
1. Loss Function
- 가중치 W가 얼마나 나쁜지를 정량적으로 보여주는 함수
- loss가 작으면 그 classifier는 이미지를 잘 분류하는 것
➡️ 이 classifier가 얼마나 잘 분류하는지!
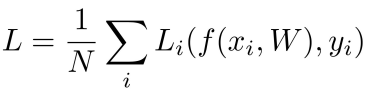
x_i : 입력 이미지
y_i : 예측 레이블 (실제 클래스의 정답 값)
L_i : 사용할 loss function
N : 클래스 수
➡️ Loss는 각 example에 대한 loss의 평균값
1-1. Multiclass SVM loss
- 2개의 클래스를 다루는 SVM을 일반화한 것
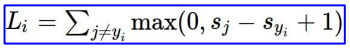
s_j : classifier을 통해 예측한 각 클래스 별 score
s_yi : 해당 클래스의 정답 score
1 : safety margin; 예측 값과 정답 값에 대한 상대적인 차이를 주기 위해 설정
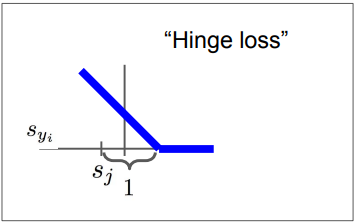
Multiclass SVM loss를 그래프로 그리면 위와 같은데, 그래프의 모양 때문에 Hinge loss라고도 부른다
정답 클래스에 가장 높은 점수를 매기면 Li는 0에 가까워진다. ➡️ 이미지를 잘 분류한다.

각 class의 loss를 계산해보면 2.9, 0, 12.9가 나오는데 이들의 평균인 5.27이 우리가 구하고자 하는 loss가 된다.
➡️ 0에 가까울수록 좋은 classifier이기 때문에 이 classifier는 이미지를 잘 분류하지 못한다고 볼 수 있다.
Q1. car score 조금 바꾸면 loss는?
📌 Multiclass SVM loss는 데이터에 민감하지 않기 때문에, score 값이 아니라 정답 클래스와 다른 클래스의 score 차이가 중요!
실제로 계산해봐도 된다. cat과 frog에 1을 더해도 car의 score보다는 낮기 때문에 loss의 변화는 없다.
loss는 여전히 0이다.
Q2. loss의 최대/최소값은?
위의 Hinge loss 그래프를 떠올려보면 쉽게 구할 수 있다!
최대값 = ∞, 최소값 = 0
Q3. W 초기화 작게 (모든 score ≈ 0) => loss는?
s_j와 s_yi에 0을 넣고 계산해보면 알 수 있다.
max(0, 0-0+1) + max(0, 0-0+1) = 2
2 + 2 + 2 / 3 = 2
➡️ class 수 - 1
📌 디버깅할 때 유용! (Sanity check)
만약 loss != 'class 수 - 1' ➡ 버그
loss =
class 수 - 1
Q4. 정답 클래스 속해서 더하면?
지금까지는 정답 클래스 값은 제외하고 loss를 구했다.
정답 클래스를 속해서 계산해보면 2.9 + 0 + max(0, 3.2 - 3.2 + 1) = 2.9 + 0 + 1 = 3.9
➡️ 각 클래스의 loss 1 증가 ➡ loss의 평균 또한 1 증가
최종 loss가 1이 된다.
Q5. 합 대신 평균 쓰면?
Q1에서도 말했듯이 Multiclass SVM loss function은 score 값이 중요한 게 아니라 score의 차이가 중요!!
➡️ 합 대신 평균을 사용하는 것은 점수의 차이를 단지 작게 해주는 것. scale이 작아지던 커지던 상관 없음!
loss가 영향 받는 것은 없다.
Q6. loss function 다른 거 쓰면?
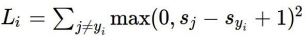
기존 식을 제곱한 식을 쓰면 loss가 달라진다.
참고로 이 식을 쓴 loss function은 Squared Hinge Loss라고 한다.
➡ 제곱을 하면 non linear해지기 때문에 그래프가 직선이 아닌 곡선!
loss가 달라진다.
Multiclass SVM Loss 코드

Q. W가 unique??
Q. Loss가 0이 되는 W를 찾았을 때, 이 W는 유일한 값일까?
A. Nope! 2W 역시 loss는 0이 된다.
즉, score에 배수 값을 취해도(2배, 3배 ...) 0이 되기 때문에 W는 여러 개!!
📍 그럼 어떤 W를 선택해야 할까?
train data를 이용해서 W를 찾고, 이를 test data에 적용했을 때 성능이 잘 나오는 것을 선택!
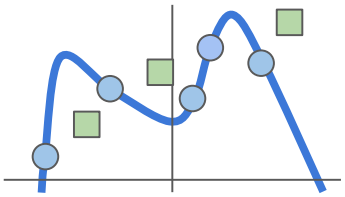
train을 해서 파란색에 해당하는 모양을 구했다고 했을 때, 초록색(test)은 예측하지 못하거나, 정확도가 낮다. ➡️ Overfitting(과적합)
파란색 모양보다는 아래의 그림에서 초록색 직선이 더 잘 예측할 것!
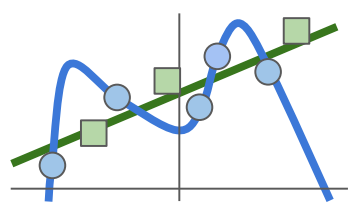
즉, test에도 맞는 W를 찾아야 한다!
📍 여기서 Regularization이라는 개념이 나온다!
Regularization
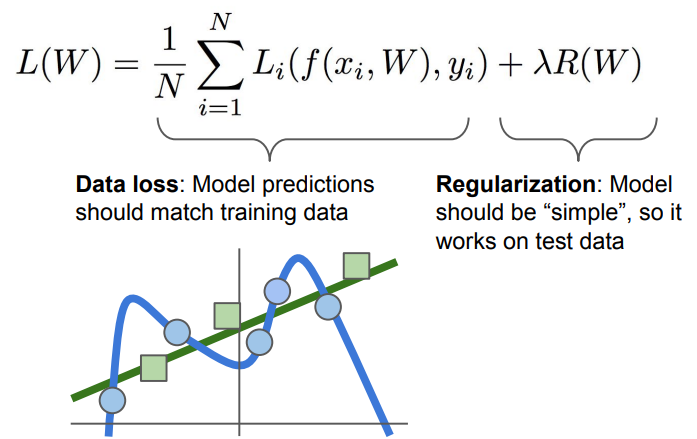
Data loss는 train data에 최적화된 예측 모델을 찾고, Regularization는 test data에 적합하도록 일반화된 예측 모델을 찾는다!

다항식이 커지지 않도록 (차수/차원이 깊어지지 않도록) 방지해주는 것!
- L1 : 차수 값이 0이 되도록 함
- L2 : 전체 차수의 값이 0에 가깝도록 유도
📌 일반적으로 L2 regularization을 많이 사용
1-2. Softmax Classifier
(Multinomial Logistic Regression)
Softmax: Multiclass SVM처럼 이항의 Logistic Regression을 다차원으로 일반화시킨 것
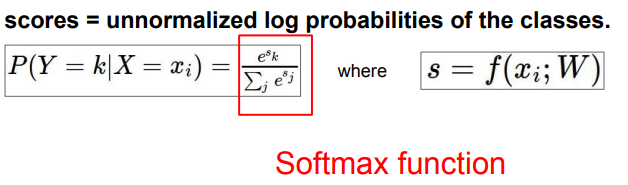
Softmax vs. SVM
📌 Multiclass SVM은 정답 클래스의 score & 다른 클래스의 score 간 차이에 관심을 보였다면, Softmax는 그 차이를 모두 수치화하여 score에 대한 해석을 한다.
2. Optimization
- Loss function을 최소화할 수 있는 parameter를 찾는 것
➡️ 어떤 W가 loss를 가장 적게 하는가 - 실제값과 loss의 차이를 줄일 수 있음
참고)
강의: https://www.youtube.com/watch?v=h7iBpEHGVNc&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=3&ab_channel=StanfordUniversitySchoolofEngineering
자료: http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture3.pdf
https://lsjsj92.tistory.com/391
https://velog.io/@guide333/4.5-CS231n-3%EA%B0%951-Loss-Functions
https://taeyoung96.github.io/cs231n/CS231n_3/
