각 특성의 데이터를 그 특성의 평균이 0이고 표준편차가 1이 되도록 변환한다. 이는 데이터를 정규분포에 가깝게 만들어주는 과정이다.
수식
Scaled Value = Value−Mean / Standard Deviation
- 일관된 스케일
다양한 스케일의 특성이 있을 때, 알고리즘은 높은 값의 범위를 가진 특성에 더 큰 가중치를 부여할 가능성이 있다. Standard Scaler를 사용하면 모든 특성이 동일한 스케일을 갖게 되므로 이 문제를 해결할 수 있다.
- 알고리즘의 성능 향상
많은 머신러닝 알고리즘들은 특성의 스케일이 유사할 때 더 잘 작동한다. 예를 들어, 경사 하강법은 스케일링이 잘 된 특성에서 더 빠르게 수렴할 수 있다.
df = pd.DataFrame( {
'A' : [10, 20, -10, 0, 25],
'B' : [1, 2, 3, 1, 0]
} )
dffrom sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()mms.fit_transform(df)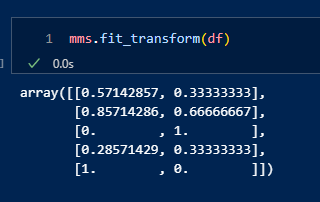
GPT : 예를 들어, 집의 크기와 방의 수라는 두 가지 특성이 있다고 가정해봅시다. 집의 크기는 수백에서 수천 제곱피트의 범위를 가질 수 있지만, 방의 수는 일반적으로 1~10의 범위를 가집니다. 이 두 특성의 스케일이 크게 다르므로, Standard Scaler를 사용하여 두 특성의 평균을 0으로, 표준편차를 1로 만들어 알고리즘이 두 특성을 공정하게 비교할 수 있도록 합니다.
특성 스케일링은 단위와 비례 관계에 관련되어 있으며, 기계 학습 알고리즘이 이러한 차이를 이해하고 더 잘 처리할 수 있도록 돕습니다. 서로 다른 단위 또는 범위의 특성을 비교할 때, 스케일링을 통해 이러한 특성을 표준화하고 비교 가능하게 만들 수 있습니다.
