
얼마 전에 출신 고등학교 사회 선생님한테 연락이 왔다. 나는 고등학교를 다닐 때 경제 동아리 활동을 했었는데, 그 때만 하더라도 내 기수가 2기였으니 몇 년 되지 않은 작은 동아리였다. 근데 이야기를 들어보니 벌써 10기째나 되었더라.
경제동아리였으니 사회과 과목 중에서 경제 과목에 대한 공부와 창업이나 금융에 대한 여러 교육들, 박람회나 연합 회의, 경시대회 출전 등 여러 경험들을 했었는데, 고등학교 생활에서 꼽아보자면 가장 재미있는 경험이었다.
아무튼 선생님께서는 동아리 아이들에게 간단한 코딩 강의를 해줄 수 있냐고 제안해주셨고, 경제 동아리에서 했던 경험들은 항상 재밌는 경험으로 기억에 남아있었기 때문에 흔쾌히 승낙하게 되었다.
주제 선정
일단 아이들과 함께 강의시간동안 이야기를 나눌만한 주제를 선정하여야 했다. 일단 제일 먼저 어떤 언어로 강의를 하는 게 좋을까?
물론 나는 IT와 함께 커왔지만, 요즘 아이들은 이미 커져있는 IT시장에서 살아남기 위해서 코딩 공부를 자연스럽게 하는 추세인 것 같다. 그렇다면 얘네들은 이미 코딩을 조금 해보았을테니 러닝커브가 조금 있는 언어로 강의를 해도 괜찮을까? 선생님께 여쭤봤다. 대답은 "최대한 쉽게 쓸 수 있는 것으로.."
나는 공부할 프로그래밍 언어를 선정해야한다는 이야기를 들으면 이런 생각을 한다.
코딩이라는 행위 자체로 돈을 벌고 싶다면 C 계열부터 시작해야할 것이고, 단순히 결과물만을 만들어내야 한다거나 프로그래밍 사고를 위한 학습 수준에서 그칠 것이라면 python으로 그치면 될 것이다.

여러 기준들에서 보았을 때 python으로 하는 것이 좋겠다고 생각했다.
선생님께서는 경제 동아리인 만큼 경제 데이터와 관련하여 무언가 해볼 수 있으면 좋겠다라고 말씀하셨다.
음. 그냥 코딩 이론이나 문법 등을 강의하는 게 아니라 코딩을 통해서 어떤 자동화를 이루어낼 수 있는 모습을 보여주는 게 좋겠다고 생각했고, 실습을 목표로 한 강의를 준비해야겠다는 생각을 하였다.
그리고 강의 시간은 2시간. 그렇게 길지 않은 시간이었기 때문에 시각적으로 퀄리티 있는 결과물을 만들어 내기에는 좀 무리가 있을 것이라 생각했고, 데이터를 visualization하는 과정까지는 염두에 두지 않기로 하였다.

그래서 목차는 실습을 마지막으로 하여 그 전에 짤막한 코딩 문법 및 이론 이야기, 그리고 그 전에 짧은 아이스브레이킹 시간 정도로 구성하게 되었다.
실습 구상하기
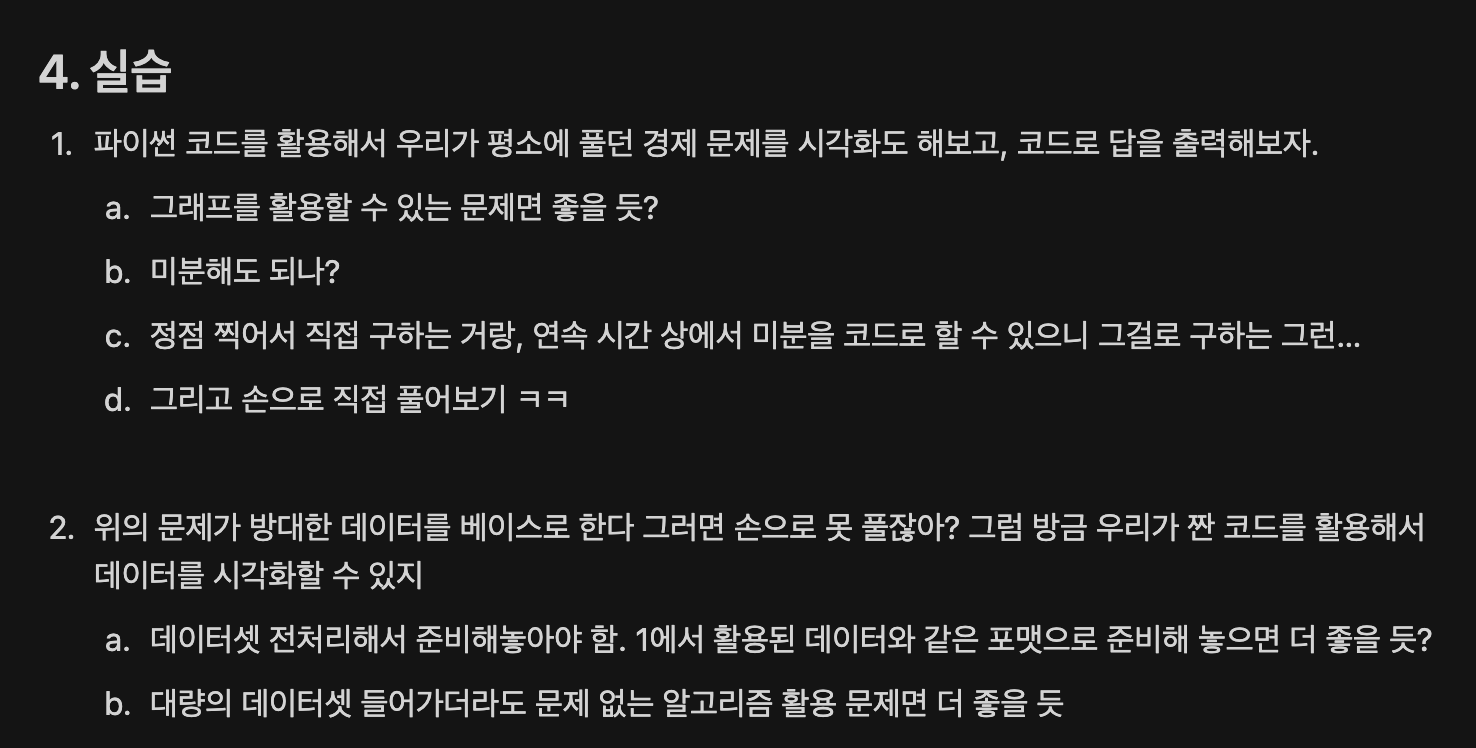
내가 재미있게 코딩을 한 경험들을 들추어보았다. 어떤 문제가 있었고, 해결 방법을 고민하고 구체화하여 코드로 작성하게 되는 그 과정. 사실 도구는 어떤 것이 되었건 상관 없다. 하지만 생산성과 반복성을 최대화할 수 있으면 좋을 것이기 때문에 그 도구는 어쩌다 코드가 되었을 것이다.
어쨋든 재미있는 코딩은 항상 재미있는 문제 상황이 시작점이었던 것 같다. 그래서 알고리즘 문제를 푸는 것처럼 어떤 문제 상황을 함께 해결해봅시다! 하는 식으로 실습 문제를 만들어야겠다고 생각했다.
하지만 실습 문제의 포맷만이 아니라, 실습 문제의 키워드도 관심을 끌 수 있어야 한다. 경제 동아리 학생들이기 때문에 경제와 관련된 키워드들이 포함되면 좋겠다는 생각에 작년 수능 경제 문제를 쭉 훑어봤다.
음...고등학교 교육 과정에서의 경제 문제들은 굉장히 가정이 많다는 생각이 들었다. 특히 거시적인 모델의 경우에는 현실 세계에서는 너무 많은 변수를 가지기 때문에 이론적으로 다루기 적절한 개념들만 남겨두고 다른 변수들에는 영향을 받지 않는다고 가정을 하게 된다.
문제는 충분히 거시적인 사이즈의 경제 모델이 아니면 실 데이터를 구하기가 쉽지 않다는 점과, 여기서 구한 데이터들은 고등학교 경제 지식에 대입했을 때 맞다 아니다를 이야기하기에 굉장히 근시안적으로 느껴질 수 있다는 점이었다.
문제에서 충분한 가정을 염두에 두면서 덜 거시적인 사이즈의 경제 모델을 활용할 수 있도록 해야겠다는 생각을 하였다. 아니면 가정이 필요 없는 수치 계산만으로 충분한 문제를 만들던가 해야했다.

여러 문제 후보들이 생겼고, 그 중에서 두 가지를 선정하게 되었다. 하나는 덜 어려우면서 코드만으로 해결할 수 있는 내용. 하나는 조금 복잡하게도 기상청 API를 받아와야 하는 내용.
아래에 몇 문제들을 적어놓았는데, 그 중에서 마지막 2개를 선정해서 아이들과 실습하였다.
경제성장률 계산하기
개념
문제
꼬미쌤은 행복한 노후를 보내기 위해 살기 좋은 나라라고 유명한 A국으로의 이민을 고민하고 있다.
꼬미쌤은 사랑하는 자녀들이 부유한 국가에서 크기를 바라기 때문에, A국의 경제가 최근에 어떤 식으로 흘러가고 있는지 분석해보고 싶어하신다. 국가의 성장 기대치는 경제성장률 지표에서 알 수 있기 때문에, 꼬미쌤은 경제성장률을 기반으로 하여 나라의 경제 현황을 파악하려고 한다.
하지만 꼬미쌤은 동아리 학생들의 생기부에 도움을 주기 위해 고군분투하고 계셔서 A국의 경제성장률을 구할 마땅한 시간이 없으시다.
고민하시는 꼬미쌤의 찬란한 노후를 위해서 A국의 각 연도에 대한 경제성장률을 대신 구해드리자.
예시 코드
import os
A_path = './물가정보.txt'
B_path = './거래정보.txt'
mode = 'r'
# 입력 전처리
물가정보 = []
거래정보 = []
with open(A_path, mode) as fileA:
streamA = fileA.readline()
while streamA:
streamArray = streamA.strip().split(',')
물가정보.append([int(streamArray[0]), float(streamArray[1])])
streamA = fileA.readline()
with open(B_path, mode) as fileB:
streamB = fileB.readline()
while streamB:
streamArray = streamB.strip().split(',')
거래정보.append([int(streamArray[0]), streamArray[1], int(streamArray[2])])
streamB = fileB.readline()
# 선언
명목GDP = [0 for _ in range(len(물가정보))]
실질GDP = [0 for _ in range(len(물가정보))]
경제성장률 = [0 for _ in range(len(물가정보))]
startYear = 물가정보[0][0]
print(*list(map(lambda x:str(x[0]) + '년', 물가정보)), sep="\t")
# 명목GDP 구하기
for 연도,항목,금액 in 거래정보:
if 항목 == "수입":
명목GDP[연도 - startYear] -= 금액
else:
명목GDP[연도 - startYear] += 금액
print(*명목GDP, sep="\t")
# 실질GDP 구하기
for 연도,물가지수 in 물가정보:
실질GDP[연도 - startYear] = int(명목GDP[연도 - startYear] * 물가지수)
print(*실질GDP, sep="\t")
# 경제성장률 구하기
for 연도,물가지수 in 물가정보:
if 연도 == startYear:
continue
temp = ((실질GDP[연도 - startYear] - 실질GDP[연도 - startYear - 1]) / 실질GDP[연도 - startYear]) * 100
경제성장률[연도 - startYear] = int(temp * 10) / 10
print(*경제성장률, sep="\t")결과

테스트 데이터 생성 코드
import random
import math
import os
pathA = './물가정보.txt'
pathB = './거래정보.txt'
mode = 'w'
GENERATE_COUNT = 10000
NATION_CASES = ['a']
DETAIL_CASES = ['소비','투자','정부구입','수입','수출']
YEAR_CASES = [2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023]
AMOUNT_RANGE = [50, 200]
PRICE_RANGE = [0.5, 1.5]
def getAccumulatedProb(count):
return [ ((i + 1) / count) for i in range(count) ]
def getRandomIndex(accumulatedProb):
rand = random.random()
for i in range(len(accumulatedProb)):
if rand < accumulatedProb[i]:
return i
return len(accumulatedProb) - 1
def generateNewTradeData(count):
probNation = getAccumulatedProb(len(NATION_CASES))
probDetail = getAccumulatedProb(len(DETAIL_CASES))
probYear = getAccumulatedProb(len(YEAR_CASES))
amountStart, amountEnd = AMOUNT_RANGE
probAmount = getAccumulatedProb(amountEnd - amountStart + 1)
results = []
for _ in range(count):
randNation = NATION_CASES[getRandomIndex(probNation)]
randDetail = DETAIL_CASES[getRandomIndex(probDetail)]
randYear = YEAR_CASES[getRandomIndex(probYear)]
randAmount = AMOUNT_RANGE[0] + getRandomIndex(probAmount)
row = [randYear, randDetail, randAmount]
results.append(row)
with open(pathB, mode) as file:
file.write('\n'.join(list(map(lambda x: ','.join(list(map(str, x))), results))))
def generateNewPriceData():
priceStart, priceEnd = PRICE_RANGE
probPrice = getAccumulatedProb(math.ceil((priceEnd - priceStart) * 10) + 1)
results = []
for i in range(len(NATION_CASES)):
for j in range(len(YEAR_CASES)):
randPrice = 1.0 if j == 0 else int(PRICE_RANGE[0] * 10 + getRandomIndex(probPrice)) / 10
nation = NATION_CASES[i]
year = YEAR_CASES[j]
row = [year, randPrice]
results.append(row)
with open(pathA, mode) as file:
file.write('\n'.join(list(map(lambda x: ','.join(list(map(str, x))), results))))
def main():
generateNewPriceData()
# generateNewTradeData(GENERATE_COUNT)
if __name__ == "__main__":
main()수익률 계산하기 문제
개념
수익률(Return Of Investment): (순이익 / 투자금) * 100
순이익 = 회수금 - 투자금
문제
우리나라에서는 공직자윤리법 제 2조 제 2항, 제 10조 제 1항에 의거하여, 4급 이상의 공무원은 주식 거래가 금지되어 있다. 또한 선출직 공무원은 지지율이 중요하기 때문에 투자에 조심스러울 수 밖에 없다.
전국의 모든 고등학교에 에코동을 신설하기 위해 교육감으로 입후보하려는 꼬미쌤은 교육감으로 선출되면 재산 투자에 감시를 받게 되는 것이다.
따라서 꼬미쌤은 교육감에 출마하기 이전에 세계음식협회에서 운용하는 금융상품을 활용해서 재산을 불려놓을 계획이다. 세계음식협회는 다양한 금융상품을 운용하는데, 각각 수익률이 모두 다르며 이름이 음식이름이다.
하지만 꼬미쌤은 교육감 출마를 준비하기 위해 매우 바쁘기 때문에 금융상품들의 수익률을 직접 계산할 시간적 여유가 없다.
에코동의 번영을 위해 주어지는 금융상품 중에 가장 수익률이 가장 높은 상품을 찾아 꼬미쌤을 도와주자.
금융상품 목록
| 이름 | 투자금 | 회수금 |
|---|---|---|
| 믿음직한 곱창 | 600 | 3200 |
| 협조적인 스키야키 | 3200 | 11500 |
| 대담한 양념치킨 | 2500 | 14200 |
| 온화한 알밥 | 6200 | 14100 |
| 고상한 쭈꾸미볶음 | 9400 | 13300 |
예시 코드
import os
filePath = './금융상품목록.txt'
mode = 'r'
# 입력 전처리
금융상품목록 = []
with open(filePath, mode) as fileA:
streamA = fileA.readline()
while streamA:
streamArray = streamA.strip().split(',')
금융상품목록.append([streamArray[0], int(streamArray[1]), int(streamArray[2])])
streamA = fileA.readline()
for 순서 in range(len(금융상품목록)):
이름, 투자금, 회수금 = 금융상품목록[순서]
#수익금 구하기
수익금 = 회수금 - 투자금
금융상품목록[순서].append(수익금)
#수익률 구하기
수익률 = int((수익금 / 투자금) * 1000) / 10
금융상품목록[순서].append(수익률)
#최고수익률상품 구하기
최고수익률상품 = ['',0,0,0,0]
for 순서 in range(len(금융상품목록)):
이름, 투자금, 회수금, 수익금, 수익률 = 금융상품목록[순서]
if 최고수익률상품[4] < 수익률:
최고수익률상품 = [이름, 투자금, 회수금, 수익금, 수익률]
print(*최고수익률상품, sep="\t")테스트 데이터 생성 코드
import random
import math
import os
filePath = './금융상품목록.txt'
mode = 'w'
ADJECTIVES = [ "행복한", "기쁜", "즐거운", "만족한", "신나는", "열광적인", "명랑한", "들뜬", "환희에 찬", "희망찬", "자신감 있는", "차분한", "편안한", "용감한", "대담한", "모험적인", "우아한", "고상한", "매력적인", "잘생긴", "매력적인", "똑똑한", "현명한", "영리한", "빛나는", "박식한", "친절한", "관대한", "동정심 있는", "동정적인", "친근한", "충실한", "성실한", "신뢰할 수 있는", "정직한", "진실한", "근면한", "성실한", "부지런한", "생산적인", "야심찬", "예의 바른", "공손한", "사려 깊은", "존경하는", "창의적인", "기발한", "상냥한", "자비로운", "온화한", "참을성 있는", "용서하는", "용기 있는", "열정적인", "성실한", "겸손한", "인내심 있는", "신뢰할 수 있는", "유머러스한", "낙천적인", "상냥한", "재능 있는", "독창적인", "헌신적인", "충성스러운", "용맹한", "사려 깊은", "성실한", "긍정적인", "활기찬", "열정적인", "적극적인", "공감하는", "인정 많은", "기운찬", "믿음직한", "열렬한", "기운찬", "자신감 있는", "생기 있는", "행운의", "활발한", "지혜로운", "믿을 만한", "깨끗한", "청결한", "정리된", "잘 정돈된", "효율적인", "체계적인", "신뢰성 있는", "유능한", "기술 좋은", "책임감 있는", "적응력 있는", "유연한", "협조적인", "팀워크 좋은", "매너 있는", "독립적인" ]
FOODS = [ "김치", "비빔밥", "불고기", "된장찌개", "삼겹살", "갈비찜", "잡채", "순두부찌개", "떡볶이", "해물파전", "김밥", "냉면", "설렁탕", "육개장", "감자탕", "닭갈비", "찜닭", "닭강정", "해물탕", "수제비", "라면", "콩나물국", "부대찌개", "쭈꾸미볶음", "골뱅이무침", "낙지볶음", "꼬막무침", "순대", "족발", "보쌈", "소불고기", "양념치킨", "후라이드치킨", "찜질방계란", "오징어볶음", "된장국", "콩비지찌개", "물냉면", "비빔냉면", "동치미", "동태찌개", "북엇국", "미역국", "육전", "갈비탕", "삼계탕", "생선구이", "새우튀김", "오뎅", "문어숙회", "전복죽", "육회", "곱창", "대창", "막창", "초밥", "참치회", "연어회", "회덮밥", "알밥", "우동", "덴푸라", "타코야키", "돈까스", "카레라이스", "오코노미야키", "야키소바", "라멘", "스키야키", "샤부샤부", "피자", "스파게티", "라자냐", "리조또", "파스타", "치즈버거", "핫도그", "프렌치프라이", "샌드위치", "토스트", "팟타이", "쌀국수", "카오팟", "반미", "솜땀", "마파두부", "딤섬", "탕수육", "깐풍기", "마라탕", "훠궈", "초밥", "우동", "덮밥", "타코", "브리또", "퀘사디아", "치즈나쵸", "칠리콘카르네", "파히타" ]
START_PRICE_RANGE = [1, 10000]
END_PRICE_RANGE = [7500, 20000]
randomNames = []
def getAccumulatedProb(count):
return [ ((i + 1) / count) for i in range(count) ]
def getRandomIndex(accumulatedProb):
rand = random.random()
for i in range(len(accumulatedProb)):
if rand < accumulatedProb[i]:
return i
return len(accumulatedProb) - 1
def generate():
startPriceStart, startPriceEnd = START_PRICE_RANGE
probStartPrice = getAccumulatedProb(startPriceEnd - startPriceStart + 1)
endPriceStart, endPriceEnd = END_PRICE_RANGE
probEndPrice = getAccumulatedProb(endPriceEnd - endPriceStart + 1)
results = []
for randName in randomNames:
randStartPrice = START_PRICE_RANGE[0] + getRandomIndex(probStartPrice)
randEndPrice = END_PRICE_RANGE[0] + getRandomIndex(probEndPrice)
row = [randName, randStartPrice, randEndPrice]
results.append(row)
with open(filePath, mode) as file:
file.write('\n'.join(list(map(lambda x: ','.join(list(map(str,x))), results))))
def main():
for adj in ADJECTIVES:
for food in FOODS:
randomNames.append(adj + ' ' + food)
random.shuffle(randomNames)
generate()
if __name__ == "__main__":
main()우산가격 정하기 문제
문제
국가공무원법 제63조(품위 유지의 의무)
공무원은 직무의 내외를 불문하고 그 품위가 손상되는 행위를 하여서는 아니 된다.
국가공무원법 제64조(영리 업무 및 겸직 금지)
① 공무원은 공무 외에 영리를 목적으로 하는 업무에 종사하지 못하며 소속 기관장의 허가 없이 다른 직무를 겸> 할 수 없다.
공무원 복무규정 제25조 본문에 따른 금지요건
• 공무원의 직무 능률을 떨어뜨릴 우려가 있는 경우
꼬미쌤은 부업으로 우산 장사를 하고 있다.
하지만 공무원의 겸직에는 조건이 있다. 공무원 복무규정 제 63조에 따라 “품위유지”라는 공무원의 의무를 지켜야하기 때문에, 꼬미쌤의 품위상 항상 최고의 매출을 내야만 한다.
우산의 수요는 강수확률에 민감하게 반응한다. 강수확률이 높아지면 우산의 수요는 증가하고, 강수확률이 낮아지면 우산의 수요는 감소한다.
꼬미쌤은 일기예보의 강수확률과 우산의 수요함수를 활용하여 총 매출액을 최대화할 수 있는 판매가격을 책정하려고 한다. 꼬미쌤은 매일 다음과 같은 방법으로 가격을 책정한다.
- 기상청 예보를 확인하여 강수확률을 알아낸다.
- 강수확률을 토대로 예상되는 우산의 수요함수를 도출한다.
- 우산의 수요함수를 활용하여 가장 많은 매출액을 얻을 수 있는 가격을 찾는다.
하지만 공무원의 겸직은 담당 직무수행에 지장이 없어야 하는데, 예보를 매일 확인하여 가격을 책정하는 것이 너무 번거로운 일이라 꼬미쌤의 직무수행에 지장을 줄 수 있다.
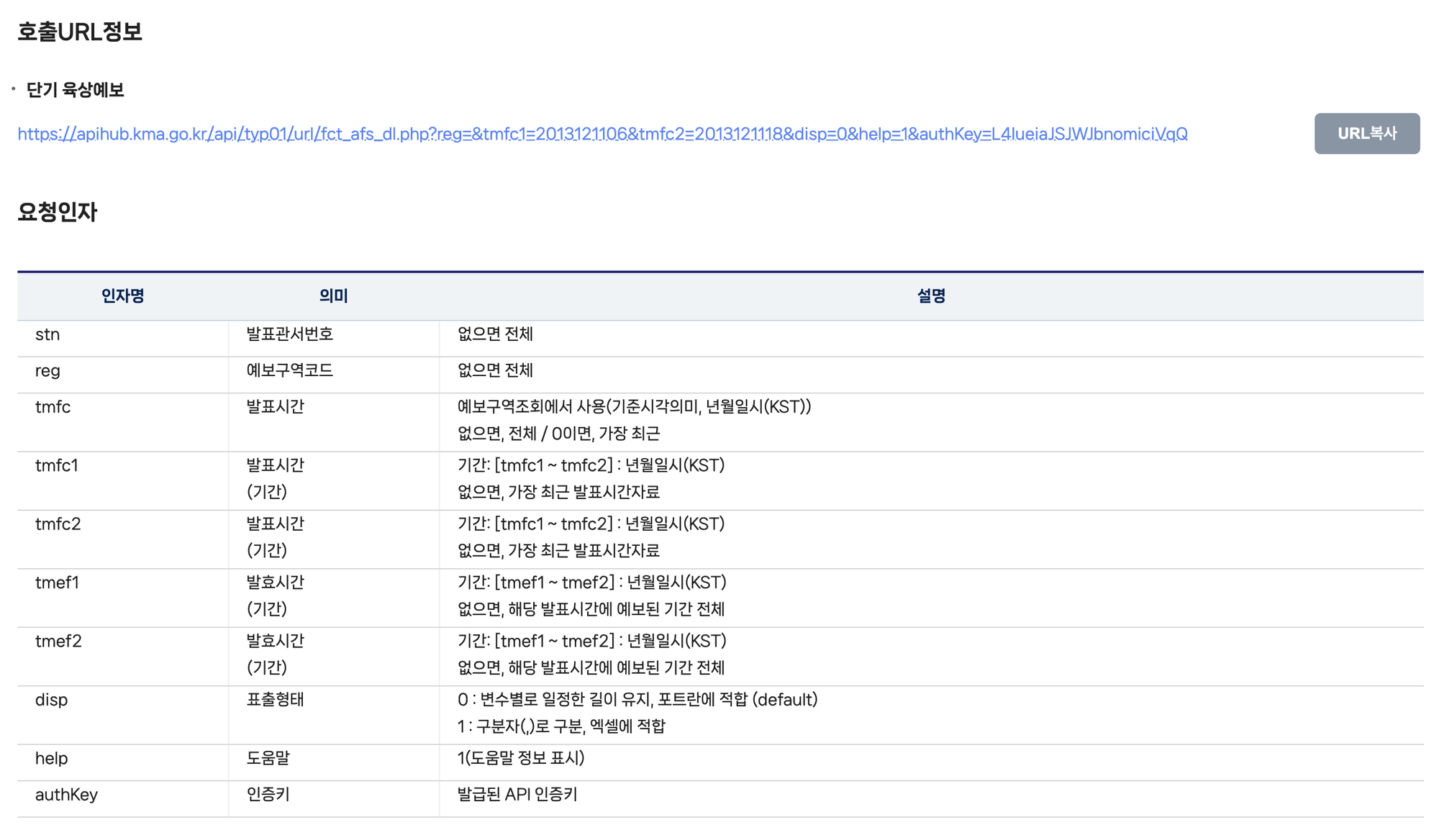
꼬미쌤의 품위유지와 직무수행을 위해 우산의 판매가격을 자동으로 책정해주는 프로그램을 작성해드리자.
예시 코드
import requests
import math
r = requests.get('https://apihub.kma.go.kr/api/typ01/url/fct_afs_dl.php?reg=11B20401&disp=0&help=1&authKey=&help=0')
lines = r.text.split('\n')
data = []
for line in lines:
if len(line) < 1:
continue
if line[0] == '#':
continue
data.append(line.split())
def 우산가격계산(강수확률):
return 강수확률 + 25
def 최대매출계산(강수확률):
return 2 * (강수확률 + 25) ** 2
for data in data:
시작시간 = data[2]
기온 = data[12]
강수확률 = int(data[13])
우산가격 = 우산가격계산(강수확률)
최대매출 = 최대매출계산(강수확률)
수요량 = 최대매출 // 우산가격
print("["
+ (시작시간[0:4] + "년 ")
+ (시작시간[4:6] + "월 ")
+ (시작시간[6:8] + "일 ")
+ ("오후" if 시작시간[8:10] == "12" else "오전")
+ "]"
+ "기온: " + 기온 + "도\t"
+ "강수확률: "+ str(강수확률) + "%\t"
+ "우산가격: " + str(우산가격) + "원\t"
+ "수요량: " + str(수요량) + "명\t"
+ "최대매출: " + str(최대매출) + "원\t"
)결과

풀이
수요함수
우리가 알고 있는 수요곡선은 좌표평면 위에 있는 수요함수의 그래프를 의미한다.
내 기억으로 고등학교 경제에서는 문제를 풀 때 수요함수 자체를 받아와서 이를 수식으로 활용하는 과정은 나오지 않는다.(수학 과목에 대한 의존성 때문인 것 같다.)
우리가 알고 있는 수요곡선이라는 녀석으로 수요함수의 수식 형태가 어떤지 유추해볼 수 있다. 수요곡선이 그려지는 좌표평면은 X축이 가격, Y축이 판매량이다. 그렇다면 다음과 같은 형태의 함수를 작성할 수 있다.
임의의 f에 대하여 P와 Q_d의 관계를 나타내는 함수를 우리는 수요함수라고 부를 수 있는 것이다.
→ f가 어떻게 추정되는지에 따라 수요곡선의 형태도 바뀔 수 있고, 해당 재화가 가지고 있는 특성을 파악할 수도 있게 된다.
수요함수의 결정
수요함수에서 f는 어떻게 결정될까?
수학에서는 매개변수라는 개념이 존재한다. 매개변수는 다양한 값을 취할 수 있는 함수나 방정식 내의 변수를 의미한다. 또한 매개변수는 여러 개가 될 수 있다. 그러니까, 우리가 일반적으로 알고 있는 일차함수: y = ax + b에서 a와 b를 매개변수라고 부를 수 있다.
대부분의 경제 모델은 사회적인 인과관계를 수식으로 표현하는 데에서 시작된다. 하지만 사회적으로 발생하는 관계는 자연현상과 같이 개입되는 모든 변수를 파악하는 것이 불가능하다. 따라서 단순한 경제 모델에 대해서 이야기하기 위해서는 대부분의 변수에 해당 모델이 영향을 받지 않는다는 조건을 달아야 한다. (A의 수요량은 가격 이외의 영향을 받지 않는다.)와 같은 문장으로 말이다.
f가 결정되는 데에는 아주 다양한 요소들이 있을 수 있다. 보완재와 대체제의 가격, 소비자의 소득수준이나 선호도, 가격에 대한 기대나 심지어는 환율변동 같은 거시적인 지표들까지도 이에 포함될 수 있다. 근데 우리가 걔네까지 전부 고려해서 함수를 짜기에는 너무 버겁다. 그러니까 다음과 같은 수요함수를 하나 작성해보자.
자. 공짜로 팔면 100개가 팔린다. 근데 가격이 올라갈 때마다 수요량이 감소한다. 일반적인 선형 수요함수이다. 그럼 이 수요함수가 우산의 수요함수라고 생각해보자.
우산은 강수량에 따라서 수요함수가 바뀔 수 있다. 강수량이 0%에서 1%p만큼 증가할 때마다 수요량이 4씩 증가한다고 해보자. 그럼 다음과 같이 표현할 수 있다.
일차함수의 평행이동을 생각해보자. R값이 바뀌면 수요함수는 가격 축에 대해 양의 방향으로 평행이동하게 될 것이다. 강수확률 값에 따라서 수요함수가 결정되는 것이다.
총매출의 최대화
만약에 우산의 가격이 어떻든 수요함수에서 얻을 수 있는 수요량만큼 전량 팔린다고 가정한다면, 우리가 벌어들일 수 있는 총 매출을 최대화하기 위해서는 어떤 가격으로 우산을 팔아야 할까?
총매출을 최대화하는 우산가격을 구해보자.
총매출을 최대화하기 위해서는 총매출함수를 구해야 한다. 총매출은 간단하게 가격과 판매량을 곱해서 구할 수 있다.
위에서의 수요함수만큼 판매량이 보장되기 때문에, 다음과 같이 적을 수 있다.
따라서 총매출함수는 다음과 같이 정리된다.
총매출함수는 가격에 대해 위로 볼록한 이차함수인 것이다. 이차함수는 실수 전체 범위에서 최대값을 갖는다. 우리는 중학생이 아니니까 미분으로 최대값을 구해보자.
총매출을 최대화하는 가격은 25+R이다. 총매출의 최대값은 위에서 구했던 총매출함수에 가격을 대입하여 구할 수 있다.
이런 과정을 거쳐서 우리는 강수확률에 따라 꼬미쌤이 설정해야하는, 총매출을 최대화하는 우산의 가격을 책정할 수 있게 되었다. 또한 이를 통해 총매출을 예상할 수도 있으니, 꼬미쌤이 가계부를 쓰시는 데에 도움이 더 되리라.
자, 근데 아직 문제는 남아있다. 강수확률 R은 일정하지 않기 때문에 항상 선생님은 우산의 가격을 책정하기 위해서 기상예보를 찾아보셔야 한다. 이런 번거로움을 해결해주기 위해 우리가 기상청에서 데이터를 받아와서 자동으로 계산해주도록 하자.
기상청 단기 예보 강수량 정보 받아오기: 기상청 API허브
실습 환경 구축하기
자, 문제는 준비가 되었으니 이제 아이들이 최대한 효율적으로 문제에만 집중할 수 있도록 실습 환경을 구축해보자.
일단 컴퓨터실에서 강의를 할 수 있는가? No.
아이들에게 공통된 하드웨어 환경을 제공할 수 있는가? No.
아이들이 파이썬 버전 등 환경 설정을 맞춰줄 시간적 여유가 있는가? No.
자연스럽게 클라우드 환경에서 실습을 진행해야겠다는 생각이 들었다. colab을 활용해서 아이들의 환경설정 시간을 최소화할 수 있게 안내해주기로 하였고, 실습에 필요한 플레이트 코드들은 Jupyter Notebook 포맷(jpynb)으로 작성하고, public github repository에 올려두어서 바로 검색하여 받아올 수 있도록 설정해주었다.
깃허브 레포지토리 주소: https://github.com/eco-dong/coding_with_eco_dong_24_06
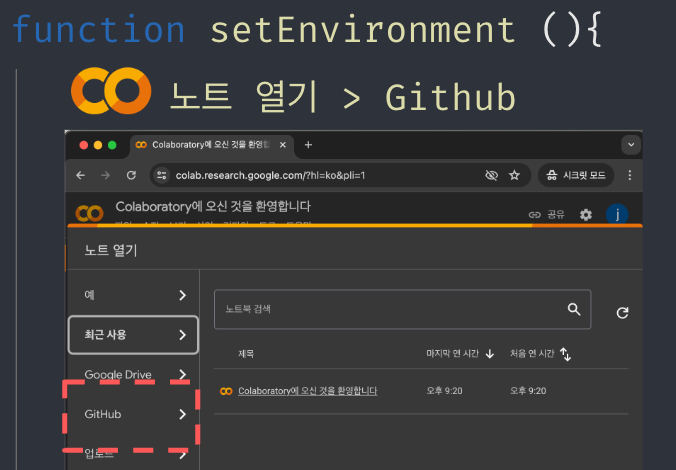
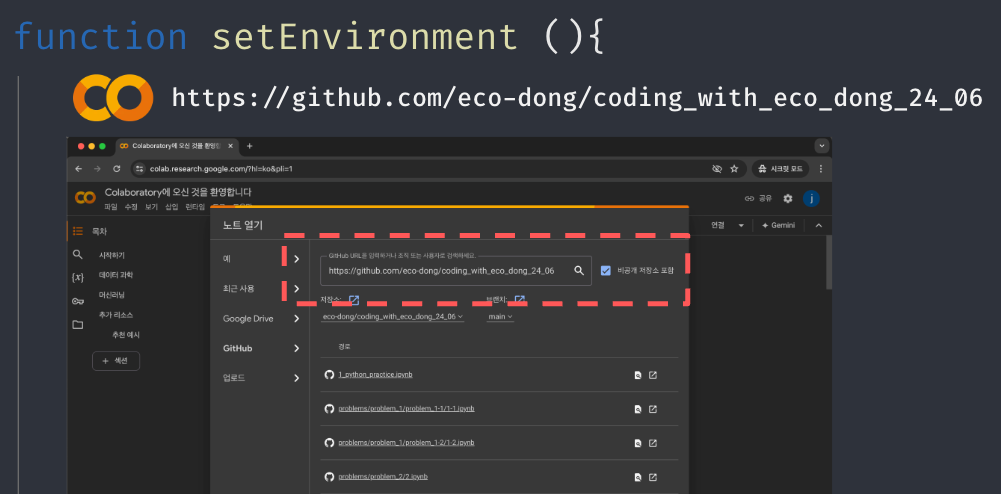
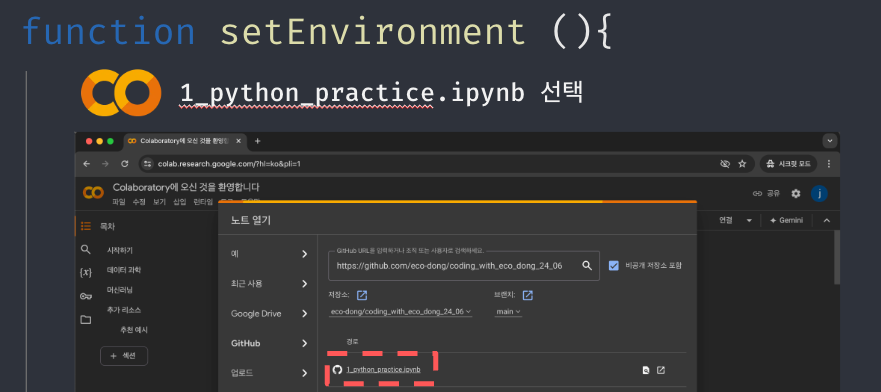
실습에 필요한 개념 강의 준비
무턱대고 문제만 던져주고 코딩해봐라.할 수는 없었다. 그래서 파이썬의 기본 문법들을 최소한으로 훑어보고 시작해야겠다고 생각했으며, 문제를 풀기 위해서 필요한 기본 개념들은 아래와 같다고 생각해 강의 자료를 구성했다.

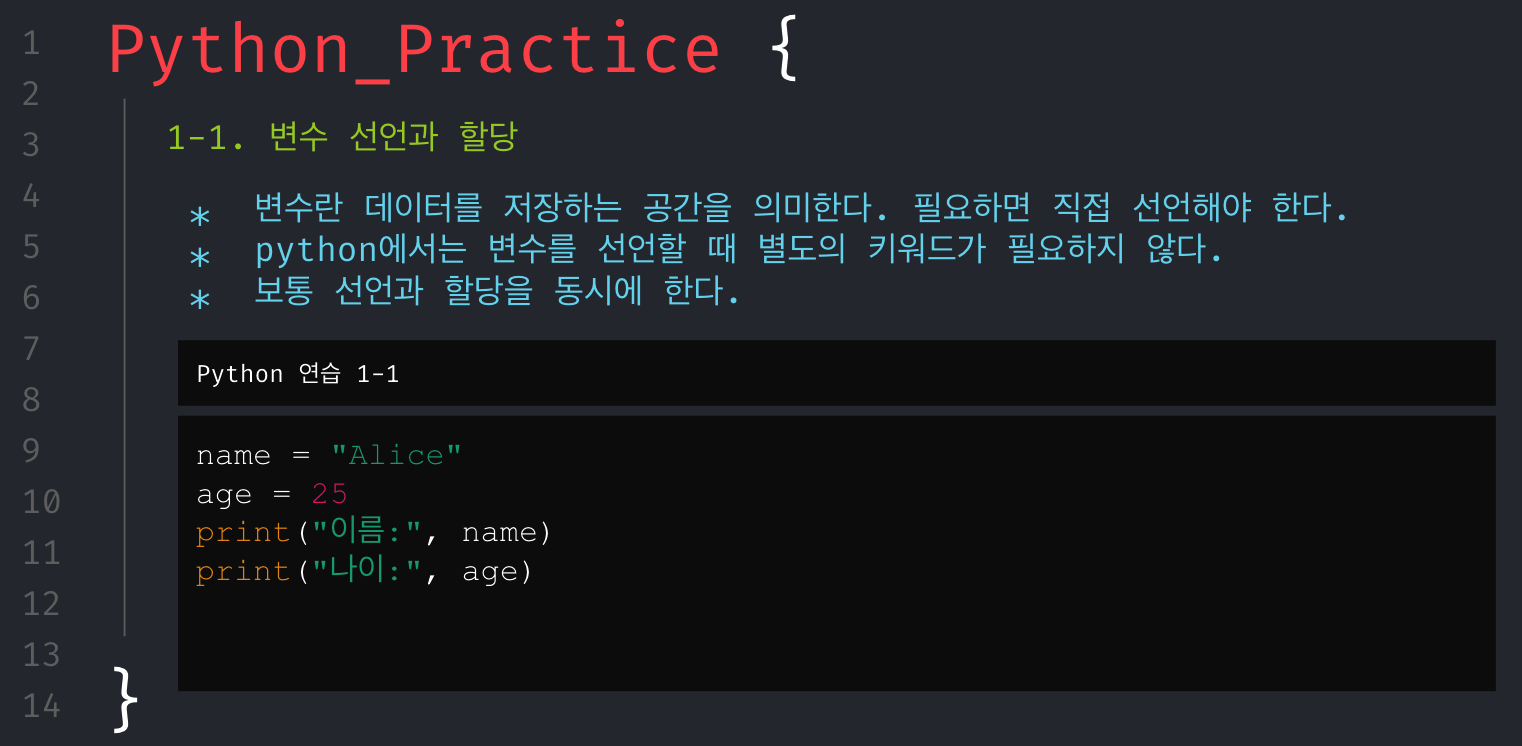
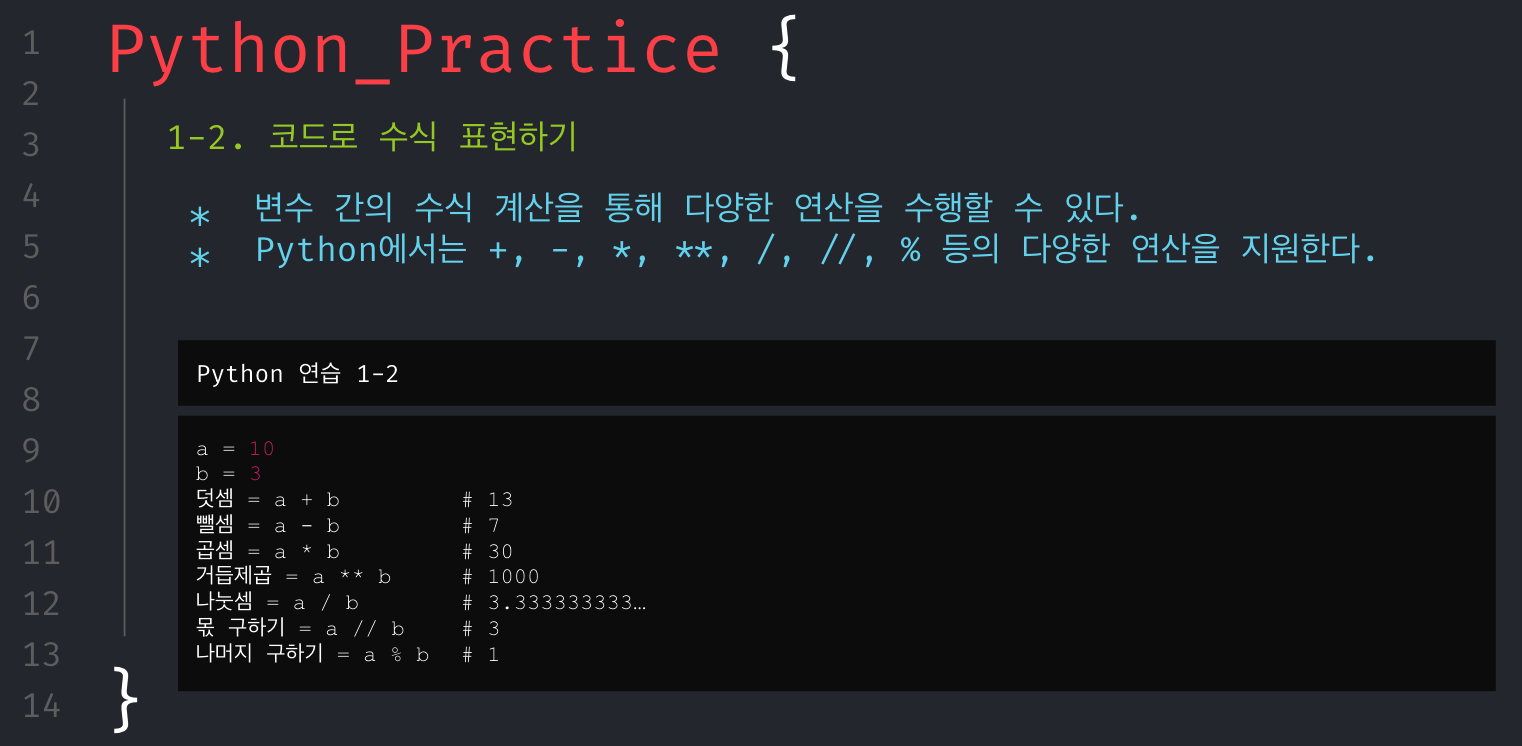
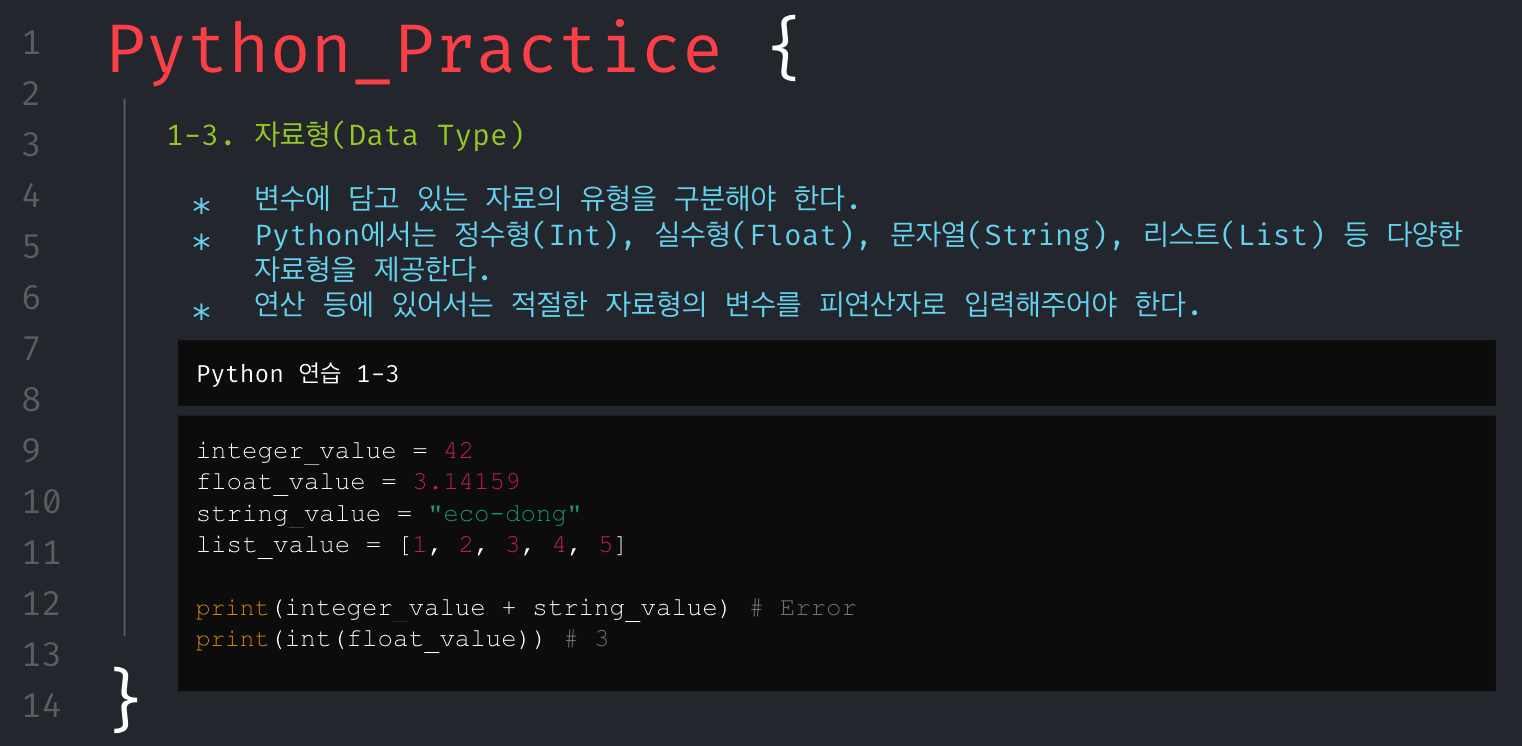
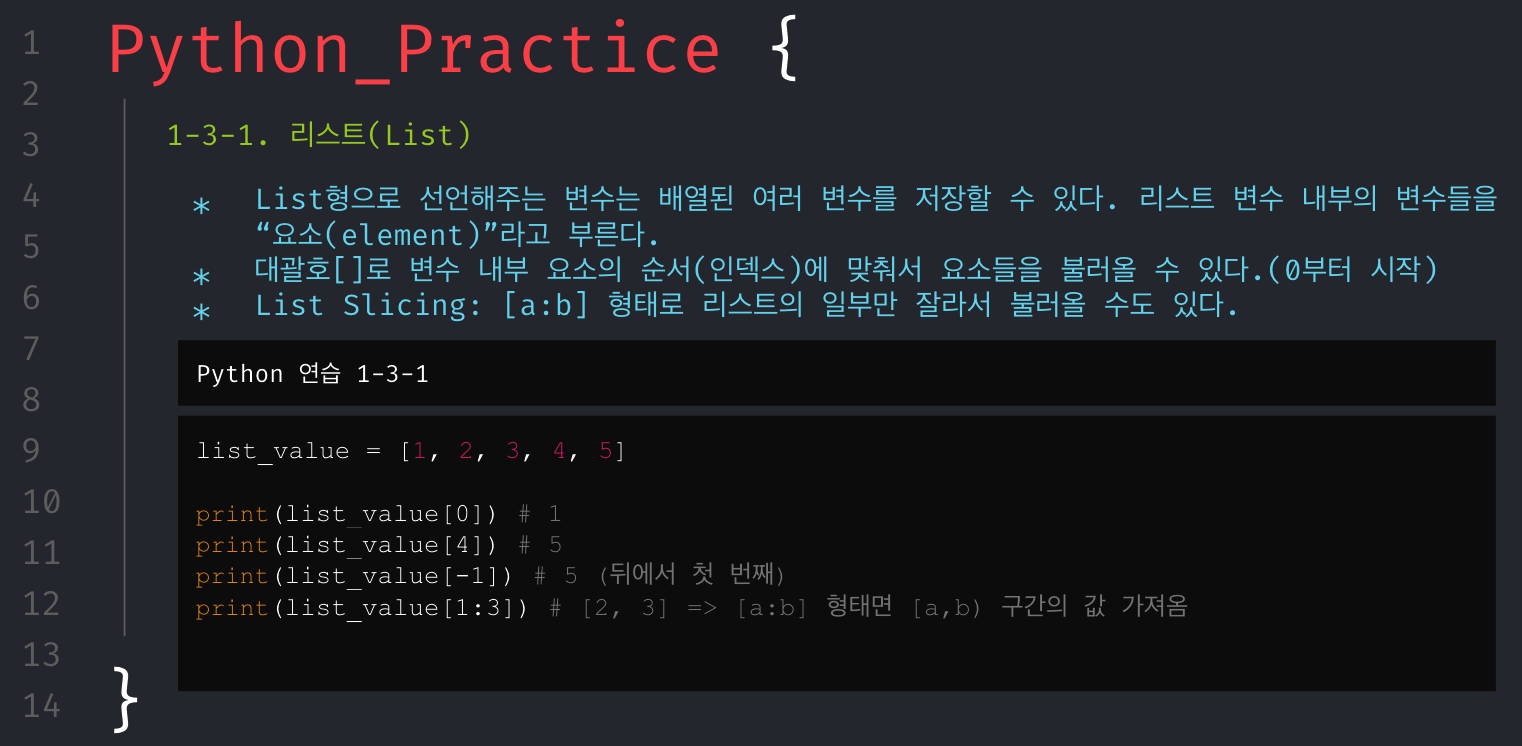
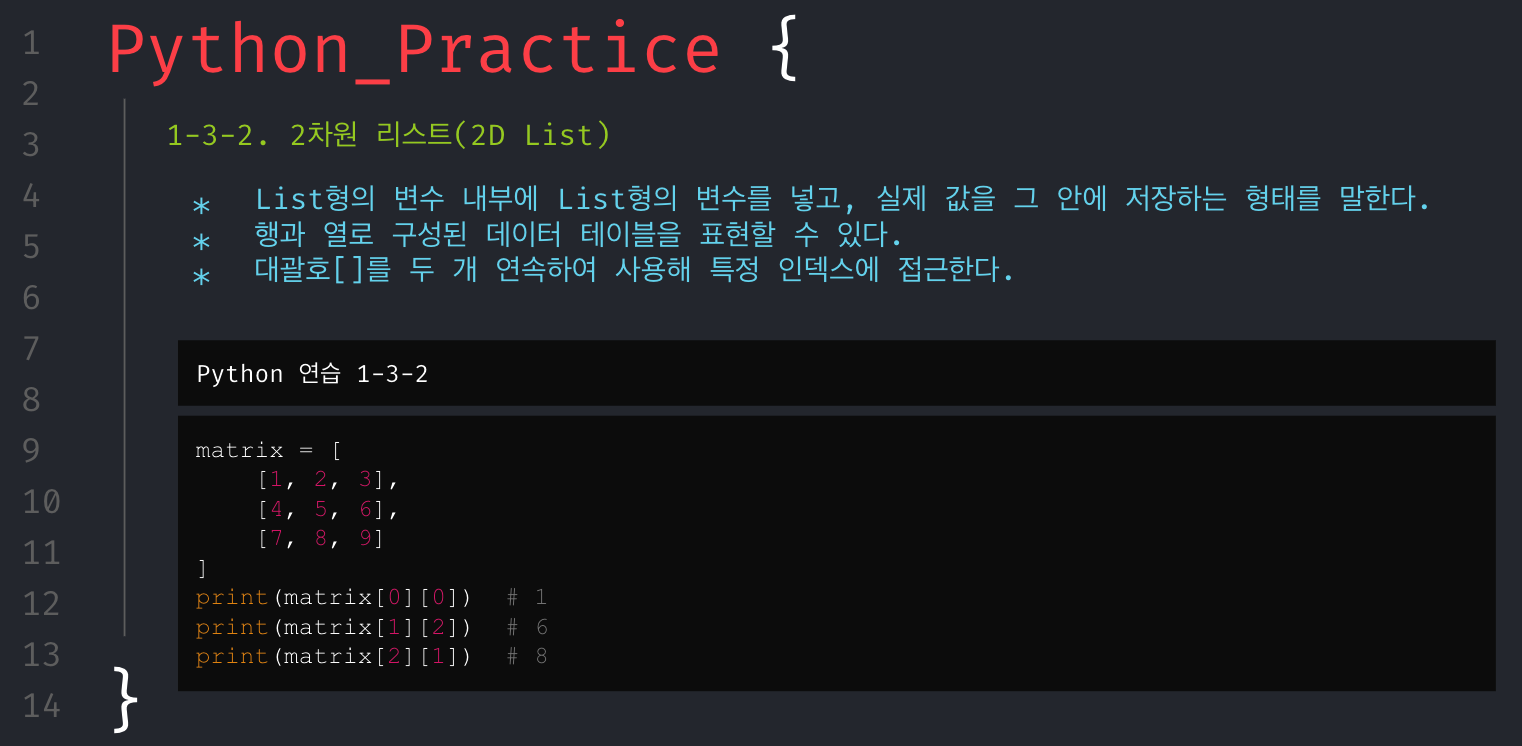
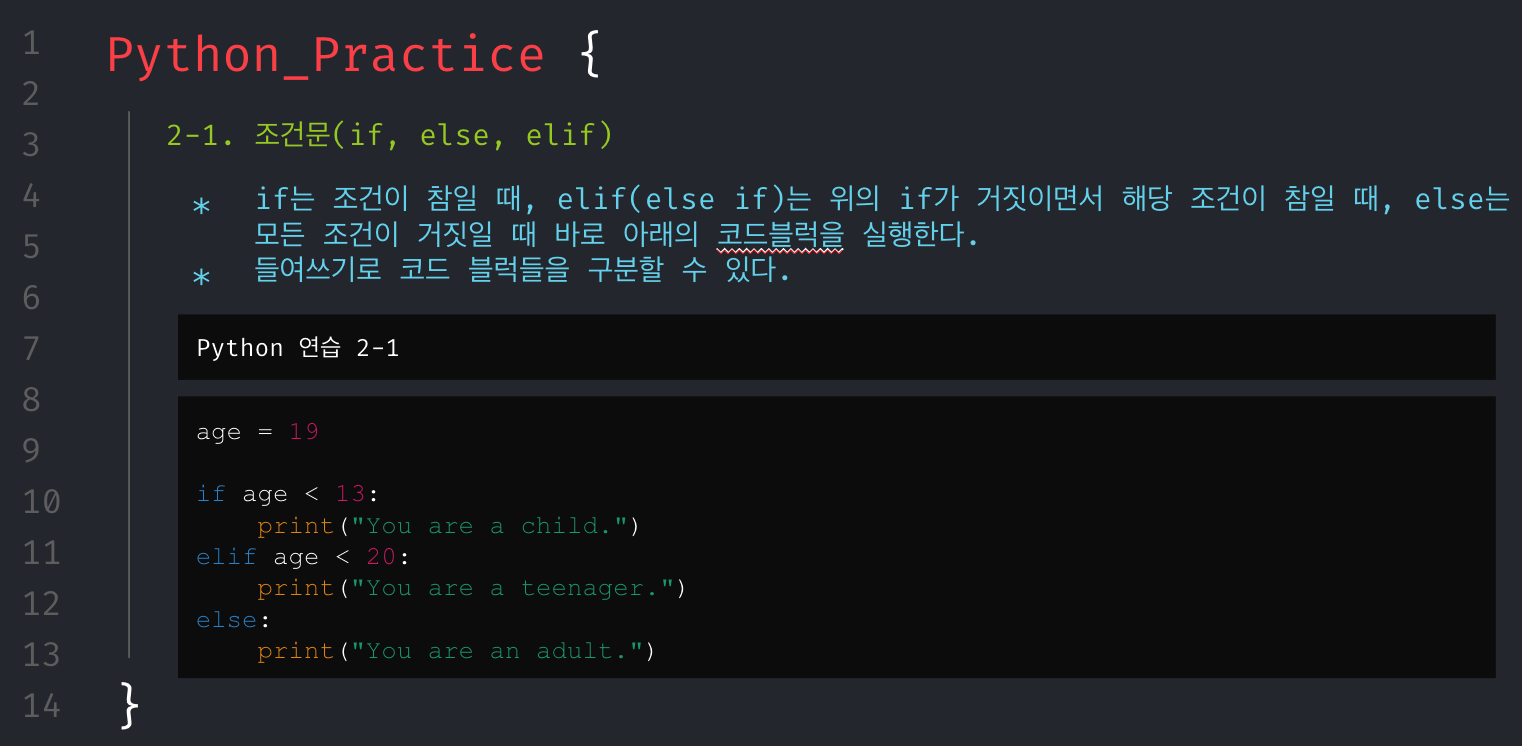
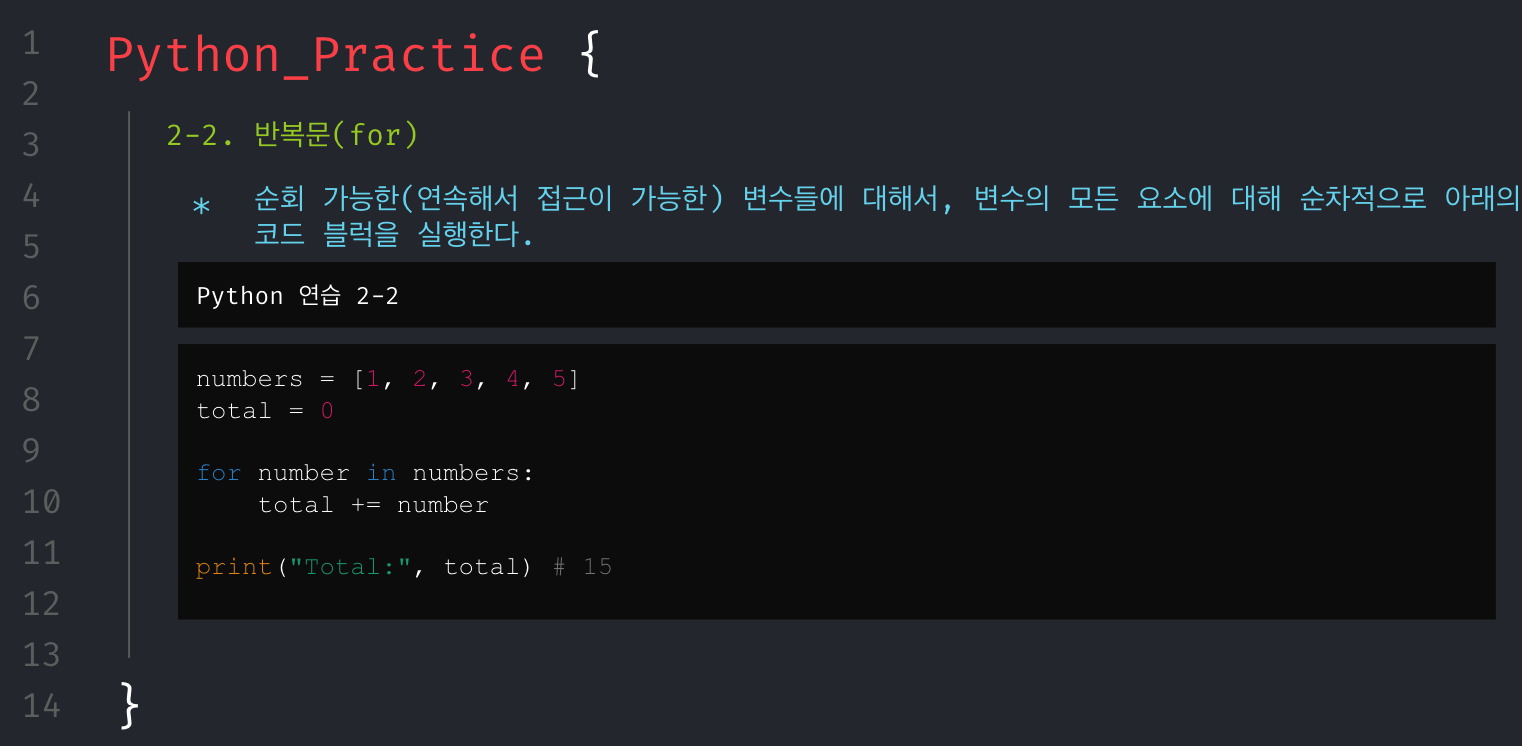
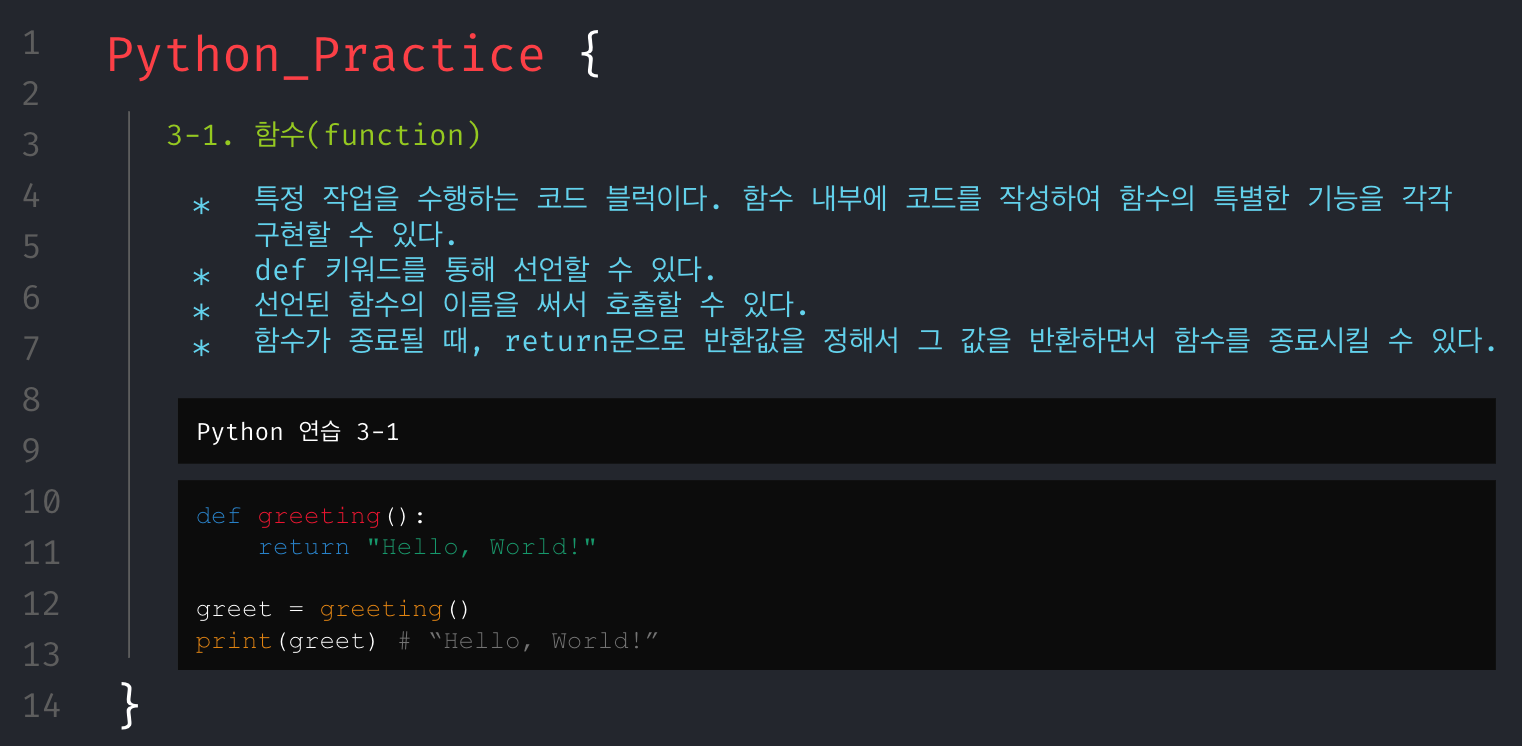
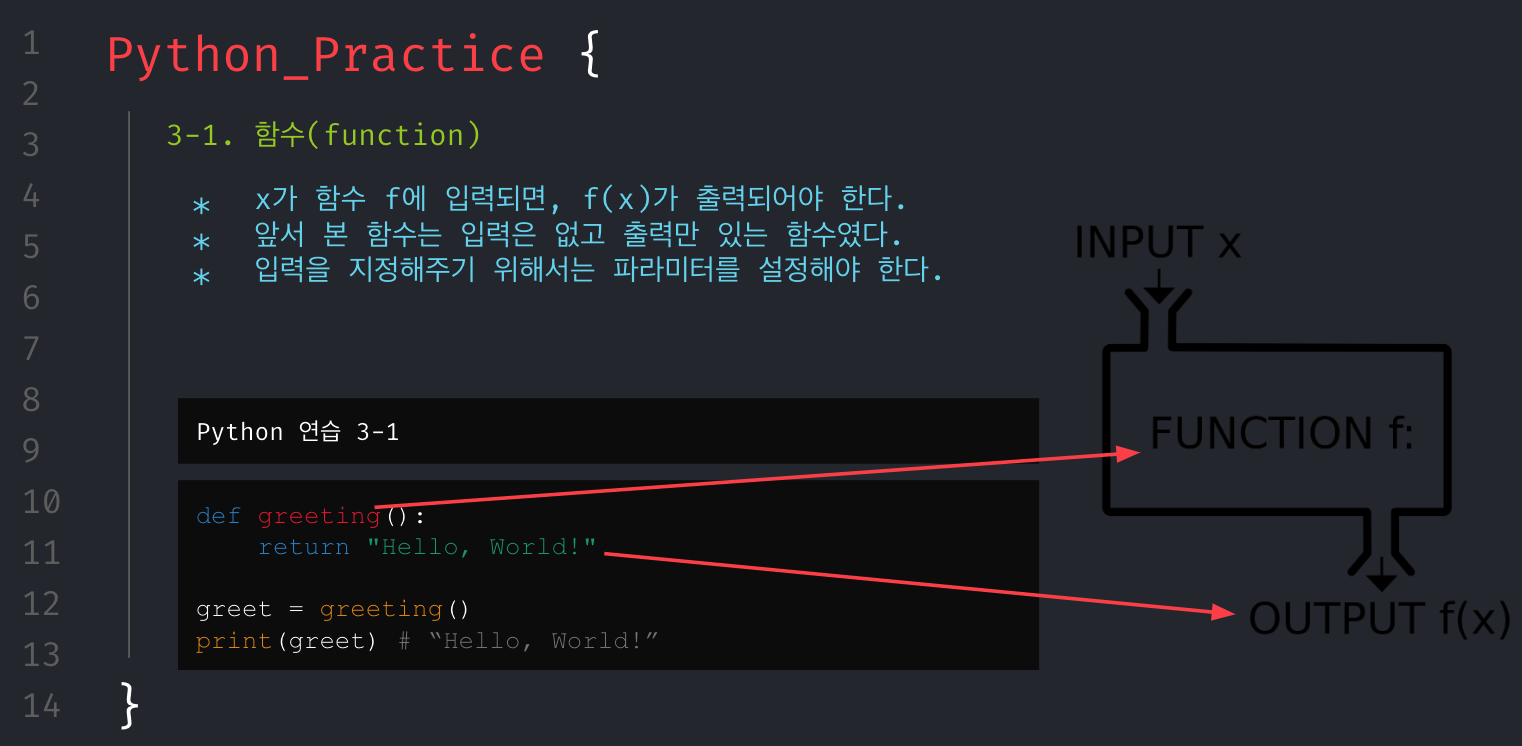

회고
역시나 재미있었다. 이전에 학원에서 수학 강의를 할 때 이후로 오랜만에 강의를 하느라고 강의를 준비하고 발표자료를 짜고 하니, 옛날 생각도 나면서 잘할 수 있을지 걱정도 되었다. 일단 아이들이 부족한 진행 능력에도 불구하고 꽤 집중을 잘 해주었다.
아이들의 코딩 실력을 제대로 알지 못한 채로 급하게 실습이 진행되다 보니까 확실히 시간이 더 많이 들게 되었다. 예상했던 시간 내에 마치지 못해서 마지막 부분을 최대한 급하게 진행하게 되었는데, 그 부분은 확실히 아쉬웠고 다음에 이런 강의를 하게 된다면 최대한 듣는 사람의 입장을 고려해서 구성해야겠다는 생각을 많이 하게 되었다.
그리고 사진 몇 장 찍어놓을 걸...하는 후회도 생기더라 ㅎㅎ
