
0. 브라우저에서 JavaScript는 어떻게 작동할까?
리액트나 뷰 등 프레임워크 생태계에 속해있는 프론트엔드 개발자는 필연적으로 JavaScript를 사용해야 한다. 특히 리액트를 사용할 경우 웹 개발의 기초가 되는 HTML, CSS를 모두 JSX 혹은 CSS-in-JS 등으로 처리하는 경우도 있는데, 이 경우에는 HTML이나 CSS를 단 한 줄도 직접 짜지 않고 모든 코드를 JavaScript로 작성해야 하는 경우도 있다. 이는 우리가 JavaScript의 작동 환경을 이해해야 비로소 좋은 개발을 할 수 있다는 이야기이다.
또한 JavaScript와 관련된 공부로 좋은 코드를 설계하고 작성하는 것은 UX를 향상시켜 웹 페이지의 상품성에 영향을 끼칠 뿐만 아니라, 서버와의 적절한 통신환경을 구축할 가능성을 만들어줘 네트워크 비용을 절감시킬 수도 있게 해준다.
앞서 이야기한 이유들 외에도 우리가 JavaScript를 깊게 공부할 이유는 충분히 많다. 하지만 좋은 코드를 설계하고 작성하기 위해서는 JavaScript의 문법을 공부하는 것만으로는 충분하지 않다.
실제 브라우저에서 JavaScript가 어떤 원리를 통해 작동되고 어떤 스케쥴링 기법을 통해 런타임에서 제어되는지, 어떤 방식으로 DOM에 접근하여 이벤트 리스너를 작동시키는지, DOM에서 이벤트가 호출되었을 때 어떤 stream을 통해 DOM에 영향을 주게 되는지 등을 이해하지 못하면 우리의 목표를 달성할 정도의 좋은 코드를 작성하는 것은 불가능하다.
오늘은 이런 이유에서 JavaScript에서 작성한 로직이 브라우저의 JS 엔진 런타임에서 어떻게 핸들링되는지 살펴볼 것이다.
1. 프로그래밍 언어로써의 JavaScript
JavaScript는
인터프리터형스크립트 프로그래밍 언어로,싱글 스레드환경을 기반으로 하면서논 블로킹방식과비동기 프로그래밍을 지원한다.
위 문장에서 우리가 알아보아야 할 키워드는 인터프리터형, 스크립트 프로그래밍 언어, 싱글 스레드, 논 블로킹 방식, 비동기 프로그래밍이다. 각자가 무슨 의미를 가지고 있는지 자세히 살펴보자.
1.1. JavaScript의 특징들
1.1.1. 인터프리터형(Interpreter)
프로그래밍 언어의 작동 방식은 크게 컴파일형과 인터프리터형으로 나뉜다.
컴파일형 프로그래밍 언어는 C나 Rust와 같이 프로그램을 실행하기 전에 high-level의 프로그래밍 언어를 기계어로 전부 번역하여 실행 파일을 생성하는 방식을 사용한다.
그와 대비하여 인터프리터형 프로그래밍 언어는 실행 이전에 따로 실행 파일을 생성하는 등의 컴파일 과정을 거치지 않고 소스코드를 한 줄씩 읽으면서 실행하는 방식을 사용한다.
JavaScript가 인터프리터형이라는 것은, 태그로 감싸진 스크립트 코드가 해당 HTML이 동작할 때 위에서부터 한 줄씩 작동되고, 이벤트 리스너 등으로 인해 브라우저에 호출된 코드가 위에서부터 한 줄씩 읽히는 방식으로 호출된다는 것이다.
1.1.2. 스크립트 프로그래밍 언어(Script language)
스크립트 언어는 시스템 언어에 비해 더 간편하고 빠르게 개발할 수 있도록 설계된 언어이며, 개발자가 시스템의 복잡한 부분을 신경쓰지 않아도 충분히 개발을 할 수 있는 정도의 높은 추상화 수준을 가진다. 또한 특정 인터페이스를 작동시키는 방식으로 작동하기 때문에 언어의 사용 목적이 정해져있는 특정 환경에 최적화되어있다.
JavaScript는 ECMAScript를 기반으로 한 웹 브라우저의 작동을 목적으로 하는 스크립트 언어이기 때문에, 문법이 간결하고 추상화 수준이 높아 기본적인 기능을 구현하는 데에 있어서는 러닝 커브가 크지 않다는 것이 특징이다.
1.1.3. 싱글 스레드(Single Thread)

프로그래밍에서는 작업을 수행하는 최소 단위의 흐름을 일반적으로 스레드(thread)라 칭한다. JavaScript가 싱글스레드라는 의미는 작업을 수행하는 단위가 단일 흐름으로 이루어져있다는 의미인데, 이는 동시에 여러 가지 작업을 수행할 수 있는 멀티 스레드 방식과는 반대로 한 시점에 오로지 한 가지 작업만을 수행할 수 있다는 것을 의미한다.
스레드는 실이라는 뜻을 가지는데, 프로그램이 동작하는 컨텍스트나 스트림이 그 실이라고 했을 때 위의 사진처럼 한 줄기의 실만으로 프로그램이 동작하는 것을 생각하면 이해가기 쉽다.
1.1.4. 논 블로킹 방식(Non-Blocking)
프로그래밍에서는 두 개 이상의 함수가 작동할 때 두 함수가 처리하는 같은 대상에 대한 제어권을 어떻게 처리할 것인지에 따라 블로킹 방식과 논 블로킹 방식으로 프로그램을 나눌 수 있다.
블로킹 방식은 함수 A가 함수 B를 호출했을 때 함수 B의 동작이 완료될 때까지 함수 A가 기다리는 방식이며, 작업 대상이 같은 새로운 함수가 호출되었을 때 호출된 함수에게 그 작업 대상에 대한 제어권을 넘겨주는 방식을 이야기한다.
논 블로킹 방식은 함수 A가 함수 B를 호출하더라도 함수 A가 함수 B에게 작업 대상에 대한 제어권을 넘겨주지 않는다.
JavaScript가 동작하는 웹 브라우저 환경에서는 여러 가지의 API를 연속적으로 호출해야하는 상황이 자주 발생한다. 이 때 각 API의 호출마다 페이지 렌더링의 제어권을 API에게 넘겨주는 블로킹 방식을 취한다면, 먼저 호출된 API에서 결과가 반환된 이후에나 다음 API를 호출하는 식의 동작이 이루어질 것이다. 하지만 논블로킹 방식을 취한다면 앞서 호출된 API의 결과 반환 여부에 의존하지 않고 다음 API를 호출하도록 할 수 있기 때문에, 일단 전부 호출한 다음에 반환된 값들이 차례대로 반영되는 식의 동작을 구현할 수 있다.
1.1.5. 비동기 프로그래밍(Asyncronous)
두 가지 이상의 함수가 실행될 때, 함수들의 시작 및 종료 시기가 다른 함수의 시작 및 종료 시기에 영향을 끼치는 경우를 동기 작업(Syncronous)라고 부른다. 함수 A가 함수 B, C를 순서대로 동기 호출하면, 함수 B의 작업 시작과 함수 C의 작업 시작을 같은 시기로 맞추거나, 함수 B의 작업 완료가 함수 C의 작업 시작의 트리거가 되는 등의 형태인 것이다.
반대로 함수들이 실행될 때 각 함수의 시작 및 종료 시기가 다른 함수들의 시작 및 종료 시기에 영향을 받지 않는 경우를 비동기 작업이라고 부른다. 함수 A가 함수 B, C를 순서대로 비동기 호출하면, 함수 B의 시작 및 종료 시기와 관계 없이 함수 C의 작업이 시작되고 종료되는 형태이다.
JavaScript가 동작하는 웹 브라우저 환경에서는 유저의 비 일관적인 입력에 따라 함수들을 호출해야하는 상황이 전제된다. 만약에 이런 식으로 호출되는 함수들을 전부 동기 작업으로 처리할 경우 먼저 호출된 함수의 작업 시작 시기를 뒤에 호출된 함수의 작업 시작 시기와 맞추기 위해, 또는 먼저 호출된 함수의 동작이 끝나기까지 뒤에 호출된 함수가 기다려야하기 때문에 의도하지 않은 딜레이가 발생할 수 있다.
따라서 JavaScript는 각 함수의 호출이 다른 함수의 시작 및 종료 시기에 영향을 받지 않도록 하는 비동기 방식의 프로그램을 구축할 수 있도록 비동기 작업을 지원하고 있다.
이처럼 JavaScript는 웹 브라우저와 웹 유저가 상호작용하는 환경에 가장 적절한 형태로 기능을 구현할 수 있도록 앞서 살펴본 것과 같은 특징들을 가지도록 설계되었다. JavaScript 엔진들은 어떤 방법으로 이런 설계상의 특징들을 만족시키는지 살펴보자.
2. JavaScript의 런타임 모델
위에서 “JavaScript의 특징들”이라는 표현을 사실 조금 모호하다. 정확하게 표현하자면, “JavaScript가 구동되는 JavaScript 엔진의 특징들”이 적절할 것 같다. JavaScript라는 프로그래밍 언어를 직접 작동시키는 엔진이 위와 같은 특징들을 수행할 수 있도록 구현되어야 비로소 저런 특징들을 갖게 되기 때문이다.
인터프리터형과 스크립트 프로그래밍 언어라는 것에서 우리는 메모리 관리의 필요성을 생각해볼 수 있다. 컴파일형의 low-level 프로그래밍의 경우 코드 내에서 작성된 메모리 할당과 할당된 메모리의 해제가 프로그램의 비정상적 종료가 발생하지 않는 이상 어느 정도 보장될 수 있다. 하지만 언제 코드의 작동이 멈추어도 이상하지 않은 인터프리터형 프로그래밍의 경우에는, 할당된 메모리가 해제되지 않을 수 있다는 여지가 커지게 된다. JavaScript 엔진은 이와 같은 문제를 해결하기 위해 가비지 콜렉션 방식을 활용한다.
그리고 JavaScript엔진은 싱글 스레드 방식으로 어떻게 논 블로킹 방식과 비동기 함수를 구현할 수 있을까? 얼핏 보기에는 논 블로킹 방식과 비동기 방식은 모두 병렬적 처리가 전제되어 있는 것처럼 보이기 때문에, 구조적으로 병렬적 처리가 불가능한 싱글 스레드 베이스로는 만족할 수 없을 것처럼 보인다. JavaScript 엔진은 이를 구현하기 위해 이벤트 루프를 활용한 런타임 모델을 사용한다.
가비지 콜렉션이나 이벤트 루프가 작동되는 구체적인 방식은 뒷부분에서 살펴보기로 하고, 일단은 JavaScript의 런타임 모델이 어떤 구조로 이루어져 있는지 살펴보자.
2.1. JavaScript 런타임 모델의 구조
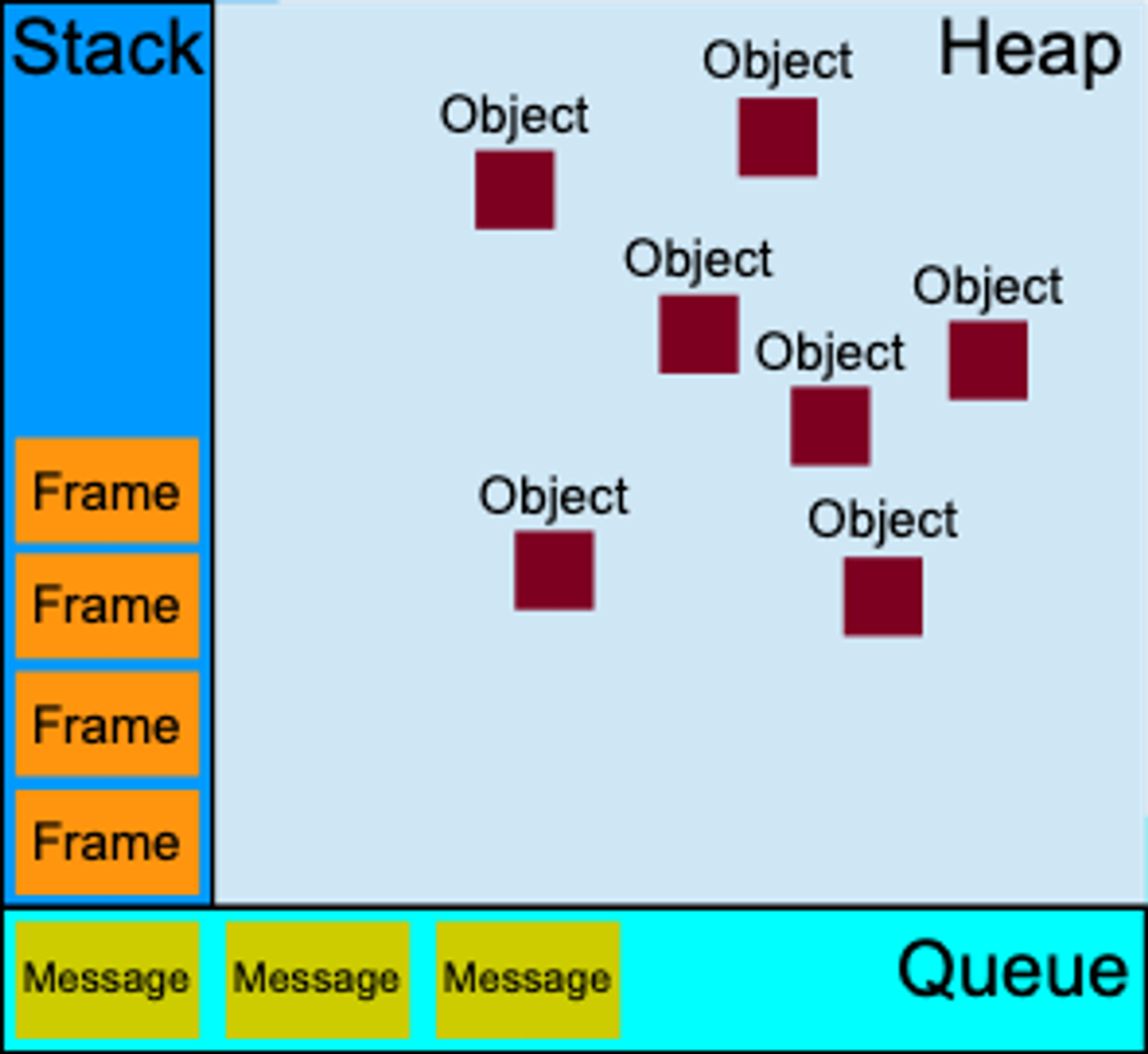
2.1.1. Heap(Heap Memory)

JavaScript 엔진은 Object 구조를 기반으로 한 변수들을 Memory Heap에 저장하여 사용한다. Heap 영역은 단순히 메모리의 큰 영역을 지칭하는 용어이며, Object들이 저장된 공간이라고 생각하면 된다.
2.1.2. Stack(Function Stack, Function Call Stack)
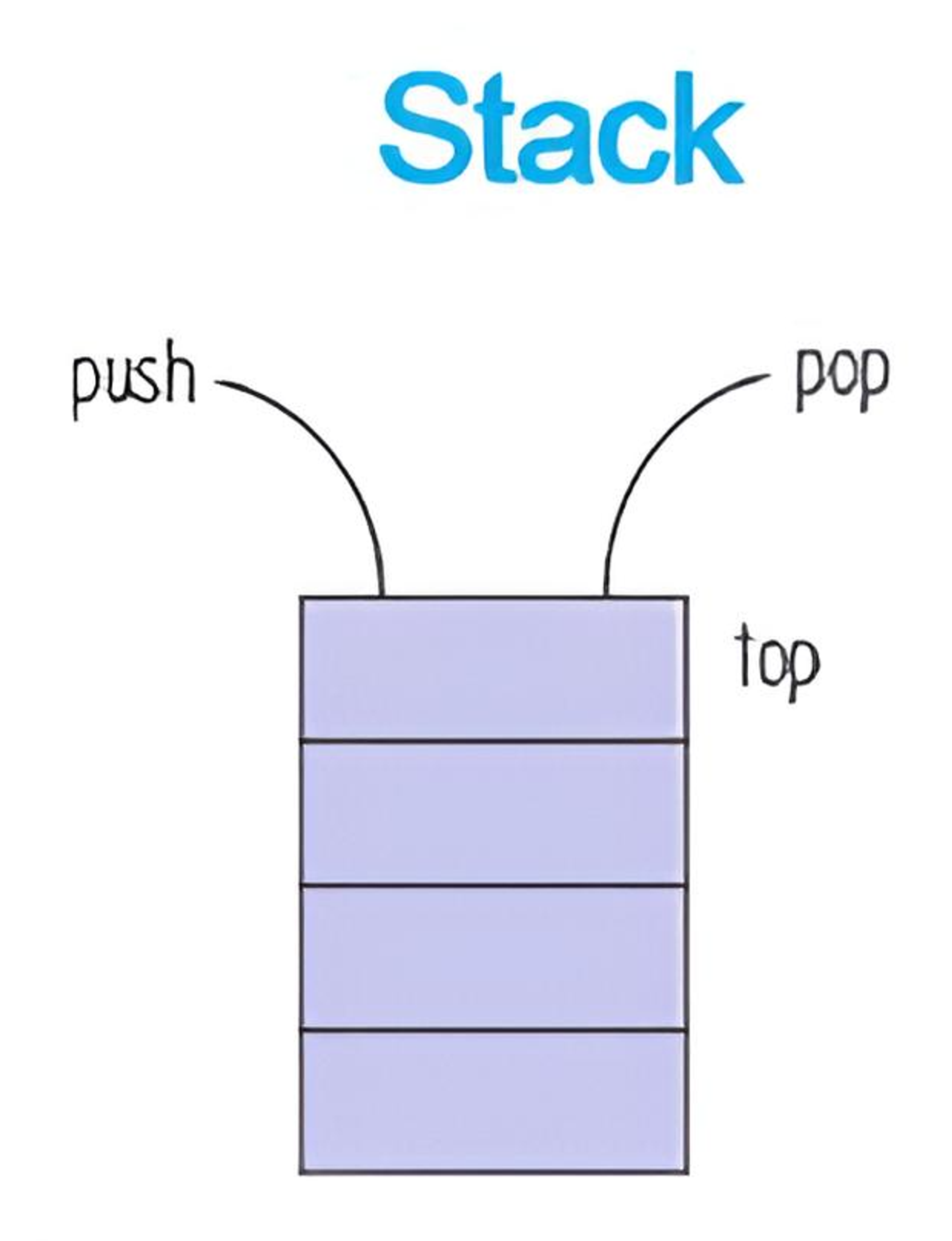
Stack에는 호출된 함수들의 목록이 저장되며, 스레드가 작동시키던 이전 함수의 작동이 끝나면 LIFO 방식으로 스택의 가장 위에 쌓여 있는 함수를 처리한다. 함수 스택, 함수 콜 스택 등으로 부를 수 있다.
2.1.3. Queue(Message Queue, Task Queue)
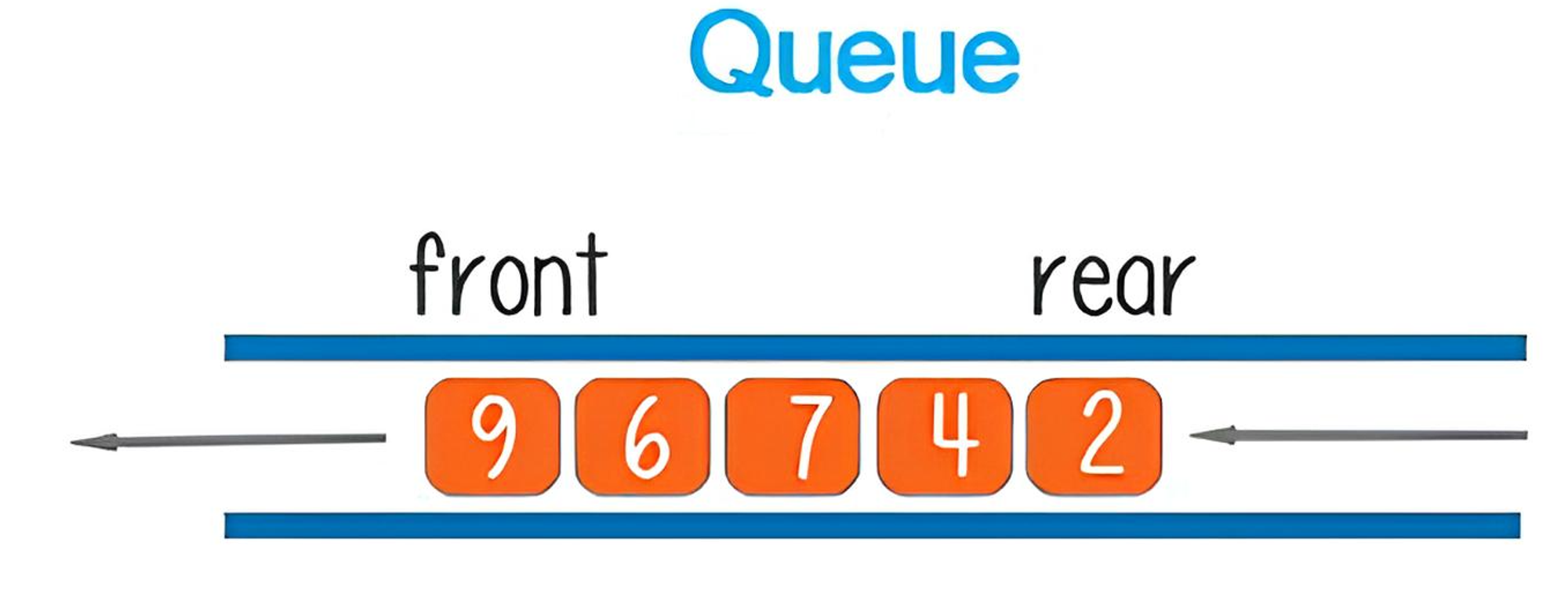
JavaScript 엔진은 이벤트나 함수 내에서의 다른 context의 호출 등으로 처리할 메시지가 발생하게 되면, 이를 Queue에 저장한다. 그리고 Queue에서 FIFO 방식으로 저장된 순서에 따라 메시지를 꺼내 작동하게 된다. JavaScript 엔진은 싱글 스레드 형태로, 메시지들을 병렬적으로 처리할 수 없기 때문에 이에 대한 스케줄링을 해줄 필요가 생긴다. Queue는 이렇게 처리해야할 메시지들을 모아두는 공간이다. 메시지 큐나 태스크 큐라고도 부른다.
2.1.4. JavaScript 엔진의 작동 방식
위 영역들의 특징들을 그대로 가지고 JavaScript 엔진의 작동 방식을 간단하게 정리하자면 다음과 같다.
- Queue에 저장된 Message를 FIFO 방식으로 순차처리한다. 이 때 호출된 함수들은 Stack에 저장한다.
- Stack에 쌓인 함수들을 LIFO 방식으로 순차처리한다. 함수의 처리 과정에서 새로운 Message가 발생할 수도 있다.
- 함수 실행에 필요한 object들은 heap에 접근하여 활용한다.
우리가 뒤에서 살펴볼 이벤트 루프와 가비지 콜렉션은 위의 과정에서 각자 정해진 역할을 수행하게 된다. 이벤트 루프는 1과 2에서 Queue와 Stack을 비동기적인 논블로킹 작동을 구현하기 위한 방식으로 스케쥴링하고, 가비지 콜렉션은 Heap에서 주기적으로 작동하여 사용하지 않으면서 할당된 Object들의 메모리 할당을 해제해준다.
2.2. 이벤트 루프(Event Loop)
2.1에서 살펴본 것처럼, JavaScript가 작동되는 환경에는 호출된 함수가 저장되는 Stack과 실행될 Context 정보를 담고 있는 Message가 저장되는 Queue가 존재한다.
이벤트 루프는 이러한 환경을 기반으로 하여 큐에 메시지가 비어있을 때까지 가장 오래된 메시지부터 큐에서 꺼내 처리하는 것을 반복하는 방식을 이야기한다. 대략적으로 다음과 같은 형태이다.
while (queue.waitForMessage()) {
queue.processNextMessage();
}이벤트 루프 방식이 적용되는 환경에서는, 싱글 스레드로 비동기 동작을 제어할 수 있게 된다. queue에 있는 메시지들은 이벤트 루프에 의해 읽어지면서 함수 스택에 등록된다. 메시지는 동기 함수나 비동기 함수 모두를 호출할 수 있는데, 이 때 호출되는 함수를 동기 함수와 비동기 함수로 분류하게 되면, 동기 함수는 함수 스택에서 호출되면 바로 실행되며, 비동기 함수는 함수 스택에서 호출되면 실행과 함께 그 메시지를 다시 큐에 등록하고 반환된다. 한 코드 블럭 안에서 동기 함수의 호출과 비동기 함수의 호출이 순차적으로 이루어지면, 비동기 함수의 콜백 함수 동작이 동기 함수의 동작보다 뒤로 밀리는 이유가 바로 이것이다.
이러한 동작을 위해서 JavaScript에서는 문법적으로 동기 함수와 비동기 함수를 구분하고 있다.
비동기 함수로 분류된 함수들에 대해 깊게 들어가기 전에 우리가 알고 가야 하는 사실은, “비동기 함수는 작동 시기 정보를 필요로 한다.”이다. 인터프리터형 프로그래밍 언어인 JavaScript는 함수의 동기 작동을 기본값으로 한 문법 구조를 가지고 있다. 따라서 아무런 추가적인 정보 없이 함수를 호출하면 그것은 순차적인 동기 작동으로 처리된다. 비동기 호출은 이러한 작동 방식에서 벗어난 형태로, 일반적인 JavaScript의 함수 작동 시기가 아닌, 우리가 원하는 특정한 시기에 함수가 작동되는 것을 목적으로 하여 작성되기 때문에 우리는 비동기 함수 호출에 작동시킬 함수에 대한 정보와 작동 시기에 대한 정보를 함께 작성해주어야 한다. 우리는 이 중 작동시킬 함수를 콜백 함수라고 부른다.
setTimeout(callback, ms);
// setTimeout에서 callback은 비동기로 호출할 함수를 의미하고,
// ms는 비동기 함수가 작동될 시기에 대한 정보를 의미한다.2.2.1. 이벤트 루프의 비동기 함수 제어
대표적으로 가장 많이 쓰이는 비동기 문법은 async와 await를 활용한 비동기 흐름 제어 문법과, setTimeout과 setInterval을 활용한 타이머 문법이다. setTimeout을 활용한 다음 예시를 통해 이벤트 루프를 통한 비동기 동작을 살펴보자. 다음과 같은 규칙들을 기억한 채로 따라가면 어렵지 않을 것이다.
⛓️ 이벤트 루프의 작동 규칙
- 코드를 한 줄씩 읽으면서 처리한다.
- 코드를 처리할 때 동기 함수의 경우 함수 스택에 바로 등록한다.
- 코드를 처리할 때 비동기 함수의 경우 메시지 큐에 등록한다.
- 코드를 한 줄씩 처리할 때마다, 함수 스택에 함수가 하나라도 존재하면 스택이 비어있을 때까지 pop하며 함수를 실행한다.
- 동기/비동기 분류 작업과 동기 동작의 실행이 전부 종료된 시점에 함수 스택이 비어있으면 메시지 큐가 비어있을 때까지 메시> 지 큐의 가장 오래된 메시지를 스택에 넣고 실행시킨다.
- setTimeout은 메시지 큐에서 함수 스택으로 넘어와 실행될 때, 현재 시각과 비교하여 함수의 실행 시각이 지나지 않았으면 그대로 이를 메시지 큐에 등록한다.
console.log('1');
서버 api 호출
console.log('3');위의 코드를 실행하면 JavaScript 엔진은 코드를 위에서부터 처리하게 된다.
console.log(’1’);은 동기 동작이기 때문에 바로 함수 스택에 등록된다. 이후엔 함수 스택에 함수가 존재하기 때문에 console.log(’1’);을 실행한다.
함수 스택이 비어있기 때문에 다음 코드라인인 setTimeout(…)을 처리한다. 이 메시지는 비동기 동작을 나타내기 때문에 함수를 실행시키지 않고 그대로 메시지 큐에 이를 등록한다.
함수 스택이 비어있기 때문에 다음 코드라인인 console.log(’3’);을 처리한다. 동기 동작이기 때문에 바로 함수 스택에 등록되고, 함수 스택에 함수가 존재하기 때문에 console.log(’3’);을 실행한다.
함수 스택이 비어있으면서 더 이상 읽을 코드가 없기 때문에, 동기 동작의 실행이 전부 완료된 것으로, 이제 메시지 큐를 확인한다.
메시지 큐에 남아있는 setTimeout(…)를 함수 스택에 등록한다.
함수 스택에 함수가 존재하기 때문에 pop하여 setTimeout(…) 구문을 실행한다. 만약 작동 시기가 도달하지 않았으면 다시 메시지 큐로 돌아가고, 작동 시기가 도달했으면 콜백 함수를 함수 스택에 등록하는 동작을 수행한다.
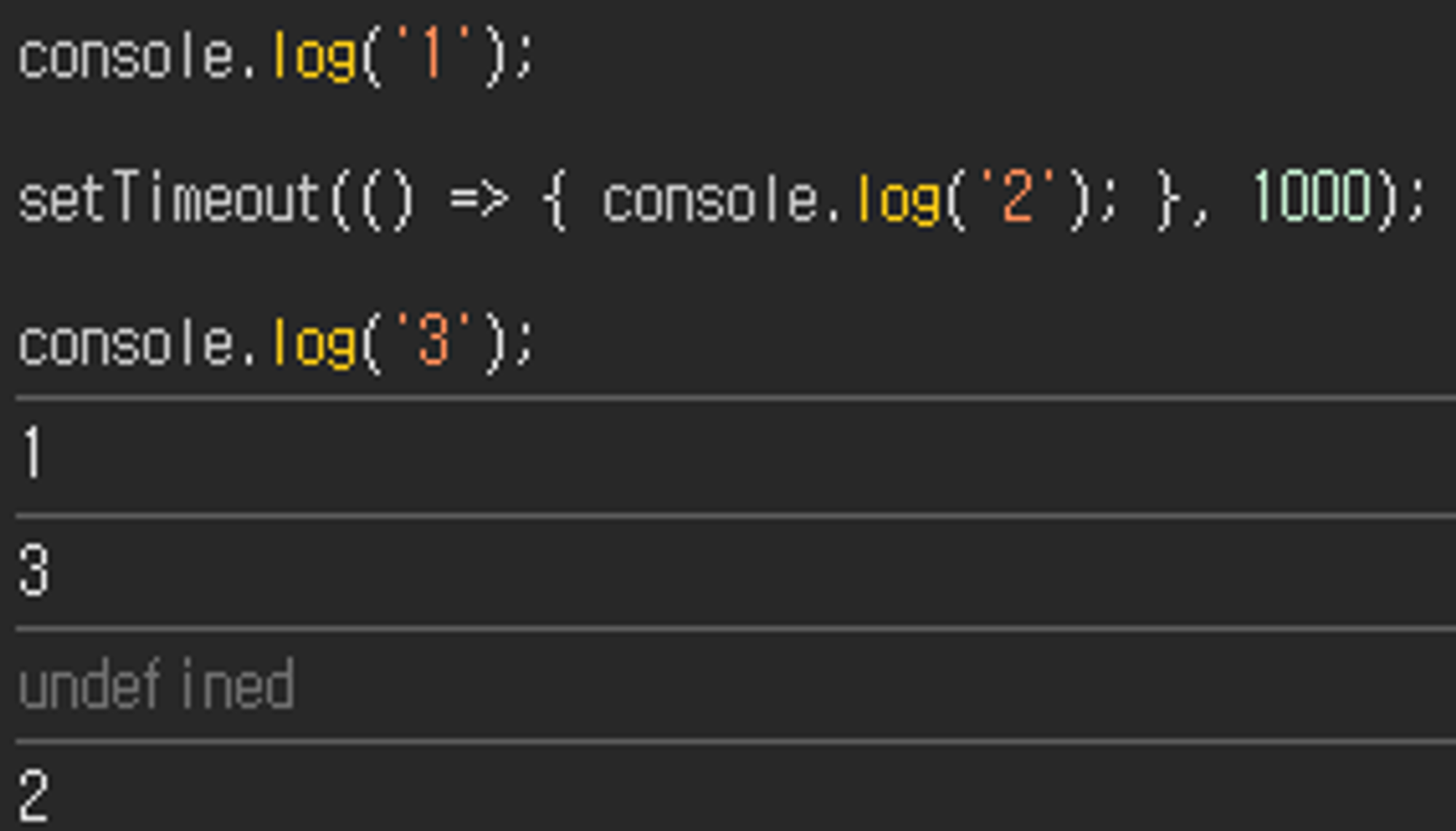
이런 식으로 비동기 함수를 우선 메시지 큐로 되돌리는 방식으로 코드 실행 과정을 거치면, 동기 함수는 비동기 함수보다 항상 먼저 호출되어 완료되고, 비동기 함수는 큐에 남아 작동 시기가 될 때까지 루프를 거친다.
위의 코드의 작동 결과에서 우리는 동기 동작과 비동기 동작의 실행시기와 완료시기가 서로 영향을 주지 않으면서 각자의 코드 흐름을 블로킹하지 않는다는 사실을 알 수 있다. 논 블로킹 방식이면서, 비동기 작동을 지원하게 된 것이다.
setTimeout의 대기시간이 1000ms로 지정되어 있기 때문에 늦게 동작하는 것처럼 보이기도 하지만, setTimeout의 대기시간을 0ms로 설정해도 위와 같은 동작이 수행된다.
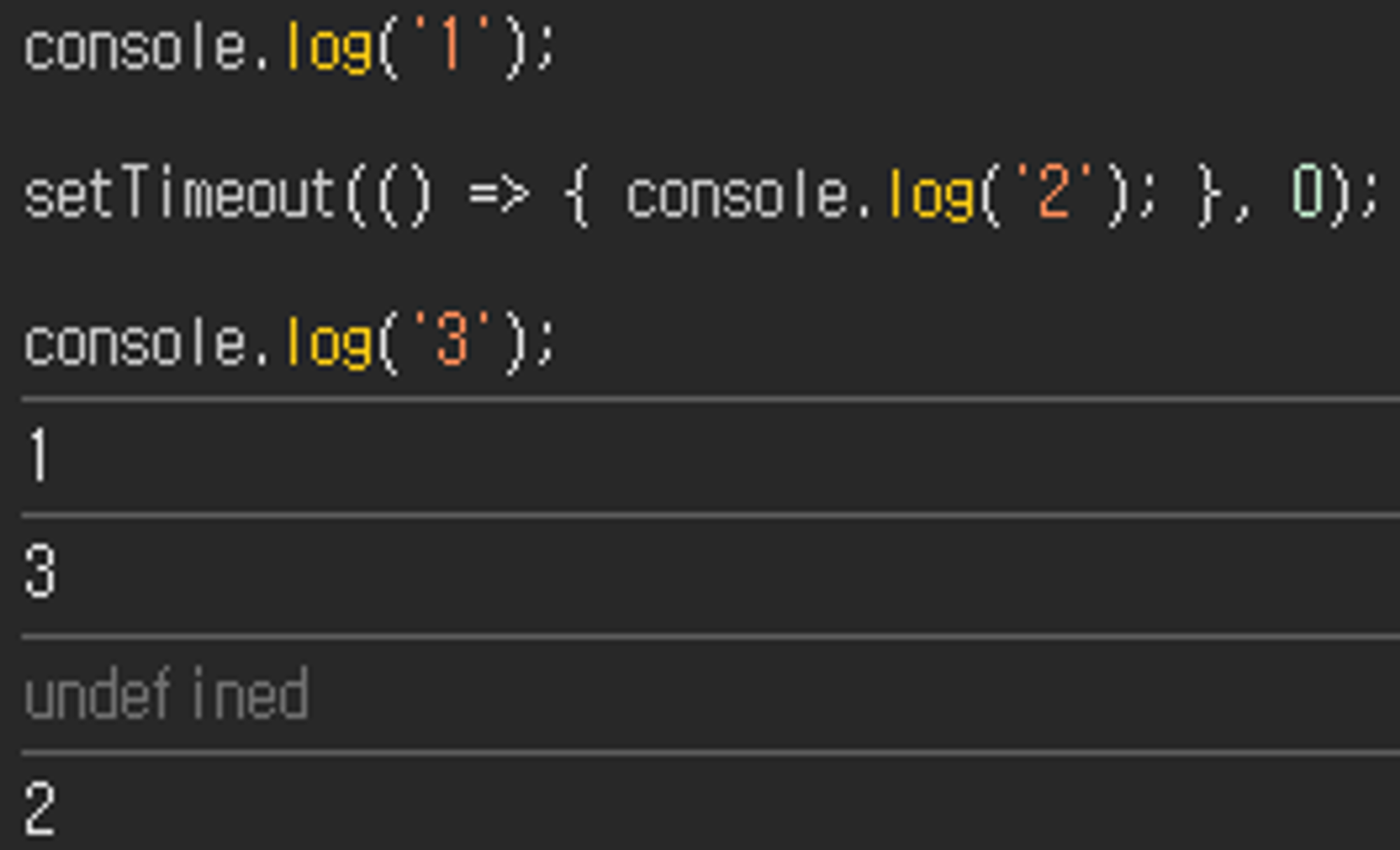
추가적으로, 이 방식에 의해 setTimeout코드가 읽혔을 때부터 엔진이 블로킹되어 호출 시기까지 대기하는 방식이 아니기 때문에, setTimeout에서 파라미터로 입력받는 시간은 실제 코드를 읽은 시점부터 그 시간이 완료되는 정확한 시점이 아닌 함수 호출의 최소 시간만을 보장할 수 있다.
2.2.2. 마이크로 태스크 큐(MicroTask Queue)와 매크로 태스크 큐(MacroTask Queue)
위에서 살펴본 setTimeout는 스크립트가 실행되는 전역적인 비동기 제어 역할을 수행할 수 있다. 특정 함수를 원하는 시기에 호출하도록 제어할 수 있는 것이다. 그렇다면 코드 내에 작성된 동기함수들과 별개의 흐름을 비동기적으로 구현하고 싶다면 어떻게 코드를 작성할 수 있을까?
다들 알다시피 Promise를 활용하면 된다. Promise 객체를 기반으로 작성된 메서드 체인은 동기형으로 작성된 동작들과는 별개의 흐름으로 순차적인 동작을 수행한다.
console.log('1');
Promise.resolve().then(() => {console.log('2');}).then(() => {console.log('3');});
console.log('4');2.2.1에서 살펴보았던 것과 마찬가지로 두 번째 줄의 Promise 코드라인은 비동기 함수 구문으로 구분되기 때문에 이벤트 루프에서 처리될 때, 동기함수의 처리를 우선하여 호출하지 않고 메시지 큐에 그대로 다시 돌려보낸다. 따라서 아래와 같은 출력을 보여준다.
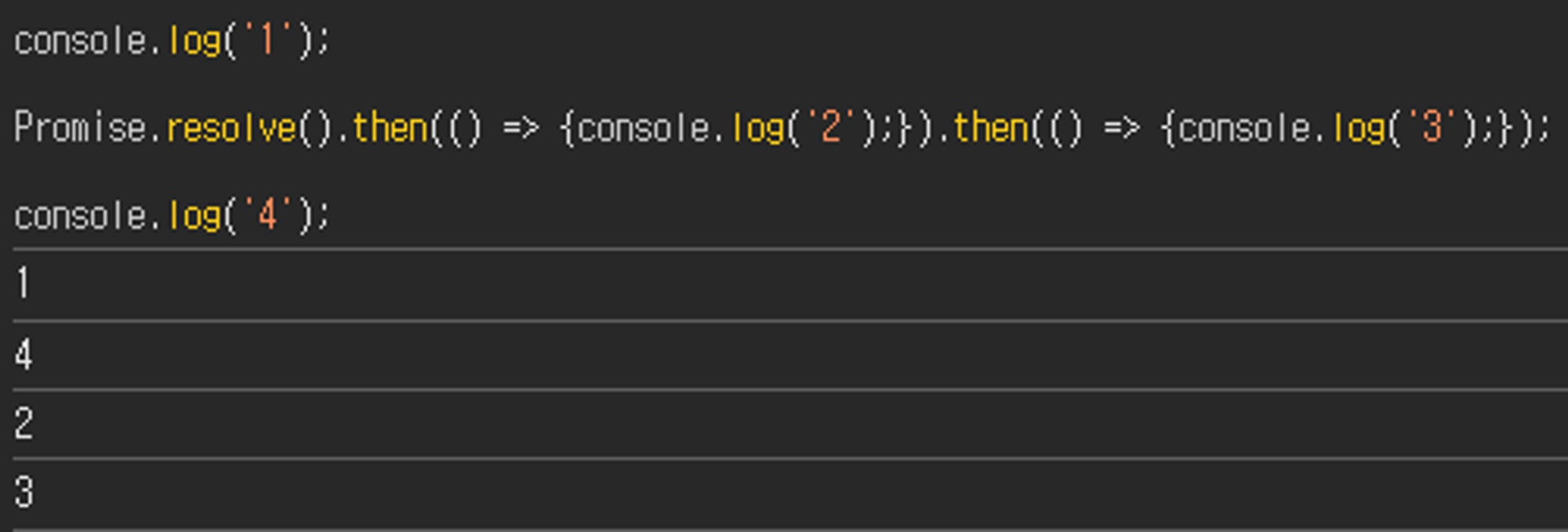
그런데, setTimeout과 Promise를 아예 같은 비동기 함수로 분류하면, 다음과 같은 문제가 발생할 수 있다.
⚠️ 메시지 큐에서 Promise 구문 메시지의 바로 뒤에 함수 호출 시기가 도래한 setTimeout 메시지가 위치한다면, then 구문을 통해서 연속적으로 실행되어야 할 context가 메시지 큐의 맨 뒤로 보내질 것이고, setTimeout 메시지가 Promise의 then 구문보다 먼저 실행되면서 원하는 연속적인 동작이 보장되지 못한다.
우리는 Promise 구문으로 작성한 코드가 정확하게 언제 실행될지 알 수 없다. 따라서 setTimeout보다 항상 앞서서 모든 Promise의 메서드 체인이 완료되도록 코드를 작성하는 데에는 무리가 있다.
JavaScript에서는 이러한 문제가 발생하지 않도록, 비동기 함수들 사이에 우선순위를 두어 태스크 큐를 “마이크로 태스크 큐”와 “매크로 태스크 큐”로 분류하고 우선순위가 높은 비동기 메시지의 경우 마이크로 태스크 큐로 관리하도록 하였다. 우리가 알고 있던 메시지 큐는 매크로 태스크 큐라고 부르면서, 마이크로 테스크 큐라는 높은 우선순위의 태스크 큐를 마이크로 태스크 큐로 따로 지정했다고 봐도 무방하다.
그러면서 2.2.1에서 작성한 이벤트 루프의 작동 규칙에 다음과 같이 규칙을 추가하게 된다.
⛓️ 이벤트 루프의 작동 규칙(with 마이크로 태스크, 매크로 태스크)
- 코드를 한 줄씩 읽으면서 처리한다.
- 코드를 처리할 때 동기 함수의 경우 함수 스택에 바로 등록한다.
- 코드를 처리할 때 비동기 함수의 경우 태스크 큐에 등록한다.
- Promise의 then, catch 등 핸들러 체인, node.js 환경에서 process.nextTick, MutationObserver 콜백 등 우선순위가 높은 비동기 함수의 경우 마이크로 테스크 큐에 등록한다.
- 코드를 한 줄씩 처리할 때마다, 함수 스택에 함수가 하나라도 존재하면 스택이 비어있을 때까지 pop하며 함수를 실행한다.
- 동기/비동기 분류 작업과 동기 동작의 실행이 전부 종료된 시점에 함수 스택이 비어있으면 매크로 태스크 큐가 비어있을 때까지 매크로 태스크 큐의 가장 오래된 메시지를 스택에 넣고 실행시킨다.
- 매크로 태스크 큐의 메시지를 처리할 때마다, 마이크로 태스크 큐에 메시지가 하나라도 존재하면 마이크로 태스크 큐가 비어있을 때까지 메시지를 pop하여 처리한다.
- 메시지가 처리될 때에도 추가적인 비동기 호출이 발생할 수 있는데, 마찬가지로 위의 우선순위가 높은 비동기 함수의 경우 마이크로 태스크 큐에 등록한다.
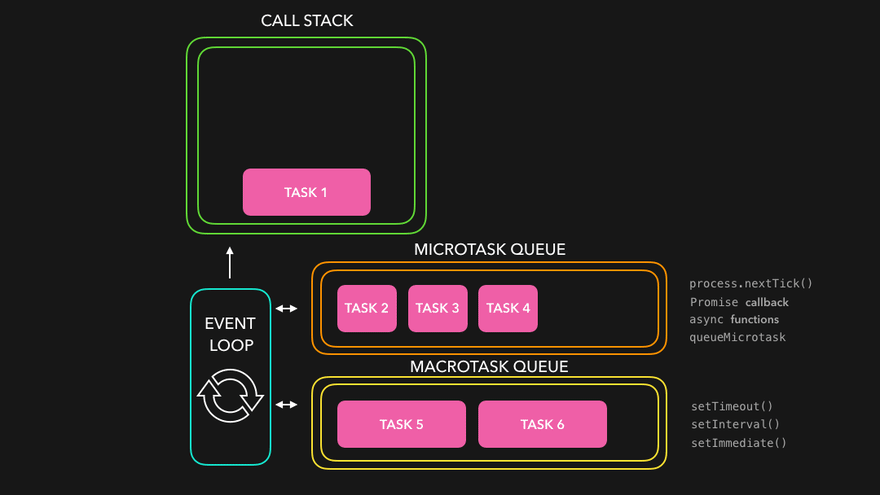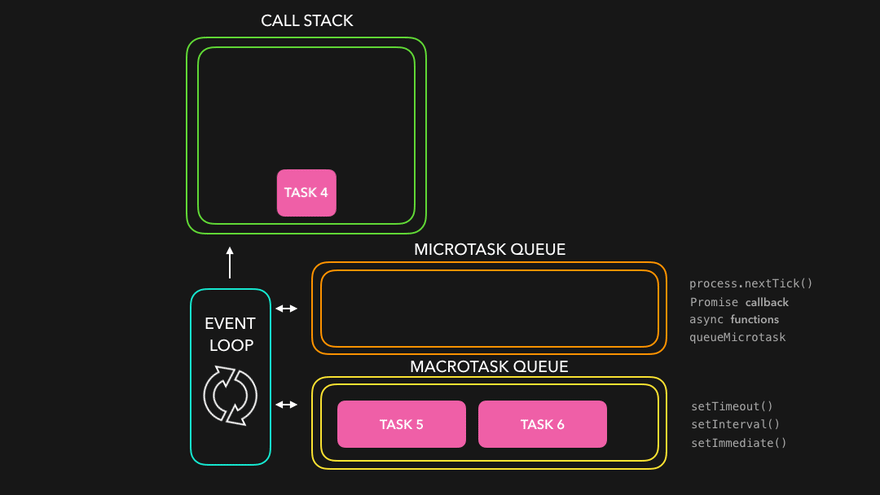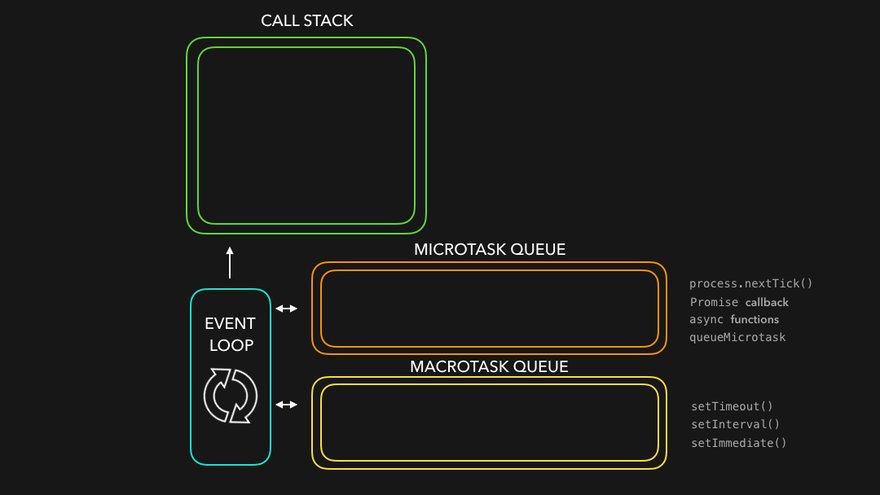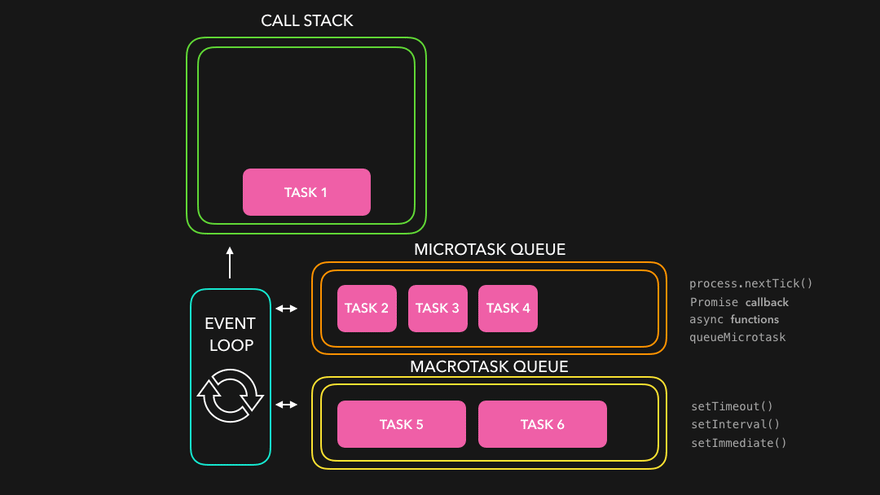
console.log('1');
setTimeout(() => { console.log('2'); }, 0);
Promise.resolve().then(() => { console.log('3'); }).then(() => { console.log('4'); });
console.log('5');만약 마이크로 태스크를 따로 분류하지 않는다면, 위의 코드의 실행 출력이 1 > 5 > 2 > 3 > 4 순으로 나타나야 한다. 하지만 실제로 실행해보면 2번째 줄의 setTimeout는 매크로 태스크 큐에 등록되고, 3번째 줄의 Promise의 then 메서드 체인들은 마이크로 태스크 큐에 등록되기 때문에, 마이크로 태스크 큐에 등록되는 Promise 함수들이 먼저 실행된다.

브라우저마다 사용되는 JavaScript 엔진이 다르기 때문에, 마이크로 태스크와 매크로 태스크의 분류 기준이 다를 수 있다. 브라우저마다 설계 시 두는 태스크들의 우선순위도 다를 수 있기 때문이다. 하지만 일반적으로 흐름 제어를 위한 구현에 있어서, 우선순위가 높으면서 연속적인 처리가 필요한 태스크들은 마이크로 태스크로 분류되고 있다고 생각해도 무방하다. 크롬의 JavaScript 엔진인 V8은 아래와 같은 함수들을 마이크로 태스크로 분류하고 있다.
- Promise의 then 및 catch 콜백
- MutationObserver 콜백
- Process.nextTick()
- QueueMicrotask()
- setImmediate()
- requestAnimationFrame 콜백
- Object.observe 콜백
- queueMicrotask()
보통 매크로 태스크로 분류되는 태스크들은 마이크로 태스크에 비해서 더 무겁고 시간이 많이 소모되는 태스크들이다.
논 블로킹 방식, 비동기 작동 방식을 지원하기 위해 사용되는 이벤트 루프 모델도 단점은 존재한다. MDN의 이벤트 루프 문서에서는 다음과 같이 이벤트 루프 방식의 단점을 이야기하고 있다.
이 모델의 단점은, 만약 메시지를 처리할 때 너무 오래 걸리면 웹 애플리케이션이 클릭이나 스크롤과 같은 사용자 상호작용을 처리할 수 없다는 점입니다. 브라우저는 "스크립트 응답 없음" 대화상자를 표시해서 이 문제를 완화합니다. 개발자로서 사용할 수 있는 좋은 방법으로는 메시지 처리를 가볍게 유지하고, 가능하다면 하나의 메시지를 여러 개로 나누는 것입니다.
MDN: 이벤트 루프
