
들어가며
이전 글을 통해 Spring의 정의, 등장 배경, 필요성과 Spring의 POJO 프로그래밍에 대해 알아보았다. 이번 글에서는 스프링의 특징인 IoC, DI, AOP, PSA에 대해 자세히 알아보고자 한다.
스프링의 3대 요소
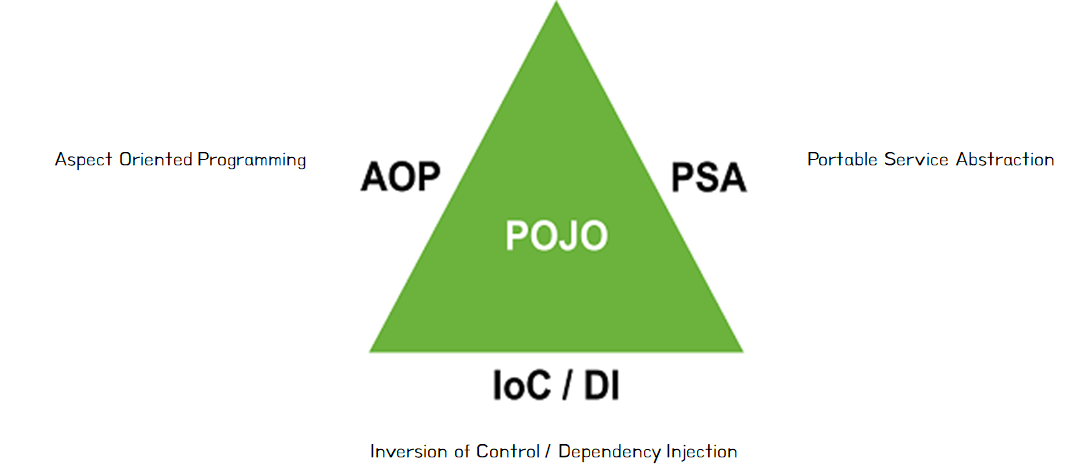
제어의 역전 (Inversion of Control , IoC)
라이브러리와는 달리 모든 프레임워크에는 IoC의 개념이 적용되어있다.
IoC 라는 말은 제어의 역전이라는 뜻으로, 개발자가 아니라 툴이 객체에 대한 제어권을 가진다.
조금 더 쉽게 이해하기 위해, 다음의 예시를 보도록 하자.
public class A {
b = new B(); // new 키워드를 통해 클래스 A에 클래스 B 객체 생성
}
일반적인 자바 코드를 작성할 때, 위와 같이 객체를 직접 생성하였을 것이다. 제어의 역전은 이와 같이 개발자가 직접 객체를 생성하는 것이 아닌 외부에 관리하는 객체를 가져오는 것을 의미한다. 위 코드에 제어의 역전을 적용하면 다음과 같다.
public class A {
private B b; // 객체를 직접 생성하지 않고, 어딘가에 있는 객체를 레퍼런스 변수 b에 할당
}
이전과는 달리, B 객체를 직접 메모리에 할당하여 사용하는 것이 아닌 어딘가에서 받아와서 레퍼런수 변수 b에 할당하고 있는 것을 볼 수 있다. 이렇듯, 제어의 역전을 적용하게 되면 객체를 외부에서 관리하게 되고, 사용할 때는 외부에서 제공해주는 객체를 받아온다. 스프링에서는 방금 설명한 외부를 스프링 컨테이너 라고 부른다.
의존성 주입(Dependency Injection, DI)
스프링에서는 객체를 관리하기 위해 제어의 역전을 사용한다. 이 제어의 역전을 구현하기 위해 사용하는 방법이 바로 DI 이다.
DI는 특정 클래스가 다른 클래스를 의존하는 것을 말한다. 이 또한, 예시를 통해 알아보도록 하자. 다음은 IoC / DI 를 기초로 하는 스프링 코드이다.
public class A {
@Autowired
B b;
}
여기서 Autowired 라는 어노테이션은 스프링 컨테이너에 있는 빈을 주입하는 역할을 한다. 빈은 스프링 컨테이너에서 관리하는 객체를 의미한다. 위 코드에서는 객체를 직접 생성하지 않고 어딘가에 있는 객체를 선언하고 있다. 즉, 객체를 주입받고 있다.
위와 같이 코드를 작성하면 스프링 컨테이너에서는 B 객체를 만들어 클래스 A에 할당해준다. 이를 통해, 객체간의 결합도가 낮아지고 재활용성이 높아진다.
스프링에서 의존성 주입에는 3가지 방법이 있다.
- 필드 주입
- 수정자 주입
- 생성자 주입
하나씩 차근차근 알아보자.
필드 주입(Field Injection)
필드 주입은 이름 그대로 클래스의 필드에 직접 주입하는 방식이다. @Autowired 어노테이션을 필드 위에 선언하여 사용한다.
이 방식은 3가지 방식 중 가장 편하게 의존관계를 주입할 수 있고 코드가 간결해지는 장점이 있으나, 참조 관계를 눈으로 직접 확인하기 어렵고 순환 참조를 막을 수 없다는 단점이 있다. 다음 코드는 필드 주입 방식이다.
@Component
public class A {
@Autowired
private B b;
}
스프링 컨테이너는 A 클래스의 레퍼런스 변수 b에 자동으로 B 객체를 주입한다.
수정자 주입(Setter Injection)
수정자 주입은 setter 메서드를 통해 의존성을 주입하는 방식이다. @Autowired 어노테이션을 setter 메서드 위에 선언하여 사용한다. Spring 3.x 까지는 권장 DI 방식이었으나, 현재는 아니다.
수정자 주입은 NPE가 발생할 수 있고 SOLID 원칙 중 단일 책임 원칙을 위반한다.
@Component
public class A {
private B b;
@Autowired
public void setB(B b) {
this.b = b;
}
}위의 예시에서 A는 setter 메소드를 통해 B를 주입받는다. 스프링 컨테이너는 setB 메소드를 호출하여 B 객체를 주입한다.
생성자 주입을 제외한 나머지 방식(필드, 수정자 주입)은 모두 생성자가 할당된 이후 호출되므로, 필드에 final를 사용할 수 없다. 이는 객체의 불변성이 보장되지 않는다는 것을 의미한다.
Spring Boot 2.6 버전 이상부터는 필드 주입이나 수정자 주입도 기본으로 순환 참조 문제를 방지할 수 있다고 한다. 관련 정보는 다음 글 에서 참고하였다.
생성자 주입(Construct Injection)
현재 가장 권장되는 의존 관계 주입 방식이다. 스프링 공식 문서에서는 Spirng 4.3 부터 생성자 주입 방식을 권장하고 있다. 다음 코드를 통해 알아보자.
@Component
public class A {
private final B b; // final 붙일 수 있음
public ClassA(B b) {
this.b = b;
}
}위의 예시에서 A는 생성자를 통해 B를 주입받는다. 스프링 컨테이너는 A의 생성자를 호출할 때 B 객체를 인자로 전달하여 주입한다.
이렇게 생성자를 통해 의존성을 주입받는 경우, A는 생성될 때 반드시 B를 필요로 하게 된다. 따라서 A의 생성이 완료된 시점에서는 B가 반드시 존재하게 되며, 이는 A의 불변성을 보장한다.
또한, 생성자 인자를 통해 A가 어떤 의존성을 필요로 하는지 명확하게 알 수 있다. 이는 코드의 가독성을 높이는 데 도움이 된다.
요약하자면 생성자 주입의 장점은 다음과 같다.
final키워드를 통해 객체가 단 한번 할당되어 객체의 불변성을 보장한다.- 초기화된 시점에 할당이 되기 때문에 NPE(Null Pointer Execption)이 발생할 수 없다.
생성자 주입의 장점은 여러 가지가 있지만 핵심은 프레임워크에 의존하지 않고 순수 Java의 특징을 잘 살리는 방법이라는 것이다.
💡 생성자 주입시 @Autowired 어노테이션가 없는 이유?
위 코드를 보면
@Autowired어노테이션이 작성되어 있지 않다.
Spring 4.3 이후부터 생성자가 한 개만 있다면 해당 생성자에 Spring이 자동으로@Autowired어노테이션을 붙여주기 때문에 생성자가 하나일 경우 생략해도 무방하다.
관련 정보는 공식 문서에서 참고하였다.
관점 지향 프로그래밍(Aspect Oriented Programming, AOP)
위키백과에 의하면 AOP는 다음과 같이 정의한다.
관점 지향 프로그래밍(Aspect Oriented Programming, AOP)은 횡단 관심사(cross-cutting concern)의 분리를 허용함으로써 모듈성을 증가시키는 것이 목적인 프로그래밍 패러다임이다.
이렇게 보면 무슨 말인지 이해하기 어렵다. 우선, 횡단 관심사에 대해 알아보자.
횡단 관심사
횡단 관심사란 여러 모듈이나 클래스에서 공통으로 나타나는 관심사를 말한다. 이는 전체 시스템에서 공통적으로 필요한 기능이나 로직으로, 주로 로깅, 보안, 트랜잭션 관리 등이 이에 해당한다.
예를 들어, 우리가 온라인 쇼핑몰 애플리케이션을 개발한다고 가정해보자. 이 애플리케이션에는 사용자 관리, 상품 관리, 주문 관리 등 다양한 모듈이 있을 것이다. 각 모듈은 서로 다른 기능을 수행하며, 각자의 '핵심 관심사'를 가지고 있다.
하지만 이들 모듈 모두에서 로그를 기록해야 하는 공통의 요구사항이 있을 수 있다. 예를 들어, 사용자가 로그인하거나 상품을 조회하거나 주문을 할 때마다 해당 정보를 로그로 남겨야 한다. 이와 같이 여러 모듈이나 클래스에서 공통으로 필요한 기능이 바로 '횡단 관심사'이다.
이를 통해 다시 AOP의 정의를 이해하면 다음과 같이 해석할 수 있다.
관점 지향 프로그래밍은 공통 기능(관심사)의 분리를 허용함으로써 모듈성을 증가시키는 것이 목적인 프로그래밍 패러다임이다.
AOP는 핵심 관심사항와 공통 관심사항(횡단 관심사)를 분리한 후, 이러한 사항들을 토대로 모듈화를 진행하기 때문에 모듈성이 증가시킬 수 있다.
모듈화는 특정 로직이나 기능을 하나의 단위로 묶는 것을 의미한다.
그렇다면, AOP는 도대체 언제 쓰는 것일까?
AOP의 필요성
관점 지향 프로그래밍의 필요성을 알아보기 위해선 먼저 기존의 프로그래밍 방식인 객체 지향 프로그래밍(OOP, Object Oriented Programming)의 한계를 이해해야 한다.
객체 지향 프로그래밍에서는 프로그램의 기능을 여러 개의 독립적인 객체들로 분리하여 개발한다. 각 객체는 자신의 상태와 행위를 가지며, 다른 객체와 메시지를 주고 받으며 협력해 프로그램을 완성한다.
하지만 객체 지향 프로그래밍만으로는 해결하기 어려운 문제가 있다. 그것은 바로 횡단 관심사의 처리이다.
횡단 관심사를 각 객체나 모듈에서 개별적으로 처리하면 코드의 중복과 복잡성이 증가하고, 유지보수가 어렵게 된다. 또한, 핵심 비즈니스 로직과 횡단 관심사의 코드가 섞이게 되어 코드의 가독성이 떨어진다.
이런 문제를 해결하기 위해 나온 것이 바로 관점 지향 프로그래밍(AOP)이다. AOP는 횡단 관심사를 별도의 '관점'으로 분리하고, 이를 프로그램의 핵심 비즈니스 로직에서 독립적으로 관리할 수 있게 해준다. 이로써 코드의 중복과 복잡성을 줄이고, 가독성을 높일 수 있다.
즉, 공통 기능과 핵심 기능을 분리할 필요가 있을 때 사용한다고 볼 수 있다.
Spring 공식문서에 의하면 AOP는 OOP를 보완하는 방법이라고 한다.
만약 특정 어플리케이션의 기능을 수행할 때, 로깅이 필요하다고 가정해보자. 이때, AOP를 적용하지 않으면 아래와 같다.
public class ProductService {
public void addProduct(Product product) {
// 로깅
System.out.println("Product added: " + product.getName());
// 핵심 비즈니스 로직
// ...
}
public void deleteProduct(Product product) {
// 로깅
System.out.println("Product deleted: " + product.getName());
// 핵심 비즈니스 로직
// ...
}
}
위의 코드에서 볼 수 있듯이, 각 메소드마다 로깅 코드가 중복되어 있다. 이렇게 되면 코드의 중복이 발생하고, 로깅 방식을 변경하려면 모든 메소드를 일일이 수정해야 한다. AOP를 적용하면, 로깅에 해당하는 로직을 모듈화할 수 있다. 그렇게 된다면, 개발자는 핵심 기능에만 집중할 수 있을 뿐만 아니라 유지 보수에 유연한 코드를 작성할 수 있다.
AOP 관련 용어
AOP가 무엇인지 알았으니, 이제 AOP에서 사용되는 용어에 대해 알아보도록 하자.
Aspect
'관점'이라고도 하며, 횡단 관심사(공통 관심사)를 모듈화한 것을 의미한다. 예를 들어, 로깅, 보안, 트랜잭션 관리 등과 같이 여러 객체나 모듈에서 공통적으로 사용하는 기능을 Aspect로 정의할 수 있다.
부가 기능을 정의한
Advice와 이 부가 기능을 어디에 적용할지 결정하는Pointcut를 통틀어 Aspect라고 한다.
Target
'타겟'이라고도 하며, Aspect가 적용되는 대상 객체를 의미한다. 즉, 실제 비즈니스 로직을 수행하는 객체를 가리킨다. 클래스나 메소드가 이에 해당한다.
Advice
'조언'이라고도 하며, 실제로 언제 공통 관심 기능(Aspect)을 핵심 로직에 적용할지 정의하는 부분이다. Target에게 제공할 부가 기능이 구현된 모듈이다.
스프링 AOP에서는 5가지 타입의 Advice를 제공한다
Before,After,AfterReturning,AfterThrowing,Around
JoinPoint
'조인 포인트'라고도 하며, 프로그램 실행 중에 Aspect가 적용될 수 있는 위치를 가리킨다. 메소드 호출, 예외 발생 등 특정한 지점에서 Aspect의 Advice가 실행될 수 있다.
PointCut
'포인트 컷'이라고도 하며, 어떤 JoinPoint(즉, 어떤 메소드)에 Advice를 적용할지 결정하는 것입니다. 클래스 이름, 메소드 이름 등 표현식을 사용하여 특정 조건을 만족하는 JoinPoint에만 Advice를 적용할 수 있다. 따라서, JoinPoint는 프로그램의 실행 흐름 중에서 Advice를 적용할 수 있는 '시점'을, PointCut은 그러한 JoinPoint 중에서 '어떤 시점'에 Advice를 적용할지를 결정하는 역할을 한다.
이식 가능한 서비스 추상화 (Portable Service Abstraction, PSA)
단순하게 직역하면 휴대용 서비스 추상화이지만, 알기 쉽게 설명하자면 스프링에서 제공하는 다양한 기술을 추상화해 개발자가 쉽게 사용하는 인터페이스 라고 볼 수 있다.
예를 들어, 스프링에서 데이터베이스에 접근하기 위한 기술로는 JDBC, Mybatis, JPA 등이 있다.
우리는 위 기술이 어떻게 구현되어있는지 모르지만 해당 기술을 사용하여 데이터베이스에 접근할 수 있었다. Mysql로 개발하다 MariaDB로 데이터베이스를 바꿔야되는 상황에서, 스프링은 데이터베이스 접근 방식을 동일하게 둔다. 그러한 이유는 스프링은 어떤 기술을 사용하든 일관된 방식으로 데이터베이스에 접근하도록 인터페이스를 지원하기 때문이다.
또 다른 예시로는 WAS 또한 PSA의 일종이라고 볼 수 있다. 스프링은 원래 Tomcat 기반으로 돌아가는데, dependency에서 web을 webflux로 바꾸고 다시 실행해보면 Netty 기반으로 돌아간다. 스프링의 PSA 덕분에 코드를 거의 바꾸지 않고도 톰캣이 아닌 완전히 다른 기술로 실행이 가능하다는 의미한다.
Spring PSA의 종류
스프링은 다양한 PSA를 제공한다. 이번 글에서는 Spring Web MVC에 대해서만 간단하게 살펴보자.
Spring Web MVC
원활한 설명을 위해 이전에 학습을 위해 이리저리 굴린 코드를 가져와봤다.
@RestController
@RequestMapping("/board")
@RequiredArgsConstructor
public class BoardController {
private final BoardService boardService;
@PostMapping
public ResponseEntity<CreateBoardResponse> create(@RequestBody CreateBoardRequest createBoardRequest) {
return ResponseEntity.ok(boardService.createBoard(createBoardRequest));
}
// offset
@GetMapping
public ResponseEntity<Page<ReadAllBoardResponse>> readAll(@PageableDefault(sort = "boardNo", direction = Sort.Direction.DESC) Pageable pageable) {
return ResponseEntity.ok(boardService.readAllBoard(pageable));
}위 클래스는 @RestController 어노테이션이 붙어 있는데, @RestController 어노테이션을 사용하면 요청을 매핑할 수 있는 컨트롤러 역할을 수행할 수 있는 클래스가 된다.
그래서 위 컨트롤러 클래스에서는 @GetMapping 등 어노테이션에 원하는 엔드 포인트를 설정하면 스프링이 자동으로 매핑을 해주기 때문에 특정 엔드 포인트로 요청이 올 경우 매핑된 메소드가 호출되어 적절한 응답을 한다.
하지만 원래는 HttpServlet을 상속받고 doGet이나 doPost 메소드를 구현해야한다. Spring에 내장된 Tomcat을 사용하면서 HttpServelet을 사용하지 않아도 되는 이유는 앞서 보았듯이 @GetMapping 와 같은 어노테이션을 사용하면 Spring이 자동으로 매핑해주기 때문이다.
따라서 Servlet과 관련된 설정이나 코드를 작성하지 않아도 정상적으로 Spring Web MVC를 사용할 수 있게 해주는게 PSA임을 알 수 있다.
이로 인해, PSA의 추상화를 통해 개발자가 다양한 기술을 쓰기 편하게 한다 라는 목적을 확실히 알 수 있다.
마치며

오늘은 스프링에서 핵심적으로 강조하는 세 가지 요소인 IoC/DI, AOP, 그리고 PSA에 대해 깊이 있게 학습하는 시간을 가졌다. 이들에 대해 대략적으로는 알고 있었지만, 이번에 글을 작성하면서 더욱 자세히 이해하고, 배운 내용을 체계적으로 정리할 수 있었다.
특히, AOP와 PSA는 명시적으로 인식하지 못했지만, 사실 이미 프로젝트를 진행하면서 활용하고 있었다는 사실이 놀라웠다. 다양한 에러를 직접 핸들링하거나 Spring Cache, Spring Web MVC를 사용하며, 그 내부에서 이러한 기술이 동작하고 있다는 사실을 몰랐었다는 건 나 자신에게 반성하게 되는 계기가 되었다.
앞으로 스프링을 활용한 프로젝트를 진행할 때에는 이런 핵심 요소들을 더욱 의식적으로 활용하고, 이해하며 적용하는 능력을 키워 나가야겠다는 생각이 든다. 특히, AOP와 PSA 같은 경우는 명시적으로 인식하지 못했던 부분이었기에, 한편으로는 이번 학습을 통해 스프링의 이런 강력한 기능을 활용하는 방법에 대해 깊이 있게 이해하게 되어 뿌듯하다.
마지막으로, 스프링과 같은 프레임워크를 사용함으로써 얻을 수 있는 이점과 그 기능들을 최대한 활용하기 위해서는 그 기능들이 어떻게 동작하며 왜 필요한지를 이해하는 것이 중요하다는 것을 다시 한번 깨닫게 되었다. 앞으로도 이렇게 꾸준히 학습하며, 어제의 나보다 성장한 개발자가 되도록 노력할 것이다.
자료 출처
스프링 공식문서
관점 지향 프로그래밍 위키백과
AOP 관련 스프링 공식문서
홍혁준님의 글
해어린님의 글
lango님의 글
