
Image Classification
- 컴퓨터 비전의 core task
- input image가 들어왔을 때, pre-determined categories/labels에서 이미지가 어디에 속할지 정하는 것
- 사람에게 이 과정은 매우 쉽지만 컴퓨터에게는 아주 어려운 task ➡
Semantic Gap때문!
Semantic Gap
컴퓨터는 이미지를 아래 이미지와 같이 큰 grid of numbers로 본다.

실제 이미지와 & 컴퓨터가 보는 pixel values 사이의 갭이 있는데 이 갭을 Semantic Gap이라고 한다.
컴퓨터가 이미지를 숫자들의 집합으로 보기 때문에 이미지에 작은 변화만 주더라도 픽셀 값이 변하게 된다. 이러한 영향을 주는 변화는 아래와 같다.
-
Viewpoint variation- 카메라의 위치 변화
-
Illumination- 조명에 의한 변화
-
Deformation- 객체 변형(pose & position)에 의한 변화
-
Occlusion- 객체 가려짐(예. 꼬리나 얼굴 일부분만 보임)에 의한 변화
-
Background Clutter- 배경과 유사한 색의 객체
-
Intraclass variation-
클래스 내부의 분산
- 예시) 고양이의 visual appereances(shape, sizes, colors, ages...) 다양성
-
Image classification 알고리즘을 작성할 때, 2가지 접근 방법
- 이미지의 특징을 찾고, 특징을 이용해 명시적 규칙을 만드는 방법으로 접근
- 데이터 중심으로 접근
✔ 데이터 중심으로 접근한 Nearest Neighbor Algorithm을 자세히 보자.
K-Nearest Neighbor Algorithm
Train: 모든 train data 기억Predict: 입력 데이터를 train data와 비교하여 어떤 label 값을 가질지 예측
Hyperparameter
- 학습을 하는데 영향을 미치는 parameter
- 학습을 하기 전 선택하는 parameter
K-Nearest Neighbor Algorithm에서 Hyperparameter는 K값과 Distance metric이다.
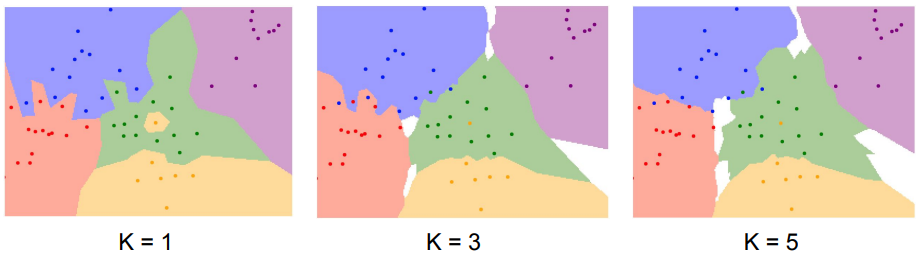
1) K값
과적합 발생을 막아준다.
아래와 같이 K값을 조절하면 경계선을 부드럽게 만들어주고 영역을 더 잘 분류하게 만들 수 있다.
2) Distance metric
-
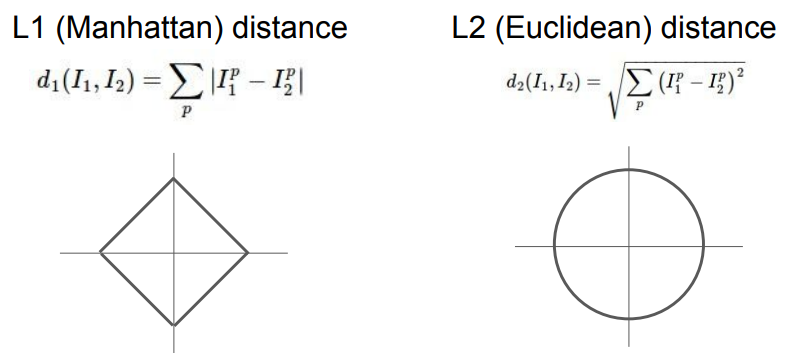
L1 distance
- 특정 벡터가 개별적인 의미를 가질 때 사용
-
L2 distance
- 벡터 요소들의 의미를 모르거나 중요하지 않을 때 사용
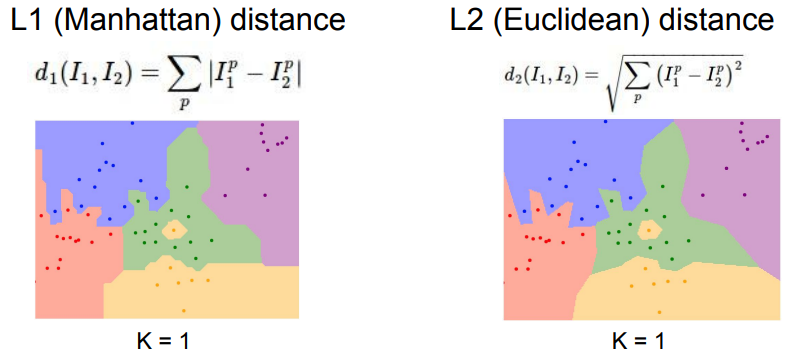
아래의 그림을 보면 Distance Metric에 따라서 경계선에 차이가 생기는 걸 볼 수 있다.
📌Hyperparameter를 잘 선택하는 방법
- Dataset을
train,validation,test로 나누는 방법

- Cross-Validation(교차 검증)을 위해 데이터를 여러
folds로 나누어, 각 fold를 validation으로 쓰고 결과의 평균을 쓰는 방법
➡ 작은 데이터셋에서는 유용하지만, 딥러닝에서는 잘 쓰지 않는다.
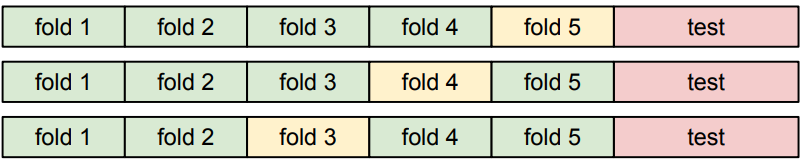
Image Classification에서 K-Nearest Neighbor Algorithm을 사용하지 않는 이유
- test 시간 ⬆⬆
- Distance Metric은 픽셀 단위에서 not informative
- 차원 증가 ➡ 필요한 train data 기하급수적으로 증가
Linear Classification
- Neural Network를 구성하는 가장 기본적인 요소
➡ Parametric model의 가장 단순한 예제가 Linear Classification
input image가 (32,32,3)일 때, 이 이미지가 주어진 10개의 카테고리 중 어디에 속하는지 찾아보자.
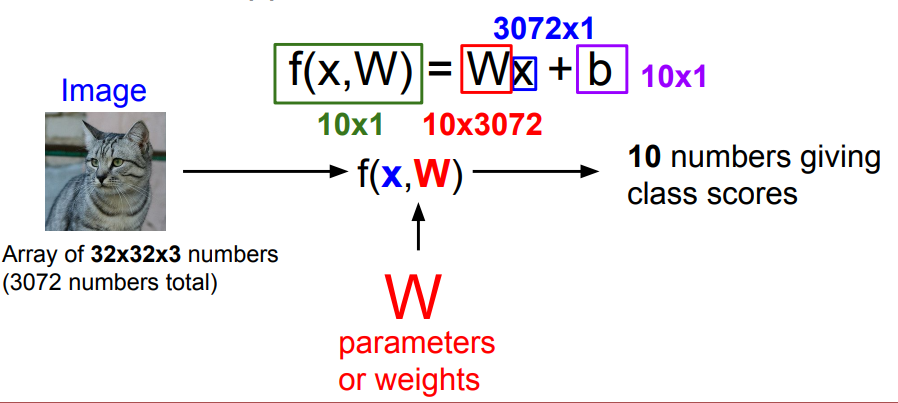
W
-
train data의 요약 정보가 들어 있어서 test할 때 시간을 단축시킬 수 있다.
-
입력 데이터를 하나의 벡터(3072 x 1)로 만든 후, 10개의 클래스에 대해 얼만큼의 점수를 부여하는지 결과값 ➡ 즉, (10 x 3072)
B
- bias(편향)를 의미
- B의 개수 = 카테고리의 개수 (1 x 10)
- 데이터와 무관하게 특정 클래스에 우선권 부여
- 주로 데이터셋이 unbalance할 때 사용 (예. 데이터셋에 고양이가 엄청 많은데 개는 적으면 고양이에 bias 값을 크게 부여)
f(x,W)를 잘 설계하는 것이 딥러닝의 핵심
Linear Classifier의 한계점은 카테고리마다 하나의 결과밖에 내지 못한다는 것이다.
또한 아래와 같은 풀기 어려운 문제들이 발생할 수 있다.
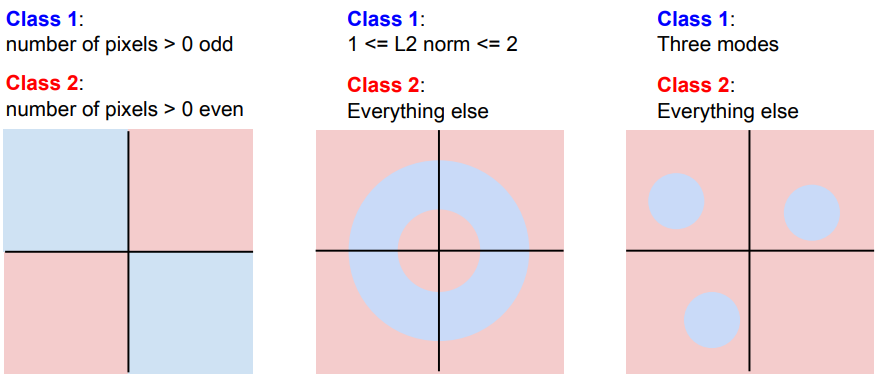
참고)
강의: https://www.youtube.com/watch?v=OoUX-nOEjG0&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=2&ab_channel=StanfordUniversitySchoolofEngineering
자료: http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture2.pdf
https://taeyoung96.github.io/cs231n/CS231n_2/
