컴퓨터비전의 역사
Hubel & Wiesel, 1959
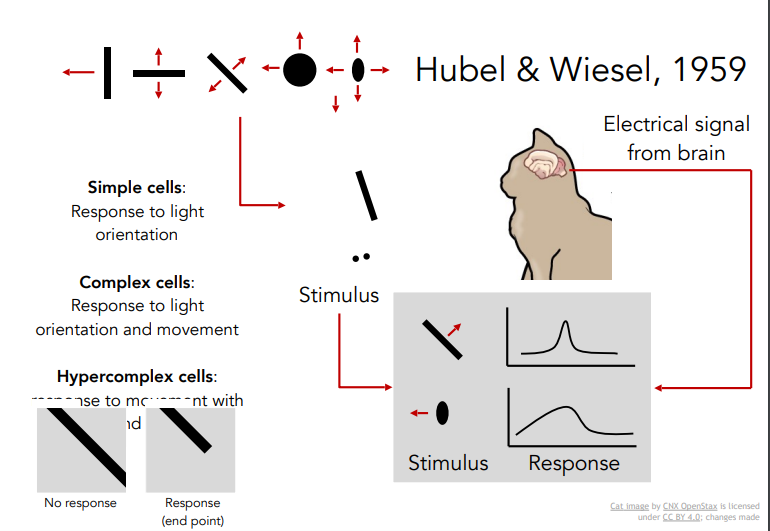
포유류의 시각적 처리 메커니즘에 대해 연구
Block World(Larry Roberts, 1963)

우리 눈에 보이는 사물들을 기하학적 모양으로 단순화
David Marr, 1970s
Vision 책 ➡️ 컴퓨터 비전이 어떤 방식으로 발전해야 하는지
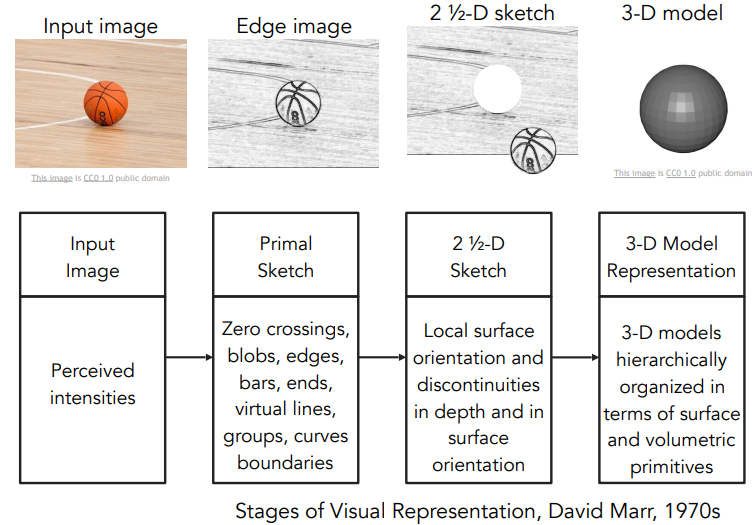
Input Image가 들어왔을 때 이미지의 특징들을 추출하고, 특징에 따라 depth와 surface를 추출 ➡️ 추출한 정보를 가지고 3D modeling
Generalized Cylinder & Pictorial Structure
기본 개념: 모든 객체는 단순한 기하학적 형태로 표현할 수 있다.
단순한 모양과 기하학적 구성을 이용해 복잡한 객체를 단순화
Generalized Cylinder (Brooks & Binford, 1979)
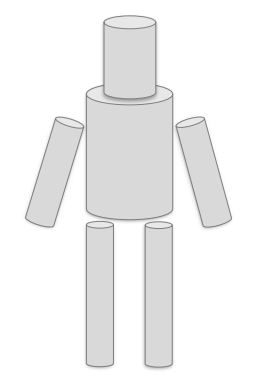
원통 모양을 조합해서 사람 표현
Pictorial Structure (Fischler and Elschlager, 1973)
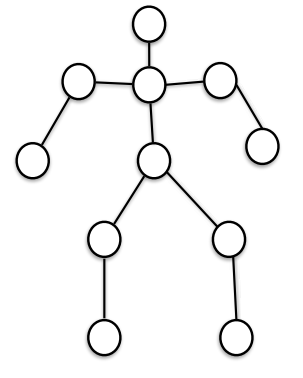
주요 부위와 관절을 사용해 사람 표현
Normalized Cut (Shi & Malik, 1997)
객체 분할(Object Segmentation) 시도
객체 분할
- 이미지의 각 픽셀을 의미있는 방향으로 군집화하는 방법
영상 분할(Image Segmentation)
- 픽셀을 모아놔도 사람을 정확히 인식하지 못할 수 있지만, 적어도 배경인 픽셀과 사람이 속해 있을지도 모르는 픽셀을 가려낼 수 있음
"SIFT" & Object Recognition, David Lowe, 1999

90년대 후반부터 2010년도까지 유행했던 알고리즘은 "특징기반 객체인식 알고리즘"
➡️ 이 시절에 나온 아주 유명한 알고리즘이 SIFT feature
📌 main idea
: 객체의 모양이 카메라 각도 혹은 조도의 영향에 따라 달라질 수 있지만, 불변하는 특징을 찾아 특징점끼리 매칭을 하는 것
이후 Spatial Pyramid Matching, Suppurt Vector Algorithm, History of Gradients(HoG), Deformable Part Model 등이 컴퓨터비전 분야에 큰 영향을 끼쳤다.
21세기에는 인터넷과 카메라의 발전으로 인해 실험데이터들의 질이 급격히 상승했다.
➡️ 이때부터 양질의 데이터셋을 모으기 위한 움직임이 이어졌다.
ImageNet
머신러닝 알고리즘을 트레이닝하는 과정에서 Overfit이 일어나는 문제가 생기는 이유는
- 시각 데이터가 매우 복잡하기 때문
- 학습 데이터가 부족하기 때문
따라서 컴퓨터비전 중 Classification 분야에서 두 가지 목표를 세운다.
- 세상의 모든 객체를 인식한다.
- Overfitting을 줄인다.
➡️ 이 목표를 위해 만든 데이터셋이 ImageNet
ImageNet
- 22K Categories & 14M Images이 있는 dataset
- 이 데이터셋을 가지고 Image Classification을 하는 대회인
ILSVRC(ImageNet Large Scale Visual Recognition Challenge를 개최
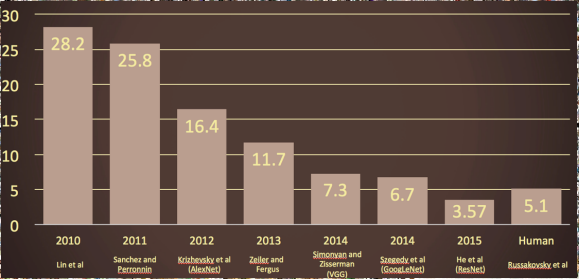
위의 슬라이드에서 2012년 오차율이 급격하게 줄어들었는데 이 알고리즘이 CNN 구조를 기반으로 한 ALexNet이다.
앞으로 이 수업에서는 CNN을 중점적으로 배우게 된다.
참고)
강의: https://www.youtube.com/watch?v=vT1JzLTH4G4&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=2
슬라이드: http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture1.pdf
