Machine Learning
1.Min Max Scaling 이란
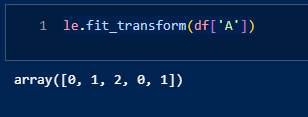
Min-Max 스케일링은 데이터를 특정 범위, 일반적으로 0과 1 사이로 재조정하는 기술입니다. 이 기술은 각 데이터 포인트에서 최솟값을 뺀 후, 최댓값과 최솟값의 차이로 나누는 공식을 사용합니다.Scaled Value = Value−Min / Max−Min이러한 스케
2023년 10월 18일
2.Standard Scaling 이란
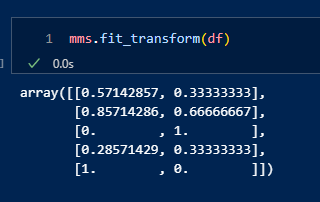
각 특성의 데이터를 그 특성의 평균이 0이고 표준편차가 1이 되도록 변환한다. 이는 데이터를 정규분포에 가깝게 만들어주는 과정이다.Scaled Value = Value−Mean / Standard Deviation다양한 스케일의 특성이 있을 때, 알고리즘은 높은 값의
2023년 10월 18일
3.Robust Scaling 이란
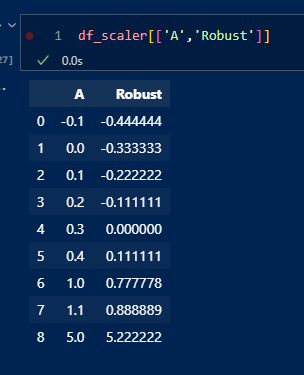
Robust Scaler는 데이터의 중앙값을 뺀 다음, 사분위수 범위(IQR, Interquartile Range)로 나누어 데이터를 스케일링한다. 이 방법은 특히 이상치(outliers)에 덜 민감한 스케일링을 원할 때 유용하다.Scaled Value = Value−
2023년 10월 18일
4.Scaler 비교
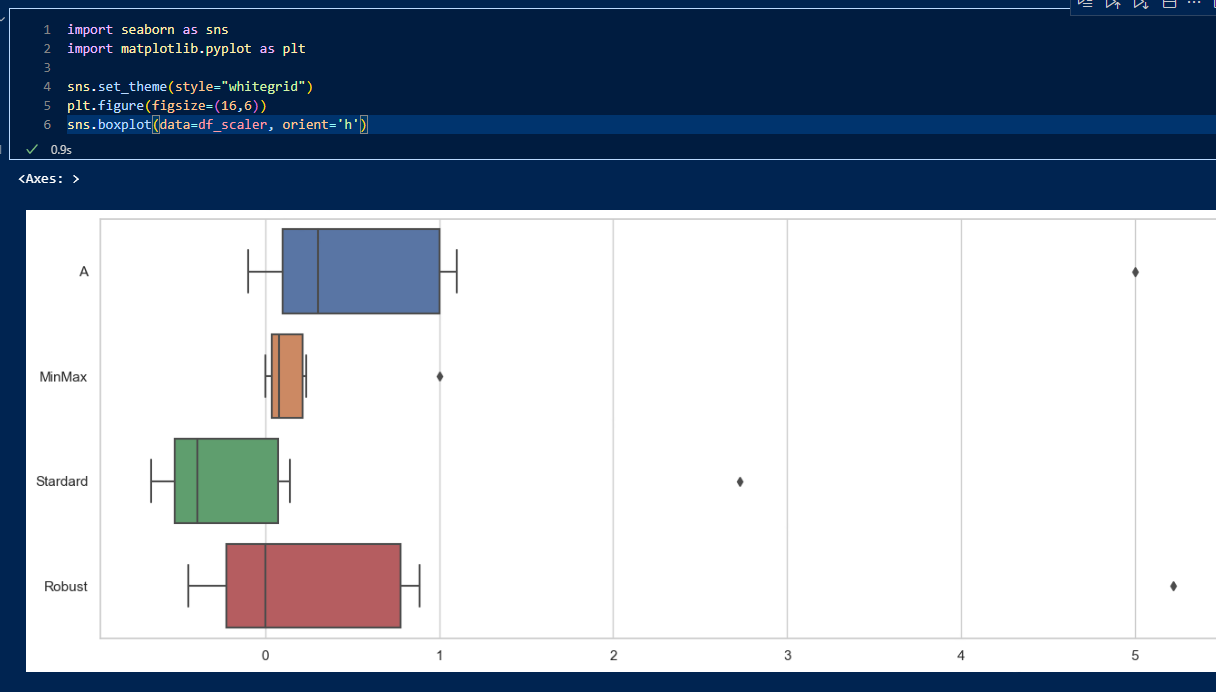
\- Standard Scaler는 데이터를 정규 분포에 가깝게 만들어야 하거나, 대규모 데이터셋에서 이상치의 영향이 상대적으로 덜할 때 유용할 수 있다.
2023년 10월 18일
5.permutation / feature importances 차이

정의: Feature Importance는 주로 결정 트리 기반 알고리즘(예: 랜덤 포레스트, 그래디언트 부스팅 머신)에서 사용되는 방법입니다. 이 방법은 모델의 학습 과정에서 각 특징이 얼마나 중요한 역할을 하는지를 평가합니다.계산 방식: 이 방법은 각 특징이 모델의
2023년 11월 28일