이 String 이라면 그것은 JSP 파일명을 의미한다.
@RestController
@RestController는 Rest API 형태의 컨트롤러 클래스를 작성할 때 사용하는 어노테이션이다.
해당 어노테이션은 @ResponseBody을 포함하고 있어 요청의 결과를 JSON 형태로 반환해준다.
💡 @Controller와 @RestController의 차이점
JSON 형태로 응답해야 하는 Rest API 구조에서 많이 사용되는 것이@RestController이다.@Controller는 요청의 응답을JSP와 같은 View에 전달해야될 경우 많이 사용된다.
@Service
@Service는 비즈니스 로직을 수행하는 클래스임을 명시하는 어노테이션이다.
이 비지니스 로직이라는게 참 애매한데, @Service 내부에 주석으로 그와 관련하여 작성된 부분이 존재한다.
Indicates that an annotated class is a "Service", originally defined by Domain-Driven Design (Evans, 2003) as "an operation offered as an interface that stands alone in the model, with no encapsulated state."
May also indicate that a class is a "Business Service Facade" (in the Core J2EE patterns sense), or something similar. This annotation is a general-purpose stereotype and individual teams may narrow their semantics and use as appropriate.
This annotation serves as a specialization of @Component, allowing for implementation classes to be autodetected through classpath scanning.
이를 해석하면, Domain-Driven Design에서 정의한 Service를 나타낸다. Service는 모델에서 독립적으로 제공되는 인터페이스를 의미한다. 즉, 이는 특정한 상태를 감싸지 않는 연산을 의미한다.

특정한 상태를 감싸지 않는 연산..? 표현이 너무 애매하다. 예시와 함께 알아보자.
특정한 상태를 감싸지 않는 연산이라는 표현은 서비스가 상태를 가지지 않는다는 것을 의미한다. 쉽게 말해, 서비스는 데이터를 저장하거나 유지하지 않는다는 것이다.
예를 들어, 우리가 쇼핑몰에서 주문을 하면 주문 서비스가 필요하다. 이 주문 서비스는 주문 정보를 받아서 주문 처리를 하고, 그 결과를 반환하는 역할을 한다. 그런데 이때 주문 서비스는 주문 정보를 직접 저장하거나 유지하지 않는다. 주문 정보는 주문이 이루어지는 동안만 사용되고, 주문 처리가 끝나면 주문 서비스는 그 정보를 잊어버린다.
이렇게 서비스는 필요한 작업을 수행하는 동안만 데이터를 사용하고, 작업이 끝나면 그 데이터를 유지하지 않는다. 이런 의미에서 서비스는 특정한 상태를 감싸지 않는 연산이라고 할 수 있다.
즉, 서비스는 요청을 받아서 처리하고 결과를 반환하는 일시적인 작업을 수행하며, 그 외의 상태나 데이터는 저장하거나 유지하지 않는다.
🤔 주문할때 주문 정보를 데이터베이스에 저장하지 않나?
맞다. 하지만 우리가 주목해야 할 부분은 서비스의 상태이다. 주문 정보를 데이터베이스에 저장하는 정보는 서비스의 상태가 아니라 데이터의 상태이다.
서비스가 상태를 갖지 않는다는 것은, 서비스 객체 자체가 데이터를 가지고 있지 않고, 요청이 오면 그때 그때 필요한 데이터를 데이터베이스나 다른 곳에서 가져와서 처리한다는 뜻이다. 즉, 서비스는 데이터를 저장하는 공간(storage)이 아니라, 비즈니스 로직을 처리하는 로직 단위이다.
@Repository
@Repository은 데이터베이스에 접근하는 역할을 하는 클래스에서 주로 사용되며, 주로 DAO 클래스에서 사용된다.
💡
@Repository의 특별한 기능
@Repository는 데이터 액세스 예외를 스프링의 DataAccessException(런타임 예외)으로 전환시켜주는 기능이 있다. 데이터 엑세스 예외는 체크 예외(Checked Exception)로 트랜젝션 롤백이 이루어지지 않는다. 트랜잭션이 적용된 메소드에서 데이터베이스 관련 오류가 발생해도 롤백이 가능한 이유가 이 때문이다.
이 외에도 스프링에서 지원하는 어노테이션이 남았지만, 너무나도 많기 때문에 여기서 마무리하도록 하겠다.
마치며
스프링 동작 원리를 공부하면서 가장 먼저 인상 깊었던 것은 스프링 컨테이너의 편의성과 효율성이다. 스프링 컨테이너는 빈 객체의 생성과 관리, 그리고 의존성 주입을 자동으로 처리해주어, 개발자는 비즈니스 로직에만 집중할 수 있게 해줘 효율성 향상에 큰 도움을 준다는 것을 알게 되었다.
또한, 스프링 컨테이너가 싱글톤의 문제를 해결해주는 것 역시 인상 깊었다. 스프링 컨테이너는 싱글톤 빈의 생명주기를 관리하고, 동시성 문제를 해결해주어, 싱글톤 패턴의 단점을 커버하고 있다. 이런 점에서 스프링의 철학인 '개발자를 위한 프레임워크'를 느낄 수 있었다.
그리고 @Repository를 학습할 때, 해당 어노테이션이 SQLException이 발생해도 자동을 스프링의 런타임 에러로 바꿔주는 부분은 굉장히 놀랐다. 데이터베이스 관련 에러는 체크 예외라고 알고 있었는데 트랜젝션 롤백이 이뤄지는게 의아했었던 부분을 해소시켜주었다.
블로그 글 작성이 생각보다 공부하는데 도움을 많이 주는 것 같다. 현재 최근 프로젝트의 리팩토링을 진행하고 있는데 조만간 이에 관해서 작성할 예정이다.
참고자료
구글 - 컨테이너란?
위키 백과 - 어노테이션이란?
잇트루님의 글
Jongwon님의 글
AlBan님의 글
